Linux篇【3】:Linux环境基础开发工具使用(下)

目录
一、Linux 调试器 - gdb 的使用
1.1、背景
1.2、开始使用
1.3、理解
二、Linux项目自动化构建工具 - make与Makefile(makefile)
2.1、背景
2.2、项目结构
三、Linux 系统中第一个小程序-倒计时
四、Linux 系统中第二个小程序-进度条
一、Linux 调试器 - gdb 的使用
1.1、背景
1、可执行程序的发布方式有两种,debug 模式和 release 模式、2、Linux 系统下,gcc/g++编译器编译出来的二进制可执行程序,默认是 release 模式、3、要使用 gdb 调试,必须在源代码生成二进制可执行程序的时候, 加上 -g 选项、
1.2、开始使用
gdb binFile ( gdb 调试命令行模式 ) 退出: ctrl + d 或 quit 指令、
常见的 gdb 调试命令行模式中的调试指令:
list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行、list/l 函数名:列出某个函数的源代码、r或run:运行程序、n 或 next:单条执行、s或step:进入函数调用、break(b) 行号:在某一行设置断点、break 函数名:在某个函数开头设置断点、info break :查看断点信息、fifinish:执行到当前函数返回,然后挺下来等待命令、print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数、p 变量:打印变量值、set var:修改变量的值、continue(或c):从当前位置开始连续而非单步执行程序、run(或r):从开始连续而非单步执行程序、delete breakpoints:删除所有断点、delete breakpoints n:删除序号为n的断点、disable breakpoints:禁用断点、enable breakpoints:启用断点、info(或i) breakpoints:参看当前设置了哪些断点、display 变量名:跟踪查看一个变量,每次停下来都显示它的值、undisplay:取消对先前设置的那些变量的跟踪、until X行号:跳至X行、breaktrace(或bt):查看各级函数调用及参数、info(i) locals:查看当前栈帧局部变量的值、quit:退出gdb、
1.3、理解
和 Windows IDE 对应理解、
[HJM@hjmlcc ~]$ whoami
HJM
[HJM@hjmlcc ~]$ pwd
/home/HJM
[HJM@hjmlcc ~]$ ls
gdb.c lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ cat gdb.c
#include
int AddToTop(int top)
{
int res=0;
int i=0;
//在Linux系统中写C语言代码时,若使用gcc编译器进行编译的话,则不能在for循环内部定义变量,即:
//不可以写成:for(int i=1;i<=top;i++),否则在编译时就会报错:‘for’ loop initial declarations
//are only allowed in C99 mode,解决方案:use option -std=c99 or -std=gnu99 to compile your
//code,具体的在后面进行阐述,但是若使用g++编译器进行编译的话,就不会报错,其次,若在Linux系统中
//写C++代码时,由于C++代码只能使用g++编译器进行编译,所以,可以在for循环内部定义变量、
//在Linux系统中,gcc编译器默认的并不是C99及其以后的版本,所以若使用gcc编译器编译C语言代码时,就
//不能在for循环内部定义变量,不支持、
//C++默认是支持在for循环中定义变量的,所以当使用g++编译器编译C语言或C++代码时,都不会报错,其次,
//C99下也是支持在for循环中定义变量的,而比如C89下是不支持在for循环中定义变量的,此时只需要我们
//指定一下C语言的版本即可,C99及C99以后的版本是都支持在for循环中定义变量的,所以我们指定一下C99
//或C99之后的版本就可以了、
for(i=1;i<=top;i++)
{
res += i;
}
return res;
}
int main()
{
int result=0;
int top=100;
result=AddToTop(top);
printf("result:%d\n",result);
return 0;
}
[HJM@hjmlcc ~]$ gcc gdb.c -o gdb
//不可以写成:gcc gdb -o gdb.c ,如果当前路径下已经存在可执行程序gdb的话,则可能导致源文件gdb.c
//中的原来的代码就没了,甚至导致该源文件gdb.c都不见了、
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ ./gdb
result:5050
//解决方法:
[HJM@hjmlcc ~]$ ls
gdb.c gdb.cpp lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ cat gdb.c
#include
int AddToTop(int top)
{
int res=0;
//int i=0;
for(int i=1;i<=top;i++)
{
res += i;
}
return res;
}
int main()
{
int result=0;
int top=100;
result=AddToTop(top);
printf("result:%d\n",result);
return 0;
}
[HJM@hjmlcc ~]$ gcc gdb.c -o gdb
gdb.c: In function ‘AddToTop’:
gdb.c:6:3: error: ‘for’ loop initial declarations are only allowed in C99 mode
for(int i=1;i<=top;i++)
^
gdb.c:6:3: note: use option -std=c99 or -std=gnu99 to compile your code
[HJM@hjmlcc ~]$ gcc gdb.c -o gdb -std=c99
//gcc gdb.c -o gdb -std=c11(C2011)也是可以的,gcc gdb.c -o gdb -std=gnu99也是可以的、
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ ./gdb
result:5050
[HJM@hjmlcc ~]$ //调试:
[HJM@hjmlcc ~]$ gdb gdb //前一个gdb是指令,后一个gdb是可执行程序的名字、
//上述指令敲回车就进入了gdb调试命令行中、
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ gdb gdb
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
在 Liunx 系统中,通过 gcc/g++ 编译器编译形成的可执行程序在默认的情况下是无法进行调试的,在 VS(Windows系统)下,默认是 Debug 版本,可以调试,所以其得到的可执行程序在默认情况下是可以直接进行调试的,但是在 Linux 系统中,默认是 release 版本,故其所得到的可执行程序在默认情况下是不可以直接进行调试的,若想要调试生成的可执行程序,则必须要手动进行设置,如下所示:
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ cat gdb.c
#include
int AddToTop(int top)
{
int res=0;
int i=0;
for(i=1;i<=top;i++)
{
res += i;
}
return res;
}
int main()
{
int result=0;
int top=100;
result=AddToTop(top);
printf("result:%d\n",result);
return 0;
}
[HJM@hjmlcc ~]$ gcc gdb.c -o gdb_Debug -g
//执行此命令,则可执行程序:gdb_Debug就会被改为Debug版本,可以直接进行调试、
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp gdb_Debug lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ ll
total 924
-rwxrwxr-x 1 HJM HJM 8392 Nov 3 11:17 gdb //8392byte、
-rw-rw-r-- 1 HJM HJM 240 Nov 3 14:43 gdb.c
-rw-rw-r-- 1 HJM HJM 453 Nov 3 10:19 gdb.cpp
-rwxrwxr-x 1 HJM HJM 9600 Nov 3 14:44 gdb_Debug //9600byte、
//由上可知,可执行程序gdb是release版本,而可执行程序gdb_Debug是Debug版本,对于可执行程
//序gdb_Debug,他相对于可执行程序gdb而言,会多出一部分调试信息,可以从两个可执行程序的体积中
//看出、
-rw-rw-r-- 1 HJM HJM 309 Nov 2 20:36 lcc.c
-rw-rw-r-- 1 HJM HJM 96 Nov 2 10:33 lcc.cpp
-rw-rw-r-- 1 HJM HJM 16921 Nov 2 10:15 lcc.i
-rw-rw-r-- 1 HJM HJM 1664 Nov 2 14:53 lcc.o
-rw-rw-r-- 1 HJM HJM 594 Nov 2 10:49 lcc.s
-rwxrwxr-x 1 HJM HJM 8408 Nov 2 20:57 mylcc
-rwxrwxr-x 1 HJM HJM 861384 Nov 2 21:48 mylcc2
[HJM@hjmlcc ~]$ ./gdb
result:5050
[HJM@hjmlcc ~]$ ./gdb_Debug
result:5050
[HJM@hjmlcc ~]$ readelf -S gdb //以段的方式来读取可执行程序的结构信息,
There are 30 section headers, starting at offset 0x1948:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000400238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000400254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000400274 00000274
0000000000000024 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000400298 00000298
000000000000001c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 00000000004002b8 000002b8
0000000000000060 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000400318 00000318
000000000000003f 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000400358 00000358
0000000000000008 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000400360 00000360
0000000000000020 0000000000000000 A 6 1 8
[ 9] .rela.dyn RELA 0000000000400380 00000380
0000000000000018 0000000000000018 A 5 0 8
[10] .rela.plt RELA 0000000000400398 00000398
0000000000000048 0000000000000018 AI 5 23 8
[11] .init PROGBITS 00000000004003e0 000003e0
000000000000001a 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000400400 00000400
0000000000000040 0000000000000010 AX 0 0 16
[13] .text PROGBITS 0000000000400440 00000440
00000000000001d2 0000000000000000 AX 0 0 16
[14] .fini PROGBITS 0000000000400614 00000614
0000000000000009 0000000000000000 AX 0 0 4
[15] .rodata PROGBITS 0000000000400620 00000620
000000000000001b 0000000000000000 A 0 0 8
[16] .eh_frame_hdr PROGBITS 000000000040063c 0000063c
000000000000003c 0000000000000000 A 0 0 4
[17] .eh_frame PROGBITS 0000000000400678 00000678
0000000000000114 0000000000000000 A 0 0 8
[18] .init_array INIT_ARRAY 0000000000600e10 00000e10
0000000000000008 0000000000000008 WA 0 0 8
[19] .fini_array FINI_ARRAY 0000000000600e18 00000e18
0000000000000008 0000000000000008 WA 0 0 8
[20] .jcr PROGBITS 0000000000600e20 00000e20
0000000000000008 0000000000000000 WA 0 0 8
[21] .dynamic DYNAMIC 0000000000600e28 00000e28
00000000000001d0 0000000000000010 WA 6 0 8
[22] .got PROGBITS 0000000000600ff8 00000ff8
0000000000000008 0000000000000008 WA 0 0 8
[23] .got.plt PROGBITS 0000000000601000 00001000
0000000000000030 0000000000000008 WA 0 0 8
[24] .data PROGBITS 0000000000601030 00001030
0000000000000004 0000000000000000 WA 0 0 1
[25] .bss NOBITS 0000000000601034 00001034
0000000000000004 0000000000000000 WA 0 0 1
[26] .comment PROGBITS 0000000000000000 00001034
000000000000002d 0000000000000001 MS 0 0 1
[27] .symtab SYMTAB 0000000000000000 00001068
0000000000000600 0000000000000018 28 46 8
[28] .strtab STRTAB 0000000000000000 00001668
00000000000001d3 0000000000000000 0 0 1
[29] .shstrtab STRTAB 0000000000000000 0000183b
0000000000000108 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
[HJM@hjmlcc ~]$ readelf -S gdb_Debug | grep debug
//打印出可执行程序gdb_Debug(Debug版本)中的调试信息、
[27] .debug_aranges PROGBITS 0000000000000000 00001061
[28] .debug_info PROGBITS 0000000000000000 00001091
[29] .debug_abbrev PROGBITS 0000000000000000 00001189
[30] .debug_line PROGBITS 0000000000000000 00001214
[31] .debug_str PROGBITS 0000000000000000 00001269
[HJM@hjmlcc ~]$ readelf -S gdb | grep debug
//发现可执行程序gdb(release版本)中不存在调试信息、
[HJM@hjmlcc ~]$ [HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp gdb_Debug lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2
[HJM@hjmlcc ~]$ gdb gdb_Debug
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
2 int AddToTop(int top)
3 {
4 int res=0;
5 int i=0;
6 for(i=1;i<=top;i++)
7 {
8 res += i;
9 }
10 return res;
(gdb) l 1 //指定从代码的第一行开始显示、
1 #include
2 int AddToTop(int top)
3 {
4 int res=0;
5 int i=0;
6 for(i=1;i<=top;i++)
7 {
8 res += i;
9 }
10 return res;
(gdb) l main //指定把包含int main()这行代码的10行(或小于10行)的代码显示出来、
8 res += i;
9 }
10 return res;
11 }
12 int main()
13 {
14 int result=0;
15 int top=100;
16 result=AddToTop(top);
17 printf("result:%d\n",result);
(gdb) l 1
1 #include
2 int AddToTop(int top)
3 {
4 int res=0;
5 int i=0;
6 for(i=1;i<=top;i++)
7 {
8 res += i;
9 }
10 return res;
(gdb) //直接敲回车,则代表在上一个指令:l 1的基础上再往后打印10行(或小于10行)的代码出来、
11 }
12 int main()
13 {
14 int result=0;
15 int top=100;
16 result=AddToTop(top);
17 printf("result:%d\n",result);
18 return 0;
19 }
(gdb) //此时所有的代码都已经显示出来,再敲回车就会提示已经打印出来了所有的代码、
Line number 20 out of range; gdb.c has 19 lines.
(gdb) b 15 //在第15行代码处打断点、
Breakpoint 1 at 0x400571: file gdb.c, line 15.
//编号为 1 的断点在普通文件gdb.c中代码的第15行、
(gdb) info b //查看已经打上的的所有的断点、
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400571 in main at gdb.c:15
(gdb) b 17
Breakpoint 2 at 0x400585: file gdb.c, line 17.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400571 in main at gdb.c:15
//编号为 1 的断点在普通文件gdb.c中代码的第15行、
2 breakpoint keep y 0x0000000000400585 in main at gdb.c:17
//编号为 2 的断点在普通文件gdb.c中代码的第17行、
(gdb) r //类似于VS下的直接F5,调试会在第一个断点处停止、
Starting program: /home/HJM/gdb_Debug
Breakpoint 1, main () at gdb.c:14
14 int result=0;
Missing separate debuginfos, use: debuginfo-install glibc-2.17-326.el7_9.x86_64
(gdb) p result //查看变量result的值,其中,p:printf、
$1 = 0
(gdb) P &result //查看变量result的地址、
$2 = (int *) 0x7fffffffe46c
(gdb) s
//逐语句,s:step,遇到函数调用会进入其中,n是逐过程,n:next,遇到函数调用不会进入函数内部、
15 int top=100;
(gdb) d 1
//删除断点,但只能按照断点的编号进行删除,1就是代表编号为1的断点,即删除编号为1的断点、
(gdb) info b
Num Type Disp Enb Address What
2 breakpoint keep y 0x0000000000400585 in main at gdb.c:17
(gdb) bt //查看函数的调用堆栈、
#0 AddToTop (top=100) at gdb.c:4
#1 0x0000000000400582 in main () at gdb.c:16
//显示在main函数中在走到第16行,在AddToTop函数中停在了第4行,但未执行第4行、
//注意:代码遇到循环的话,逐过程和逐语句都会进入循环,因为循环并不是函数调用、
(gdb) display res //添加常显示、
1: res = 0
(gdb) display i //添加常显示、
2: i = 0
(gdb) n
5 int i=0;
2: i = 0
1: res = 0
(gdb) s
6 for(i=1;i<=top;i++)
2: i = 0
1: res = 0
(gdb) n
8 res += i;
2: i = 1
1: res = 0
(gdb) s
6 for(i=1;i<=top;i++)
2: i = 1
1: res = 1
(gdb) n
8 res += i;
2: i = 2
1: res = 1
(gdb) s
6 for(i=1;i<=top;i++)
2: i = 2 //动态变化、
1: res = 3 //动态变化、
(gdb) undisplay 1 //取消编号为1(res)的常显示、
(gdb) undisplay 2 //取消编号为2(i)的常显示、
(gdb) n
8 res += i;
(gdb) s
6 for(i=1;i<=top;i++)
(gdb) display top,result
//可以一次添加多个常显示,其中:top,result = 0中的0代表的只是result的值,相当于top没有成功进行
//常显示添加,所以不推荐,最好一次添加一个常显示、
3: top,result = 0
(gdb) n
8 res += i;
3: top,result = 0
(gdb) s
6 for(i=1;i<=top;i++)
3: top,result = 0
(gdb) undisplay 3
(gdb) n
8 res += i;
(gdb) s
6 for(i=1;i<=top;i++)
(gdb)
//注意:在VS(Windows)中,若正在一个循环体中进行调试,且已经很明确的知道该循环体不会出现错误,此
//时可以点住调试的黄色箭头将其拉出到循环体外继续进行调试,但要注意的是:在这一操作中,中间略过的
//所有的程序都不会被执行,但若在 Linux 系统中出现了上述情况的话,应该怎么办呢,如下所示:
(gdb) until 10
//直接运行到普通文件gdb.c中的代码的第10行处,和VS(Windows)不同的是,此时,中间略过的所有的程序
//都会被执行、
AddToTop (top=100) at gdb.c:10
10 return res;
(gdb)
//注意:直接进入gdb调试命令行模式时,程序并未跑起来,需要输入指令 r (类似于VS(Windows)中的F5)使
//得程序跑起来,若程序中未打断点,则程序会直接一次全部运行完毕,若已经打了断点,则会停止在第一个
//断点处,整体的操作流程和VS(Windows下)中直接ctrl+F10的操作还是存在一定的区别、
//在VS(Windows)下,若想从某一个断点直接运行到该断点后的其他的第一个断点处,则可以直接F5,且中间
//略过的所有的程序都会被执行,若在Linux系统下,在gdb调试命令行下,直接输入指令c(continue),则就
//会从某一个断点直接运行到该断点后的其他的第一个断点,且中间略过的程序都会被执行,如下所示:
(gdb) b 5
Breakpoint 4 at 0x40053b: file gdb.c, line 5.
(gdb) b 11
Breakpoint 5 at 0x400560: file gdb.c, line 11.
(gdb) info b
Num Type Disp Enb Address What
4 breakpoint keep y 0x000000000040053b in AddToTop at gdb.c:5
5 breakpoint keep y 0x0000000000400560 in AddToTop at gdb.c:11
(gdb) r
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /home/HJM/gdb_Debug
Breakpoint 4, AddToTop (top=100) at gdb.c:5
5 int i=0;
(gdb) c
Continuing.
Breakpoint 5, AddToTop (top=100) at gdb.c:11
11 return res;
(gdb)
//在Linux系统中的gdb调试命令行模式中,如果使用逐语句(s)指令进入了调用函数内部,但是此时已经明
//确当前该调用函数不会出现问题,若想要直接执行完该调用函数,且返回到进入该调用函数的那一行代码
//处,则可以使用finish指令,但前提是必须要保证已经使用了逐语句(s)指令进入了调用函数内部,如下所示:
[HJM@hjmlcc ~]$ gdb gdb_Debug
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-120.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
2 int AddToTop(int top)
3 {
4 int res=0;
5 int i=0;
6 for(i=1;i<=top;i++)
7 {
8 res += i;
9 printf("%d\n",i);
10 }
(gdb)
11 return res;
12 }
13 int main()
14 {
15 int result=0;
16 int top=100;
17 result=AddToTop(top);
18 printf("result:%d\n",result);
19 return 0;
20 }
(gdb)
Line number 21 out of range; gdb.c has 20 lines.
(gdb) b 17
Breakpoint 1 at 0x400590: file gdb.c, line 17.
(gdb) r
Starting program: /home/HJM/gdb_Debug
Breakpoint 1, main () at gdb.c:17
17 result=AddToTop(top);
Missing separate debuginfos, use: debuginfo-install glibc-2.17-326.el7_9.x86_64
(gdb) s
AddToTop (top=100) at gdb.c:4
4 int res=0;
(gdb) finish
Run till exit from #0 AddToTop (top=100) at gdb.c:4
1
2
3
4
...
...
98
99
100
0x000000000040059a in main () at gdb.c:17
17 result=AddToTop(top);
Value returned is $1 = 5050
(gdb) n //此时逐语句指令s和逐过程指令n的作用是一样的、
18 printf("result:%d\n",result);
(gdb) 二、Linux项目自动化构建工具 - make与Makefile(makefile)
2.1、背景
1、会不会写 makefile/Makefile 普通文件,从侧面说明了一个人是否具备完成大型工程的能力、2、一个工程中的源普通文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile/Makefile 普通文件定义了一系列的规则来指定,哪些源普通文件需要先编译,哪些源普通文件需要后编译,哪些源普通文件需要重新编译,甚至于进行更复杂的功能操作、3、makefile/Makefile 普通文件带来的好处就是——"自动化编译",一旦写好,只需要一个make 命令,整个工程完全自动编译,极大的提高了软件开发的效率、4、make 是一个命令工具,是一个解释 makefile/Makefile 普通文件中指令的命令工具,一般来说,大多数的 IDE 都有这个命令,比如:Delphi的make,Visual C++ 的 nmake,Linux 下GNU 的 make,可见,makefile/Makefile 普通文件都成为了一种在工程方面的编译方法、5、make 是一条命令,makefile/Makefile 是一个普通文件,两个搭配使用,完成项目自动化构建、
2.2、项目结构
项目结构:
1、
代码中若存在多个 .c 源普通文件或者存在多个 .cpp 源普通文件,那么应该先编译(编译链接中的编译)哪个后编译哪个 .c 或 .cpp 源普通文件呢?一般来说,一份代码中不能同时存在 .c 和 .cpp 源普通文件、
2、链接时都需要哪些链接库呢?
3、链接库和对应的头文件等应该在哪里找呢?
4、整个项目结构应该如何维护?
以上问题在 Vs(Windows系统) 中,根本不需要自己解决,但是在 Linux 系统中,上述问题就要自己进行解决了,就比如在上述问题1中,假设一份代码中存在100个 .c 源普通文件,在此之前,如果我们想要把这些 .c 源普通文件都经过编译(编译链接中的编译)阶段生成普通目标文件(真正的),就需要一个一个的进行操作,然后,再把每一个普通目标(真正的)文件链接起来,整体再与链接库链接起来,这样就比较麻烦了,其次就是,这100个 .c 源普通文件,应该先编译(编译链接中的编译)哪个后编译哪个 .c 源普通文件呢,这都是我们需要考虑的问题,如果每一份代码都需要我们自己去考虑这些问题的话,就会比较麻烦,这是因为 Linux 系统并不是集成开发环境,除此之外,若使用 gcc 编译器进行编译时,则每次编译都需要输入指令:gcc mytest.c test.c .... ...(100个 .c 普通源文件) -o mytest,这样也会很麻烦,因此可以使用:make(指令) 和 makefile/Makefile(普通文件) 来统一解决上述问题,这样就可以避免了上述这些麻烦的操作,除此之外,使用 makefile/Makefile(普通文件) 和 make(指令) 还可以避免出现一些未定义的错误、
为了降低学习成本,目前只使用一个 .c 源普通文件进行操作,其次,对 makefile/Makefile(普通文件) 和 make(指令) 先进行简单的阐述,后面的博客会陆续更新比较深入的内容、
注意:make 本质上是一个指令,makefile/Makefile 本质上是一个普通文件、
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp gdb_Debug lcc.c lcc.cpp lcc.i lcc.o lcc.s mylcc mylcc2 mytest.c
[HJM@hjmlcc ~]$ touch Makefile //或者 touch makefile ,两者都是可以的、
[HJM@hjmlcc ~]$ ls
gdb gdb.c gdb.cpp gdb_Debug lcc.c lcc.cpp lcc.i lcc.o lcc.s Makefile mylcc mylcc2 mytest.c
[HJM@hjmlcc ~]$ vim Makefile //在普通文件Makefile或makefile中添加依赖关系和依赖方法、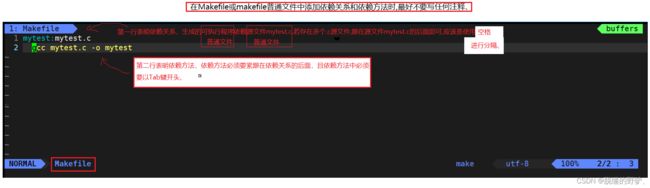
//自动化构建项目:此处所说的项目指的就是在当前路径下生成的可执行程序mytest(普通文件)、
[HJM@hjmlcc ~]$ ll
total 8
-rw-rw-r-- 1 HJM HJM 47 Nov 3 21:25 Makefile
-rw-rw-r-- 1 HJM HJM 73 Nov 3 20:50 mytest.c
[HJM@hjmlcc ~]$ cat Makefile
mytest:mytest.c
gcc mytest.c -o mytest
[HJM@hjmlcc ~]$ make
//此时只需要输入指令make,便会自动在当前路径下生成可执行程序:mytest(普通文件)、
//此处的make指令的作用就等价于在VS(Windows系统)中的生成解决方案、
gcc mytest.c -o mytest
[HJM@hjmlcc ~]$ ls
Makefile mytest mytest.c
[HJM@hjmlcc ~]$ ll
total 20
-rw-rw-r-- 1 HJM HJM 47 Nov 3 21:25 Makefile
-rwxrwxr-x 1 HJM HJM 8360 Nov 3 21:40 mytest
-rw-rw-r-- 1 HJM HJM 73 Nov 3 20:50 mytest.c
[HJM@hjmlcc ~]$ ./mytest
Hello,Linux!
[HJM@hjmlcc ~]$
//如何自动化清理(自动化构成的)项目呢,即如何自动化清理掉在当前路径下生成的可执行程序mytest(普通文件)呢?
//可以直接使用指令:rm mytest,但是当在makefile或Makefile普通文件中形成了大量的临时普通文件的话
//直接使用这种方法容易把源普通文件(mytest.c)就删掉了,故不推荐使用该方法、
//自动化清除(自动化构建的)项目:
[HJM@hjmlcc ~]$ ls
Makefile mytest mytest.c
[HJM@hjmlcc ~]$ vim Makefile
[HJM@hjmlcc ~]$ cat Makefile
mytest:mytest.c
gcc mytest.c -o mytest
.PHONY:clean
clean:
rm -f mytest
[HJM@hjmlcc ~]$ make clean
//此处的make clean指令的作用就等价于在VS(Windows系统)中的清理解决方案、
rm -f mytest
[HJM@hjmlcc ~]$ ls
Makefile mytest.c
[HJM@hjmlcc ~]$ ll
total 8
-rw-rw-r-- 1 HJM HJM 77 Nov 3 21:55 Makefile
-rw-rw-r-- 1 HJM HJM 73 Nov 3 20:50 mytest.c
[HJM@hjmlcc ~]$ 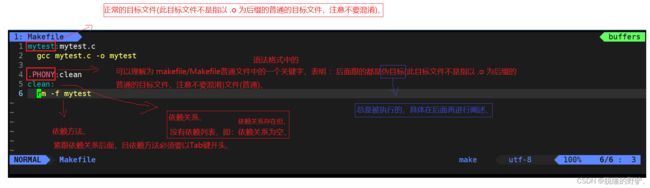 如上图所示,普通且正常的目标文件 mytest (可执行程序)和普通伪目标文件 clean,两者都是普通目标文件(此目标文件不是指以 .o 为后缀的普通的目标文件),两者都是根据自己的依赖关系来执行依赖方法,为什么在执行 make 指令时,默认只形成了普通正常的目标文件 mytest (可执行程序),而未形成普通伪目标文件 clean,若想得到普通伪目标文件 clean ,则必须执行指令:make clean (制作指定名称的普通目标文件),在 makefile/Makefile 普通文件中,从上至下进行形成普通目标文件时,可以根据需求一次形成多个普通目标文件,在后期会讲解如何使用 makefile/Makefile 普通文件一次形成多个可执行程序、
如上图所示,普通且正常的目标文件 mytest (可执行程序)和普通伪目标文件 clean,两者都是普通目标文件(此目标文件不是指以 .o 为后缀的普通的目标文件),两者都是根据自己的依赖关系来执行依赖方法,为什么在执行 make 指令时,默认只形成了普通正常的目标文件 mytest (可执行程序),而未形成普通伪目标文件 clean,若想得到普通伪目标文件 clean ,则必须执行指令:make clean (制作指定名称的普通目标文件),在 makefile/Makefile 普通文件中,从上至下进行形成普通目标文件时,可以根据需求一次形成多个普通目标文件,在后期会讲解如何使用 makefile/Makefile 普通文件一次形成多个可执行程序、
注意:当使用指令 make 在 makefile/Makefile 普通文件中形成普通目标文件时,会在 makefile/Makefile 普通文件中自动的自上往下进行扫描,默认只会形成第一个普通目标文件,执行该依赖关系的依赖方法,一般情况下,习惯把形成可执行程序的依赖关系和依赖方法放在最前面,也就是能够在执行 make 指令时直接形成可执行程序,其次还要注意:我们制定指定名称的普通目标文件并不是因为该指定名称的普通目标文件被 makefile/Makefile 普通文件中的关键字 .PHONY 修饰过,而是因为我们执行指令 make 时无法形成该普通目标文件才选择使用指定名称的方式来制作该普通目标文件、
[HJM@hjmlcc ~]$ ls
Makefile mytest.c
[HJM@hjmlcc ~]$ cat Makefile
.PHONY:clean
clean:
rm -f mytest
mytest:mytest.c
gcc mytest.c -o mytest
[HJM@hjmlcc ~]$ make
rm -f mytest
[HJM@hjmlcc ~]$ make
rm -f mytest
[HJM@hjmlcc ~]$ ls
Makefile mytest.c
[HJM@hjmlcc ~]$ make mytest
gcc mytest.c -o mytest
[HJM@hjmlcc ~]$ ls
Makefile mytest mytest.c
[HJM@hjmlcc ~]$ ./mytest
Hello,Linux!
[HJM@hjmlcc ~]$ make
rm -f mytest
[HJM@hjmlcc ~]$ ll
total 8
-rw-rw-r-- 1 HJM HJM 78 Nov 4 15:21 Makefile
-rw-rw-r-- 1 HJM HJM 73 Nov 4 09:20 mytest.c
[HJM@hjmlcc ~]$ 由上图可知:makefile/Makefile 普通文件中的 .PHONY 可以理解为:makefile/Makefile 普通文件中语法格式中的一个关键字,表明在 :后面的都是伪目标普通文件(此目标文件并不是指以 .o 为后缀的普通的目标文件,注意不要混淆),并且该伪目标普通文件总是被执行的,那么我们应该怎么理解:总是被执行和总是不被执行的这两句话呢?
[HJM@hjmlcc ~]$ ls Makefile mytest.c [HJM@hjmlcc ~]$ make gcc mytest.c -o mytest [HJM@hjmlcc ~]$ ls Makefile mytest mytest.c [HJM@hjmlcc ~]$ make make: `mytest' is up to date. [HJM@hjmlcc ~]$ make make: `mytest' is up to date. [HJM@hjmlcc ~]$ make make: `mytest' is up to date. [HJM@hjmlcc ~]$ cat Makefile mytest:mytest.c gcc mytest.c -o mytest .PHONY:clean clean: rm -f mytest [HJM@hjmlcc ~]$ //注意:在当前的 makefile/Makefile 普通文件中的关键字.PHONY 只修饰了目标文件 clean (伪目标普 //通文件),而未修饰目标文件 mytest (正常的普通目标文件(可执行程序)),此时就默认正常的普通目标 //文件(可执行程序mytest)总是不被执行的、 //若在当前路径下,已经存在了一个最新的可执行程序mytest,而当我们再执行 make 指令时,就会出现上 //面这种情况,这种现象就被称为:总是不被执行的,这种情况不仅节省时间,还可以节省资源、 [HJM@hjmlcc ~]$ ls Makefile mytest.c [HJM@hjmlcc ~]$ cat Makefile .PHONY:mytest mytest:mytest.c gcc mytest.c -o mytest .PHONY:clean clean: rm -f mytest [HJM@hjmlcc ~]$ make gcc mytest.c -o mytest [HJM@hjmlcc ~]$ ls Makefile mytest mytest.c [HJM@hjmlcc ~]$ make gcc mytest.c -o mytest [HJM@hjmlcc ~]$ ls Makefile mytest mytest.c [HJM@hjmlcc ~]$ make gcc mytest.c -o mytest [HJM@hjmlcc ~]$ ls Makefile mytest mytest.c [HJM@hjmlcc ~]$ //由上述可知,在 makefile/Makefile 普通文件中,普通目标文件(可执行程序) mytest 也被关键 //字.PHONY 修饰了,所以此时的普通目标文件(可执行程序) mytest 就是伪目标普通文件,默认则是总是被 //执行的,所以在当前路径下,即使已经存在了一个最新的可执行程序 mytest 时,当我们再执行 make 指 //令时,会出现上述这种情况,即:无论在当前路径下再执行 make 指令所得到的可执行程序 mytest 中的 //内容是新的还是旧的(仍是当前路径下已经存在的可执行程序 mytest 中的内容),则都照样根据依赖关 //系直接执行依赖方法,但是我们一般情况下不太习惯将形成的普通的目标文件 mytest (可执行程序)定 //义成伪目标普通文件,而是习惯定义成普通且正常的目标文件,并且习惯于将普通目标文件 clean 定义 //成伪目标普通文件、 [HJM@hjmlcc ~]$ ls Makefile mytest.c [HJM@hjmlcc ~]$ cat Makefile mytest:mytest.c gcc mytest.c -o mytest .PHONY:clean clean: rm -f mytest [HJM@hjmlcc ~]$ make gcc mytest.c -o mytest [HJM@hjmlcc ~]$ ls Makefile mytest mytest.c [HJM@hjmlcc ~]$ make make: `mytest' is up to date. [HJM@hjmlcc ~]$ gcc mytest.c -o mytest //等价于: gcc -o mytest mytest.c 、 [HJM@hjmlcc ~]$ gcc mytest.c -o mytest [HJM@hjmlcc ~]$ gcc mytest.c -o mytest [HJM@hjmlcc ~]$ ls Makefile mytest mytest.c [HJM@hjmlcc ~]$ //由此可知,虽然在当前路径下已经存在了最新的可执行程序 mytest ,但是如果我们执行指令:gcc //mytest.c -o mytest,却是可以的,由此可知: makefile/Makefile 普通文件中的关键字.PHONY 的起 //作用的范围只在该 makefile/Makefile 普通文件内部,出了该普通文件就不再起作用了、
Makefile/makefile 普通文件是如何识别当前路径下若再执行 make 指令所得到的可执行程序 mytest 中的内容是新的还是旧的(仍是当前路径下已经存在的可执行程序 mytest 中的内容)呢?
通过对比源普通文件 mytest.c 和可执行程序 mytest (普通文件)两者的 ModifyTime 来判断在当前路径下若再执行 make 指令所得到的可执行程序 mytest 中的内容是新的还是旧的(仍是当前路径下已经存在的可执行程序 mytest 中的内容),只要源普通文件 mytest.c 的 ModifyTime 比可执行程序 mytest (普通文件)的 ModifyTime 大,则就可以重新生成新的可执行程序 mytest (普通文件),不考虑源普通文件 mytest.c 的 ModifyTime 和可执行程序 mytest (普通文件)的 ModifyTime 相等的情况、
若在当前路径下不存在可执行程序 mytest 的话,则可随意使用 make 指令都会在当前路径下生成一个新的可执行程序 mytest ,永远不会报 " make: `mytest' is up to date. "、
而对于:总是被执行,可以理解为:忽略了时间(指的是:ModifyTime)的对比,直接根据依赖关系执行依赖方法、
[HJM@hjmlcc ~]$ ls
Makefile mytest mytest.c
[HJM@hjmlcc ~]$ stat mytest.c
File: ‘mytest.c’
Size: 73 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 664944 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1002/ HJM) Gid: ( 1002/ HJM)
Access: 2022-11-04 09:20:07.300310842 +0800
Modify: 2022-11-04 09:20:05.402310872 +0800
Change: 2022-11-04 09:20:05.402310872 +0800
Birth: -
[HJM@hjmlcc ~]$ stat mytest
File: ‘mytest’
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 663317 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1002/ HJM) Gid: ( 1002/ HJM)
Access: 2022-11-04 16:43:09.315974630 +0800
Modify: 2022-11-04 16:43:09.132974639 +0800
Change: 2022-11-04 16:43:09.132974639 +0800
Birth: -
[HJM@hjmlcc ~]$ touch mytest.c
//该指令还可以更新文件(所有的文件,包括目录文件和普通文件等等)的时间戳、
[HJM@hjmlcc ~]$ stat mytest.c
File: ‘mytest.c’
Size: 73 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 664944 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1002/ HJM) Gid: ( 1002/ HJM)
Access: 2022-11-04 16:43:51.319972645 +0800
Modify: 2022-11-04 16:43:49.709972721 +0800
Change: 2022-11-04 16:43:49.709972721 +0800
Birth: -
[HJM@hjmlcc ~]$ stat mytest
File: ‘mytest’
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 663317 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1002/ HJM) Gid: ( 1002/ HJM)
Access: 2022-11-04 16:43:09.315974630 +0800
Modify: 2022-11-04 16:43:09.132974639 +0800
Change: 2022-11-04 16:43:09.132974639 +0800
Birth: -
[HJM@hjmlcc ~]$ make
gcc mytest.c -o mytest
[HJM@hjmlcc ~]$ make
make: `mytest' is up to date.
[HJM@hjmlcc ~]$ [HJM@hjmlcc ~]$ ls
Makefile mytest mytest.c
[HJM@hjmlcc ~]$ stat mytest
//查看文件(所有文件:包括普通文件和目录文件等等)的各种时间(属性)、
File: ‘mytest’
Size: 8360 Blocks: 24 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 663317 Links: 1
Access: (0775/-rwxrwxr-x) Uid: ( 1002/ HJM) Gid: ( 1002/ HJM)
Access: 2022-11-04 15:58:41.311132643 +0800
Modify: 2022-11-04 15:58:40.383132674 +0800
Change: 2022-11-04 15:58:40.383132674 +0800
Birth: -
[HJM@hjmlcc ~]$
//文件包括文件的内容和文件的属性,文件有自己的时间,在 Linux 系统下,文件的时间有三个,分
//别是:Access,Modify和Change,其中:Access记录的是读取或进入该文件的时间,Modify记录的是修改该
//文件内容时的时间,Change记录的是修改该文件属性时的时间、
//注意:
//改变文件属性时,不会影响文件的 Modify 时间,但是有些情况下,改变了文件内容时,会影响文件的Change
//时间,比如增添了文件的内容,那么该文件属性中的所占内存空间的大小就随之改变了,也就相当于自动改
//变了该文件的属性,那么相应的该文件的 Change 的时间就发生变化了,经过测试发现,修改文件内容的
//基础是已经进入了该文件中,而现在发现,在修改文件内容时,该文件的Access时间有时候发生改变,有时
//候并未改变,这是因为,进入或读取文件的操作的频率是很高的,如果每次进入或读取文件时,对应的
//Access时间都发生改变的话,这个过程就会造成时间和资源的浪费,因此在比较新的 Linux 内核版本中,
//就对这种情况进行了优化,即:在 Linux 系统中,会将读取或进入文件的次数累积到一定的数量之后才会
//改变该文件的Access时间,Access(文件的各个)时间也属于该文件的属性部分(暂时不考虑这三个时间(
//文件的属性)的变化导致该文件的 Change 时间的变化)、[HJM@hjmlcc ~]$ ls
main.c test.c test.h
[HJM@hjmlcc ~]$ cat main.c
#include"test.h"
int main()
{
show();
return 0;
}
[HJM@hjmlcc ~]$ cat test.c
#include"test.h"
void show()
{
printf("You can see me\n");
printf("You can see me\n");
printf("You can see me\n");
printf("You can see me\n");
printf("You can see me\n");
}
[HJM@hjmlcc ~]$ cat test.h
#pragma once
#include
//关键字extern可以省略、
extern void show();
//方法一(1):
[HJM@hjmlcc ~]$ gcc -o hello test.c main.c //不用把头文件(普通文件) test.h 放进指令中、
[HJM@hjmlcc ~]$ ls
hello main.c test.c test.h
[HJM@hjmlcc ~]$ ./hello
You can see me
You can see me
You can see me
You can see me
You can see me
//方法一(2):
[HJM@hjmlcc ~]$ gcc -o hello2 main.c test.c //不用把头文件(普通文件) test.h 放进指令中、
[HJM@hjmlcc ~]$ ls
hello hello2 main.c test.c test.h
[HJM@hjmlcc ~]$ ./hello2
You can see me
You can see me
You can see me
You can see me
You can see me
[HJM@hjmlcc ~]$
//上述方法一(1和2)中,均未考虑先编译哪个源普通文件,后编译哪个源普通文件,但是这种方法每次在形成
//可执行程序(hello和hello2)时,都需要输入指令gcc -o hello test.c main.c或gcc -o hello2
//main.c test.c,若该代码中还存在更多的 .c 源普通文件时,当使用上述两条指令时就会更加复杂,所以
//不推荐使用这种方法、
//方法二:
[HJM@hjmlcc ~]$ ls
main.c makefile test.c test.h
[HJM@hjmlcc ~]$ cat makefile // cat Makefile 也是可以的、
//在makefile和Makefile普通文件中,hello:main.c test.c指令中的main.c和test.c的顺序可以颠倒,在
//指令gcc -o hello main.c test.c中的main.c和test.c的顺序也可颠倒、
hello:main.c test.c
gcc -o hello main.c test.c
.PHONY:clean
clean:
rm -f hello
[HJM@hjmlcc ~]$ make
gcc -o hello main.c test.c
[HJM@hjmlcc ~]$ ls
hello main.c makefile test.c test.h
[HJM@hjmlcc ~]$ ./hello
You can see me
You can see me
You can see me
You can see me
You can see me
[HJM@hjmlcc ~]$ ls
hello main.c makefile test.c test.h
[HJM@hjmlcc ~]$ make clean
rm -f hello
[HJM@hjmlcc ~]$ ls
main.c makefile test.c test.h
[HJM@hjmlcc ~]$
//方法二中,未考虑先编译哪个源普通文件,后编译哪个源普通文件,并且上述这种方法每次在形成可执行程
//序时,直接使用指令 make 就可以了,会方便很多、
//方法二拓展(更倾向于选择该方法):
[HJM@hjmlcc ~]$ ls
main.c makefile test.c test.h
[HJM@hjmlcc ~]$ cat makefile //cat Makefile 也是可以的、
hello:main.o test.o
gcc -o hello main.o test.o
main.o:main.c
gcc -c main.c -o main.o
test.o:test.c
gcc -c test.c -o test.o
.PHONY:clean
clean:
rm -f *.o hello
[HJM@hjmlcc ~]$ ls
main.c makefile test.c test.h
[HJM@hjmlcc ~]$ make
gcc -c main.c -o main.o
gcc -c test.c -o test.o
gcc -o hello main.o test.o
[HJM@hjmlcc ~]$ ls
hello main.c main.o makefile test.c test.h test.o
[HJM@hjmlcc ~]$ ./hello
You can see me
You can see me
You can see me
You can see me
You can see me
[HJM@hjmlcc ~]$ ls
hello main.c main.o makefile test.c test.h test.o
[HJM@hjmlcc ~]$ make clean
rm -f *.o hello
[HJM@hjmlcc ~]$ ls
main.c makefile test.c test.h
[HJM@hjmlcc ~]$
//1、
//上述方法二拓展中,未考虑先编译哪个源普通文件,后编译哪个源普通文件,可以把第3和4行代码与5和6行
//代码交换位置,并且第1和2行指令中的main.o和test.o的顺序可以交换,其次,当执行第1行代码时,不存
//在普通目标文件(真正的目标文件)main.o和test.o,那么此时在makefile/Makefile普通文件中将会使
//用第2行及其下面的代码形成普通目标文件(真正的目标文件)main.o和test.o,其形成的先后顺序无所谓、
//2、
//其次我们知道,当使用指令make在makefile/Makefile普通文件中形成普通目标文件(非真正的目标文件)
//时,会在makefile/Makefile普通文件中自动的自上往下进行扫描,默认只会形成第一个普通目标文件(
//非真正的目标文件),执行该依赖关系的依赖方法,但是在形成普通且正常的目标文件(非真正的目标
//文件)hello(可执行程序)时,还不存在普通且正常的目标文件(非真正的目标文件)main.o(真正的普通目
//标文件)和test.o(真正的普通目标文件),所以此时这种情况下,直接使用make指令默认还会形成普通且
//正常的目标文件(非真正的目标文件)main.o(真正的普通目标文件)和test.o(真正的普通目标文件)、
//3、
//最后,指令gcc -c main.c和指令gcc -c main.c -o main.o的作用是一样的,只写指令gcc -c main.c
//在makefile/Makefile普通文件中也会把结果放到与main同名的以.o为后缀的临时普通目标文件(真正
//的目标文件)中、
//4、
//指令rm -f *.o,代表删除所有以.o为后缀的普通目标文件(真正的目标文件),注意,*与.中间不能有空格
//,否则就代表删除所有的文件(包括普通文件和目录文件等等),*是通配符,指令rm -f *.o hello代表在
//前面的基础上再删除掉可执行程序hello、
//5、
//并且上述这种方法每次在形成可执行程序hello时,直接使用指令make就可以了,会方便很多,其次使
//用makefile/Makefile普通文件直接可以生成多个以.o为后缀的普通目标文件(真正的目标文件),不需
//要自己一个个的手动生成、
//方法三:
[HJM@hjmlcc ~]$ ls
main.c test.c test.h
[HJM@hjmlcc ~]$ gcc -o hello *.c //或 gcc *.c -o hello
[HJM@hjmlcc ~]$ ls
hello main.c test.c test.h
[HJM@hjmlcc ~]$ ./hello
You can see me
You can see me
You can see me
You can see me
You can see me
[HJM@hjmlcc ~]$
//方法三在后期讲解使用makefile/Makefile普通文件一次形成多个可执行程序时,就会造成混淆,最好不
//要采用这种方法、 实例代码:
[HJM@hjmlcc ~]$ ls hello.c makefile [HJM@hjmlcc ~]$ cat hello.c #includeint main() { printf("hello,M/makefile\n"); return 0; } [HJM@hjmlcc ~]$ cat makefile hello:hello.o gcc -o hello hello.o hello.o:hello.s gcc -c hello.s -o hello.o hello.s:hello.i gcc -S hello.i -o hello.s hello.i:hello.c gcc -E hello.c -o hello.i .PHONY:.clean clean: rm -f hello.i hello.s hello.o hello [HJM@hjmlcc ~]$ ls hello.c makefile [HJM@hjmlcc ~]$ make gcc -E hello.c -o hello.i gcc -S hello.i -o hello.s gcc -c hello.s -o hello.o gcc -o hello hello.o [HJM@hjmlcc ~]$ ls hello hello.c hello.i hello.o hello.s makefile [HJM@hjmlcc ~]$ ./hello hello,M/makefile [HJM@hjmlcc ~]$ ls hello hello.c hello.i hello.o hello.s makefile [HJM@hjmlcc ~]$ make clean rm -f hello.i hello.s hello.o hello [HJM@hjmlcc ~]$ ls hello.c makefile [HJM@hjmlcc ~]$ 依赖方法:gcc hello.* -option hello.* //就是与之对应的依赖关系、原理:make 指令是如何工作的,在默认的方式下,也就是我们只输入 make 命令,那么:1、make 指令会在当前目录下找名字叫 "Makefile" 或 "makefile" 的普通文件、2、如果找到,它会找该普通文件中的第一个普通目标文件(非真正的),在上面的例子中,他会找到 "hello" 这个正常且普通的目标文件(非真正的),并把这个正常且普通的目标文件(非真正的)作为最终的普通目标文件(非真正的)、3、如果 hello 这个正常且普通的目标文件(非真正的)不存在,或是 hello 这个正常且普通的目标文件(非真正的)所依赖的后面的 hello.o 这个普通目标文件(真正的)的 ModifyTime 要比hello 这个正常且普通的目标文件(非真正的)新,那么,他就会根据该依赖关系执行该依赖方法来形成一个新的可执行程序 hello (普通文件)、4、如果 hello 这个正常且普通的目标文件(非真正的)所依赖的 hello.o 这个普通目标文件(真正的)不存在,那么 make 指令会在当前 makefile/Makefile 普通文件中找正常且普通的目标文件(非真正)为 hello.o (真正的普通目标文件) 的依赖关系,如果找到,则再根据那一个依赖方法生成正常且普通的目标文件(非真正的) hello.o (真正的普通目标文件),这有点像一个堆栈的过程、5、当然,你的C文件和H文件是存在的了,于是 make 指令会生成正常且普通的目标文件(非真正的目标文件) hello.o (真正的普通目标文件),然后再用它来生成正常且普通的目标文件(非真正的目标文件) hello (可执行程序)了、6、这就是整个 make 指令的依赖性,make 指令会一层又一层地去找普通目标文件(非真正的目标文件)的依赖关系,直到最终编译出第一个普通目标文件(非真正的目标文件)、7、在找寻的过程中,如果出现错误,比如最后被依赖的普通文件找不到,那么 make 指令就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make 指令根本不理、8、make 指令只管普通目标文件(非真正的目标文件)的依赖性,即,如果在我找到了依赖关系之后,冒号后面的普通文件还是不在,那么对不起,我就不工作啦、项目清理,即:自动化清理项目,工程是需要被清理的:1、像 clean 这种,没有被第一个普通目标文件(非真正的普通目标文件) 直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显式的要 make 指令执行,即命令:make clean,以此根据需求来完成项目的清除,以便重新编译、2、但是一般这种 clean 的普通目标文件(非真正的普通目标文件),我们习惯将它设置为普通伪目标文件(非真正的普通目标文件),用关键字 .PHONY 进行修饰,普通伪目标文件(非真正的普通目标文件)的特性是,总是被执行的、
三、Linux 系统中第一个小程序-倒计时
预备知识点:
//方法一:
[HJM@hjmlcc ~]$ man 3 sleep
//在Linux系统下查询c语言的函数(库函数)、
//以秒为单位进行休眠、
SLEEP(3) Linux Programmer's Manual SLEEP(3)
NAME
sleep - sleep for the specified number of seconds
SYNOPSIS
#include
unsigned int sleep(unsigned int seconds);
DESCRIPTION
sleep() makes the calling thread sleep until seconds seconds have elapsed or a signal arrives which is not ignored.
RETURN VALUE
Zero if the requested time has elapsed, or the number of seconds left to sleep, if the call was interrupted by a signal handler.
CONFORMING TO
POSIX.1-2001.
BUGS
sleep() may be implemented using SIGALRM; mixing calls to alarm(2) and sleep() is a bad idea.
Using longjmp(3) from a signal handler or modifying the handling of SIGALRM while sleeping will cause undefined results.
SEE ALSO
alarm(2), nanosleep(2), signal(2), signal(7)
COLOPHON
This page is part of release 3.53 of the Linux man-pages project. A description of the project, and information about reporting
bugs, can be found at http://www.kernel.org/doc/man-pages/.
GNU 2010-02-03 SLEEP(3)
Manual page sleep(3) line 1 (press h for help or q to quit)
//方法二:
//还可以在Linux系统中的vim里面的命令模式下查询c语言的函数(库函数),但是必须要加上!,如下所示:
//在vim的命名模式中输入!man 3 sleep,得到如下所示内容:
unsigned int sleep(unsigned int seconds);
DESCRIPTION
sleep() makes the calling thread sleep until seconds seconds have
elapsed or a signal arrives which is not ignored.
RETURN VALUE
Zero if the requested time has elapsed, or the number of seconds left
to sleep, if the call was interrupted by a signal handler.
CONFORMING TO
POSIX.1-2001.
BUGS
sleep() may be implemented using SIGALRM; mixing calls to alarm(2) and
sleep() is a bad idea.
Using longjmp(3) from a signal handler or modifying the handling of
SIGALRM while sleeping will cause undefined results.
SEE ALSO
alarm(2), nanosleep(2), signal(2), signal(7)
COLOPHON
This page is part of release 3.53 of the Linux man-pages project. A
description of the project, and information about reporting bugs, can
be found at http://www.kernel.org/doc/man-pages/.
GNU 2010-02-03 SLEEP(3)
Press ENTER or type command to continue [HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
printf("hello,M/makefile\n"); //1
sleep(2); //2
return 0;
}
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ls
a.out mytest.c
[HJM@hjmlcc ~]$ ./a.out
hello,M/makefile
[HJM@hjmlcc ~]$
//1、
//当使用指令./a.out运行可执行程序a.out时,在显示器(终端/外设)上直接先打印出hello,M/makefile,
//再进行换行操作,然后休眠2秒,再打印出[HJM@hjmlcc ~]$ ,注意:此时是先执行部分1的代码,再执行部
//分2的代码、
//2、
//当运行部分1的代码时,运行结果放到了缓冲区内,但是由于字符串"hello,M/makefile\n"中含有字符'\n'
//即该行字符串能够构成一个完整行,所以会直接从缓冲区内刷新到显示器(终端/外设)上,所以我们看到的
//现象是:直接将hello,M/makefile打印出来,进行换行操作,再进行休眠2秒,当遇到return(或main函数
//结束时,只考虑代码中只有main函数的情况,其他情况暂时不考虑)时,缓冲区内没有任何内容,等main函
//数结束后,最后再打印出来[HJM@hjmlcc ~]$ ,注意:此处的实验可能和vs(Windows系统)下的现象不一样
//在vs下,如上面的部分1处的代码,即使不加字符'\n',也会先在显示器(终端/外设)上打印出
//hello,M/makefile,然后再进行休眠2秒,最后打印出[HJM@hjmlcc ~]$ ,这一点要注意,我们只考虑
//在Linux系统下的现象即可、
//3、
//有没有办法,即:不想使用字符'\n',但是就想让内容从缓冲区内立马刷新出来到显示器(终端/外设),怎
//么做呢,如下所示:
[HJM@hjmlcc ~]$ man stdout
STDIN(3) Linux Programmer's Manual STDIN(3)
NAME
stdin, stdout, stderr - standard I/O streams
SYNOPSIS
#include
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;
//在后期讲解文件系统时再进行具体的阐述,一般一个程序在启动时,默认会打开三个如上所示的输入输出流
//如果我们想让缓冲区的内容立马刷新出来到显示器(外设/终端),还有另外一个方法就是,手动刷新一
//下stdout,即手动刷新一下标准输出流,因为我们要打印在显示器(终端/外设)上,所以刷新的应该
//是stdout(标准输出流),具体方法如下所示:
DESCRIPTION
Under normal circumstances every UNIX program has three streams opened for it when it starts up, one for input, one for output,
and one for printing diagnostic or error messages. These are typically attached to the user's terminal (see tty(4) but might
instead refer to files or other devices, depending on what the parent process chose to set up. (See also the "Redirection" sec‐
tion of sh(1).)
The input stream is referred to as "standard input"; the output stream is referred to as "standard output"; and the error stream
is referred to as "standard error". These terms are abbreviated to form the symbols used to refer to these files, namely stdin,
stdout, and stderr.
Each of these symbols is a stdio(3) macro of type pointer to FILE, and can be used with functions like fprintf(3) or fread(3).
Since FILEs are a buffering wrapper around UNIX file descriptors, the same underlying files may also be accessed using the raw
UNIX file interface, that is, the functions like read(2) and lseek(2).
On program startup, the integer file descriptors associated with the streams stdin, stdout, and stderr are 0, 1, and 2, respec‐
tively. The preprocessor symbols STDIN_FILENO, STDOUT_FILENO, and STDERR_FILENO are defined with these values in .
(Applying freopen(3) to one of these streams can change the file descriptor number associated with the stream.)
Note that mixing use of FILEs and raw file descriptors can produce unexpected results and should generally be avoided. (For the
Manual page stdout(3) line 1 (press h for help or q to quit)
[HJM@hjmlcc ~]$ man 3 fflush
FFLUSH(3) Linux Programmer's Manual FFLUSH(3)
NAME
fflush - flush a stream
SYNOPSIS
#include
int fflush(FILE *stream);
DESCRIPTION
For output streams, fflush() forces a write of all user-space buffered data for the given output or update stream via the stream's
underlying write function. For input streams, fflush() discards any buffered data that has been fetched from the underlying file,
but has not been consumed by the application. The open status of the stream is unaffected.
If the stream argument is NULL, fflush() flushes all open output streams.
For a nonlocking counterpart, see unlocked_stdio(3).
RETURN VALUE
Upon successful completion 0 is returned. Otherwise, EOF is returned and errno is set to indicate the error.
ERRORS
EBADF Stream is not an open stream, or is not open for writing.
The function fflush() may also fail and set errno for any of the errors specified for write(2).
ATTRIBUTES
Multithreading (see pthreads(7))
The fflush() function is thread-safe.
CONFORMING TO
Manual page fflush(3) line 1 (press h for help or q to quit)
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
printf("hello,M/makefile"); //1
fflush(stdout);
sleep(2); //2
return 0;
}
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ls
a.out mytest.c
[HJM@hjmlcc ~]$ ./a.out
hello,M/makefile[HJM@hjmlcc ~]$
//此时,使用指令./a.out运行可执行程序a.out时,现象即为:在显示器(终端/外设)直接打印出
//来hello,M/makefile,然后休眠2秒,再打印出[HJM@hjmlcc ~]$ ,本质上就是当执行部分1的代码时,将
//结果存放到缓冲区内,但是由于缓冲区没满,也没有遇到return(或main函数结束时,只考虑代码中只有
//main函数的情况,其他情况暂时不考虑),也没有遇到换行符'\n',所以该结果不会被直接刷新到显示器
//(外设/终端)上,但是遇到了程序fflush(stdout); ,故直接将缓冲区的所有内容刷新到显示器
//(外设/终端)上,然后再休眠2秒,当遇到return 0;时,缓冲区内就没有任何内容了,最后当main函数整体
//全部结束后,再打印出[HJM@hjmlcc ~]$ 、 [HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
printf("hello,M/makefile"); //1
sleep(2); //2
return 0;
}
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ls
a.out mytest.c
[HJM@hjmlcc ~]$ ./a.out
hello,M/makefile[HJM@hjmlcc ~]$
//这种情况下,还是先执行部分1代码,再执行部分2代码,记住,默认情况下都是自上往下依次执行(跳转,
//循环,判断等等特殊情况除外),这就是顺序结构,也叫作默认结构,但是当使用指令./a.out运行可执行程
//序a.out时,现象则是:先休眠2秒,然后先打印出hello,M/makefile,再打印出[HJM@hjmlcc ~]$ 、
//这是因为:1部分的代码先执行了,但是执行后的结果并没有显示在终端(显示器/外设),而是将结果放到
//了缓冲区,然后休眠2秒,程序遇到了return 0;时,此时将缓冲区的所有内容显示在终端(显示器/外设)上
//当main函数全部执行完毕之后,再在终端(显示器/外设)上打印出[HJM@hjmlcc ~]$
//在后期讲解文件系统,c语言中相关的概念和基础IO时,就明确缓冲区(输入缓冲区和输出缓冲区等等)到
//底在哪里了,缓冲区有很多,本质上,缓冲区就是一段内存空间,内容只要在内存空间中,就不会出现在外
//设中,而此处的终端(显示器)就可以理解成外设,此时缓冲区中的内容就没有打印在显示器(终端/外设)、
//在内存空间中的内容分为两种策略:
//立马将内存空间中的内容显式在显示器(终端/外设)上,使得在内存空间中的内容出去内存空间外面,对
//应的就是刷新策略,其中:行刷新策略就是要在显示器(终端/外设)上打印的这一个字符串中,是不是一个
//完整行,只要是一个完整行,就会被直接刷新到显示器(终端/外设)上,若不是,则不刷新,只能等缓冲区满
//了或者程序遇到return(或main函数结束时,只考虑代码中只有main函数的情况,其他情况暂时不考虑)时
//或者遇到换行符'\n'时,再进行刷新,字符串中每一个字符'\n'以及该字符前面的所有内容整体构成了一
//个完整行、 注意:
我们平常所谓的 "回车" 和 "换行" 都代表另起一行并且从头开始,但是本质上,回车只是将光标移动到当前行的开始,而换行只是将光标由上一行变换到同一列的下一行中,我们平常所谓的 "回车" 和 "换行" ,两者中每一个都是回车与换行的组合,我们在平常时还可以按照 "回车" 和 "换行" 去理解,但是在本质与平常两者中我们要能够进行区分,我们平常所谓的 "回车" 和 "换行" 都可以使用字符 '\n' 来表达他们的意思,但是对于本质上的回车而言,我们使用字符 '\r' 来表达其意思,对于本质上的换行而言,由于不常用,可以不用了解、
//1、
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
int cnt=9;
while(cnt>=0)
{
printf("%d",cnt--);
sleep(1);
}
return 0;
}
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ls
a.out mytest.c
[HJM@hjmlcc ~]$ ./a.out
9876543210[HJM@hjmlcc ~]$
//现象:当使用指令./a.out运行可执行程序a.out时,先等待10s,然后打印出9876543210,最后再打印
//出[HJM@hjmlcc ~]$ ,这是因为,由于代码语句:printf("%d",cnt--);中不存在字符'\n',在循环过程
//中产生的结果都放在了缓冲区内,这10s内,在显示器(终端/外设)中都不打印任何内容,直到程序遇
//到return 0;时,将缓冲区中的所有内容(9876543210)全部刷新到显示器(终端/外设)中,然后当main函
//数整体全部执行完毕后,再在显示器(终端/外设)中打印出[HJM@hjmlcc ~]$
//2、
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
int cnt=9;
while(cnt>=0)
{
printf("%d\n",cnt--);
sleep(1);
}
return 0;
}
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ls
a.out mytest.c
[HJM@hjmlcc ~]$ ./a.out
9
8
...
...
1
0
[HJM@hjmlcc ~]$
//3、
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
int cnt=9;
while(cnt>=0)
{
printf("%d",cnt--);
fflush(stdout);
sleep(1);
}
return 0;
}
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ls
a.out mytest.c
[HJM@hjmlcc ~]$ ./a.out
9876543210[HJM@hjmlcc ~]$
//现象:当使用指令./a.out运行可执行程序a.out时,直接在显示器(终端/外设)中打印9,然后等待1s,再
//在显示器(终端/外设)中打印8,然后再等待1s,重复上述过程,直到在显示器(终端/外设)中打印出0,等待
//1s后,然后再在显示器(终端/外设)中打印出[HJM@hjmlcc ~]$ ,这是因为,当第一次循环执行
//指令:printf("%d",cnt--);时,将结果9放进了缓冲区内,然后执行代码:fflush(stdout);又将缓冲区
//内的所有内容刷新到显示器(终端/外设)中,然后休眠1s,重复上述过程,直到将结果0放进了缓冲区内,
//然后执行代码:fflush(stdout);又将缓冲区内的所有内容刷新到显示器(终端/外设)中,然后休眠1s,等
//程序执行到return 0;时,缓冲区内已经没有任何内容了,然后再等到main函数整体全部执行完毕后,再在
//显示器(终端/外设)中打印出[HJM@hjmlcc ~]$
//4、
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ cat mytest.c
#include
#include
int main()
{
int cnt=9;
while(cnt>=0)
{
printf("%d\r",cnt--);
fflush(stdout);
sleep(1);
}
return 0;
}
[HJM@hjmlcc ~]$ ls
mytest.c
[HJM@hjmlcc ~]$ gcc mytest.c
[HJM@hjmlcc ~]$ ./a.out
[HJM@hjmlcc ~]$
//现象:当使用指令./a.out运行可执行程序a.out时,直接在显示器(终端/外设)中打印出9,然后等待1s,
//再在显示器(终端/外设)中打印出8,并且覆盖掉之前的9,重复上述过程,直到在显示器(终端/外设)中打
//印出0,并且覆盖掉之前的1,当程序执行到return 0;时,缓冲区内不存在任何内容,当main函数整体执行
//完毕后,再在显示器(终端/外设)中打印出[HJM@hjmlcc ~]$ ,且覆盖掉之前的0,这是因为,当第一次循
//环执行指令:printf("%d\r",cnt--);时,将结果9'\r'放到了缓冲区,但是不存在字符'\n',所以不会马
//上将其刷新到显示器(终端/外设)中,但是当遇到代码:fflush(stdout);时,会将缓冲区内的所有内容全
//部刷新到显示器(终端/外设)中,此时会在显示器(终端/外设)中打印出9,并且再执行字符'\r',将光标置
//为显示器(终端/外设)中的9的前面,重复上述操作,直到最后将0'\r'从缓冲区中刷新到显示器(终端/外设
//)中,此时,0把显示器(终端/外设)中的1覆盖掉,且将光标置为显示器(终端/外设)中的0的前面,然后等执
//行代码:return 0;时,缓冲区内不存在任何内容,当main函数整体执行完毕后,又在显示器(终端/外设)
//中打印出[HJM@hjmlcc ~]$ ,而此时光标位于显示器(终端/外设)中的0的前面,所以会把0覆盖掉,打印
//出[HJM@hjmlcc ~]$ ,其次,此时的光标则位于显示器(终端/外设)中的[HJM@hjmlcc ~]$的后面,因为
//此时的字符'\r'将不再起作用、 四、Linux 系统中第二个小程序-进度条
预备知识点:
[HJM@hjmlcc ~]$ ls
code process.c
//下述指令:ls > Makefile,或 ls > makefile,代表的是:使用当前路径下存在的所有文件(包括普通文件
//和目录文件等等)的文件名形成一个makefile/Makefile普通文件、
[HJM@hjmlcc ~]$ ls > Makefile
[HJM@hjmlcc ~]$ ls
code Makefile process.c
[HJM@hjmlcc ~]$ cat Makefile
//此时在makefile/Makefile普通文件中存在内容:上述注释中的所有文件(包括普通文件和目录文件等等)的
//文件名(文本)当做了makefile/Makefile普通文件中内容(文本),并且在makefile/Makefile普通文件中
//还存在与形成的普通文件(makefile或Makefile)同名的内容Makefile(文本)、
code
Makefile
process.c
[HJM@hjmlcc ~]$ [HJM@hjmlcc ~]$ man 3 usleep
//以微秒为单位进行休眠,1(s)=10^6(us)、
USLEEP(3) Linux Programmer's Manual USLEEP(3)
NAME
usleep - suspend execution for microsecond intervals
SYNOPSIS
#include
int usleep(useconds_t usec);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
usleep():
Since glibc 2.12:
_BSD_SOURCE ||
(_XOPEN_SOURCE >= 500 ||
_XOPEN_SOURCE && _XOPEN_SOURCE_EXTENDED) &&
!(_POSIX_C_SOURCE >= 200809L || _XOPEN_SOURCE >= 700)
Before glibc 2.12:
_BSD_SOURCE || _XOPEN_SOURCE >= 500 || _XOPEN_SOURCE && _XOPEN_SOURCE_EXTENDED
DESCRIPTION
The usleep() function suspends execution of the calling thread for (at least) usec microseconds. The sleep may be lengthened
slightly by any system activity or by the time spent processing the call or by the granularity of system timers.
RETURN VALUE
The usleep() function returns 0 on success. On error, -1 is returned, with errno set to indicate the cause of the error.
ERRORS
EINTR Interrupted by a signal; see signal(7).
EINVAL usec is not smaller than 1000000. (On systems where that is considered an error.)
Manual page usleep(3) line 1 (press h for help or q to quit) [HJM@hjmlcc ~]$ ls
Makefile process.c
[HJM@hjmlcc ~]$ cat Makefile
process:process.c
gcc process.c -o process
.PHONY:clean
clean:
rm -f process
[HJM@hjmlcc ~]$ cat process.c
#include
#include
#include
#define STYLE '#'
#define NUM 101 //在显示器(终端/外设)中,0%对应0个#,100%对应100个#,当做一个字符串来看,要留一个位置给字符'\0'、
void process()
{
//1、
char bar[NUM]={0};
//2、
//char bar[NUM];
//memset(bar,'\0',sizeof(bar));
const char* lable="|/-\\"; //存在转义字符、
int cnt=0;
while(cnt<=100)
{
//格式控制:在显示器(终端/外设)中输出一个字符串时,预先留出100个空间、
//printf("[%-100s][%d%%][%c]\r",bar,cnt,lable[cnt%4]); //C语言中的对齐方式默认从右往左,该行语句中的[%d%%]可以使用[%d\%]来替换、
printf("\033[46;34m%-100s\033[0m[%d%%][%c]\r",bar,cnt,lable[cnt%4]);
fflush(stdout);
bar[cnt++]=STYLE;
usleep(200000);
}
//此处光标位于显示器(终端/外设)中某一行内容的最前面,若执行下面语句的话,只是会将光标进行"回车"或"换行",而该行内容不会随着进行"回车"或"换行",只是光标会发生移动、
printf("\n");
}
int main()
{
process();
return 0;
}
[HJM@hjmlcc ~]$ make
gcc process.c -o process
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ ./process
####################################################################################################[100%][|]
[HJM@hjmlcc ~]$ ls
Makefile process process.c
[HJM@hjmlcc ~]$ make clean //make clean;make 代表先执行指令make clean,再执行指令make、
rm -f process
[HJM@hjmlcc ~]$ ls
Makefile process.c
[HJM@hjmlcc ~]$
有关C语言中 printf 库函数输出颜色,请参考博客:
//链接:
https://blog.csdn.net/weixin_36138385/article/details/117103723?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166771772216782388069597%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=166771772216782388069597&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-117103723-null-null.nonecase&utm_term=C%E8%AF%AD%E8%A8%80%E8%BE%93%E5%87%BA%E9%A2%9C%E8%89%B2&spm=1018.2226.3001.4450
//关键部分的基本格式是:
printf("\033[字背景颜色;字体颜色m字符串\033[0m" );
printf("\033[47;31mhello world\033[0m");效果如下所示:
![]()