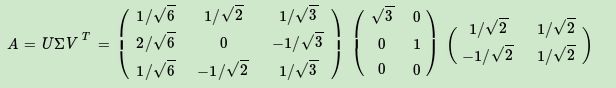机器学习 | 奇异值分解SVD与实现
文章目录
- 前言
- 一、回顾特征分解
-
- 特征分解的原理
- 特征值与特征向量的求解
- 二、奇异值分解(SVD)
- 三、推荐系统中SVD的特殊性
-
- SGD优化
- ALS
- 四、Suprise实现SVD
-
- 召回环节
- 考虑用户隐式反馈的SVD++
- 总结
-
- 附录:SVD数学计算示例
前言
特征分解——>奇异值分解(SVD)——>隐语义模型(LFM),三个算法在前者的基础上推导而成,按顺序先后出现。三者均用于矩阵降维。其中:
SVD奇异值分解为矩阵分解的一种方法,可用于推荐系统中,将评分矩阵补全、降维。

一、回顾特征分解
在了解SVD前,有必要先了解什么是特征分解,如何求得矩阵的特征值和特征向量?
Q1: 矩阵分解的作用?
- 将矩阵降维,将大型矩阵分解为简单矩阵乘积的形式,减少计算量。
- 在NLP和推荐系统中,会有非常稀疏的矩阵(如用户打分矩阵),把稀疏矩阵分解成高阶特征的线性组合,便于分类和预测。
Q2: 什么样的矩阵可以进行特征分解(前提)?
- 待降维的矩阵是方阵,即行与列数量相等的矩阵。
- ( A − λ E ) x = 0 (A-\lambda E)x=0 (A−λE)x=0有非零解,即 ∣ A − λ E ∣ = 0 |A-\lambda E|=0 ∣A−λE∣=0。
特征分解的原理
A = U ∑ U − 1 A=U∑U^ {-1} A=U∑U−1
其中U是n个特征向量组成的n × n维方阵,∑是这n个特征值为主对角线的n × n维方阵。
特征值与特征向量的求解
为了方便理解,附上教科书的截图。。
二、奇异值分解(SVD)
Q1: 既然有了矩阵分解,为什么进行SVD分解?
- 若矩阵是方阵,可以采用上一节提到的特征分解。
- 若矩阵不是方阵,即行数和列数不相等,该如何分解,最常用的方法即奇异值分解(SVD)
奇异值分解与矩阵分解类似,都是将目标矩阵A,转化为三个矩阵相乘,如下:

其中,A为目标矩阵,例如user对item的打分;P为左奇异矩阵,mm维,为User矩阵;Q为右奇异矩阵,nn维,为item矩阵;Λ为对角矩阵,对角线上的非零元素为特征值λ1, λ2, … , λk。
这种情况中,我们认为矩阵是低秩的,即矩阵中行列线性无关的程度,反映在奇异值矩阵中,其Λ矩阵衰减的特别快,很多情况下,前10%甚至1%的奇异值就能占据全部奇异值的99%以上的比例。
也就是说,我们可以用最大的k个奇异值对应的左右向量来近似描述矩阵。
k的选取可根据交叉验证,RMSE, MAE来不断去择优,初始可根据ceiling(m*n, 1/4)来选取

例如,推荐系统中,用户与物品的打分矩阵R则可以分解为如下两个矩阵:
R m x n = P m x k Q k x n T R_{mxn} = P_{m x k}Q^T_{k x n} Rmxn=PmxkQkxnT
三、推荐系统中SVD的特殊性
至此,我们了解了如何对一个矩阵进行奇异值分解,但事情没有那么简单,对于推荐系统中的矩阵是一个稀疏矩阵,稀疏矩阵不存在特征值,导致我们不可能直接对原User-Item矩阵用数学方法进行矩阵分解!
因此,我们需要使用机器学习的方法,根据损失函数不断学习,不断更新稀疏矩阵中的预测值!
我们把评分矩阵(Rating Matrix)计作V, V ∈ R n × m V∈R^{n×m} V∈Rn×m,那么 V V V的每一行 V i V_i Vi代表一个人的所有评分,每一列 V j V_j Vj代表某一部电影所有人的评分, V i j V_{ij} Vij代表某个人 i i i对某部电影 j j j的评分。对应电影推荐来说,V必定是稀疏的,因为电影数量(列的数目)是巨大的,V中必定有很多很多项为null。
我们接下来看这两个矩阵P(Users Features Matrix )和Q(Movie Features Matrix)。P为用户对特征的偏好程度矩阵,Q为电影对特征的拥有程度矩阵。U∈Rf×n的每一行表示用户,每一列表示一个特征,它们的值表示用户与某一特征的相关性,值越大,表明特征越明显。矩阵M∈Rf×m,的每一行表示电影,每一列表示电影与特征的关联。
R m x n = P m x k Q k x n T R_{mxn} = P_{m x k}Q^T_{k x n} Rmxn=PmxkQkxnT

注:上图中的数值仅作为参考,读者无需考虑准确性
上图中k取2,即隐含因子为2,即把用户和物品向量降维成k=2的向量
分别为“搞笑,恐怖”, 实际工程中是一个超参数,人为给定。
这样通过P的第u行乘以Q的第i列即可预测出原矩阵R中的缺失值。
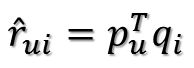
则真实值与预测值的误差为:
![]()
继而可以计算出总的误差平方和:
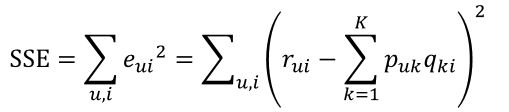
只要通过训练把损失函数SSE降到最小那么P、Q就能最好地拟合R了。
实际上,我们给一部电影评分时,除了考虑电影是否合自己口味外,还会受到自己是否是一个严格的评分者和这部电影已有的评分状况影响。
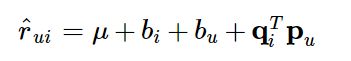
μ μ μ : 训练集中所有记录的评分的全局平均数。在不同网站中,因为网站定位和销售的物品不同,网站的整体评分分布也会显示出一些差异。比如有些网站中的用户就是喜欢打高分,而另一些网站的用户就是喜欢打低分。而全局平均数可以表示网站本身对用户评分的影响。
b u b_u bu : 用户偏置(user bias)项。这一项表示了用户的评分习惯中和物品没有关系的那种因素。比如有些用户就是比较苛刻,对什么东西要求都很高,那么他的评分就会偏低,而有些用户比较宽容,对什么东西都觉得不错,那么他的评分就会偏高。
b i b_i bi: 物品偏置(item bias)项。这一项表示了物品接受的评分中和用户没有什么关系的因素。比如有些物品本身质量就很高,因此获得的评分相对都比较高,而有些物品本身质量很差,因此获得的评分相对都会比较低。
有人就说了,这些偏置参数怎么定呢?难道我要预先把所有的数据集计算一遍?❌
才不需要呢,这些偏置参数也是通过学习而来,所以现在我们需要学习的矩阵参数变成了5个。
这个时候我们的损失函数变为:
![]()
SGD优化


此时,我们的梯度下降也变成了这样:(γ为学习率)

说到这里,SVD算法的本质是帮我们找到(学习出)item中隐含的维度(features),这些隐含的维度可以是(类型,派别,国别,或者两个组合,n种组合等等),SVD还可以找到(学习出)用户对各个维度(features)的类别喜爱程度。我们要做的只是指定维度的数量(n_factors),SVD会自动帮我们干好接下来的工作。
ALS
在实际应用中,交替最小二乘更常用一些,这也是社交巨头 Facebook 在他们的推荐系统中选择的主要矩阵分解方法。
交替最小二乘的核心是 “交替”,接下来看看 ALS 是如何 “交替”。
矩阵分解的最终任务是找到两个矩阵 P 和 Q,让它们相乘后约等于原矩阵 R:
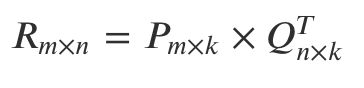
难就难在,P 和 Q 两个都是未知的,如果知道其中一个的话,就可以按照线性代数标准解法求得,比如如果知道了 Q,那么 P 就可以这样算:
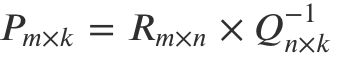
也就是 R 矩阵乘以 Q 矩阵的逆矩阵就得到了结果。
反之知道了 P 再求 Q 也一样。交替最小二乘通过迭代的方式解决了这个鸡生蛋蛋生鸡的难题4:
- 初始化随机矩阵 Q 里面的元素值;
- 把 Q 矩阵当做已知的,直接用线性代数的方法求得矩阵 P;
- 得到了矩阵 P 后,把 P 当做已知的,故技重施,回去求解矩阵 Q;
- 上面两个过程交替进行,一直到误差可以接受为止。
这便是机器学习的一大优势,先给一个假的结果,让整个模型运转起来,然后不断迭代最终得到想要的结果。
另外,WRMF 这种带权重的 ALS 优化算法叫做加权交替最小二乘:Weighted-ALS。还有 Spark 平台中集成了 ALS 算法,可以快速实现矩阵分解的优化。
四、Suprise实现SVD
原数据结构如下所示,至于如何提取到原数据,可以用爬虫,pandas等方式进行处理,这里就不再赘述了。
if __name__ == '__main__':
# 数据预处理
user_df = preprocessing()
user_df.reset_index()
user_df = user_df[['userID', 'movieID', 'rating']]
# Movie_ID 与 Movie_Name转化
rid_to_name = pickle.load(open(r'../dataset/rid_to_name.pkl', 'rb'))
# Suprise Reader读取数据
reader = Reader(rating_scale=(1, 10))
data = Dataset.load_from_df(user_df[['userID', 'movieID', 'rating']], reader)
# 对于SVD而言,我理解直接使用全数据进行奇异值分解,这样分解后的矩阵更具有准确率
trainset = data.build_full_trainset()
#trainset, testset = train_test_split(data, test_size=.25)
# 实例化SVD_Model
algo = SVD() # 超参数采用默认值, 隐含特征k: n_factors=100
# 喂入训练集
algo.fit(trainset)
# 计算准确率
#predictions = algo.test(trainset.build_anti_testset())
# 然后计算RMSE
#accuracy.rmse(predictions)
# 人工检测一下数据预测的准确性
print(algo.predict(1, 20761, r_ui=2))
print(algo.predict(1, 9283, r_ui=10))
print(algo.predict(1, 3108, r_ui=10))
print(algo.predict(3, 20318, r_ui=2))
print(algo.predict(3, 16255, r_ui=10))
print(algo.predict(3, 11978, r_ui=8))
# 我理解,仅当输入文件是文本形式入读的时候才会在这里转为str,如果直接是从df读入的,直接用int类型就好
# print(algo.predict(str(1), str(20761), r_ui=2))
# 验证分解后的矩阵P和Q的shape
print("Model user_factor matrix shape:{}".format(algo.pu.shape))
print("Model item_factor matrix shape:{}".format(algo.qi.shape))
打印出人工检测的结果,可以看出r_ui即真实评分,est为预测评分,大体看起来符合规律。


召回环节
模型训练完,就可以进入正式的召回阶段了,即给定用户ID,召回用户可能感兴趣的n个item。
这里采用Suprise推荐的方法
def get_top_n(predictions, n=10):
#'从一个预测集中为每个用户返回top-N个推荐'
# 首先将预测值映射至每个用户
# defaultdict是避免待查询的key不在字典内时报错的情况,而会报默认的[]
top_n = defaultdict(list)
for uid, iid, true_r, est, _ in predictions:
top_n[uid].append((iid, est))
# Then sort the predictions for each user and retrieve the k highest ones.
for uid, user_ratings in top_n.items():
user_ratings.sort(key=lambda x: x[1], reverse=True)
top_n[uid] = user_ratings[:n]
return top_n
if __name__ == '__main__':
user_df = preprocessing()
user_df.reset_index()
user_df = user_df[['userID', 'movieID', 'rating']]
rid_to_name = pickle.load(open(r'../dataset/rid_to_name.pkl', 'rb'))
reader = Reader(rating_scale=(1, 10))
data = Dataset.load_from_df(user_df[['userID', 'movieID', 'rating']], reader)
trainset, testset = train_test_split(data, test_size=.25)
algo = SVD()
algo.fit(trainset)
predictions = algo.test(testset)
# 然后计算RMSE
accuracy.rmse(predictions)
# 召回Top-n
top_n = get_top_n(predictions, n=10)
for uid, user_ratings in top_n.items():
print(uid, [iid for (iid, _) in user_ratings])
这里我们单独看一下userID==3的用户的召回结果,大体符合预测评分排行榜顺序
![]()

考虑用户隐式反馈的SVD++
某个用户对某个电影进行了评分,那么说明他看过这部电影,那么这样的行为事实上蕴含了一定的信息,因此我们可以这样来理解问题:评分的行为从侧面反映了用户的喜好,可以将这样的反映通过隐式参数的形式体现在模型中,从而得到一个更为精细的模型,便是 SVD++.
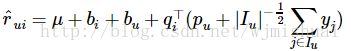
其中,I(u) 为该用户所评价过的所有电影的集合,yj为隐藏的“评价了电影 j”反映出的个人喜好偏置。收缩因子取集合大小的根号是一个经验公式,并没有理论依据。
模型参数bi,bu,qi,pu,yj通过最优化下面这个目标函数获得:
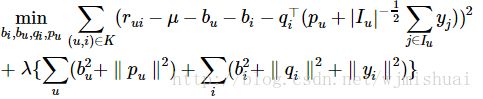
总结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。
SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
嘿嘿,顺便推荐一下自己记笔记的公众号:
附录:SVD数学计算示例
这里我们用一个简单的例子来说明矩阵是如何进行奇异值分解的。我们的矩阵A定义为:
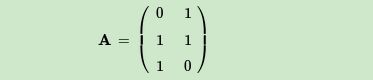
首先求出 A T A A^TA ATA和 A A T AA^T AAT
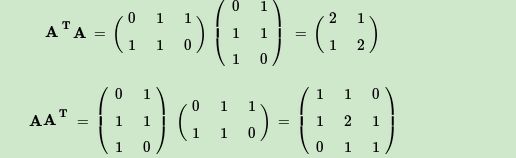
进而求出 A A T AA^T AAT的特征值和特征向量:
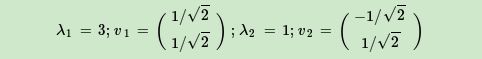
接着求出 A A T AA^T AAT的特征值和特征向量:
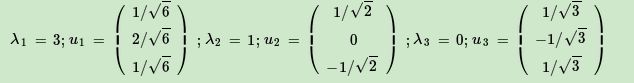
利用 A v i = σ i u i , i = 1 , 2 Av_i=\sigma_iu_i, i=1,2 Avi=σiui,i=1,2求奇异值:

最终得到A的奇异值分解为: