------- 慎入!
文章目录
- 一:HashMap (Java基础)
-
- HashMap底层实现
- HashMap 扩容机制
- HashMap和HashTable的区别
- ConcurrentHashMap是如何保证线程安全
- 如何设计哈希表? 哈希算法怎么选, 数组大小怎么确定
- Java反射机制
- 内部类和静态类的本质区别
- 二:MySQL
-
- MySQL的事务和索引
- 关系型数据库和非关系型数据库
- 表的约束
- 计算机网络
-
- 1. 网络分层情况
- 2.Http状态码
- 3.五元组
- 4.TCP的核心机制
- UDP 和 TCP 的区别
- 为什么要等待两个MSL?
- TCP中close_wait是一个什么状态,如何理解,close_wait 过多是什么原因
- time_wait 过多是什么原因
- DNS解析
- Get 和 Post 的区别
- url 和 uri 的区别
- 请求重定向和请求转发的区别
- HTTP协议的格式
- 输⼊网址之后,输⼊url 的整个过程(输入URL)
- Http协议和Https有什么区别
- 对称加密和非对称加密
- Http2.0为什么能实现多路服用
- TCP的粘包和拆包
- mac地址和ip地址
- 进程,线程,多线程
-
- 1. 进程和线程的区别
- 2.线程的生命周期(状态之间的转换)
- 3.线程的创建方式
- 线程池有什么好处(为什么要创建线程池)
- 线程池的创建方式
- 用过线程池吗?核心参数是啥子?代表啥子含义底层是如何实现的
- 线程池执行流程
- run方法和start方法的区别
- 了解多线程?实现线程的几种安全模式
- synchronized 用法有哪些?
- synchronized 和 Lock 的主要区别
- volatile关键字有什么用?
- volatile关键字和synchronized关键字的区别
- 常见锁策略
- 什么是CAS
-
- CAS 有什么缺点
- 什么是ABA问题
一:HashMap (Java基础)
HashMap底层实现

对于JDK 1.7 HashMap底层是 链表加数组,在JDK 1.8中对HashMap进行了优化
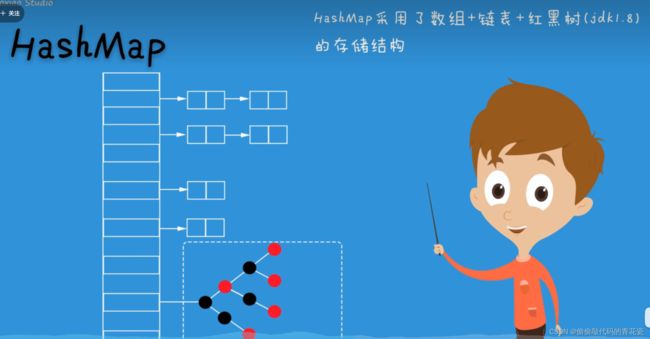
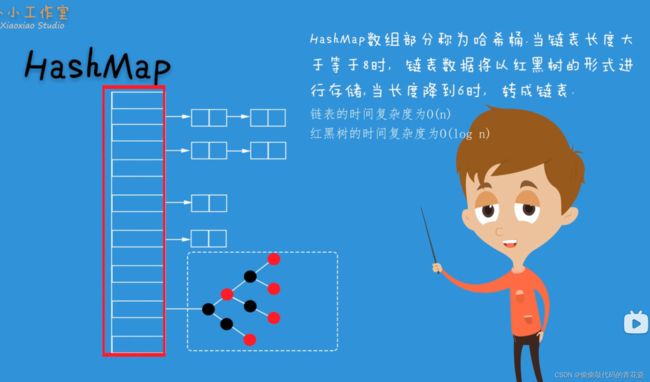
HashMap数组部分称为哈希桶,当链表长度大于等于8时,链表数据将以红黑树的形式进行存储,当长度降为6时,转成链表




HashMap 扩容机制
Hashmap 在存储数据过多时就会进行扩容,以免影响运行效率。当数据超过容量与负载因子的乘积时,就会进行扩容。hashmap扩容时会创建一个原数组两倍大的数组,然后遍历原数组,将原来所有的数据都移到新数组中。扩容之后需要重新hash,因为hash值是hashcode &(length-1)计算的,扩容后长度改变,hash值也会随之改变。在jdk1.7中,扩容采用的是头插法,头插法会改变原节点的位置,在多线程的情况下,原先按顺序排列的链表就会出现收尾相连的问题,所以在jdk1.8之后就采用了尾插法。其实扩容操作对于效率的影响是很大的,所以我们在使用hashmap时应该计算好需要的大小,尽量避免出现扩容而影响效率。
HashMap和HashTable的区别
对于第5个来说,他们同时都实现了 Map接口,但是他们的父类不同,Hashtable 的父类是 Dictionary,HashMap 的父类是 AbstractMap类

ConcurrentHashMap是如何保证线程安全
首先 ConcurrentHashMap 是 HashMap 的多线程版本 ,HashMap 在并发操作时会有各种问题,比如 死循环问题,数据覆盖等问题,而这些问题,只要使用 ConcurrentHashMap就可以完美解决
那么问题来了ConcurrentHashMap,是如何保证线程安全的呢?它的底层又是如何实现的呢?
在JDK1.7中它使用的是数组加链表的形式实现的,而数组又分为 大数组Segment 和 小数组HashEntry

知道了ConcurrentHashMap 的底层实现,再看它的线程安全实现就比较简单了
这里直接记录总结吧,源码也不放了,因为我也记不住~
总结
- ConcurrentHashMap 在JDK1.7中使用的是数组加链表的结构,其中分为两大类,大数组(Segment)小数组(HashEntry),而加锁是通过给 Segment 加 ReentrantLock 重入锁来保证线程安全
- ConcurrentHashMap 在JDK1.8中使用的是数组加链表加红黑树的结果,它通过CAS或synchronized来保证线程安全的,并且缩小了锁的粒度,查询性能也更高
tips:
所谓粒度,即细化的程度。锁的粒度越大,则并发性越低且开销大;锁的粒度越小,则并发性高且开销小
如何设计哈希表? 哈希算法怎么选, 数组大小怎么确定
哈希表设计原则:
- 不能太复杂,定义域必须包含需要存储的所有关键码(key)
- 通过哈希函数计算出来的地址必须能够均匀分布在整个空间中
常用哈希函数:
- 直接定制法
- 除留余数法
负载因子a = 填入表中的元素个数/散列表的长度
- a越大,产生冲突的可能性越大反之,a一般是0.75
Java反射机制
Java反射机制定义:对一任意一个类都能获取到这个类的所有属性和方法,对于任意一个对象都能调用它的任意属性和方法,这种动态的获取信息以及动态的调用对象的方法的功能我们叫做 Java反射机制
内部类和静态类的本质区别
内部类
- 内部类中的变量和方法不能声明为静态的
- 内部类实例化:B 是 A 的内部类,实例化B
A.B b = new A().new B() - 内部类可以引用外部类的静态或者非静态属性及方法
静态内部类
- 静态内部类属性和方法可以声明为静态的
- 静态内部类实例化:B 是 A 的静态内部类,
A.B b = new A.B() - 静态内部类只能引用外部类的静态的属性及方法
二:MySQL
MySQL的事务和索引
MySQL索引和事务详解
关系型数据库和非关系型数据库
关系型数据库:采用关系模式来组织,包括:oracle,Mysql,SQL server
非关系型数据库:不规定基于SQL实现(基于key - value),基于文档
表的约束
- NULL::指示某列不能存储NULL值
- UNIQUE:保证某列的每行必须有唯一的值
- DEFAULT::默认值(NULL),也可以修改其他我们需要的内容
- PRIMARY KEY:主键约束,相当于数据的唯一身份标识,类似于身份证号码
- PRIMARY KEY AUTO-INCREMENT:自增主键
- FOREIGN KEY :外键约束
剩下的在笔记本上,难得写了~
计算机网络
1. 网络分层情况
TCP/IP 五层模型:
从上到下:
- 应用层(又分为:应用层,表示层,会话层)
- 传输层(负责端到端)
- 网络层(负责点到点)
- 数据链路层(相邻设备)
- 物理层(网卡,网线…)
2.Http状态码
- 以 2 开头:属于成功了
- 以 3 开头:属于重定向(301 302)
- 以 4 开头:客户端出问题了(404,403)
- 以 5 开头:服务器出问题了
3.五元组
- 源IP
- 源端口号
- 目的IP
- 目的端口号
- 协议号
4.TCP的核心机制
TCP的核心机制包括:
-
确认应答(ACK)
包含:序号,和确认序号 -
超时重传
- 分为两种情况:ACK丢了,数据丢了,这两种情况会触发超时重传
- 但是当 ACK 丢了会触发 TCP内部去重机制:
TCP内部去重:接收方收到的消息会先放到操作系统内核的接收缓冲区中,根据接收数据的序号来确认是否存在,如果不存在就放进去,如果存在就丢弃
-
连接管理机制
- TCP 三次握手
图我就不画了,自行脑补~
目的:相当于投石问题,检查当前网络是否满足可靠传输 - 为什么一定要三次?两次行吗?四次呢?
两次不行,两次少了最后一次 客服端给服务器发送ACK,这回导致 服务器不知道自己的接受能力是否正常,客服端的发送能力是否正常
四次也不行,没必要,中间两次是可以合并在一起的,分开效率低,不如合在一起
>tips: 为什么三次握手中间两次能合并,四次挥手不可以? 因为三次握手 服务器给客户端发送的 SYN(同步报文段)+ACK(确认应答)是操作系统内核同一时间发送的 那么同理:四次挥手 服务器给客户端发送的 FIN(结束报文段) + ACK 合并不了的原因在于 ACK 是操作系统内核发送的 FIN 是用户代码执行的(调用 socket.colse()) - TCP 三次握手
-
滑动窗口(在保证可靠性传输的前提下,提高传输效率)
-
丢包:数据丢了 和 ACK 丢了
上面我们说了 触发超时重传机制时也是 数据和ACK丢了,但是这里有点差别
这里 ACK 丢了咋们不用管,因为滑动窗口— 看图自行脑补~
如果 数据 丢了则会触发— 》 快重传
what is 快重传呢? 就相当于 看电视剧,这一集没看不影响你看下一节,以后 看到没看的那一节自动补上就行 -
滑动窗口的衍生:
- 流量控制
相当于生产者消费者模型,A为生产者 B为消费者 中间有个B的接收缓冲区
如果B的接收缓冲区空间剩余较大,说明B的接收能力强,这个时候我们就可以增大A的窗口大小 - 拥塞队列
中间有个链路~ 怎么说呢,A能发多快不仅仅要看B的接收能力,还要看中间链路的处理能力
拥塞队列控制的处理方法:通过实验的方式,通过调整发送速度,找到一个合适的范围,A一开始从很小的窗口来发送数据,如果很流畅的就到达B,那么就增大窗口大小,如果大到一定程度,出现丢包问题,那么再去减小
- 流量控制
-
UDP 和 TCP 的区别
区别:
- UDP 不可靠传输,TCP 可靠传输(可不可靠指的是:数据能否发送成功,不是指安不安全)
- UDP 不需要链接,TCP 需要链接
- UDP 面向数据报,TCP 面向字节流
为什么要等待两个MSL?
这里是 TCP 中的状态,这里为什么要等待两个MSL?意思是 为什么 A 在TIME_WAIT 状态下,为什么要等待 2MSL?
- 为了保证 客服端 最后一个 ACK 报文段能够到达 服务器
- 防止已经失效的 请求报文段 出现在 本地连接中
TCP中close_wait是一个什么状态,如何理解,close_wait 过多是什么原因
close_wait 是四次挥手,挥了两次出现的情况,这个状态是等待 用户 调用 Socket.close() 方法来 进行 挥手过程
close_wait 按道理来说,一个服务器上不应该存在大量的 close_wait,过多就是出现bug了
time_wait 过多是什么原因
- 保证最后一次 ACK 一定到达,为实现 TCP 全双工 连接的可靠性
- 此时的 TCP 处于 time_wait 状态,处于这种状态下的 TCP 连接 不能 立即 以同样的 四元组建立新的连接
DNS解析
DNS就是域名系统,用于实现域名和IP地址相互映射的一个分布式数据库。通过主机名,得到该主机名对应的 IP 地址的过程叫做域名解析
DNS相当于是个指路人,当你输入一串域名之后,如 www.baidu.com,然后DNS会告诉服务器你输入的这串域名对应的 IP 是多少,你的电脑再去通过这个 IP 去访问,这样一来,大家只需要记住互联网的访问和数据交互,而不需要记 IP 地址
Get 和 Post 的区别
Get 和 Post 本质是没什么区别的,如果硬要说区别,那么从以下细节来说:
- url 可见性来说:get 参数可见,post 参数不可见
- 数据传输上来说:get 通过 query string 来传输数据,没有 boby,而 post 通过 body 来传输数据
- 缓存性:get 可以缓存,post 不可以缓存
- 安全性:post 比 get 安全
url 和 uri 的区别
uri 是 url 的父类,url 是 uri 的一个子集
uri 是 统一资源标识符,url 是 统一资源定位符
请求重定向和请求转发的区别
假设你去办理一个业务执照
请求重定向:你先去A局,A局的人说,这个业务不归我们管,去B局,然后你就从A局出来,自己去了B局
请求转发:你先去了A局,A局的人说,这个业务不归我们管,但是他们没有叫你走,让你待一会,他们自己去联系B局的人,让他们办理好了给你送过来
HTTP协议的格式
HTTP协议包含:HTTP请求和HTTP响应
HTTP请求:
- 请求行:method,url,version(方法,路径,版本号)
- 请求报头
- 空行(相当于报头的结束标志,如果没有这个空行就会出粘包问题–》后面再说粘包问题)
- 请求正文
HTTP响应:
- 响应行:version,状态码,状态码描述
- 响应报头
- 空行
- 响应正文
输⼊网址之后,输⼊url 的整个过程(输入URL)
Http协议和Https有什么区别
- Http协议是超文本传输协议(应用层),信息是明文传世
- Https协议是具有安全性的SSL加密的传输协议
- Http 端口号 是 80,Https 端口号 是 443
对称加密和非对称加密
笔记本上~
Http2.0为什么能实现多路服用
TCP的粘包和拆包
首先说一下什么是粘包和拆包:
拆包:一个完整的业务可能会被TCP拆分成多个包进行发送
粘包:一个完整的业务可能会被把多个小的包封装成一个整体
粘包:
- 客户端 向 服务器 发送了两个包,接收端收到一块,因为TCP传输是不会出现丢包问题的,所以这个数据包中包含了两个数据包信息,即为粘包
粘包和拆包
2. 还有一种 就是收到的大小不一致,发生了粘包和拆包
为什么会发生粘包和拆包:
- 应用程序写入的数据 大于 套接字缓冲区大小,这样会发生拆包
- 应用程序写入的数据 小于 套接字缓冲区,这样会发生粘包
- 接收方不及时读取套接字缓冲区数据,这样会发生粘包
如何解决粘包和拆包:
- 消息定长,通过固定每次发送的数据长度,接收方同样就以这个长度作为分界区分前后两个不同的包
- 加包头,为每一个要数据添加一个
2字节或4字节的长度标识,接收方程序每次先读取该长度,然后再读取其他数据 - 在包尾部增加回车或者空格等特殊字符进行分隔
- 其他复杂协议,如 RTMP 协议等
mac地址和ip地址
MAC地址由12位16进制数组成,分为6组,每组2位,用 冒号 来隔开 08:00:20:0A:8C:6D,前6为16进制代表网络硬件制造商的编号,后6位为网卡的序号(几个网卡就有几个MAC地址,1vs1),每一个网卡的MAC地址都是独一无二的
IP长度是4个字节32位,每一个字节都是用一个点隔开,且每个字节都是用十进制表示,例如:192.168.1.56,IP地址主要是在互联网上逻辑上的代表某一台设备
IP 和 MAC 的区别:
比如: 一个小孩姓名叫张二蛋,身份证号是xxxx,世界上 叫张二蛋的很多,但是 身份证号是独一无二的,这个身份证号就 MAC 地址,姓名就是 IP 地址
进程,线程,多线程
1. 进程和线程的区别
2.线程的生命周期(状态之间的转换)
-
初始化状态(NEW):创建了一个线程但是还没有调用 start()
-
运行状态(Runnable):分为 就绪(Ready)和 运行 (Running),这两种状态统称为“运行”。就绪状态的线程在获取到 CPU 时间片之后变为运行状态
-
阻塞状态(Blocked):分为三种阻塞
- 等待阻塞:运行的线程执行
o.wait()JVM会把该线程放入等待队列中 - 同步阻塞:(lock - 》锁池)运行的线程在获取对象的
同步锁时,该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock)中 - 其他阻塞:
t.join() , Thread.sleep()
- 等待阻塞:运行的线程执行
-
等待:分为 无限等待(Waiting)和 限期等待(Timed_Waiting)
- 无限等待(Waiting)进入该状态的线程需要等待其他线程做出一些动作(通知或者中断),处于这种状态的线程不被 CPU 分配执行时间,他们要等待被唤醒
(notify,notifyAll),否则将永远处于无限期等待状态 - 超时等待(Timed_Waiting)处于这种状态的线程不会被分配 CPU 执行时间,不需要等待其他其他线程显示得唤醒,在到达一定时间自动唤醒
- 无限等待(Waiting)进入该状态的线程需要等待其他线程做出一些动作(通知或者中断),处于这种状态的线程不被 CPU 分配执行时间,他们要等待被唤醒
-
终止
3.线程的创建方式

线程池有什么好处(为什么要创建线程池)
- 降低资源消耗:通过重复利用线程池中的线程,能够避免由于我们不断创建线程,和不断销毁线程造成的资源消耗
- 提高响应速度:当任务到达线程池中,可以不需要等待线程创建就能立即执行
- 提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
回答这个问题 可能会问到 创建线程池的方式有哪些~
线程池的创建方式
线程池的创建方式总共有以下 7 种:
Executors.newFixedThreadPool:创建一个固定大小的线程池,可控制并发的线程数,超出的线程会在队列中等待。
Executors.newCachedThreadPool:创建一个可缓存的线程池,若线程数超过处理所需,缓存一段时间后会回收,若线程数不够,则新建线程。
Executors.newSingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执行顺序。
Executors.newScheduledThreadPool:创建一个可以执行延迟任务的线程池。
Executors.newSingleThreadScheduledExecutor:创建一个单线程的可以执行延迟任务的线程池。
Executors.newWorkStealingPool:创建一个抢占式执行的线程池(任务执行顺序不确定)【JDK 1.8 添加】。
ThreadPoolExecutor:手动创建线程池的方式,它创建时最多可以设置 7 个参数。
而线程池的创建推荐使用最后一种 ThreadPoolExecutor 的方式来创建,因为使用它可以明确线程池的运行规则,规避资源耗尽的风险。
用过线程池吗?核心参数是啥子?代表啥子含义底层是如何实现的
- corePoolSize 核心线程数,指线程池中长期存活的线程数(内勤)
- maximumPoolSize 最大线程数,线程池允许创建的最大线程数(内勤+外包),最大线程数不能小于核心线程数,不然运行时会有非法参数异常
- keepAliveTime 线程空闲时间,当线程池中没任务时,会销毁一些线程,销毁线程数量 = 最大线程数 - 核心线程数
- TimeUnit 时间单位,空闲线程存活时间的描述单位
- BlockingQueen 阻塞队列,用于保存线程池待执行任务的容器
- ThreadFactory 创建线程的工厂,可以设置线程的优先级,线程命名规则以及线程类型
- RejectedExecutionHandler拒绝策略,当线程池的任务超出线程池任务队列最大值,执行的策略,默认是拒绝并抛出异常
线程池执行流程
- 提交任务到线程池
- 判断核心线程数是否已满
- 已满:执行第三步
- 未满:创建一个新的线程去执行我们提交的任务
- 判断我们的阻塞队列是否已满
- 已满: 执行第4步
- 未满: 将我们提交的任务存入任务队列中等待执行
- 判断最大线程数是否已满
- 已满:执行第5步
- 未满:内部创建非核心线程去执行我们的任务
- 根据配置的拒绝策略,去处理未执行的任务

run方法和start方法的区别
线程直接调用 run()就相当于一个普通对象调用的其他方法,而只有调用 start()方法,线程才会启动,此时才具有抢占 CPU 资源的资格,当某个线程抢占到 CPU 资源后,会自动调用 run()方法
了解多线程?实现线程的几种安全模式
线程安不安全:就是多线程环境当中,存在数据共享,一个线程访问的共享数据被其他线程修改了,那么就发生了线程安全问题,反之整个访问过程中,无一共享元素被修改,线程就是安全的。
实现线程安全的方法:加锁:
synchronizedvolatile关键字lock锁
这里肯定会问 锁的相关问题~
synchronized 用法有哪些?
- 用来加锁
当我们使用 synchronized 的时候,我们不需要手动的去加锁和释放锁,JVM会自动帮我们加锁和释放锁 - 修饰静态方法
当synchronized修饰静态方法时,其作用范围是整个程序,这个锁对于所有调用这个锁的对象都是互斥的(互斥:指的是同一时间只能有一个线程能够使用),其他线程只能排队等待 - 修饰普通方法 VS 修饰静态方法
synchronized修饰普通方法和静态方法看似相同,但二者完全不同
对于静态方法来说,synchronized 加锁是全局的,也就是整个程序运行期间,所有调用这个静态方法的对象都是互斥的
对于普通方法来说:普通方法是针对对象级别的,不同的对象对应着不同的锁
synchronized 和 Lock 的主要区别
- synchronized 是一个关键字,Lock 是一个接口
- synchronized 在线程中发生异常会自动释放锁,不会死锁,而Lock不会自动释放,需要在 finally 中实现放锁
- Lock是可以中断锁,而synchronized是非中断锁,必须等待线程执行完才释放锁
- synchronized用于少量同步的情况下,性能开销大,Lock锁适用于大量同步阶段,可以提高线程进行读的效率
volatile关键字有什么用?
禁止编译器优化,保证内存可见性,被 volatile 关键字修饰的变量,如果值发生了改变,其线程立马课件,避免出现脏读现象
volatile关键字和synchronized关键字的区别
- volatile 只能修饰 变量,synchronized 可以修饰方法,静态方法,代码块(加锁)
- 多线程访问 volatile 不会发生阻塞,而 synchronized 会发生阻塞
- volatile 是变量在多线程之间的可见性,synchronized是多线程之间访问资源的同步性
- volatile 对任意单个变量的读/写具有原子性,但是类似于i++这种符合操作不具有原子性
常见锁策略
-
悲观锁 vs 乐观锁
锁冲突:两个线程争同一把锁
悲观锁:做的工作更多,付出的成本更多,更低效,锁冲突高
乐观锁:做的工作少,付出的成本少,更高效,锁冲突低 -
读写锁 vs 普通的互斥锁
读写锁:三个操作,读锁,写锁,解锁
普通互斥锁:两个操作:加锁 和 解锁 -
重量级锁 vs 轻量级锁
和上面的悲观乐观有一定重叠
重量级就是做了更多的事情,开销更大
轻量级就是做了更少的时候,开销更小
悲观锁一般都是 重量级锁
乐观锁 一般都是 轻量级锁 -
挂机等待锁 vs 自旋锁
-
公平锁 vs 非公平锁
公平:多个线程等待一把锁的时候,谁先来,谁就先获得
非公平:不遵守先来后到 -
可重入锁 vs 不可重入锁
对一个线程 加锁两次 出现死锁 不可重入
反之 可重入
什么是CAS
CAS是英文单词CompareAndSwap的缩写,中文意思是:比较并替换。CAS需要有3个操作数:内存地址V,旧的预期值A,即将要更新的目标值B。
CAS指令执行时,当且仅当内存地址V的值与预期值A相等时,将内存地址V的值修改为B,否则就什么都不做。整个比较并替换的操作是一个原子操作。
CAS 有什么缺点
- 循环时间长开销大
- 只能保证一个共享的原子操作
- ABA问题
什么是ABA问题
举个例子:我买个手机,我拿到这个手机,我无法区分,它是新机,还是翻新机(出厂后被人使用了一段时间,又回回来换个壳)