SpringBoot+Sharding-JDBC+MyBatisPlus进行多数据源分表操作
SpringBoot+Sharding-JDBC+MyBatisPlus进行多数据源分表操作
文章目录
-
- SpringBoot+Sharding-JDBC+MyBatisPlus进行多数据源分表操作
- 1.前言
-
- 1.1什么是Sharding-JDBC?什么是分库分表?为什么要分库分表?
- 1.2关于个人学习的说明
- 2.创建工程环境
-
- 2.2搭建环境
- 2.3创建数据库
- 2.4配置application.properties文件
- 2.5自定义的分表逻辑类
- 3.编写增删改查业务代码
-
- 3.1利用MyBatisPlus逆向工程生成代码
1.前言
1.1什么是Sharding-JDBC?什么是分库分表?为什么要分库分表?
可查看本片博客以及官网:
① Apache——ShardingSphere(分布式数据库中间件、对于分库分表的操作利器)
②ShardingSphere官网
1.2关于个人学习的说明
首先推荐两篇高质量博客:
③ SpringBoot+Sharding-JDBC操作分库分表(超超超详细)
④ 使用ShardingJDBC实现按时间维度分表轻松支撑千万级数据
由于需要自己做一个demo,所以在学习的过程中,也是借鉴了上述文章的很多内容,如果对大家看了博客①,就知道这里比较难处理的地方是水平分表的过程中如何选择分片建和分片策略,所以博客③和博客④分别对以id字段和date字段进行分表操作做了详细阐述。
第二点是,自己的案例没有涉及到垂直分表,公共表,读写分离等等其他的内容,有需要的同学请参考官网以及上述博客进行学习
2.创建工程环境
2.2搭建环境
1.基础环境:
springboot2 +sharding-jdbc+mybatisplus
另外我使用了swagger2编写接口文档,目的是方便测试接口
2.创建springboot工程,pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sharding-jdbc-4.0.0.rc1</groupId>
<artifactId>com.xiao</artifactId>
<version>1.0-SNAPSHOT</version>
<description>sharding-jdbc-4.0.0.rc1 </description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.3.RELEASE</version>
<relativePath/>
</parent>
<properties>
<java.version>1.8</java.version>
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version>
<swagger.version>2.7.0</swagger.version>
<mybatis-plus.version>3.1.0</mybatis-plus.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!--添加 代码生成器 依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- velocity 模板引擎, Mybatis Plus 代码生成器需要 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>
<!--数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--数据库连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--分表分库依赖-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
<scope>compile</scope>
</dependency>
<!-- swagger -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>${swagger.version}</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-spring-ui</artifactId>
<version>3.0.2</version>
</dependency>
<!--其他依赖-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
这里关于分库分表操作需要引入的依赖如下:
<!--数据库连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!--分表分库依赖-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
2.3创建数据库
1.创建数据库ds0和ds1
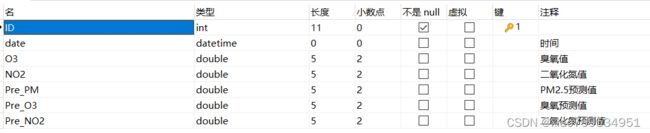
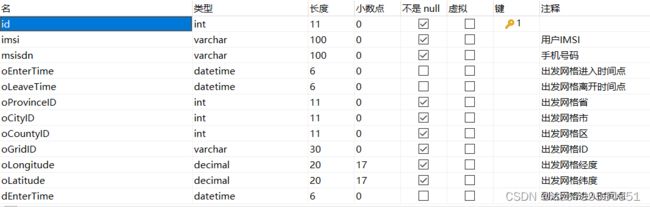
2.在ds0中我创建了三个表psim,user,station,其中psim和user进行分表操作,station当做单表,在ds1中创建表od
3.数据库结构:
ds0:
psim_{2021_1…2022_12}
user_{0…1}

station
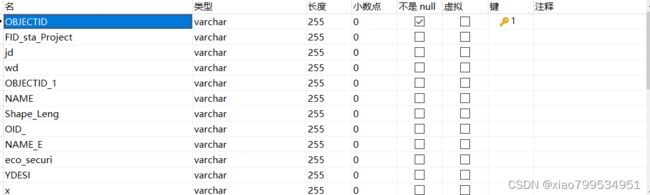
ds1:
od_{1…20}
2.4配置application.properties文件
这里可以参照官网配置手册:
官网Sharding-JDBC的springboot配置手册
# 服务端口
server.port=8080
# 配置数据源,给数据源起名ds0,ds1...此处可配置多数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 数据源ds0
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0?useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 数据源ds1
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1?useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
###分表策略(逻辑表为psim)
spring.shardingsphere.sharding.tables.psim.actual-data-nodes.=ds0.psim_$->{2021..2022}_$->{1..12}
#分片策略(用于单分片键的标准分片场景)
spring.shardingsphere.sharding.tables.psim.table-strategy.standard.sharding-column=date
spring.shardingsphere.sharding.tables.psim.table-strategy.standard.precise-algorithm-class-name=com.xiao.ds.config.DatePreciseShardingAlgorithm
spring.shardingsphere.sharding.tables.psim.table-strategy.standard.range-algorithm-class-name=com.xiao.ds.config.DateRangeShardingAlgorithm
###分表策略(逻辑表为user)
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_$->{0..1}
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#分片策略(行表达式分片策略)
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 2}
###分表策略(逻辑表为od)
spring.shardingsphere.sharding.tables.od.actual-data-nodes.=ds1.od_$->{1..20}
spring.shardingsphere.sharding.tables.od.key-generator.column=id
spring.shardingsphere.sharding.tables.od.key-generator.type=SNOWFLAKE
#分片策略(行表达式分片策略)
spring.shardingsphere.sharding.tables.od.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.od.table-strategy.inline.algorithm-expression=od_$->{id % 20}
# 绑定表规则列表, 多个用逗号隔开
spring.shardingsphere.sharding.binding-tables=psim,user,od
#返回json的全局时间格式
spring.jackson.date-format=yyyy-MM-dd HH:mm:ss
spring.jackson.time-zone=GMT+8
#打印sql
spring.shardingsphere.props.sql.show=true
我们拆分来看,首先是配置数据源部分:
# 配置数据源,给数据源起名ds0,ds1...此处可配置多数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 数据源ds0
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0?useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=123456
# 数据源ds1
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1?useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=123456
数据库连接池可以用其他类型如c3p0,dbcp等,但需要导入相应的依赖,我这里配置了两个数据源,需要配置多个数据源按照上面的添加即可。
接下来是重点部分:
###分表策略(逻辑表为psim)
spring.shardingsphere.sharding.tables.psim.actual-data-nodes.=ds0.psim_$->{2021..2022}_$->{1..12}
#分片策略(按日期分类)
spring.shardingsphere.sharding.tables.psim.table-strategy.standard.sharding-column=date
spring.shardingsphere.sharding.tables.psim.table-strategy.standard.precise-algorithm-class-name=com.xiao.ds.config.DatePreciseShardingAlgorithm
spring.shardingsphere.sharding.tables.psim.table-strategy.standard.range-algorithm-class-name=com.xiao.ds.config.DateRangeShardingAlgorithm
首先psim表我的分表策略是按照日期字段分类,第一行配置的官网解释为:
由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
第二行配置填分片列的名称,即你是按照该表的哪一个字段进行分片
第三行配置的官网解释为:
精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器
第四行配置的官网解释为:
范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器
对于我个人的理解,也就是说,当我们不是以id字段来分类时,就需要使用第三,四行配置,即需要自定义相应的算法来实现分片策略
user表的分片策略是按照id字段分类:
###分表策略(逻辑表为user)
spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_$->{0..1}
spring.shardingsphere.sharding.tables.user.key-generator.column=id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#分片策略(行表达式分片策略)
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 2}
第二行填自增列名称,第三行官网解释为:
自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
第四行填分片列名称,第五行官网解释为:
分片算法行表达式,需符合groovy语法
2.5自定义的分表逻辑类
1.DatePreciseShardingAlgorithm
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
import java.util.Date;
public class DatePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Date> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> preciseShardingValue) {
Date date = preciseShardingValue.getValue();
String suffix = ShardingUtils.getSuffixByYearMonth(date);
for (String tableName : availableTargetNames) {
if (tableName.endsWith(suffix)) {
return tableName;
}
}
throw new IllegalArgumentException("未找到匹配的数据表");
}
}
该类实现了PreciseShardingAlgorithm接口,用于条件精确匹配时的表路由(=和in)。availableTargetNames就是我们在配置中配的actual-data-nodes,preciseShardingValue.getValue()获取到的是我们执行sql传递的时间参数
2.DateRangeShardingAlgorithm
import com.google.common.collect.Range;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.*;
@Slf4j
public class DateRangeShardingAlgorithm implements RangeShardingAlgorithm<Date> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Date> rangeShardingValue) {
List<String> list = new ArrayList<>();
log.info("availableTargetNames : " + availableTargetNames);
log.info(rangeShardingValue.toString());
Range<Date> valueRange = rangeShardingValue.getValueRange();
Date lowerDate = valueRange.lowerEndpoint();
Date upperDate = valueRange.upperEndpoint();
String lowerSuffix = ShardingUtils.getSuffixByYearMonth(lowerDate);
String upperSuffix = ShardingUtils.getSuffixByYearMonth(upperDate);
TreeSet<String> suffixList = ShardingUtils.getSuffixListForRange(lowerSuffix, upperSuffix);
for (String tableName : availableTargetNames) {
if (containTableName(suffixList, tableName)) {
list.add(tableName);
}
}
log.info("match tableNames-----------------------" + list.toString());
return list;
}
private boolean containTableName(Set<String> suffixList, String tableName) {
boolean flag = false;
for (String s : suffixList) {
if (tableName.endsWith(s)) {
flag = true;
break;
}
}
return flag;
}
}
该类实现了RangeShardingAlgorithm接口,用于条件范围匹配时的路由(between、<、>等)。valueRange.lowerEndpoint()和valueRange.upperEndpoint()表示分别获取范围的上下边接,根据这两个时间的跨度去计算目标表的后缀,然后在可用的表中选取路由的目标表。
另外需要提供DataUtils和ShardingUtils的两个工具类,至此环境搭建完成,可以编写增删改查业务代码了
3.编写增删改查业务代码
3.1利用MyBatisPlus逆向工程生成代码
逆向工程需要的依赖如下:
<!--mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!--添加 代码生成器 依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- velocity 模板引擎, Mybatis Plus 代码生成器需要 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>
编写配置类
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
import org.junit.Test;
public class CodeGenerator {
@Test
public void run() {
// 1、创建代码生成器
AutoGenerator mpg = new AutoGenerator();
// 2、全局配置
GlobalConfig gc = new GlobalConfig();
String projectPath = System.getProperty("user.dir");
gc.setOutputDir(projectPath + "/src/main/java");
gc.setAuthor("xiaoYL");
gc.setOpen(false); //生成后是否打开资源管理器
gc.setFileOverride(false); //重新生成时文件是否覆盖
gc.setServiceName("%sService"); //去掉Service接口的首字母I
gc.setIdType(IdType.ID_WORKER); //主键策略
gc.setDateType(DateType.ONLY_DATE);//定义生成的实体类中日期类型
gc.setSwagger2(true);//开启Swagger2模式
mpg.setGlobalConfig(gc);
// 3、数据源配置
DataSourceConfig dsc = new DataSourceConfig();
dsc.setUrl("jdbc:mysql://localhost:3306/ds1?useSSL=false");
dsc.setDriverName("com.mysql.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("123456");
dsc.setDbType(DbType.MYSQL);
mpg.setDataSource(dsc);
// 4、包配置
PackageConfig pc = new PackageConfig();
pc.setParent("com.xiao");
pc.setModuleName("ds"); //模块名
pc.setController("controller");
pc.setEntity("entity");
pc.setService("service");
pc.setMapper("mapper");
mpg.setPackageInfo(pc);
// 5、策略配置
StrategyConfig strategy = new StrategyConfig();
strategy.setInclude("od");
strategy.setNaming(NamingStrategy.underline_to_camel);//数据库表映射到实体的命名策略
strategy.setTablePrefix(pc.getModuleName() + "_"); //生成实体时去掉表前缀
strategy.setColumnNaming(NamingStrategy.underline_to_camel);//数据库表字段映射到实体的命名策略
strategy.setEntityLombokModel(true); // lombok 模型 @Accessors(chain = true) setter链式操作
strategy.setRestControllerStyle(true); //restful api风格控制器
strategy.setControllerMappingHyphenStyle(true); //url中驼峰转连字符
mpg.setStrategy(strategy);
// 6、执行
mpg.execute();
}
}
对于分表我们可以创建逻辑表再逆向生成代码,生成后逻辑表可以删除,并不影响测试,逆向生成代码的好处在于省去了我们去编写大量的业务逻辑层,实体层的代码,只需专注于视图层的编写即可
user,station,od三个表的映射与不分表时并无区别,传入主键即可,最后当我们增删改查时,会根据对应id取模后的值找到对应的分表,这里测试一下接口,启动服务,我在demo中整合了swagger2,这里浏览器输入 http://localhost:8080/doc.html访问
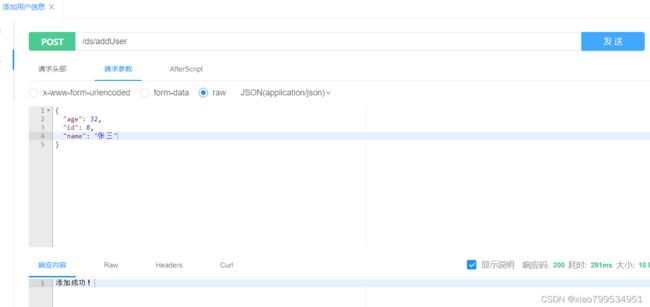
当我们添加id为8的数据时,在数据库中查看,发现数据存入了user_0中

在控制台中能看到具体的sql语句:
2022-02-25 22:20:34.691 INFO 8748 --- [nio-8080-exec-2] ShardingSphere-SQL : Actual SQL: ds0 ::: INSERT INTO user_0 (id, name, age) VALUES (?, ?, ?) ::: [8, 张三, 32]
其他接口测试是同样的原理,下面我们看一下Psim表的映射,这里我们需要同时传入主键和date做查询条件,mybatisplus没有给我们提供该类接口,我们自己编写一下业务层:
public interface PsimService extends IService<Psim> {
Psim getByIdandDate(Integer id, String date);
void deleteByIdandDate(Integer id, String date);
}
@Service
public class PsimServiceImpl extends ServiceImpl<PsimMapper, Psim> implements PsimService {
@Override
public Psim getByIdandDate(Integer id, String date) {
QueryWrapper<Psim> queryWrapper = new QueryWrapper<>();
QueryWrapper<Psim> wrapper = queryWrapper.eq("id", id).eq("date", DateUtils.parseTime(date));
return getOne(wrapper);
}
@Override
public void deleteByIdandDate(Integer id, String date) {
QueryWrapper<Psim> queryWrapper = new QueryWrapper<>();
QueryWrapper<Psim> wrapper = queryWrapper.eq("id", id).eq("date", DateUtils.parseTime(date));
remove(wrapper);
}
}
我们测试一下接口:
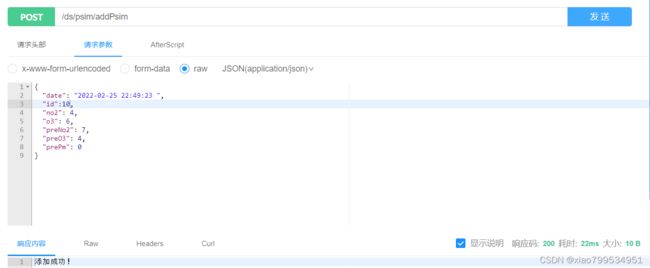
查看数据库,发现数据存入到了表psim_2022_2中:

在控制台中能看到数据传入到了psim_2022_2中:
2022-02-25 22:49:41.723 INFO 17964 --- [nio-8080-exec-5] ShardingSphere-SQL : Actual SQL: ds0 ::: INSERT INTO psim_2022_2 (ID, date, O3, NO2, Pre_PM, Pre_O3, Pre_NO2) VALUES (?, ?, ?, ?, ?, ?, ?) ::: [10, 2022-02-25 22:49:23.0, 6.0, 4.0, 0.0, 4.0, 7.0]
这里我将返回json的全局时间格式确定为yyyy-MM-dd HH:mm:ss,在配置文件中有体现,大家可以自己确定返回的时间格式。
以上是关于SpringBoot+Sharding-JDBC+MyBatisPlus进行多数据源分表操作,demo源码已上传至GitHub,假如您有疑问,可以在下方评论留言,大家一起学习,共同进步!
源码地址