机器学习快速入门:1~2章
第一章
1.1 机器学习简介
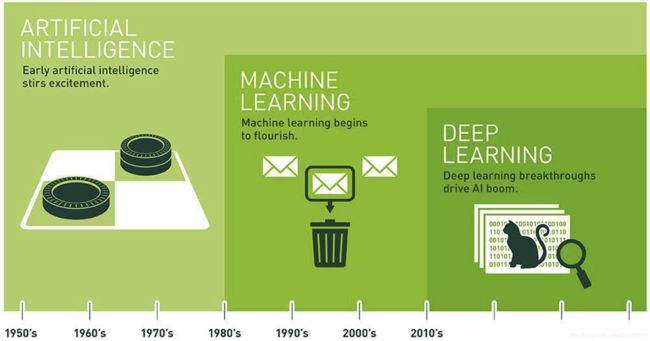
人工智能 (Artificial Intelligence,简称AI) 是对人的意识、思维过程进行模拟的一门新学科。
如今,人工智能从虚无缥缈的科学幻想变成了现实。计算机科学家们在 机器学习 (Machine Learning) 和 深度学习 (Deep Learning) 领域已经取得重大的突破,机器被赋予强大的认知和预测能力。2016 年 AplphaGO 成功击败人类世界冠军向世界证明,机器也可以像人类一样思考,甚至比人类做得更好。
人工智能、机器学习和深度学习三者关系
人工智能涵盖了机器学习和深度学习的所有范畴,人工智能研究的主要目标是使机器能够胜任一些通常需要人类才能完成的复杂工作,人工智能、机器学习、深度学习三者之间是逐层包含的关系。
机器学习:人工智能核心技术
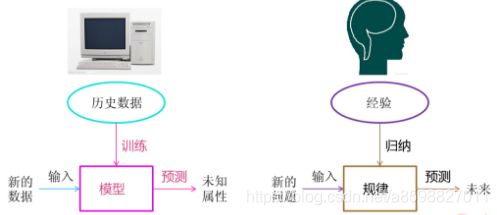
机器学习是利用经验或数据来改进算法的研究,通过算法让机器从大量历史数据中学习和寻找规律,得到某种模型并利用此模型预测未来。
1.2 机器学习应用场景
机器学习:应用领域
从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的。同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。

机器学习:应用场景
- 客户分析
- 营销分析
- 社交媒体分析
- 网络安全
- 设备管理
- 交通物流
- 欺诈检测
机器学习应用场景:客户分析
主要是客户的基本数据信息进行商业行为分析。
- 分析目标客户
根据客户的需求,目标客户的性质,所处行业的特征以及客户的经济状况等基本信息使用统计分析方法和预测验证法,分析目标客户,提高销售效率。 - 制定营销策略
了解客户的采购过程,根据客户采购类型、采购性质进行分类分析制定不同的营销策略。 - 分析客户价值
根据已有的客户特征,进行客户特征分析、客户忠诚分析、客户注意力分析、客户营销分析和客户收益分析。
机器学习应用场景:营销分析
囊括了产品分析,价格分析,渠道分析,广告与促销分析这四类分析。
- 产品分析
主要是竞争产品分析,通过对竞争产品的分析制定自身产品策略。 - 价格分析
分为成本分析和售价分析,成本分析的目的是降低不必要成本,售价分析的目的是制定符合市场的价格。 - 渠道分析
指对产品的销售渠道进行分析,确定最优的渠道配比。 - 广告与促销分析
结合客户分析,实现销量的提升,利润的增加。
机器学习应用场景:社交媒体分析
以不同社交媒体渠道生成的内容为基础,实现不同社交媒体的用户分析,访问分析,互动分析等。同时,还能为情感和舆情监督提供丰富的资料。
- 用户分析
根据用户注册信息,登录平台的时间点和平时发表的内容等用户数据,分析用户个人画像和行为特征。 - 访问分析
通过用户平时访问的内容,分析用户的兴趣爱好,进而分析潜在的商业价值。 - 互动分析
根据互相关注对象的行为预测该对象未来的某些行为特征。
机器学习应用场景:网络安全和设备管理
- 网络安全
新型的病毒防御系统可使用数据分析技术,建立潜在攻击识别分析模型,监测大量网络活动数据和相应的访问行为,识别可能进行入侵的可疑模式,做到未雨绸缪。 - 设备管理
通过物联网技术能够收集和分析设备上的数据流,包括连续用电、零部件温度、环境湿度和污染物颗粒等无数潜在特征,建立设备管理模型,从而预测设备故障,合理安排预防性的维护,以确保设备正常作业,降低因设备故障带来的安全风险。
机器学习应用场景:交通物流和欺诈检测
- 交通物流
物流是物品从供应地向接收地的实体流动。通过业务系统和GPS定位系统获得数据,对于客户使用数据构建交通状况预测分析模型,有效预测实时路况、物流状况、车流量、客流量和货物吞吐量,进而提前补货,制定库存管理策略。 - 欺诈检测
身份信息泄露盗用事件逐年增长,随之而来的是欺诈行为和交易的增多。公安机关,各大金融机构,电信部门可利用用户基本信息,用户交易信息,用户通话短信信息等数据,识别可能发生的潜在欺诈交易,做到提前预防未雨绸缪。
1.3 机器学习算法分类
机器学习不同层次
- 两眼摸瞎,不知所措
- 会用工具跑模型和评估模型
- 根据应用的特点改进模型来获取更好的结果
- 熟悉各类模型及其特点并能准确应用
- 解决行业重点问题推动行业技术的发展
机器学习介绍
- 数学基础
-
- 微积分、矩阵计算、线性代数、概率论和数理分析
- 计算机基础
-
- Linux、DataBase、Python/R、Hadoop、Spark、HDFS、YARN、Pig、Flume、Sqoop、Hive、Impala、Sentry、Zookeeper
- 传统机器学习算法
-
- K-近邻算法、决策树、朴素贝叶斯、逻辑回归、支持向量机、聚类、主成分分析
机器学习提升路径

机器学习概念
- 概念
-
- 假设用PP来评估计算机程序在某任务类TT上的性能, 若一个程序通过利用经验EE在TT中任务上获得了性能改善,则我们就说关于TT 和PP,该程序对EE进行了学习。
- 研究内容
-
- 关于在计算机上从数据中产生 模型 (Model) 的算法,即学习算法 (Learning Algorithm)。
机器学习算法分类
按学习的方式来划分,机器学习主要包括:
- 监督学习
输入数据带有标签。监督学习建立一个学习过程,将预测结果与 “训练数据”(即输入数据)的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率,比如分类和回归问题等。常用算法包括决策树、贝叶斯分类、最小二乘回归、逻辑回归、支持向量机、神经网络等。
- 非监督学习
输入数据没有标签,而是通过算法来推断数据的内在联系,比如聚类和关联规则学习等。常用算法包括独立成分分析、K-Means 和 Apriori 算法等。
- 半监督学习
输入数据部分标签,是监督学习的延伸,常用于分类和回归。常用算法包括图论推理算法、拉普拉斯支持向量机等。
- 强化学习
输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入 / 输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平q衡。
机器学习算法分类
- 回归算法: 线性回归、逻辑回归
- 基于实例的学习算法: K-邻近算法
- 正则化算法: 岭回归、LASSO、Elastic Net
- 决策树算法: 分类和回归树、ID3算法、C4.5/C5.0、随机森林、梯度推进机
- 贝叶斯算法: 朴素贝叶斯、高斯朴素贝叶斯、多项式朴素贝叶斯
- 基于核的算法: 支持向量机(SVM)、径向基函数(RBF)、线性判别分析(LDA)
- 聚类算法: K-均值、K-中位数、EM算法、分层聚类
- 关联规则: Apriori算法、Eclat算法
- 神经网络: 感知器、反向传播
- 深度学习: 卷积神经网络、递归神经网络
- 降维算法: 主成分分析、主成分回归、偏最小二乘回归
- 集成算法: Boosting、Bagging、AdaBoost
1.4 机器学习基本术语
机器学习的基本原理就是把现实世界当中要研究的对象通过特征值将其数字化,然后让计算机通过这些已有的数字学习“经验”,从而有了判断的能力,这时如果有了新的输入,计算机就能够根据这些经验来做出判断。
比如下面的例子就是要计算机判断西瓜是好瓜还是坏瓜,我们把西瓜对象提取出三种类型的特征值,然后通过算法让机器去学习,从而拥有了判断西瓜好坏的能力。我们把这个可以将经验(数据)转化为最终的模型(Model,也就是那个能判断好瓜还是坏瓜的程序)的算法称之为学习算法(Learning Algorithm)

- 模型、学习算法、数据集、示例/样本、属性/特征、属性值

- 维数、样本空间/属性空间、特征向量

我们可以看出现实世界的任何事物其实都可以通过属性或着特征来进行描述,上图给出的就是通过三个属性来描述西瓜的一组数据。属性的数目我们称之为维数,本例中表示西瓜用了三个特征,因此就是三维。
下面的图表示样本空间(Sample Space)或者属性空间(Attribute Space),我们也可以看到这是一个三维空间。
每个样本根据其特征值都会落在样本空间的一个点上,这个点由一组坐标向量来表示,因此样本又叫做特征向量(Feature Vector)。
机器学习的过程就是通过这些样本数据进行训练学习的过程,通过训练,我们可以得出自己的模型,这个模型我们可以理解为经过训练的机器大脑,这个机器大脑可以帮助我们做判断,比如判断一个西瓜的好坏,判断的越准确,说明我们的模型越好。
- 标记、样例、标记空间/输出空间
当我们开始训练我们的模型的时候,只有上面所示的数据集是不够的,我们还需要一组带有判断结果的数据
判断结果我们叫做标记(Label),带有标记信息的样本,则称之为样例(Example)
所有标记的集合叫做标记空间(Label Space)或输出空间(Output Space)
((色泽='青绿',根蒂='蜷缩',敲声='浊响'), 好瓜)通常我们训练模型就是为了找到输入空间到输出空间的对应关系,即给定输入空间的一个特征向量,能够对应到输出空间的一个值。
- 分类问题
((色泽='青绿',根蒂='蜷缩',敲声='浊响'), 好瓜)- 回归问题
((色泽='青绿',根蒂='蜷缩',敲声='浊响'), 0.95)- 聚类问题
- 监督学习/无监督学习
如果我们想让我们的模型只是简单地去判断(通常叫预测)一个瓜是好瓜还是坏瓜,即分成两类,这种学习任务称为分类问题(Classification),预测的是离散值;如果是想让其预测的是连续值,如预测西瓜成熟度0.95, 0.88,此类学习任务就叫做回归(Regression)
在我们的示例中只是简单地分为“好瓜”,“坏瓜”两类,此种分类称为二分类问题(Binary Classification),通常一个称为正类(Positive Class)也有翻译为“阳类”,另一个称为反类(Negtive Class)或者成为为阴类。
如果是多个类别的话,就称为多分类问题。
如果我们想将训练集中的西瓜分成若干组,每组就称之为一个簇(Cluster),这个过程就叫做聚类(Clustering)。这些簇可能对应一些潜在的分类,比如“浅色瓜”,“深色瓜”等。而这些分类可能是我们事先并不知道的,就是说学习算法在做聚类分析的时候是自动产生的类别,通常训练样本中也不需要标记信息。
根据训练数据是否有标记信息,学习任务可分为监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。
分类和回归是监督学习的典型代表,而聚类则是无监督学习的典型代表。
- 假设
(色泽='青绿',根蒂='蜷缩',敲声='浊响')每种特征的组合都认为是一个假设(Hypothesis),所有假设的集合我们称之为假设空间。
- 假设空间、版本空间
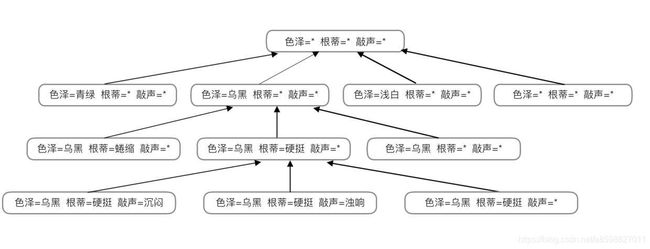
如果“色泽”,“根蒂”,“敲声”分别有3,2,2种可能,(每种特征值都要加一种任意值可能)那么假设空间的规模就是 4*3x=*3+1=374∗3x=∗3+1=37
从这幅图可以看出,每种特征值在计算可能性的时候都加了一种可能,就是任意值可能,我们用“*”表示,最后结果加1是由于存在一种可能就是根本没有“好瓜”这个概念,或者说“好瓜”跟这些特征都没有关系。当给定一个训练集进行训练的时候,模型会逐渐删除那些与正例不一致的假设和(或)与反例一致的假设,最后获得与训练集一致的假设。而剩下的这些假设可能有多个,我们把剩下的这些假设的集合称之为版本空间(Version Space)。
- 泛化
-
- 学习到模型对未知数据的预测能力
- 归纳
-
- 从特殊情况到一般的泛化过程(具体事实一般性规律)
- 演绎
-
- 从一般到特殊的特化过程(基础原理具体状况)
- 归纳学习
-
- 从样例中学习显然时一个归纳的过程
- 广义的归纳学习:从样例中学习
- 侠义的归纳学习:从训练数据中学的概念/概念生成/概念(concept)学习
- 归纳偏好
-
- 机器学习算法在学习过程中对某种类型假设的偏好
- 奥卡姆剃刀原则
-
- 若有多个假设与观察一致,则选最简单的那个
Scikit-learn安装与查看
- 安装Scikit-learn
-
!pip install -U scikit-learn
- 安装Matplotlib
-
!pip install matplotlib
tips:镜像已经安装好相关库,你可以使用以下命令查看Scikit-learn版本
- 先导入sklearn:
import sklearn - 查看sklearn版本号:
sklearn.__version__
第二章
2.1 模型评估:基本概念
- 错误率(Error Rate)
-
- 预测错误的样本数aa占样本总数的比例mm
E=\frac{a}{m}E=ma
- 准确率(Accuracy)
准确率=1-错误率准确率=1−错误率
- 误差(Error)
-
- 学习器的实际预测输出与样本的真实输出之间的差异
- 训练误差(Training Error)或经验误差(Empirical Error)
-
- 学习器在训练集上的误差
- 泛化误差(Generalization Error)
-
- 学习器在新样本上的误差
- 解释与泛化
-
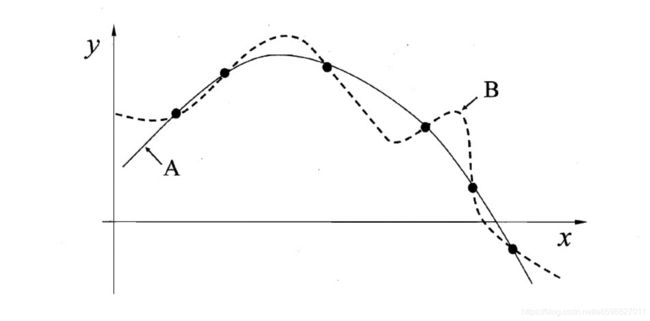
- 当模型在训练集上表现很好而在新样本上误差很大时,称为过拟合;反之模型在训练集上误差就很大时,称为 欠拟合。
- 过拟合和欠拟合

2.2 判别方法
判别方法:误差
引起误差的原因主要是因为偏差和方差。
- 偏差(Bias)
-
- 描述的是预测值(估计值)的期望与真实值之间的偏离程度。偏差越大,越偏离真实数据。
- 方差(Variance)
-
- 描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散。
- 偏差和方差对误差Error的影响可以表示为
Error = Bias + Variance + NoiseError=Bias+Variance+Noise

- 偏差(bias)造成的误差 - 准确率和欠拟合
如果模型具有足够的数据,但因不够复杂而无法捕捉基本关系,即如果模型不适当,则会出现偏差。这样一来,模型一直会系统地错误表示数据,从而导致预测准确率降低出现欠拟合。 - 方差(variance)造成的误差 - 精确率和过拟合
方差就是指模型过于贴近训练数据,以至于没办法把它的结果泛化。而泛化正是机器学习要解决的问题,如果一个模型只能对一组特定的数据有效,换了数据就无效了,我们就说这个模型过拟合。

判别方法:学习曲线

2.3 解决方法
- 欠拟合通常容易解决
-
- 如 增加数据、增大训练次数、增大学习率 或 使用更复杂的模型 等。
- 过拟合则很难解决
-
- 常用的方法包括 简化模型,减少特征,更多的数据,交叉验证,正则化,Dropout 和 Shuffling 等。
当心陷阱:维度灾难(Curse of Dimensionality)
当维数提高时,模型空间的体积提高太快,因而可用数据变得很稀疏。
在高维空间中,所有的数据都很稀疏,从很多角度看都不相似,因而平常使用的数据组织策略变得极其低效。
为了获得在统计学上正确并且有可靠的结果,用来支撑这一结果所需要的数据量通常随着维数的提高而呈指数级增长。

如何避免维度灾难
实际上并没有一种固定的方法避免维度灾难,解决方法需要结合数据集和所选的模型。训练数据集越小,则用到的特征应当越少。
另外,对于诸如神经网络、kNN、决策树等泛化不好容易过拟合的分类器,维度应当适当的减少。而对于朴素贝叶斯和线性分类器等不太复杂的分类器,特征可以适当的增大。

2.4 数据集拆分
为了得到泛化误差小的模型,并避免过拟合,在构建机器模型时,通常将数据集拆分为相互独立的训练数据集、验证数据集和测试数据集
- 训练数据集(Train Dataset)用来构建机器学习模型
- 验证数据集(Validation Dataset)辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数
- 测试数据集(Test Dataset)用来评估训练好的最终模型的性能

为了划分这几种数据集,可以选择采用留出法、K-折交叉验证法或者自助法等多种方法。这些方法都对数据集有一些基本的假设,包括:
- 数据集是随机抽取且独立同分布的
- 分布是平稳的,不会随时间发生变化
- 始终从同一个分布中抽取样本
陷阱:请勿对测试数据集进行训练。
自助法的性能评估变化小,在数据集小、难以有效划分数据集时很有用。另外,自助法也可以从初始数据中产生多个不同的训练集,对集成学习等方法有好处。
然而,自助法产生的数据集改变了初始数据的分布,会引入估计偏差。因而,数据量足够时,建议使用留出法和交叉验证法。
数据集拆分:留出法
留出法(hold-out)直接将数据集划分为互斥的集合,如通常选择 80% 数据作为训练集,20% 作为测试集。
需要注意的是保持划分后集合数据分布的一致性,避免划分过程中引入额外的偏差而对最终结果产生影响。
通常来说,单次使用留出法得到的结果往往不够稳定可靠,一般采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
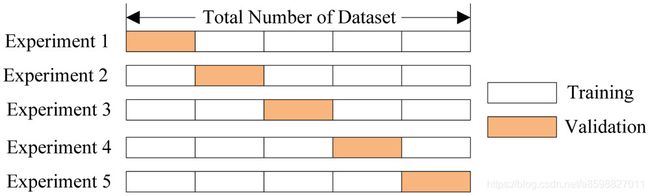
数据集拆分:K-折交叉检验法
机器学习中,算法模型性能比较是比较复杂的。
- 我们希望比较的是泛化性能,而实际中只能得到测试集上的性能,两者的结果未必相同
- 测试集上的性能跟测试集本身的选择有很大关系
- 很多机器学习算法本身有一定的随机性,即便用相同参数运行在同一个测试集上,多次的运行的结果也有可能不同
数据集拆分:K-折交叉检验法
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次。方差Variance随着k的增大而减小。
K常常取10,所以又称为十折交叉检验。

参数调节
- 参数调节
-
- 简称调参(parameter tuning),在进行模型评估与选择时,除了要对适用学习算法进行选择,还需对算法参数进行设定的过程称参数调节;
- 常用方法
-
- 对每个参数选定一个范围和变化步长,例如在[0,0.2][0,0.2]范围内以0.05为步长,则实际要评估的候选参数值有5个,最终是从这5个候选值中产生选定值。
网格搜索
网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法。
即将各个参数可能的取值进行排列组合,列出所有可能的组合结果生成参数网格。
然后将各组合用于训练,并使用交叉验证对表现进行评估。
在拟合函数尝试了所有的参数组合后,返回一个合适的分类器,自动调整至最佳参数组合,可以获得参数值
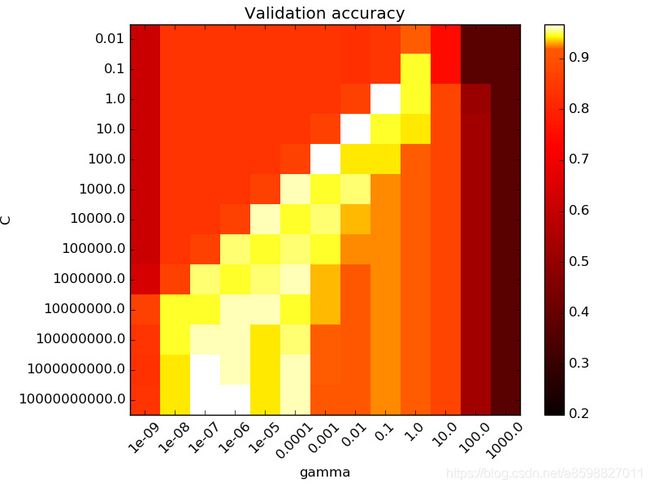
对SVM的C参数和gamma的网格搜索可视化结果如上图所示,可知{C=1.0,gamma = 0.1}时效果最好。
2.5 模型评价
- 分类模型
- 回归模型
- 聚类模型
模型评价:分类模型评价
- 分类模型是通过训练数据建立预测模型,并利用模型将需要预测的数据样本划分到已知的几个类别中的过程。
- 机器学习中常见分类算法:逻辑回归、决策树、朴素贝叶斯等
分类模型评价:混淆矩阵
- 标签
-
- 在分类问题中,每一个样本都存在两种角度的标签: 一个是样本真实的标签,一个是模型预测的标签。
- 混淆矩阵
-
- 根据每一个样本的两种角度的标签,可以得到一个混淆矩阵(Confusion Matrix)。混淆矩阵中的每一列代表预测类别 ,每一列的总数表示预测为该类别的样本的数目。每一行代表了样本的真实归属类别 ,每一行的数据总数表示该类别的样本的数目。
分类模型的评价指标主要基于混淆矩阵。对于二分类问题,每一个样本都可以划分到以下四种类型中:
- 真正(True Positive , TP):样本真实类别是正向的,模型预测的类别也是正向的
- 真负(True Negative , TN):样本真实类别是负向的,模型预测的类别也是负向的
- 假正(False Positive , FP):样本真实类别是负向的,模型预测的类别是正向的(取伪)
- 假负(False Negative , FN):样本真实类别是正向的,模型预测的类别是负向的(去真)
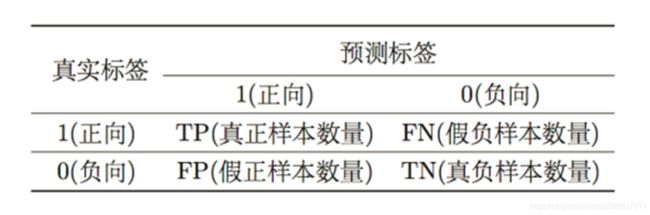
分类模型评价:多分类混淆矩阵

分类模型评价:评价指标
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1值(F1 score)
- ROC和AUC
- 分类模型评价指标:准确率
在分类问题中最常见的指标是准确率(accuracy),它表示模型预测正确的样本比例,即将正的判定为正,负的判定为负。
准确率的定义如下:
accuracy=\frac{TP+TN}{TN+FN+FP+TP}accuracy=TN+FN+FP+TPTP+TN

在不均衡数据中,准确率无法很好地度量模型的好坏。
例如在文本情感分类数据集中,正面的样本占比为80%,负面的内容占比只有20%。
如果一个分类模型将所有的样本都预测为正面,这个模型显然是一个无用的模型,但是它的准确率却可以达到80%。
对于不均衡数据,精确率和召回率是比准确率更好的性能评价指标。
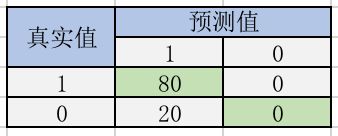
总样本量:100
accuracy=\frac { TP+TN }{ TN+FN+FP+TP } =\frac { 80+0 }{ 0+0+20+80 } =80%accuracy=TN+FN+FP+TPTP+TN=0+0+20+8080+0=80
- 分类模型评价指标:精确率
精确率(precision)又称查准率,是指正确预测的正样本占所有预测为正样本的比例。
precision=\frac{TP}{TP+FP}precision=TP+FPTP

- 分类模型评价指标:召回率
召回率(recall)又称查全率、灵敏度和命中率,是指样本中被正确预测的样本比例。
recall=\frac{TP}{TP+FN}recall=TP+FNTP

- 分类模型评价指标:F_{\beta}Fβ值
单独考虑精确率和召回率是片面的,而F值则是一个综合考虑精确率和召回率的指标。
F_{\beta}=\frac{(1+\beta^2)precision\times recall}{\beta^2\times precision+ recall}Fβ=β2×precision+recall(1+β2)precision×recall
其中\betaβ为正数,其作用是调整精确率和召回率的权重。\betaβ越大,召回率的权重更大;\betaβ越小,则精确率的权重更大。当\beta=1β=1时,精确率和召回率的权重一样,此时称为F_1F1值,它是精确率和召回率的调和平均数。
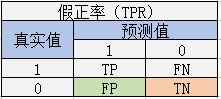
- 分类模型评价指标:假正率
假正率(False Positive Rate)为被预测为正的负样本结果数除以负样本实际数的比值。
假正率的定义为
FPR=\frac{FP}{FP+TN}FPR=FP+TNFP
- 分类模型评价指标:ROC曲线
ROC曲线通过召回率(TPR)和假正率(FPR)两个指标进行绘制图形,是一个画在ROC空间的曲线,横坐标为FPR, 纵坐标为TPR。

- (TPR=0,FPR=0)
-
- 把每个实例都预测为负类的模型
- (TPR=1,FPR=1)
-
- 把每个实例都预测为正类的模型
- (TPR=1,FPR=0)
-
- 理想模型
一个好的分类模型应该尽可能靠近图形的左上角,而一个随机猜测模型应位于连接点(TPR=0,FPR=0)和(TPR=1,FPR=1)的主对角线上。
- 分类模型评价指标:AUC
AUC就是处于ROC曲线下方的那部分面积的大小。通常AUC介于0.5到1.0之间,较大的AUC代表了较好的模型性能。
- 如果模型是完美的,那么它的 AUC=1AUC=1
- 如果模型是个简单的随机猜测模型,那么它的 AUG=0.5AUG=0.5
- 如果一个模型好于另一个,则它的曲线下方面积相对较大。
- 一般来说,AUC大于0.75可以认为是一个比较理想的模型。
分类模型评价指标:应用场景
- 如果需要你使用机器学习进行地震预报,您会选择哪个指标作为算法模型的评价指标?
- 如果需要你使用机器学习认定犯罪嫌疑人,您会选择哪个指标作为算法模型的评价指标?
回归模型评价指标
回归模型的预测值一般都是连续的。评价模型的指标没有统一的标准。下面介绍三个常用的方法:
- 平均绝对误差
- 均方误差
- 决定系数R^2R2
回归模型评价指标:平均绝对误差
平均绝对误差(Mean Absolute Error,MAE)是所有单个观测值与算术平均值的偏差的绝对值的平均。
MAE=\frac{1}{n}\sum_{i=1}^n|\hat{y_i}-y_i|MAE=n1∑i=1n∣yi^−yi∣
回归模型评价指标:均方误差
均方误差(Mean Squared Error,MSE)是衡量"平均误差"的一种较方便的方法,可以评价数据的变化程度。
均方根误差(Root Mean Square Error,RMSE)是均方误差的算术平方根,有时也用RMSE对回归模型进行评价。
MSE=\frac{1}{n}\sum_{i=1}^n(\hat{y_i}-y_i)^2MSE=n1∑i=1n(yi^−yi)2
回归模型评价指标:决定系数
在统计学中,通常使用决定系数对回归模型进行评价。假设样本真实值的平均值为:
y=\frac{1}{n}\sum_{i=1}^ny_iy=n1∑i=1nyi
- 残差平方和为
SSE=\sum_{i=1}^n(y_i-\hat{y_i})^2SSE=∑i=1n(yi−yi^)2
- 总平方和为
SST=\sum_{i=1}^n(y_i-\bar{y_i})^2SST=∑i=1n(yi−yiˉ)2
R^2R2的计算公式为
R^2(y,\hat{y})=1-\frac{SSE}{SST}R2(y,y^)=1−SSTSSE
- 通常R^2R2取值范围为[0,1][0,1]。
- R^2R2越趋近于1,说明回归效果越好。
- R^2R2越趋近于0,说明回归效果越差。
在一些回归效果非常差的情况下,残差平方和可能大于总平方和,此时可能小于0。
决定系数计算例子(重庆2017链家房价预测)

聚类模型评价指标
聚类模型的性能指标主要分为内部指标(Internal Index)和外部指标(External Index)两类。
- 内部指标适用于无标注数据,根据聚类结果中簇内相似度和簇间分离度进行聚类质量评估;
- 外部指标适用于有标注数据,将聚类结果与已知类标签进行比较。
- 内部指标
-
- DB 指数
- 轮廓系数
- 外部指标
-
- Rand指数
- 调整Rand指数
聚类模型评价:DB指数
聚类模型的目标是使得簇内数据尽量相似,不同簇之间的数据尽量不相似。
DB指数正是基于这个思想所构建的指标,它表示簇内距离与簇内距离与簇间距离之比,DB的值越小说明聚类效果越好。
DB(k)=\frac{1}{k}\sum_{i=1}^K {max}_{\substack{j=1,...,k\\j\neq i}} (\frac{W_i+W_j}{c_{ij}})DB(k)=k1∑i=1Kmaxj=1,...,kj=i(cijWi+Wj)
DB(k)=\frac{1}{k}\sum_{i=1}^K {max}_{\substack{j=1,...,k\\j\neq i}} (\frac{W_i+W_j}{c_{ij}})DB(k)=k1∑i=1Kmaxj=1,...,kj=i(cijWi+Wj)
其中,KK是聚类数目,W_iWi表示类C_iCi中的所有样本到其聚类中心的平均距离,W_jWj表示类C_iCi中的所有样本到类C_jCj中心的平均距离,C_{ij}Cij表示类C_iCi和C_jCj中心之间的距离。
DBDB越小表示类与类之间的相似度越低,从而对应越佳的聚类结果。
聚类模型评价:轮廓系数
轮廓系数结合了内聚度和**分离度两种因素,可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。对于样本ii的轮廓系数其计算公式:
s(i)=\frac{b(i)-a(i)}{max(a(i),b(i))}s(i)=max(a(i),b(i))b(i)−a(i)
- a(i)=average(样本i到所有它属于的簇中其它点的距离)a(i)=average(样本i到所有它属于的簇中其它点的距离),表示ii向量到同一簇内其他点不相似程度的平均值;
- b(i)=min(样本i到所有非本身所在簇的点的平均距离)b(i)=min(样本i到所有非本身所在簇的点的平均距离),表示样本ii到其他簇的平均不相似程度的最小值。

s(i)=\left\{ \begin{array}{cc} 1-\frac{a(i)}{b(i)},a(i)
- s(i)s(i)接近1,则说明样本ii聚类合理
- s(i)s(i)接近-1,则说明样本ii更应该分类到其他类
- s(i)s(i)接近0,则说明样本ii在两个类的边界上
聚类模型评价:Rand指数
Rand指数(Rand Index,RI)类似于分类模型中的准确度指标,其具体定义如下:
- 设数据集XX的一个聚类结构为
C ={C_1,C_2,\dots, C_m}C=C1,C2,…,Cm
- 数据集已知的划分为
P ={ P_1,P_2,\dots,P_s }P=P1,P2,…,Ps ,
- 可通过比较CC和PP的混淆矩阵来评价聚类的质量。

纯度(Purity)方法是极为简单的一种聚类评价方法,只需计算正确聚类的文档数占总文档数的比例
互信息(Mutual Information)是纯度的另一种表述,作用与纯度(Purity)一致。建立在熵的概念基础上,又称信息增益。
查看sklearn的帮助文档
- 我们可以通过help()函数来查看sklearn的帮助文档
-
- 导入sklearn库:
import sklearn - 查看sklearn帮助:
help(sklearn)
- 导入sklearn库: