《Monolingual and Cross-Lingual Intent Detection without Training Data in Target Languages》论文的研读
原文出处:英文原文
由于文章的篇幅较长,本文主要翻译了摘要 引言以及结论部分,方法以及结果部分捡重点进行翻译研读,有不恰当之处,敬请指导和交流!
此外本文的相关工作部分总结的比较完善,本文也会进一步进行归纳。
目录
摘要
1 引言
2 与论文相关的工作
2.1 在ATIS语料库上进行的研究
2.2 在SNIPS数据集上的相关的工作
2.3 在其他数据集上面的探索
2.4 意图检测的其他用途
2.5 少样本(few-shot)意图检测研究
2.6 同一个语句多种意图的识别的研究
2.7 多语言意图识别方向的研究
3 方法
3.1 数据集
3.2 使用的方法
4 部分结果与分析
5 结论
摘要
【现状】近些年来,由于DNN的发展,使用基于transformer-based模型和监督数据可以有效地解决许多NLP问题。
【问题】然而,某些语言是没有充足的数据集。
【研究前提】本文研究基于以下假设:(1)训练数据可以通过机器从另一种语言翻译得到;(2)有些跨语言解决方案无需目标语言的训练数据就可以工作。
【研究内容】在本研究中使用英语数据集,同时解决了五种目标语言(德语、法语、立陶宛语、拉脱维亚语和葡萄牙语)的意图检测问题。在寻找最准确的答案时,本文联合积极学习分类器(eager learning classifiers 如CNN, BERT微调,FFNN)和惰性学习方法( lazy learning approach,余弦相似度作为基于记忆的方法)研究了基于BERT的词和句子transformers。随后,本文提供并评估了几种策略,以克服机器翻译、跨语言模型和这两者结合的任务中数据稀缺的问题。
【研究结果】实验研究表明句子transformers在不同的跨语言条件下具有鲁棒性。用完全单语模型的英语数据集实现的精度为~0.842;本文的跨语言方法也显示出相似的准确度,在德语、法语、立陶宛语、拉脱维亚语和葡萄牙语上达到~0.831、~0.829、~0.853、~0.831和~0.813。
1 引言
【背景】在自然语言处理(NLP)领域中在深度神经网络(DNN)取得的推动下,聊天机器人在实时客户服务[1]中越来越受欢迎。聊天机器人的研究领域已经有很长的历史,可以追溯到1966年[2]。麻省理工学院人工智能实验室推出的第一款聊天机器人ELIZA经过调整,可以与有心理问题的人交流。ELIZA检查用户输入的关键词,并根据一组预定义的规则提示答案。如今,聊天机器人被广泛应用于市场营销、教育、医疗保健和其他行业。他们甚至被应用在互动剧院表演娱乐中[3]。然而,这场新冠疫情大流行尤其展示了在新闻媒体、医院或医疗保健系统中用于管理大量涌入问题的聊天机器人的必要性。
根据输入处理方式和响应性质可以判断聊天机器人是基于生成的还是基于意图检测的。生成式聊天机器人通常需要大量的训练数据,并且可以学习如何从这些数据中生成回应。基于意图检测的聊天机器人具有分类器的功能,因此仅限于预定义的响应。尽管有先进的算法,但在真实的用户对话场景中,任何这些聊天机器人都无法避免失败的。相比之下,基于意愿检测的机器人比基于生成的更健壮,通常用于生产聊天机器人,这将作为本文的研究方向。
聊天机器人由四个不同的组件组成:自然语言理解(NLU)(负责理解用户请求的含义和结构)、对话管理(控制对话的顺畅流动)、内容(聊天机器人必须如何响应的模板)和外部数据(从外部web服务或数据库提取数据)。然而,如果不理解用户的请求,那么所有其他组件都是次要的。因此,本研究的重点是改进NLU组件。
【研究内容】自然语言处理领域以资源丰富的英语研究为主,并且以英语为基础研究展开了许多研究,但是,哪些不太流行或资源较少的语言也同样需要关注并寻求较好的问题解决或理解的方法。因此,本研究的目标是找到解决多语言问题的措施。一种简单的方法是选择可用的基准英语数据集,随后将它们翻译为目标语言。此时,研究所依赖的假设是,机器翻译不会扭曲数据到显著降低其质量而不适合训练NLU模型的程度。我们甚至假设这个问题可以在没有机器翻译的情况下解决,只需要使用能够捕获句子语义的多语言转换器(如预先训练的向量化模型)。
【研究对象】本文选择了英语、德语、法语、立陶宛语、拉脱维亚语和葡萄牙语作为我们的目标语言。这样的选择是有目的的:它包括不同的语系(日耳曼语、罗曼斯语和波罗的海语),涵盖了拥有不同数量资源的语言。
2 与论文相关的工作
2.1 在ATIS语料库上进行的研究
语料库详情:语音记录,17个意图类别,每句话11个单词,训练集、验证集与测试集分别有4478、500和893个语句组成。
相关研究:
| 方法 | 意图识别精度(最优) | 是否与槽位填充联合训练 |
| Bi-model based RNN semantic frame parsing approach | ~0.99 | 是 |
| transformer-capsule model(GloV e embeddings+transformer encoder +capsule network) | ~0.98 | -- |
| Attention BiRNN | ~0.95 | 是 |
| BERT-based | ~0.98 | 是 |
2.2 在SNIPS数据集上的相关的工作
语料库详情:语音记录,7个意图类别,每句话约9个单词,1.6万众包询问。
相关研究:
| 方法 | 意图识别精度(最优) | 是否与槽位填充联合训练 |
| BERT-based stack-propagation framework | ~0.97 | 是 |
| BiLSTM 考虑上下文 | ~0.94 | 是 |
| 改进的BiLSTM | ~0.92 | 是 |
当数据集确定时,一些研究人员则通过扩展数据资源的方式来提高精度,对ATIS和SNIPS数据集注入扰动输入(对抗示例)形成新的数据集,随后联合解决意图检测和槽位填充任务,开发了对抗训练方法对抗训练方,使得设计的模型更加健壮。模型组成:将LSTM encoder-decoder与stacked CRF 应用在BERT-large embedding model的顶层之上。
2.3 在其他数据集上面的探索
语料库详情:HWU64(包含约2.57万个实例,64个意图,每个实例7个单词),CLINC150(约2.37万个实例,150个意图,每个实例8个单词),以及BANKING77(约1.3万个客户服务查询,77个意图,每个实例12个单词)。这三种数据集的特点就是意图更多更复杂。
研究建议使用对偶句子编码器(dual sentence encoders),这种编码器能够从输入/上下文和relevel响应之间的交互中进行学习,从而封装会话知识。例如,可以使用USE(通用句子编码器)和ConverRT来支持意图检测。实验研究表明,对偶嵌入优于固定或微调BERT-large模型,这在较小的意图(覆盖~ 10-30例)尤其明显。
2.4 意图检测的其他用途
为了解决电子邮件超载的问题,作者[18]将它们分为两类:“阅读”或“做”。作者对上下文无关词嵌入(word2vec和GloVe)、上下文词嵌入(ELMo和BERT)和句子嵌入(DAN-based USE和Transformer-based USE)进行了测试,证明了ELMo的优势,其次对比了基于transformer的USE和基于dan的USE。结果证明句子嵌入对于目标检测是非常有用的。
2.5 少样本(few-shot)意图检测研究
之前总结的研究都是集中在意图种类的情况下,对语句所包含意图的识别。这一部分作者总结了在新的分类下,对标签数据中意图缺少(few-shot intent)情况下的目标识别研究方法。
1、一种是基于Bi-LSTM的语义匹配和聚合网络方法。该方法通过附加动态正则化约束的多头自我注意从话语中提取语义成分。通过实验将他们提供的方法与另外6种方法(匹配网络、原型网络、关系网络、混合注意力原型网络、分层原型网络、多层次匹配和聚合网络)进行了比较,证明他们的方法在两个数据集上都取得了最好的性能。
2、另一种方法是利用双重伪标记技术。伪标记过程将嵌入的用户话语传递给分层聚类方法(自下而上的树状结构),然后由上而下形成树状结构,扩展具有多个不同标签的被标记句子的节点。一旦伪标签被检索,该方法执行BERT微调的意图检测,这是一个常见的解决意图检测问题的方案。
2.6 同一个语句多种意图的识别的研究
作者在[21]中使用自适应图交互框架方法解决了联合多种意图检测和槽位填充的问题。首先,使用自注意的Bi-LSTM编码器进行语句的表示,然后将其传递给多标签意图检测解码器,由其利用自注意计算上下文向量。然后,自适应意图-槽图交互层利用多个意图的信息进行槽位预测。除了提供的方法之外,作者还测试了五种最先进的方法(Attention BiRNN, Slot-Gated Atten, Bi-Model, SF-ID Network, Stack-Propagation),证明他们提供的方法在MixATIS和MixSNIPS数据集(近似于ATIS和SNIPS版本,但包含多个意图)具有优越性。无论是few-shot还是multi意图问题,都有超越常见意图检测问题的附加机制。
2.7 多语言意图识别方向的研究
最后作者总结了多语言意图识别方向的研究,即跨语言的方法。主要梳理如下:
- 【方法】fastText+卷积神经网络(CNN)进行embedding;BiLSTM作为编码器;用于意图检测的多层感知器MLP和用于NER的CRF序列标记器作为两个解码器。【迁移策略】a、编码器和解码器都迁移并微调;b、仅迁移编码器,不微调;c、仅迁移编码器并解冻部分训练步骤,进行微调。【数据集】英语(约220万个语句,316个意图和282个槽位)、西班牙语(约300万个语句,365个意图,311个槽位、意大利语(约2.5个语句,379个意图,324个槽位)和印地语(约40万个语句,302个意图,267个槽位)数据集。【结果】在所有使用迁移学习的模型中,性能都有改善,其中编码器迁移的改善最大。
- 【方法】方法是具有self-attention的Bi-LSTM层和条件随机场(CRF)层。该方法通过作者训练的几种类型的词嵌入(zero、XLU、编码器、CoVe、多语言CoVE和多语言CoVE +自动编码器)和可用的西班牙语预训练的ELMo编码器进行测试。【结果】数据资源有限的语言将从跨语言学习中受益。尽管如此,多语言上下文单词表示还是优于跨语言静态嵌入。
- 该方法首先发布了一个【数据集】:包括英语、西班牙语、法语和德语中16个COVID-19特定意图的约69000个句子。【研究内容】(1)单语言和多语言模型基线;(2)从英语到西班牙语、法语和德语的跨语言迁移;(3)西班牙英语的zero-shot CS。文中对fastText、XLM-R和ELMo嵌入进行了测试。【结果】在zero-setting下获得较低的结果,XLM-R跨语言句子嵌入明显优于文中提到的其他方法。
- 【方法】发展了基于XLM-R的语言模型,首次在不降低每种语言性能的情况下提出了多语言建模。它证明了预训练的多语言模型的鲁棒性,能够显著提升跨语言迁移任务的性能,如自然语言推断(15种语言),NER(英语,荷兰语,西班牙语和德语),问题回答(英语,西班牙语,德语,阿拉伯语,印地语,越南语和汉语)。【结果】XLM-Rbase (L = 12, H = 768, A = 122.7亿参数)和XLM-R (L = 24, H = 1024, A = 165.5亿参数)模型在跨语言任务中明显优于mBERT,在资源匮乏的语言中表现尤其出色。
总之,啰啰嗦嗦总结了这么多,本文的主要目的就是发展一种多语言意图检测的方法,该方法不需要对目标语言中的训练数据集进行标注。
3 方法
3.1 数据集
本文以英语(EN)作为基础数据集,同时文中还选择了一种日耳曼语言(即德语(DE))、两种罗曼语系语言(法语(FR)和葡萄牙语(PT))以及两种波罗的海语系语言(立陶宛语(LT)和拉脱维亚语(LV)),它们在形态学、派生体系、句式结构等特征上存在差异。表1所示的是从Tildes BiurasAPP上获取的EN的原始数据集。表2种所示的是基于原始的数据集EN,使用谷歌机器翻译翻译成DE、FR、LT、LV和PT语言用作训练数据集,而测试数据集是手动翻译成DE、FR、LT、LV和PT语言。这样做的目的是:即使机器翻译不是很精确,但是句子主要的意思能够被保存下来,因此,机器翻译是形成训练数据集的一种可靠方法。测试数据集是手动翻译的,因为意图检测模型通常由真实用户用他们的语言编写问题来测试。


3.2 使用的方法
文中描述本文主要的目的是找到文本表示(text representation )和分类技术(classification techniques)的最佳结合。
- 词嵌入(word embedding):本文研究了四种英语单语的BERT模型、即BERT -base-cased、BERT -base-uncase、BERT -large-cased和bert-large-uncase。base模型和large模型的区别在于堆叠的编码器层数(base模型和large模型分别为12和24)、attention heads(12和16)、参数(1.1亿和3.4亿)和隐藏层(768和1024)。Cased模型对字母大小写敏感,反之,uncased模型则不敏感。论文模型相关的网站 这些模型就是下文的BERT-w
- 句子嵌入(sentence embedding):本文研究了4个单语英语句子嵌入模型:roberta-base-nli-stsb-mean-tokens, roberta-large-nli-stsb-mean-tokens, bert-large-nli-stsb-mean-tokens, distilbert-base-nli-stsb-mean-tokens以及四个多语句子嵌入模型: distiluse-base-multilingual-cased-v2, xlm-r-distilroberta-base-paraphrase-v1, xlm-r-bert-base-nli-stsb-mean-tokens, distilbert-multilingual-nli-stsb-quora-ranking模型相关的网站这些模型就是下文的BERT-s
在意图检测部分使用下面的方法:
- BERT-w + CNN:将卷积神经网络(CNN)分类器应用于级联BERT词嵌入之上;
- BERT-w + BERT
- BERT-s + FFNN:BERT句子嵌入作为特征输入前馈神经网络(FFNN)作为分类器;
- BERT-s + COS: 与前面描述的基于分类的方法不同,这种方法不学习任何通用模型。它只是存储所有训练数据,并计算测试实例和所有训练实例之间的相似性,测试实例被赋予与相似度最大的训练实例的标签。利用余弦相似度计算句子嵌入之间的相似度
为了解决数据稀缺问题,前面描述的机器学习方法将使用以下策略形成的训练数据进行训练:
- Monolingual machine-translated 单语机器翻译(简称MT-based):训练和测试均以同一目标语言进行。这些实验将展示在机器翻译数据上训练的单语模型的性能(例如:在表2中,训练数据为DE,则测试数据也为DE)。
- Cross-lingual跨语言:在这种情况下,只在EN训练数据集上进行训练,而在其他目标语言的测试数据集上进行测试(例如:DE, FR, LT, LV , 和 PT),这些实验完全不使用机器翻译的训练数据,而是依赖于多语言BERT模型。这将测试基于bert的模型捕捉不同语言编写的相同文本之间的语义相似性的能力(例如,在表2中,训练数据为EN,则测试数据为DE, FR, LT, LV , 或 PT)。
- 以上两者的结合:这些实验结合了前面的两种方法:训练在两种语言的两个数据集上进行,即原始英文加上机器翻译的目标语言(例如:在表2中,训练数据为EN+DE,测试数据为DE)。这样的实验将揭示两种训练数据准备方法是否互补。这也将有助于回答以下问题:仅仅依赖基于bert的模型是否足够,或者机器翻译器的角色(或用目标语言训练数据)是否至关重要。
-
Cross-lingual without any target language data:在这种情况下,对所有语言的所有训练数据集进行训练,包括对EN的手工训练和对其他语言的机器翻译,但必须排除目标语言(例如:在表2中,训练数据为EN+DE+LT+LV,测试数据为PT)。这表示无法获得目标语言数据(即使是机器翻译的)的场景。我们提出,通过对被机器翻译成多种其他语言的数据进行训练,我们可以在基于bert的模型中促进语言之间的语义接口。在成功的情况下,这些实验对无法获得机器翻译数据或质量很差的语言尤其有益。
4 部分结果与分析

MT-based策略下BERT-w + CNN、BERT-w + BERT、BERT-s + FFNN和BERT-s + COS的最佳准确率+置信区间。虚线将(在同一种语言中)获得的最佳准确性与统计上差异不显著的准确性联系在一起。EN结果是在原始数据上获得的,并表示最好的效果(top-line),该结果用作与其他识别结果的比较。
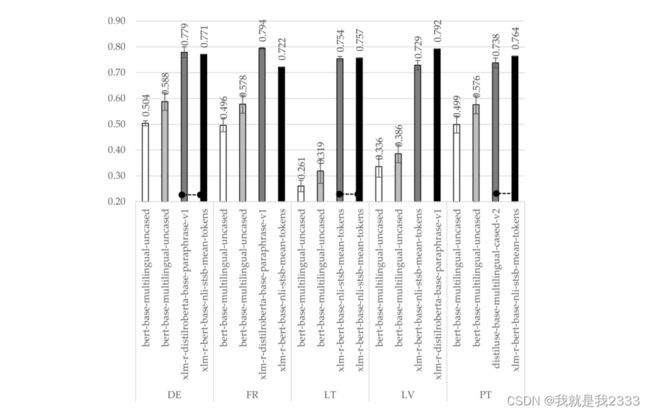
在Cross-lingual跨语言策略下BERT-w + CNN、BERT-w + BERT、BERT-s + FFNN和BERT-s + COS的最佳准确率+置信区间。

在组合策略训练的BERT-s + FFNN和BERT-s + COS模型的最佳精度+置信区间。

在Cross-lingual without any target language data策略下BERT-s + FFNN和BERT-s + COS的最佳准确率+置信区间。
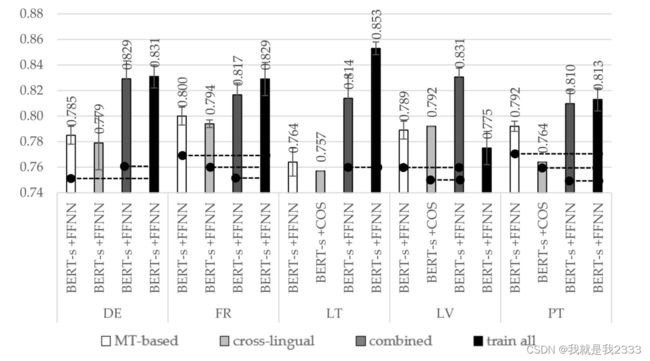
不同语言在不同条件下的最佳准确度+置信区间。
更加详细的结果大家可以移步论文的附件A中查看。
5 结论
利用两种BERT-based的矢量化模型(即单词和句子嵌入)、三个急切学习分类器(CNN、BERT微调、FFNN)和一种惰性学习方法(余弦相似度作为基于记忆的方法)来解决意图检测问题。通过测试以下训练数据使用策略来解决标注的数据短缺问题:MT-based(依赖于机器翻译的训练数据)、跨语言(单独训练英语)、结合(英语+目标语言一起训练)和训练所有(跨语言补充除目标语言外的多种语言的机器翻译实例)。实验结果表明,综合训练所有策略对五种目标语言均具有优越性。实验结果表明句子转换算法优于词嵌入算法,特别是,FFNN应用于BERT-based的句子嵌入之上。
英语语言数据集上的最佳精度为~0.842(这也是本文最好的数据),是通过完全单语模型(单语矢量化和单语分类方法)实现的。然而,在没有原始训练数据集的情况下,其他语言如德语、法语、立陶宛语、拉脱维亚语和葡萄牙语的精度分别为~0.831、~0.829、~0.853、~0.831和~0.813。
以上就是小编对本论文的简单罗列,详细的结果分析这里就不多赘述了,欢迎大家一起探讨哦。