2020李宏毅机器学习笔记——26.Conditional Generation by GAN(条件生成—GAN)
Conditional Generation by GAN
文章目录
- 摘要
- 1. Supervised Conditional GAN
-
- 1.1 Traditional supervised approach
- 1.2 Conditional GAN
- 2. unsupervised conditional GAN
-
- 2.1 什么是unsupervised conditional GAN
- 2.2 unsupervised conditional GAN要怎么做
-
- 2.2.1 Direct Transformation(直接转)
- 2.2.2 Projection to Common Space
- 3.总结与展望
摘要
本章是在围绕Conditional GAN——即条件生成的GAN,Conditional GAN可以控制我们想要输出的结果。Conditional GAN分为两大类:
一是监督学习的条件生成GAN,其做法是同时输入一个随机的正态分布vector z,和条件condition,都丢给生成器G,得到一个样本image,再将G生成的图片及条件(文字encode c )组合起来,都丢给D去打分。(常用的判别器D 有两种 架构)
二是无监督学习的条件生成GAN,其做法有两种:一种是直接转换,在生成图片后面加上一个判别器D,用来判别生成的图片是否符合要求的domain。为了解决输出与输入相关联,讲解了一些解决方法,比如无视,pre-trained,Cycle GAN等。另一种是投影到相同的空间,对于不同的domain,设置不同的domain encoder和decoder。由于两个auto-encoder是分开train的,所以两者之间是没有关联的;所以后面有几种方法去解决这个相关联的问题,比如共享参数,增加domain的判别器D,Cycle Consistency等。
1. Supervised Conditional GAN
一般来说自动生成图片或文本意义不算很大,但如果能在一定限制条件下生成,则十分有意义。由于之前的GAN,是随机输入一个vector然后产生输出,无法控制产生我们想要的输出。Conditional GAN就是想要控制我们输出的结果。
1.1 Traditional supervised approach
输入文字,生成对应的图片。应用传统的监督学习方法,会遇到麻烦的问题,产生模糊的图片。
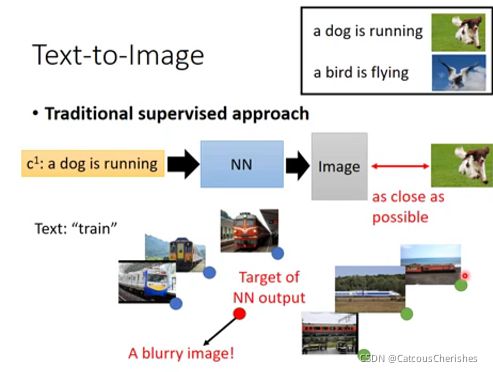
1.2 Conditional GAN
Conditional GAN 的意思就是有条件的GAN。Conditional GAN 可以让 GAN 产生的结果符合一定的条件,即可以通过人为改变输入的向量,控制最终输出的结果。
Conditional GAN的做法是:
- 关于生成器架构:
1.同时输入一个随机的正态分布vector z,和条件condition(比如下图中的文本train火车)。
2.通过深度神经网络构建的生成器,生成一个样本图片。
对于生成器这一块,只是多了一个condition输入而已。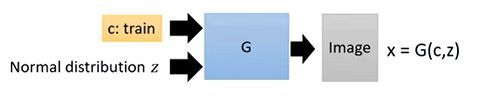
- 关于判别器的架构:
-
一个最常见的架构是将object x(图片)和condition c(文字)分别通过Network变成Embedding,然后将这两个Embedding组合起来,丢给Network去打分。
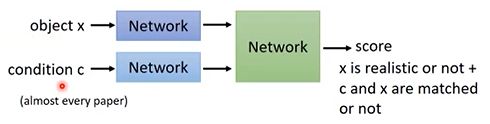
判别器的目标有两个,一个是样本图片要尽量真实,第二个是样本要和条件是匹配的。(这与通用的GAN是不同的) -
一个最新的架构是:为了避免模型需要应对两个条件,导致难度过大。我们也可以把判别器的两个条件分开,也就是将用两个不同的Network,一个辨别图片是否真实,一个辨别图片与条件是否匹配。

将网络Network分为两路,样本x通过绿色network,判别是否是真实样本。条件condition c和样本x 同时经过蓝色network,判别二者是否是match的。这样做得到的结果更加清晰明,对于判别得到低分的,我们可以很容易知道原因是什么。
2. unsupervised conditional GAN
2.1 什么是unsupervised conditional GAN
通用GAN和条件GAN,都需要监督信号,也就是满足条件的真实样本。有时候真实样本不是那么容易得到,那我们有没有办法实现无监督条件GAN呢?
研究无监督学习,只需要两堆数据(无标签的),可将某种特征从一堆转到另一堆,即有domain x的画作和domain y的画作的data。可以训练一个生成器,无需label data就可以将x风格的画转换成 y风格的画作。这种方法还可以用在语音和文字上。
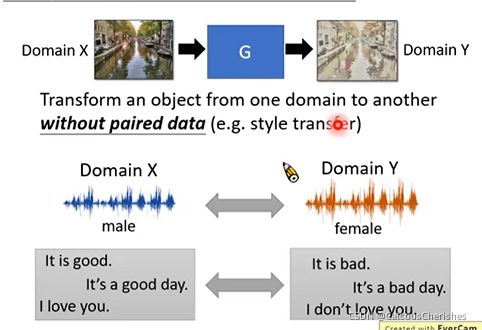
2.2 unsupervised conditional GAN要怎么做
首先可分为两大类的做法:
- Direct Transformation(直接转):直接学习一个生成器,可以将domainX转换为domainY(通常适用于小改,比如颜色,纹理等,也就是改变图片画风)
- Projection to Common Space(投影到公共空间): 处理差距比较大的两个domain,将domain x的特征提取出来,生成一个face attribute,然后再输入decode得出domain y风格的图像。
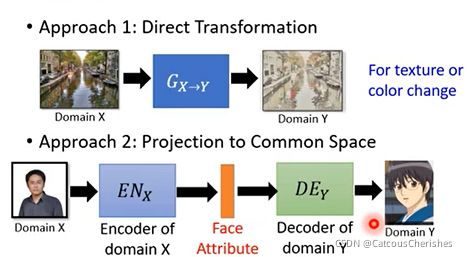
2.2.1 Direct Transformation(直接转)
现在我们需要学习一个生成器,我们有domain x,y 的图像,如果输入domain x的数据,然后用生成器生成对应的domain y的图片,这是监督学习的方法。因为之前的监督学习中的生成器看过domain y的风格,可以直接是生成出来。
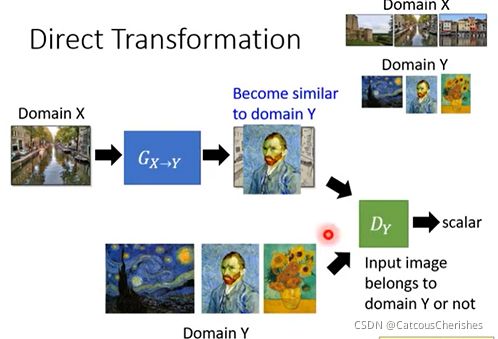
但是现在是无监督学习的GAN,就需要一个Y domain的判别器D,即可以识别出生成图片是否属于domain y。那接下来生成器G要做的事就是想办法去骗过判别器,这样就生成domain Y 的东西。
然而这样做又会有一个问题:如果生成器为了骗过判别器,产生domain y 的图片,而图片与domain x完全无关怎么办?
因此生成器不仅要骗过判别器,还要让输出的东西与输入有一定的关系。
解决方法有:
1.直接无视问题。由于生成器输入与输出,本来就是尽可能的接近的。
2. pre-trained:将生成器的输入和输出image,统统丢给这个pre-train好的网络,就会输出两个embedding vector,在训练时要求这两个vector 很接近,并且需要生成器去生成的样本尽可能的骗过判别器D。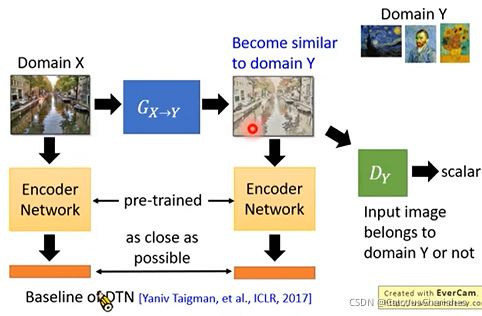
3. Cycle GAN:通过两个生成器,将domain x的图片转换为domain y,然后又转换回domain x,从而确保两个domain图片是关联的。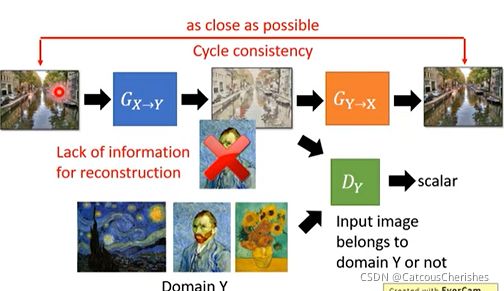
4. starGAN
之前的转换是两个domain之间,而StarGAN则是在多个不同domain之间互相转换。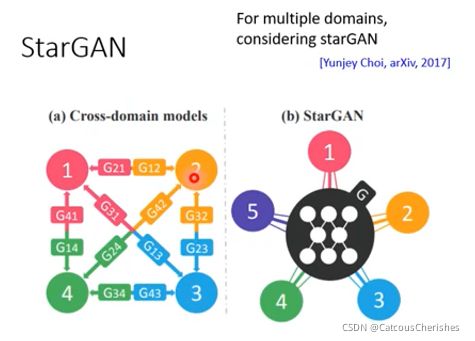
StarGAN的做法:
- 首先需要训练一个判别器D,这个判别器要做两件事:一是对于一张image,它要鉴别它的真假;二是判断这个image来自于哪一个domain;
- 只需要训练一个生成器G,生成器G的输入是目标domain和输入图片,输出得到一个fake image。
- 将得到的fake image和原来的domain输入给相同的生成器G,希望还原成之前的图片,输出的重建的图片要接近之前原始输入的图片。
- 最后将fake image输入给判别式D,来检查fake image是否真实,是不是我们想要的domain。
StarGAN的应用:
multi-domain的表示是很多属性编码的,目标domain中:第一个10011黑色头发男性年轻;原始domian中:00101表示棕色女性年轻。
2.2.2 Projection to Common Space
首先有两个domain:真人X和动画Y,要做这两个之间的转换。
目标是:真实图片输入,经过model输出动漫图片,动漫图片输入,输出真实图片。
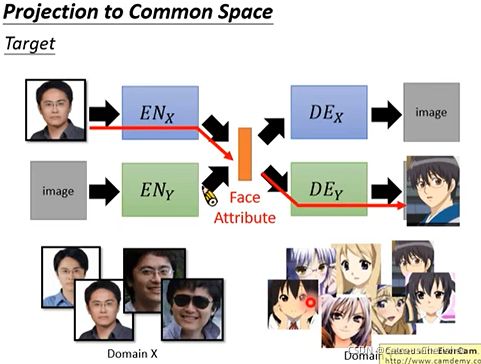
现在是无监督学习,做法是分别训练两个Auto-encoder,一个train真实图片,一个train动漫图片,我们还分别引入判别器D,以确保产生图片的domain。
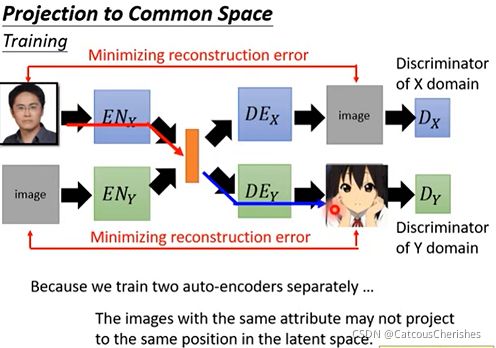
由于两个auto-encoder是分开train的,所以两者之间是没有关联的;也就是说没法保证真实图片和动漫图片的vector每个维度代表的意义是一样的。
怎么解决关联问题?
-
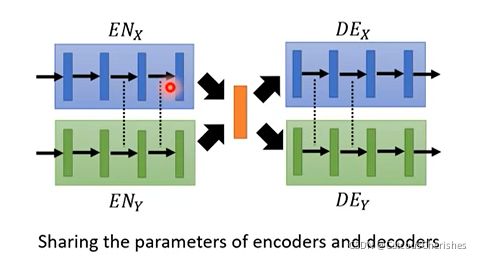
共享参数:不同domain的encoder,最后几层的参数是共用的。不同Decoder,前面几层参数也是共用的。
-
增加domain的判别器D:
在model的中间引入一个Domain Discriminator,该D做的事情是通过判别器来判断encoder输出来自于哪个domain;训练的目的就是骗过这个domain discrimination。当domain discrimination无法识别出特征来自于哪个domain,说明两个encoder产生的特征表示都来自同一个分布,也就是说它们具有相同的维度空间表示。
-
Cycle Consistency:
将一张真人的图片通过encoder x 得到的code,丢给decoder y生成动漫图片,在将生成的图片作为输入丢给encoder y,得到code,再用其丢给decoder x去生成真人图片,然后希望生成的真人图片和原图越接近越好。
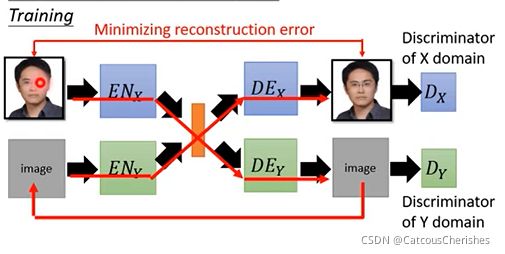
-
semantic consistency:将真人图片通过encoder x和decoder y得到动漫图片,将得到的image在通过encoder y,输出得到一个code ;用这个code 和encoder x输出的code 进行比较,让它们越接近越好。这个是在latent space上进行比较,而不是在表象pixle上比较像不像。
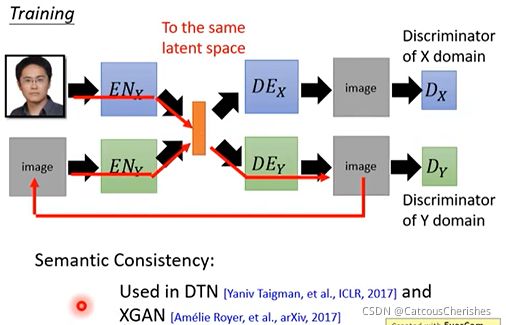
3.总结与展望
Supervised Conditional GAN主要应用在Text-to-Image图文转换,以及训练数据较为充足的情况。Unsupervised Conditional GAN的应用范围是更加广泛的,研究无监督学习GAN,只需要两堆数据(无标签的),可将某种特征从一堆转到另一堆。其关键一是在于生成的样本图片需要与原图片有一定的关联,二是在于其生成的样本需要去骗过判别器D,使生成的样本是可以在目标domain。
GAN在图像处理和计算机视觉方面应用最为广泛,例如图像翻译、图像生成、图像超分辨率、目标检测、视频生成等领域的应用。以及GAN也逐渐被应用于序列数据上,比如自然语言、音乐、语音、音频等序列数据。