Python数据分析与机器学习31-SVM案例:人脸识别
文章目录
- 一. 数据集介绍
- 二. 训练模型
-
- 2.1 使用grid search cross-validation来选择我们的参数
- 2.2 初步看下模型的效果
- 三. 模型验证
- 四. 混淆矩阵
- 参考:
一. 数据集介绍
数据集我们使用的sklearn官网的数据集
代码:
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
import seaborn as sns
# 从sklearn官网获取数据集
faces = fetch_lfw_people(min_faces_per_person=60)
print(faces.target_names)
print(faces.images.shape)
# 显示数据集
fig, ax = plt.subplots(3, 5)
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='bone')
axi.set(xticks=[], yticks=[],
xlabel=faces.target_names[faces.target[i]])
plt.show()
测试记录:
[‘Donald Rumsfeld’ ‘George W Bush’ ‘Gerhard Schroeder’ ‘Junichiro Koizumi’]
(820, 62, 47)

每个图的大小是 [62×47]
二. 训练模型
2.1 使用grid search cross-validation来选择我们的参数
每个图的大小是 [62×47],计算量太大
在这里我们就把每一个像素点当成了一个特征,但是这样特征太多了,用PCA降维一下吧!
代码:
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
from sklearn.svm import SVC
#from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
# 从sklearn官网获取数据
faces = fetch_lfw_people(min_faces_per_person=60)
# 使用PCA进行降维
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
model = make_pipeline(pca, svc)
# 划分训练集和测试集
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,random_state=40)
# 使用grid search cross-validation来选择我们的参数
param_grid = {'svc__C': [1, 5, 10],
'svc__gamma': [0.0001, 0.0005, 0.001]}
grid = GridSearchCV(model, param_grid)
# 训练模型
grid.fit(Xtrain, ytrain)
# 打印最佳模型参数
print(grid.best_params_)
测试记录:
{‘svc__C’: 10, ‘svc__gamma’: 0.0005}
2.2 初步看下模型的效果
代码:
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
from sklearn.svm import SVC
#from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
faces = fetch_lfw_people(min_faces_per_person=60)
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
model = make_pipeline(pca, svc)
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,random_state=40)
# 使用grid search cross-validation来选择我们的参数
param_grid = {'svc__C': [1, 5, 10],
'svc__gamma': [0.0001, 0.0005, 0.001]}
grid = GridSearchCV(model, param_grid)
grid.fit(Xtrain, ytrain)
model = grid.best_estimator_
yfit = model.predict(Xtest)
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],
color='black' if yfit[i] == ytest[i] else 'red')
fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14)
plt.show()
测试记录:

三. 模型验证
查看模型的评分
代码:
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
from sklearn.svm import SVC
#from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
faces = fetch_lfw_people(min_faces_per_person=60)
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
model = make_pipeline(pca, svc)
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,random_state=40)
# 使用grid search cross-validation来选择我们的参数
param_grid = {'svc__C': [1, 5, 10],
'svc__gamma': [0.0001, 0.0005, 0.001]}
grid = GridSearchCV(model, param_grid)
grid.fit(Xtrain, ytrain)
model = grid.best_estimator_
yfit = model.predict(Xtest)
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],
color='black' if yfit[i] == ytest[i] else 'red')
print(classification_report(ytest, yfit,target_names=faces.target_names))
测试记录:
precision recall f1-score support
Donald Rumsfeld 0.69 0.75 0.72 24
George W Bush 0.95 0.89 0.92 137
Gerhard Schroeder 0.76 0.92 0.83 24
Junichiro Koizumi 0.91 1.00 0.95 20
accuracy 0.89 205
macro avg 0.83 0.89 0.86 205
weighted avg 0.90 0.89 0.89 205
- 精度(precision) = 正确预测的个数(TP)/被预测正确的个数(TP+FP)
- 召回率(recall)=正确预测的个数(TP)/预测个数(TP+FN)
- F1 = 2精度召回率/(精度+召回率)
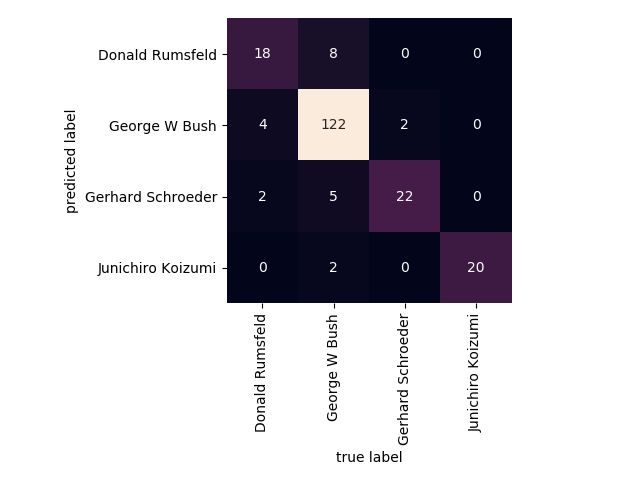
四. 混淆矩阵
这样显示出来能帮助我们查看哪些人更容易弄混
代码:
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.svm import SVC
#from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
faces = fetch_lfw_people(min_faces_per_person=60)
pca = PCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
model = make_pipeline(pca, svc)
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target,random_state=40)
# 使用grid search cross-validation来选择我们的参数
param_grid = {'svc__C': [1, 5, 10],
'svc__gamma': [0.0001, 0.0005, 0.001]}
grid = GridSearchCV(model, param_grid)
grid.fit(Xtrain, ytrain)
model = grid.best_estimator_
yfit = model.predict(Xtest)
mat = confusion_matrix(ytest, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');
plt.show()
测试记录:
参考:
- https://study.163.com/course/introduction.htm?courseId=1003590004#/courseDetail?tab=1