2020人体姿态估计综述(Part2:2D Top-Down Multi-Person Pose Estimation)
承接上一篇博文:A 2020 Human Pose Estimation Review (Part1:2D Single Person)
目录
1 Human Pose Estimation
2 2D Single-Person Pose Estimation
3 2D Top-Down Multi-Person Pose Estimation
3.1 Top-Down
3.2 Mask RCNN
3.3 Cascaded Pyramid Network for Multi-Person Pose Estimation
3.4 RMPE: Regional Multi-Person Pose Estimation
3.5 A coarse-fine network for keypoint localization
3.6 Rethinking on Multi-Stage Networks for Human Pose Estimation
3.7 Simple Baselines for Human Pose Estimation and Tracking
3.8 Spatial Shortcut Network for Human Pose Estimation
3.9 2D Top-Down Multi-Person Pose Estimation小结
4 2D Bottom-Up Multi-Person Pose Estimation
5 3D Human Pose Estimation from Image
6 3D Human Pose Estimation from Video
3 2D Top-Down Multi-Person Pose Estimation
3.1 Top-Down
Top-Down的思路就是,先检测出图片中每个人体的边界框,然后将每个人体裁剪出来,进行单人的人体姿态估计。这种方法与单人人体姿态估计有着高度的联系,但也存在一些不同,一是图片中会有各种大小的人,这使得裁剪出的人体图象分辨率不一;另一方面,裁剪出的图像中,可能还包含其他人体的一些部分,这使得准确定位关节点更加困难;最后就是需要先使用bbox的检测器,检测器性能对于最终的pose预测性能也会有影响。
3.2 Mask RCNN, ICCV2017
Mask RCNN的结构我可能一辈子也不会忘记,作为自己的毕设内容,每一部分都能很详细地背出来了。Mask RCNN在Faster RCNN地基础上进行改进,特征提取采用了ResNet-FPN骨架,由RPN网络进行proposal,然后NMS筛选掉多余的候选框,之后进行分类、mask以及bbox回归。Mask RCNN论文的实验中,也提到了用它来做human pose的方法,这可以视为Top-Down的一种baseline。具体实现是,使用segmentation分支,预测K个关节点的mask。人体每个部位的关键点对应于一个one-hot掩码,训练的目标最终是得到一个56*56的二值掩码,当中只有一个像素被标记为关键点,其余像素均为背景。对于每一个关键点的位置,进行最小化平均交叉熵损失检测,K个关键点是被独立处理的。

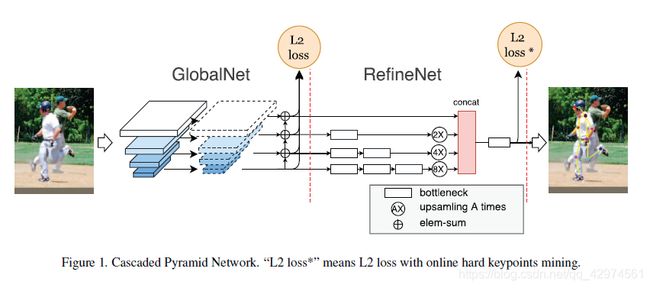
3.3 Cascaded Pyramid Network for Multi-Person Pose Estimation, CVPR2018
CPN是旷视的工作,整个网络结构非常简单,也依然达到了当时的SOTA。CPN需要先用检测器检测出bbox,然后再进行姿态估计。整个工作的亮点在于网络结构和人视觉思维的结合,网络分为GlobalNet和RefineNet两个部分,使用类似于ResNet-FPN的骨架进行特征提取(有一丢丢小小的不同),先预测所有关节点的heatmap,然后RefineNet网络再次进行特征整合,对困难关节点进行修正。要注意的是,Global的预测结果只在Training的时候会用到,为的是更好地训练前面的特征提取网络,RefineNet采用L2 Loss*,即计算loss时,只取最大的八个关节点,这样可以使网络更关注于困难关节点的预测。实际预测的时候,GlobalNet只承担了特征提取的工作,不进行关节点位置的预测,姿态结果只取RefineNet的预测。
3.4 RMPE: Regional Multi-Person Pose Estimation, ICCV2017
上海交大卢策吾课题组的工作。Top-Down的方法会受到bbox检测器性能的影响,这篇论文重点研究的就是如何减少bbox预测时候的各种问题。在目标检测产生Proposals的过程中,可能会出现检测框定位误差、对同一个物体重复检测等问题。检测框定位误差,会出现裁剪出来的区域没有包含整个人活着目标人体在框内的比例较小,造成接下来的单人人体骨骼关键点检测错误;对同一个物体重复检测,虽然目标人体是一样的,但是由于裁剪区域的差异可能会造成对同一个人会生成不同的关键点定位结果。本文提出了一种方法来解决目标检测产生的Proposals所存在的问题,即通过空间变换网络(STN)将同一个人体的产生的不同裁剪区域(Proposals)都变换到一个较好的结果。结构如图所示,首先使用基于VGG的SSD-512网络用作单人检测得到人体检测框,然后经过SSTN+SPPE网络生成pose proposals(单人的姿态估计采用stacked hourglass),再通过Parametric Pose NMS算法得到估计的人体姿态。

RMPE框架主要包括三个内容:
(1)Symmetric Spatial Transformer Network – SSTN 对称空间变换网络:在不准确的bounding box中提取单人区域
(2) Parametric Pose Non-Maximum-Suppression – NMS 参数化姿态非最大抑制,解决proposal的冗余
(3)Pose-Guided Proposals Generator – PGPG 姿态引导区域框生成器:数据增强
先看SSTN,SSTN=STN+SSPE+SDTN,STN是空间变换网络,用于执行二维的仿射变换来处理边界框,然后SPPE执行单人人体姿态估计,SDTN将姿态结果重新映射回原图中,这样就可以根据姿态调整原来的框,使得其更加精准。为了进一步帮助STN去提取更好的人体区域位置,在训练阶段添加了一个Parallel SPPE分支。这个分支和上一个分支共享同一个STN,但是省略了SDTN,而且训练标签为单个人的ground truth姿态,训练时这个分支网络的各个层和权重是固定的,目的是当输出与ground truth间的误差较大时,产生较大的loss来帮助STN进行正确的变换,得到高质量的人体框。
PPNMS思想与NMS差不多,这里是根据关节点之间的相似度来消除多余关节点。最后的PGPG的基本思想是,数据增强不一定要在原始图像上进行,使用不准确的bbox也可以是一种数据增强,这里PGPG就是用来产生与gt有一些偏差的bbox,以此来扩充数据集,增强模型鲁棒性。
3.5 A coarse-fine network for keypoint localization, ICCV2017
CFN作者认为,现今的姿态估计方法都是基于关节点置信图的严格监督方法,这种方法虽然能准确定位简单关节点,但是对于存在遮挡等情况的困呐关节点定位不准确。作者浅层的网络通常可以对容易检测出来的部位能够很好地定位,对于ambiguoukeypoin来讲检测又不是很好。深层的精细网络虽然能够对ambiguous的keypoint有很好的定位效果,但是在关键的localization accuracy上面却损失了很多的精度。为此,作者提出了一个网络结构,由一些粗检测分支和一个精细检测分支组成。粗检测分支建立在CNN的某一特征层上,而精细检测分支建立在多个特征层上。对每一个分支,指定label map进行监督,以实现不同的监督严格程度,最后所有分支的预测结果共同生成最终的人体姿态估计结果。
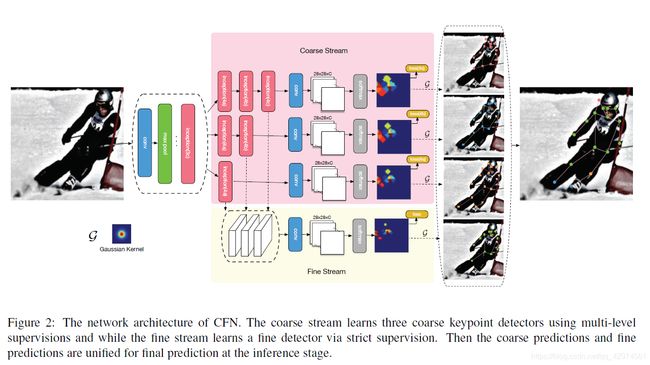
先看coarse网络,三个分支的区别在于堆叠的inception数量不同,inception越多,感受野越大,越能够捕捉关节点之间的关系。作者采用的是inception v2,abc三个粗检测器,感受野分别是107x107,139x139,171x171。如果输入图片是224x224,那么171的感受野相对于224太大了,可能会导致ambiguous的检测,所以作者增加输入大小到448×448。
在计算每个分支的loss时,作者设计了不同的label map,对于粗分支,以a分支为例,输出28×28×K张特征图,K代表关节点总数。Heatmap上每个点可以映射回原图中的一个正方形区域,然后用同样的感受野去对第k个关节点的gt做出同样的框,两个框求IoU,大于阈值,则这个点的标签为1,否则为0。再结合gt生成的label map,即可计算粗预测分支的分类损失。
对于精细网络,分类的label map不是基于anchor的,而是对gt关节点附近一定距离内的点的label设为1,计算loss时候。最终的loss由corase和fine两个分支的分类loss组成。
在predict过程中,将各个分支产生的K张heatmap送入高斯平滑器,找到各个分支的第k个关节点的最大响应位置,然后结合corase和fine两个结果来决定究竟是哪个位置。优先用fine网络的结果,当fine网络这个位置的分类得分低于一个阈值时候,改用corase网络的结果。这里有一个点想说一下,作者在论文中只提到了先用一个bbox检测器,然后用CFN执行单人人体姿态估计,但是作者一直没有说自己的bbox检测器性能有多少,贴的result图也只说了pose的结果有多少,完全没有提bbox性能多少,这不禁让我怀疑作者是不是直接拿gt跑的?如果真的是这样,未免也太学术不端了,以上仅仅是个人猜测(狗头)。
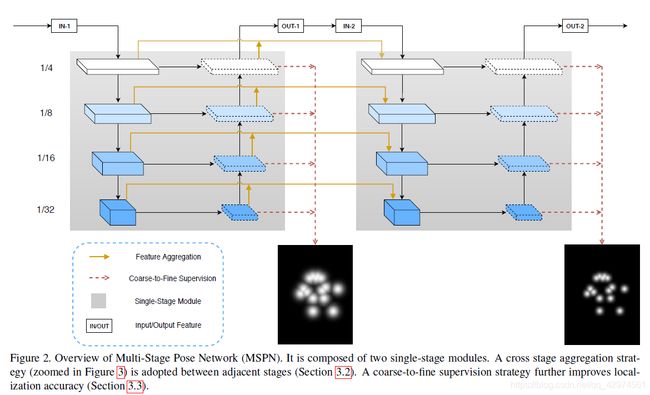
3.6 Rethinking on Multi-Stage Networks for Human Pose Estimation, Arxiv2019
也就是MSPN,在多人姿态估计中,stack多个stage并不能够显著提升性能,这篇文章从结构、特征传递以及loss多方面来改善和提升multi-stage在多人姿态估计上的性能,达到了当时的SOTA。
文章主要有三个方面的创新,一个是对于hourglass的结构进行改进,在每次下采样后,增加了通道数。因为降采样过程中我们想提取不同尺度丰富的信息,丢失的信息在上采样中很难恢复。所以在降采样分辨率下降时,channel适当增加才能减少信息丢失。
另一个是不采用hourglass那样每个stage直接串联的方式,而是改用U-Net的连接方式。
最后一个是,对于不同层次的label heatmap,要采用不同大小的高斯核,即下一个stage的高斯核要比上一个stage的高斯核更小。
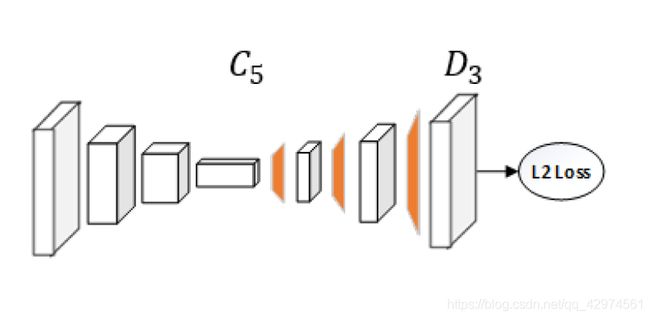
3.7 Simple Baselines for Human Pose Estimation and Tracking, ECCV2018
对于人体姿态估计,高分辨率特征图是一个关键,作者根据这个指导思想,着重于使得网络生成高分辨率图。网络结构很简单,直接在ResNet后面跟反卷积模块,然后输出预测结果。使用ResNet-152,input尺寸为384*288时,mAP达到了73.7。
3.8 Spatial Shortcut Network for Human Pose Estimation, Arxiv2019
作者的出发点是感受野对于关节点估计的影响,同时也考虑了减少信息流动的成本,设计了一种轻量级的网络。SSN能够将特征映射移动和注意机制结合在特征移动模块feature shifting module(FSM)中。
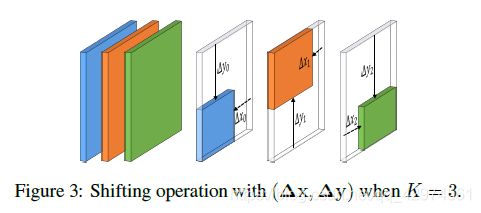
FSM包括main模块以及注意力机制correlation attention(CA)模块,main模块输入为C个通道的特征P,首先通过11的卷积变换为K个通道的特征。然后对K个通道的特征,作逐通道的shift操作,该过程中需要 K对偏置参数。shift操作后的特征和CA模块的输出,作逐元素相乘。再利用11的卷积将通道数变换为C个。最后在和模块的输入特征P做短连接逐元素相加,经过BN和Relu后输出。
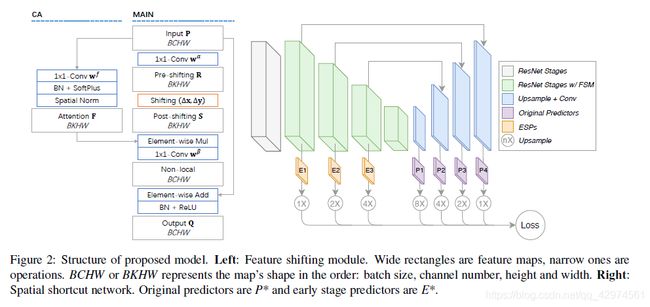
其中,shift操作为,对每个通道进行特征偏移,相当于改变了感受野的范围。这个思想是这样的,当我们要判断手是左手还是右手时,需要借助头部区域的信息来判断,但是如果直接使用感受野最大的特征图,需要的成本比较大,那么如果直接通过特征图位移来获取头部区域,相应的成本就很小了。FSM就是用于获取相关部分的特征信息的,支路的CA模块则是用来判定位移后的特征是否和原来的特征区域相关。之后,两个支路特征结合起来,用于预测最后的人体姿态。
3.9 2D Top-Down Multi-Person Pose Estimation小结
可以看到,Top-Down的思路其实是吧多人人体姿态估计拆成了单人人体姿态估计和人体检测两个问题,之前我也提到,单人的人体姿态估计主流方法已经基本固定,而检测的问题,又是另一个研究方向了。就单纯以学术研究来说,在多人这个方向上能做的更多是小修小补,蛋糕已经分的差不多了。RMPE将这两个问题结合起来,是一种很有姿态估计特色的创新,后续的研究可以借鉴这种思维,思考如何将两者联系在一起来提升性能。
另外,Top-Down的一个优势或者说特点在于,我们裁剪后的人体区域图像,往往人是在bbox中央,且通常会缩放到统一尺度,那么神经网络会隐式地学到各个关节点的位置分布。师兄曾经做过一个实验,它用一幅噪声图像给姿态估计器,估计器输出的结果也大致能展现出人的样子。我认为这是Top-Down的优势,隐式地学到关节点位置分布,可以减少网络预测难度,即使我们用COCO这种姿态比较多样的数据集,这个现象依然存在,只是不像用MPII数据集单独训练出来的估计器的位置分布那么紧密。