数字图像处理练习题整理 (二)
- 注: 内容仅供参考, 不保证正确性, 如有误欢迎交流指正.
- 鸣谢: 感谢 小组的各位同学为内容整理提供的帮助
四.空域邻域滤波
1. 高斯模板生成
请写出生成大小为 (2N+1)×(2N+1)、标准差为 sigma 的高斯模板 H 的方法。
二维高斯模板矩阵 H H H, 模板的大小为 ( 2 N + 1 , 2 N + 1 ) (2N+1, 2N+1) (2N+1,2N+1), 标准差为 σ \sigma σ, 则其中 ( N , N ) (N,N) (N,N) 为模板中心, 则 H ( i , j ) H(i, j) H(i,j) 的值如下所示:
H ( i , j ) = 1 2 π σ 2 exp ( − ( i − N − 1 ) 2 + ( j − N − 1 ) 2 2 σ 2 ) H(i,j)=\frac{1}{2\pi \sigma^2}\exp(-\frac{(i-N-1)^2+(j-N-1)^2}{2\sigma^2}) H(i,j)=2πσ21exp(−2σ2(i−N−1)2+(j−N−1)2)
代码:

请写出生成大小为 (2N+1)×(2N+1)、标准差为 sigma 的高斯一阶导数模板 HX(水平方向的梯度)、HY(垂直方向的梯度)的方法。
H x ( i , j ) = − x σ 2 H ( i , j ) H_x(i,j)=-\frac{x}{\sigma^2}H(i,j) Hx(i,j)=−σ2xH(i,j)
H y ( i , j ) = − y σ 2 H ( i , j ) H_y(i,j)=-\frac{y}{\sigma^2}H(i,j) Hy(i,j)=−σ2yH(i,j)
代码:


2. 线性滤波
请写出使用大小为(2N+1)×(2N+1)模板 H 对图像 I 进行滤波,生成图像 J 的方法。
- 模板在图像中漫游,并将模板中心与某像素重合
- 将模板系数与模板下对应像素相乘
- 将所有乘积相加
- 将上述求和结果赋予模板中心对应像素
J ( i , j ) = ∑ m , n I ( m , n ) H ( m − i , n − j ) = I ( i , j ) H ( 0 , 0 ) + I ( i + 1 , j + 1 ) H ( 1 , 1 ) + . . . + I ( i − 1 , j − 1 ) H ( − 1 , − 1 ) J(i,j)=\sum_{m,n}I(m,n)H(m-i,n-j)=I(i,j)H(0,0)+I(i+1,j+1)H(1,1)+...+I(i-1,j-1)H(-1,-1) J(i,j)=m,n∑I(m,n)H(m−i,n−j)=I(i,j)H(0,0)+I(i+1,j+1)H(1,1)+...+I(i−1,j−1)H(−1,−1)
代码:

算法流程:
- 获得源图像的首地址及图像的宽和高
- 开辟一块内存缓冲区,用以暂存结果图像,并初始化为0
- 选取线性模板和原图像进行卷积计算
- 将结果从内存缓冲区复制到源图像的数据区
3. 高斯滤波
在线性滤波器为一个高斯模板时,不同大小的高斯模板会产生怎样的滤波效果?
当 σ \sigma σ 值固定时,高斯模板越大,其权值分布越平缓,因此邻域各点值对输出值的影响越大,最终导致图像平滑力度增大, 即图像越模糊。
- 拓展: 不同 σ \sigma σ 对滤波效果的影响:
高斯滤波模板中最重要的参数就是高斯分布的标准差 σ \sigma σ, 它代表着数据的离散程度.
如果 σ \sigma σ 较小,那么生成的模板中心系数越大,而周围的系数越小,这样对图像的平滑效果就不是很明显;相反, σ \sigma σ 较大时,则生成的模板的各个系数相差就不是很大,比较类似于均值模板,对图像的平滑效果就比较明显.
4. 中值滤波
请写出使用大小为3×3的模板对图像 I 进行中值滤波,生成图像J的方法。
中值滤波将模板里面的所有像素进行排序取得中位数来代表该窗口中心的像素值,对椒盐噪声和脉冲噪声的抑制效果特别好,同时又能保留边缘细节,用公式表示是:
J ( x , y ) = m e d i a n ( I ( i , j ) ) , ( i , j ) ∈ N e i g h b o r ( x , y ) J(x,y)=median(I(i,j)),\quad (i,j)\in Neighbor(x,y) J(x,y)=median(I(i,j)),(i,j)∈Neighbor(x,y)
其中, N e i g h b o r ( x , y ) Neighbor(x,y) Neighbor(x,y) 表示以 ( x , y ) (x,y) (x,y) 为中心的模板大小
代码:

算法流程:
- 获得源图像的首地址及图像的宽和高
- 开辟一块内存缓冲区,用以暂存结果图像,并初始化为0
- 逐个扫描图像中的像素点,将其邻域各元素的像素值从小到大进行排序,将求得到的中间值赋值给目标图像中与当前点对应的像素点
- 循环步骤 (3),直到处理完源图像的全部像素点
- 将结果从内存缓冲区复制到源图像的数据区
简述中值滤波的特性和适用场合。
中值滤波是一种非线性滤波,由于它在实际运算过程中并不需要图像的统计特性,所以比较方便。
中值滤波首先是被应用在一维信号处理技术中,后来被二维图像信号处理技术所应用。
在一定的条件下,可以克服线性滤波器所带来的图像细节模糊,而且对抑制图像随机脉冲噪声及图像扫描噪声、散射噪声的处理比较理想,因为其通常与周围像素值的差异非常大。中值滤波的目的是保护图像边缘的同时去除噪声, 且运算速度快,可硬化,便于实时处理。
设计一个能保持图像中细小尺寸的边缘(如线状目标)的滤波方法。(!)
可以采用自适应的中值滤波。当噪声的密度很大时,常规的中值滤波的效果会减弱,这时只能通过增大滤波器窗口来应对,但这样会给图像造成较大的模糊,不能保留图像中的细节。使用自适应中值滤波器的目的就是,根据预设好的条件,动态地改变中值滤波器的窗口尺寸,以同时兼顾去噪声作用和保护细节的效果。自适应中值滤波的方法描述如下:
符号定义:

自适应中值滤波器分为以下两个过程:Stage A & Stage B
Stage A决定中值滤波器 Z m e d Z_{med} Zmed 的输出是否是一个脉冲噪声,如果不是,那么转去Stage B;如果是,那么将增加窗口大小直到大小达到 S m a x S_{max} Smax 或 Z m e d Z_{med} Zmed 不再是一个脉冲噪声。

Stage B决定 ( x , y ) (x,y) (x,y) 上的像素值 z x y z_{xy} zxy 是否是一个脉冲噪声。如果不是,算法直接输出它原来的像素值 z x y z_{xy} zxy;如果是,算法输出中值 Z m e d Z_{med} Zmed。

5.统计排序滤波
最大值滤波的实现方法是什么?
首先要排序周围像素值,然后将中心像素值与周围像素的最大像素值比较,如果中心像素比最大值大,则替换中心像素为最大值。
- 拓展: 最大最小值滤波实现:
首先要排序周围像素值,然后将中心像素值与周围像素的最小和最大像素值比较,如果比最小值小,则替换中心像素为最小值,如果中心像素比最大值大,则替换中心像素为最大值。
对于一个二值图像,使用最大值滤波会产生何种效果?
最大值滤波可以去除图像中的暗斑,同时也会使亮斑增大
对于一个二值图像,使用最小值滤波会产生何种效果?
最小值滤波可以去除图像中的亮斑,同时也会增大暗斑
6. 各向同性滤波和各向异性滤波
什么是各向同性滤波?
各向同性滤波是滤波时各个方向都一视同仁,将图像上各个方向梯度相差不多的位置抹平,如噪声、边缘、纹理、细节等, 在去噪的同时容易丢失边缘等有意义的高频; 包括高斯滤波、均值滤波等.
什么是各向异性滤波?
各向异性扩散滤波是滤波时,各个方向不是一视同仁的,边缘等高频跟平坦区域会区别对待。将图像看成物理场的力场或者热流场;图像像素总是跟他的值相异不是很大的方向流动,这样那些差异大的地方(边缘)就得以保留。
如何实现各向异性滤波?
在图像的平坦区域选择大尺度平滑,而边缘区域则选择小尺度的平滑,在抑制噪声的同时保持了图像的边缘信息。
算法描述:
- 遍历图像,求出当前像素点和不同方向的像素点灰度的变化量;
∇ N ( I x , y ) = I x , y − 1 − I x , y ∇ S ( I x , y ) = I x , y + 1 − I x , y ∇ E ( I x , y ) = I x − 1 , y − I x , y ∇ W ( I x , y ) = I x + 1 , y − I x , y \begin{aligned} \nabla_N(I_{x,y})=I_{x,y-1}-I_{x,y}\\ \nabla_S(I_{x,y})=I_{x,y+1}-I_{x,y}\\ \nabla_E(I_{x,y})=I_{x-1,y}-I_{x,y}\\ \nabla_W(I_{x,y})=I_{x+1,y}-I_{x,y} \end{aligned} ∇N(Ix,y)=Ix,y−1−Ix,y∇S(Ix,y)=Ix,y+1−Ix,y∇E(Ix,y)=Ix−1,y−Ix,y∇W(Ix,y)=Ix+1,y−Ix,y - 根据变化量求出导热系数,变化越大,导热系数越小;
c N x , y = exp ( − ∥ ∇ N ( I ) ∥ 2 / k 2 ) c S x , y = exp ( − ∥ ∇ S ( I ) ∥ 2 / k 2 ) c E x , y = exp ( − ∥ ∇ E ( I ) ∥ 2 / k 2 ) c W x , y = exp ( − ∥ ∇ W ( I ) ∥ 2 / k 2 ) \begin{aligned} cN_{x,y}=\exp(-\Vert\nabla_N(I)\Vert^2/k^2)\\ cS_{x,y}=\exp(-\Vert\nabla_S(I)\Vert^2/k^2)\\ cE_{x,y}=\exp(-\Vert\nabla_E(I)\Vert^2/k^2)\\ cW_{x,y}=\exp(-\Vert\nabla_W(I)\Vert^2/k^2)\\ \end{aligned} cNx,y=exp(−∥∇N(I)∥2/k2)cSx,y=exp(−∥∇S(I)∥2/k2)cEx,y=exp(−∥∇E(I)∥2/k2)cWx,y=exp(−∥∇W(I)∥2/k2) - 根据变化量和导热系数更新当前像素点,变化量小的方向的像素点对当前像素点的影响更大,变化量大的方向的像素点对当前像素点的影响更小。
I t + 1 = I t + λ ( c N x , y ∇ N ( I t ) + c S x , y ∇ S ( I t ) + c E x , y ∇ E ( I t ) + c W x , y ∇ W ( I t ) ) I_{t+1}=I_t+\lambda(cN_{x,y}\nabla_N(I_t)+cS_{x,y}\nabla_S(I_t)+cE_{x,y}\nabla_E(I_t)+cW_{x,y}\nabla_W(I_t)) It+1=It+λ(cNx,y∇N(It)+cSx,y∇S(It)+cEx,y∇E(It)+cWx,y∇W(It))
代码:
imgn=zeros(m,n);
for i=1:N
for p=2:m-1
for q=2:n-1
%当前像素的散度,对四个方向分别求偏导,局部不同方向上的变化量,
%如果变化较多,就证明是边界,想方法保留边界
NI=img(p-1,q)-img(p,q);
SI=img(p+1,q)-img(p,q);
EI=img(p,q-1)-img(p,q);
WI=img(p,q+1)-img(p,q);
%四个方向上的导热系数,该方向变化越大,求得的值越小,从而达到保留边界的目的
cN=exp(-NI^2/(k*k));
cS=exp(-SI^2/(k*k));
cE=exp(-EI^2/(k*k));
cW=exp(-WI^2/(k*k));
imgn(p,q)=img(p,q)+lambda*(cN*NI+cS*SI+cE*EI+cW*WI); %扩散后的新值
end
end
img=imgn; %整个图像扩散完毕,用已扩散图像的重新扩散。
end
7. 双边滤波
什么是双边滤波?
双边滤波(Bilateral filter)是一种非线性的滤波方法,是结合图像的空间邻近度和像素值相似度的一种折中处理,同时考虑空域信息和灰度相似性,达到保边去噪的目的。
空间距离:当前点 ( i , j ) (i,j) (i,j) 距离滤波模板中心点 ( i , j ) (i,j) (i,j) 的欧式距离.
d ( i , j , k , l ) = exp ( − ( i − k ) 2 + ( j − l ) 2 2 σ d 2 ) d(i,j,k,l)=\exp(-\frac{(i-k)^2+(j-l)^2}{2\sigma_d^2}) d(i,j,k,l)=exp(−2σd2(i−k)2+(j−l)2)
灰度距离:当前点 ( i , j ) (i,j) (i,j) 距离滤波模板中心点 ( i , j ) (i,j) (i,j) 的灰度的差值的绝对值。
r ( i , j , k , l ) = exp ( − ∥ I ( i , j ) − I ( k , l ) ∥ 2 2 σ r 2 ) r(i,j,k,l)=\exp(-\frac{\Vert I(i,j)-I(k,l)\Vert^2}{2\sigma_r^2}) r(i,j,k,l)=exp(−2σr2∥I(i,j)−I(k,l)∥2)
双边滤波公式:
ω ( i , j , k , l ) = exp ( − ( i − k ) 2 + ( j − l ) 2 2 σ d 2 − ∥ I ( i , j ) − I ( k , l ) ∥ 2 2 σ r 2 ) \omega(i,j,k,l)=\exp(-\frac{(i-k)^2+(j-l)^2}{2\sigma_d^2}-\frac{\Vert I(i,j)-I(k,l)\Vert^2}{2\sigma_r^2}) ω(i,j,k,l)=exp(−2σd2(i−k)2+(j−l)2−2σr2∥I(i,j)−I(k,l)∥2)
g ( i , j ) = ∑ k , l I ( k , l ) ω ( i , j , k , l ) ∑ k , l ω ( i , j , k , l ) g(i,j)=\frac{\sum_{k,l}I(k,l)\omega(i,j,k,l)}{\sum_{k,l}\omega(i,j,k,l)} g(i,j)=∑k,lω(i,j,k,l)∑k,lI(k,l)ω(i,j,k,l)
其中, I ( i , j ) I(i,j) I(i,j) 是图像灰度值, ω ( i , j , k , l ) \omega(i,j,k,l) ω(i,j,k,l) 是模板中点的权重系数, g ( i , j ) g(i,j) g(i,j) 是最终输出的像素值.
如何实现双边滤波?
- 首先依据高斯滤波的原理生成一个大小为 ( 2 ∗ N + 1 ) ∗ ( 2 ∗ N + 1 ) (2*N+1)*(2*N+1) (2∗N+1)∗(2∗N+1) 的高斯模板,
- 对图像上的所有像素进行扫描, 对图像上每一个大小为 ( 2 ∗ N + 1 ) ∗ ( 2 ∗ N + 1 ) (2*N+1)*(2*N+1) (2∗N+1)∗(2∗N+1) 上的像素点,计算灰度距离: r ( i , j , k , l ) r(i,j,k,l) r(i,j,k,l) ,其中 I ( i , j ) I(i,j) I(i,j) 为当前像素点的灰度值, I ( k , l ) I(k,l) I(k,l) 为中心像素点的灰度值
- 将每个点的灰度信息与高斯模板对应相乘,得到该区域上的卷积模板 ω ( i , j , k , l ) \omega(i,j,k,l) ω(i,j,k,l)
- 将模板与该区域进行卷积运算确定中心点的灰度值 g ( i , j ) g(i,j) g(i,j)。
8. 非局部均值滤波
Non Local Means 的基本思想是什么?
NLM的算法思想是通过利用图片中的所有信息,来对图像像素进行某种确定方式的相似度加权平均; 即当前像素点的灰度值是与图像中所有与其结构相似的像素点加权平均得到。
NLM通过在图像块中进行搜索,通过计算滑动窗口与指定窗口的欧氏距离,从而得到它们之间的相似程度,从而确定加权平均的值,进行滤波操作。

- 拓展: 与高斯滤波的区别区别
高斯滤波使用当前滤波点与矩形窗口内其它点的空间欧式距离来计算权重,距离越近权重越大;而非局部均值滤波则使用当前滤波点的邻域块与矩形窗口内其它点的邻域块的相似度来计算权重,相似度越大则权重越大
非均值滤波如何实现?
对图像四个方向扩充half_ssize+half_ksize
for 图像中的每一个像素点i:
初始化矩阵mse,大小为k_size*k_size
for 该以该像素点为中心的大小为k_size*k_size的区域上每一个像素点j:
计算以j为中心的大小为s_size*s_size区域与以i为中心的大小为s_size*s_size区域的均方误差存入mse
end
权重系数矩阵A=mse/sum(mse)
像素点i的像素值=A.*(以i为中心的大小为k_size*k_size区域上点的像素值)
end
9. 卷积
什么是非移变的线性系统?
满足叠加原理的系统称为线性系统。即: y 1 ( n ) = T [ a 1 x 1 ( n ) ] y_1(n)=T[a_1x_1(n)] y1(n)=T[a1x1(n)], y 2 ( n ) = T [ a 2 x 2 ( n ) ] y_2(n)=T[a_2x_2(n)] y2(n)=T[a2x2(n)],则有: T [ a 1 x 1 ( n ) + a 2 x 2 ( n ) ] = y 1 ( n ) + y 2 ( n ) T[a_1x_1(n)+a_2x_2(n)]=y_1(n)+y_2(n) T[a1x1(n)+a2x2(n)]=y1(n)+y2(n).
若系统的响应与输入信号施加于系统的时刻无关,称该系统为非移变系统(非时变)。即 y ( n ) = T [ x ( n ) ] y(n)=T[x(n)] y(n)=T[x(n)],则 y ( n − n 0 ) = T [ x ( n − n 0 ) ] y(n−n_0)=T[x(n−n_0)] y(n−n0)=T[x(n−n0)]
什么是单位冲激?
单位冲激是一个面积等于1的理想化的窄脉冲,脉冲的幅度等于宽度(时间)的倒数。
连续变量 t t t 在 t = 0 t=0 t=0 处的单位冲激表示为
δ ( t ) = { ∞ , t = 0 0 , t ≠ 0 \delta(t)=\begin{cases} \infty,&t=0\\ 0,&t\neq 0 \end{cases} δ(t)={∞,0,t=0t=0
它还被限制为满足等式 ∫ − ∞ ∞ δ ( t ) d t = 1 \int_{-\infty}^\infty\delta(t)dt=1 ∫−∞∞δ(t)dt=1.
一个冲激具有取样特性: ∫ − ∞ ∞ f ( t ) δ ( t ) d t = f ( 0 ) \int_{-\infty}^\infty f(t)\delta(t)dt=f(0) ∫−∞∞f(t)δ(t)dt=f(0)
什么是单位冲激响应?
单位冲激响应就是指外加激励为单位冲激信号时系统产生的零状态响应,给冲激信号求积分其响应为单位阶跃信号。
设单位冲激响应函数(模板)为h,原始信号为 f,则通过系统后的输出如何计算?
输出 = ∫ − ∞ ∞ f ( t ) h ( t − t 0 ) = f ( t 0 ) 输出=\int_{-\infty}^\infty f(t)h(t-t_0)=f(t_0) 输出=∫−∞∞f(t)h(t−t0)=f(t0)
滤波(imfilter)与卷积(conv) 有何关系?
滤波操作就是图像对应像素与掩膜(mask)的乘积之和。
比如有一张图片(左)和一个掩膜(右),如下图所示。
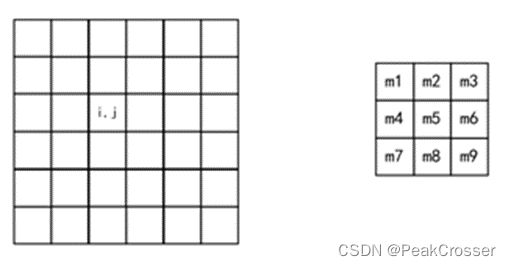
那么像素(i,j)的滤波后结果可根据以下公式计算: G ( i , j ) = I ( i − 1 , j − 1 ) × m 1 + I ( i − 1 , j ) × m 2 + . . . + I ( i , j ) × m 5 + . . . + I ( i + 1 , j + 1 ) × m 9 G(i,j)=I(i-1,j-1)\times m_1+I(i-1,j)\times m_2+...+I(i,j)\times m_5+...+I(i+1,j+1)\times m_9 G(i,j)=I(i−1,j−1)×m1+I(i−1,j)×m2+...+I(i,j)×m5+...+I(i+1,j+1)×m9. 其中 G ( i , j ) G(i,j) G(i,j) 是图片中 ( i , j ) (i,j) (i,j) 位置像素经过滤波后的像素值。当掩膜中心 m 5 m_5 m5 位置移动到图像 ( i , j ) (i,j) (i,j) 像素位置时,图像 ( i , j ) (i,j) (i,j) 位置像素称为锚点。所以滤波的步骤为:
- 对原始图像的边缘进行某种方式的填充(一般为 0 填充)。
- 将掩膜划过整幅图像,计算图像中每个像素点的滤波结果。
依照这个步骤,假设我们有一个二维矩阵 I,掩膜 M,则滤波的结果如下, 即滤波后的图像大小不变。

卷积的原理与滤波类似。但是卷积却有着细小的差别。卷积操作也是卷积核与图像对应位置的乘积和。但是卷积操作在做乘积之前,需要先将卷积核翻转180度,之后再做乘积。

卷积的步骤为:
- 180度翻转卷积核。
- 不做边界填充,直接对图像进行相应位置乘积和。
从以上步骤可以看出,如果卷积核不是中心对称的,那么卷积和滤波操作将会得到完全不一样的结果。另外,卷积操作会改变图像大小!
由于卷积操作会导致图像变小(损失图像边缘),所以为了保证卷积后图像大小与原图一致,经常的一种做法是人为的在卷积操作之前对图像边缘进行填充。
卷积运算中三种模式 full、same、valid 各是什么意思?
- full 卷积式典型的上采样卷积,其特点式卷积核可以超出特征图的范围,但是卷积核的边缘要与特征图的边缘有交点。
- valid 卷积是最常用的下采样卷积,其特点是卷积核不能超出特征图的范围。
- same 卷积是介于 full 卷积和 valid 卷积之间的一种卷积方式,其特点是卷积前后特征图的尺寸不变。由于 same 卷积的特点,其 Padding 值是固定设置的。
10. 卷积运算的特性
卷积运算的交换率、结合率、分配率各是什么?
- 交换律: f ( t ) ∗ g ( t ) = g ( t ) ∗ f ( t ) f(t)∗g(t)=g(t)∗f(t) f(t)∗g(t)=g(t)∗f(t)
conv(a,b) =conv(b,a) - 结合律: f ( t ) ∗ g ( t ) ∗ h ( t ) = f ( t ) ∗ ( g ( t ) ∗ h ( t ) ) f(t)∗g(t)∗h(t)=f(t)∗(g(t)∗h(t)) f(t)∗g(t)∗h(t)=f(t)∗(g(t)∗h(t))
conv(conv(a, b), c) =conv(a, conv(b,c)) - 分配率: f ( t ) ∗ ( g ( t ) + h ( t ) ) = f ( t ) ∗ g ( t ) + f ( t ) ∗ h ( t ) f(t)∗(g(t)+h(t))=f(t)∗g(t)+f(t)∗h(t) f(t)∗(g(t)+h(t))=f(t)∗g(t)+f(t)∗h(t)
conv(conv(a, b), c) =conv(a, conv(b,c))
试证明卷积运算的交换率、结合率。
- 交换律:

- 结合律:

如对一幅图像进行高斯滤波,如何运用卷积运算的特性,提高滤波的速度?
先用一维的高斯逐行(或逐列)对图像进行高斯滤波,然后再用一维的高斯逐列(或逐行)对新图像进行高斯滤波。
c o n v 2 ( I , g 2 ( x , y ) ) = c o n v 2 ( c o n v 2 ( I , g 1 ( x ) ) , g 1 T ( x ) ) conv2(I, g2(x,y)) = conv2(conv2(I, g1(x)), g1^T(x)) conv2(I,g2(x,y))=conv2(conv2(I,g1(x)),g1T(x))
如需要对图像进行高斯平滑后,求水平、垂直方向的梯度,又如何提高速度?
水平方向: 先对图像用一维高斯在列方向平滑,然后用一维高斯的梯度模板在行方向上平滑。
c o n v 2 ( c o n v 2 ( I , g 2 ( x , y ) ) , [ 1 0 − 1 ] ) = c o n v 2 ( I , c o n v 2 ( g 2 ( x , y ) , [ 1 0 − 1 ] ) ) = c o n v 2 ( I , ∂ g 2 ( x , y ) / ∂ x ) \begin{aligned} &conv2(conv2(I, g2 (x,y)),[1\ 0\ -1])\\ =& conv2(I, conv2(g2 (x,y), [1\ 0\ -1]))\\ =& conv2(I, \partial g2(x,y)/\partial x) \end{aligned} ==conv2(conv2(I,g2(x,y)),[1 0 −1])conv2(I,conv2(g2(x,y),[1 0 −1]))conv2(I,∂g2(x,y)/∂x)
垂直方向: 先对图像用一维高斯在行方向平滑,然后用一维高斯的梯度模板在列方向上平滑。
11. CNN中的卷积
在Convolution Neural Network 中的卷积与一般的二维图像中的卷积有何相同和不同之处?
- 相同之处: 都是经过相乘和累加得到
- 不同之处:
- 数学上的卷积,要经过180度旋转,然后对应位置相乘并求和;而卷积神经网络中的卷积不需要经过旋转。
- 数学上的“卷积核”是给定的或者预知的,而卷积神经网络中的卷积是首先随机初始化然后经过训练而学习得到的。
五. 频域滤波
1. 傅里叶变换
写出一维、二维离散傅立叶变换、反变换的计算公式。
一维:
傅里叶变换: F ( u ) = ∑ x = 0 M − 1 f ( x ) e − j 2 π u x / M F(u)=\sum_{x=0}^{M-1}f(x)e^{-j2\pi ux/M} F(u)=∑x=0M−1f(x)e−j2πux/M
傅里叶反变换: f ( x ) = 1 M ∑ u = 0 M − 1 F ( u ) e j 2 π u x / M f(x)=\frac{1}{M}\sum_{u=0}^{M-1}F(u)e^{j2\pi ux/M} f(x)=M1∑u=0M−1F(u)ej2πux/M
二维:
傅里叶变换: F ( u , v ) = 1 M N ∑ x = 0 M − 1 ∑ y = 0 N − 1 f ( x , y ) e − j 2 π ( u x / M + v y / N ) F(u,v)=\frac{1}{MN}\sum_{x=0}^{M-1}\sum_{y=0}^{N-1}f(x,y)e^{-j2\pi(ux/M+vy/N)} F(u,v)=MN1∑x=0M−1∑y=0N−1f(x,y)e−j2π(ux/M+vy/N)
傅里叶反变换: f ( x , y ) = ∑ u = 0 M − 1 ∑ v = 0 N − 1 F ( u , v ) e j 2 π ( u x / M + v y / N ) f(x,y)=\sum_{u=0}^{M-1}\sum_{v=0}^{N-1}F(u,v)e^{j2\pi(ux/M+vy/N)} f(x,y)=∑u=0M−1∑v=0N−1F(u,v)ej2π(ux/M+vy/N)
傅立叶系数的物理含义是什么?
傅里叶变换可以看做“数学的棱镜”,将时域信号分解为若干不同频率的频域信号,而不同傅立叶系数则代表了分解的不同频率信号的振幅。
傅立叶变换的物理意义是将图像的灰度分布函数变换为图像的频率分布函数,傅立叶逆变换是将图像的频率分布函数变换为灰度分布函数.
对图像进行二维傅立叶变换得到频谱图,就是图像梯度的分布图,当然频谱图上的各点与图像上各点并不存在一一对应的关系,即使在不移频的情况下也是没有。傅立叶频谱图上我们看到的明暗不一的亮点,实际上图像上某一点与邻域点灰度值差异的强弱,即梯度的大小,也即该点的频率的大小(差异/梯度越大,频率越高,能量越低,在频谱图上就越 暗。差异/梯度越小,频率越低,能量越高,在频谱图上就越 \亮。换句话说,频率谱上越亮能量越高,频率越低,图像差异越小/平缓)
简述对一个二维图像进行快速傅里叶变换的方法。
假设图像为一个M行N列的二维图像,用 f ( x , y ) f(x,y) f(x,y)表示, FFT变换结果为 F ( u , v ) F(u,v) F(u,v)简述对其二维FFT步骤为:
- 根据基2快速傅里叶变换的计算要求,需要图像的行数M、列数N均满足2的n次方,如果不满足,在计算FFT之前先要对图像补零以满足2的n次。
- 先按列变量y做一次长度为N的一维快速傅里叶变换FFT得到 F ( x , v ) F(x,v) F(x,v):
F ( x , v ) = 1 N ∑ y = 0 N − 1 f ( x , y ) e − j 2 π v y / N , v = 0 , 1 , . . , N − 1 F(x,v)=\frac{1}{N} \sum_{y=0}^{N-1}{f(x,y)e^{-j2\pi vy/N}}, v=0,1,..,N-1 F(x,v)=N1y=0∑N−1f(x,y)e−j2πvy/N,v=0,1,..,N−1 - 再将第2步骤所得结果按x做一次长度为M的一维快速傅里叶变换得到最终结果 F ( u , v ) F(u,v) F(u,v):
F ( u , v ) = 1 M ∑ x = 0 N − 1 F ( x , v ) e − j 2 π u x / M , u = 0 , 1 , . . , N − 1 F(u,v)=\frac{1}{M} \sum_{x=0}^{N-1}{F(x,v)e^{-j2\pi ux/M}}, u=0,1,..,N-1 F(u,v)=M1x=0∑N−1F(x,v)e−j2πux/M,u=0,1,..,N−1
上述流程中使用了一维FFT,原理主要是将长序列DFT分解为若干短序列DFT,利用旋转因子W的周期性,对称性,可约性减少计算量。 一维快速傅里叶(基2时分)原理具体介绍如下:
- 假设信号序列为 x ( n ) x(n) x(n),将其分解为偶数和奇数两个子序列即 x ( n ) = x 1 ( n ) + x 2 ( n ) x(n)=x_1(n)+x_2(n) x(n)=x1(n)+x2(n), 两个子序列的长度都是 N / 2 N/2 N/2, x 1 ( n ) x_1(n) x1(n)是偶数序列, x 2 ( n ) x_2(n) x2(n)是奇数序列,则有:
X ( k ) = ∑ n = − N 2 − 1 x 1 ( n ) W N 2 k n + ∑ n = 0 N 2 x 2 ( n ) W N ( 2 n + 1 ) k , ( k = 0 , 1 , . . . , N − 1 ) X(k)=\sum_{n=-}^{\frac{N}{2}-1}x_1(n)W_N^{2kn}+\sum_{n=0}^{\frac{N}{2}}x_2(n)W_N^{(2n+1)k}, (k=0,1,...,N-1) X(k)=∑n=−2N−1x1(n)WN2kn+∑n=02Nx2(n)WN(2n+1)k,(k=0,1,...,N−1)
所以, X ( k ) = ∑ n = − N 2 − 1 x 1 ( n ) W N 2 k n + W N k ∑ n = 0 N 2 − 1 x 2 ( n ) W N 2 k n , ( k = 0 , 1 , . . . , N − 1 ) X(k)=\sum_{n=-}^{\frac{N}{2}-1}x_1(n)W_N^{2kn}+W_N^k\sum_{n=0}^{\frac{N}{2}-1}x_2(n)W_N^{2kn}, (k=0,1,...,N-1) X(k)=∑n=−2N−1x1(n)WN2kn+WNk∑n=02N−1x2(n)WN2kn,(k=0,1,...,N−1),
由于 W N 2 k n = e − j 2 π N 2 k n = e − j 2 π N / 2 k n = W N / 2 k n W_N^{2kn}=e^{-j\frac{2\pi}{N}2kn}=e^{-j\frac{2\pi}{N/2}kn}=W_{N/2}^{kn} WN2kn=e−jN2π2kn=e−jN/22πkn=WN/2kn, 则
X ( k ) = ∑ n = 0 N 2 − 1 x 1 ( n ) W N / 2 k n + W N k ∑ n = 0 N 2 − 1 x 2 ( n ) W N / 2 k n = X 1 ( k ) + W N k X 2 ( k ) , ( k = 0 , 1 , . . . , N − 1 ) X(k)=\sum_{n=0}^{\frac{N}{2}-1}x_1(n)W_{N/2}^{kn}+W_N^k\sum_{n=0}^{\frac{N}{2}-1}x_2(n)W_{N/2}^{kn}=X_1(k)+W_N^kX_2(k), (k=0,1,...,N-1) X(k)=∑n=02N−1x1(n)WN/2kn+WNk∑n=02N−1x2(n)WN/2kn=X1(k)+WNkX2(k),(k=0,1,...,N−1) - 其中 X 1 ( k ) X_1(k) X1(k) 和 X 2 ( k ) X_2(k) X2(k) 分别为 x 1 ( n ) x_1(n) x1(n) 和 x 2 ( n ) x_2(n) x2(n) 的 N / 2 N/2 N/2 点DFT。由于 X 1 ( k ) X_1(k) X1(k)和 X 2 ( k ) X_2(k) X2(k)均以 N / 2 N/2 N/2 为周期,且 W N k + N / 2 = − W N k W_N^{k+N/2}=-W_N^k WNk+N/2=−WNk,所以 X ( k ) X(k) X(k)又可表示为:
X ( k ) = X 1 ( k ) + W N k X 2 ( k ) , ( k = 0 , 1 , . . . , N / 2 − 1 ) X(k)=X_1(k)+W_N^kX_2(k), (k=0,1,...,N/2-1) X(k)=X1(k)+WNkX2(k),(k=0,1,...,N/2−1)
X ( k + N 2 ) = X 1 ( k ) − W N k X 2 ( k ) , ( k = 0 , 1 , . . . , N / 2 − 1 ) X(k+\frac{N}{2})=X_1(k)-W_N^kX_2(k),(k=0,1,...,N/2-1) X(k+2N)=X1(k)−WNkX2(k),(k=0,1,...,N/2−1)
即我们把一个 N N N 点的DFT拆成了两个 N / 2 N/2 N/2 的DFT。 - 上述步骤2只是一次划分,经过若干次递归迭代二分划分,则原本的DFT(普通傅里叶)的 O ( n 2 ) O(n^2) O(n2)时间复杂度 降为FFT(快速傅里叶)的 O ( n ⋅ log n ) O(n·\log n) O(n⋅logn)。
2. 基于频域滤波的基本步骤
写出基于频域的低通滤波的步骤。
- 傅里叶变换,将灰度图由 f ( x , y ) → F ( u , v ) f(x,y)\rightarrow F(u,v) f(x,y)→F(u,v) (空域转频域),得到图像在频域中的频谱
- 中心化, 将频谱 F ( u , v ) F(u,v) F(u,v) 中心化,将低频点移到频谱中心(这样就可以通过设置一个截止频率 D 0 D_0 D0,来过滤信号)
- 遍历频谱图,使用巴特沃兹低通滤波器或高斯高斯低通滤波器进行低通滤波,计算滤波器函数 h ( u , v ) h(u,v) h(u,v) 与 F ( u , v ) F(u,v) F(u,v) 的乘积 G ( u , v ) G(u,v) G(u,v),直到频谱图遍历完
-
巴特沃兹低通滤波:
H ( u , v ) = 1 1 + ( 2 − 1 ) [ D ( u , v ) D 0 ] 2 n ) H(u,v)=\frac{1}{1+(\sqrt 2-1)[\frac{D(u,v)}{D_0}]^{2n})} H(u,v)=1+(2−1)[D0D(u,v)]2n)1 -
高斯低通滤波:
H ( u , v ) = exp ( − D 2 ( u , v ) 2 σ 2 ) H(u,v)=\exp(-\frac{D^2(u,v)}{2\sigma^2}) H(u,v)=exp(−2σ2D2(u,v))
-
- 反中心化,对滤波后的频谱 G ( u , v ) G(u,v) G(u,v) 的低频点移回到频谱的四周
- 傅里叶反变换,将第 4 步的结果傅里叶反变换 G ( u , v ) → g ( x , y ) G(u,v)\rightarrow g(x,y) G(u,v)→g(x,y),取 g ( x , y ) g(x,y) g(x,y) 实数部分作为最后滤波之后的结果,虚数部分是浮点运算存在的误差造成的(虚数部分的绝对值很小,可以忽略不计),得到滤波后的空域图像
编写程序(可以调用 FFT、 IFFT等函数),实现基于频域的滤波。

3. 直方图平滑
请使用频域滤波方法,实现直方图的平滑。

- 对原图像进行傅里叶变换
- 对变化后的图像进行滤波处理,滤波方法有
- 理想低通滤波器:
H ( u , v ) = { 1 , D ( u , v ) ≤ D 0 0 , D ( u , v ) > D 0 H(u,v)=\begin{cases} 1, &D(u,v)\leq D_0\\ 0, &D(u,v) > D_0 \end{cases} H(u,v)={1,0,D(u,v)≤D0D(u,v)>D0 - 指数低通滤波器:
H ( u , v ) = exp ( [ ( ln 1 2 ) ( − D ( u , v ) D 0 ) n ] H(u,v)=\exp([(\ln\frac{1}{\sqrt2})(-\frac{D(u,v)}{D_0})^n] H(u,v)=exp([(ln21)(−D0D(u,v))n] - 巴特沃斯低通滤波器
H ( u , v ) = 1 1 + ( 2 − 1 ) [ D ( u , v ) / D 0 ] 2 n H(u,v)=\frac{1}{1+(\sqrt 2-1)[D(u,v)/D_0]^{2n}} H(u,v)=1+(2−1)[D(u,v)/D0]2n1
- 理想低通滤波器:
- 对滤波后的图像再进行反傅里叶变换
4. 目标边界的平滑
设一幅图像中含有一个目标对象,采用某种分割方法已分割出目标区域。试给出一种处理方法,使得分割出的目标边界比较平滑。
- 第一步是缩小尺寸,是为了缩小边缘的干扰,
- 在缩小图的基础之上做中值滤波,
- 把得到的顶点等比例还原。
- 为了减少对后面处理的干扰,需要删除距离很近的点,可以用一个参数控制,随时调节。
- 用了 Bezier三阶曲线公式平滑图案上的的转折点
- 找到每条边的中点(或三等分点或n等分点)
- 连接顶点两边的中点
- 垂直平移该线段直到经过顶点P
- 此时线段两端点就是控制点
- 用控制点和顶点计算原顶点转移后的点,计算公式为:
B ( t ) = P 0 ( 1 − t ) 3 + 3 P 1 t ( 1 − t ) 2 + 3 P 2 t 2 ( 1 − t ) + P 3 t 3 , t ∈ [ 0 , 1 ] B(t)=P_0(1-t)^3+3P_1t(1-t)^2+3P_2t^2(1-t)+P_3t^3,\ t\in[0,1] B(t)=P0(1−t)3+3P1t(1−t)2+3P2t2(1−t)+P3t3, t∈[0,1]
其中, P 0 P_0 P0 为起点; P 1 , P 2 P_1, P_2 P1,P2 为控制点; P 3 P_3 P3 为终点; B ( t ) B(t) B(t) 为转移后得到的点.

5. 频域滤波与卷积
频域滤波与卷积有何关系?(!)
在时域内做模板运算,实际上就是对图像进行卷积。根据卷积定理,时域卷积等价与频域乘积。因此,在时域内对图像做模板运算就等效于在频域内对图像做滤波处理。
比如说一个均值模板,其频域响应为一个低通滤波器;在时域内对图像作均值滤波就等效于在频域内对图像用均值模板的频域响应对图像的频域响应作一个低通滤波。
对卷积模板(如7*7 的模板,图像为N*N)进行傅里叶变换时,应如何处理?
- 将卷积模板填充到图像大小准备逐元素乘法
- 对输入图像和卷积模板进行傅里叶变换
- 转换后的输入和转换后的卷积模板的元素相乘
- 对结果进行反傅里叶变换
如果模板为一个 1*10,每个元素值为 1/10,对模板进行二维傅里叶变换,生成的系数矩阵为200*200,则其系数的频谱(振幅)图有何特点?
呈一个十字星的放射状,中间白四周黑

该滤波为一个均值滤波

呈现低通滤波的样子,低频赋值较高,高频赋值小
六. 图像分割
1. Otsu阈值分割
请写出求 Otsu 阈值(即最大类间距准则)的计算方法。
大津法(OTSU)是一种确定图像二值化分割阈值的算法,它计算简单,不受图像亮度和对比度的影响,按照图像的灰度特征将图像分成背景和前景两个部分,构成图像的两部分差别越大,前景和背景的两个类别像素的方差也越大。
OTSU算法的假设是存在阈值TH将图像所有像素分为两类 C1 (小于 TH ) 和 C2 (大于 TH),则这两类像素各自的均值就为 m 1 m_1 m1、 m 2 m_2 m2,图像全局均值为 m m m。同时像素被分为 C1 和 C2 类的概率分别为 p 1 p_1 p1、 p 2 p_2 p2。因此就有:
p 1 + p 2 = 1 \begin{equation*}p_1+p_2=1\tag{1} \end{equation*} p1+p2=1(1)
p 1 m 1 + p 2 m 2 = m \begin{equation*}p_1m_1+p_2m_2=m\tag{2} \end{equation*} p1m1+p2m2=m(2)
根据方差的概念得到C1和C2的类间方差为:
σ 2 = p 1 ( m − m 1 ) 2 + p 2 ( m − m 2 ) 2 \begin{equation*}\sigma^2=p_1(m-m_1)^2+p_2(m-m_2)^2\tag{3} \end{equation*} σ2=p1(m−m1)2+p2(m−m2)2(3)
将式子 (1) (2) 带入式 (3) 中,可以得到简化的式子:
σ 2 = p 1 p 2 ( m 1 − m 2 ) 2 \begin{equation*}\sigma^2=p_1p_2(m_1-m_2)^2\tag{4} \end{equation*} σ2=p1p2(m1−m2)2(4)
计算灰度到灰度级 k k k 的累加和图像的全局累加 M G MG MG:
M = ∑ i = 0 k i p i , M G = ∑ i = 0 L − 1 i p i \begin{equation*}M=\sum_{i=0}^kip_i,\quad MG=\sum_{i=0}^{L-1}ip_i\tag{5} \end{equation*} M=i=0∑kipi,MG=i=0∑L−1ipi(5)
m 1 m_1 m1, m 2 m_2 m2 可由以上两个量和 p 1 p_1 p1, p 2 p_2 p2 表示:
m 1 = 1 p 1 M , m 2 = 1 p 2 ( M G − M ) \begin{equation}m_1=\frac{1}{p_1}M,\quad m_2=\frac{1}{p_2}(MG-M)\tag{6}\end{equation} m1=p11M,m2=p21(MG−M)(6)
将 (6) 式带入 (4) 式, 可以得到最终描述类间间距:
σ 2 = ( M G × p 1 − M ) 2 p 1 ( 1 − p 1 ) \sigma^2=\frac{(MG\times p_1-M)^2}{p_1(1-p_1)} σ2=p1(1−p1)(MG×p1−M)2
这样遍历 255 个灰度级,找到使得 σ 2 \sigma^2 σ2 最大的灰度级,该灰度即该图像的分割阈值。
试证明采用最大类间距准则计算出的阈值与采用最小类内距准则计算出的阈值相同。
设 p 1 p_1 p1、 p 2 p_2 p2 分别为像素被分为 C1 和 C2 类的概率(两个区域的比重), σ 1 2 \sigma_1^2 σ12, σ 2 2 \sigma_2^2 σ22 分别为两个区域的方差
定义: 类内方差: σ w 2 = p 1 σ 1 2 + p 2 σ 2 2 \sigma_w^2= p_1\sigma_1^2+p_2\sigma_2^2 σw2=p1σ12+p2σ22, 类间方差: σ b 2 = p 1 ( m 1 − m c ) 2 + p 2 ( m 2 − m c ) 2 \sigma_b^2=p_1(m_1-m_c)^2+p_2(m_2-m_c)^2 σb2=p1(m1−mc)2+p2(m2−mc)2
其中: m c m_c mc 为均值, 两类像素各自的均值就为 m 1 m_1 m1、 m 2 m_2 m2, m c = p 1 m 1 + p 2 m 2 m_c=p_1m_1+p_2m_2 mc=p1m1+p2m2
代入类间方差表达式得: σ b = p 1 p 2 ( m 1 − m 2 ) 2 \sigma_b=p_1p_2(m_1-m_2)^2 σb=p1p2(m1−m2)2
对于整个图像的方差 σ 2 = ∑ n = 0 255 p n n 2 − m c 2 \sigma^2=\sum_{n=0}^{255}p_nn^2-m_c^2 σ2=∑n=0255pnn2−mc2, 即 σ 2 = E ( x 2 ) − E ( x ) 2 \sigma^2=E(x^2)-E(x)^2 σ2=E(x2)−E(x)2
同理:
σ 1 2 = ∑ n = 0 t g n n 2 − m 1 2 , σ 2 2 = ∑ n = t + 1 255 g n n 2 − m 2 2 \sigma_1^2=\sum_{n=0}^tg_nn^2-m_1^2, \sigma_2^2=\sum_{n=t+1}^{255}g_nn^2-m_2^2 σ12=n=0∑tgnn2−m12,σ22=n=t+1∑255gnn2−m22
t t t 代表阈值分割点, g n g_n gn 代表第 n n n 个像素点在该区域中的比重, p n p_n pn 代表第 n n n 个像素点在整个图像中的比重, 根据定义有: p n = w i p n ( i = 0 或 1 ) p_n=w_ip_n (i=0或1) pn=wipn(i=0或1)
则
σ w 2 + σ b 2 = ∑ n = 0 t p n n 2 − p 1 m 1 2 + ∑ n = t + 1 255 p n n 2 − p 2 m 2 2 + p 1 p 2 ( m 1 − m 2 ) 2 = ∑ n = t + 1 255 p n n 2 − p 1 2 m 1 2 − p 2 2 m 2 2 − 2 p 1 p 2 m 1 m 2 = σ 2 \begin{aligned} &\sigma_w^2+\sigma_b^2 =\sum_{n=0}^tp_nn^2-p_1m_1^2+\sum_{n=t+1}^{255}p_nn^2-p_2m_2^2+p_1p_2(m_1-m_2)^2\\ =&\sum_{n=t+1}^{255}p_nn^2-p_1^2m_1^2-p_2^2m_2^2-2p_1p_2m_1m_2=\sigma^2 \end{aligned} =σw2+σb2=n=0∑tpnn2−p1m12+n=t+1∑255pnn2−p2m22+p1p2(m1−m2)2n=t+1∑255pnn2−p12m12−p22m22−2p1p2m1m2=σ2
即类内方差与类间方差之和为定值, 最大化类间方差与最小化类内方差等价.
2. K-means 聚类分割
K-means 聚类分割的目标函数是什么?
K-means 作为一种典型的基于划分的聚类算法,它根据相似性原则,把具有较高相似度的数据对象划分到同一类簇,把具有较高相异度的数据对象划分到不同类簇。在普通的聚类任务中,一般将欧氏距离作为衡量数据对象相似度的度量,而在基于K-means的图像分割中,我们将RGB或者灰度值作为衡量两个数据对象相似度的度量。K-means聚类方法就是寻找 K 个聚类中心 μ k ( k = 1 , . . . , K ) \mu_k(k=1,...,K) μk(k=1,...,K),将所有的数据分配到距离最近的聚类中心, 使得每个点与其相应的聚类中心距离的平方和最小。
J = ∑ n = 1 N ∑ k = 1 K r n k ∥ x n − μ k ∥ 2 J=\sum_{n=1}^N\sum_{k=1}^Kr_{nk}\Vert x_n-\mu_k\Vert^2 J=n=1∑Nk=1∑Krnk∥xn−μk∥2
该问题的目标就是寻找使得损失函数 J J J 最小的所有数据点的归属值 { r n k } \{r_{nk}\} {rnk} 和聚类中心 { μ k } \{\mu_k\} {μk}。K-means 算法提供了一种迭代求解方法,在每次迭代中交替优化 r n k r_{nk} rnk 和 μ k \mu_k μk。其中, N N N 为聚类中心的个数.
请写出K-means聚类(也称c-means)分割的基本步骤。
- 随机初始化 k k k 个不同的聚类中心(RGB取值)。
- 计算图像中所有点与这 k k k 个聚类中心的欧氏距离,将这些点划为与其距离最短的聚类中心的类别。
- 按不同类别重新计算 RGB 均值作为新的聚类中心。
- 计算新聚类中心与老聚类中心的差别,若小于阈值,则分割完毕; 若大于阈值,则重复步骤 (2)~(3) 直到聚类中心差别小于阈值或达到设定的迭代次数。
3. 区域标记
设有一幅二值图像(元素取值为0或1),请生成该图像的标记图像。(即第一个连通区域中的每一个白色像素的值都置为1,第二个连通区域中的每一个白色像素的值都置为2,依此类推。区域编号可不考虑顺序)
区域标记主要有两种算法,一种是 Seed-Filling 标记算法; 一种是 Two-Pass 算法。
- Seed-Filling 算法:
- 从左到右,从上至下依次扫描图像,直到当前像素点 B(x,y) == 1:
- 如果该像素点已经遍历过,则继续遍历; 否则转向步骤 3
- 将 B(x,y) 作为种子(像素位置), 并赋予其一个新 label(数字, 从 1 开始, 每次 +1), 然后将该种子相邻的所有前景像素(值为1的像素)都压入栈中
- 弹出栈顶像素, 赋予其相同的 label, 然后再将与该栈顶像素相邻的所有前景像素都压入栈中
- 重复步骤 4,直到栈为空. 此时, 便找到了图像B中的一个连通区域,该区域内的像素值被标记为 label重复第(1)步,直到扫描结束;
- 重复步骤 1,直到扫描结束;扫描结束后,就可以得到图像中所有的连通区域
- Two-Pass 算法:
- 第一次扫描: 访问当前像素B(x,y),如果 B(x,y) == 1:
- 如果 B(x,y) 的领域中像素值都为 0,则赋予 B(x,y) 一个新的label:label += 1, B(x,y) = label;
- 如果 B(x,y) 的领域中有像素值 > 1的像素Neighbors:
- 将 Neighbors 中的最小值赋予给 B(x,y): B(x,y) = min{Neighbors}
- 记录 Neighbors 中各个 label 之间的相等关系,即这些 label 同属同一个连通区域: l a b e l S e t [ i ] = { l a b e l m , . . , l a b e l n } labelSet[i] = \{ label_m, .., label_n \} labelSet[i]={labelm,..,labeln},labelSet[i] 中的所有 label 都属于同一个连通区域(注:这里可以有多种实现方式,只要能够记录这些具有相等关系的 label 之间的关系即可)
- 第二次扫描:访问当前像素 B(x,y),如果 B(x,y) > 1:找到与 label == B(x,y) 同属相等关系的一个最小 label 值,赋予给 B(x,y). 完成扫描后,图像中具有相同 label 值的像素
- 第一次扫描: 访问当前像素B(x,y),如果 B(x,y) == 1:
4. 信息熵
如何计算一幅图像的信息熵?
图像的一维熵: 表示图像中灰度分布的聚集特征所包含的信息量,令 p i p_i pi 表示图像中灰度值为 i i i 的像素所占的比例,则一维熵的计算公式如下:
H = − ∑ i = 0 255 p i log 2 p i H=-\sum_{i=0}^{255}p_i\log_2p_i H=−i=0∑255pilog2pi
图像的二维熵: 表征灰度信息的空间特征, 引入图像的像素点与该点的邻域信息. 对于二元组 ( i , j ) (i,j) (i,j), 其中 i i i 表示像素的灰度值 ( 0 ≤ i ≤ 255 ) (0\leq i\leq 255) (0≤i≤255), j j j 表示邻域灰度均值 ( 0 ≤ j ≤ 255 ) (0\leq j\leq 255) (0≤j≤255)。 P i j P_{ij} Pij 表示了某像素位置上的灰度值与其周围像素的灰度分布的综合特征, f ( i , j ) f(i,j) f(i,j) 表示特征二元组 ( i , j ) (i,j) (i,j) 出现的频次, N N N 是图像的尺寸:
P i , j = f ( i , j ) / N 2 P_{i,j}=f(i,j)/N^2 Pi,j=f(i,j)/N2
二维熵的计算公式如下:
H = − ∑ i = 0 255 ∑ j = 0 255 P i j log 2 P i j H=-\sum_{i=0}^{255}\sum_{j=0}^{255}P_{ij}\log_2P_{ij} H=−i=0∑255j=0∑255Pijlog2Pij
如何计算两个概率分布之间的交叉熵?
设分布 A 的概率密度函数为 p ( x ) p(x) p(x), 分布 B 的概率密度函数为 q ( x ) q(x) q(x),那么有两个概率分布之间的交叉熵为:
H ( p , q ) = − ∑ x p ( x ) log ( q ( x ) ) H(p,q)=-\sum_xp(x)\log(q(x)) H(p,q)=−x∑p(x)log(q(x))
交叉熵有何物理含义?
交叉熵描述了两个分布之间的相似程度。在机器学习中常用来作为分类器的损失函数。
5. 区域生长
在一幅灰度图像中,给定一个点为种子点,试从该种子点生长出一个区域,区域中像素的灰度与种子点灰度的差距在10以内。
假设图像像素点为 N × N N\times N N×N,灰度数组为 d a t a [ N ] [ N ] data[N][N] data[N][N],初始种子坐标为 ( x 0 , y 0 ) (x_0,y_0) (x0,y0),种子点灰度为 m i d _ g r e y s c a l e mid\_greyscale mid_greyscale;定义队列 Q Q Q 用于存放生长过程中未遍历的点, 数组 v a l i d a t e [ N ] [ N ] validate[N][N] validate[N][N],用来判断点是否已经被访问.
详细步骤如下:
- 将初始种子坐标 ( x 0 , y 0 ) (x_0,y_0) (x0,y0) 放入队列 Q Q Q,初始化 v a l i d a t e validate validate 数组为全 0
- 将 Q Q Q 队头像素点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1) 出队,且置对头点 v a l i d t e [ x ] [ y ] validte[x][y] validte[x][y] 值为 1 表示已被访问
- 根据 d a t a data data 数组判断该点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1) 周围 8 个点 ( x , y ) (x,y) (x,y) 的灰度值与种子点灰度值 m i d _ g r e y s c a l e mid\_greyscale mid_greyscale 之差是否在10以内,若在10以内且 v a l i d a t e [ x ] [ y ] validate[x][y] validate[x][y] 值为 0 (未访问过) 则将该点 ( x , y ) (x,y) (x,y) 追加至队列 Q Q Q
- 判断队列 Q Q Q 是否为空,若队列为空则程序结束,否则跳回步骤 2
- 数组 v a l i d a t e validate validate 中值为 1 的点即代表了得到的区域
6. 含约束条件的区域生长
在一幅灰度图像中,给定一个点为种子点,试从该种子点生长出一个区域。要求:
(1) 区域中像素的灰度与种子点灰度的差距一般在10以内;少数噪声点也可以出现在区域中;
(2) 区域具有团、块中特性,不能通过细线连接到其他目标中。
假设图像像素点为 N × N N\times N N×N,灰度数组为 d a t a [ N ] [ N ] data[N][N] data[N][N],初始种子坐标为 ( x 0 , y 0 ) (x_0,y_0) (x0,y0),种子点灰度为 m i d _ g r e y s c a l e mid\_greyscale mid_greyscale;定义队列 Q Q Q 用于存放生长过程中未遍历的点,数组 v a l i d a t e [ N ] [ N ] validate[N][N] validate[N][N],用来判断点是否已经被访问;
详细步骤如下:
- 初始化 v a l i d a t e validate validate 数组为全 0,将初始种子坐标 ( x 0 , y 0 ) (x_0,y_0) (x0,y0) 放入队列 Q Q Q.
- 将 Q Q Q 队头像素点 ( x 1 , y 1 ) (x_1,y_1) (x1,y1) 出队,根据 d a t a data data 数组判断该点周围 8 个点 ( x , y ) (x,y) (x,y) 的灰度值与种子点灰度 m i d _ g r e y s c a l e mid\_greyscale mid_greyscale 之差是否在 10 以内,若在 10 以内则将该点 ( x , y ) (x,y) (x,y) 存入临时队列 t m p tmp tmp
- 若队头点 ( x 1 , y 1 ) (x_1, y_1) (x1,y1) 周围 8 点的临时队列 t m p tmp tmp 中点的数量大于等于 4:
则依次遍历临时队列 t m p tmp tmp 中的点 , 若 ( x ′ ′ , y ′ ′ ) (x'',y'') (x′′,y′′) 的 v a l i d a t e [ x ′ ′ ] [ y ′ ′ ] validate[x''][y''] validate[x′′][y′′] 值为 0, 则将其追加至队列 Q Q Q. 最后将队头点 v a l i d a t e [ x 1 ] [ y 1 ] validate[x_1][y_1] validate[x1][y1] 置 1.
若队头点 ( x 1 , y 1 ) (x_1, y_1) (x1,y1) 周围 8 点的临时队列 t m p tmp tmp 中点的数量小于 4:
则只清空临时队列 t m p tmp tmp - 判断队列 Q Q Q 是否为空,若队列为空则程序结束,否则跳回步骤 2
- 对所有 v a l i d a t e validate validate 值为 0 的点 ( x ′ , y ′ ) (x',y') (x′,y′) 做判断, 若周围 8 个点 v a l i d a t e validate validate 值均为 1(即都标记为区域内像素), 则判定该像素点 ( x ′ , y ′ ) (x',y') (x′,y′) 为噪声点, 将它的 v a l i d a t e validate validate 值也置 1
- 数组 v a l i d a t e validate validate 中值为 1 的点即代表了得到的区域