统计学习方法第三章习题
统计学习方法第三章习题
- 习题3.1
- 习题3.2
- 习题3.3
- 习题3.4
习题3.1
本题摘抄自:原文链接:https://blog.csdn.net/qq_35082030/article/details/60965320
参照图3.1,在二维空间中给出实例点,画出k为1和2时的k近邻法构成的空间划分,并对其进行比较,体会k值选择与模型复杂度及预测准确率的关系。
我们不去考虑k为1的情况,因为k为1的情况我们可以很容易从原图中获取,我们来考虑k=2时候的空间划分。
我们都知道,在2维空间中,我们通常使用的是一条线来进行2分类,这也是最优的分类方式(每次减小样本空间一半),那么在这个题目中,如果k=2的时候,我们考虑最近的3个点开始,其实无论是多少都没关系的,只不过时间复杂度比较大,但是我们通常不会选取过多的候选点。
现在,这条线就是2个点的连线的垂直平分线,如下图所示:
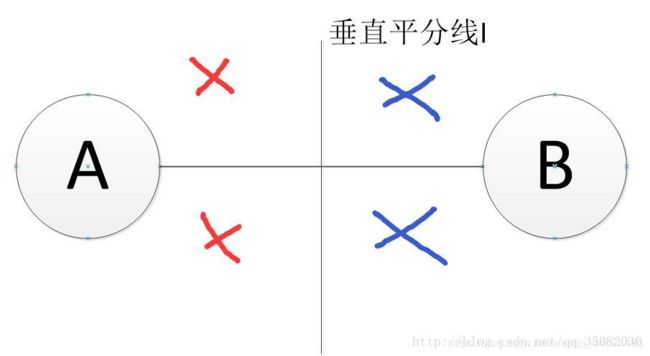
为了更清楚,我把图片放大,以至于A,B点变成了圆,l为AB两点连线的垂直平分线。如图上所标,这时候只能考虑k=1d的时候的划分。一条垂直平分线可以把平面分成两个部分,左边红色的部分都会被归结为离A点近,右边的蓝色部分都会被归结于B点近。
那么如果我们考虑三个点的k近邻,如下图所示:

如果K=1,那么最终的分类就会是如此,蓝色的点都是被归于点A,红色的点都归于点B,紫色的点都归于点C,但是如果是K=2的时候呢?K=2的时候,只需要把垂直平分线延长就可以了,如下图:

为了区分归属,我把三个点都标上了颜色,而被划分的6个区域,其最近的2个点的颜色都在图上标出,其实就是一个二维层面的三次切分,取其中最近的2个点。这样就得到了空间划分。
实际上4个点,5个点,n个点都是同样的道理,这个算法不一定是最优的,但是是可以推广到n个点的普适算法,而且又由于k的取值不会过大,因此不会造成大数灾难。
你可能觉得很巧,为什么所有的垂直平分线都会交于一点,实际上,所有的凸多边体都会有一个外接圆,那么圆心到所有点的距离都相等,这就是所有边的垂直平分线的焦点。但是对于凹多边体,就没有外接圆了,但是也不用担心,空间中所有的部分都会被若干个垂直平分线所分割,只需要比较围成这个区域的n个垂直平分线,然后再根据k的取值取前K个点即可。
这样就解决了题目3.1。
习题3.2
import numpy as np
class kdNode():
def __init__(self, x, y):
self.value = x
self.dimension = y #切分的x维度
self.left = None
self.right = None
def loadData():
T = np.array([[2,3], [5,4], [9,6], [4,7], [8,1], [7,2]])
return T
def buildTree(T, Depth):
if len(T) == 0:
return None
k = T.shape[1]
T = T[T[:, int(Depth % k)].argsort()]
mid = T.shape[0] // 2
root = kdNode(T[mid], Depth%k)
root.left = buildTree(T[:mid], Depth+1)
root.right = buildTree(T[mid+1:], Depth+1)
return root
def levelTravel(root):
queue = [root]
level = 0
while len(queue):
temp = []
print("第%d层结点:"%level)
level += 1
for i in range(len(queue)):
print(queue[i].value)
if queue[i].left != None:
temp.append(queue[i].left)
if queue[i].right != None:
temp.append(queue[i].right)
queue = temp
def find_closest(root, x, min_dis, closest_point):
#step1:在kd树中找出包含目标点x的叶节点
if root == None:
return
#更新最短距离和最近点
cur_distance = (sum((root.value[:] - x)**2))**0.5
if min_dis[0] < 0 or cur_distance < min_dis:
min_dis[0] = cur_distance
for i in range(len(root.value)):
closest_point[i] = root.value[i]
# 递归向下访问kd树
if x[root.dimension] <= root.value[root.dimension]:
find_closest(root.left, x, min_dis, closest_point)
else:
find_closest(root.right, x, min_dis, closest_point)
#计算测试点和分割超平面的距离,如果相交则进入叶节点的右子树进行遍历查找最近点
distance = abs(x[root.dimension] - root.value[root.dimension])
if distance > min_dis[0]:
return
else:
if x[root.dimension] <= root.value[root.dimension]:
find_closest(root.right, x, min_dis, closest_point)
else:
find_closest(root.left, x, min_dis, closest_point)
return
if __name__ == "__main__":
T = loadData()
root = buildTree(T, 0)
levelTravel(root)
test_x = [3, 4.5]
closet_point = np.copy(root.value)
min_dis = np.array([-1.0])
find_closest(root, test_x, min_dis, closet_point)
print("测试的点", test_x)
print("最近的点",closet_point)
print("最短距离%f" % min_dis[0])
习题3.3
思考k近邻的算法的模型复杂度体现在哪里,什么情况下会造成过拟合?
答:模型复杂度体现在k值得大小
k过小容易造成过拟合,k越大,模型复杂度越大
习题3.4
给定一个二维空间的数据集T={正实例:(5,4),(9,6),(4,7);负实例:(2,3),(8,1),(7,2)},试基于欧氏距离,找到数据点S (5,3)的最近邻(k=1),并对S点进行分类预测。
⑴)用“线性扫描"算法自编程实现。
(2)试调用sklearn.neighbors的KNeighborsClassifier模块,对S点进行分类预测,并对比近邻数k取值不同,对分类预测结果的影响。
(3)思考题:思考“线性扫描”算法和“kd树"算法的时间复杂度。
(1)
import numpy as np
from collections import Counter
class KNN:
def __init__(self,x_train,y_train,x_test,k = 3):
self.k = k
self.x_train = x_train
self.y_train = y_train
self.x_test = x_test
def predict(self):
#计算测试集和训练集的距离L2范数
dist = [[np.linalg.norm(self.x_test - self.x_train[i]),self.y_train[i]] for i in range(len(self.x_train))]
#对距离进行排序,默认从小到大
dist.sort(key = lambda x : x[0])
#取前k个最小距离对应的类别
y_list = [dist[i][-1] for i in range(self.k)]
#对上述k个最小距离对应类别进行统计,取数量最多的那个类别
y_count = Counter(y_list).most_common(1)
return y_count[0][0]
if __name__ == "__main__":
#训练数据
x_train = np.array([[5, 4],
[9, 6],
[4, 7],
[2, 3],
[8, 1],
[7, 2]])
#数据类别
y_train = np.array([1, 1, 1, -1, -1, -1])
#测试数据
x_test = np.array([5,3])
#选择不同的k值
for k in range(1,6,2):
#构建knn实例
clf = KNN(x_train,y_train,x_test,k)
#对数据进行预测
y_predict = clf.predict()
print("当k取值%d时,测试点(5,3)的类别为%d"%(k,y_predict))
知识点1:
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)
这个可以求向量的范数也可以求矩阵的范数;我这里主要是求向量的范数。x数据,ord范数,默认2范数(1范数(菱形,绝对值求和)、2范数(平方和开根号(圆形))、无穷范数(取绝对值最大的那个))
知识点2:
List.sort()方法
list.sort(cmp=None, key=None, reverse=False)
对list元素进行排序,根据key来排序 key = lambda x : x[0]
默认从小到大
知识点3:
collections类的Counter方法
返回字典,对序列化元素分别计数
.most_common(1)取计数最大的那个
>>> l = [1,1,1,-1,-1,-1,-1]
>>> Counter(l)
Counter({-1: 4, 1: 3})
>>> Counter(l).most_common(1)
[(-1, 4)]
(2)
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
if __name__ == "__main__":
#训练数据
X_train = np.array([[5,4],[9,6],[4,7],[2,3],[8,1],[7,2]])
y_train = np.array([1,1,1,-1,-1,-1])
#待预测数据
X_test = np.array([[5,3]])
#不同k值对结果的影响
for k in range(1,6,2):
#构建实例
clf = KNeighborsClassifier(n_neighbors=k,n_jobs=-1)
#选择合适的算法
clf.fit(X_train,y_train)
print("临近点:",clf.kneighbors(X_test))#返回两个数组,一个是距离数组,另一个是索引数组
#预测
y_predict = clf.predict(X_test)
print('属于每个类的概率',clf.predict_proba(X_test))
print("k={},被分类为:{}".format(k, y_predict), "预测正确率:{:.0%}".format(clf.score([[5, 3]], [[1]])))
原文:https://blog.csdn.net/sdu_hao/article/details/103055338