MIMO-UNet学习
MIMO-UNet学习
看了一篇去模糊的论文,使用这个MIMO-UNet跑自己找的数据集,效果图还没跑完。先记录一下学到的东西,有不正确的地方还望指出。
摘要
由粗到细的策略广泛应用于单图片去模糊网络结构当中。传统的方法是堆叠以多尺度图像作为输入的子网络。从底层子网络到顶部网络逐渐提高图像清晰度。产生了不可避免的高计算量消耗。为了设计一个快速而精确的去模糊网络,提出了MIMO-UNet。
MIMO-UNet的三个特点:
- MIMO-UNet的单个编码器输入多尺度的图像,降低了训练难度。
- MIMO-UNet的单个解码器输出多尺度的去模糊图像,单个U型网络,模拟多级联U-Net。
- 引入非对称特征融合(AFF),对多尺度特征进行有效融合。
介绍
这部分我觉得一半说的都是摘要和去模糊背景的东西,感觉不是那么重要,可以直接跳过,这里就记一下自己的笔记吧。
背景: 相机模块近十来年得到快速发展,当摄像机或目标移动的时候,模糊和伪影的现象仍然存在。早期:CNN的方法,用CNN作为模糊核的估计器,构建两阶段图像去模糊框架。CNN估计阶段 + 基于核的去卷积阶段。(我的理解就是一个用来估计模糊核,一个通过学习,学习使用模糊核来去模糊,用非盲去模糊的方式去模糊)。近期:基于CNN的去模糊方法,直接端到端的方式,学习模糊-清晰图像之间的复杂关系。Deepblur:由多个堆叠的子网络组成,用于处理多尺度模糊,每个子网络取一个缩小的图像,然后以粗到细的方式逐渐恢复一个清晰图像。
由粗到细的网络设计原则已被证明是有效的图像去模糊方法。
然而,这却增加了计算量和内存的使用,在移动设备,车辆,机器人上面难以使用。提出了一个轻量CNN的网络,比传统的网络浅,但无法达到最先进方法的精度。
提出了MIMO-UNet。解码器输出多个去模糊图像,multi-output single decoder(MOSD)。单编码器输入多尺度图像,multi-input single encoder(MISE)。非对称特征融合,对多尺度特征进行有效融合,asymmetric feature fusion(AFF)。
结构
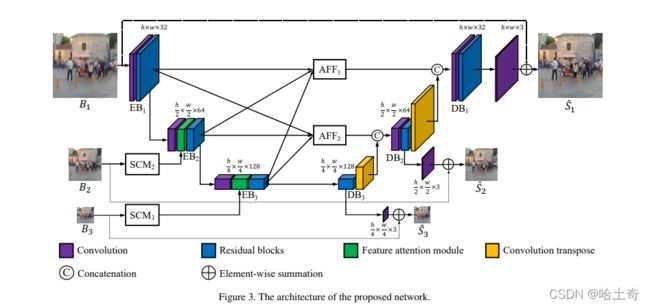
MIMO-UNet的编码器和生成器是由3个EBs(Encoder Blocks)和3个DBs(Decoder Blocks)组成。
多输入的单编码器 MISE
有研究表明,多尺度图像可以更好地处理图像中不同程度的模糊。
在MIMO-UNet当中,一个EB用不同尺寸的模糊图像作为输入。然后用缩小后的特征和下采样的图像互补信息。这种方法可以有效处理各种图像的模糊。
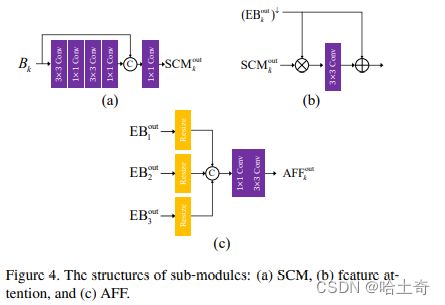
使用shallow convolutional module(SCM)从下采样提取特征,考虑到效率问题,如图4(a),使用3 x 3和1 x 1卷积层堆叠。将最后1x1层的结果和前边输入B结合,在用1 x 1细化连接特征。对于 S C M k o u t SCM^{out}_{k} SCMkout的特征和 E B k − 1 o u t EB^{out}_{k-1} EBk−1out的融合,使用一个stride为2的卷积给到EB上,使得大小和SCM的输出一致进行融合。
这里也提出了一个feature attention module(FAM)特征注意力模块,用来主动强调或者抑制尺度特征,并且从SCM中学习空间/通道特征的重要特征。 ( E B k − 1 o u t ) ↓ (EB^{out}_{k-1})^{\downarrow} (EBk−1out)↓(就是前面说的经过那个卷积之后,尺寸缩小的那个)和SCM之间是元素之间相乘,之后通过一个3 x 3 的卷积,输出包含互补信息来进行去模糊,最终加到 ( E B k − 1 o u t ) ↓ (EB^{out}_{k-1})^{\downarrow} (EBk−1out)↓中,最后用残差块进行细化,使用了8个修改过的残差块。
EB(Encoder Block)详细解释
MIMOUnet中的EB,不仅仅是接收上一个EB中提取的缩小特征外,还从下采样的模糊图像中提取特征,然后两者结合起来。利用了压缩特征和下采样的特征。图中EB有三层(紫色,绿色,蓝色)
紫色: 一个步长为2的卷积层,用来将上层EB输出的特征进行压缩,同时也是降低尺寸和下采样的SCM产生的特征图大小一致。
绿色: 为FAM模块,用来主动强调或抑制尺度特征,期望获得互补信息用来去模糊。逐个元素相乘(个人理解是,通过图中的做法可以列出公式方便理解。 ( E B k − 1 o u t ) ↓ (EB^{out}_{k-1})^{\downarrow} (EBk−1out)↓假设为X1,下边SCM模块的特征为X2,中间的卷积可以作为f(x)的操作。那么总公式则为X1 + f(X1 * X2),中间的卷积理解为权重的调整W,提出X1得到。X1 * (1 + W * X2),那么也就是说,中间的卷积是起到了自动调节增强或抑制各个特征权重的功能)FAM模块,文中使用了消融实验证实该模块有助于提高PSNR指标。
蓝色: 为残差模块,MIMO-UNet中是8个残差块,将前面的特征进行总结细化。MIMO-UNet++则是20个残差块。
多输出的单解码器 MOSD
在MIMO-UNet中,不同的DB有不同的特征图尺寸,文中的做法就是将中间监督应用到每个解码器当中。就是每个Decoder Block的产出都是有对应尺寸的清晰图进行训练。但是DB产生的是特征图而不是图像,然后就用的一个o()函数将特征图映射到图像。公式如下
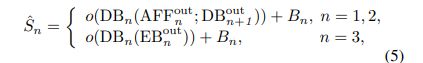
这个映射其实就是一个卷积。转为三通道的一个卷积。
非对称特征融合 AFF
每个AFF拿到所有EB的输出作为输入,用卷积结合多尺度特征。解决的问题: 传统的由粗到细的去模糊方法中粗尺度网络中特征用于细尺度网络,导致信息流动不灵活。提出了AFF模块,让不同尺度信息在一个U-Net中流动。每个AFF将所有EB的输出作为输入,并用卷积结合多尺度特征。传入对应的DB中。让每个DB可以得到不同尺度的特征,提高去模糊的性能。
loss函数
内容损失使用的是L1Loss
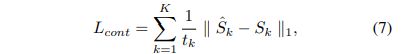
由于去模糊的目的是恢复丢失的高频分量,因此减少频率空间的差异至关重要,所以提出了MSFR损失
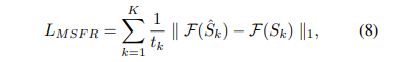
F指的是快速傅里叶变换(FFT),最终损失为
![]()
文中设定lambda为0.1
代码注意点
论文中提供的是pytorch代码,版本比较老,如果是较新的pytorch版本需要将代码有些改动。改动如下:
# 插值修改尺寸部分
F.interpolate(...., recompute_scale_factor=True)
# 所有代码中做插值修改尺寸大小中,要添加recompute_scale_factor=True参数,明确按照老版本的方式执行。不加会有警告。
# 傅里叶变换部分代码修改
# 旧版
label_fft1 = torch.rfft(label_img4, signal_ndim=2, normalized=False, onesided=False)
# 新版
t = rfft2(label_img4, dim = (-2))
label_fft1 = torch.stack((t.real, t.imag), -1)
效果图
以下是用的是自己找的数据集跑的,是跑的30个epoch的结果。论文中的使用的是GoPro和RealBlur数据集,在GoPro训练了3000个epoch,Adam优化器,初始化学习率为 1 0 − 4 10^{-4} 10−4,每500个epoch减小为原始的0.5。在Realblur中训练1000epoch,相同学习率,也是500个epoch减小为原始的0.5
模糊图

生成图

Ground Truth
额,我把我修改过能跑通的MIMOUNet代码也放出来吧。
MIMOUNet
相关链接
Rethinking Coarse-to-Fine Approach in Single Image Deblurring
论文中源码MIMO-UNet