TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation

Abstract
在各种医学图像分割任务上,u形架构(也称为U-Net)已成为事实上的标准并取得了巨大的成功。但是,由于卷积运算的内在局限性,U-Net通常在显式建模远程依赖关系方面显示出局限性。专为序列到序列预测而设计的具有全局自我关注机制的Transformer已经成为替代架构,但是由于缺乏low-level的细节,其结果可能导致定位能力受限。在本文中提出的TransUNet同时具有Transformers和U-Net的优点,是医学图像分割的有力替代方案。一方面,Transformer将来自CNN特征图的标记化图像块编码为提取全局上下文的输入序列。另一方面,解码器对编码的特征进行上采样,然后将其与高分辨率的CNN特征图组合以实现精确的定位。
作者认为通过结合U-Net来恢复localized spatial information来增强神经元细节,可以将Transformers用作医疗图像分割任务的强大编码器。TransUNet在多种医疗应用(包括多器官分割和心脏分割)中,比各种竞争方法具有更高的性能。代码
1 Introduction
在U-Net的不同变体中,由具有skip-connection的对称编解码器网络以增强细节保留,已成为事实上的选择。基于这种方法,在广泛的医疗应用中取得了巨大的成功,例如来自CMR的心脏分割和来自CT的器官分割等等。
尽管基于CNN的方法具有出色的表示能力,但由于卷积运算的固有局限性,通常仍在建模显式远程关系方面存在局限性。因此,这些架构通常会产生较弱的性能,尤其是对于在纹理,形状和大小方面表现出较大的患者间差异的目标结构。为了克服这种局限性,现有研究提议基于CNN特征建立自我注意机制。另一方面,专为序列到序列预测而设计的Transformers已经成为替代架构,它完全采用分配卷积运算符并且完全依赖于注意力机制。与以前的基于CNN的方法不同,Transformers不仅在建模全局上下文方面功能强大,而且在大规模预训练下对下游任务也显示出卓越的可移植性。机器翻译和NLP领域已广泛见证了这一成功。最近,在各种图像识别任务的尝试也达到甚至超过了SOTA。
在本文中,作者提出了第一个研究,探讨了在医学图像分割背景下Transformers的潜力。但是,作者发现单纯的用法(即使用Transformers对标记化的图像patches进行编码,然后直接将隐藏的特征表示升采样为全分辨率的密集输出)无法产生令人满意的结果。
这是由于Transformers将输入视为1D序列,并且只专注于在所有阶段建模全局上下文,因此会导致低分辨率特征缺乏局部信息的细节。通过直接上采样到完整分辨率无法有效地恢复此信息,因此会导致粗略的分割结构。另一方面,CNN架构(eg. U-Net)提供了提取低级视觉cue的途径,可以很好地弥补此类空间细节。
为此,提出了TransUNet,该框架从序列到序列的预测角度建立了自我注意机制。为了补偿由Transformers带来的特征分辨率的损失,TransUNet采用了一种混合CNN-Transformer体系结构,以利用来自CNN特征的详细高分辨率空间信息以及由Transformers编码的全局上下文。受U形结构设计的启发,然后对Transformers编码的自注意特征进行上采样,与从编码路径中跳连接的各种高分辨率CNN特征相结合,以实现精确的定位。实验表明,这种设计使框架能够保留Transformers的优势,并有益于医学图像分割。实验结果表明,与以前的基于CNN的自我注意方法相比,基于Transformer的体系结构提供了一种更好的利用自我注意的方法。另外,作者观察到,更深入地整合低级特征通常会导致更好的分割精度。
3 Method
给定图像其空间分辨率为HxW,通道数为C。目标是预测尺寸为HxW的相应像素级标签图。最常见的方法是直接训练CNN(例如U-Net)以将图像首先编码为高级特征表示,然后将其解码回到完整的空间分辨率。与现有方法不同,TransUNet通过使用Transformers将自我注意机制引入编码器设计。第3.1节中首先介绍如何直接应用Transformer对来自分解后的图像patch的特征表示进行编码。然后,将在3.2节中详细说明TransUNet的总体框架。

3.1 Transformers as Encoder
Image Sequentialization:如下图所示,首先通过将输入reshaping为一系列2D patches

上图模型概述:将图像分割成固定大小的patch,线性地嵌入每个patch,添加位置嵌入,然后将所得的矢量序列提供给标准的Transformer编码器。为了执行分类,向序列添加额外的可学习“分类令牌”的标准方法。这项工作的灵感来自
Attention Is All You Need
TransUNet是在此基础上的创新。论文地址ViT,这个工作的思想是在模型设计中,尽可能地遵循原始的Transformer。这种特意简单的设置的一个优点是,几乎可以立即使用可扩展的NLP Transformer体系结构及其有效的实现。
Patch Embedding:使用可训练的线性投影将矢量化patch Xp映射到潜在的D维嵌入空间中。为了对patch空间信息进行编码,我们学习特定的位置嵌入,将其添加到patch嵌入中以保留位置信息,如下所示:

其中E是patch嵌入投影,Epos代表位置嵌入。
Transformer编码器由L层多头自注意(MSA)和多层感知器块(MLP)组成(Eq. (2)(3))。因此,L层的输出能被表示如下:

LN(·)代表layer normlization操作,Z L是编码图像表示。
3.2 TransUNet
出于分割的目的,一个直观的解决方案是简单地将编码后的特征表示Z L上采样到完整分辨率,以预测密集输出。为了恢复空间顺序,应首先将编码特征的大小从HW/P2更改为H/P X W/P。我们使用1x1的卷积以将重塑特征的通道大小减小到类的数量,然后将特征图直接双线性上采样到全分辨率HxW,以预测最终的分割结果。
如上所述,尽管结合使用Transformer和简单的上采样已经可以产生合理的性能,但是由于H/P x W/P通常比原始图像分辨率HxW小得多,因此该策略并不是分割中Transformer的最佳用法,因此不可避免地会导致缺少low-level的细节(例如器官的形状和边界)。
因此,为了补偿这种信息丢失,TransUNet采用了混合CNN-Transformer架构作为编码器以及级联的上采样器,以实现精确的定位。
CNN-Transformer Hybrid as Encoder
TransUNet没有使用纯Transformer作为编码器(Section 3.1),而是采用了CNN-Transformer混合模型,其中CNN首先用作特征提取器来生成输入的特征图。Patch嵌入适用于从CNN特征图提取的1x1patches而不是原始图像。
之所以选择这种设计
- 它允许我们在解码路径中利用中间的高分辨率CNN特征图;
- 作者实验发现,混合型CNN-Transformer编码器的性能要优于单纯使用纯Transformer作为编码器。
Cascaded Upsampler
我们引入了级联上采样器(CUP),它由多个上采样步骤组成,以解码隐藏特征以输出最终分割掩码。将隐藏特征Z L的序列重塑为H/P x W/P x D的形状后,我们通过级联多个上采样块以实现从H/P x W/P到H x W的完整分辨率来实例化CUP,其中每个块包括
一个2上采样算子,一个3x3卷积层和一个ReLU层。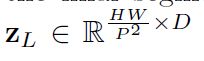
我们可以看到CUP与混合编码器一起形成了一个U形架构,该架构可以通过跳过连接以将不同的分辨率级别进行特征聚合。 CUP的详细体系结构以及中间的跳过连接可以在图1(b)中找到。
4 Experiments and Discussion
文中使用了两个数据集,分别是腹部CT扫描和心脏CMR。
- Synapse multi-organ segmentation dataset
- Automated cardiac diagnosis challenge
Implementation Details
对于所有实验,我们都应用简单的数据扩充,例如随机旋转和提取。
对于纯基于Transformer的编码器,我们仅采用具有12个Transformer层的ViT。对于混合编码器设计,我们在本文中将ResNet-50和ViT结合在一起,记为R50-ViT。所有Transformer主干(即ViT)和ResNet-50(表示为R-50)都已在ImageNet上进行了预训练。除非另外指定,否则输入分辨率和色块大小P设置为224 224和16。因此,我们需要在CUP中连续级联四个2个上采样块,以达到完整的分辨率。
并且使用SGD优化器对模型进行了训练,学习速率为0.01,动量为0.9,权重衰减为1e-4。对于ACDC数据集,默认批处理大小为24,默认的训练迭代数为20k,对于Synapse数据集,默认训练迭代数为14k。所有实验均使用单个Nvidia RTX2080Ti GPU进行。
以逐个切片的方式推断所有3D体积,并将预测的2D切片堆叠在一起以重建3D预测以进行评估。
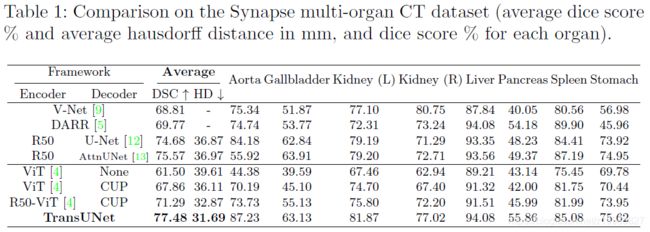
Comparison with State-of-the-arts
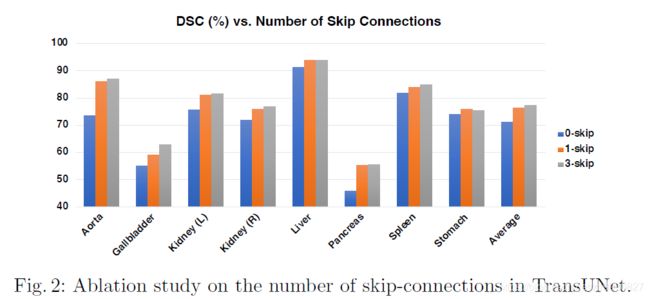
Analytical Study



Visualizations

5 Conclusion
Transformer被称为具有强大的先天性自我注意机制的架构。在本文中,我们提出了第一个研究,以调查Transtrans在一般医学图像分割中的用途。为了充分利用Transformers的功能,提出了TransUNet,它不仅通过将图像特征视为序列来编码强大的全局上下文,而且还通过U形混合体系结构设计很好地利用了低级CNN特征。作为基于FCN的主流医学图像分割方法的替代框架,TransUNet的性能优于包括基于CNN的自我注意方法在内的各种竞争方法。