使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割)学习笔记
使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割)学习笔记
https://www.bilibili.com/video/BV1rq4y1w7xM?spm_id_from=333.1007.top_right_bar_window_custom_collection.content.click
1.
up提到这里为了进行了BN所以把上面的bias设置成了False,这个是为啥?
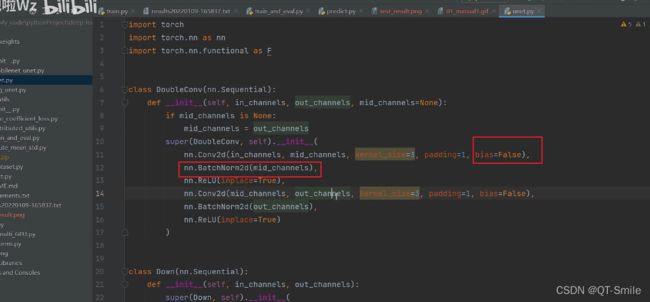
2.
现在都是比较流行对于一个层内部,不对图像的长和宽进行维度的改变
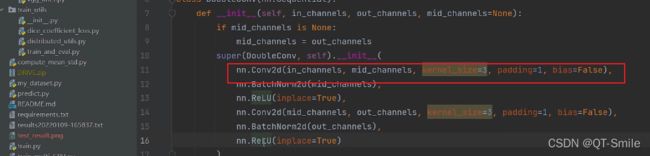
3.
上采样使用双线性差值
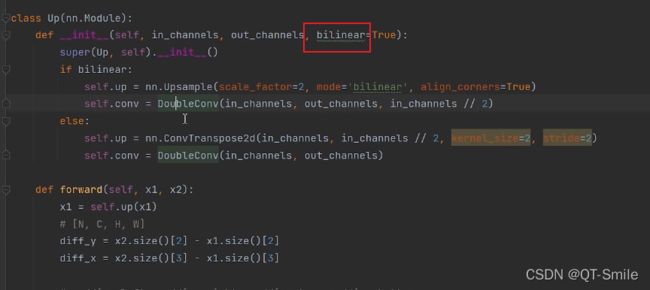
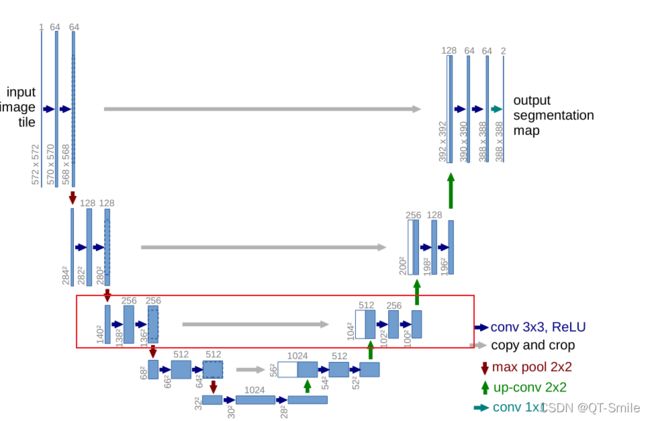
U_Net原论文中的上采样方式,转置卷积方法
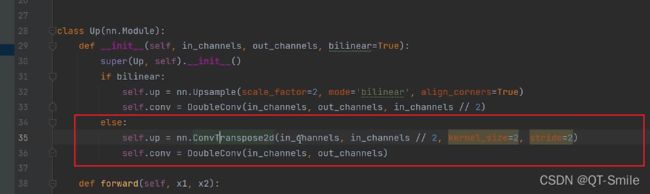
5.
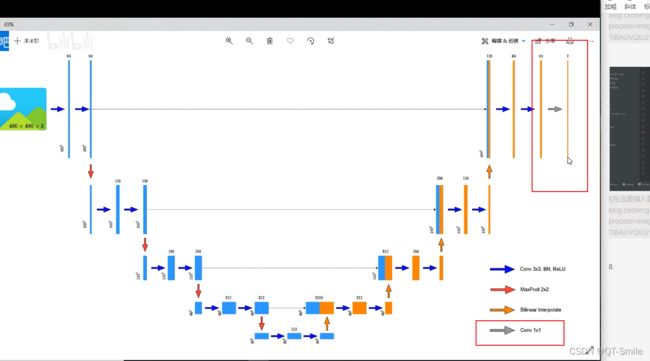
U_Net原论文的框架结构图
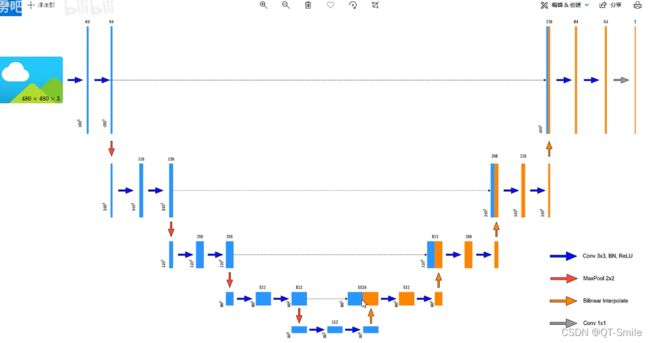
6.
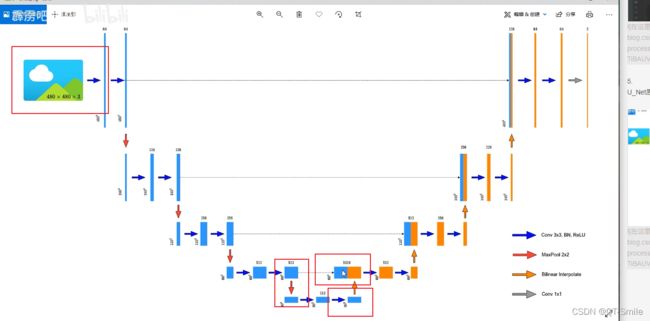
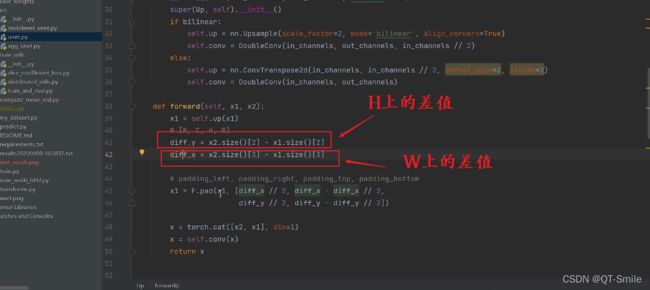
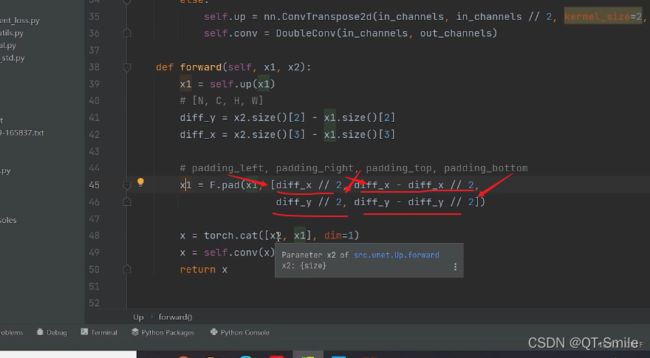
下面的代码是为了防止输入的图片的长和宽不是32的倍数,那么在进行才采样的时候,由于下采样,会导致,最后与上采样,需要与之拼接的图片的维度不一样,所以进行了padding,让上采样得到的图片的长和宽,和对应的下采样得到的图片的长和宽保持一样,这样才能够进行拼接操作。

7.
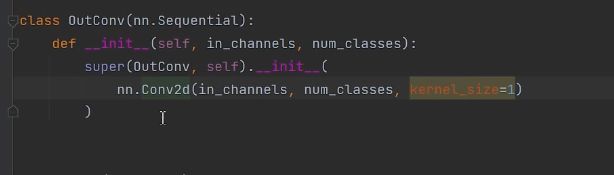
上面的1*1卷积层是通过下面这行代码实现的。
9.
4.
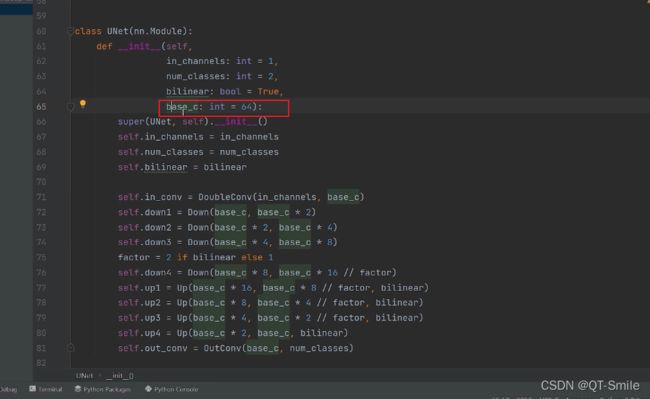
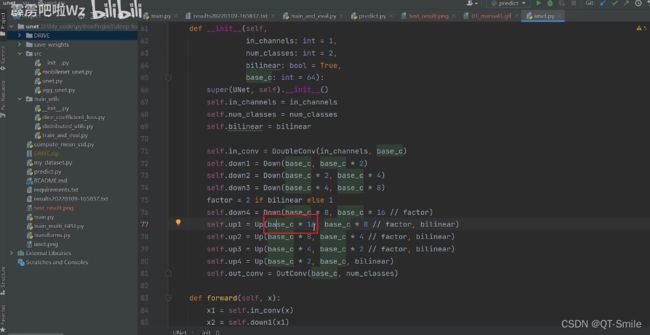
base_c:指的是下面的64,
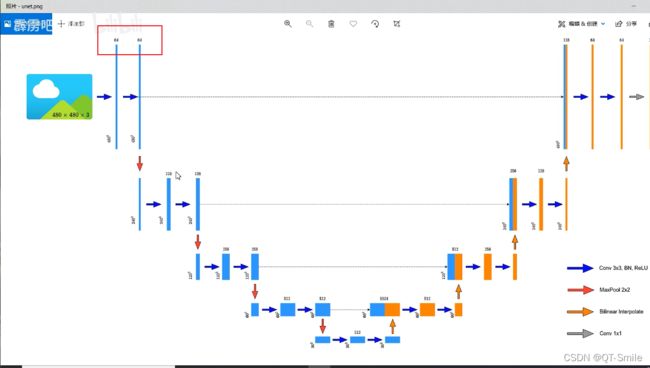
5.
传统U_Net结构图中,只是对对应的特征矩阵进行简单的cat拼接操作,
但是在CVPR2022的那篇论文中,使用的是
下面这种操作,它是与它对应的阶段的特征矩阵的上一个图像特征矩阵进行cat拼接的,然后进行一个1*1卷积,把channels数减少一倍。
6.
这里传入的是进行拼接之后的channels数,
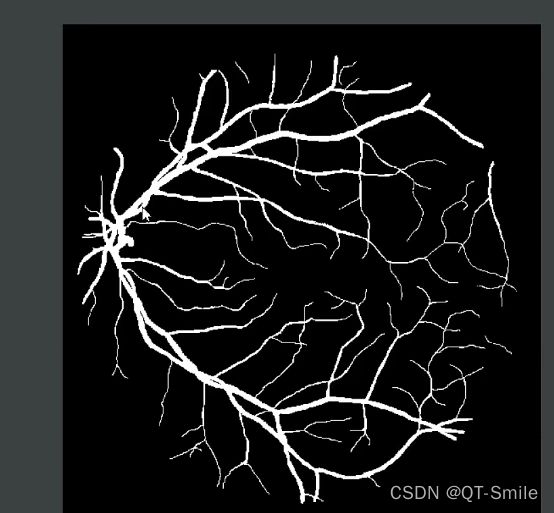
白色的像素值是255,黑色的像素值是0

8.
root是指数据集的路径。
train赋值为true,就载入training数据集,如果赋值为test,就载入test数据集
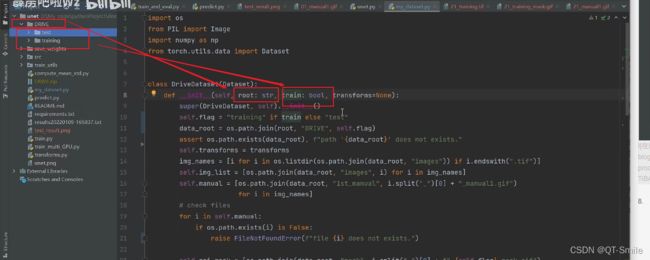
判断data_root这个路径是否存在
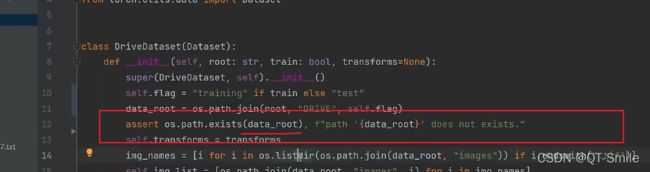
10.
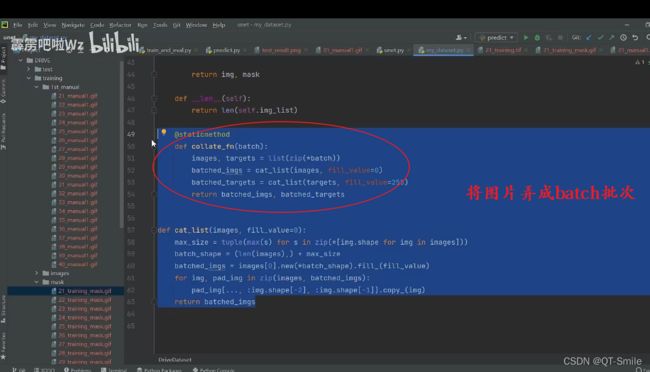
路径的拼接

11.
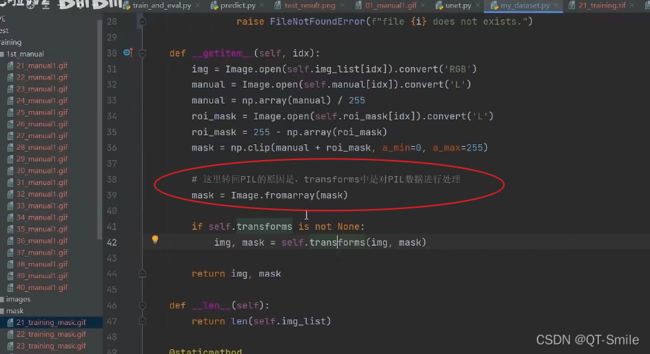
将图片转化成RGB图片
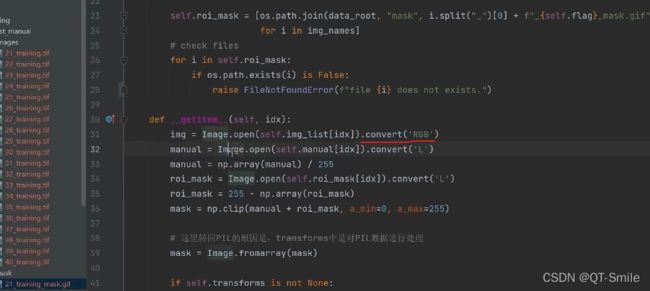
12.、
转换成灰度图片
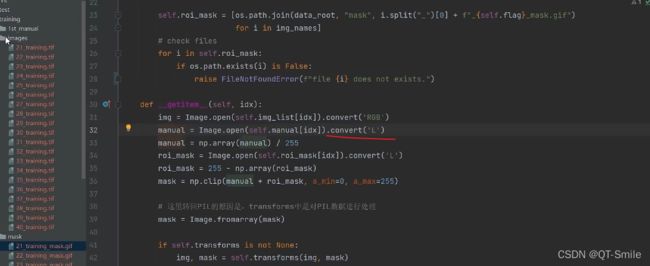
13.
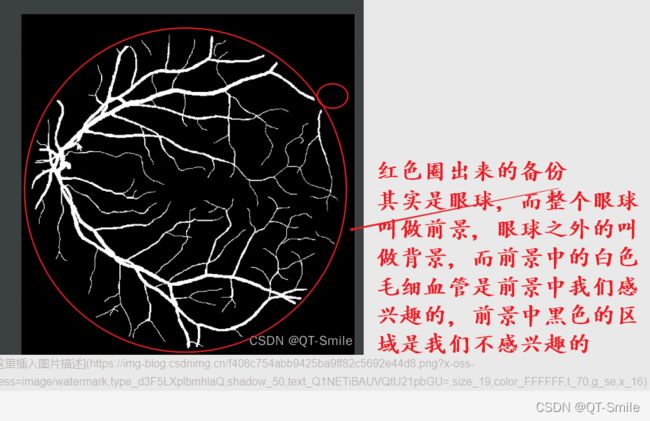
把前景的像素值设置成1,因为这个人工标记的人眼球毛细血管是黑白的,白色是我们要的,所以我们把这个叫做前景,把后面我们不要的叫做背景,又由于前景都是白色,白色的像素值是255,没搞懂为什么前景的像素值要从1开始,所以我们在这里除以了255.
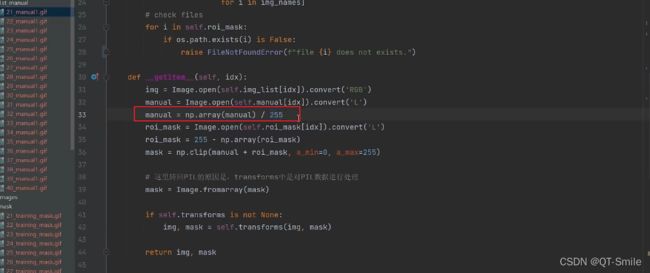
14.

15.
16.
17.



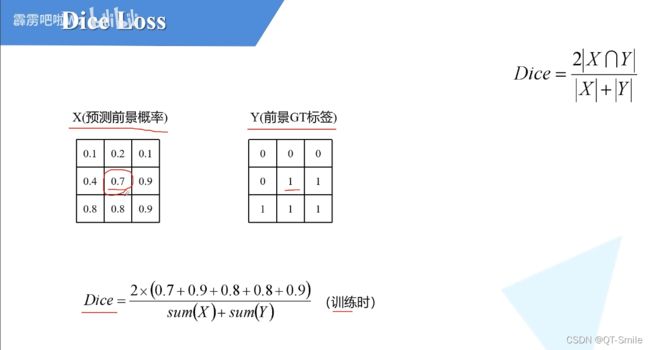

GT好像是背景
GT标签:应该指的是背景标签
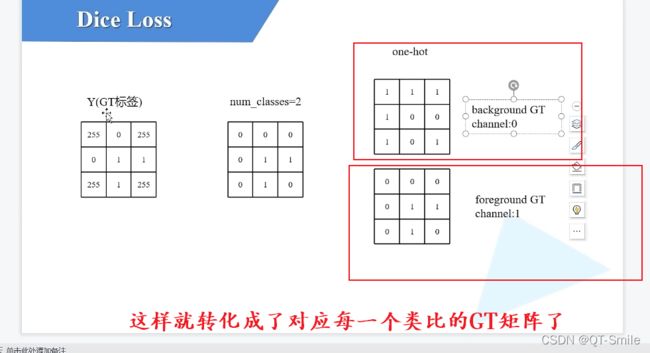
需要为每一个类别分别计算一个dice
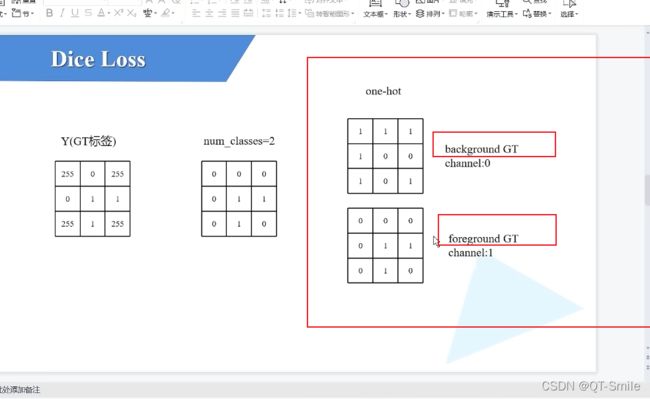
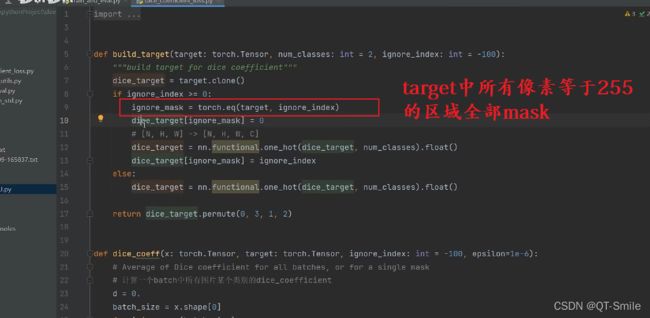
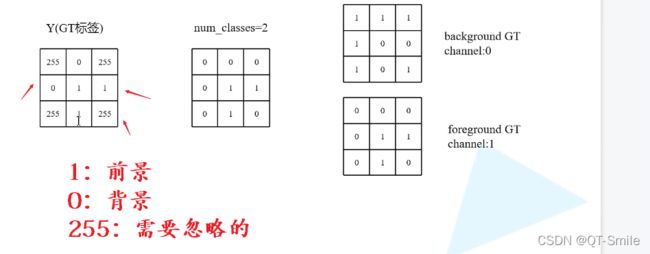
24.
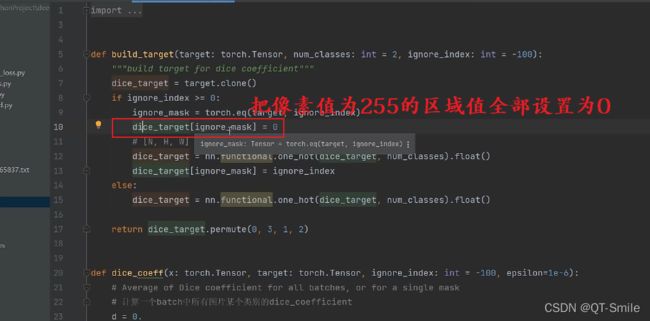
就是下面图片的实现
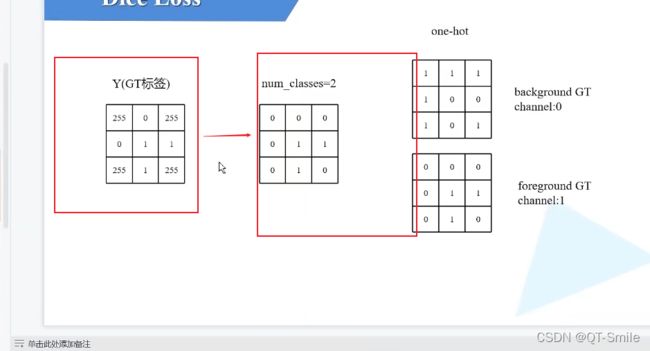
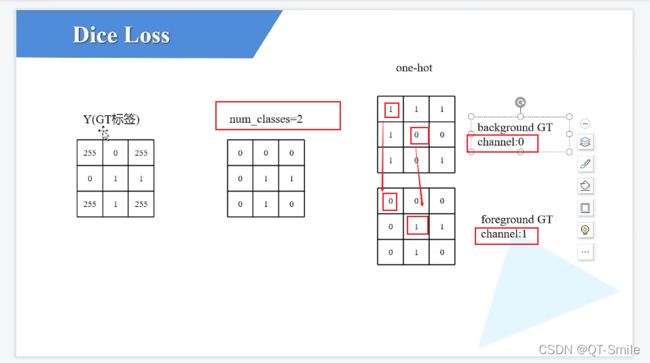
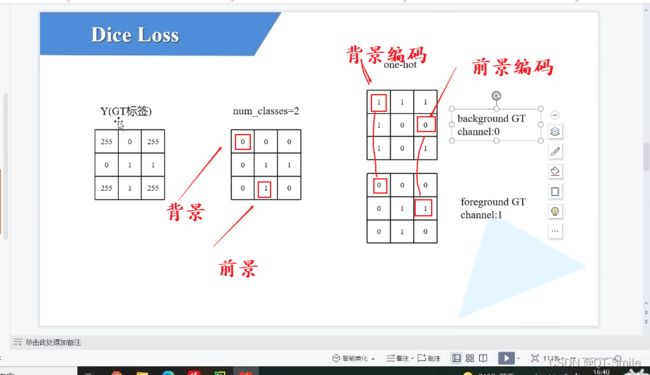
在下面中,我们最终的目标是分出来那些是前景,那些是背景。
就是一个2分类任务,我们把背景编码为1 0,把前景编码成0 1
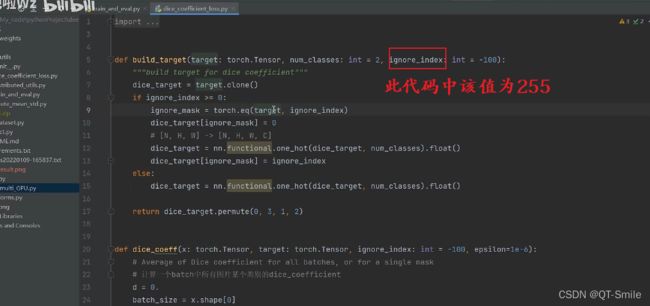
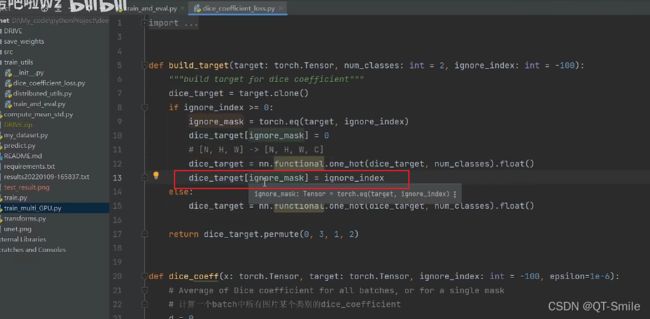
把之前找到的255区域的数值又重新填回255
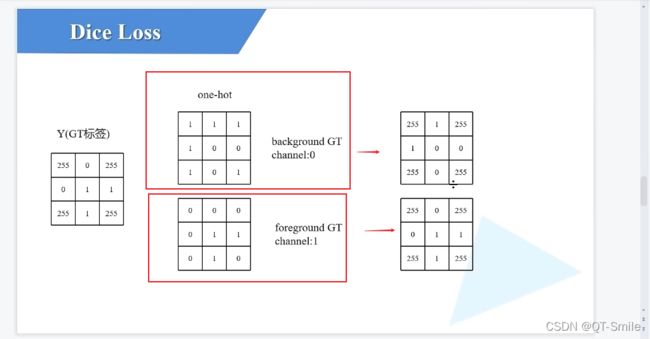
这样我们在分别计算不同类别(背景和前景)的dice loss时就还是只计算非255的区域
上面一系列的操作,最终会为特征矩阵增增加channels数,但你的任务中最后需要分成多少个类别时,就需要变成多少个channels,其实无论你最终是进行几分类的,最后都是进行2分类。
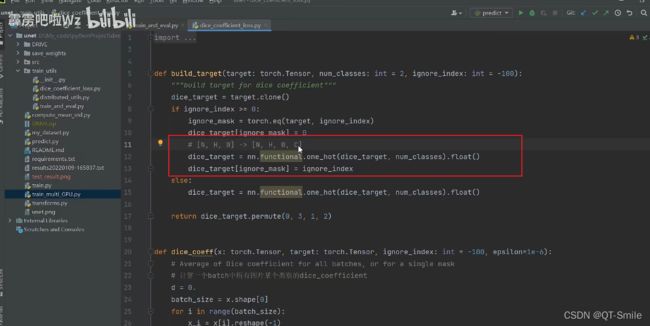
又由于我们的操作,把channels放在了最后,所以我们需要把channels重新放在第2位上,所以需要对维度进行修改。
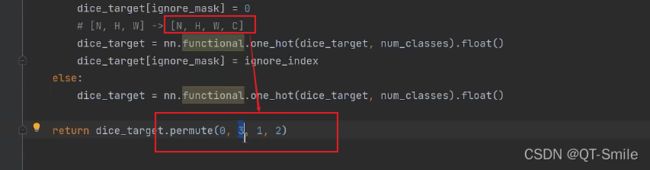
x:网络模型预测得到的类别
dice_target:我们上面一系列处理得到的
最终计算这两者的dice_loss
30.

我们这里对每一个channels进行一个softmax,而通过上面构建target矩阵可以知道,每一个channels都对应的着一个类别的判断,而我们这儿dim=1,就是判断所有的channels,而每一个channels对应着一个类别是否是的矩阵,那么对所有的channels进行softmax,就是判断这张图片,最有可能是哪个类别。
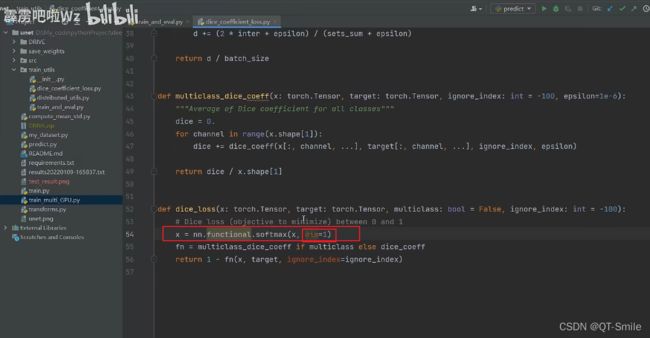
对于一个高维的矩阵,softmax是怎样计算的啊?(比如对于一个[5, 8, 9, 5]大小的张量,
上面代码中的操作怎样进行的,
)
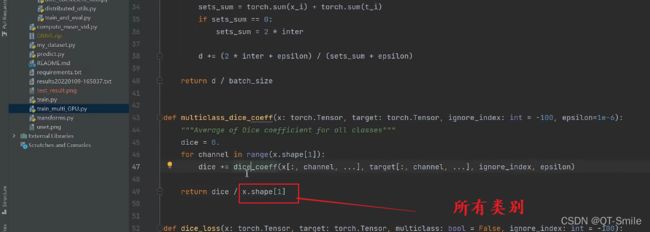
33.
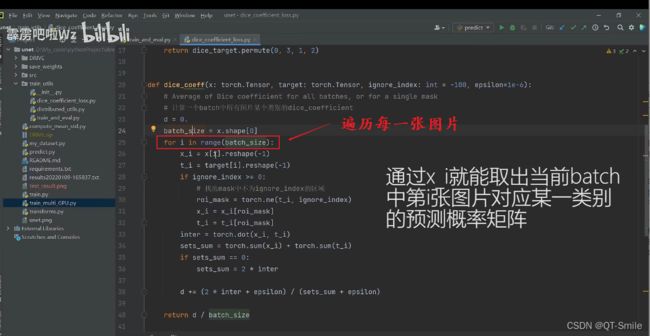
34.
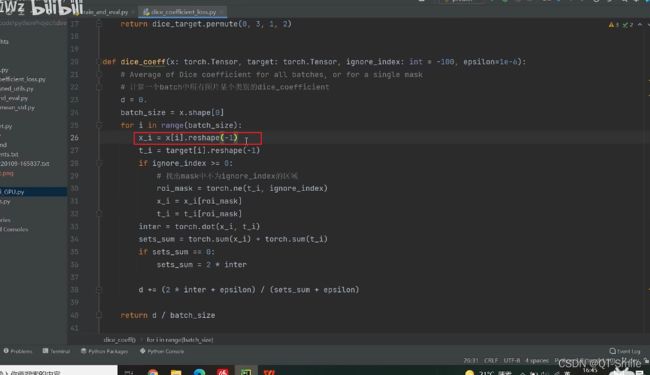
将第i张图片变成向量的格式
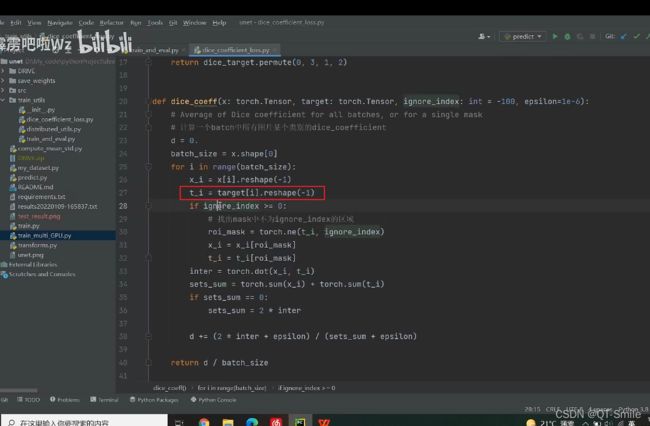
把对于图片的target也变成向量的格式
找出区域中我们感兴趣的区域,也就是不是255的区域
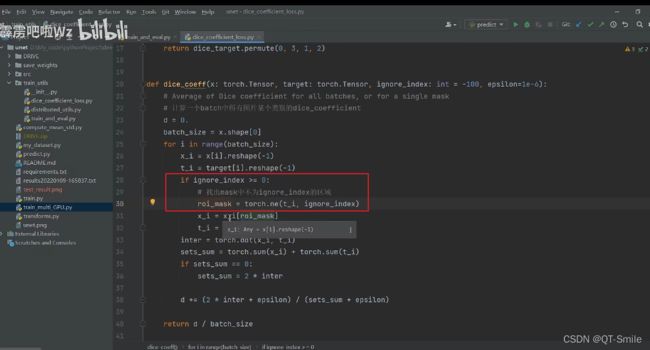
从向量x和向量t中得到我们感兴趣的区域
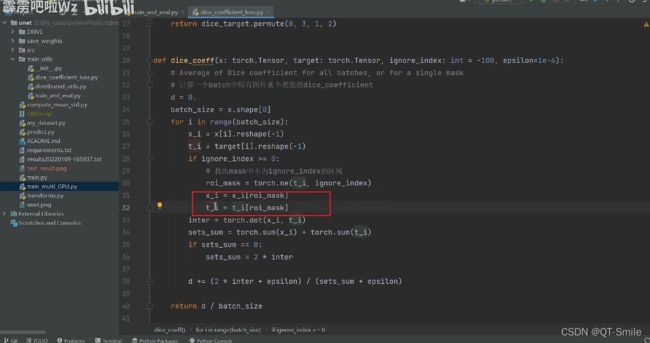
对这两个向量进行内积操作,相应元素相乘,然后求和的一种操作,也就是下面分子计算的过程
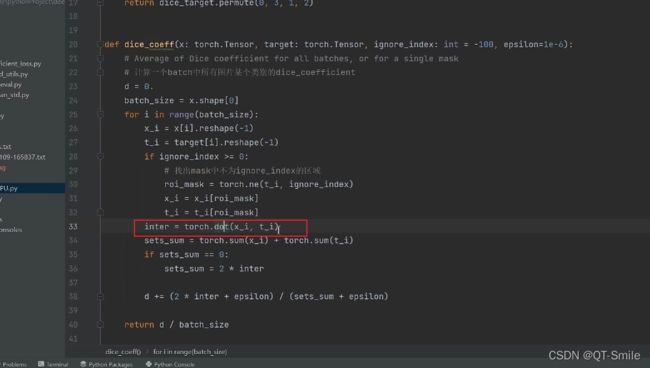
37.
这就是分母的代码实现操作
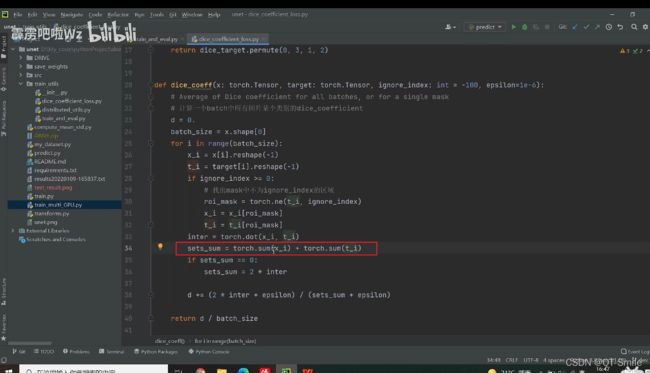
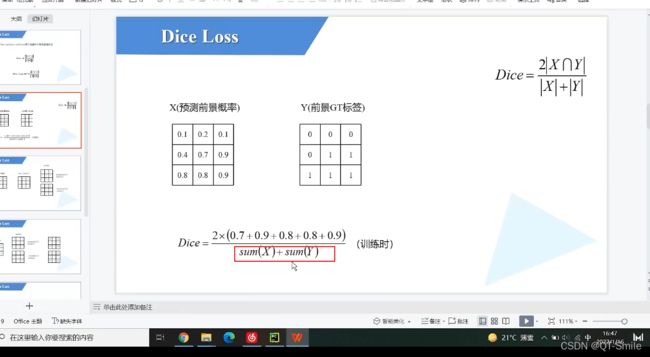
38.
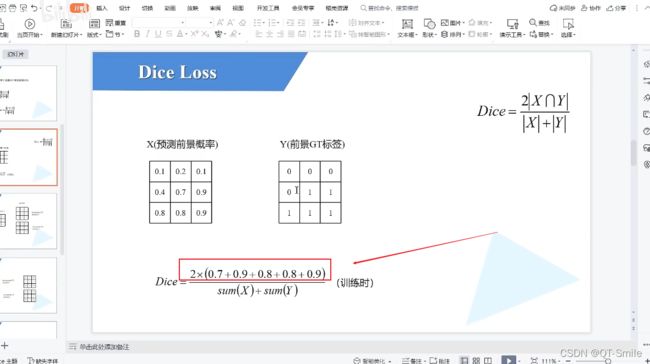
sets_sum=0,那么就说明x_i和t_i都是等于0的,那么就说明我们进行的预测都是对的
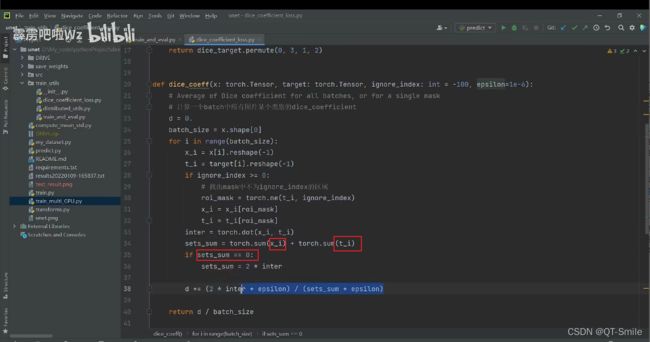
也就是时候下面的公式中X和Y是相同的,那么DICE=1 dice loss=0,既然dice loss=0,那么就说明没有误差,这也就反向说明了,预测全部都是对的。

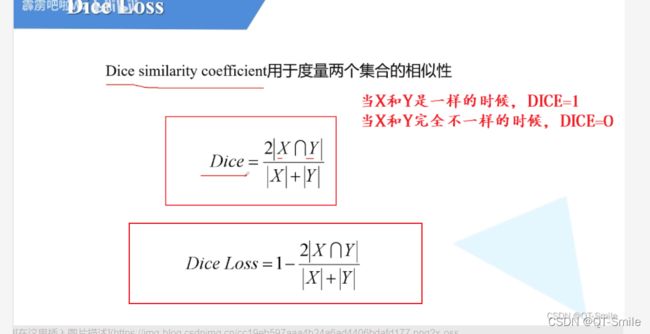
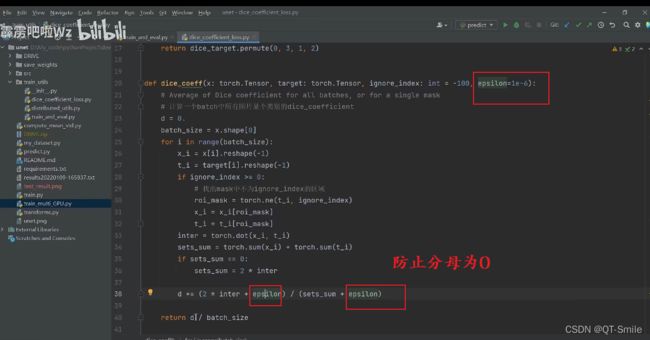
这表示每张图片对于某个类别的dice_coefficient的均值

补充:
1.下面的test图片,是经过predict.py代码预测出来的图片
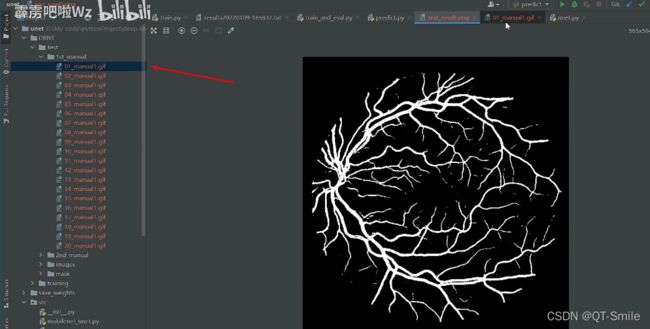
而下面这张是之前彩色图片通过人手工弄的,上面那个是根据彩色图骗预测出来的。
2.