【学习笔记】《深入浅出Pandas》第6章:Pandas分组聚合
分组聚合非常常见,我们的数据是扁平化的,没有任何分组信息。比如我们一周多次去同一家便利店,每次会产生一条购买记录,便利店要想统计每个人这周的购买情况,就需要以人来进行分组,然后将每个人的所有金额相加。
文章目录
- 6.1 概述
-
- 6.1.1 原理
- 6.1.2 groupby语法
- 6.1.3 DataFrame应用分组
- 6.1.4 Series应用分组
- 6.2 分组
-
- 6.2.1 分组对象
- 6.2.2 按标签分组
- 6.2.3 表达式
- 6.2.4 函数分组
- 6.2.5 多种方法混合
- 6.2.6 用pipe调用分组方法
- 6.2.7 分组器Grouper
- 6.2.8 索引
- 6.2.9 排序
- 6.2.10 小结
- 6.3 分组对象的操作
-
- 6.3.1 选择分组
- 6.3.2 迭代分组
- 6.3.3 选择列
- 6.3.4 应用函数apply()
- 6.3.5 管道方法pipe()
- 6.3.6 转换方法transform()
- 6.3.7 筛选方法filter()
- 6.3.8 其他功能
- 6.3.9 小结
- 6.4 聚合统计
-
- 6.4.1 描述统计
- 6.4.2 统计函数
- 6.4.3 聚合方法agg()
- 6.4.4 时序重采样方法resample()
- 6.4.5 组内头尾值
- 6.4.6 组内分位数
- 6.4.7 组内差值
- 6.4.8 小结
- 6.5 数据分箱
-
- 6.5.1 定界分箱pd.cut()
- 6.5.2 等宽分箱pd.qcut()
- 6.5.3 小结
- 6.6 分组可视化
-
- 6.6.1 绘图方法plot()
- 6.6.2 直方图hist()
- 6.6.3 箱线图boxplot()
- 6.7 本章小结
6.1 概述
在常规的数据探索方法中,我们将数据集按一定的粒度进行划分,然后以此粒度的聚合数据来了解数据的聚集趋势,以便解决问题。
本节将介绍数据分组的原理及简单操作。
6.1.1 原理
6.1.2 groupby语法
df.groupby()可以按指定字段对DataFrame进行分组,生成一个分组器对象。
df.groupby(by=None, axis=0, level=None, as_index: bool = True, sort: bool = True,
group_keys: bool = True, observed: bool = False, dropna: bool = True,
) -> 'DataFrameGroupBy'
分组操作会按制定规则对数据进行拆分,groupby完成的就是拆分的工作。groupby也能对Series完成分组操作。各个参数意义如下:
- by:代表分组的依据和方法。如果by是一个函数,则会在数据的索引的每个值去调用它,从而产生值,按照这些值来确定分组。如果传递dict或Series,则将使用dict或Series的值来确定组;如果传递的是ndarray,则按原样使用这些值来确定组。传入字典,键为原索引名,值为分组名。
- axis:沿行(0)或列(1)进行拆分。也可传入index或columns,默认是0。
- level:如果轴是多层索引,则按一个或多个特定的层级进行拆分,支持数字、层名及序列。
- as_index:数据分组聚合输出,默认返回带有组标签的对象作为索引,传False则不会。
- sort:是否对分组进行排序。默认会排序,传False会让数据分组中第一个出现的值在前。
- group_keys:调用函数时,将组键添加到索引中进行识别。
- observed:仅当分组是分类数据时才适用。如果为True,仅显示分类分组数据的显示值;如果为False,显示分类分组数据的所有值。
- dropna:如果为True,并且组键包含NA值,则NA值及行/列将被删除;如果为False,则NA值也将被视为组中的键。
以上大多参数也适用于Series,如果对DataFrame进行分组,会返回DataFrame-Groupby对象,对Series分组会返回SeriesGroupby对象。
6.1.3 DataFrame应用分组
# 按team分组对应列相加
df.groupby('team').sum()
# 对不同列采用不同的聚合计算方法
df.groupby('team').agg({'Q1': sum, 'Q2': 'count', 'Q3': 'mean', 'Q4': max})
# 对同一列使用不同的计算方法
df.groupby('team').agg({'Q1': [sum, 'std', max],
'Q2': 'count', 'Q3': 'mean', 'Q4': max})
6.1.4 Series应用分组
# 对df.Q1(Series)按team分组,求和
df.Q1.groupby(df.team).sum()
6.2 分组
本节将针对分组对象介绍什么是分组对象, 分组对象的创建可以使用哪些方法。
6.2.1 分组对象
groupby方法最终输出的是一个分组对象,DataFrameGroupBy和SeriesGroupBy都是分组对象。
接下来介绍创建分组对象的一些方法:
6.2.2 按标签分组
# 指定DataFrame的一列,按这列的去重数据分组
grouped = df.groupby('col')
grouped = df.groupby('col', axis='columns') # 按行
grouped = df.groupby(['col1', 'col2']) # 多列
# get_group查看分组对象单个分组的内容
grouped = df.groupby('team')
grouped.get_group('D') # 查看D组
6.2.3 表达式
通过行和列的表达式,生成一个布尔数据的序列,从而将数据分为True和False两组。
# 索引值是否为偶数,分成两组
df.groupby(lambda x:x%2==0).sum()
df.groupby(df.index%2==0).sum() # 同上
"""
Q1 Q2 Q3 Q4
False 2322 2449 2823 2699
True 2598 2806 2444 2579
"""
6.2.4 函数分组
by参数可以调用函数来通过计算返回一个分组依据。
# 有一个时间列,按年进行分组,提取年份
df.groupby(df.time.apply(lambda x:x.year)).count()
如果DataFrame和Series函数接收到的参数是数值,想要传入其他列的值,可以使用apply来调用。
# 按照姓名首字母为元音、辅音分组:
def get_letter_type(letter):
if letter[0].lower() in 'aeiou':
return '元音'
else:
return '辅音'
df.set_index('name').groupby(get_letter_type).sum() # 需要设置name为索引index
"""
Q1 Q2 Q3 Q4
元音 1462 1440 1410 1574
辅音 3458 3815 3857 3704
"""
6.2.5 多种方法混合
# eg:先按team分组,再按姓名首字母是否为元音分组
df.groupby(['team', df.name.apply(get_letter_type)]).sum()
# 这里没有先设置索引name,因此需要通过apply来调用
"""
Q1 Q2 Q3 Q4
team name
A 元音 274 197 141 199
辅音 792 442 734 584
B 元音 309 291 269 218
辅音 666 927 933 918
C 元音 473 488 453 464
辅音 583 706 615 663
D 元音 273 333 409 486
辅音 587 858 832 713
E 元音 133 131 138 207
辅音 830 882 743 826
"""
6.2.6 用pipe调用分组方法
df.pipe()管道方法,可以调用函数对DataFrame进行处理。而Pandas的groupby是一个函数:
# 使用pipe调用分组函数
df.pipe(pd.DataFrame.groupby, 'team').sum()
"""
Q1 Q2 Q3 Q4
team
A 1066 639 875 783
B 975 1218 1202 1136
C 1056 1194 1068 1127
D 860 1191 1241 1199
E 963 1013 881 1033
"""
以此类推。可以传入更多参数。
6.2.7 分组器Grouper
# 分组器语法
pandas.Grouper(key=None, level=None, freq=None, axis=0, sort=False)
df.groupby(pd.Grouper('team'))
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000021CD49D0E10>
# eg
df.groupby('team')
df.groupby(pd.Grouper('team')).sum()
# 如果是时间,可以60s一分组
df.groupby(Grouper(key='date', freq='60s'))
# 轴方向
df.groupby(Grouper(level='data', freq='60s', axis=1))
# 按索引
df.groupby(Grouper(level=1)).sum()
# 多列
df.groupby([pd.Grouper(freq='1M', key='Date'), 'Buyer']).sum()
df.groupby([pd.Grouper('dt', freq='D'), pd.Grouper('other_column')])
# 按轴层级
df.groupby([pd.Grouper(level='second'), 'A']).sum()
df.groupby([pd.Grouper(level=1), 'A']).sum()
6.2.8 索引
groupby操作后分组字段会成为索引,如果不想让它成为索引,可以使用as_index=False进行设置:
df.groupby('team', as_index=False).sum() #team仍然是表头
"""
team Q1 Q2 Q3 Q4
0 A 1066 639 875 783
1 B 975 1218 1202 1136
2 C 1056 1194 1068 1127
3 D 860 1191 1241 1199
4 E 963 1013 881 1033
"""
6.2.9 排序
groupby操作后分组字段会成为索引,数据会对索引进行排序,如果不想排序,可以使用sort=False进行设置,不排序的情况下会按索引出现的顺序排列:
df.groupby('team', sort=False).sum()
"""
Q1 Q2 Q3 Q4
team
E 963 1013 881 1033
C 1056 1194 1068 1127
A 1066 639 875 783
D 860 1191 1241 1199
B 975 1218 1202 1136
"""
6.2.10 小结
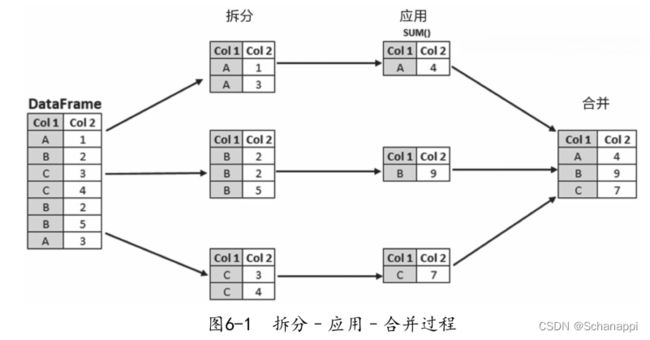
groupby可以简单总结为拆开数据、应用数据和合并数据。Pandas提供了很多分组方法,能够灵活自由地进行分组。
另外,对于时序数据的分组, Pandas提供了df.resample()的方法,将会在14章介绍。
6.3 分组对象的操作
上一节完成了分组对象的创建,接下来对分组对象进行操作,获取其相关信息,为最后的数据聚合统计打好基础。
# 创建分组对象
grouped = df.drop('name', axis=1).groupby('team') # 为方便介绍,删去name列
# 应用聚合函数
grouped.sum() # 数据被分为A-E五组
6.3.1 选择分组
分组对象的groups方法会生成一个字典,包含分组名称和分组的内容索引列表,可以使用字典的.keys()方法取出分组名称:
# 查看分组内容
df.groupby('team').groups
# {'A': [2, 7,...], 'B': [6, ...], 'C': [1, ...,], 'D': [4, ...], 'E': [0,...}
# 查看分组名
df.groupby('team').groups.keys()
# dict_keys(['A', 'B', 'C', 'D', 'E'])
多层索引:
# 用团队和姓名的首字母分组
grouped2 = df.groupby(['team', df.name.str[0]])
# 选择B组、姓名以A开头的数据
grouped2.get_group(('B', 'A'))
"""
name team Q1 Q2 Q3 Q4
6 Acob B 61 95 94 8
83 Albert0 B 85 38 41 17
"""
grouped.indices返回一个字典,其键为组名,值为本组索引的array格式,可以实现对单分组数据的选取:
# 获取分组字典数据
grouped.indices
# 选择A组
grouped.indices['A']
# array([ 2, 7, 9, 16, 17, 20, 22, 34, 40, 42, 51, 67, 70, 71, 75, 79, 88],
dtype=int64)
6.3.2 迭代分组
分组对象grouped的每个迭代元素是一个元组,每个元素又是由分组名和分组数据内容组成的元组:
# 迭代
for g in grouped:
print(type(g))
# <class 'tuple'>
# 迭代元素的数据类型
for name, group in grouped:
print(type(name))
print(type(group))
# <class 'str'>
# <class 'pandas.core.frame.DataFrame'>
6.3.3 选择列
# 选择数据分组后的某一列,和DataFrame选择列操作一样
grouped.Q1
grouped['Q1'] # 同上
# 选择多列
grouped[['Q1', 'Q2']]
6.3.4 应用函数apply()
分组对象使用apply()调用一个函数,传入的是DataFrame,返回一个经过函数计算后的DataFrame、Series或标量,然后再把数据组合。
对每一列单独操作
# eg1:将数据中的所有元素*2
df.groupby('team').apply(lambda x: x*2)
"""
name team Q1 Q2 Q3 Q4
0 LiverLiver EE 178 42 48 128
1 ArryArry CC 72 74 74 114
2 AckAck AA 114 120 36 168
3 EorgeEorge CC 186 192 142 156
4 OahOah DD 130 98 122 172
... ... ... ... ... ... ...
98 EliEli EE 22 148 116 182
99 BenBen EE 42 86 82 148
100 rows × 6 columns
"""
# eg2:实现每组Q1成绩最高的三个
def first_3(df_, c):
return df_[c].sort_values(ascending=False).head(3)
# 调用函数
df.set_index('name').groupby('team').apply(first_3, 'Q1')
"""
team name
A Aaron 96
Henry 91
Nathan 87
B Elijah 97
Harrison 89
Michael 89
C Lincoln4 98
Eorge 93
Alexander 91
D Mason 80
Albie1 79
Ethan 79
E Max 97
Ryan 92
Liver 89
Name: Q1, dtype: int64
"""
6.3.5 管道方法pipe()
类似于DataFrame的管道方法,分组对象的管道方法接收之前的分组对象,将同组的所有数据应用在方法中,最后返回的是经过函数处理过的返回数据格式。
# eg1:每组最大值和最小值的和
df.groupby('team').pipe(lambda x: x.max()+ x.min())
"""
name Q1 Q2 Q3 Q4
team
A TylerAaron 105 91 113 105
B ThomasAcob 99 103 111 101
C WilliamAdam 99 109 88 118
D Theodore3Aiden 85 104 105 110
E ZacharyArlo8 101 99 100 101
"""
# eg2:定义了A组和B组平均值的差值
def mean_diff(x):
return x.get_group('A').mean() - x.get_group('B').mean()
df.groupby('team').pipe(mean_diff)
"""
Q1 18.387701
Q2 -17.775401
Q3 -3.165775
Q4 -5.577540
dtype: float64
"""
pipe和apply的区别:
pipe接收的是分组对象;而apply接收的是DataFrame。
6.3.6 转换方法transform()
transform()类似于agg(),但不同的是,transform返回的是一个与原始数据形状相同的DataFrame,会将每个数据原来的值一一替换为统计后的值。
使用函数时,分别传入每个分组的子DataFrame的每一列,经过计算后每列返回一个结果,然后再将每组的这列所有值都替换为计算结果,最后以原DataFrame的形式显示所有数据。
# eg:将所有数据替换成分组中的平均成绩
df.groupby('team').transform(np.mean)
"""
Q1 Q2 Q3 Q4
0 48.150000 50.650000 44.050000 51.650000
1 48.000000 54.272727 48.545455 51.227273
2 62.705882 37.588235 51.470588 46.058824
3 48.000000 54.272727 48.545455 51.227273
4 45.263158 62.684211 65.315789 63.105263
... ... ... ... ...
95 48.000000 54.272727 48.545455 51.227273
96 48.000000 54.272727 48.545455 51.227273
97 48.000000 54.272727 48.545455 51.227273
98 48.150000 50.650000 44.050000 51.650000
99 48.150000 50.650000 44.050000 51.650000
100 rows × 4 columns
"""
6.3.7 筛选方法filter()
使用filter对组作为整体进行筛选,如果满足条件,则整个组会被显示。传入它调用函数中的默认变量为每个分组的DataFrame,经过计算,最终返回一个布尔值(不是布尔序列),为真的DataFrame全部显示。
# 筛选出所在组平均分大于51的成员 (通过计算后只有B、D两组,即显示出B、D组的所有成员)
df.groupby('team').filter(lambda x: x.mean(1).mean() > 51)
"""
name team Q1 Q2 Q3 Q4
4 Oah D 65 49 61 86
6 Acob B 61 95 94 8
8 Reddie D 64 93 57 72
10 Leo B 17 4 33 79
11 Logan B 9 89 35 65
.....
"""
6.3.8 其他功能
df.groupby('team').first() # 组内第一个
df.groupby('team').last() # 组内最后一个
df.groupby('team').ngroups # 5 分组数
df.groupby('team').ngroup() # 分组序号
grouped.backfill()
grouped.bfill()
df.groupby('team').head() # 每组显示前5个
grouped.tail(1) # 每组最后一个
grouped.rank() # 排序值
grouped.fillna(0)
grouped.indices() # 组名:序列组成的字典
# 分组中的第几个值
gp.nth(1) # 第一个
gp.nth(-1) # 最后一个
# 第n个非空项
gp.nth(0, dropna='all')
gp.nth(0, dropna='any')
df.groupby('team').shift(-1) # 组内移动
grouped.tshift(1) # 按时间周期移动
# 返回布尔序列
df.groupby('team').any()
df.groupby('team').all()
df.groupby('team').rank() # 每个成员在组内的排名
# 仅SeriesGroupBy可用
df.groupby("team").Q1.nlargest(2) # 每组最大的两个
df.groupby("team").Q1.nsmallest(2) # 每组最小的两个
df.groupby("team").Q1.nunique() # 每组去重数量
df.groupby("team").Q1.unique() # 每组去重值
df.groupby("team").Q1.value_counts() # 每组去重值及数量
df.groupby("team").Q1.is_monotonic_increasing # 每组值是否单调递增
df.groupby("team").Q1.is_monotonic_decreasing # 每组值是否单调递减
# 仅DataFrameGroupBy可用
df.groupby("team").corrwith(df2) # 相关性
6.3.9 小结
本节介绍了对分组的基本操作和一些函数方法,特别注意分辨以下三个方法:
- apply:最为灵活,可以对数据完成操作后返回各种形式的数据;
- transform:对数据完成操作后返回原型形状的数据,可以类比为对一个汽车不改变结构,只重新进行涂装;
- filter:每个分组传入后,通过计算返回这个分组的真假值,真的留下,作为最终结果。
其中transform和filter计算的都是每个分组的整体结果。
6.4 聚合统计
本节主要介绍对分组完的数据的统计工作,这是分组聚合的最后一步。通过最终数据的输出,可以观察到业务变化情况。
6.4.1 描述统计
分组对象如同df.describe(),也支持.describe(),用来对数据的总体进行描述:
# 描述统计,由于列过多,进行转置
df.groupby('team').describe().T
"""
team A B C D E
Q1 count 17.000000 22.000000 22.000000 19.000000 20.000000
mean 62.705882 44.318182 48.000000 45.263158 48.150000
std 24.155136 32.607896 31.000768 25.886166 33.242767
min 9.000000 2.000000 1.000000 5.000000 4.000000
25% 52.000000 11.000000 21.750000 18.000000 11.750000
50% 64.000000 48.000000 46.000000 50.000000 48.000000
75% 78.000000 66.000000 77.250000 64.500000 73.250000
max 96.000000 97.000000 98.000000 80.000000 97.000000
Q2 count 17.000000 22.000000 22.000000 19.000000 20.000000
...
"""
6.4.2 统计函数
对分组对象直接使用统计函数,对分组内的所有数据进行计算,最终以DataFrame形式显示数据。
grouped.mean()
"""
Q1 Q2 Q3 Q4
team
A 62.705882 37.588235 51.470588 46.058824
B 44.318182 55.363636 54.636364 51.636364
C 48.000000 54.272727 48.545455 51.227273
D 45.263158 62.684211 65.315789 63.105263
E 48.150000 50.650000 44.050000 51.650000
"""
# 常用的统计方法
df.groupby('team').describe() # 描述性统计
df.groupby('team').sum()
df.groupby('team').count() # 每组数量,不包括缺失值
df.groupby('team').max()
df.groupby('team').min()
df.groupby('team').size() # 分组数量
df.groupby('team').mean()
df.groupby('team').median() # 中位数
df.groupby('team').std()
df.groupby('team').var()
grouped.corr() # 相关性系数
grouped.sem() # 标准误差
grouped.prod() # 乘积
grouped.cummax() # 每组的累计最大值
grouped.cumsum() # 累加
grouped.mad() # 平均绝对偏差
6.4.3 聚合方法agg()
分组对象的方法.aggregate简写为.agg。它的作用是将分组后的对象给定统计方法,也支持按字段分别给定不同的统计方法。
单个统计方法实现与上个小节相同的功能:
df.groupby('team').aggregate(sum)
df.groupby('team').agg(sum)
grouped.agg(np.size)
grouped['Q1'].agg(np.mean)
使用它主要是为了实现一个字段使用多种统计方法,不同字段使用不同方法:
# 每个字段使用多个计算方法
grouped[['Q1', 'Q3']].agg([np.sum, np.mean, np.std])
"""
Q1 Q3
sum mean std sum mean std
team
A 1066 62.705882 24.155136 875 51.470588 27.171027
B 975 44.318182 32.607896 1202 54.636364 29.981813
C 1056 48.000000 31.000768 1068 48.545455 27.921194
D 860 45.263158 25.886166 1241 65.315789 21.916642
E 963 48.150000 33.242767 881 44.050000 21.808919
"""
# 不同列使用不同计算方法,且一列用多个计算方法
df.groupby('team').agg({'Q1': ['min', 'max'], 'Q2': 'sum'})
Q1 Q2
min max sum
team
A 9 96 639
B 2 97 1218
C 1 98 1194
D 5 80 1191
E 4 97 1013
类似于之前学过的增加新列的方法df.assign(),agg()可以指定新列名字:
# 指定列名,列表是原列和方法
df.groupby('team').Q1.agg(Mean='mean', Sum='sum')
df.groupby('team').agg(Mean=('Q1', 'mean'), Sum=('Q2', 'sum'))
df.groupby('team').agg(
Q1_max=pd.NamedAgg(column='Q1', aggfunc='max'),
Q2_sum=pd.NamedAgg(column='Q2', aggfunc='sum'))
如果列名不是有效的Python变量格式,则可以使用以下方法:
df.groupby('team').agg(**{
'1_max':pd.NamedAgg(column='Q1', aggfunc='max')})
统计方法可以使用函数。在使用函数时,分别传入每个分组后的子DataFrame,会按子DataFrame把这组的所有列组成的序列传到函数里进行计算,最终返回一个固定值。
# 聚合结果使用函数
# lambda/函数,所有方法都可以使用
def max_min(x):
return x.max() - x.min()
# 定义函数
df.groupby('team').Q1.agg(Mean='mean', Sum='sum', Diff=lambda x:x.max()-x.min(), Max_min=max_min)
如果对同一列全使用同一函数,直接写函数名即可:
df.groupby('team').agg(max_min)
6.4.4 时序重采样方法resample()
针对时间序列数据,resample将分组后的时间索引按周期进行聚合计算。14章会详细介绍。
# eg:
idx = pd.date_range(start='1/1/2020', periods=100, freq='T')
df2 = pd.DataFrame(data={'a':[0, 1]*50, 'b':1}, index=idx)
df2
"""
a b
2020-01-01 00:00:00 0 1
2020-01-01 00:01:00 1 1
2020-01-01 00:02:00 0 1
2020-01-01 00:03:00 1 1
2020-01-01 00:04:00 0 1
... ... ...
2020-01-01 01:35:00 1 1
2020-01-01 01:36:00 0 1
2020-01-01 01:37:00 1 1
2020-01-01 01:38:00 0 1
2020-01-01 01:39:00 1 1
100 rows × 2 columns
"""
索引是一个时序数据,接下来按a列进行分组,然后按20分钟(由于1分钟是一个周期T,我们传入20T)对b进行求和计算:
# 每20分钟聚合一次
df2.groupby('a').resample('20T').sum()
"""
a b
a
0 2020-01-01 00:00:00 0 10
2020-01-01 00:20:00 0 10
2020-01-01 00:40:00 0 10
2020-01-01 01:00:00 0 10
2020-01-01 01:20:00 0 10
1 2020-01-01 00:00:00 10 10
2020-01-01 00:20:00 10 10
2020-01-01 00:40:00 10 10
2020-01-01 01:00:00 10 10
2020-01-01 01:20:00 10 10
"""
6.4.5 组内头尾值
在一个组内,如果希望取第一个值和最后一个值,可以使用以下方法。当然,定义第一个和最后一个需要事先完成。
# 每组第一个
df.groupby('team').first()
"""
name Q1 Q2 Q3 Q4
team
A Ack 57 60 18 84
B Acob 61 95 94 8
C Arry 36 37 37 57
D Oah 65 49 61 86
E Liver 89 21 24 64
"""
6.4.6 组内分位数
中位数是二分位,如果在分组中需要看指定分位数据,使用.quantile()来实现。
# 以下均为二分位
df.groupby('team').median()
df.groupby('team').quantile()
df.groupby('team').quantile(0.5)
6.4.7 组内差值
和DataFrame的diff()一样,分组对象的diff()方法会在组内进行前后数据的差值计算,并以原DataFrame形状返回数据:
grouped.diff()
6.4.8 小结
本节介绍的功能是将分组的结果最终统计并展示出来。我们需要掌握常见的数学统计函数,也可以使用Numpy的大量统计方法。
6.5 数据分箱
数据分箱(离散组合或数据分桶)是一种数据预处理技术,将原始数据分成几个区间,即bin(小箱子),是一种量子化形式。数据分箱可以最大限度减小观察误差的影响。落入给定区间的原始数据值被代表该区间的值(通常是中心值)替换。然后将其替换为针对该区间计算的常规值。具有平滑输入数据的作用,并且在小数据集的情况下还可以减少过拟合。
Pandas主要基于以下两个函数实现连续数据的离散化处理:
- pandas.cut:根据指定分界点对连续数据进行分箱处理。
- pandas.qcut:根据指定区间数量对连续数据进行等宽分箱处理。等宽指的是每个区间中的数据量相同。
6.5.1 定界分箱pd.cut()
pd.cut()可以指定区间将数字进行划分。
# eg:将Q1成绩换60分及以上、60分以下进行分类
pd.cut(df.Q1, bins=[0, 60, 100])
"""
0 (60, 100]
1 (0, 60]
2 (0, 60]
3 (60, 100]
4 (60, 100]
...
95 (0, 60]
96 (0, 60]
97 (60, 100]
98 (0, 60]
99 (0, 60]
Name: Q1, Length: 100, dtype: category
Categories (2, interval[int64]): [(0, 60] < (60, 100]]
"""
将分箱结果应用到groupby分组中:
# Series使用
df.Q1.groupby(pd.cut(df.Q1, bins=[0, 60, 100])).count()
"""
Q1
(0, 60] 57
(60, 100] 43
Name: Q1, dtype: int64
"""
# DataFrame使用
df.groupby(pd.cut(df.Q1, bins=[0, 60, 100])).count()
"""
name team Q1 Q2 Q3 Q4
Q1
(0, 60] 57 57 57 57 57 57
(60, 100] 43 43 43 43 43 43
"""
以下显示了每个分组的数据。其他参数示例如下:
# 不显示区间,使用数字作为每个箱子的标签,形式如0,1,2,n
pd.cut(df.Q1, bins=[0, 60, 100], labels=False)
# 指定标签名
pd.cut(df.Q1, bins=[0, 60, 100], labels=['不及格', '及格'])
# 包含最低部分
pd.cut(df.Q1, bins=[0, 60, 100], include_lowest=True)
# 是否为右闭区间
pd.cut(df.Q1, bins=[0, 60, 100], right=False)
6.5.2 等宽分箱pd.qcut()
pd.qcut()可以指定所分区间的数量,Pandas会自动进行分箱:
# 按Q1成绩分为两组
pd.qcut(df.Q1, q=2)
"""
0 (51.5, 98.0]
1 (0.999, 51.5]
2 (51.5, 98.0]
3 (51.5, 98.0]
4 (51.5, 98.0]
...
95 (0.999, 51.5]
96 (0.999, 51.5]
97 (51.5, 98.0]
98 (0.999, 51.5]
99 (0.999, 51.5]
Name: Q1, Length: 100, dtype: category
Categories (2, interval[float64]): [(0.999, 51.5] < (51.5, 98.0]]
"""
# 查看分组区间
pd.qcut(df.Q1, q=2).unique()
"""
[(51.5, 98.0], (0.999, 51.5]]
Categories (2, interval[float64]): [(0.999, 51.5] < (51.5, 98.0]]
"""
应用到分组中:
# Series使用
df.Q1.groupby(pd.qcut(df.Q1, q=2)).count()
"""
Q1
(0.999, 51.5] 50
(51.5, 98.0] 50
Name: Q1, dtype: int64
"""
# DataFrame使用
df.groupby(pd.qcut(df.Q1, q=2)).count()
"""
name team Q1 Q2 Q3 Q4
Q1
(0.999, 51.5] 50 50 50 50 50 50
(51.5, 98.0] 50 50 50 50 50 50
"""
其他参数如下:
# 0-5, 4个区间
pd.qcut(range(5), 4)
"""
[(-0.001, 1.0], (-0.001, 1.0], (1.0, 2.0], (2.0, 3.0], (3.0, 4.0]]
Categories (4, interval[float64]): [(-0.001, 1.0] < (1.0, 2.0] < (2.0, 3.0] < (3.0, 4.0]]
"""
pd.qcut(range(5), 4, labels=False) # array([0, 0, 1, 2, 3], dtype=int64)
# 指定标签名
pd.qcut(range(5), 3, labels=["good", "medium", "bad"])
# 返回箱子标签: array([ 1. , 51.5, 98. ]))
pd.qcut(df.Q1, q=2, retbins=True)
# 分箱位小数位数
pd.qcut(df.Q1, q=2, precision=3)
# 排名分三个层次
pd.qcut(df.Q1.rank(method='first'), 3)
6.5.3 小结
分箱也是一种数据分组方式,经常用于数据建模、机器学习中,更适合离散数据。
6.6 分组可视化
6.6.1 绘图方法plot()
数据分组对象也支持plot(),不过它以分组对象中每个DataFrame或Series为对象,绘制出所有分组图形。默认情况下, 它绘制的是折线图。
# 分组,设置索引name
grouped = df.set_index('name').groupby('team')
# 绘制图形
grouped.plot()
"""
team
A AxesSubplot(0.125,0.125;0.775x0.755)
B AxesSubplot(0.125,0.125;0.775x0.755)
C AxesSubplot(0.125,0.125;0.775x0.755)
D AxesSubplot(0.125,0.125;0.775x0.755)
E AxesSubplot(0.125,0.125;0.775x0.755)
dtype: object
"""
生成如下图形:(这里只展示A组)
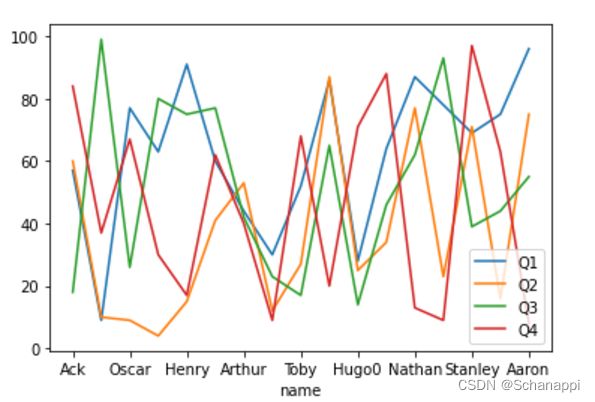
还可以通过plot.x()或者plot(kind=‘x’)的形式调用其他形状的图形:
- plot.line:折线图
- plot.pie:饼图
- plot.bar:柱状图
- plot.hist:直方图
- plot.box:箱型图
- plot.area:面积图
- plot.scatter:散点图
- plot.hexbin:六边形分箱图
6.6.2 直方图hist()
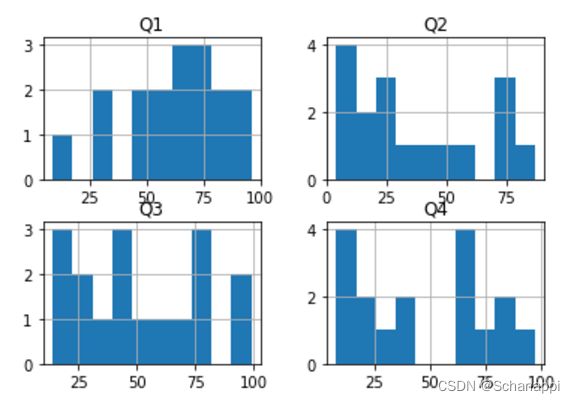
# 绘制直方图
grouped.hist()
"""
team
A [[AxesSubplot(0.125,0.551739;0.336957x0.328261...
B [[AxesSubplot(0.125,0.551739;0.336957x0.328261...
C [[AxesSubplot(0.125,0.551739;0.336957x0.328261...
D [[AxesSubplot(0.125,0.551739;0.336957x0.328261...
E [[AxesSubplot(0.125,0.551739;0.336957x0.328261...
dtype: object
"""
共生成五组直方图(这里只展示A组的直方图):
6.6.3 箱线图boxplot()
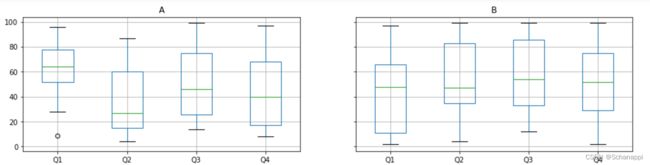
箱线图展示了各个字段的最大值、最小值、分位数等信息。
# 分组箱线图
grouped.boxplot(figsize=(15, 12))
"""
A AxesSubplot(0.1,0.679412;0.363636x0.220588)
B AxesSubplot(0.536364,0.679412;0.363636x0.220588)
C AxesSubplot(0.1,0.414706;0.363636x0.220588)
D AxesSubplot(0.536364,0.414706;0.363636x0.220588)
E AxesSubplot(0.1,0.15;0.363636x0.220588)
dtype: object
"""
以上代码将按组显示一个箱线图矩阵(这里展示A、B两组):
另外,DataFrame的boxplot()方法可以传入分组字段,绘制出每个字段在不同分组中的数据图像:
# 分组箱线图
df.boxplot(by='team', figsize=(15, 10))
"""
array([[<AxesSubplot:title={'center':'Q1'}, xlabel='[team]'>,
<AxesSubplot:title={'center':'Q2'}, xlabel='[team]'>],
[<AxesSubplot:title={'center':'Q3'}, xlabel='[team]'>,
<AxesSubplot:title={'center':'Q4'}, xlabel='[team]'>]],
dtype=object)
"""
以上代码会按team分组并返回箱线图:
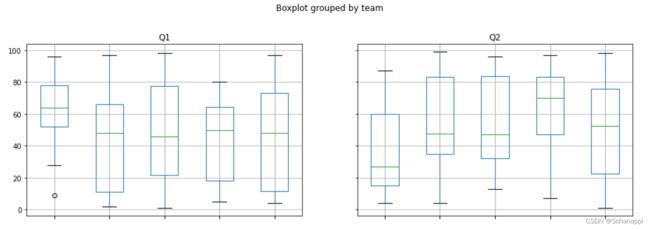
6.7 本章小结
本章全面介绍了分组聚合的数据操作原理,依次可分为以下部分:
- 分拆(split):将DataFrame或Series按照一定规则进行分组,生成分组对象,其中包含多个子DataFrame或Series。
- 应用(apply):对每个组进行操作或数据统计,如算平均数,还可以使用函数进行复杂操作或计算。
- 合并(combine):将每组的计算结果再拼合起来,最终得到一个DataFrame或Series,或者直接进行可视化显示。