LMOEA-DS算法_2021TEVC_大规模多目标优化
Large-Scale Evolutionary Multiobjective Optimization Assisted by Directed Sampling_2021TEVC
- 背景
-
- 三个论文创新点
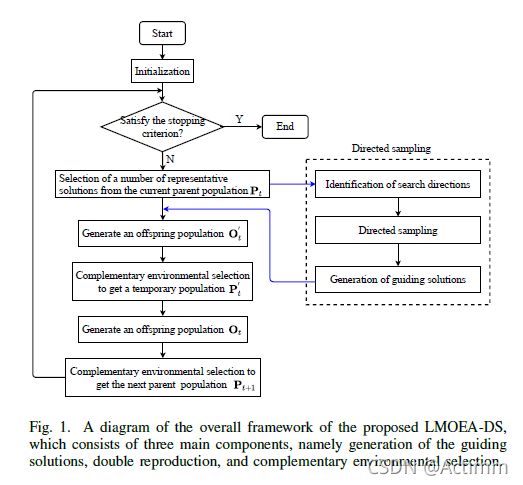
- 所提出的LMOEA-DS
- 初始化
- 直接采样和指导解的产生
- *Double Reproduction and Complementary Environmental Selection*
- 实验(快结束了)
背景
大规模多目标算法的分类
- Cooperative coevolution (CC) 的算法,CCGDE3。
- Decision variable clustering based MOEAs. (这里应该是决策变量划分的算法),MOEA/DVA和LMEA。还有一个在LMEA上加一个PCA降维的算法,PCA-MOEA
3.问题转化算法,WOF,LSMOF
4.新奇的方法:LMOCSO,一个an information
feedback model (IFM)产生子代的算法等
缺点: 1和2 有的会消耗评价次数,性能受限于分组技术;其他的算法可能会耗费很多的评价次数,如LMOCSO评价次数设置为15000 X D,D为决策变量数目。
问题转化的算法,会陷入局部最优。
三个论文创新点
通俗讲解论文,实际上论文是将何成的LMOF算法中的另个方向向量进行改进or应用。LMOF的工作是通过一个单目标的进化算法来找最优参数,这个论文是通过直接采样。再加上其他的创新点等。
- 种群进化的每一带中,直接采用的方式被用来产生子代。 目标空间的解通过一些少的参考向量聚为几类。(在目标空间中聚类)。 然后,每一个类中的个体距离理想点最近的被挑选作为指导解。每一个指导解会产生两个搜索方向,然采样点在这些方向产生子代。
- 两个产生子代的过程
- 环境选择,分别使用了参考向量和非支配排序。
所提出的LMOEA-DS
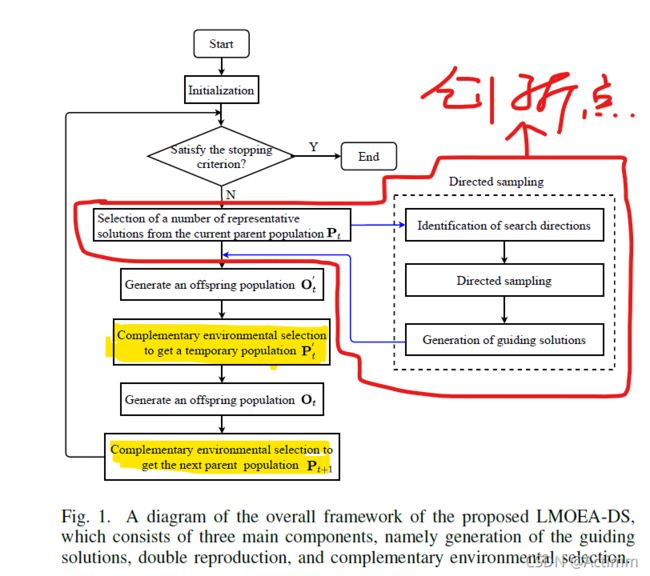
三部分组成:1.identification of the guiding solutions, 2. guided double reproduction, and 3.comlementary environmental selection.
初始化
首先,种群随机的初始化。
两个参考向量集合W和W’被创建。其中W’的集合中的参考向量数目小于W的。W集合大小和种群数目一样,用来做环境选择。W’用于将目标空间划分为子区域用于目标空间中的种群聚类。
假设NW’个解被选择来产生方向,我们用W’个参考向量将目标空间中的解用K-menas聚类为NW’–m类.
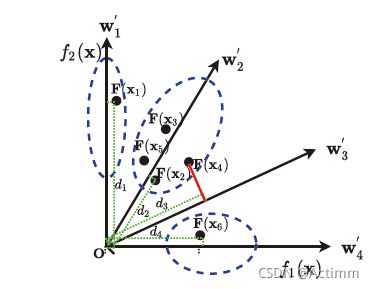
比如上图,5个参考向量W’,聚类为5-2=3类。
直接采样和指导解的产生
指导解的意义是协助MOEA来发现正确的搜索方向来加速收敛。问题是理想点只有一个在目标空间中,将目标空间中的解进行聚类,是为了选择多个个体距离理想点近的解,保证一个多样性。

上图聚类之后,每一个区域都可以选择距离理想点最近的解,这样就可以选择三个而不是一个。
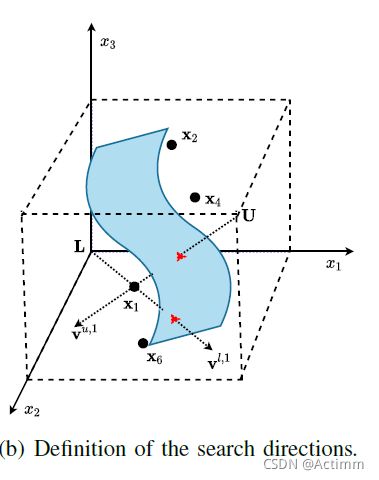
- Identification of Search Directions: 解的产生是决策空间中,而解的评价和比较是在目标空间。
目标空间中接近理想点的解保证一个好的搜索方向。一个解在决策空间中,和决策空间的下边界点和上边界点形成了两个搜索直线。
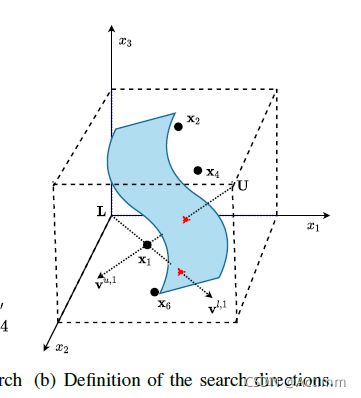
上图是一个三维的决策空间示意图,蓝色的曲面是PS,解x1形成两个搜索直线。实际上这个是LSMOF论文中的中的创新思想。
前面提出的W’是用于在目标空间进行划分解。每一解都找到距离最近的参考向量(参考向量和解相关联起来),每一个向量至少分配一个解。
整个种群被划分为NW’个(我认为NW’=|W’|-M;M为目标数,|.|为参考向量的个数)。(吐槽:论文符号不严谨)
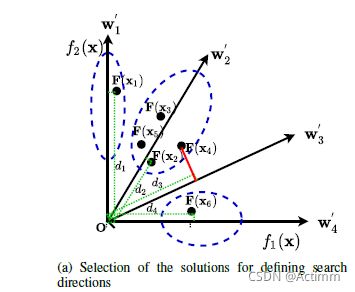
上图中,蓝色圈内是一个子种群,总共有三个子种群。如果有的参考向量没有分配到解,那么就从临近的参考向量中挑出一个距离最近的,如图中的X4分配给了W3’.
明确一下NW’为挑选的距离理想点最近的解,这样每个解两个方向。 2 × N W ′ 2 \times N_W^\prime 2×NW′个搜索方向。

这幅图解释上面的公式,很简单,向量的加减乘除。

这个所谓的“伪代码”很清楚了,描述了如何挑选出指导解和生成搜索方向。
直接采样
![]()
上图是产生的 2 × N W ′ 2\times N_W^\prime 2×NW′个方向向量。这些方向向量在决策空间中和PS相交有三种情况。
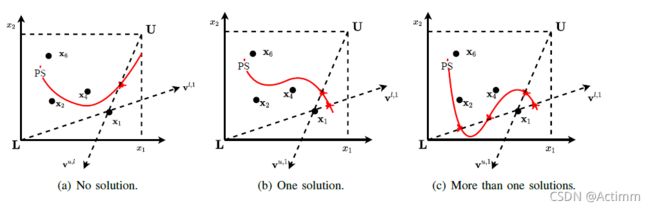
红色为PS。理论上,我们可以通过优化方式,发现这些和PS相交的点(LMOF使用的进化的单目标方式),但是当第三种情况,有多个点和PF相交的话,进化算法(LSMOF)的方式可能只能找到一个点。
所以本文的采用一个随机的采用,就是随机数来生成在这些方向上的点。

S就是0~||U-L||的随机数。
个人理解,这样产生子代的方法可以嵌入到每一代中,更好的非支配解产生更好的方向向量,产生更好在方向向量的解,随机的方法更为的简单,产生多个解(只要生成多个随机数),比LMOF的算法更为的灵活。
指导解的产生
假设每个方向上采样NS个值(NS个值),那么总共会产生 2 × N S × N W ′ 2\times N_S \times N_W^\prime 2×NS×NW′个解。(其中回顾一下 N W ′ N_W^\prime NW′为挑选的距离理想点最近的解的数目.)
这些采样产生的解和放入种群中过滤出所有的非支配解,放在存档SG中。存档中的解作为指导解来产生一些后代。
Double Reproduction and Complementary Environmental Selection
指导解在存档中,作用是用来当做双亲中的一方,另一方在种群P中。产生|Pt|个子代O’t。(交叉和变异)。
然后环境选择在 C t ′ = P t + O t ′ + S G C^\prime_t=P_t+O^\prime_t+S_G Ct′=Pt+Ot′+SG上执行。然后是正常的交叉和变异在种群 P t ′ P^\prime_t Pt′中进行,和正常的环境选择。
环境选择的伪代码:

创新点就是一个NSGAII的环境选择加一个参考向量的选择,自定义了一个参数
其中这个参数兼顾了收敛性和多样性,很简单。Cos值越大,角度等于0,越好,d越小越好。(折磨简单的公式)
实验(快结束了)
1.所有的算法都跑20次
2.函数评价为80000(这个倒是挺少)
3.初始种群大小为153,SBX和PM,其中交叉概率为0.9(其他参数一样)
4.采样点的数目为30,就是每个方向产生30个子代
5.环境选择中的一个参数为Nx(2/3),意思是有三分之一的参考向量没有分配到解,就使用NSGAII的环境选择。
消融实验
在决策变量为5000个上LMOP1和LMOP4和LMOP7上跑20次
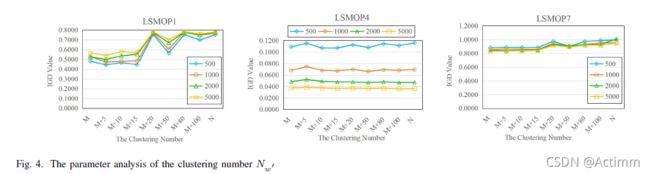
最终采用了M+10这样的参数,也就是参考向量W’的数目。这个实验做的不错,讲道理!
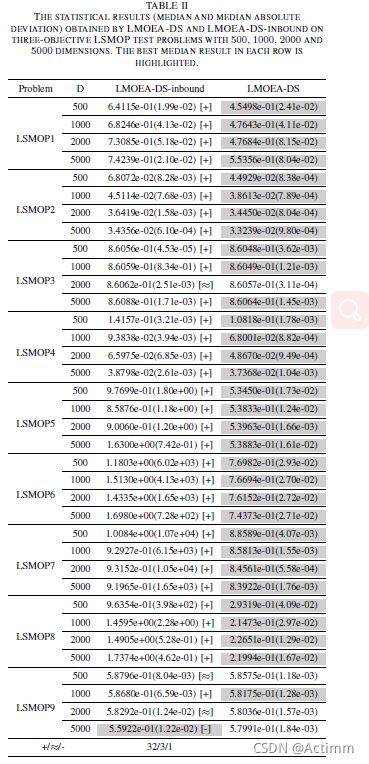
上面对比了LMOF中使用一个HV指标的单目标寻找采样点值的方法和本文随机采样点的办法。参数设置上公平。
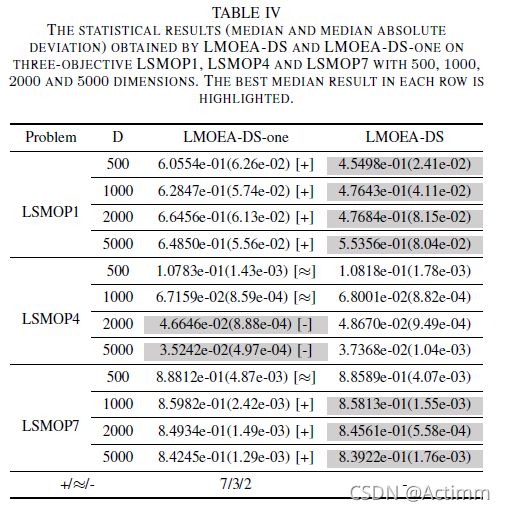
这个表是采用了一次产生子代和本文两次产生子代的对比。
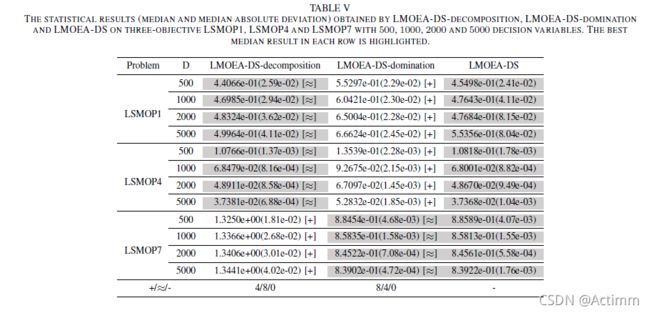
上表是对比了环境选择,一个是只是使用参考向量,一个是只是用NSGAII的,最后是本文两个都结合的。
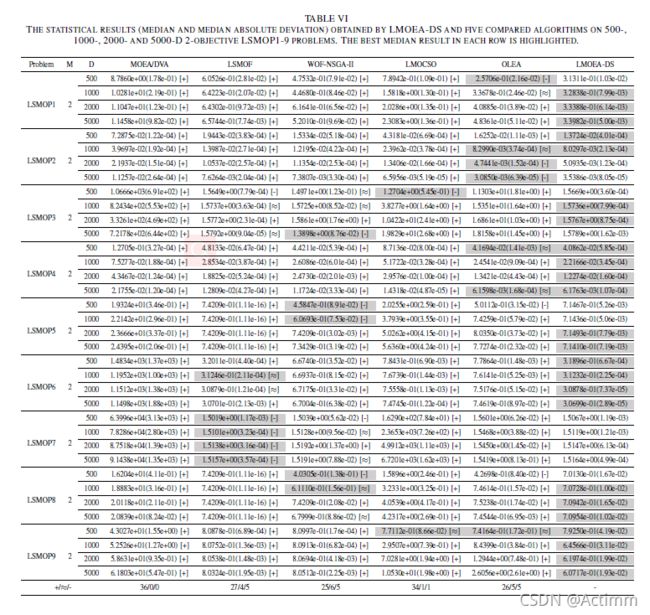
2个目标上的对比
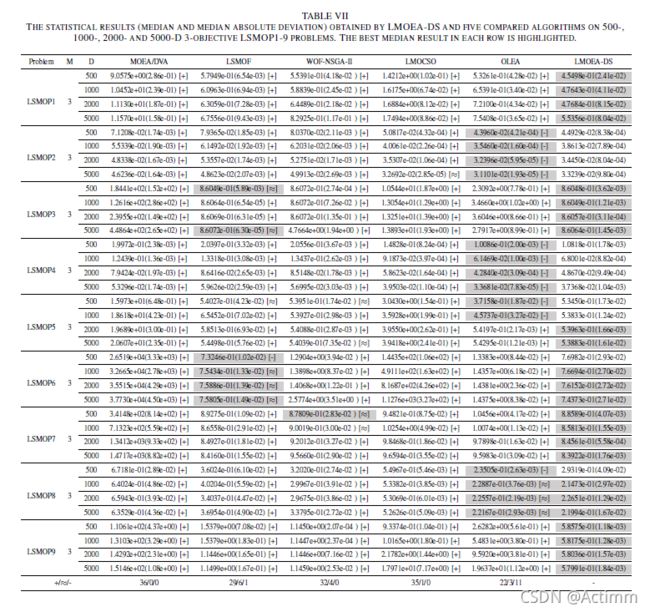
三个目标上的对比。
总结,加油努力学习,努力搬砖。