【PyTorch学习笔记】7.自编码器
文章目录
- 47.Auto-Encoder介绍
- 48.Auto-Encoder变种
- 49.Variational Auto-Encoder引入
- 50.变分自编码器VAE
- 51.实战
-
- 51.1AE
- 51.2VAE
根据龙良曲Pytorch学习视频整理,视频链接:
【计算机-AI】PyTorch学这个就够了!
(好课推荐)深度学习与PyTorch入门实战——主讲人龙良曲
47.Auto-Encoder介绍
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Why need Unsupervised Learning?
- Dimension reduction
- Preprocessing
- Visualization https://projector.tensorflow.org/
- Taking advantages of unsupervised data
- Compression, denoising, super-resolution…
How to Train?
- Loss function for binary inputs
l ( f ( x ) ) = − ∑ k ( x k l o g ( x ^ k ) + ( 1 − x k ) l o g ( 1 − x ^ k ) ) l(f(x))=-\sum_k(x_klog(\hat{x}_k)+(1-x_k)log(1-\hat{x}_k)) l(f(x))=−∑k(xklog(x^k)+(1−xk)log(1−x^k))
Cross-entropy error function (reconstruction loss) f ( x ) ≡ x ^ f(x)\equiv \hat{x} f(x)≡x^ - Loss function for real-valued inputs
l ( f ( x ) ) = 1 2 ∑ k ( x ^ k − x k ) 2 l(f(x))=\frac{1}{2}\sum_k(\hat{x}_k-x_k)^2 l(f(x))=21∑k(x^k−xk)2
sum of squared differences (reconstruction loss)
we use a linear activation function at the output
自编码器是一种无监督的数据维度压缩和数据特征表达方法。自编码器是神经网络的一种,由编码器和解码器组成,经过训练后能尝试将输入复制到输出。
PCA V.S. Auto-Encoders
- PCA, which finds the directions of maximal variance in high-dimensional data, select only those axes that have the largest variance.
- The linearity of PCA, however, places significant limitations on the kinds of feature dimensions that can be extracted.
48.Auto-Encoder变种
Denosing AutoEncoders
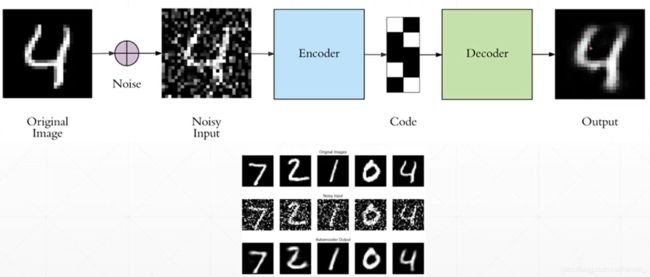
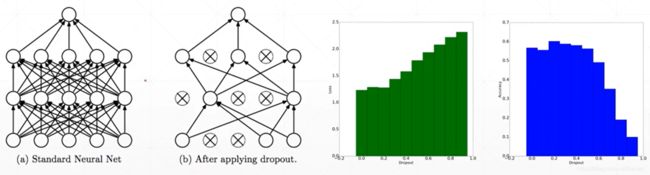
Dropout AutoEncoders
Adversarial AutoEncoders
- Distribution of hidden code
- Give more details after GAN

49.Variational Auto-Encoder引入
Another Approach: q ( z ) → p ( z ) q(z)\rightarrow p(z) q(z)→p(z)
- Explicitly enforce
l i ( θ , ϕ ) = − E z ∼ q θ ( z ∣ x i ) [ l o g p ϕ ( x i ∣ z ) ] + K L ( q θ ( z ∣ x i ) ∣ ∣ p ( z ) ) l_i(\theta, \phi)=-E_{z\sim q_{\theta}(z|x_i)}[log\space p_{\phi}(x_i|z)]+KL(q_{\theta}(z|x_i)||p(z)) li(θ,ϕ)=−Ez∼qθ(z∣xi)[log pϕ(xi∣z)]+KL(qθ(z∣xi)∣∣p(z))
How to compute KL between q ( z ) q(z) q(z) and p ( z ) p(z) p(z)
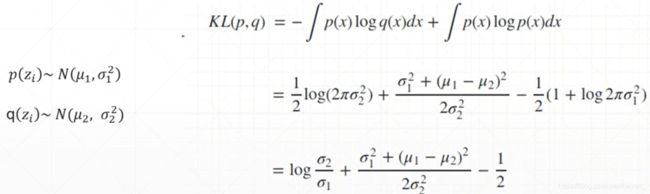
Sample() is not differentiable
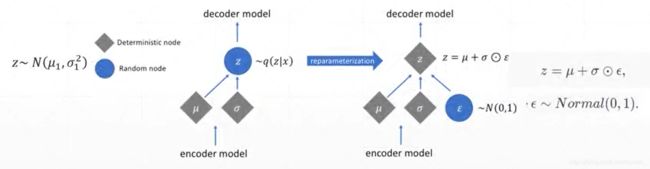
Reparameterization trick


50.变分自编码器VAE

51.实战
main.py
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from Pytorch21_7_29.autoencoder.ae import AE
from Pytorch21_7_29.autoencoder.vae import VAE
from torch import nn, optim
import visdom
def main():
mnist_train = datasets.MNIST('mnist', True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test,batch_size=32,shuffle=True)
x, _ = iter(mnist_train).next()
print('x:', x.shape) # x: torch.Size([32, 1, 28, 28])
device = torch.device('cuda')
# model = AE().to(device)
model = VAE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
viz = visdom.Visdom()
for epoch in range(1000):
for batchidx, (x, _) in enumerate(mnist_train):
# [b, 1, 28, 28]
x = x.to(device)
# x_hat = model(x)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
# elbo = -loss - 1.0 * kld
# loss = -elbo
loss = loss + kld
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print(epoch, 'loss', loss.item())
print(epoch, 'loss', loss.item(), 'kld:', kld.item())
x, _ = iter(mnist_test).next()
x = x.to(device)
with torch.no_grad():
# x_hat = model(x)
x_hat, _ = model(x)
viz.images(x, nrow=8, win='x', opts=dict(title='x'))
viz.images(x_hat, nrow=8, win='x_hat', opts=dict(title='x_hat'))
if __name__ == '__main__':
main()
51.1AE
ae.py
from torch import nn
class AE(nn.Module):
def __init__(self):
super(AE, self).__init__()
# [b, 784] => [b, 20]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU(),
)
# [b, 20] => [b, 784]
self.decoder = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x: [b, 1, 28, 28]
:return:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
x = self.encoder(x)
# decoder
x = self.decoder(x)
# reshape
x = x.view(batchsz, 1, 28, 28)
return x

51.2VAE
vae.py
import torch
from torch import nn
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] => [b, 20]
# u: [b, 10] sigma: [b, 10]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU(),
)
# [b, 10] => [b, 784]
self.decoder = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x: [b, 1, 28, 28]
:return:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
# [b, 20], including mean and sigma
h_ = self.encoder(x)
# [b, 20] => [b, 10] + [b, 10]
mu, sigma = h_.chunk(2, dim=1)
# reparameterization trick, epision~N(0, 1)
h = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(h)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) +
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz * 28 * 28)
return x_hat, kld
