学习pytorch——了解深度学习一般框架
学习pytorch——了解深度学习一般框架
python的安装–anaconda
1 下载anaconda
环境配置
Anaconda_Home
E:\dev\Anaconda3
path:
%Anaconda_Home%
%Anaconda_Home%\Library\bin
%Anaconda_Home%\Scripts
%Anaconda_Home%\Library\mingw-w64\bin
常用命令
查看所有虚拟环境: conda info -e
查看当前环境的包:conda list
启动虚拟环境:activate 环境名
创建:conda create -n 环境名 ,如,conda create -n rcnn python=3.6
删除:conda remove -n rcnn --all
配置anaconda缓存目录
修改环境名称在environments中
使用命令查看当前conda参数conda info
active environment : base
active env location : E:\dev\Anaconda3
shell level : 1
user config file : C:\Users\65782\.condarc #配置的镜像源
populated config files : C:\Users\65782\.condarc #environments.txt包含了环境名称(可修改)C:\Users\\.conda\environments.txt
conda version : 4.10.1
conda-build version : 3.21.4
python version : 3.8.8.final.0
virtual packages : __cuda=11.1=0
__win=0=0
__archspec=1=x86_64
base environment : E:\dev\Anaconda3 (writable)
conda av data dir : E:\dev\Anaconda3\etc\conda
conda av metadata url : https://repo.anaconda.com/pkgs/main
channel URLs : https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/noarch
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/noarch
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/win-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/noarch
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/win-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/noarch
https://repo.anaconda.com/pkgs/main/win-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/win-64
https://repo.anaconda.com/pkgs/r/noarch
https://repo.anaconda.com/pkgs/msys2/win-64
https://repo.anaconda.com/pkgs/msys2/noarch
package cache : E:\dev\Anaconda3\pkgs
C:\Users\65782\.conda\pkgs
C:\Users\65782\AppData\Local\conda\conda\pkgs
envs directories : E:\dev\Anaconda3\envs
C:\Users\65782\.conda\envs
C:\Users\65782\AppData\Local\conda\conda\envs
platform : win-64
user-agent : conda/4.10.1 requests/2.25.1 CPython/3.8.8 Windows/10 Windows/10.0.19041
administrator : False
netrc file : None
offline mode : False
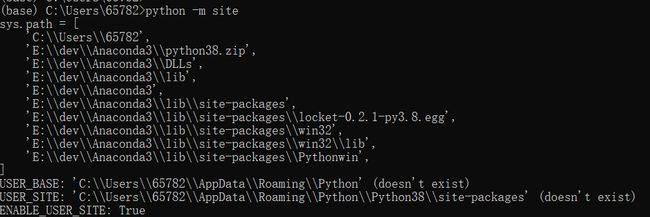
2 PIP下载目录修改
https://blog.csdn.net/ZCShouCSDN/article/details/84990674
使用命令查看用户下载包路径:
python -m site
修改lib\site.py


USER_SITE = "E:\dev\Anaconda3\Lib\site-packages" #USER_SITE = None
USER_BASE = "E:\dev\Anaconda3\Scripts" #USER_BASE = None
3 Jupyter
Jupyter Notebook修改默认工作目录
输入命令查看当前jupyter_notebook_config.py文件位置
jupyter notebook --generate-config
C:\Users\65782>jupyter notebook --generate-config
Overwrite C:\Users\65782\.jupyter\jupyter_notebook_config.py with default config? [y/N]n
该地址即为jupyter_notebook_config.py所在地址。找到此文件并打开
将#c.NotebookApp.notebook_dir改为c.NotebookApp.notebook_dir = 'E:\Projects\jupyter_notebook'自己的项目目录
安装插件
https://blog.csdn.net/weixin_44560088/article/details/121050748
- 安装插件
pip install jupyter_contrib_nbextensions - 安装 javascript and css files:
jupyter contrib nbextension install --user - 安装configure:
pip install jupyter_nbextensions_configurator - 卸载:
pip uninstall jupyter_contrib_nbextensionspip uninstall jupyter_nbextensions_configurator
插件安装:https://blog.csdn.net/sinat_23971513/article/details/120102672
插件推荐
-
Hinterlandcoding 时肯定需要自动填充功能,jupyter notebook默认的状态并不理想,此插件可以增加此功能。
-
Code prettify 格式化代码,相当于pycharn中的
Ctrl + Alt + L -
Autopep8: 自动代码格式优化
-
AutoSaveTime: 控制脚本的自动保存时间
-
Hide Input All: 隐藏所有的代码单元,保持所有的输出和 markdown 单元可见
-
Spellchecker: 对 markdown 单元中的内容进行拼写检查
-
Execute Time 显示一个cell执行花费的时间
-
Scratchpad 窗口分面
-
Table of Contents (2) 添加目录
-
Variable Inspector :这是一个查看变量的插件,类似于 Matlab 和 R studio 的工作空间,可以查看变量名、类型,大小,形状和值。其中变量的 shape (形状)这个参数在进行矩阵运算时,十分实用,并且这个窗口还可以调节大小,排序等功能
Jupyter Notebook切换不同环境(不同核)
https://blog.csdn.net/zhangqiqiyihao/article/details/115251703
https://blog.csdn.net/weixin_44560088/article/details/121050748
较好:https://blog.csdn.net/weixin_39669880/article/details/106577481
- 查看所有环境:conda info -e

2.base环境中安装 conda install ipykernel
3.base环境中安装好jupyter notebook
4.在需要关联的环境中输入`conda环境注入:
5.查看自己的环境:``
python -m ipykernel install --user --name 你的conda环境名称 --display-name "Python [conda env:your_env]"
Python [conda env:your_env]:将是你在notebook中看到的名称。
python -m ipykernel install --user --name mypytorch --display-name mypytorch
查看所有核:jupyter kernelspec list
删除核:jupyter kernelspec remove mypytorch
卸载name核:jupyter kernelspec uninstall pytorch1.8_python3.6
- 当创建了新的conda虚拟环境的时候,可以在新环境上面安装ipykernel:
python -m ipykernel install --user --name=pytorch_gpu(你自定义的虚拟环境的名字)
# 安装插件
conda install nb_conda
或者安装 conda install ipykernel
# 在虚拟环境中安装jupyter
pip install jupyter -i 任意源
# 然后查看是否安装成功:
jupyter kernelspec list
4 安装torch https://pytorch.org/
配置镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
安装CUDA
使用nvcc -V查看本机状态
https://zhuanlan.zhihu.com/p/428082594
https://blog.csdn.net/qq_45128278/article/details/114580990
查看本机显卡,并下载驱动http://www.nvidia.com/Download/index.aspx
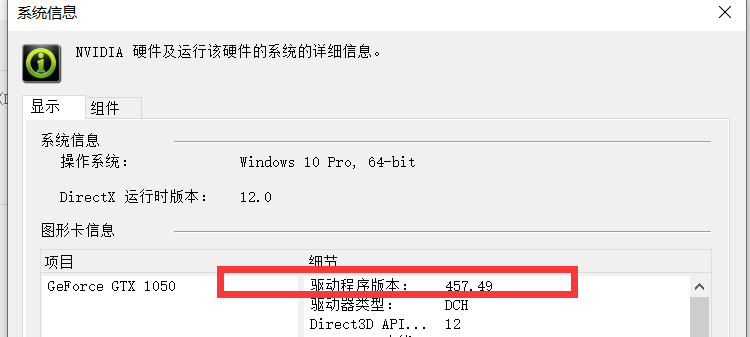
检查驱动版本号:查看cuda适合版本:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html


查看是否安装cuda:https://blog.csdn.net/qq_41897154/article/details/115273699
https://blog.csdn.net/m0_45447650/article/details/123704930
https://zhuanlan.zhihu.com/p/428082594
window 的 CUDA安装教程,分为以下步骤:
- 准备工作:查看本机的CUDA驱动适配版本;
- 检查主机GPU
- 检查驱动版本
CUDA: CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题
查看显卡是否支持CUDA及支持的版本https://www.jianshu.com/p/8fd2a7233d09

-
下载: CUDA 和 CUDNN 安装包;
-
https://developer.nvidia.com/cuda-toolkit-archive
```txt
cuda:
https://developer.nvidia.com/cuda-11.1.1-download-archive?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exelocal
cudnn:
https://developer.nvidia.com/rdp/cudnn-download
```
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Gc4zC6o-1653983180065)(python的安装--anacoda.assets/image-20220518225827842.png)]
-
安装和配置:CUDA;
-
CUDA_HOME:E:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
-
path:%CUDA_HOME%\v11.1\lib\x64
-
cmd:>nvcc --version
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3wTIE3ln-1653983180065)(python的安装--anacoda.assets/image-20220519002844681.png)]
-
安装和配置:CUDNN;
-
在 jupyter 配置环境;
- conda install ipykernel
- python -m ipykernel install --user --name mypytorch --display-name mypytorch
执行显卡命令:
安装tourch

-c pytorch去掉
# CUDA 10.2
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2
# CUDA 11.3
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
# CPU Only
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cpuonly -c pytorch
torch
数据加载:Dataset
# -*- coding: utf-8 -*-
# @Time : 2022/5/19 18:20
# @Author : PVINCE
# @File : 1_read_data.py
#@desc:
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path)
def __getitem__(self, index):
img_name=self.img_path[index]
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
img=Image.open(img_item_path)
label=self.label_dir
return img,label #img label:ants|bees
def __len__(self):
return len(self.img_path)
root_dir= '../dataset\\train'
ants_label_dir='ants'
bees_label_dir='bees'
ants_dataSet=MyData(root_dir,ants_label_dir)
bees_dataSet=MyData(root_dir,bees_label_dir)
trian_dataset=ants_dataSet+ants_dataSet#数据集的拼接 dataset[0]是ants的数据集 dataset[1]是bees的数据集
# -*- coding: utf-8 -*-
# @Time : 2022/5/23 21:29
# @Author : PVINCE
# @File : 2_rename_dataset.py
#@desc:
import os
root_dir='../dataset\\train'
target_dir='ants'
label='ants'
out_dir='ants_label'
img_path=os.listdir(os.path.join(root_dir,target_dir))
for i in img_path:
file_name=i.split('.jpg')[0]
with open(os.path.join(root_dir,out_dir,"{}.txt".format(file_name)),'a')as f:
f.write(label)
tensorBoard的使用
导包from torch.utils.tensorboard import SummaryWriter
安装TensorBoard:pip install tensorboard
报错:AttributeError: module ‘distutils’ has no attribute 'version’原因 setuptools版本过高
解决:pip uninstall setuptools pip install setuptools==59.5.0
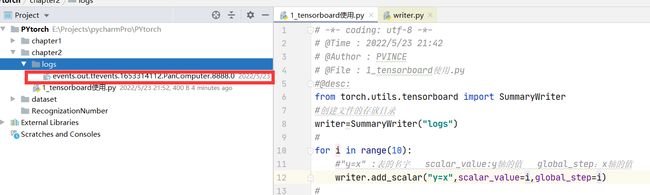
使用命令tensorboard --logdir=logs查看面板
使用端口限制 tensorboard --logdir=logs --port=8080
这里会报错TensorFlow installation not found - running with reduced feature set
解决办法:
- 使用绝对路径:tensorboard --logdir=E:\Projects\logs
- 不要加引号
- 切换到log文件夹的目录下,含有logs的目录下>tensorboard --logdir=logs
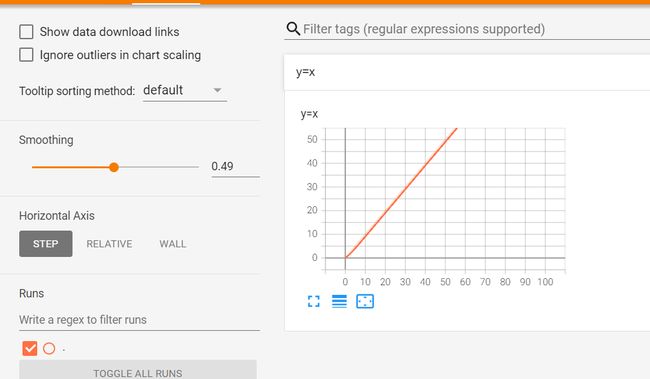
使用tag标签区分表格
代码:
# -*- coding: utf-8 -*-
# @Time : 2022/5/23 21:42
# @Author : PVINCE
# @File : 1_tensorboard使用.py
#@desc:
from torch.utils.tensorboard import SummaryWriter
#创建文件的存放目录
writer=SummaryWriter("logs")
#tensorboard dev upload --logdir 'E:\Projects\pycharmPro\PYtorch\chapter2\logs'
for i in range(100):
#"y=x" :tag表的名字 scalar_value:y轴的值 global_step:x轴的值
writer.add_scalar("y=x",scalar_value=i,global_step=i)
#
writer.close()
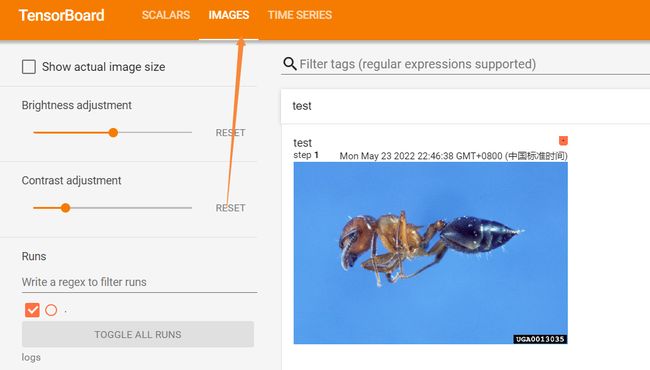
支持的图像

image加载
# -*- coding: utf-8 -*-
# @Time : 2022/5/23 21:42
# @Author : PVINCE
# @File : 1_tensorboard使用.py
#@desc:
from torch.utils.tensorboard import SummaryWriter
#创建文件的存放目录
writer=SummaryWriter("logs")
#tensorboard --logdir=logs
##########使用折线图#######
# for i in range(100):
# #"y=x" :表的名字 scalar_value:y轴的值 global_step:x轴的值
# writer.add_scalar("y=x",scalar_value=i,global_step=i)
#writer.close()
# #################################
########使用图片
from PIL import Image
import numpy as np
ants_path='../dataset/train/ants/0013035.jpg'
img_PIL=Image.open(ants_path)
img=np.array(img_PIL)
# img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data Default is :math:`(3, H, W)`
#默认img的np中的shape是(hwc) 所以需要用dataformats指定顺序
# #"test" :表的名字 img:y轴的值 1:x轴的值
writer.add_image('test',img,1,dataformats='HWC')
writer.close()
Transform
是一个工具箱,有很多的工具,可以使用当中的工具来进行
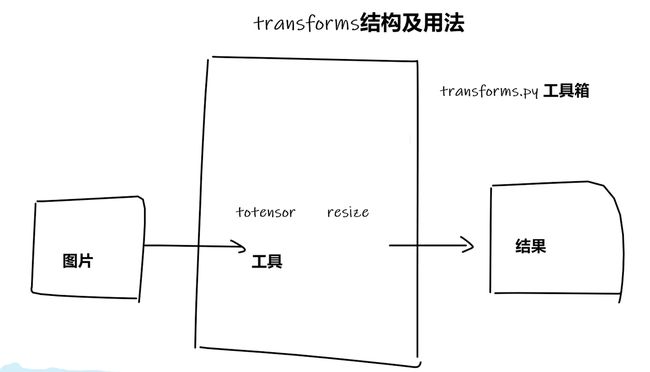
ToTensor
-
transform该如何使用
# -*- coding: utf-8 -*- # @Time : 2022/5/23 22:49 # @Author : PVINCE # @File : 1_transform.py #@desc: from torchvision import transforms from PIL import Image img_path='../dataset/train/ants/0013035.jpg' img=Image.open(img_path) print(img)##使用transformer tensor_trans=transforms.ToTensor() tensor_img=tensor_trans(img)#tensor([[[0.3137, 0.3137, 0.3137, ..., 0.3176, 0.3098, 0.2980], print(tensor_img) 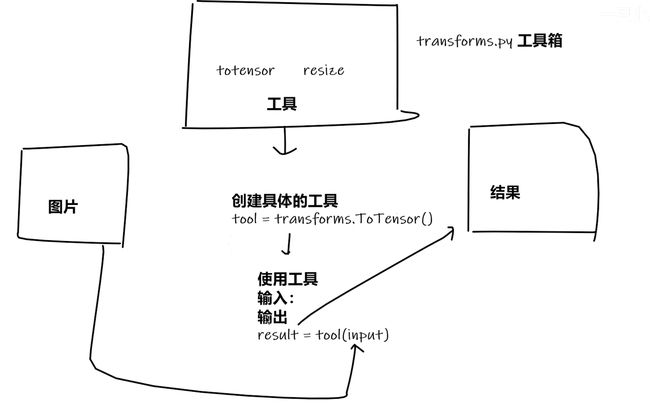
-
为什么会用到transformer
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path='../dataset/train/ants/0013035.jpg'
不使用transformer
img_PIL=Image.open(img_path)
img=np.array(img_PIL)
writer.add_image('test',img,1,dataformats='HWC')
writer.close()
使用transformer
img_PIL=Image.open(img_path)
ts=transforms.ToTensor()
ts_img=ts(img)
writer.add_image("Tensor_img",ts_img)
writer.close()
tensor包装了神经网络所要用到的参数
#@desc:使用opencv读取图片
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
writer=SummaryWriter("logs","使用opencv读取图片")
img_path='../dataset/train/ants/0013035.jpg'
img=Image.open(img_path)
# 使用tensor读取图片
trans=transforms.ToTensor()
trans_img=trans(img)
writer.add_image("使用transforms读取图片",trans_img)
# 使用cv读取
import cv2
img_cv2=cv2.imread(img_path) #ndarray hwc
trans_img2=trans(img_cv2)
writer.add_image("使用opencv读取图片",trans_img2)
writer.close()
常见的transform

ToTensor
转换图片,将PIL Image和ndarray转换成tensor
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. This transform does not support torchscript.
Normalize
归一化:均值和标准差对张量图像进行归一化。这种变换不支持 PIL 图像。给定均值:(mean[1],...,mean[n]) 和 std:(std [1],..,std[n]) 用于 n 个通道,此变换将对输入的每个通道进行归一化
channel一般是3
``torch.*Tensor`` i.e.,
``output[channel] = (input[channel] - mean[channel]) / std[channel]``
输入通道-通道均值/标准差
Args:
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation in-place.

图片转换成tensor后是一个3x3x3的矩阵 [3][h][w]=像素点的值

# -*- coding: utf-8 -*-
# @Time : 2022/5/26 17:10
# @Author : PVINCE
# @File : 4_Norm.py
#@desc: tranforms中的正则化函数
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
writer=SummaryWriter("logs","正则化")
img_path='../dataset/train/ants/0013035.jpg'
img=Image.open(img_path)
# 使用tensor读取图片
trans=transforms.ToTensor()
img_tensor=trans(img)
writer.add_image("正则化之前img_tensor",img_tensor)
print(img_tensor[0][0][0])#正则化之前tensor(0.3137)
tran_norm=transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
img_norm=tran_norm(img_tensor)
print(img_norm[0][0][0])#正则化之后tensor(-0.3725)
writer.add_image("正则化之后img_norm",img_norm)
writer.close()
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O7c02PT9-1653983180069)(python的安装–anacoda.assets/image-20220526172240690.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O7c02PT9-1653983180069)(python的安装–anacoda.assets/image-20220526172240690.png)]
Resize
"""Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions
Args:
size (sequence or int): Desired output size. If size is a sequence like
(h, w), output size will be matched to this. If size is an int,
smaller edge of the image will be matched to this number.
i.e, if height > width, then image will be rescaled to
(size * height / width, size).
img.size
Out[9]: (768, 512)
trans_resize=transforms.Resize((512,512))
print(trans_resize(img).size)
(512, 512)
# -*- coding: utf-8 -*-
# @Time : 2022/5/26 18:49
# @Author : PVINCE
# @File : 4_Resize.py
#@desc:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
writer=SummaryWriter("logs","使用resize图片")
#1 读取Image.open(img_path)
img_path='../dataset/train/ants/0013035.jpg'
img=Image.open(img_path)
print(img.size)#(768, 512)
#2 使用tensor转换
trans=transforms.ToTensor()
img_tensor=trans(img)
writer.add_image("resize之前",img_tensor)
#3 使用resize函数
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img)
print(img_resize.size)#(512, 512)
img_resize=trans(img_resize)
#4 加入日志
writer.add_image("resize之后",img_resize)
writer.close()
Compose
将多个transforms的函数出传入作为参数,进行一个组合
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.PILToTensor(),
>>> transforms.ConvertImageDtype(torch.float),
>>> ])
# -*- coding: utf-8 -*-
# @Time : 2022/5/26 18:49
# @Author : PVINCE
# @File : 4_Resize.py
#@desc:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision.transforms import transforms
writer=SummaryWriter("logs","使用resize图片")
#1 读取Image.open(img_path)
img_path='../dataset/train/ants/0013035.jpg'
img=Image.open(img_path)
print(img.size)#(768, 512)
#2 使用tensor转换
trans_ToTensor=transforms.ToTensor()
img_tensor=trans_ToTensor(img)
writer.add_image("resize之前",img_tensor)
#3 使用resize函数
trans_resize=transforms.Resize((512,512))
img_resize=trans_resize(img)
print(img_resize.size)#(512, 512)
img_resize=trans_ToTensor(img_resize)
#4 加入日志
writer.add_image("resize之后",img_resize)
# 使用compose
trans_resize2=transforms.Resize(512)
#第一个输入PIL->PIL->tensor 输入与输出要匹配,上一个函数的输出是下一个的输入
trans_compose=transforms.Compose([trans_resize2,trans_ToTensor])
img_resize2=trans_compose(img)
writer.add_image("使用compose",img_resize2)
writer.close()
RandomCrop
随机裁剪
"""Crop the given image at a random location.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions,
but if non-constant padding is used, the input is expected to have at most 2 leading dimensions
在随机位置裁剪给定的图像。如果图像是torch Tensor,它应该具有[..., H, W] 形状,其中...表示任意数量的前导维度,但如果不是- 使用常量填充,输入预计最多有 2 个前导维度
trans_crop=transforms.RandomCrop(512)
img_crop=trans_crop(img)#512,512
python中call含义
class Person:
def __call__(self, name):
print("__call__hello"+name)
def hello(self,name):
print("hello"+name)
person=Person()
person("zhangsan") ##调用了call方法
person.hello("losi")#调用了hello方法
打印结果
__call__hellozhangsan
hellolosi
Transform数据集的处理
torchvision库数据集
数据集:https://pytorch.org/vision/stable/index.html


CIFAR10数据集:使用参数


数据集属性

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ycpLBijI-1653983180071)(python的安装–anacoda.assets/image-20220526195428350.png)]
train_set=torchvision.datasets.CIFAR10(root="./dataset/",train=True,transform=dataset_transform,download=True)
download=true会自动解压文件夹下面的数据集包
# -*- coding: utf-8 -*-
# @Time : 2022/5/26 19:40
# @Author : PVINCE
# @File : 数据使用.py
#@desc:
import torchvision
#将数据集转换成tensor,还可以进行正则化
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset/",train=True,transform=dataset_transform,download=False)
test_set=torchvision.datasets.CIFAR10(root="./dataset/",train=False,transform=dataset_transform,download=False)
img,target=train_set[0]
dataloader使用
https://pytorch.org/docs/stable/data.html
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
-
batch_size
-
shuffle洗牌
-
num_workers 多进程
-
drop_last:100/3余1是否要
# -*- coding: utf-8 -*-
# @Time : 2022/5/26 21:36
# @Author : PVINCE
# @File : dataloader使用.py
#@desc: dataloader使用
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(test_data,batch_size=51,shuffle=True,num_workers=0,drop_last=False)
# batch_size返回一组包含4个的数据;shuffle洗牌;num_workers多进程;drop_last是否放弃不足以4个的返回
img,target=test_data[0]
target_names=test_data.classes
print(img.shape)
print(target)
print(target_names)
writer=SummaryWriter("logs")
step=0
for data in test_loader:
imgs,targets=data
print(imgs.shape)# torch.Size([4, 3, 32, 32])
print(targets) #tensor([2, 1, 3, 6])
writer.add_images("test_data",imgs,step)
step+=1
writer.close()

洗牌对比
shuffle=true


shuffle=False
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V58ZExgP-1653983180072)(python的安装–anacoda.assets/image-20220526220820449.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V58ZExgP-1653983180072)(python的安装–anacoda.assets/image-20220526220820449.png)]
神经网络的搭建nn(Neural network)
https://pytorch.org/docs/stable/nn.html
module
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
前向传播
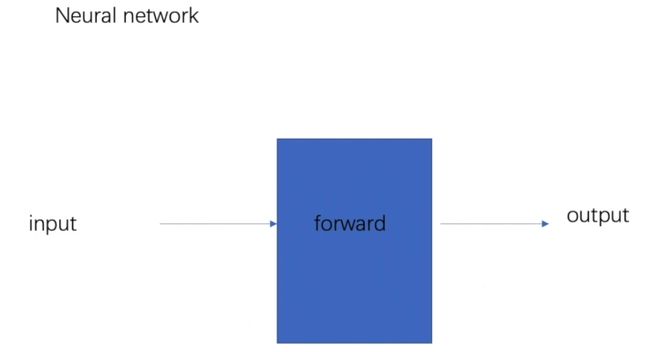
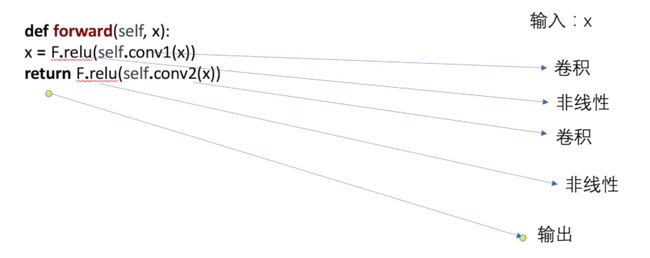
# -*- coding: utf-8 -*-
# @Time : 2022/5/26 22:15
# @Author : PVINCE
# @File : nn_module.py
#@desc:神经网络模型
import torch
from torch import nn
class myModule(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output=input+1
return output
# 创建神经网络
pp=myModule()
x=torch.tensor(1.0)
output=pp(x)
print(output)
卷积
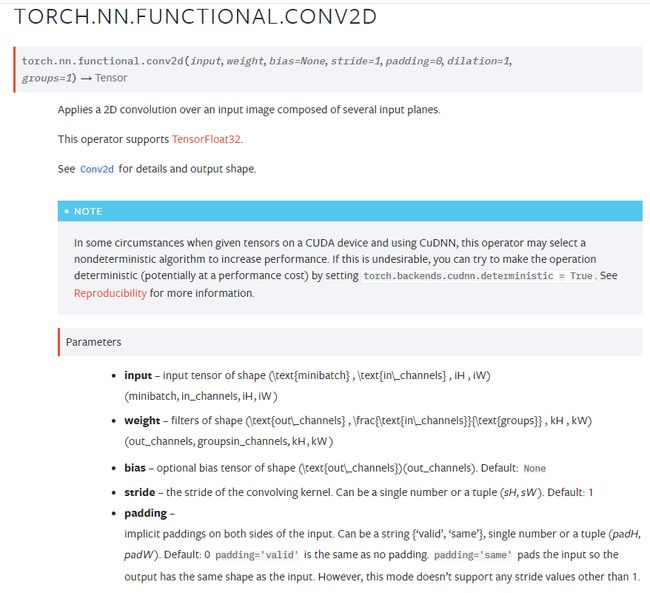
https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d、
https://pytorch.org/docs/stable/generated/torch.nn.functional.conv2d.html#torch.nn.functional.conv2d
卷积HW计算:https://zhuanlan.zhihu.com/p/163017446
参数动图展示: https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
- 参数动图展示: https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
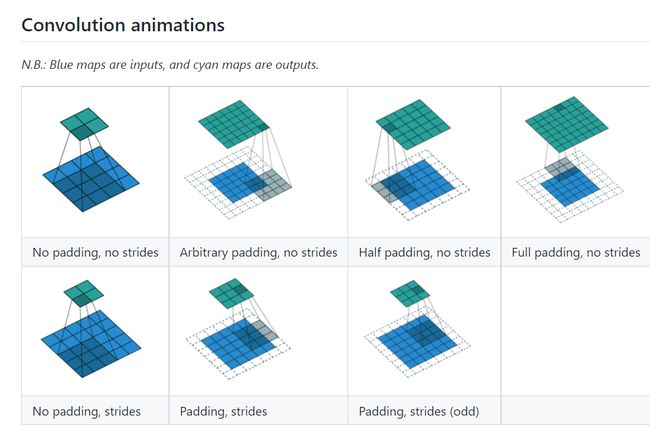
-
in_channels (int) – Number of channels in the input image
-
out_channels (int) – Number of channels produced by the convolution
- 有时候一个通道,2个输出通道

-
kernel_size (int or tuple) – Size of the convolving kernel 卷积核大小,只有一个矩阵的时候会生成另外的https://zhuanlan.zhihu.com/p/163017446
- N是特征图的宽度,M是输出的宽度,卷积核的滑动次数是 M − 1 M-1 M−1 ,padding之后的矩阵宽度等于 N + 2 ∗ p a d d i n g N+2*padding N+2∗padding


-
stride (int or tuple, optional) – Stride of the convolution. Default: 1
-
padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0
-
padding_mode (string*,* optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros' -
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1 空洞卷积

-
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
-
bias (bool, optional) – If
True, adds a learnable bias to the output. Default:True添加偏置
卷积过程

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2AaIKBOJ-1653983180075)(python的安装–anacoda.assets/image-20220527160021889.png)]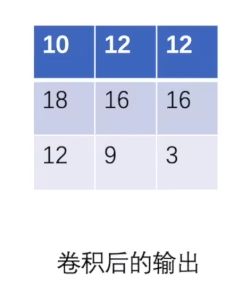
# -*- coding: utf-8 -*-
# @Time : 2022/5/27 15:50
# @Author : PVINCE
# @File : nn_conv.py
#@desc:
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]
)
kernel=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
print(input.shape, kernel.shape)#torch.Size([5, 5]) torch.Size([3, 3])
input=torch.reshape(input,(1,1,5,5))#bathsize=1,chanel=1,h=5,w=5
kernel=torch.reshape(kernel,(1,1,3,3))#bathsize=1,chanel=1,h=3,w=3
output=F.conv2d(input=input,weight=kernel,stride=1)
print(output)
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
output=F.conv2d(input=input,weight=kernel,stride=2)
tensor([[[[10, 12],
[13, 3]]]])
Padding
给矩阵数组添加新的行列,进行扩展一个像素,默认为0
output3=F.conv2d(input=input,weight=kernel,stride=1,padding=1)
print(output3)
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
小案例
# -*- coding: utf-8 -*-
# @Time : 2022/5/27 16:22
# @Author : PVINCE
# @File : nn_conv2d.py
#@desc:
import torch
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch import nn
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class PP(nn.Module):
def __init__(self):
super(PP,self).__init__()
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
pp=PP()
print(pp)# (conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)
writer=SummaryWriter("logs")
step=0
for data in dataloader:
imgs,targets=data
output=pp(imgs)
print(imgs.shape)#torch.Size([64, 3, 32, 32])
print(output.shape)#torch.Size([64, 6, 30, 30])
output=torch.reshape(output,[-1,3,30,30])
writer.add_images("input imgs",imgs,global_step=step)
writer.add_images("con2d imgs",output,global_step=step)
step+=1
writer.close()
池化==降采样
减少数据量,同时选取有用的值。
https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d
Parameters
- kernel_size – the size of the window to take a max over
- stride – the stride of the window. Default value is
kernel_size - padding – implicit zero padding to be added on both sides
- dilation – a parameter that controls the stride of elements in the window
- return_indices – if
True, will return the max indices along with the outputs. Useful fortorch.nn.MaxUnpool2dlater - ceil_mode – when True, will use ceil instead of floor to compute the output shape
最大池化:找到池化核中的最大的值。
默认设置kernel_size

# -*- coding: utf-8 -*-
# @Time : 2022/5/27 17:02
# @Author : PVINCE
# @File : nn_maxPool.py
#@desc:
import torch
from torch.nn import MaxPool2d
from torch import nn
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32
)
input=torch.reshape(input,(-1,1,5,5))
class Mymodule(nn.Module):
def __init__(self):
super(Mymodule, self).__init__()
self.maxPool=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxPool(input)
return output
model=Mymodule()
output=model(input)
print(output)#tensor([[[[2., 3.],[5., 1.]]]])
代码2
# -*- coding: utf-8 -*-
# @Time : 2022/5/27 17:02
# @Author : PVINCE
# @File : nn_maxPool.py
#@desc:
import torch
import torchvision
from torch.nn import MaxPool2d
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
input=torch.reshape(input,(-1,1,5,5))
class Mymodule(nn.Module):
def __init__(self):
super(Mymodule, self).__init__()
self.maxPool=MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output=self.maxPool(input)
return output
writer=SummaryWriter("logs_maxpool")
model=Mymodule()
step=0
for data in dataloader:
imgs,target=data
output=model(imgs)
writer.add_images("maxpool input imgs",imgs,global_step=step)
writer.add_images("maxpool output imgs",output,global_step=step)
writer.close()


非线性激活
函数:sigmod relu 正切
Relu:https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html#torch.nn.ReLU
作用:增加泛化能力
ReLU(inplace=False) false会保留原来的值

# -*- coding: utf-8 -*-
# @Time : 2022/5/27 17:23
# @Author : PVINCE
# @File : nn_Relu.py
#@desc:
import torch
from torch import nn
from torch.nn import ReLU
input=torch.tensor([[1,-0.5],
[-1,3]])
input=torch.reshape(input,(-1,1,2,2))
print(input.shape) #torch.Size([1, 1, 2, 2])
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.relu1=ReLU(inplace=False)
def forward(self,x):
x=self.relu1(x)
return x
mymodel=MyModel()
output=mymodel(input)
print(output) #[[[[1., 0.],[0., 3.]]]])
# -*- coding: utf-8 -*-
# @Time : 2022/5/27 17:23
# @Author : PVINCE
# @File : nn_Relu.py
#@desc:
from torch import nn
from torch.nn import ReLU
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.relu1=ReLU(inplace=False)
def forward(self,x):
x=self.relu1(x)
return x
dataset=torchvision.datasets.CIFAR10('./dataset',train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=64)
writer=SummaryWriter("logs_relu")
mymodel=MyModel()
step=0
for data in dataloader:
imgs,target=data
output=mymodel(imgs)
writer.add_images("relu input",imgs,global_step=step)
writer.add_images("relu output",output,global_step=step)
step = step+1
writer.close()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BCiMlURk-1653983180077)(python的安装–anacoda.assets/image-20220527175108272.png)]
正则化-加速收敛
https://pytorch.org/docs/stable/nn.html#normalization-layers

# With Learnable Parameters
m = nn.BatchNorm2d(100)
# Without Learnable Parameters
m = nn.BatchNorm2d(100, affine=False)
input = torch.randn(20, 100, 35, 45)
output = m(input)
ReCurrent layers
https://pytorch.org/docs/stable/nn.html#recurrent-layers
一些文字识别会用到
nn.RNNBase |
|
|---|---|
nn.RNN |
Applies a multi-layer Elman RNN with \tanhtanh or \text{ReLU}ReLU non-linearity to an input sequence. |
nn.LSTM |
Applies a multi-layer long short-term memory (LSTM) RNN to an input sequence. |
nn.GRU |
Applies a multi-layer gated recurrent unit (GRU) RNN to an input sequence. |
nn.RNNCell |
An Elman RNN cell with tanh or ReLU non-linearity. |
nn.LSTMCell |
A long short-term memory (LSTM) cell. |
nn.GRUCell |
A gated recurrent unit (GRU) cell |
Linear Layers
nn.Identity |
A placeholder identity operator that is argument-insensitive. |
|---|---|
nn.Linear |
Applies a linear transformation to the incoming data: y = xA^T + by=xAT+b |
nn.Bilinear |
Applies a bilinear transformation to the incoming data: y = x_1^T A x_2 + by=x1TAx2+b |
nn.LazyLinear |
A torch.nn.Linear module where in_features is inferred. |
Dropout Layers
随机变成零,防止过拟合
nn.Dropout |
During training, randomly zeroes some of the elements of the input tensor with probability p using samples from a Bernoulli distribution. |
|---|---|
nn.Dropout2d |
Randomly zero out entire channels (a channel is a 2D feature map, e.g., the jj-th channel of the ii-th sample in the batched input is a 2D tensor \text{input}[i, j]input[i,j]). |
nn.Dropout3d |
Randomly zero out entire channels (a channel is a 3D feature map, e.g., the jj-th channel of the ii-th sample in the batched input is a 3D tensor \text{input}[i, j]input[i,j]). |
nn.AlphaDropout |
Applies Alpha Dropout over the input. |
nn.FeatureAlphaDropout |
Randomly masks out entire channels (a channel is a feature map, e.g. |
Distance Functions
误差衡量
线性层
Linear Layers
nn.Identity |
A placeholder identity operator that is argument-insensitive. |
|---|---|
nn.Linear |
Applies a linear transformation to the incoming data: y = xA^T + by=xAT+b |
nn.Bilinear |
Applies a bilinear transformation to the incoming data: y = x_1^T A x_2 + by=x1TAx2+b |
nn.LazyLinear |
A torch.nn.Linear module where in_features is inferred. |
# -*- coding: utf-8 -*-
# @Time : 2022/5/27 19:18
# @Author : PVINCE
# @File : nn_linear.py
#@desc:线性层
import torch
import torchvision
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch import nn
dataset=torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Mymdl(nn.Module):
def __init__(self):
super(Mymdl,self).__init__()
self.linear1=Linear(196608,10)#输入特征值数量,输出特征值数量
def forward(self,input):
output=self.linear1(input)
return output
Pmodel=Mymdl()
for data in dataloader:
imgs,target=data
print(imgs.shape)#torch.Size([64, 3, 32, 32])
output=torch.reshape(imgs,(1,1,1,-1))
print(output.shape)#torch.Size([1, 1, 1, 196608])
output2=torch.flatten(imgs)#摊平
print(output2.shape)#torch.Size([196608])
output3=Pmodel(output2)
print(output3.shape)#torch.Size([10])
Sequential模型案例
代码写起来简洁易懂
CIFAR10一个简单网络结构模型

卷积HW计算:https://zhuanlan.zhihu.com/p/163017446

模型网络层参数计算
-
c o n v 2 d : 3 @ 32 × 32 conv2d :3@32\times32 conv2d:3@32×32的数据经过卷积后为 32 @ 32 × 32 32@32\times32 32@32×32
- 32 = 32 + 2 ∗ p a d d i n g − 5 s t r i d e = 1 + 1 32=\frac{32+2*padding-5}{stride=1}+1 32=stride=132+2∗padding−5+1
- padding=2,stride=1,k=5
-
M a x P o o l i n g : k = 2 MaxPooling:k=2 MaxPooling:k=2
- input:32*32*32
- ouput:32*16*16
-
c o n v 2 d : 32 @ 16 × 16 conv2d :32@16\times16 conv2d:32@16×16的数据经过卷积后为 32 @ 16 × 16 32@16\times16 32@16×16
- 16 = 16 + 2 ∗ p a d d i n g − 5 s t r i d e = 1 + 1 16=\frac{16+2*padding-5}{stride=1}+1 16=stride=116+2∗padding−5+1
- padding=2,stride=1,k=5
-
M a x P o o l i n g : k = 2 MaxPooling:k=2 MaxPooling:k=2
- input:32*16*16
- ouput:32*8*8
-
c o n v 2 d : 32 @ 8 × 8 conv2d :32@8\times 8 conv2d:32@8×8的数据经过卷积后为 64 @ 8 × 8 64@8\times 8 64@8×8
- 8 = 8 + 2 ∗ p a d d i n g − 5 s t r i d e = 1 + 1 8=\frac{8+2*padding-5}{stride=1}+1 8=stride=18+2∗padding−5+1
- padding=2,stride=1,k=5
-
M a x P o o l i n g : k = 2 MaxPooling:k=2 MaxPooling:k=2
- input:64*8*8
- ouput:64*4*4
-
F l a t t e n Flatten Flatten
-
将64个通道的进行展开 64 × 4 × 4 = 1024 64\times 4 \times 4=1024 64×4×4=1024
-
print(imgs.shape)#torch.Size([64, 3, 32, 32]) output=torch.reshape(imgs,(1,1,1,-1)) print(output.shape)#torch.Size([1, 1, 1, 196608]) 其实就是 64个图片*3通道*32高*32宽的结果 output2=torch.flatten(imgs)#摊平 print(output2.shape)#torch.Size([196608])
-
-
全连接层
- self.linear1=Linear(196608,10)#196608输入特征值数量,10输出特征值数量
模型编写
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.conv2d1=Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)
self.maxPool1 = MaxPool2d(2) # 池化的stride默认为kernel
self.conv2d2=Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2,stride=1)
self.maxPool2 = MaxPool2d(2)
self.conv2d3=Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2,stride=1)
self.maxPool3=MaxPool2d(2)
self.flatten=Flatten()
self.linear1=Linear(1024,64)
self.linear2=Linear(64,10)
def forward(self,input):
input=self.conv2d1(input)
input = self.maxPool1(input)
input=self.conv2d2(input)
input = self.maxPool2(input)
input=self.conv2d3(input)
input=self.maxPool3(input)
#展开
input= self.flatten(input)
#全连接
input=self.linear1(input)
output=self.linear2(input)
return output
mymodel=MyModule()
input=torch.ones((64,3,32,32))
output=mymodel(input)#torch.Size([64, 10])
使用sequential改写
# -*- coding: utf-8 -*-
# @Time : 2022/5/27 19:36
# @Author : PVINCE
# @File : NN_seq.py
# @desc:cifar10
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Flatten
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
mymodel = MyModule()
input = torch.ones((64, 3, 32, 32))
output = mymodel(input)
print(output.shape)
writer=SummaryWriter("logs_seq")
writer.add_graph(mymodel,input)
writer.close()
使用日志观察

使用数据
损失函数

https://pytorch.org/docs/stable/nn.html#loss-functions
要根据实际的需求去选择损失函数,注意输出和输入
nn.L1Loss |
Creates a criterion that measures the mean absolute error (MAE) between each element in the input xx and target yy. |
|---|---|
nn.MSELoss |
Creates a criterion that measures the mean squared error (squared L2 norm) between each element in the input xx and target yy. |
nn.CrossEntropyLoss |
This criterion computes the cross entropy loss between input and target. |
nn.CTCLoss |
The Connectionist Temporal Classification loss. |
nn.NLLLoss |
The negative log likelihood loss. |
nn.PoissonNLLLoss |
Negative log likelihood loss with Poisson distribution of target. |
nn.GaussianNLLLoss |
Gaussian negative log likelihood loss. |
nn.KLDivLoss |
The Kullback-Leibler divergence loss. |
nn.BCELoss |
Creates a criterion that measures the Binary Cross Entropy between the target and the input probabilities: |
nn.BCEWithLogitsLoss |
This loss combines a Sigmoid layer and the BCELoss in one single class. |
nn.MarginRankingLoss |
Creates a criterion that measures the loss given inputs x1x1, x2x2, two 1D mini-batch or 0D Tensors, and a label 1D mini-batch or 0D Tensor yy (containing 1 or -1). |
nn.HingeEmbeddingLoss |
Measures the loss given an input tensor xx and a labels tensor yy (containing 1 or -1). |
nn.MultiLabelMarginLoss |
Creates a criterion that optimizes a multi-class multi-classification hinge loss (margin-based loss) between input xx (a 2D mini-batch Tensor) and output yy (which is a 2D Tensor of target class indices). |
nn.HuberLoss |
Creates a criterion that uses a squared term if the absolute element-wise error falls below delta and a delta-scaled L1 term otherwise. |
nn.SmoothL1Loss |
Creates a criterion that uses a squared term if the absolute element-wise error falls below beta and an L1 term otherwise. |
nn.SoftMarginLoss |
Creates a criterion that optimizes a two-class classification logistic loss between input tensor xx and target tensor yy (containing 1 or -1). |
nn.MultiLabelSoftMarginLoss |
Creates a criterion that optimizes a multi-label one-versus-all loss based on max-entropy, between input xx and target yy of size (N, C)(N,C). |
nn.CosineEmbeddingLoss |
Creates a criterion that measures the loss given input tensors x_1x1, x_2x2 and a Tensor label yy with values 1 or -1. |
nn.MultiMarginLoss |
Creates a criterion that optimizes a multi-class classification hinge loss (margin-based loss) between input xx (a 2D mini-batch Tensor) and output yy (which is a 1D tensor of target class indices, 0 \leq y \leq \text{x.size}(1)-10≤y≤x.size(1)−1): |
nn.TripletMarginLoss |
Creates a criterion that measures the triplet loss given an input tensors x1x1, x2x2, x3x3 and a margin with a value greater than 00. |
nn.TripletMarginWithDistanceLoss |
Creates a criterion that measures the triplet loss given input tensors aa, pp, and nn (representing anchor, positive, and negative examples, respectively), and a nonnegative, real-valued function (“distance function”) used to compute the relationship between the anchor and positive example (“positive distance”) and the anchor and negative example (“negative distance”). |
L1Loss
https://pytorch.org/docs/stable/generated/torch.nn.L1Loss.html#torch.nn.L1Loss
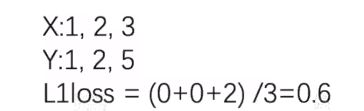
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 16:51
# @Author : PVINCE
# @File : nn_loss.py
#@desc:
import torch
from torch.nn import L1Loss
inputs=torch.tensor([1,2,3],dtype=torch.float32)
targets=torch.tensor([1,2,5],dtype=torch.float32)
inputs=torch.reshape(inputs,(1,1,1,3))
targets=torch.reshape(targets,(1,1,1,3))
loss=L1Loss(reduction='sum')
result=loss(inputs,targets)
print(result)#tensor(2.)
MSELoss 平方差
https://pytorch.org/docs/stable/generated/torch.nn.MSELoss.html#torch.nn.MSELoss
CrossEntropyLoss 交叉熵
https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss
案例
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 16:51
# @Author : PVINCE
# @File : nn_loss.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Flatten
from torch.nn import L1Loss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
# 开始训练
# 数据加载
dataset = torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
loss=nn.CrossEntropyLoss()
mymodel = MyModule()
for data in dataloader:
imgs,targets=data
outputs=mymodel(imgs)
result_loss=loss(outputs,targets)
result_loss.backward() #进行反向传播 获取当前梯度,拿到梯度后想办法降低梯度
print(result_loss)#tensor(2.2508, grad_fn=)
print("ok")
# writer=SummaryWriter("logs_seq")
# writer.add_graph(mymodel,input)
# writer.close()
优化器
https://pytorch.org/docs/stable/optim.html
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 16:51
# @Author : PVINCE
# @File : nn_loss.py
#@desc:使用交叉熵作为loss使用SGD作为优化器
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Flatten
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
# 开始训练
# 数据加载
dataset = torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
myModel = MyModule()
loss=nn.CrossEntropyLoss()
lr=1e-2 #学习率
optim=torch.optim.SGD(myModel.parameters(),lr=lr)
for epoch in range(20):#使用20轮循环
running_loss=0.0 #每一轮的loss
for data in dataloader:
imgs,targets=data
outputs=myModel(imgs)
result_loss=loss(outputs,targets)#计算loss
optim.zero_grad()#引入 使用优化器,对上一次的梯度清零
result_loss.backward() # 进行反向传播 获取当前梯度,拿到梯度后想办法降低梯度
optim.step()#调整参数
running_loss=running_loss+result_loss#求出总的loss
print(running_loss)
# writer=SummaryWriter("logs_seq")
# writer.add_graph(mymodel,input)
# writer.close()

一般的模型
https://pytorch.org/audio/0.8.0/models.html
VGG16
使用vgg网络作为前置的网络提取关键的信息,再去训练
https://pytorch.org/vision/0.9/models.html#id2
VGG16的模型架构如下:输出是1000的分类


使用数据集imgnet
https://pytorch.org/vision/0.9/datasets.html#imagenet

pip install scipy
在CIf10上使用VGG(改写)
输出1000改写为10
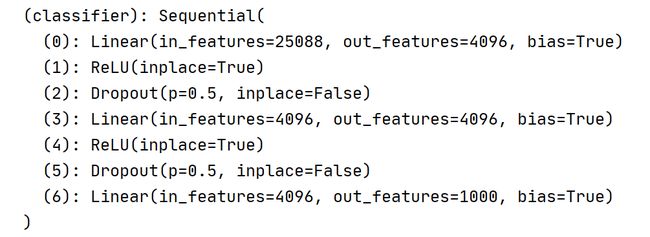

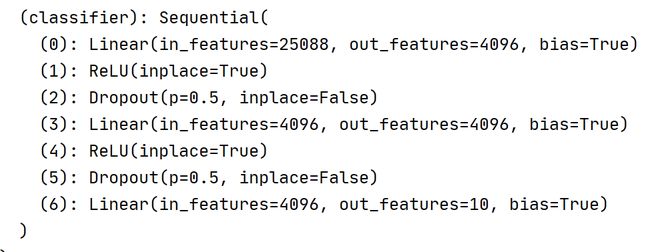
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 17:52
# @Author : PVINCE
# @File : model_pretrained.py
#@desc:加载预训练模型
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
import os
os.environ['TORCH_HOME']='E:/dev/torch_model' #设置vgg模型下载路径
vgg16_true=torchvision.models.vgg16(pretrained=True)
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
vgg16_false.classifier[6]=nn.Linear(4096,10)
print(vgg16_true)
print(vgg16_false)
模型的保存&加载
方式1
torch.save 保存模型的结构和模型参数,比较大
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:26
# @Author : PVINCE
# @File : nn_load.py
#@desc:模型的加载
import torch
model=torch.load("vgg16_false.pth")
print(model)
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:24
# @Author : PVINCE
# @File : nn_save.py
#@desc:模型的保存
import torchvision
from torch import nn
import torch
import os
os.environ['TORCH_HOME']='E:/dev/torch_model'
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_false.classifier[6]=nn.Linear(4096,10)
torch.save(vgg16_false,"vgg16_false.pth")

方式2
json:只是保存参数,官方推荐,占用内存小
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:29
# @Author : PVINCE
# @File : nn_save2.py
#@desc:保存模式2
import torch
import torchvision
#模型的保存
vgg16_false=torchvision.models.vgg16(pretrained=False)
torch.save(vgg16_false.state_dict(),"vgg16_false2.pth")
#模型的加载
model_dict=torch.load("vgg16_false2.pth")#打开的是字典的模式,故要新建网络模型结构
vgg16_false2=torchvision.models.vgg16(pretrained=False)
vgg16_false2.load_state_dict(model_dict)
模型训练方法
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:39
# @Author : PVINCE
# @File : 2_train.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
#模型
class MyModule1(nn.Module):
def __init__(self):
super(MyModule1, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
#数据集加载
train_data= torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data= torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度{},测试数据集长度{}.".format(test_data_size,test_data_size))
#使用dataloader
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
mymodel = MyModule1()
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#定义优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(mymodel.parameters(),lr=learning_rate)
#设置训练参数
total_train_step=0 #训练的次数
total_test_step=0 #测试的次数
epoch=10 #训练的轮数
for i in range(epoch):
print("----------第{}轮训练开始------------".format(i+1))
for data in train_dataloader:
imgs,targets=data
outputs=mymodel(imgs)
loss=loss_fn(outputs,targets)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
print("训练次数:{},loss:{}".format(total_train_step,loss))
打印内容
训练数据集长度10000,测试数据集长度10000.
----------第1轮训练开始------------
训练次数:1,loss:2.2796311378479004
训练次数:2,loss:2.297395706176758
模型达到需求?
使用测试数据集评估模型
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:39
# @Author : PVINCE
# @File : 2_train.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
#模型
from torch.utils.tensorboard import SummaryWriter
class MyModule1(nn.Module):
def __init__(self):
super(MyModule1, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
#数据集加载
train_data= torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data= torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度{},测试数据集长度{}.".format(test_data_size,test_data_size))
#使用dataloader
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
mymodel = MyModule1()
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#定义优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(mymodel.parameters(),lr=learning_rate)
#设置日志
writer=SummaryWriter("logs")
#设置训练参数
total_train_step=0 #训练的次数
total_test_step=0 #测试的次数
epoch=10 #训练的轮数
for i in range(epoch):
print("----------第{}轮训练开始------------".format(i+1))
for data in train_dataloader:
imgs,targets=data
outputs=mymodel(imgs)
loss=loss_fn(outputs,targets)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss))
#添加到日志
writer.add_scalar("Train_loss",loss,total_train_step)
# 测试开始
total_test_loss=0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = mymodel(imgs)
loss = loss_fn(outputs, targets)
total_test_loss=total_test_loss+loss
print("整体测试集的loss:{}".format(total_test_loss))
writer.add_scalar("Test_loss", total_test_loss,total_test_step)
total_train_step=total_test_step+1
torch.save(mymodel,"mymodel_{}.pth".format(i))
print("模型已保存")
writer.close()
正确数量

# -*- coding: utf-8 -*-
# @Time : 2022/5/28 19:24
# @Author : PVINCE
# @File : 统计.py
#@desc:
import torch
outputs=torch.tensor([[0.1,0.2],
[0.05,0.4]])
print(outputs.argmax(0))#tensor([0, 1]) 代表的意思是 竖着看 [0.1和0.05]大的idx是0 [0.2,0.4] 大的是0.4的idx=1
print(outputs.argmax(1))#tensor([1, 1])代表的意思是 横着看 [0.1和0.2]大的idx是1 [0.05,0.4] 大的是0.4的idx=1
preds=outputs.argmax(1)
targets=torch.tensor([0,1])#目标组
print((preds==targets).sum())#tensor(1) 代表 tensor([1, 1])和tensor([0,1]比较相等的只有一个,表示预测正确的是1个
加入统计
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:39
# @Author : PVINCE
# @File : 2_train.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
#模型
from torch.utils.tensorboard import SummaryWriter
class MyModule1(nn.Module):
def __init__(self):
super(MyModule1, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
#数据集加载
train_data= torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data= torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度{},测试数据集长度{}.".format(test_data_size,test_data_size))
#使用dataloader
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
mymodel = MyModule1()
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#定义优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(mymodel.parameters(),lr=learning_rate)
#设置日志
writer=SummaryWriter("logs")
#设置训练参数
total_train_step=0 #训练的次数
total_test_step=0 #测试的次数
epoch=10 #训练的轮数
for i in range(epoch):
print("----------第{}轮训练开始------------".format(i+1))
for data in train_dataloader:
imgs,targets=data
outputs=mymodel(imgs)
loss=loss_fn(outputs,targets)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss))
#添加到日志
writer.add_scalar("Train_loss",loss,total_train_step)
# 测试开始
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = mymodel(imgs)
loss = loss_fn(outputs, targets)
total_test_loss=total_test_loss+loss
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集正确率acc:{}".format(total_accuracy/test_data_size))
writer.add_scalar("Test_loss", total_test_loss,total_test_step)
total_train_step=total_test_step+1
torch.save(mymodel,"mymodel_{}.pth".format(i))
print("模型已保存")
writer.close()
Train()
当模型有dropout层和个别层的时候,要调用
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
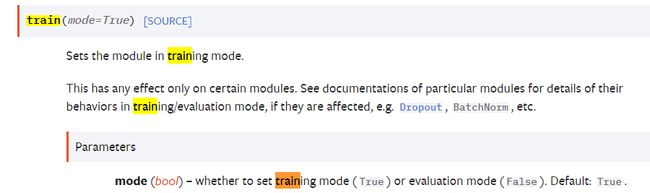
eval()

# -*- coding: utf-8 -*-
# @Time : 2022/5/28 18:39
# @Author : PVINCE
# @File : 2_train.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
#模型
from torch.utils.tensorboard import SummaryWriter
class MyModule1(nn.Module):
def __init__(self):
super(MyModule1, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
#数据集加载
train_data= torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data= torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度{},测试数据集长度{}.".format(test_data_size,test_data_size))
#使用dataloader
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
mymodel = MyModule1()
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#定义优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(mymodel.parameters(),lr=learning_rate)
#设置日志
writer=SummaryWriter("logs")
#设置训练参数
total_train_step=0 #训练的次数
total_test_step=0 #测试的次数
epoch=10 #训练的轮数
for i in range(epoch):
print("----------第{}轮训练开始------------".format(i+1))
mymodel.train()
for data in train_dataloader:
imgs,targets=data
outputs=mymodel(imgs)
loss=loss_fn(outputs,targets)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
print("训练次数:{},loss:{}".format(total_train_step,loss))
#添加到日志
writer.add_scalar("Train_loss",loss,total_train_step)
# 测试开始
mymodel.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = mymodel(imgs)
loss = loss_fn(outputs, targets)
total_test_loss=total_test_loss+loss
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集正确率acc:{}".format(total_accuracy/test_data_size))
writer.add_scalar("Test_loss", total_test_loss,total_test_step)
total_train_step=total_test_step+1
torch.save(mymodel,"mymodel_{}.pth".format(i))
print("模型已保存")
writer.close()
GPU1
- 模型
- lossFn
- 数据
- .cuda()
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 19:42
# @Author : PVINCE
# @File : 使用GPU训练.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
import time
#模型
from torch.utils.tensorboard import SummaryWriter
cuda_isAvailable=torch.cuda.is_available()
class MyModule1(nn.Module):
def __init__(self):
super(MyModule1, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
#数据集加载
train_data= torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data= torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度{},测试数据集长度{}.".format(test_data_size,test_data_size))
#使用dataloader
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
mymodel = MyModule1()
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#转移到cuda
if cuda_isAvailable:
mymodel=mymodel.cuda()
loss_fn=loss_fn.cuda()
#定义优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(mymodel.parameters(),lr=learning_rate)
#设置训练参数
total_train_step=0 #训练的次数
total_test_step=0 #测试的次数
epoch=10 #训练的轮数
#设置日志
writer=SummaryWriter("logs")
start_time=time.time()
for i in range(epoch):
print("----------第{}轮训练开始------------".format(i+1))
mymodel.train()
for data in train_dataloader:
imgs,targets=data
# 转移到GPU
if cuda_isAvailable:
imgs=imgs.cuda()
targets=targets.cuda()
outputs=mymodel(imgs)
loss=loss_fn(outputs,targets)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
end_time = time.time()
print("时间花费:{}".format(end_time-start_time))
print("训练次数:{},loss:{}".format(total_train_step,loss))
#添加到日志
writer.add_scalar("Train_loss",loss,total_train_step)
# 测试开始
mymodel.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = mymodel(imgs)
loss = loss_fn(outputs, targets)
total_test_loss=total_test_loss+loss
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集正确率acc:{}".format(total_accuracy/test_data_size))
writer.add_scalar("Test_loss", total_test_loss,total_test_step)
total_train_step=total_test_step+1
torch.save(mymodel,"mymodel_{}.pth".format(i))
print("模型已保存")
writer.close()
GPU2
使用谷歌的GPu
https://colab.research.google.com/
- .to(device)
- Device = torch.device("cpu”)
- lorch.device("cuda”)
- Torch.device( "cuda:0”)
- Torch.device( "cuda:1”)
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 19:42
# @Author : PVINCE
# @File : 使用GPU训练.py
#@desc:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
import time
#模型
from torch.utils.tensorboard import SummaryWriter
cuda_isAvailable=torch.cuda.is_available()
#定义训练的设备
device=torch.device("cuda")
class MyModule1(nn.Module):
def __init__(self):
super(MyModule1, self).__init__()
self.model1 = nn.Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2), # 池化的stride默认为kernel
Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2, stride=1),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, input):
output=self.model1(input)
return output
#数据集加载
train_data= torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data= torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集长度{},测试数据集长度{}.".format(test_data_size,test_data_size))
#使用dataloader
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
mymodel = MyModule1()
#定义损失函数
loss_fn=nn.CrossEntropyLoss()
#转移到cuda
if cuda_isAvailable:
mymodel=mymodel.cuda()
loss_fn=loss_fn.cuda()
# mymodel=mymodel.to(device)
# loss_fn=loss_fn.to(device)
#定义优化器
learning_rate=1e-2
optimizer=torch.optim.SGD(mymodel.parameters(),lr=learning_rate)
#设置训练参数
total_train_step=0 #训练的次数
total_test_step=0 #测试的次数
epoch=10 #训练的轮数
#设置日志
writer=SummaryWriter("logs")
start_time=time.time()
for i in range(epoch):
print("----------第{}轮训练开始------------".format(i+1))
mymodel.train()
for data in train_dataloader:
imgs,targets=data
# 转移到GPU
if cuda_isAvailable:
imgs=imgs.cuda()
targets=targets.cuda()
# imgs = imgs.to(device)
# targets = targets.to(device)
outputs=mymodel(imgs)
loss=loss_fn(outputs,targets)
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
end_time = time.time()
print("时间花费:{}".format(end_time-start_time))
print("训练次数:{},loss:{}".format(total_train_step,loss))
#添加到日志
writer.add_scalar("Train_loss",loss,total_train_step)
# 测试开始
mymodel.eval()
total_test_loss=0
total_accuracy=0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = mymodel(imgs)
loss = loss_fn(outputs, targets)
total_test_loss=total_test_loss+loss
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集的loss:{}".format(total_test_loss))
print("整体测试集正确率acc:{}".format(total_accuracy/test_data_size))
writer.add_scalar("Test_loss", total_test_loss,total_test_step)
total_train_step=total_test_step+1
torch.save(mymodel,"mymodel_{}.pth".format(i))
print("模型已保存")
writer.close()
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
使用现成的模型
重点:
import os
os.environ['TORCH_HOME']='E:/dev/torch_model' #设置vgg模型下载路径
image=torch.reshape(image,(1,3,32,32))
#在gpu训练的模型,加载在cpu运行需要指定map_location
model=torch.load("mymodel.pth",map_location=torch.device('cpu'))
model.eval()
with torch.no_grad():
# -*- coding: utf-8 -*-
# @Time : 2022/5/28 20:11
# @Author : PVINCE
# @File : test.py
#@desc:
import torch
from PIL import Image
from torch import nn
from torchvision import transforms
# 搭建模型
class MymModel(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,16,(5,5),(1,1),padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16,64,(3,3),(1,1),padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64,128,(3,3),(1,1),padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 256, (3, 3), (1, 1), padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(256*8*8,400),
nn.Dropout2d(p=0.2),
nn.Linear(400,10)
)
def forward(self,x):
x = self.model(x)
return x
image_path="./dataset/cat.jpg"
image=Image.open(image_path)
image=image.convert("RGB")
print(image)
transform=transforms.Compose([transforms.Resize((32,32)),
transforms.ToTensor()])
image=transform(image)
print(image.shape)
image=torch.reshape(image,(1,3,32,32))
#在gpu训练的模型,加载在cpu运行需要指定map_location
model=torch.load("mymodel.pth",map_location=torch.device('cpu'))
model.eval()
with torch.no_grad():
output=model(image)
print(output)
print(output.argmax(1))
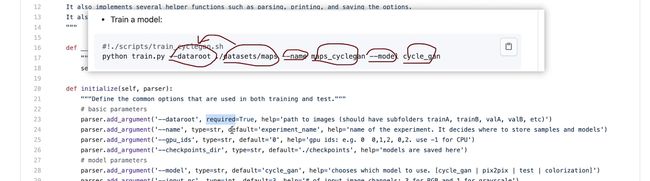
开源仓库
命令行参数可以修改,把required删除或写一个default