Pytorch学习笔记9——AutoEncoder
Pytorch学习笔记9——AutoEncoder
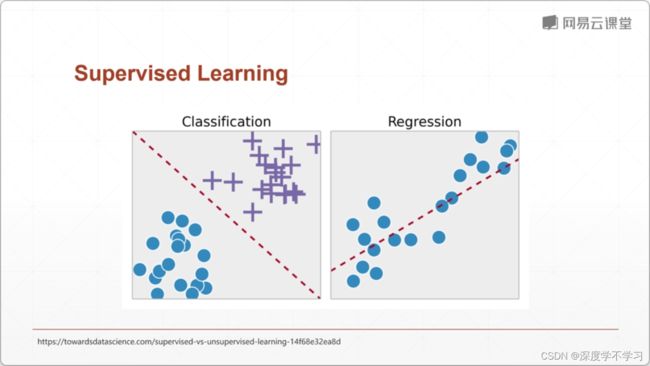


非监督学习的作用:
1.降维
2.预处理
3.可视化
4.利用无监督标签
5.压缩,超分辨率,降噪




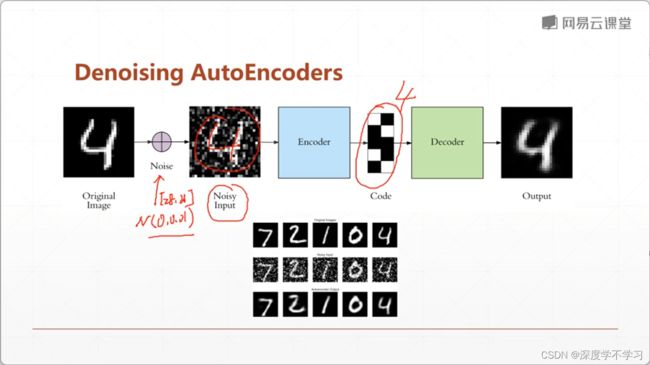

对抗自编码器:

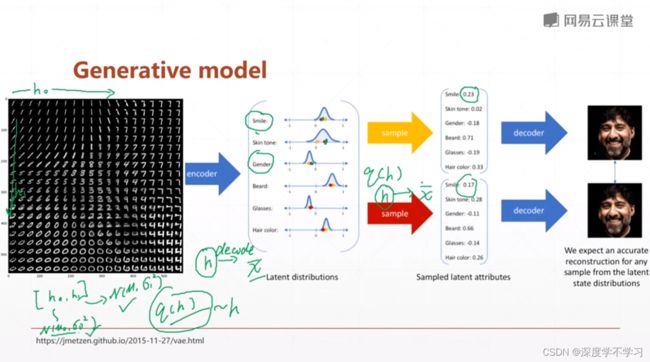
中间变量变成一个分布:

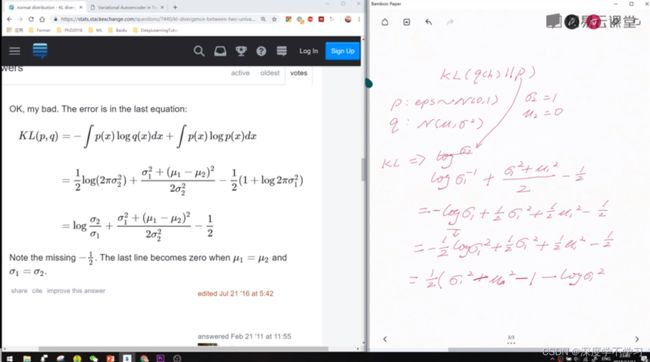
KL divergence:
直观理解:



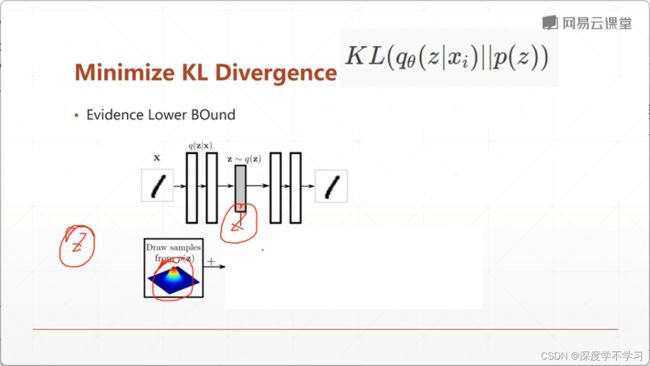

 此时autoencoder获得的中间hidden vector不是一个具体的vector,而是一个分布,我们需要再sample一个vector x出来
此时autoencoder获得的中间hidden vector不是一个具体的vector,而是一个分布,我们需要再sample一个vector x出来

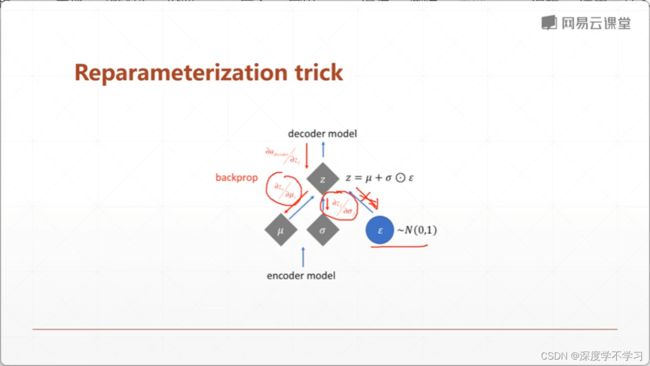
怎么backpropogation?取出分布(sample)过程不可微分:
把对z的sample过程转变为计算过程:
z=μ+σe

加入KL divergence的regularization效果:
Loss+βKL(q,p)
如果没有regularization,网络就可以通过学习一个很narrow的distribution来骗过test(数据集中,loss低),有的话,得到的分布越接近正态分布总loss越低,迫使学习到的分布趋近于均值为0的正态分布。
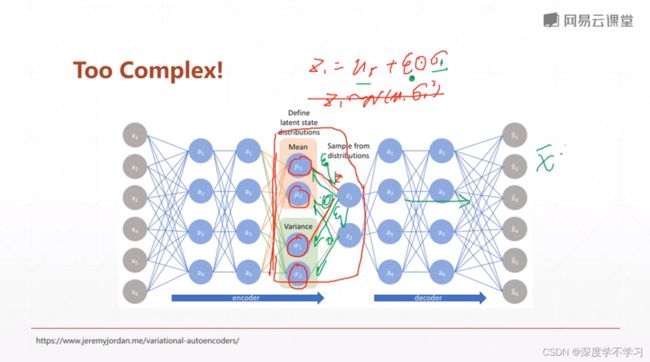
VAE: variational auto encoder:用分布代替确定的序列数值。


KL divergence,当p为正态分布时:
AE与VAE实战代码:
AE:
import torch
from torch import nn
class AE(nn.Module):
def __init__(self):
super(AE,self).__init__()
#[b,784]
self.encoder=nn.Sequential(
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256,64),
nn.ReLU(),
nn.Linear(64,20),
nn.ReLU()
)
#[b,20]=>[b,784]
self.decoder=nn.Sequential(
nn.Linear(20,64),
nn.ReLU(),
nn.Linear(64,256),
nn.ReLU(),
nn.Linear(256,784),
nn.Sigmoid()
)
def forward(self,x):
'''
:param x: [b,1,28,28]
:return:
'''
batchsz=x.size(0)
#flatten
x=x.view(batchsz,784)
x=self.encoder(x)
x=self.decoder(x)
#RESHAPE
x=x.view(batchsz,1,28,28)
return x
MAIN:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms,datasets
from torch import nn,optim
from pytorch2.AE import AE
import visdom
if __name__=='__main__':
mnist_train=datasets.MNIST('mnist',True,transform=transforms.Compose([
transforms.ToTensor()]),download=True)
mnist_train=DataLoader(mnist_train,batch_size=32,shuffle=True)
mnist_test=datasets.MNIST('mnist',False,transform=transforms.Compose([
transforms.ToTensor()]),download=True)
mnist_train=DataLoader(mnist_test,batch_size=32,shuffle=True)
x=iter(mnist_train).next()
print('x:',x.shape)
device=torch.device('cuda')
model=AE().to(device)
criteon=nn.MSELoss()
optimizer=optim.Adam(model.parameters(),lr=1e-3)
print(model)
viz=visdom.Visdom()
for epoch in range(1000):
for batchidx,(x,_) in enumerate(mnist_train):
#[b,1,28,28]
x=x.to(device)
x_hat=model(x)
loss=criteon(x_hat,x)#x是输入图像,x_hat是得到的输出图像
#backpropogation
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch,'loss:',loss.item)
x,_=iter(mnist_test).next()
x=x.to(device)
with torch.no_grad():
x_hat=model(x)
viz.images(x,nrow=8,win='x',opts=dict(title='x'))
viz.images(x_hat,nrow=8,win='x_hat',opts=dict(title='x_hat'))
VAE:
import numpy as np
import torch
from torch import nn
class VAE(nn.Module):
def __init__(self):
super(VAE,self).__init__()
#[b,784]
#u:[b,10]
#sigma:[b,10]
self.encoder=nn.Sequential(
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256,64),
nn.ReLU(),
nn.Linear(64,20),
nn.ReLU()
)
#[b,20]=>[b,784]
self.decoder=nn.Sequential(
nn.Linear(10,64),
nn.ReLU(),
MAIN2:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms,datasets
from torch import nn,optim
from pytorch2.AE import AE
import visdom
if __name__=='__main__':
mnist_train=datasets.MNIST('mnist',True,transform=transforms.Compose([
transforms.ToTensor()]),download=True)
mnist_train=DataLoader(mnist_train,batch_size=32,shuffle=True)
mnist_test=datasets.MNIST('mnist',False,transform=transforms.Compose([
transforms.ToTensor()]),download=True)
mnist_train=DataLoader(mnist_test,batch_size=32,shuffle=True)
x=iter(mnist_train).next()
print('x:',x.shape)
device=torch.device('cuda')
model=AE().to(device)
criteon=nn.MSELoss()
optimizer=optim.Adam(model.parameters(),lr=1e-3)
print(model)
viz=visdom.Visdom()
for epoch in range(1000):
for batchidx,(x,_) in enumerate(mnist_train):
#[b,1,28,28]
x=x.to(device)
x_hat,kld=model(x)
loss=criteon(x_hat,x)#x是输入图像,x_hat是得到的输出图像
if kld is not None:
elbo=-loss-1.0*kld
loss=-elbo
# backpropogation
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch,'loss:',loss.item,'kld:',kld)
x,_=iter(mnist_test).next()
x=x.to(device)
with torch.no_grad():
x_hat=model(x)
viz.images(x,nrow=8,win='x',opts=dict(title='x'))
viz.images(x_hat,nrow=8,win='x_hat',opts=dict(title='x_hat'))