多模态对比学习ALBEF(融合之前对齐)
论文题目(Title):Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
研究问题(Question):视觉信息和语言信息融合之前的对齐,实现最大化信息交互。
研究动机(Motivation):
(1)图像特征和文本符号映射仍然停留在他们自己的空间,使得多模态编码器很难学习建模他们之间的交互;
(2)物体检测器 --- 标注费钱,使用费算力 --- 在预训练阶段需要标注矩形框,在推理阶段高分辨率图像,如 600*1000,速度较慢;
(3)广泛使用的 image-text 数据集均是从网上搜集的带有严重噪声的数据,现有的预训练目标,如 MLM 可能过拟合到文本数据,降低了模型的泛化性能。
主要贡献(Contribution):
1.提出了对比损失,在图像和文本融合之前,将其对齐。
2.针对噪声数据,提出动量蒸馏,从动量模型(教师模型)的伪目标中学习。
研究思路(Idea):
作者提出了 ALBEF 以尝试解决上述问题。作者首先用一个 detector-free 的方式分别对 image 和 text 进行编码。然后,利用一个多模态编码器来融合图像特征。引入了一个中间的 image-text contrastive (ITC) 损失,该损失函数可以达到如下三个效果:
1). 其将 image 和 text 特征进行了对齐,使其更加易于多模态编码器进行跨模态学习;
2). 其改善了单个编码器以更好地理解图像和文本的语义意义;
3). 学习了一个公共的低纬度空间以映射 image 和 text,使得 image-text matching objective 可以通过对比困难负样本挖掘找到更多有信息的样本。
为了改善在噪声环境下的学习问题,本文引入了 Momentum Distillation (MoD),一个简单的方法就可以使得模型引入较大的网络数据集。在训练过程中,作者构建了一个动量版本,然后利用这个动量模型来产生 pseudo-targets 作为额外的监督。有了 MoD, 该模型就不会因为产生了其他合理的输出,且该输出不同于 web annotations 而受到惩罚。实验表明,MoD 不仅改善了 pre-training,也对下游任务有较好的提升。
研究方法(Method):
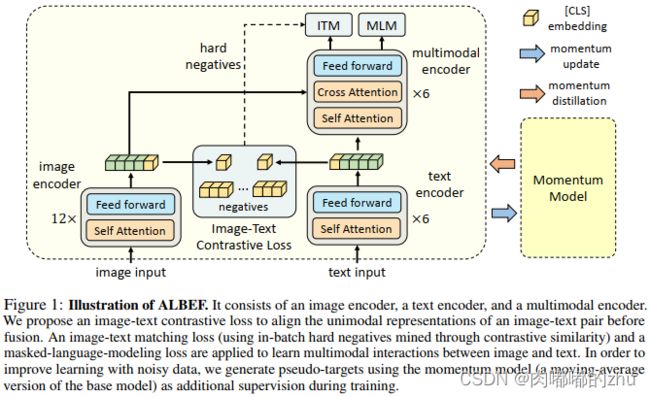
ALBEF包含一个图像编码器、一个文本编码器和一个多模态编码器。作者将一个12层的视觉transformer ViT-B/16作为图像编码器,并通过在ImageNet-1k上预训练的权重对图像编码器进行初始化。
研究过程(Process):
■ 预训练任务
作者在三个目标任务上进行预训练,分别是:(1)图像文本对比学习(ITC)(2)图像文本匹配(ITM)(3)掩码语言建模(MLM)。作者在单模态编码器上进行ITC和MLM训练,在多模态编码器上进行ITM训练。
1. 图像文本对比学习(Image-Text Contrastive Learning)
图像文本对比学习的目的是在融合前学习更好的单模态表示。它学习了一个相似度函数:

2.掩码语言建模(Masked Language Modeling)
掩码语言建模同时利用了图像和上下文文本来预测被掩盖的词。作者以15%的概率随机掩盖输入的token,并用特殊token[MASK]来替换它们。
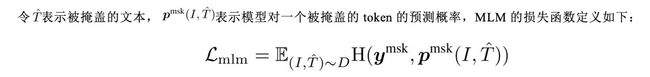
3.图像文本匹配(Image-Text Matching)
图像文本匹配预测了一对图像文本对是positive(匹配的)还是negative(不匹配的)。作者使用了[CLS] token在多模态编码器的输出嵌入作为图像文本对的联合表示,然后通过一个带有softmax的全连接层来预测一个二分类的概率。ITM的损失函数定义如下:
![]()
作者提出了一种对ITM任务进行hard negatives采样的策略。当负样本的图像文本对有相同的语义但在细粒度细节上不同,那么该样本是难样本。作者通过对比相似度寻找batch内的 hard negatives。对于一个batch中的每一幅图像,作者根据对比相似性分布从相同的batch中抽取一个负文本,其中与图像更相似的文本有更高的可能被采样。同样的,作者还为每个文本采样一个hard negative图像。
■ 动量蒸馏
用于预训练的图像文本对大多都收集自网络,往往都包含噪声。因此,正样本对经常是弱相关的,即文本包含和图像无关的文字或图像包含文本中没有描述的实体。对于ITC学习,图像的负样本文本可能也会匹配图像的内容。对于MLM,可能存在其他和标注不同的词能够更好地描述图像。但是ITC和MLM的one-hot标签会惩罚所有负标签预测,不考虑它们的正确性。
为了解决这一问题,作者提出从动量模型生成的伪目标中学习。动量模型是一个不断发展的教师模型,包含单模态和多模态编码器的指数移动平均版本。在训练过程中,作者训练基本模型使得它的预测值和动量模型的相匹配。对于ITC,作者首先使用来自动量单模态编码器的特征计算图像文本相似度,然后计算伪目标。
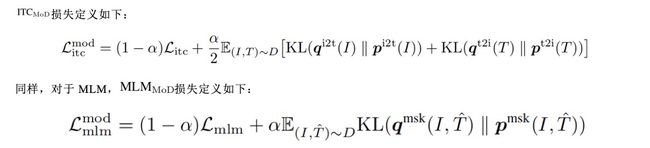
作者展示了伪目标中前5个候选对象的示例,有效地捕捉了图像的相关单词或文本。

1.数据集(Dataset)
作者使用了两个网页数据集(Conceptual Captions, SBU Captions)和两个in-domain数据集(COCO和Visual Genome)构建预训练数据。图像总数为4.0M,图像-文本对数量为5.1M。为了证明本文的方法可以用更大规模的web数据进行扩展,作者还使用了噪声更大的 Conceptual12M数据集,将图像总数增加到14.1M。
2.实验结果(Result)
1.下游任务
作者在五个下游任务上测试了预训练模型,分别为:
(1)Image-Text Retrieval:包含两个子任务,即image-to-text检索和text-to-image检索。
(2)Visual Entailment:一个视觉推理任务,用于预测一张图片和一段文本之间的关系是蕴含的、中立的还是对立的。
(3)Visual Question Answering:给定一张图片和一个问题,预测答案。
(4)Natural Language for Visual Reasoning:预测一段文本是否描述了图片。
(5)Visual Grounding:定位对应于特定文本描述的图像中的区域。
2. Evaluation on the Proposed Methods
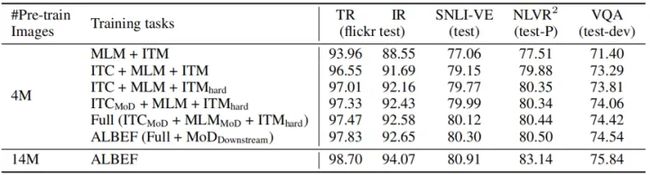
上表展示了本文方法的不同变体在下游任务上的性能。从表中可以看出,对比基础的预训练任务(MLM+ITM),增加ITC在所有任务上极大地提高了预训练模型的性能。前文所提到的hard negatives采样策略通过寻找更加具有信息的训练样本改进了ITM。此外,添加动量蒸馏改进了ITC、MLM和所有下游任务。表中最后一行表现了ALBEF可以有效地利用更多带有噪音的数据改进预训练的性能。
3. Evaluation on Image-Text Retrieval
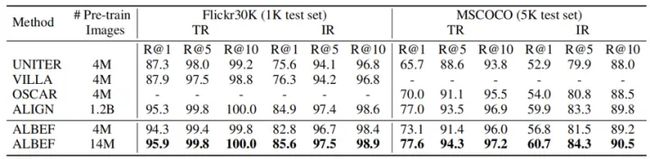
上表表现了图文检索微调的结果。
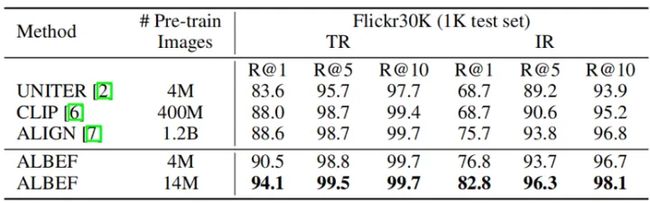
上表表现了图文检索zero-shot的结果。
ALBEF取得了SOTA性能,取得了比在数量级更大的数据集上进行训练的CLIP和ALIGN更好的效果。考虑到当训练图像的数量从4M增加到14M时,ALBEF有相当大的改进,作者认为它有可能通过在更大规模的图像文本对上训练进一步改进。
4. Evaluation on VQA, NLVR, and VE
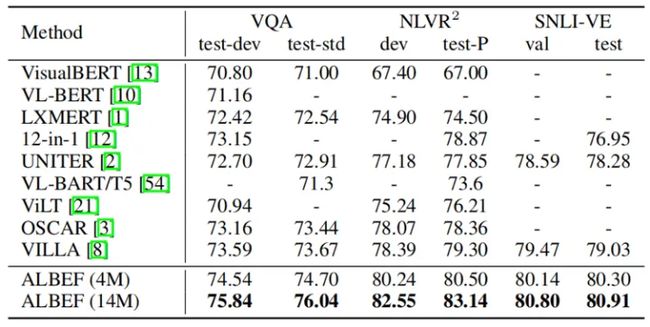
上表表现了本文方法和其他方法在其他理解类下游任务上的实验结果对比。在4M的预训练图片上,ALBEF已经取得了SOTA的性能。在14M的预训练图片上,ALBEF大大优于现有的方法,包括额外使用对象标签或对抗性数据增强的方法。和VILLA相对比,ALBEF在VQA test-std上取得了2.37%的改进,在NLVR^2 test-P上取得了3.84%的改进,在SNLI-VE test上取得了1.88%的改进。因为ALBEF是无检测器的,需要的图像分辨率更低,所以与大多数现有方法相比速度更快。
5. Weakly-supervised Visual Grounding
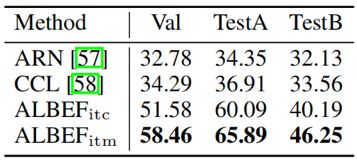
上表表现了在RefCOCO+上的结果,ALBEF的弱监督Visual Grounding效果远远超过现有的方法。

上图表现了在多模态编码器的第三层的cross-attention图上的Grad-CAM可视化。

上图表现了在VQA模型的多模态编码器的cross-attention图上的Grad-CAM可视化。

上图表现了与单个单词对应的cross-attention图上的Grad-CAM可视化。
值得注意的是,ALBEF不仅定位objects,而且还定位它们的属性和关系。
6.消融实验

上表研究了不同的设计选择对图像文本检索的效果。
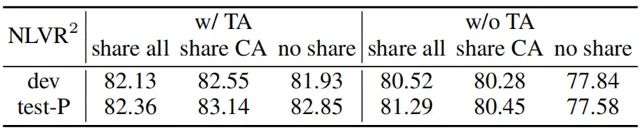
上表研究了文本分配(TA)预训练和参数共享对NLVR^2的影响。作者研究了三种策略:(1)这两个多模态块共享所有参数,(2)只有cross-attention (CA)层是共享的,(3)没有共享。如果没有TA,共享整个块会有更好的性能。通过TA对模型进行图像对的预训练,共享CA可以获得最好的性能。
总结(Conclusion):在将图像表示和文本表示通过一个多模态编码器融合之前,ALBEF首先将它们对齐。作者从理论上和实验上验证了所提出的图像-文本对比学习和动量蒸馏的有效性。与现有的方法相比,ALBEF在多个下游V+L任务上有更好的性能和更快的速度。