Chapter5 深度学习基础
文章目录
- 1、激活函数
-
- 1.1、sigmoid函数
- 1.2、tanh函数
- 1.3、ReLU函数
- 1.4、softmax函数
- 2、损失函数
-
- 2.1、平均绝对误差损失函数(L1Loss)
- 2.2、均方误差损失函数(MSELoss)
- 2.3、负对数似然损失函数(NLLLoss)
-
- 2.3.1、似然
- 2.3.2、似然函数
- 2.3.3、极大似然估计
- 2.3.4、对数似然
- 2.3.5、负对数似然
- 2.3.6、pytorch中的应用
- 2.4、交叉熵损失函数(CrossEntropyLoss)
-
- 2.4.1、信息量
- 2.4.2、信息熵
- 2.4.3、相对熵(KL散度)
- 2.4.4、交叉熵
- 2.4.5、pytorch中的应用
- 2.4.6、使用总结
- 2.5、二元交叉熵损失函数(BCELoss&BCEWithLogitsLoss)
- 2.7 使用整合
- 3、优化器(Optimizer)
-
- 3.1、传统梯度优化的不足(BGD,SGD,MBGD)
-
- 3.1.1 一维梯度下降
- 3.1.2 多维梯度下降
- 3.2、动量(Momentum)
- 3.3、AdaGrad算法
- 3.4、RMSProp算法
- 3.5、Adam算法
- 4、过拟合和欠拟合
-
- 4.1、权重正则化
-
- 4.1.1、简介
- 4.1.2、从零开始实现
- 4.1.3、使用Pytorch的简洁实现
- 4.2 Dropout正则化
-
- 4.2.1、简介
- 4.2.2、从零开始实现
- 4.2.3、简洁实现
本节主要介绍深度学习的基础部分,深度学习是机器学习的重要分支,也是机器学习的核心,但深度学习是在机器学习基础上发展起来的,因此理解机器学习的基本概念,基本原理对理解深度学习有很大的帮助。本节首先介绍激活函数、损失函数和优化器,然后介绍如何选择合适的激活函数和损失函数,最后介绍解决过拟合、欠拟合的一些方法。本节的主要内容为:
- 激活函数
- 损失函数
- 如何选择激活函数和损失函数
- 优化器
- 解决过拟合、欠拟合的一些方法
1、激活函数
激活函数在神经网络中的作用有很多,主要作用是给神经网络提供非线性建模能力。如果没有激活函数,那么再多层的神经网络也只能处理线性可分问题。常用的激活函数有sigmoid、tanh、relu、softmax等。
1.1、sigmoid函数
sigmoid函数将输入变换为(0,1)上的输出。它将范围(-inf,inf)中的任意输入压缩到区间(0,1)中的某个值:
s i g m o i d ( x ) = 1 1 + e x p ( − x ) sigmoid(x)=\frac{1}{1+exp(-x)} sigmoid(x)=1+exp(−x)1
sigmoid函数是⼀个⾃然的选择,因为它是⼀个平滑的、可微的阈值单元近似。当我们想要将输出视作⼆元分类问题的概率时, sigmoid仍然被⼴泛⽤作输出单元上的激活函数(你可以将sigmoid视为softmax的特例)。然而, sigmoid在隐藏层中已经较少使⽤,它在⼤部分时候被更简单、更容易训练的ReLU所取代。下面为sigmoid函数的图像表示,当输入接近0时,sigmoid更接近线形变换。
import torch
from d2l import torch as d2l
%matplotlib inline
x=torch.arange(-8.0,8.0,0.1,requires_grad=True)
sigmoid=torch.nn.Sigmoid()
y=sigmoid(x)
d2l.plot(x.detach(),y.detach(),'x','sigmoid(x)',figsize=(5,2.5))

sigmoid函数的导数为下面的公示:
d d x s i g m o i d ( x ) = e x p ( − x ) ( 1 + e x p ( − x ) ) 2 = s i g m o i d ( x ) ( 1 − s i g m o i d ( x ) ) \frac{d}{dx}sigmoid(x)=\frac{exp(-x)}{(1+exp(-x))^2}=sigmoid(x)(1-sigmoid(x)) dxdsigmoid(x)=(1+exp(−x))2exp(−x)=sigmoid(x)(1−sigmoid(x))
sigmoid函数的导数图像如下所示。当输入值为0时,sigmoid函数的导数达到最大值0.25;而输入在任一方向上越远离0点时,导数越接近0。
#清除以前的梯度
#retain_graph如果设置为False,计算图中的中间变量在计算完后就会被释放。
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(),x.grad,'x','grad of sigmoid')

1.2、tanh函数
与sigmoid函数类似,tanh函数也能将其输入压缩转换到区间(-1,1)上,tanh函数的公式如下:
t a n h ( x ) = 1 − e x p ( − 2 x ) 1 + e x p ( − 2 x ) tanh(x)=\frac{1-exp(-2x)}{1+exp(-2x)} tanh(x)=1+exp(−2x)1−exp(−2x)
tanh函数的图像如下所示,当输入在0附近时,tanh函数接近线形变换。函数的形状类似于sigmoid函数,不同的是tanh函数关于坐标系原点中心对称。
import torch
from d2l import torch as d2l
%matplotlib inline
x=torch.arange(-8.0,8.0,0.1,requires_grad=True)
tanh=torch.nn.Tanh()
y=tanh(x)
d2l.plot(x.detach(),y.detach(),'x','tanh(x)',figsize=(5,2.5))

tanh函数的导数是:
d d x t a n h ( x ) = 1 − t a n h 2 ( x ) \frac{d}{dx}tanh(x)=1-tanh^2(x) dxdtanh(x)=1−tanh2(x)
tanh函数的导数如下,当输入接近0时,tanh函数的导数接近最大值1。与sigmoid函数图像中看到的类似,输入在任一方向上远离0点,导数越接近0。
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(),x.grad,'x','grad of tanh',figsize=(5,2.5))

1.3、ReLU函数
线性整流单元(ReLU),ReLU提供了一种非常简单的非线性变换。给定元素 x x x,ReLU函数被定义为该元素与0的最大值。
R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x,0) ReLU(x)=max(x,0)
ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素。如下为ReLU函数的曲线图。
import torch
from d2l import torch as d2l
%matplotlib inline
x=torch.arange(-8.0,8.0,0.1,requires_grad=True)
relu=torch.nn.ReLU()
y=relu(x)
d2l.plot(x.detach(),y.detach(),'x','relu',figsize=(5,2.5))

当输入为负时,reLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。当输入值等于0时,ReLU函数不可导。如下为ReLU函数的导数:
f ′ ( x ) = { 1 , x≥0 0 , x<0 f^{'}(x) = \begin{cases} 1, & \text{ x≥0 } \\ 0, & \text{x<0} \end{cases} f′(x)={1,0, x≥0 x<0
#retain_graph如果设置为False,计算图中的中间变量在计算完后就会被释放。
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(),x.grad,'x','grad of relu',figsize=(5,2.5))

ReLU函数的求导表现的很好:要么让参数消失,要么让参数通过。ReLU减轻了神经网络的梯度消失问题。ReLU函数有很多变体,如LeakyReLU,pReLU等。
1.4、softmax函数
在二分类任务时,经常使用sigmoid激活函数。而在处理多分类问题的时候,需要使用softmax函数。它的输出有两条规则。
- 每一项的区间范围的(0,1)
- 所有项相加的和为1.
假设有一个数组V, V i V_i Vi代表V中的第i个元素,那么这个元素的softmax值的计算公式为:
S i = e i ∑ j e j S_i=\frac{e^i}{\sum_j e^j} Si=∑jejei
下图为更为详细的计算过程:
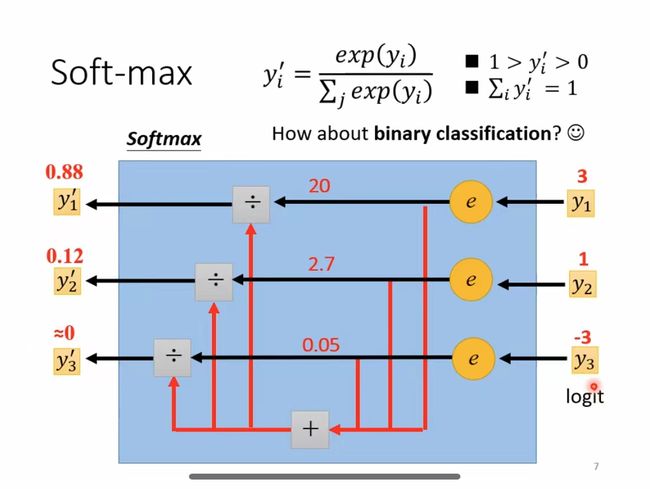
如上图所示,输入的数组为[3,1,-3]。那么每项的计算过程为:
当输入为3时,计算公式为 e 3 e 3 + e 1 + e − 3 ≈ 0.88 \frac{e^3}{e^3+e^1+e^{-3}}\approx 0.88 e3+e1+e−3e3≈0.88
当输入为1时,计算公式为 e 1 e 3 + e 1 + e − 3 ≈ 0.12 \frac{e^1}{e^3+e^1+e^{-3}}\approx 0.12 e3+e1+e−3e1≈0.12
当输入为-3时,计算公式为 e − 3 e 3 + e 1 + e − 3 ≈ 0 \frac{e^{-3}}{e^3+e^1+e^{-3}}\approx 0 e3+e1+e−3e−3≈0
下面使用代码实现这一计算过程。
x=torch.Tensor([3.,1.,-3.])
softmax=torch.nn.Softmax(dim=0)
y=softmax(x)
print(y)
tensor([0.8789, 0.1189, 0.0022])
那么在搭建神经网络的时候,应该如何选择激活函数?
- 如果搭建的神经网络的层数不多的时候,选择sigmoid、tanh、relu都可以,如果搭建的网络层数较多的时候,选择不当不当会造成梯度消失的问题,此时一般不宜选择sigmoid、tanh激活函数,最好选择relu激活函数。
- 在二分类问题中,网络的最后一层适合使用sigmoid激活函数;而多分类任务中,网络的最后一层使用softmax激活函数。
2、损失函数
损失函数在机器学习中非常重要,因为训练模型的过程实际就是优化损失函数的过程。损失函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟合时添加正则化项也是加在损失函数后面。损失函数用来衡量模型的好坏,损失函数越小说明模型和参数越符合训练样本。任何能够衡量模型预测值与真实值之间的差异的函数都可以叫做损失函数。下面介绍介个常用的损失函数,如平均绝对误差函数、均方误差函数、交叉熵损失函数、负对数似然损失函数、二分类交叉熵损失等。
2.1、平均绝对误差损失函数(L1Loss)
衡量输入 x x x和目标 y y y中每个元素之间的平均绝对误差(MAE)。具体的计算公式为:
M A E = ∑ i = 1 n ∣ x i − y i ∣ n MAE=\frac{\sum_{i=1}^{n}|x_i-y_i|}{n} MAE=n∑i=1n∣xi−yi∣
在pytorch中根据参数不同有不同计算方式,在pytorch中的具体格式为:
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
参数说明:
size_average(bool,可选):已废弃(可以使用reduction)。reduce(bool,可选):已废弃(可以使用reduction)。reduction(string,可选):指定要应用于输出的reduction:none|mean|sum。none:不应用reduction,mean:输出的总和将除以输出中的元素数,sum:输出将被求和。默认为mean
计算公式:
reduction设置为none(默认是mean)的损失可以描述为:
l ( x , y ) = L = { l 1 , ⋯ , l N } , l n = ∣ x n − y n ∣ \mathscr{l}(x,y)=L=\{l_1, \cdots ,l_N\}, \; \; \; l_n=|x_n-y_n| l(x,y)=L={l1,⋯,lN},ln=∣xn−yn∣
其中 N N N为批处理量。如果reduction不是none(默认是mean),那么:
l ( x , y ) = { m e a n ( L ) , if r e d u c t i o n = ’mean’ s u m ( L ) , if r e d u c t i o n = ’sum’ \mathscr{l}(x,y)=\begin{cases} mean(L), & \text{if $reduction$ = 'mean'} \\ sum(L), & \text{if $reduction$ = 'sum'} \end{cases} l(x,y)={mean(L),sum(L),if reduction = ’mean’if reduction = ’sum’
实例代码:
import torch.nn as nn
import torch
loss=nn.L1Loss()
input=torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()
2.2、均方误差损失函数(MSELoss)
测量输入 x x x和目标 y y y中每个元素之间的均方误差。回归问题预测的不是类别,而是一个任意实数。反应预测值与实际值之间的距离可以用欧式距离来表示,所以对于回归问题通常使用均方差作为损失函数。均方差的定义为:
M S E = ∑ i = 1 n ( x i − y i ) 2 n MSE=\frac{\sum_{i=1}^{n}{(x_i-y_i)}^2}{n} MSE=n∑i=1n(xi−yi)2
在pytorch中根据参数不同有不同计算方式,在pytorch中的具体格式为:
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
参数说明:
size_average(bool,可选):已废弃(可以使用reduction)。reduce(bool,可选):已废弃(可以使用reduction)。reduction(string,可选):指定要应用于输出的reduction:none|mean|sum。none:不应用reduction,mean:输出的总和将除以输出中的元素数,sum:输出将被求和。默认为mean
计算公式:
reduction设置为none(默认是mean)的损失可以描述为:
l ( x , y ) = L = { l 1 , ⋯ , l N } , l n = ( x n − y n ) 2 \mathscr{l}(x,y)=L=\{l_1, \cdots ,l_N\}, \; \; \; l_n=(x_n-y_n)^2 l(x,y)=L={l1,⋯,lN},ln=(xn−yn)2
其中 N N N为批处理量。如果reduction不是none(默认是mean),那么:
l ( x , y ) = { m e a n ( L ) , if r e d u c t i o n = ’mean’ s u m ( L ) , if r e d u c t i o n = ’sum’ \mathscr{l}(x,y)=\begin{cases} mean(L), & \text{if $reduction$ = 'mean'} \\ sum(L), & \text{if $reduction$ = 'sum'} \end{cases} l(x,y)={mean(L),sum(L),if reduction = ’mean’if reduction = ’sum’
实例代码
loss = nn.MSELoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
output.backward()
2.3、负对数似然损失函数(NLLLoss)
2.3.1、似然
在解释负对数似然之前,首先要了解什么是似然。似然(likelihood)和概率(probability)有着一定的区别和联系。似然和概率是针对不同内容的估计和近似。概率表达了给定参数 θ \theta θ下样本随机向量 X = x X=x X=x的可能性,而似然表达了给定样本 X = x X=x X=x下参数 θ = θ 1 \theta=\theta_1 θ=θ1(相对于另外的参数取值 θ 2 \theta_2 θ2)为真实值的可能性。用一句话可以总结为:概率是已知参数,推数据。似然是已知数据,推参数。
2.3.2、似然函数
下面来看一下函数 P ( x ∣ θ ) P(x|\theta) P(x∣θ),输入有两个, x x x表示某一个具体的数据; θ \theta θ表示模型的参数:
-
如果 θ \theta θ是已知确定的, x x x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点,其出现的概率是多少。
-
如果 x x x是已知确定的, θ \theta θ是变量,这个函数叫做似然函数(likelihood function),他描述对于不同的模型参数,出现 x x x这个样本点的概率是多少。
2.3.3、极大似然估计
假设有训练集 D D D,令 D c D_c Dc表示训练集 D D D中第 c c c类样本组成的集合,假设这些样本是独立同分布的,则参数 θ c \theta_c θc对于数据集 D c D_c Dc的似然是
P ( D c ∣ θ c ) = ∏ x ∈ D c P ( x ∣ θ c ) P(D_c|\theta_c)=\prod_{x \in D_c}P(x|\theta_c) P(Dc∣θc)=x∈Dc∏P(x∣θc)
对 θ c \theta_c θc进行极大似然估计(Maximum likelihood estimation,MLE),就是去寻找能最大化似然 P ( D c ∣ θ c ) P(D_c|\theta_c) P(Dc∣θc)的参数值 θ c ^ \hat{\theta_c} θc^。直观上看,极大似然估计是试图在 θ c \theta_c θc所有可能的取值中,找到一个能使数据出现“可能性”最大的值。
2.3.4、对数似然
从公式可以看出,似然函数是很多个数相乘的形式。然而很多个数相乘并不容易计算容易造成下溢,一不方便求导,通常对其求对数。使用对数似然(log-likelihood),连乘就可以写成连加的形式:
L ( θ c ) = l o g P ( D c ∣ θ c ) = ∑ x ∈ D c l o g P ( x ∣ θ c ) L(\theta_c)=log \; P(D_c|\theta_c)=\sum_{x \in D_c}log \; P(x|\theta_c) L(θc)=logP(Dc∣θc)=x∈Dc∑logP(x∣θc)
2.3.5、负对数似然
对数似然是对概率分布求对数,概率 P ( x ) P(x) P(x)的值为 [ 0 , 1 ] [0,1] [0,1]区间,取对数后为 ( − ∞ , 0 ] (- \infty ,0] (−∞,0]区间。再在这个前面加个符号,变成 [ 0 , ∞ ] [0,\infty] [0,∞]区间,就得到了负对数似然(Negative log-likelihood, NLL):
L ( θ c ) = − ∑ x ∈ D c l o g P ( x ∣ θ c ) L(\theta_c)=-\sum_{x \in D_c}log \; P(x|\theta_c) L(θc)=−x∈Dc∑logP(x∣θc)
这样就得到了负对数似然函数,我们的目标是要选择合适的参数 θ \theta θ使得这个函数的数值最小。
看到有个博客举了一个关于硬币的例子来解释什么是最大似然估计,我在这个加加工一下看看负对数似然是怎么回事。假设有一个形状不规则的硬币,我们不知道它正面朝上的概率是多少,用 θ \theta θ表示,为模型的参数。想要求得这个模型参数 θ \theta θ是多少合适,就需要数据来进行估计。于是拿这枚硬币抛了10次,得到的数据为:“反正正正正反正正正反”。根据这个实验的结果我们就可以得到负对数似然函数为:
L ( θ ) = − ( l o g ( 1 − θ ) + l o g ( θ ) + l o g ( θ ) + l o g ( θ ) + l o g ( θ ) + l o g ( 1 − θ ) + l o g ( θ ) + l o g ( θ ) + l o g ( θ ) + l o g ( 1 − θ ) ) = − ( 3 l o g ( 1 − θ ) + 7 l o g ( θ ) ) L(\theta)=-(log(1-\theta)+log(\theta)+log(\theta)+log(\theta)+log(\theta)+log(1-\theta)\\+log(\theta)+log(\theta)+log(\theta)+log(1-\theta))=-(3log(1-\theta)+7log(\theta)) L(θ)=−(log(1−θ)+log(θ)+log(θ)+log(θ)+log(θ)+log(1−θ)+log(θ)+log(θ)+log(θ)+log(1−θ))=−(3log(1−θ)+7log(θ))
而我们的目标是使得负对数似然损失函数的值越小越好,我们可以画出损失函数的图像为:
import numpy as np
import matplotlib.pyplot as plt
theta=np.arange(0,1,0.01)
y=-(3*np.log(1-theta)+7*np.log(theta))
plt.plot(theta, y, label="NNLLoss")
plt.xlabel("theta")
plt.ylabel("Loss")
plt.legend()
plt.show()
D:\environment\Anaconda3\envs\pytorchGpuEnv\lib\site-packages\ipykernel_launcher.py:4: RuntimeWarning: divide by zero encountered in log
after removing the cwd from sys.path.

可以看出,在 θ = 0.7 \theta=0.7 θ=0.7时,负对数似然损失函数取得的值最小,至此就求出了是负对数似然损失函数最小的参数取值。(这里正面朝上的概率竟然为0.7,与我们的常识不符呀,有可能是因为抛的次数太少了,或者它确实就是个不规则的硬币哈哈哈,不过都不重要)。
2.3.6、pytorch中的应用
Pytorch中对应的负对数似然损失函数为:
torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean')
当网络的输出为每个类别的对数概率的时候才可以使用该损失函数,因此可以在网络的最后一层添加一个LogSoftmax层来获得对数概率。
如果不添加
LogSoftmax层,也可以直接使用CrossEntropyLoss损失函数。即CrossEntropyLoss=LogSoftmax+NLLLoss
这个损失所使用的标签应该是 [ 0 , C − 1 ] [0, C-1] [0,C−1]范围内的一个类索引,其中C=类的数量。因此不需要使用one-hot编码(使用one-hot编码会错,这个在下面的代码中进行验证)。
当reduction参数设置为none的时候,损失可以描述为:
l ( x , y ) = L = { l 1 , ⋯ , l N } T , l n = − w y n x n , y n w c = w e i g h t [ c ] ⋅ 1 { c ≠ i g n o r e _ i n d e x } \mathscr{l}(x,y)=L=\{l_1, \cdots ,l_N\}^T, \; \; \; l_n=-w_{y_n}x_{n,y_n}\;w_c=weight[c] \cdot1 \{c \neq ignore\_index\} l(x,y)=L={l1,⋯,lN}T,ln=−wynxn,ynwc=weight[c]⋅1{c=ignore_index}
其中, x x x是输入, y y y是目标, w w w是权重, N N N是批次大小。weight参数如果没有设置的话,默认为1。如果reduction不是none(默认是mean),那么:
l ( x , y ) = { ∑ n = 1 N 1 ∑ n = 1 N w w y n l n , if r e d u c t i o n = ’mean’ ∑ n = 1 N l n , if r e d u c t i o n = ’sum’ \mathscr{l}(x,y)=\begin{cases} \sum_{n=1}^N \frac{1}{\sum_{n=1}^N w_{w_{yn}}}l_n, & \text{if $reduction$ = 'mean'} \\ \sum_{n=1}^N l_n, & \text{if $reduction$ = 'sum'} \end{cases} l(x,y)={∑n=1N∑n=1Nwwyn1ln,∑n=1Nln,if reduction = ’mean’if reduction = ’sum’
下面用一段代码看看torch.nn.NLLLoss如何使用:
import torch
#就是求完softmax后对每一个数求log
logsoftmax=torch.nn.LogSoftmax(1)
lossFun=torch.nn.NLLLoss()
input=torch.rand(3,5,requires_grad=True)
print(input)
tensor([[0.7382, 0.7357, 0.1277, 0.5875, 0.4181],
[0.4176, 0.3701, 0.9907, 0.3997, 0.0968],
[0.7373, 0.5034, 0.9795, 0.5484, 0.1390]], requires_grad=True)
lsoftmax=logsoftmax(input)
lsoftmax
tensor([[-1.4175, -1.4200, -2.0280, -1.5682, -1.7376],
[-1.6929, -1.7404, -1.1198, -1.7108, -2.0137],
[-1.4913, -1.7252, -1.2492, -1.6803, -2.0897]],
grad_fn=)
#不使用one-hot编码
label=torch.tensor([1,0,4])
loss=lossFun(lsoftmax,label)
loss
tensor(1.7342, grad_fn=)
#测试使用one-hot编码
onehot_label=torch.tensor([[0.0,1.0,0.0,0.0,0.0],
[1.0,0.0,0.0,0.0,0.0],
[0.0,0.0,0.0,0.0,1.0]])
lossFun=torch.nn.NLLLoss()
loss=lossFun(lsoftmax,onehot_label)
loss
#RuntimeError: 0D or 1D target tensor expected, multi-target not supported
模型输出在经过LogSoftmax函数后,在经过负对数似然函数的计算过程为:
L o s s = − ( − 1.3110 − 1.4703 − 1.7949 ) / 3 = 1.5254 Loss=-(-1.3110-1.4703-1.7949)/3=1.5254 Loss=−(−1.3110−1.4703−1.7949)/3=1.5254
因此在pytorch中,nn.NLLLoss()函数虽然叫负对数似然函数,但是该函数并没有进行对数运算,而须在最后一层的激活函数上使用nn.LogSoftmax()函数,然后nn.NLLLoss()函数只是做了求和取平均再取反的运算。因此在分类问题中要使用nn.NLLLoss(),必须和nn.LogSoftmax()函数一起使用。当然也可以直接使用nn.CrossEntropyLoss()。
在使用nn.NLLLoss()时使用one-hot编码会报错,在使用nn.CrossEntropyLoss()的时候使用one-hot不会报错。
2.4、交叉熵损失函数(CrossEntropyLoss)
下面看一看交叉熵损失以及如何在Pytorch中使用它。
交叉熵主要是用来判定实际的输出与期望的输出的接近程度。要理解交叉熵,需要先理解以下几个概念。
2.4.1、信息量
信息是用来消除随机不确定性的东西,也就是说衡量信息量的大小就是看这个信息消除不确定性的程度。
“人会死”,这条信息没有减少不确定性,因为人肯定会死亡的,信息量为0。;“明天会下雨”,我们不知道明天到底会不会下雨,因此明天会下雨的不确定性因素很大,而这句话消除了明天会下雨的不确定性,多以按照定义,这句话的信息量很大。
综上所述:信息量的大小与信息发生的概率成反比。概率越大,信息量越小。概率越小,信息量越大。设某一事件发生的概率是 p ( x ) p(x) p(x),其信息量表示为:
I ( x ) = − l o g ( p ( x ) ) I(x)=-log(p(x)) I(x)=−log(p(x))
2.4.2、信息熵
信息熵也被成为熵,用来表示所有信息量的期望,即:
H ( X ) = − ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) H(X)=-\sum_{i=1}^np(x_i)log(p(x_i)) H(X)=−i=1∑np(xi)log(p(xi))
举一个例子,使用明天的天气概率来计算熵:
| 序号 | 事件 | 概率p | 信息量 |
|---|---|---|---|
| 1 | 晴天 | 0.5 | -log(0.5) |
| 2 | 雨天 | 0.2 | -log(0.2) |
| 3 | 多云 | 0.3 | -log(0.3) |
则熵为:
H ( X ) = − ( 0.5 ∗ l o g ( 0.5 ) + 0.2 ∗ l o g ( 0.2 ) + 0.3 ∗ l o g ( 0.3 ) ) H(X)=-(0.5*log(0.5)+0.2*log(0.2)+0.3*log(0.3)) H(X)=−(0.5∗log(0.5)+0.2∗log(0.2)+0.3∗log(0.3))
2.4.3、相对熵(KL散度)
如果对于同一个随机变量X有两个单独的概率分布 P ( X ) P(X) P(X)和 Q ( X ) Q(X) Q(X),其中 Q ( X ) Q(X) Q(X)表示模型所预测的分布, P ( X ) P(X) P(X)表示样本的真实分布。则KL散度用来衡量这两个概率分布之间的差异。计算公式为:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) q ( x i ) ) D_{KL}(p||q)=\sum_{i=1}^np(x_i)log(\frac{p(x_i)}{q(x_i)}) DKL(p∣∣q)=i=1∑np(xi)log(q(xi)p(xi))
KL散度越小,表示 P ( X ) P(X) P(X)与 Q ( X ) Q(X) Q(X)的分布更加接近,可以通过反复训练 Q ( X ) Q(X) Q(X)的分布逼近 P ( X ) P(X) P(X)。
2.4.4、交叉熵
将KL散度展开为:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) q ( x i ) ) = ∑ i = 1 n p ( x i ) l o g ( p ( x i ) ) − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) = − H ( p ( x ) ) + [ − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) ] D_{KL}(p||q)=\sum_{i=1}^np(x_i)log(\frac{p(x_i)}{q(x_i)})\\ =\sum_{i=1}^n p(x_i)log(p(x_i))-\sum_{i=1}^n p(x_i)log(q(x_i))\\=-H(p(x))+[-\sum_{i=1}^n p(x_i)log(q(x_i))] DKL(p∣∣q)=i=1∑np(xi)log(q(xi)p(xi))=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))=−H(p(x))+[−i=1∑np(xi)log(q(xi))]
其中 H ( p ( x ) ) H(p(x)) H(p(x))表示信息熵, − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) -\sum_{i=1}^n p(x_i)log(q(x_i)) −∑i=1np(xi)log(q(xi))代表交叉熵,则KL散度=交叉熵-信息熵
进而得到交叉熵的公式为:
H ( p , q ) = − ∑ i = 1 n p ( x i ) l o g ( q ( x i ) ) H(p,q)=-\sum_{i=1}^n p(x_i)log(q(x_i)) H(p,q)=−i=1∑np(xi)log(q(xi))
而在训练过程中,标签通常采用one-hot编码表示,而样本真实分布的概率 p ( x i ) p(x_i) p(xi)为1。那么就可以得到交叉熵简化后的公式为:
H ( p , q ) = − ∑ i = 1 n l o g ( q ( x i ) ) H(p,q)=-\sum_{i=1}^n log(q(x_i)) H(p,q)=−i=1∑nlog(q(xi))
这与上面推导的负对数似然损失函数是一样的哇!!!
2.4.5、pytorch中的应用
Pytorch中对应的交叉熵损失函数为:
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0)
CrossEntropyLoss()
计算公式为,当reduction设置为none时,表示为
l ( x , y ) = L = { l 1 , ⋯ , l N } T , l n = − ∑ c = 1 C w c l o g e x p ( x n , c ) ∑ i = 1 C e x p ( x n , i ) y n , c \mathscr{l}(x,y)=L=\{l_1, \cdots ,l_N\}^T, \; \; \; l_n=-\sum_{c=1}^C w_clog\frac{exp(x_{n,c})}{\sum_{i=1}^Cexp(x_{n,i})}y_{n,c} l(x,y)=L={l1,⋯,lN}T,ln=−c=1∑Cwclog∑i=1Cexp(xn,i)exp(xn,c)yn,c
如果reduction不是none(默认是mean),那么:
l ( x , y ) = { ∑ n = 1 N l n N , if r e d u c t i o n = ’mean’ ∑ n = 1 N l n , if r e d u c t i o n = ’sum’ \mathscr{l}(x,y)=\begin{cases} \frac{\sum_{n=1}^Nl_n}{N}, & \text{if $reduction$ = 'mean'} \\ \sum_{n=1}^N l_n, & \text{if $reduction$ = 'sum'} \end{cases} l(x,y)={N∑n=1Nln,∑n=1Nln,if reduction = ’mean’if reduction = ’sum’
在使用交叉熵损失函数的时,网络的最后一层不需要加softmax层,因为pytorch中的CrossEntropyLoss帮助我们实现了该操作,如果添加了softmax,那么就重复了,但效果并不会有什么影响。下面我们看一下交叉熵损失函数的计算过程,以及使用pytorch的实现过程。
根据交叉熵损失函数手动计算
首先假设batch_size为4,分类为3的网络最后一层的输出。
import torch
input=torch.rand(4,3)
input
tensor([[0.5953, 0.9872, 0.7510],
[0.9447, 0.0602, 0.7399],
[0.2185, 0.6771, 0.0168],
[0.7719, 0.8075, 0.7505]])
根据交叉熵损失函数,计算完softmax之后还需要计算每一个值的log数值,因此我们可以使用LogSoftmax函数来计算。
output=torch.nn.LogSoftmax(dim=1)(input)
output
tensor([[-1.2942, -0.9024, -1.1385],
[-0.8010, -1.6855, -1.0058],
[-1.2236, -0.7649, -1.4252],
[-1.1037, -1.0680, -1.1250]])
假设标签为:
[1,0,2,1]
[1, 0, 2, 1]
根据交叉熵的计算公式,最终的损失为:
l o s s = − ( − 0.7956 − 1.4796 − 1.4163 − 1.5762 ) / 4 = 1.3169 loss=-(-0.7956-1.4796-1.4163-1.5762)/4=1.3169 loss=−(−0.7956−1.4796−1.4163−1.5762)/4=1.3169
使用pytorch进行计算
#未使用one-hot编码
target = torch.tensor([1,0,2,1])
loss = torch.nn.CrossEntropyLoss()
output = loss(input, target)
output
tensor(1.0491)
上述为使用one-hot编码,下面试一下标签使用one-hot编码:
#未使用one-hot编码
target = torch.tensor([[0.0,1.0,0.0],
[1.0,0.0,0.0],
[0.0,0.0,1.0],
[0.0,1.0,0.0]])
loss = torch.nn.CrossEntropyLoss()
output = loss(input, target)
output
tensor(1.0491)
可见在使用交叉熵损失函数时,标签可以使用one-hot编码,也可以不使用one-hot编码。
2.4.6、使用总结
虽然负对数似然损失函数和交叉熵损失函数的公式一样,但是他们在pytorch中的使用有一定的差别,下面是对pytorch中的nn.NLLLoss()和nn.CrossEntropyLoss()的使用总结:
- 在使用
nn.NLLLoss()是,需要结合nn.LogSoftmax()一起使用,而nn.CrossEntropyLoss不需要。 - 使用
nn.CrossEntropyLoss时,网络的最后一层不需要加softmax层。 - 使用
nn.NLLLoss()是,标签不能使用one-hot编码标签,在使用nn.CrossEntropyLoss时,可以使用one-hot标签,也可以不使用one-hot标签。
2.5、二元交叉熵损失函数(BCELoss&BCEWithLogitsLoss)
BCELoss()是衡量目标和输入概率之间的二元交叉熵损失函数。该函数用来计算二项分布的交叉熵。在Pytorch中的形式为:
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
当reduction设置为none时,损失可以描述为:
l ( x , y ) = L = { l 1 , ⋯ , l N } T , l n = − w n [ y n ⋅ l o g x n + ( 1 − y n ) ⋅ l o g ( 1 − x n ) ] \mathscr{l}(x,y)=L=\{l_1, \cdots ,l_N\}^T, \; \; \; l_n = -w_n[y_n \cdot log \; x_n + (1-y_n)\cdot log(1-x_n)] l(x,y)=L={l1,⋯,lN}T,ln=−wn[yn⋅logxn+(1−yn)⋅log(1−xn)]
如果reduction不是none(默认是mean),那么:
l ( x , y ) = { m e a n ( L ) , if r e d u c t i o n = ’mean’ s u m ( L ) , if r e d u c t i o n = ’sum’ \mathscr{l}(x,y)=\begin{cases} mean(L), & \text{if $reduction$ = 'mean'} \\ sum(L), & \text{if $reduction$ = 'sum'} \end{cases} l(x,y)={mean(L),sum(L),if reduction = ’mean’if reduction = ’sum’
这用于测量例如自动编码器中的重建误差。注意,目标 y y y应该是0和1之间的数字。在使用时需要先试用sigmoid激活函数将模型的输出转为0和1之间的数据,然后再使用BCELoss函数计算损失。下面通过一段代码看看是如何使用pytorch进行计算的。
import torch.nn as nn
import torch
input = torch.tensor([-0.7001, -0.7231, -0.2049])
target = torch.tensor([0,0,1]).float()
m = nn.Sigmoid()
loss = nn.BCELoss()
output = loss(m(input), target)
output
tensor(0.5332)
分析是如何一步步进行计算的,首先它的输入是:
input = torch.tensor([-0.7001, -0.7231, -0.2049])
然后经过sigmoid得到的输出为:
output_mid = m(input)
output_mid
tensor([0.3318, 0.3267, 0.4490])
然后根据二元交叉熵损失函数的公式:
l o s s = − [ y ⋅ l o g x + ( 1 − y ) ⋅ l o g ( 1 − x ) ] loss=-[y\cdot log \; x +(1-y)\cdot log(1-x)] loss=−[y⋅logx+(1−y)⋅log(1−x)]
带入模型输出值和标签值得到损失:
l o s s = − [ 1 ∗ l o g ( 1 − 0.3318 ) + 1 ∗ l o g ( 1 − 0.3267 ) + 1 ∗ l o g ( 0.4490 ) ] / 3 = 0.5331 loss=-[1*log(1-0.3318)+1*log(1-0.3267)+1*log(0.4490)]/3=0.5331 loss=−[1∗log(1−0.3318)+1∗log(1−0.3267)+1∗log(0.4490)]/3=0.5331
可见计算的结果如使用BCELoss函数计算的结果一样。
但是在使用BCELoss函数的时候需要搭配sigmoid,函数一起使用,会有一点的麻烦。因此在pytorch中提供了BCEWithLogitsLoss函数,它将sigmoid和BCELoss组合到了一起。下面使用BCEWithLogitsLoss函数计算上面计算过的损失,看看损失的值是否一样。
input = torch.tensor([-0.7001, -0.7231, -0.2049])
target = torch.tensor([0,0,1]).float()
loss = nn.BCEWithLogitsLoss()
output = loss(input, target)
output
tensor(0.5332)
可见结果是一样的,因此可以使用BCEWithLogitsLoss代替sigmoid和BCELoss的组合。
2.7 使用整合
下面通过一个表格列出常见问题类型最后一层激活函数和损失函数的关系,仅供参考,还需要根据实际需求进行选择。
| 问题类型 | 最后一层激活函数 | 损失函数 |
|---|---|---|
| 二分类,单标签 | 添加sigmoid层 | nn.BCELoss |
| 不添加sigmoid层 | nn.BCEWithLogitsLoss | |
| 二分类,多标签 | 无 | nn.SoftMarginLoss |
| 多分类,单标签 | 不添加softmax层 | nn.CrossEntropyLoss |
| 添加LogSoftmax层 | nn.NLLLoss | |
| 多分类,多标签 | 无 | nn.MultiLabelSoftMarginLoss |
| 回归 | 无 | nn.MSELoss |
3、优化器(Optimizer)
优化器在机器学习、深度学习中往往起着举足轻重的作用,同一个模型,因选择不同的优化器,性能有可能相差很大,甚至导致一些模型无法训练。所以了解各种优化器的基本原理非常重要。下面介绍各种常用优化器或算法的主要原理,及各自的优点或不足。
3.1、传统梯度优化的不足(BGD,SGD,MBGD)
BGD、SGD、MBGD分别为批量梯度下降算法、随机梯度下降算法、小批量梯度下降算法。BGD在训练的时候选用所有的训练集进行计算,SGD在训练的时候只选择一个数据进行训练,而MBGD在训练的时候只选择小部分数据进行训练。这三个优化算法在训练的时候虽然所采用的的数据量不同,但是他们在进行参数优化的时候是相同的。
在训练的时候一般都是使用小批量梯度下降算法,即选择部分数据进行训练,在此把这三种算法统称为传统梯度更新算法,因为他们在更新参数的时候采用相同的方式,而更优的优化算法从梯度方向和学习率方面对参数更新方式进行优化。
传统梯度更新算法为最常见、最简单的一种参数更新策略。其基本思想是:先设定一个学习率 λ \lambda λ,参数沿梯度的反方向移动。假设需要更新的参数为 θ \theta θ,梯度为 g g g,则其更新策略可表示为:
θ ← θ − λ g \theta \leftarrow \theta-\lambda g θ←θ−λg
这种梯度更新算法简洁,当学习率取值恰当时,可以收敛到全面最优点(凸函数)或局部最优点(非凸函数)。但其还有很大的不足点:
- 对超参数学习率比较敏感(过小导致收敛速度过慢,过大又越过极值点)。
- 学习率除了敏感,有时还会因其在迭代过程中保持不变,很容易造成算法被卡在鞍点的位置。
- 在较平坦的区域,由于梯度接近于0,优化算法会因误判,在还未到达极值点时,就提前结束迭代,陷入局部极小值。
3.1.1 一维梯度下降
下面展示如何实现梯度下降以及上述这些不足点。为了简单,选用目标函数 f ( x ) = x 2 f(x)=x^2 f(x)=x2。尽管我们知道 x = 0 x=0 x=0时 f ( x ) f(x) f(x)能取得最小值(这里x为模型参数)。
import numpy as np
import torch
from d2l import torch as d2l
%matplotlib inline
#目标函数
def f(x):
return x**2
#目标函数的梯度(导数)
def f_grad(x):
return 2*x
接下来,使用 x = 10 x=10 x=10作为初始值,并假设 η = 0.2 \eta=0.2 η=0.2。使用梯度下降迭代法迭代 x x x共10次,可以看到 x x x的值最终将接近最优解。
#进行梯度下降
def gd(eta,f_grad):
x=10.0
results=[x]
for i in range(10):
x-=eta*f_grad(x)
results.append(float(x))
print(f'epoch 10,x:{x:f}')
return results
results = gd(0.2,f_grad)
epoch 10,x:0.060466
对 x x x优化的过程进行可视化。
def show_trace(results,f):
n=max(abs(min(results)),abs(max(results)))
f_line=torch.arange(-n,n,0.01)
d2l.set_figsize()
d2l.plot([f_line,results],[[f(x) for x in f_line],[f(x) for x in results]],'x','f(x)',fmts=['-','-o'])
show_trace(results,f)

学习率
学习率决定了目标函数是否能够收敛到局部最小值,以及何时收敛到最小值。学习率 η \eta η可由算法设计者设置。请注意,如果使用的学习率太小,将导致 x x x的更新非常缓慢,需要更多的迭代。下面将学习率设置为0.05。如下图所示,尽管经历了10个步骤,我们仍然离最优解很远。
show_trace(gd(0.05,f_grad),f)
epoch 10,x:3.486784

相反,当使用过高的学习率, x x x的迭代不能保证降低 f ( x ) f(x) f(x)的值,例如,当学习率为 η = 1.1 \eta=1.1 η=1.1时, x x x超出了最优解 x = 0 x=0 x=0并逐渐发散。
show_trace(gd(1.1,f_grad),f)
epoch 10,x:61.917364

局部极小值
为了演示非凸函数的梯度下降,考虑函数 f ( x ) = x ⋅ c o s ( x ) f(x)=x\cdot cos(x) f(x)=x⋅cos(x),其中 c c c为某常数。这个函数有无穷多个最小值。如果学习率选择不当,我们最终只会得到一个最优解。下面的例子说明了高学习率如何导致较差的局部最小值。
f ′ ( x ) = c o s ( c x ) − c ∗ x ∗ s i n ( c x ) f^{'}(x)=cos(cx)-c*x*sin(cx) f′(x)=cos(cx)−c∗x∗sin(cx)
c=torch.tensor(0.15*np.pi)
#目标函数
def f(x):
return x*torch.cos(c*x)
#目标函数的梯度
def f_grad(x):
return torch.cos(c*x)-c*x*torch.sin(c*x)
show_trace(gd(2,f_grad),f)
epoch 10,x:-1.528166

3.1.2 多维梯度下降
在对单元梯度下降有了了解之后,下面看看多元梯度下降,即考虑 x = [ x 1 , x 2 , ⋯ , x d ] T x=[x_1,x_2,\cdots ,x_d]^T x=[x1,x2,⋯,xd]T的情况。相应的它的梯度也是多元的,是一个由d个偏导数组成的向量:
∇ f ( x ) = [ ∂ f x ∂ x 1 , ∂ f x ∂ x 2 , ⋯ , ∂ f x ∂ x d ] T \nabla f(x)=[\frac{\partial f{x}}{\partial x_1},\frac{\partial f{x}}{\partial x_2},\cdots,\frac{\partial f{x}}{\partial x_d}]^T ∇f(x)=[∂x1∂fx,∂x2∂fx,⋯,∂xd∂fx]T
然后选择合适的学率进行梯度下降:
x ← x − η ∇ f ( x ) x \leftarrow x-\eta \nabla f(x) x←x−η∇f(x)
下面通过代码可视化它的参数更新过程。构造一个目标函数 f ( x ) = x 1 2 + 2 x 2 2 f(x)=x_1^2+2x_2^2 f(x)=x12+2x22,并有二维向量 x = [ x 1 , x 2 ] x=[x_1,x_2] x=[x1,x2]作为输入,标量作为输出。梯度由 ∇ f ( x ) = [ 2 x 1 , 4 x 2 ] T \nabla f(x)=[2x_1,4x_2]^T ∇f(x)=[2x1,4x2]T给出。从初始位置[-5,-2]通过梯度下降观察x的轨迹。
首先需要定义两个辅助函数第一个是train_2d()函数,用指定的训练机优化2D目标函数;第二个是show_trace_2d(),用于显示x的轨迹。
#用指定的训练机优化2D目标函数
def train_2d(trainer,steps=20,f_grad=None):
x1,x2,s1,s2=-5,-2,0,0
results=[(x1,x2)]
for i in range(steps):
if f_grad:
x1,x2,s1,s2=trainer(x1,x2,s1,s2,f_grad)
else:
x1,x2,s1,s2=trainer(x1,x2,s1,s2)
results.append((x1,x2))
print(f'epoch{i+1},x1:{float(x1):f},x2:{float(x2):f}')
return results
#显示优化过程中2D变量的轨迹
def show_trace_2d(f,results):
d2l.set_figsize()
d2l.plt.plot(*zip(*results),'-o',color='#ff7f0e')
x1,x2=torch.meshgrid(torch.arange(-5.5,1.0,0.1),
torch.arange(-3.0,1.0,0.1))
d2l.plt.contour(x1,x2,f(x1,x2),colors='#1f77b4')
d2l.plt.xlabel('x1')
d2l.plt.ylabel('x2')
接下来,使用学习率为 η = 0.1 \eta=0.1 η=0.1时优化变量 x x x的轨迹。在经过20步时, x x x的值接近其位于[0,0]的最小值。
#目标函数
def f_2d(x1,x2):
return x1**2+2*x2**2
#目标函数的梯度
def f_2d_grad(x1,x2):
return (2*x1,4*x2)
#SGD更新参数
def gd_2d(x1,x2,s1,s2,f_grad):
g1,g2=f_grad(x1,x2)
return (x1-eta*g1,x2-eta*g2,0,0)
eta=0.1
show_trace_2d(f_2d,train_2d(gd_2d,f_grad=f_2d_grad))
epoch20,x1:-0.057646,x2:-0.000073
D:\environment\Anaconda3\envs\pytorchGpuEnv\lib\site-packages\torch\functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ..\aten\src\ATen\native\TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]

针对传统梯度优化算法的缺点,许多优化算法从梯度方向和学习率两方面入手。有些从梯度方向入手,如动量更新策略;而有些从学习率入手,这涉及调参问题;还有从两方面同时入手,如自适应更新策略。
在pytorch中使用传统的梯度下降算法可以使用torch.optim.SGD其格式为:
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False, *, maximize=False)
因为使用的是传统的梯度下降算法,则momentum参数和nesterov参数默认即可不需要设置。下面看一看它的用法。
import torch
#改代码不可运行
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
#梯度清零
optimizer.zero_grad()
loss_fn(model(input), target).backward()
#参数更新
optimizer.step()
3.2、动量(Momentum)
动量(Momentum)是模拟物理中动量的概念,具有物理上惯性的含义,一个物体在运动时具有惯性,把这个思想运用到梯度下降的计算中,可以增加算法的收敛速度和稳定性,具体实现如图所示:
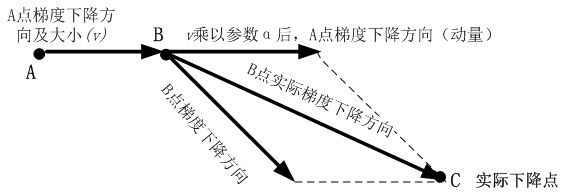
动量算法每下降一步都是由前面下降方向的一个累积和当前点梯度方向组合而成。含动量的随机梯度下降算法,其更新方式如下:
更 新 梯 度 : g ^ ← 1 b a t c h _ s i z e ∑ i = 0 b a t c h _ s i z e ∇ θ L ( f ( x ( i ) ) , y ( i ) ) 计 算 梯 度 : v ← β v + g 更 新 参 数 : θ ← θ − η v 更新梯度:\hat{g} \leftarrow \frac{1}{batch\_size} \sum_{i=0}^{batch\_size}\nabla_{\theta}L(f(x^{(i)}),y^{(i)})\\ 计算梯度:v \leftarrow \beta v+g\\ 更新参数:\theta \leftarrow \theta-\eta v 更新梯度:g^←batch_size1i=0∑batch_size∇θL(f(x(i)),y(i))计算梯度:v←βv+g更新参数:θ←θ−ηv
其中 β \beta β为动量参数, η \eta η为学习率。
为了更好的观察动量带来的好处,使用一个新函数 f ( x ) = 0.1 x 1 2 + 2 x 2 2 f(x)=0.1x_1^2+2x_2^2 f(x)=0.1x12+2x22上使用不带动量的传统梯度下降算法观察下降过程。与上节的函数一样,f的最低水平为(0,0)。该函数在 x 1 x_1 x1方向上比较平坦,在此选择0.4的学习率。
import torch
from d2l import torch as d2l
%matplotlib inline
eta=0.4
#目标函数
def f_2d(x1,x2):
return 0.1*x1**2+2*x2**2
#sgd更新参数
def gd_2d(x1,x2,s1,s2):
return (x1-eta*0.2*x1,x2-eta*4*x2,0,0)
d2l.show_trace_2d(f_2d,d2l.train_2d(gd_2d))
epoch 20, x1: -0.943467, x2: -0.000073

从结果来看, x 2 x_2 x2方向的梯度比水平 x 1 x_1 x1方向的渐变高得多,变化快得多。因此就陷入了两个不可取的选择:如果选择较小的准确率。可以确保不会朝 x 2 x_2 x2方向发生偏离,但在 x 1 x_1 x1反向收敛会缓慢。如果学习率较高, x 1 x_1 x1方向会收敛很快,但在 x 2 x_2 x2方向就不会向最优点靠近。下面将学习率从0.4调整到0.6。可以看出在 x 1 x_1 x1方向会有所改善,但是整体解决方案会很差。
eta=0.6
d2l.show_trace_2d(f_2d,d2l.train_2d(gd_2d))
epoch 20, x1: -0.387814, x2: -1673.365109

下面看一下使用动量算法在实践中的应用。
#动量法更新参数
def momentum_2d(x1,x2,v1,v2):
v1=beta*v1+0.2*x1
v2=beta*v2+4*x2
return x1-eta*v1,x2-eta*v2,v1,v2
eta,beta=0.6,0.5
d2l.show_trace_2d(f_2d,d2l.train_2d(momentum_2d))
epoch 20, x1: 0.007188, x2: 0.002553

可见使用和之前一样的学习率,也能够很好的收敛,下面看看当降低动量参数时会发生啥。虽然将其减半到 β = 0.25 \beta=0.25 β=0.25会导致一条几乎没有收敛的轨迹。但是也要比没有动力好很多。
eta,beta=0.6,0.25
d2l.show_trace_2d(f_2d,d2l.train_2d(momentum_2d))
epoch 20, x1: -0.126340, x2: -0.186632

既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,因此可以按照前面一小步位置的“超前梯度”来做梯度合并。这样就可以先往前走一小步,在靠前一点的位置看到梯度,然后按照那个位置再来修正这一步的梯度方向,如下图所示。这样就得到动量算法的一种改进算法,称为Nesterov Accelerated Gradient,简称NAG算法。这种更新的算法能够防止大幅振荡,不会错过最小值,并会对参数更加敏感。

下面看看在pytorch中的使用:
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False, *, maximize=False)
因为使用了动量,因此参数momentum就需要给定数值,nesterov设置为True时,将会使用NAG算法,它是动量算法的一种优化。
3.3、AdaGrad算法
AdaGrad算法是通过参数来调整合适的学习率,是能独立自动调整模型参数的学习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新,因此,AdaGrad方法非常适合处理稀疏数据。AdaGrad算法在某些深度学习模型上效果不错。但还是有些不足,可能是因其累积梯度平方导致学习率过早或过量的减少所致。以下是AdaGrad算法的更新步骤:
更 新 梯 度 : g ^ ← 1 b a t c h _ s i z e ∑ i = 0 b a t c h _ s i z e ∇ θ L ( f ( x ( i ) ) , y ( i ) ) 累 积 平 方 梯 度 : r ← r + g ^ ⊙ g ^ 计 算 参 数 : △ θ ← − λ δ + r ⊙ g ^ 更 新 参 数 : θ ← θ + △ θ 更新梯度:\hat{g} \leftarrow \frac{1}{batch\_size} \sum_{i=0}^{batch\_size}\nabla_{\theta}L(f(x^{(i)}),y^{(i)})\\ 累积平方梯度:r \leftarrow r+\hat{g} \odot \hat{g}\\ 计算参数:\triangle \theta \leftarrow - \frac{\lambda}{\delta+\sqrt{r}}\odot \hat{g}\\ 更新参数:\theta \leftarrow \theta+\triangle \theta 更新梯度:g^←batch_size1i=0∑batch_size∇θL(f(x(i)),y(i))累积平方梯度:r←r+g^⊙g^计算参数:△θ←−δ+rλ⊙g^更新参数:θ←θ+△θ
其中 r r r为累积梯度变量,初始为0; λ \lambda λ为学习率; δ \delta δ为小参数,避免分母为0。
通过上述更新步骤可以看出:
- 随着迭代时间越长,累积梯度 r r r越大,导致学习速率 λ δ + r \frac{\lambda}{\delta+\sqrt{r}} δ+rλ随着时间较小,在接近目标值时,不会因为学习率过大而越过极值点。
- 不同参数之间的学习速率不同,因此,与之前固定学习率相比,不容易卡在鞍点。
- 如果梯度累积参数 r r r比较小,则速率会比较大,所以参数迭代的步长就会比较大。相反,如果梯度累积参数 r r r比较大,则速率会比较小,所以参数迭代的步长就会比较小。
下面使用和以前相同的问题:
f ( x ) = 0.1 x 1 2 + 2 x 2 2 f(x)=0.1x_1^2+2x_2^2 f(x)=0.1x12+2x22
将使用与之前相同的学习率来实施AdaGrad,即 η = 0.4 \eta=0.4 η=0.4。
import math
import torch
from d2l import torch as d2l
%matplotlib inline
#adagrad更新参数
def adagrad_2d(x1,x2,s1,s2):
eps=1e-6
g1,g2=0.2*x1,4*x2
s1+=g1**2
s2+=g2**2
x1-=eta/math.sqrt(s1+eps)*g1
x2-=eta/math.sqrt(s2+eps)*g2
return x1,x2,s1,s2
#目标函数
def f_2d(x1,x2):
return 0.1*x1**2+2*x2**2
eta=0.4
d2l.show_trace_2d(f_2d,d2l.train_2d(adagrad_2d))
epoch 20, x1: -2.382563, x2: -0.158591

由结果来看,参数更新的过程变得平稳,但是由于梯度累积的越来越大,学习率持续下降,因此参数在后期阶段移动的不会那么多。现在我们适当的提高学习率到2,看看结果怎么样。
eta=2
d2l.show_trace_2d(f_2d,d2l.train_2d(adagrad_2d))
epoch 20, x1: -0.002295, x2: -0.000000

可以看出,在越接近最优点附近,学习率越来越小,参数更新变得更慢,以至于不会错过最优点的位置。
下面看看在Pytorch中如何使用AdaGrad优化算法,在Pytorch中的格式为:
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
各个参数的功能为:
params– 要优化的参数。lr(float, optional) – 学习率 (默认: 1e-2)lr_decay(float, optional) – 学习率衰减 (默认: 0)weight_decay(float, optional) – 权重衰减 (L2 penalty) (默认: 0)eps(float, optional) – 为提高数字稳定性,在分母上添加了该项 (默认: 1e-10)
3.4、RMSProp算法
RMSProp算法通过修改AdaGrad得来,其目的是在非凸背景下效果更好。针对梯度平方和累计越来越大的问题,RMSProp指数加权的移动平均代替梯度平方和。RMSProp为了使用移动平均,还引入了一个新的超参数 ρ \rho ρ,用来控制移动平均的长度范围。以下是RMSProp算法的更新步骤:
更 新 梯 度 : g ^ ← 1 b a t c h _ s i z e ∑ i = 0 b a t c h _ s i z e ∇ θ L ( f ( x ( i ) ) , y ( i ) ) 累 积 平 方 梯 度 : r ← ρ r + ( 1 − ρ ) g ^ ⊙ g ^ 计 算 参 数 更 新 : △ θ ← − λ δ + r ⊙ g ^ 更 新 参 数 : θ ← θ + △ θ 更新梯度:\hat{g} \leftarrow \frac{1}{batch\_size} \sum_{i=0}^{batch\_size}\nabla_{\theta}L(f(x^{(i)}),y^{(i)})\\ 累积平方梯度:r \leftarrow \rho r+ (1- \rho) \hat{g} \odot \hat{g}\\ 计算参数更新:\triangle \theta \leftarrow - \frac{\lambda}{\delta+\sqrt{r}}\odot \hat{g}\\ 更新参数:\theta \leftarrow \theta+\triangle \theta 更新梯度:g^←batch_size1i=0∑batch_size∇θL(f(x(i)),y(i))累积平方梯度:r←ρr+(1−ρ)g^⊙g^计算参数更新:△θ←−δ+rλ⊙g^更新参数:θ←θ+△θ
RMSProp算法在实践中已被证明是一种有效且实用的深度神经网络优化算法,因而在深度学习中得到了广泛应用。
和之前一样,使用二次函数 f ( x ) = 0.1 x 1 2 + 2 x 2 2 f(x)=0.1x_1^2+2x_2^2 f(x)=0.1x12+2x22来观察RMSProp的轨迹。在使用学习率为0.4的AdaGrad的时候,参数在算法的后期阶段移动的越来越慢,因为学习率下降太快。由于 η \eta η是单独控制的,RMSProp不会发生这种情况。
import math
from d2l import torch as d2l
#rmsprop更新参数
def rmsprop_2d(x1,x2,s1,s2):
g1,g2,eps=0.2*x1,4*x2,1e-6
s1=gamma*s1+(1-gamma)*g1**2
s2=gamma*s2+(1-gamma)*g2**2
x1-=eta/math.sqrt(s1+eps)*g1
x2-=eta/math.sqrt(s2+eps)*g2
return x1,x2,s1,s2
#目标函数
def f_2d(x1,x2):
return 0.1*x1**2+2*x2**2
eta,gamma=0.4,0.9
d2l.show_trace_2d(f_2d,d2l.train_2d(rmsprop_2d))
epoch 20, x1: -0.010599, x2: 0.000000

在pytorch中,RMSProp算法的格式为:
torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
alpha为平滑常数,momentum为动量。
3.5、Adam算法
Adam本质上是带有动量项的RMSProp,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使参数比较稳定。
Adam是一种学习速率自适应的深度神经网络方法,他利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam算法的更新步骤如下:
t ← t + 1 计 算 梯 度 : g t ← ∇ θ f t ( θ t − 1 ) 更 新 有 偏 一 阶 矩 估 计 : m t ← β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t 更 新 有 偏 二 阶 矩 估 计 : v t ← β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ g t 2 计 算 偏 差 校 正 的 一 阶 矩 估 计 : m t ^ ← m t 1 − β 1 t 计 算 偏 差 校 正 的 二 阶 矩 估 计 : v t ^ ← v t 1 − β 2 t 更 新 参 数 : θ t ← θ t − 1 − α ⋅ m t ^ ϵ + v t ^ t \leftarrow t+1\\ 计算梯度:g_t \leftarrow \nabla_{\theta} f_t(\theta_{t-1})\\ 更新有偏一阶矩估计:m_t \leftarrow \beta_1 \cdot m_{t-1} + (1-\beta_1)\cdot g_t\\ 更新有偏二阶矩估计:v_t \leftarrow \beta_2 \cdot v_{t-1} + (1-\beta_2)\cdot g_t^2\\ 计算偏差校正的一阶矩估计:\hat{m_t} \leftarrow \frac{m_t}{1-\beta_1^t}\\ 计算偏差校正的二阶矩估计:\hat{v_t} \leftarrow \frac{v_t}{1-\beta_2^t}\\ 更新参数:\theta_t \leftarrow \theta_{t-1}-\alpha \cdot \frac{\hat{m_t}}{\epsilon+\sqrt{\hat{v_t}}} t←t+1计算梯度:gt←∇θft(θt−1)更新有偏一阶矩估计:mt←β1⋅mt−1+(1−β1)⋅gt更新有偏二阶矩估计:vt←β2⋅vt−1+(1−β2)⋅gt2计算偏差校正的一阶矩估计:mt^←1−β1tmt计算偏差校正的二阶矩估计:vt^←1−β2tvt更新参数:θt←θt−1−α⋅ϵ+vt^mt^
下面看看每个步骤的含义是:
首先,计算梯度的指数移动平均数, m 0 m_0 m0初始化为0。类似于Momentum算法,综合考虑之前时间步的梯度动量。 β 1 \beta_1 β1系数为指数衰减率,控制权重分配(动量与当前梯度),通常取接近于1的值。默认为0.9
m t ← β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t m_t \leftarrow \beta_1 \cdot m_{t-1} + (1-\beta_1)\cdot g_t mt←β1⋅mt−1+(1−β1)⋅gt
其次,计算梯度平方的指数移动平均数, v 0 v_0 v0初始化为0。 β 2 \beta_2 β2系数为指数衰减率,控制之前的梯度平方的影响情况。类似于RMSProp算法,对梯度平方进行加权均值。默认为0.999
v t ← β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ g t 2 v_t \leftarrow \beta_2 \cdot v_{t-1} + (1-\beta_2)\cdot g_t^2 vt←β2⋅vt−1+(1−β2)⋅gt2
第三,由于 m 0 m_0 m0初始化为0,会导致 m t m_t mt偏向于0,尤其在训练初期阶段。所以,此处需要对梯度均值 m t m_t mt进行偏差纠正,降低偏差对训练初期的影响。
m t ^ ← m t 1 − β 1 t \hat{m_t} \leftarrow \frac{m_t}{1-\beta_1^t} mt^←1−β1tmt
第四,与 m 0 m_0 m0类似,因为 v 0 v_0 v0初始化为0导致训练初始阶段 v t v_t vt偏向0,对其进行纠正。
v t ^ ← v t 1 − β 2 t \hat{v_t} \leftarrow \frac{v_t}{1-\beta_2^t} vt^←1−β2tvt
最后,更新参数,初始的学习率 α \alpha α乘以梯度均值与梯度方差的平方根之比。其中默认学习率 α = 0.001 \alpha=0.001 α=0.001, ϵ = 1 0 − 8 \epsilon=10^{-8} ϵ=10−8,避免除数变为0。由表达式可以看出,对更新的步长计算,能够从梯度均值及梯度平方两个角度进行自适应地调节,而不是直接由当前梯度决定。
θ t ← θ t − 1 − α ⋅ m t ^ ϵ + v t ^ \theta_t \leftarrow \theta_{t-1}-\alpha \cdot \frac{\hat{m_t}}{\epsilon+\sqrt{\hat{v_t}}} θt←θt−1−α⋅ϵ+vt^mt^
Adam主要包含以下几个显著的优点:
- 实现简单,计算高效,对内存需求少
- 参数的更新不受梯度的伸缩变换影响
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调
- 更新的步长能够被限制在大致的范围内(初始学习率)
- 能自然地实现步长退火过程(自动调整学习率)
- 很适合应用于大规模的数据及参数的场景
- 适用于不稳定目标函数
- 适用于梯度稀疏或梯度存在很大噪声的问题
和之前一样,使用二次函数 ()=0.121+222 来观察Adam的轨迹。使用学习率为0.16的AdaGrad并迭代50次。
import math
from d2l import torch as d2l
%matplotlib inline
#针对Adam改造原来的优化目标函数
def train_2d_adam(trainer,steps=20,f_grad=None):
x1,x2,m1,m2,v1,v2=-5,-2,0,0,0,0
results=[(x1,x2)]
for i in range(steps):
x1,x2,m1,m2,v1,v2=trainer(x1,x2,m1,m2,v1,v2)
results.append((x1,x2))
print(f'epoch{i+1},x1:{float(x1):f},x2:{float(x2):f}')
return results
#Adam更新参数过程
def rmsprop_2d(x1,x2,m1,m2,v1,v2):
g1,g2,eps=0.2*x1,4*x2,1e-8
m1=beta1*m1+(1-beta1)*g1
m2=beta1*m2+(1-beta1)*g2
v1=beta2*v1+(1-beta2)*g1**2
v2=beta2*v2+(1-beta2)*g2**2
m_hat_1=m1/(1-beta1)
m_hat_2=m2/(1-beta1)
v_hat_1=v1/(1-beta2)
v_hat_2=v2/(1-beta2)
x1-=alpha*(m_hat_1/(eps+math.sqrt(v_hat_1)))
x2-=alpha*(m_hat_2/(eps+math.sqrt(v_hat_2)))
return x1,x2,m1,m2,v1,v2
#目标函数
def f_2d(x1,x2):
return 0.1*x1**2+2*x2**2
alpha,beta1,beta2=0.16,0.9,0.999
d2l.show_trace_2d(f_2d,train_2d_adam(rmsprop_2d))
epoch20,x1:0.131652,x2:0.447787

在pytorch中Adam的使用格式为
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False, *, maximize=False)
参数betas为 β 1 \beta_1 β1和 β 2 \beta_2 β2的集合,分别控制权重分配和之前的梯度平方的影响情况。
4、过拟合和欠拟合
对模型进行评估和优化的过程往往是循环往复的。在训练模型的过程中,经常会出现刚开始训练时,训练和测试精度不高,这时的模型时欠拟合,然后通过增加迭代次数或者通过优化,训练精度和测试精度继续提升。但随着训练迭代次数的增加或不断优化,有可能会出现训练精度和损失值继续改善,但测试精度或损失值不降反而上升的情况,如下图所示,这就是出现了过拟合,这时的模型开始学习仅和训练数据有关的模式,但是这种模式对新数据来说是错误或无关紧要的。

为了防止模型从训练数据中学到错误或无关紧要的模式,最优的解决方法是获取更多的训练数据。模型训练的训练数据越多,泛化能力自然也越好。如果无法获取更多的数据,次优的解决方法是调节模型允许存储的信息量,或对模型允许存储的信息加以约束。如果一个网络只能记住几个模式,那么优化过程会迫使模型集中学习最重要的模式,这样更可能得到良好的泛化。这种降低过拟合的方法叫做正则化。
4.1、权重正则化
4.1.1、简介
给定一些训练数据和一种网络结构,很多组权重值(即很多模型)都可以解释这些数据。简单的模型比复杂模型更不容易过拟合。这些简单模型是指参数分布的熵更小的模型(或参数更少的模型)。因此一种常见的降低过拟合的方法就是强制让模型的权重只能取较小的值,从而限制模型的复杂度,这使得权重值的分布更规则。
这种方法叫作权重正则化,其实现方法是向网络损失函数中添加与较大权重值相关的成本。这个成本有两种形式:
- L1正则化(L1 regularization):添加的成本与权重系数的绝对值(权重的L1范数)成正比。
- L2正则化(L2 regularization):添加的成本与权重系数的平方(权重的L2范数)成正比。神经网络的L2正则化也叫权重衰减(weight decay)。
下面详细介绍和使用 L 2 L_2 L2范数正则化。 L 2 L_2 L2范数正则化在模型原损失函数基础上添加 L 2 L_2 L2范数惩罚项,从而得到训练所需要最小化的函数。 L 2 L_2 L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。以线性回归损失函数为例:
L ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w T x ( i ) + b − y ( i ) ) 2 L(w, b) = \frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(w^Tx^{(i)} + b - y^{(i)}\right)^2 L(w,b)=n1i=1∑n21(wTx(i)+b−y(i))2
其中 w w w是权重参数, b b b是偏差参数,样本 i i i的输入为 x ( i ) x^{(i)} x(i),标签为 y ( i ) y^{(i)} y(i),样本数为 n n n。带有 L 2 L_2 L2范数惩罚项的新损失函数为:
L ( w , b ) + λ 2 ∥ w ∥ 2 L(w, b) + \frac{\lambda}{2} \|\boldsymbol{w}\|^2 L(w,b)+2λ∥w∥2
其中超参数 λ > 0 \lambda > 0 λ>0。当权重参数均为0时,惩罚项最小。当 λ \lambda λ较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当 λ \lambda λ设为0时,惩罚项完全不起作用。有了 L 2 L_2 L2范数惩罚项后,在小批量随机梯度下降中,我们将线性回归一节中权重 w w w和的迭代方式更改为:
w ← ( 1 − η λ ) w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( x ( i ) w T + b − y ( i ) ) , \begin{aligned} w &\leftarrow \left(1- {\eta\lambda} \right)w - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x^{(i)} \left(x^{(i)} w^T + b - y^{(i)}\right),\\ \end{aligned} w←(1−ηλ)w−∣B∣ηi∈B∑x(i)(x(i)wT+b−y(i)),
可见, L 2 L_2 L2范数正则化令权重 w w w和先自乘小于1的数,再减去不含惩罚项的梯度。因此, L 2 L_2 L2范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,我们有时也在惩罚项中添加偏差元素的平方和。
4.1.2、从零开始实现
下面,以高维线性回归为例引入一个过拟合问题,并使用权重衰减来应对过拟合,首先导入所使用的相关包。
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
生成数据,生成数据的公式为:
y = 0.05 + ∑ i = 1 d 0.01 x i + ϵ y = 0.05 + \sum_{i = 1}^d 0.01x_i + \epsilon y=0.05+i=1∑d0.01xi+ϵ
选择标签是关于输入的线性函数。 标签同时被均值为0,标准差为0.01高斯噪声破坏。 为了使过拟合的效果更加明显,我们可以将问题的维数增加到 d=200 , 并使用一个只包含20个样本的小训练集。
#生成y=Xw+b+噪声
def synthetic_data(w,b,num_example):
X=torch.normal(0,1,(num_example,len(w)))
y=torch.matmul(X,w)+b
y+=torch.normal(0,0.01,y.shape)
return X,y.reshape((-1,1))
#构造一个Pytorch数据迭代器
def load_array(data_arrays,batch_size,is_train=True):
dataset=data.TensorDataset(*data_arrays)
return
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
#生成训练数据
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
#生成测试数据
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
下面我们将从头开始实现权重衰减,只需将 L 2 L_2 L2范数惩罚项添加到原始目标函数中。
首先,我们将定义一个函数来随机初始化模型参数。
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
定义 L 2 L_2 L2范数惩罚项。这里只乘法模型的权重参数。实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估。
#定义模型、损失函数和优化方法
def linreg(X,w,b):
#线性回归模型
return torch.matmul(X,w)+b
def squared_loss(y_hat,y):
#均方损失
return (y_hat-y.reshape(y_hat.shape))**2/2
def sgd(params,lr,batch_size):
#小批量随机梯度下降
with torch.no_grad():
for param in params:
param-=lr*param.grad/batch_size
param.grad.zero_()
#开始训练,lambd为0是没有添加权重衰减
def train(lambd):
w, b = init_params()
#linreg和squared_loss和sgd在之前进行定义
#
net, loss = lambda X: linreg(X, w, b), squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
我们现在用lambd = 0禁用权重衰减后运行这个代码。 注意,这里训练误差有了减少,但测试误差没有减少, 这意味着出现了严重的过拟合。
train(lambd=0)
w的L2范数是: 13.111292839050293
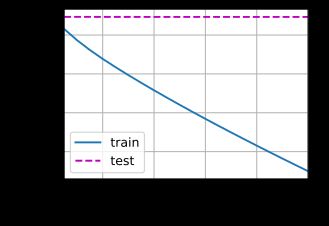
下面,我们使用权重衰减来运行代码。 注意,在这里训练误差增大,但测试误差减小。 这正是我们期望从正则化中得到的效果。
train(lambd=3)
w的L2范数是: 0.3369603753089905

4.1.3、使用Pytorch的简洁实现
由于权重衰减在神经网络中很常用,深度学习框架为了便于我们使用权重衰减,将权重衰减集成到优化算法中,以便与任何损失函数结合使用。神经网络的 L 2 L_2 L2正则化称为权重衰减(weight decay)。troch.optim中继承了很有优化器,上节详细介绍了几个,如SGD,Adadelta,Adam,Adagrad,RMSProp等,这些优化器自带的一个参数weight_decay用于指定权值衰减率,相当于 L 2 L_2 L2正则化中的 λ \lambda λ参数。
L ( w , b ) + λ ∥ w ∥ 2 L(w, b) + \lambda \|\boldsymbol{w}\|^2 L(w,b)+λ∥w∥2
这里我们只为权重 w w w设置了weight_decay,所以偏置参数 b b b不会衰减。
def train_concise(wd):
#定义网络
net=nn.Sequential(nn.Linear(num_inputs,1))
for param in net.parameters():
param.data.normal_()
#均方误差损失函数
loss=nn.MSELoss(reduction='none')
num_epochs,lr=100,0.003
#通过设置参数weight_decay设置衰减,偏置参数b没有衰减,只对权重参数w进行衰减
trainer=torch.optim.SGD([
{"params":net[0].weight,'weight_decay':wd},
{"params":net[0].bias}],lr=lr)
animator=d2l.Animator(xlabel='epochs',ylabel='loss',yscale='log',
xlim=[5,num_epochs],legend=['train','test'])
for epoch in range(num_epochs):
for X,y in train_iter:
trainer.zero_grad()
l=loss(net(X),y)
l.mean().backward()
trainer.step()
if (epoch+1)%5==0:
animator.add(epoch+1,(d2l.evaluate_loss(net,train_iter,loss),
d2l.evaluate_loss(net,test_iter,loss)))
print('w的L2范数:',net[0].weight.norm().item())
不使用衰减:
train_concise(0)
w的L2范数: 12.565210342407227

使用衰减:
train_concise(3)
w的L2范数: 0.366534024477005

4.2 Dropout正则化
4.2.1、简介
除了权重正则化外,深度学习模型常常使用丢弃法(Dropout)来应对过拟合问题。Dropout的做法是在训练过程中按一定比例(比例参数可设置)随机忽略或屏蔽一些神经元。这些神经元会被随机“抛弃”,也就是说他们在正向传播过程中对于下游神经元的共享效果暂时消失了,反向传播时该神经元也不会有任何权重的更新。所以,通过传播过程,Dropout将产生和 L 2 L_2 L2范数相同的收缩权重的效果。
随着神经网络模型的不断学习,神经元的权值会与整个网络的上下文相匹配。神经元的权重针对某些特征进行优化,进而产生一些特殊化。周围的神经元则会依赖于这种特殊化,但如果过于特殊化,模型会因为对训练数据的过拟合而变得脆弱不堪。加入了Dropout以后,输入的特征都是有可能会被随机清除的,所以该神经元不会再特别依赖于任何一个输入特征,也就是说不会给任何一个输入设置太大的权重。由于网络模型对神经元特定的权重不那么敏感,因此提升了模型的泛化能力,不容易对训练数据过拟合。
有一个隐藏层5个隐藏单元的多层感知机,当将dropout应用到隐藏层,该层的隐藏单元将有一定的概率被丢弃掉。设丢弃概率为 p p p,那么有 p p p的概率 h i h_i hi会被清零,有 1 − p 1-p 1−p的概率 h i h_i hi会除以 1 − p 1-p 1−p做拉伸。丢弃概率是丢弃法的超参数。因此,每个中间激活值 h h h以丢弃概率 p p p由随机变量 h ′ h^{'} h′替换,如下所示:
h ′ { 0 , 概 率 为 p h 1 − p , 其 他 情 况 h^{'} \begin{cases} 0, & 概率为p \\ \cfrac {h}{1-p}, & 其他情况 \end{cases} h′⎩⎨⎧0,1−ph,概率为p其他情况
根据设计,期望值保持不变,即 E [ h ′ ] = h E[h^{'}]=h E[h′]=h
对左图的隐藏层使用Dropout法,一种可能的结果如右图所示,其中 h 2 h_2 h2和 h 5 h_5 h5被清零。这时输出值的计算不在依赖 h 2 h_2 h2和 h 5 h_5 h5,在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即 h 1 , ⋯ , h 5 h_1,\cdots ,h_5 h1,⋯,h5都有可能被清零,输出层的计算无法过度依赖 h 1 , ⋯ , h 5 h_1,\cdots ,h_5 h1,⋯,h5中的任何一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。

Dropout在训练阶段和测试阶段是不同的,一般在训练中使用,测试时不使用。不过在测试时,为了平衡(因训练时舍弃了部分节点或输出),一般将输出按Dropout Rate比例缩小。
如何或何时使用Dropout?下面是一般原则:
- 通常丢弃率控制在20%~50%比较好,可以从20%开始尝试。如果比例太低则起不到效果,比例太高则会导致模型的欠学习。
- 在大的网络模型上应用:当dropout用在较大的网络模型时,更有可能得到效果的提升,模型有更多的机会学习到多种独立的表征。
- 在输入层和隐藏层都使用dropout。
- 增加学习速率和冲量:把学习速率扩大10-100倍,冲量值调高到0.9-0.99。
- 大的学习速率往往导致大的权重值。对网络的权重值做最大范数的正则化,被证明能提升模型性能。
4.2.2、从零开始实现
要实现单层的dropout函数,必须从伯努利(二元)随机变量中提取与我们的层的维度一样多的样本,其中随机变量以概率 1 − p 1-p 1−p取值1(保持),以概率 p p p取值0(丢弃)。实现这一点的简单方式是首先从均匀分布 U [ 0 , 1 ] U[0,1] U[0,1]中抽取样本。那么就可以保留那些对样样本大于 p p p的节点,把剩下的丢弃。
下面实现dropout_layer函数,该函数以dropout的概率丢弃张量输入X中的元素,如上所述重新缩放剩余部分:将剩余部分除以 1.0 − d r o p o u t 1.0-dropout 1.0−dropout。
import torch
from torch import nn
import torch.nn.functional as F
from d2l import torch as d2l
import torchvision
from torch.utils import data
from torchvision import transforms
def dropout_layer(X,dropout):
assert 0<=dropout<=1
#在该情况下,所有元素都被丢弃
if dropout==1:
return torch.zeros_like(X)
#在该情况下所有元素都被保留
if dropout==0:
return X
#torch.Tensor(X.shape).uniform_(0,1):生成0-1内的随机数,形状与X相同
#大于dropout设置为1,小于等于为0
mask=(torch.Tensor(X.shape).uniform_(0,1)>dropout).float()
return mask*X/(1.0-dropout)
下面通过几个例子来测试dropout_layer函数。在下面的代码中,将输入X通过dropout操作,丢弃率分别为0、0.5、1。
X=torch.arange(16,dtype=torch.float32).reshape((2,8))
print(X)
print(dropout_layer(X,0.))
print(dropout_layer(X,0.5))
print(dropout_layer(X,1.))
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 0., 0., 0., 0., 0., 0., 14.],
[ 0., 18., 0., 0., 0., 0., 28., 30.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
数据集使用Fashion-MNIST数据集,构建的模型完成多分类任务。
定义的模型是具有两个隐藏层的多层感知机,模型将dropout应用于每个隐藏层的输出(在激活函数之后)。分别为每一层设置丢弃概率。通常在靠近输入层的地方设置较低的丢弃概率。下面将第一个和第二个隐藏层的丢弃概率分别设置为0.2和0.5。并且只在训练期间有效。
dropout1,dropout2=0.2,0.5
class Net(nn.Module):
def __init__(self,num_inputs,num_outputs,num_hiddens1,num_hiddens2,is_training=True):
super(Net, self).__init__()
self.num_inputs=num_inputs
self.training=is_training
self.lin1=nn.Linear(num_inputs,num_hiddens1)
self.lin2=nn.Linear(num_hiddens1,num_hiddens2)
self.lin3=nn.Linear(num_hiddens2,num_outputs)
def forward(self,X):
X=F.relu(self.lin1(X.reshape((-1,self.num_inputs))))
#只有在训练的时候才是用dropout
if self.training==True:
#在第一个全连接层之后添加一个dropout层
X=dropout_layer(X,dropout1)
X=F.relu(self.lin2(X))
if self.training==True:
# 在第二个全连接层之后添加一个dropout层
X = dropout_layer(X, dropout2)
X=self.lin3(X)
return X
#实例化模型
num_inputs,num_outputs,num_hiddens1,num_hiddens2=784,10,256,256
net=Net(num_inputs,num_outputs,num_hiddens1,num_hiddens2)
定义加载Fashion-MNIST数据集的函数,并加载数据集。
#定义加载数据集函数并加载数据集
def load_data_fashion_mnist(batch_size,resize=None):
#下载Fashion-MNIST数据集,然后将其加载到内存中
#ToTensor():将numpy的ndarray或PIL.Image读的图片转换成形状为(C,H, W)的Tensor格式,
trans=[transforms.ToTensor()]
#insert:将数据形状转为规定形状,并用0补充数据
if resize:
trans.insert(0,transforms.Resize(resize))
#Compose将多个步骤组合在一起
trans=transforms.Compose(trans)
mnist_train=torchvision.datasets.FashionMNIST(root="./fashion_mnist_data",train=True,
transform=trans,download=True)
mnist_test=torchvision.datasets.FashionMNIST(root="./fashion_mnist_data",train=False,
transform=trans,download=True)
return (data.DataLoader(mnist_train,batch_size,
shuffle=True,num_workers=0),
data.DataLoader(mnist_test,batch_size,
shuffle=False,num_workers=0))
batch_size=256
train_iter,test_iter=load_data_fashion_mnist(batch_size)
定义与模型训练相关的函数,并对模型进行训练。
#训练轮次和学习率
num_epochs,lr=10,0.5
#交叉熵损失函数
loss=nn.CrossEntropyLoss()
#SGD优化器
trainer=torch.optim.SGD(net.parameters(),lr=lr)
#计算预测正确的数量
def accuracy(y_hat,y):
if len(y_hat.shape)>1 and y_hat.shape[1]>1:
y_hat=y_hat.argmax(axis=1)
cmp=y_hat.type(y.dtype)==y
return float(cmp.type(y.dtype).sum())
#用于对多个变量进行累加
class Accumulator:
def __init__(self,n):
self.data=[0.0]*n
def add(self,*args):
self.data=[a+float(b) for a,b in zip(self.data,args)]
def reset(self):
self.data=[0.0]*len(self.data)
#可以通过索引获取数据
def __getitem__(self, idx):
return self.data[idx]
#定义一个可以获取任一模型精度的函数
def evaluate_accuracy(net,data_iter):
if isinstance(net,torch.nn.Module):
#将模型设置为评估模式
net.eval()
#正确预测数和预测总数两个变量
metric=Accumulator(2)
with torch.no_grad():
for X,y in data_iter:
metric.add(accuracy(net(X),y),y.numel())
return metric[0]/metric[1]
#训练模型的一个迭代周期
def train_epoch(net,train_iter,loss,updater):
#将模型设置为训练模式
if isinstance(net,torch.nn.Module):
net.train()
#记录损失总和,训练准确度总和,样本数
metric=Accumulator(3)
for X,y in train_iter:
#计算梯度并更新参数
y_hat=net(X)
l=loss(y_hat,y)
if isinstance(updater,torch.optim.Optimizer):
##使用Pytorch内置的优化器和损失函数
updater.zero_grad()
l.sum().backward()
updater.step()
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
#返回训练损失和训练精度
return metric[0]/metric[2],metric[1]/metric[2]
#训练模型
def train(net,train_iter,test_iter,loss,num_epochs,updater):
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics=train_epoch(net,train_iter,loss,updater)
test_acc=evaluate_accuracy(net,test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
train(net,train_iter,test_iter,loss,num_epochs,trainer)

4.2.3、简洁实现
在pytorch中,只需要在全连接层之后添加一个Dropout层,将丢弃概率作为唯一的参数传递给他的构造函数。
dropout1,dropout2=0.2,0.5
class Net1(nn.Module):
def __init__(self,num_inputs,num_outputs,num_hiddens1,num_hiddens2,is_training=True):
super(Net1, self).__init__()
self.num_inputs=num_inputs
self.training=is_training
self.lin1=nn.Linear(num_inputs,num_hiddens1)
self.lin2=nn.Linear(num_hiddens1,num_hiddens2)
self.lin3=nn.Linear(num_hiddens2,num_outputs)
self.dropout1=nn.Dropout(dropout1)
self.dropout2 = nn.Dropout(dropout2)
def forward(self,X):
X=F.relu(self.lin1(X.reshape((-1,self.num_inputs))))
#只有在训练的时候才是用dropout
if self.training==True:
#在第一个全连接层之后添加一个dropout层
X=self.dropout1(X)
X=F.relu(self.lin2(X))
if self.training==True:
# 在第二个全连接层之后添加一个dropout层
X = self.dropout2(X)
X=self.lin3(X)
return X
num_inputs,num_outputs,num_hiddens1,num_hiddens2=784,10,256,256
net1=Net1(num_inputs,num_outputs,num_hiddens1,num_hiddens2)
#训练轮次和学习率
num_epochs,lr=10,0.5
#加载训练和测试所使用的的数据。
batch_size=256
train_iter,test_iter=load_data_fashion_mnist(batch_size)
#交叉熵损失函数
loss=nn.CrossEntropyLoss()
#SGD优化器
trainer=torch.optim.SGD(net1.parameters(),lr=lr)
train(net1,train_iter,test_iter,loss,num_epochs,trainer)
