【李宏毅机器学习HW2】
按照自己的计划,以后应该会一两个星期完成一个作业,目标是尽量都达到boss baseline吧,能参考的资料也挺多的,但如果只是学会掉包肯定是不行的,所以以后也会花时间总结一下原理。除了算法思想和如何构造外,我认为代码能力也很重要,但现在能看到的代码注解还是较少,包括助教给的代码有些注释不算很详细,所以以后不懂的函数也会总结总结,然后注解好发到GitHub上
文章目录
- 前言
- 一、过strongbaseline所需
- 1、concat_nframes
- 2、小细节方面
- 3、余弦退火
- 二、后续改进
- 1.RNN(Recurrent Neural Network)循环神经网络
- 2.LSTM(Long Short-term Memory )
- 3.LSTM+CRF
- 4.问题
- 总结
- 参考
前言
这篇文章是我关于李宏毅机器学习2022年版第二次作业的一些想法,记录自己的学习历程,主要参考内容附在文末。
然后这是我发的第一篇博客,以后会坚持更新一些关于李宏毅作业和视觉方面作业的解答,欢迎关注我的博客和GitHub
HW2作业任务:
这次作业来自于语音辨识的一部分,他需要我们根据已有音频材料预测音位,而数据预处理部分是:从原始波形中提取mfcc特征(已经由助教完成了),然后我们则需要以此分类:即使用预先提取的mfcc特征进行帧级音素分类 。
音位分类预测(Phoneme classification)是通过语音数据,预测音位。音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的音位系统。
要求如下
| 水平 | 准确率 |
|---|---|
| simple | 0.45797 |
| medium | 0.69747 |
| strong | 0.75028 |
| boss | 0.82324 |
下面是对助教代码的改动和方法的总结
一、过strongbaseline所需
1、concat_nframes

首先按照助教提示由于一个phoneme 不会只有一个frame(帧) 训练时接上前后的frame会得到较好的结果,这里将concat_nframes调大,这里前后接对称数量,例如concat_n = 19 则前后都接9个frame。
2、小细节方面
添加了Batch Normalization 和 dropout
关于Batch Normalization的优点:
链接: link
关于weight decay
链接: link
关于dropout
链接: link

3、余弦退火
参考:链接: link
官网链接为链接: link
这里我们添加以下代码
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=8,T_mult=2,eta_min = learning_rate/2)
余弦退火学习率公式为
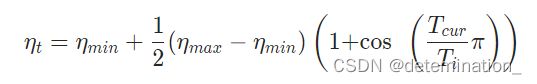
函数用法如下
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=- 1, verbose=False)
T_0为初始时的周期,准确来说是学习率从最大值到下一个最大值所需epoch,之后所需的epoch为上一个步骤的T_mult倍。而eta_min为最小学习率。last_epoch是最后一个epoch的索引,默认为-1。verbose为True时可以自动输出每一个epoch时学习率为多少。
我们通过以下代码来验证
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts
import matplotlib.pyplot as plt
#随便构造一个简单的模型
class Simple_Model(nn.Module):
def __init__(self):
super(Simple_Model, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=3,kernel_size=1)
def forward(self,x):
pass
learning_rate = 0.0001
model = Simple_Model()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#设置好我们用在代码中的参数
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=8,T_mult=2,eta_min = learning_rate/2)
print('初始时的学习率',optimizer.defaults['lr'])
lr_get = [] #保存lr来作图
for epoch in range(1,100):
# train
optimizer.zero_grad()
optimizer.step()
lr_get.append(optimizer.param_groups[0]['lr'])
scheduler.step()
#CosineAnnealingWarmRestarts画学习率的变化
plt.plot(list(range(1,100)),lr_get)
plt.xlabel('epoch')
plt.ylabel('learning_rate')
plt.title('How CosineAnnealingWarmRestart goes')
plt.show()
结果如图:

最后通过以上步骤我们的模型能达到下面的结果

这里是过strongbaseline全部代码(改下地址就能跑,可以在kaggle上或者自己下数据集在本地跑):
# Preparing Data
import os
import random
import pandas as pd
import torch
from tqdm import tqdm
# 以下几个函数都是用于concat_feat拼接的
def load_feat(path):
feat = torch.load(path)
return feat
def shift(x, n):
if n < 0:
left = x[0].repeat(-n, 1)
right = x[:n]
elif n > 0:
right = x[-1].repeat(n, 1)
left = x[n:]
else:
return x
return torch.cat((left, right), dim=0)
#一个phoneme 不会只有一个frame(帧) 训练时接上前后的frame会得到较好的结果
#这里前后接对称数量,例如concat_n = 11 则前后都接5
def concat_feat(x, concat_n):
assert concat_n % 2 == 1 # n #为奇数
if concat_n < 2:
return x
seq_len, feature_dim = x.size(0), x.size(1)
x = x.repeat(1, concat_n)
x = x.view(seq_len, concat_n, feature_dim).permute(1, 0, 2) # concat_n, seq_len, feature_dim
mid = (concat_n // 2)
for r_idx in range(1, mid+1):
x[mid + r_idx, :] = shift(x[mid + r_idx], r_idx)
x[mid - r_idx, :] = shift(x[mid - r_idx], -r_idx)
return x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim)
# x = torch.tensor([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12]])
# y = concat_feat(x , 3)
# print(y)
def preprocess_data(split, feat_dir, phone_path, concat_nframes, train_ratio=0.8, train_val_seed=1337):
class_num = 41 # NOTE: pre-computed, should not need change
mode = 'train' if (split == 'train' or split == 'val') else 'test'
label_dict = {}
if mode != 'test':
phone_file = open(os.path.join(phone_path, f'{mode}_labels.txt')).readlines()
#print(os.path.join(phone_path, f'{mode}_labels.txt'))
for line in phone_file:
line = line.strip('\n').split(' ')
label_dict[line[0]] = [int(p) for p in line[1:]]
if split == 'train' or split == 'val':
# split training and validation data
usage_list = open(os.path.join(phone_path, 'train_split.txt')).readlines()
random.seed(train_val_seed)
random.shuffle(usage_list)
percent = int(len(usage_list) * train_ratio)
usage_list = usage_list[:percent] if split == 'train' else usage_list[percent:]
elif split == 'test':
usage_list = open(os.path.join(phone_path, 'test_split.txt')).readlines()
else:
raise ValueError('Invalid \'split\' argument for dataset: PhoneDataset!')
#得到每一个音频代号
usage_list = [line.strip('\n') for line in usage_list]
print('[Dataset] - # phone classes: ' + str(class_num) + ', number of utterances for ' + split + ': ' + str(len(usage_list)))
max_len = 3000000
X = torch.empty(max_len, 39 * concat_nframes)
if mode != 'test':
y = torch.empty(max_len, dtype=torch.long)
#将音频数据读取出来 X为特征 y为label
idx = 0
for i, fname in tqdm(enumerate(usage_list)):
feat = load_feat(os.path.join(feat_dir, mode, f'{fname}.pt'))
cur_len = len(feat)
feat = concat_feat(feat, concat_nframes)
if mode != 'test':
label = torch.LongTensor(label_dict[fname])
X[idx: idx + cur_len, :] = feat
if mode != 'test':
y[idx: idx + cur_len] = label
idx += cur_len
X = X[:idx, :]
if mode != 'test':
y = y[:idx]
print(f'[INFO] {split} set')
print(X.shape)
if mode != 'test':
print(y.shape)
return X, y
else:
return X
#Define Dataset
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class LibriDataset(Dataset):
def __init__(self, X, y=None):
self.data = X
if y is not None:
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)
# Define Model
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.BatchNorm1d(output_dim,eps=1e-05, momentum=0.1, affine=True),
# num_features: 来自期望输入的特征数,C from an expected input of size (N,C,L) or L from input of size (N,L)
# eps: 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# momentum: 动态均值和动态方差所使用的动量。默认为0.1。
# affine: 一个布尔值,当设为true,给该层添加可学习的仿射变换参数。
nn.Dropout(0.35),
)
def forward(self, x):
x = self.block(x)
return x
class Classifier(nn.Module):
def __init__(self, input_dim, output_dim=41, hidden_layers=1, hidden_dim=256):
super(Classifier, self).__init__()
self.fc = nn.Sequential(
BasicBlock(input_dim, hidden_dim),
*[BasicBlock(hidden_dim, hidden_dim) for _ in range(hidden_layers)],
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
x = self.fc(x)
return x
#超参数
## Hyper-parameters
# data prarameters
concat_nframes = 19 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.95 # the ratio of data used for training, the rest will be used for validation
# 百万级数据集的训练集验证集划分
# 一种常见的启发式策略是将整体30%的数据用作测试集,这适用于总体数据量规模一般的情况
# (比如100至10,000个样本)。但在大数据时期,分配比例会发生变化,
# 如100万数据时,98%(训练)1%(验证)1%(测试),超百万时,95%(训练)/2.5%(验证)2.5%(测试)
# -《Machine Learning Yearning》 Andrew Ng
# training parameters
seed = 0 # random seed
batch_size = 1024 # batch size (512)
num_epoch = 100 # the number of training epoch
learning_rate = 0.0001 # learning rate
model_path = './model.ckpt' # the path where the checkpoint will be saved
# model parameters
input_dim = 39 * concat_nframes # the input dim of the model, you should not change the value
hidden_layers = 2 # the number of hidden layers
hidden_dim =1024 # the hidden dim
#对垃圾进行回收所需调用的函数
## Prepare dataset and model
import gc
# preprocess data
train_X, train_y = preprocess_data(split='train', feat_dir='F:\kaggle\HW2\libriphone\libriphone\\feat', phone_path='F:\kaggle\HW2\libriphone\libriphone', concat_nframes=concat_nframes, train_ratio=train_ratio)
val_X, val_y = preprocess_data(split='val', feat_dir='F:\kaggle\HW2\libriphone\libriphone\\feat', phone_path='F:\kaggle\HW2\libriphone\libriphone', concat_nframes=concat_nframes, train_ratio=train_ratio)
# get dataset
train_set = LibriDataset(train_X, train_y)
val_set = LibriDataset(val_X, val_y)
# remove raw feature to save memory
del train_X, train_y, val_X, val_y
gc.collect()
# get dataloader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
print(f'DEVICE: {device}')
import numpy as np
#fix seed
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# fix random seed
same_seeds(seed)
# create model, define a loss function, and optimizer
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=8,T_mult=2,eta_min = learning_rate/2)
# #
# import torchsummary
# torchsummary.summary(model, input_size=(input_dim,))
# TorchSummary提供了更详细的信息分析,包括模块信息(每一层的类型、输出shape和参数量)
# 、模型整体的参数量、模型大小、一次前向或者反向传播需要的内存大小等。
#ncol 设置输出宽度
## Training
best_acc = 0.0
early_stop_count = 0
early_stopping = 8
for epoch in range(num_epoch):
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# training
model.train() # set the model to training mode
pbar = tqdm(train_loader, ncols=110) #用于可视化进度
pbar.set_description(f'T: {epoch + 1}/{num_epoch}')
samples = 0
for i, batch in enumerate(pbar):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(features)
# optimizer.zero_grad()
# 函数会遍历模型的所有参数,,清空上一次的梯度记录。
loss = criterion(outputs, labels) #设定判别损失函数
loss.backward() #执行反向传播,更新梯度
optimizer.step() #执行参数更新
# 关于上述函数的讲解 https://blog.csdn.net/PanYHHH/article/details/107361827?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166523672216782391838079%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166523672216782391838079&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-107361827-null-null.142^v52^control,201^v3^add_ask&utm_term=optimizer.step%28%29&spm=1018.2226.3001.4187
_, train_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
correct = (train_pred.detach() == labels.detach()).sum().item()
# t.item()将Tensor变量转换为python标量(int float等),其中t是一个Tensor变量,只能是标量,转换后dtype与Tensor的dtype一致
# detach 该参数的requires_grad 属性设置为False,这样之后的反向传播时就不会更新它
train_acc += correct
samples += labels.size(0)
train_loss += loss.item()
lr = optimizer.param_groups[0]["lr"]
# 可视化进度条的参数设置
pbar.set_postfix({'lr': lr, 'batch acc': correct / labels.size(0),
'acc': train_acc / samples, 'loss': train_loss / (i + 1)})
scheduler.step() #用于更新学习率
# 各个情况下的 .step() 一般都是用来更新参数的
pbar.close() #清空并关闭进度条 (progress bar)
# validation
if len(val_set) > 0:
model.eval() # set the model to evaluation mode#用于将模型变为评估模式,而不是训练模式,这样batchNorm层,dropout层等用于优化训练而添加的网络层会被关闭,从而使得评估时不会发生偏移。
with torch.no_grad():
pbar = tqdm(val_loader, ncols=110)
pbar.set_description(f'V: {epoch + 1}/{num_epoch}')
samples = 0
for i, batch in enumerate(pbar):
features, labels = batch #取出一个batch中的特征和标签
features = features.to(device)
labels = labels.to(device)
outputs = model(features) #得到预测结果
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
# 用于得到预测结果
# torch.max(input: tensor, dim: index)
# 该函数有两个输入:inputs: tensor,第一个参数为一个张量
# dim: index,第二个参数为一个整数[-2 - 1],dim = 0表示计算每列的最大值,dim = 1表示每行的最大值
val_acc += (val_pred.cpu() == labels.cpu()).sum().item()
samples += labels.size(0)
val_loss += loss.item()
pbar.set_postfix({'val acc': val_acc / samples, 'val loss': val_loss / (i + 1)})
pbar.close()
# 如果模型有进步(在训练集上)就保存一个checkpoint,把模型保存下来
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), model_path)
print('saving model with acc {:.3f}'.format(best_acc / len(val_set)))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= early_stopping:
# print(f'')中的f使得其有print(''.format())的作用
print(f"Epoch: {epoch + 1}, model not improving, early stopping.")
break
else:
print('i dont know')
# print(f'[{epoch + 1:03d}/{num_epoch:03d}] Acc: {acc:3.6f} Loss: {loss:3.6f}')
# print(f'[{epoch + 1:03d}/{num_epoch:03d}] Acc: {acc:3.6f} Loss: {loss:3.6f}')
# 如果没有测试,保存最后一次训练 我们是有测试集的,所以下述代码用不着
# if not validating, save the last epoch
if len(val_set) == 0:
torch.save(model.state_dict(), model_path)
print('saving model at last epoch')
#老规矩,清除内存
del train_loader, val_loader
gc.collect()
## Testing## 创造一个测试集用来得到题目想要的预测结果,我们从之前保存的checkpoint也就是最好的模型来预测结果
## Testing
# Create a testing dataset, and load model from the saved checkpoint.
# Create a testing dataset, and load model from the saved checkpoint.
# load data
test_X = preprocess_data(split='test', feat_dir='F:\kaggle\HW2\libriphone\libriphone\\feat', phone_path='F:\kaggle\HW2\libriphone\libriphone', concat_nframes=concat_nframes)
test_set = LibriDataset(test_X, None)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
# load model
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
model.load_state_dict(torch.load(model_path))
#Make prediction.
test_acc = 0.0
test_lengths = 0
pred = np.array([], dtype=np.int32)
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(test_loader)):
features = batch
features = features.to(device)
outputs = model(features)
_, test_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
pred = np.concatenate((pred, test_pred.cpu().numpy()), axis=0)
with open('prediction.csv', 'w') as f:
f.write('Id,Class\n')
for i, y in enumerate(pred):
f.write('{},{}\n'.format(i, y))
二、后续改进
1.RNN(Recurrent Neural Network)循环神经网络
参考:关于RNN代码和LSTM代码参数解释链接: link

2.LSTM(Long Short-term Memory )


3.LSTM+CRF
最后选用BI-LSTM模型(双向LSTM)和CRF拼接而成的模型,其可以兼具二者的优点,能达到更高的准确率
双向LSTM不仅可以考虑上文的信息还可以考虑下文的信息,双向LSTM可以理解为两个LSTM同时训练,但他们两的方向相反,而且参数由于顺序不同也不一样,当前时刻的输出就是将两个不同方向的LSTM的输出拼接到一起。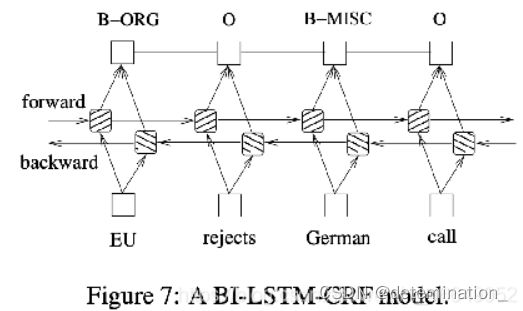
而CRF源于HMM,HMM模型的其次马尔科夫假设为:隐藏的马尔可夫链在任意时刻t的状态只与前一时刻的状态有关,而与其他时刻的状态及观测无关,也与时间t无关。CRF模型就算不仅考虑前一时刻的状态,同时考虑前后多个状态。

Bi-LSTM和CRF都可以捕捉未来和过去的特征,将他们拼接起来的原因是Bi-LSTM网络是利用隐含信息,而CRF可以直接利用label的信息,因此可以加快训练。
LSTM的参数如下
class torch.nn.LSTM(*args, **kwargs):
input_size:x的特征维度
hidden_size:隐藏层的特征维度
num_layers:lstm隐层的层数,默认为1
bias:默认为True
batch_first:True则输入输出的数据格式为 (batch, seq, feature)
dropout:除最后一层,每一层的输出都进行dropout,默认为: 0
bidirectional:True则为双向lstm默认为False
主要架构代码如下
class BiLSTM(nn.Module):
def __init__(self, class_size=41, input_dim=39, hidden_dim=384,linear_hidden = 1024, dropout=0.5,concat_nframes = 19):
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.class_size = class_size
self.linear_hidden = linear_hidden
self.concat_nframes = concat_nframes
self.lstm = nn.LSTM(input_dim, hidden_dim // 2, dropout=dropout,
num_layers=3, bidirectional=True, batch_first=True)
self.hidden2tag = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(hidden_dim,linear_hidden),
nn.BatchNorm1d(self.concat_nframes),
# torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# num_features – 特征维度 你想要归一化那一层,就把那一层的维数写上去
# eps – 为数值稳定性而加到分母上的值。
# momentum – 移动平均的动量值。
# affine – 一个布尔值,当设置为真时,此模块具有可学习的仿射参数。
nn.ReLU(inplace=True),
nn.Linear(linear_hidden, class_size)
)
def forward(self, x):
feats, _ = self.lstm(x)
return self.hidden2tag(feats)
class Crf(nn.Module):
def __init__(self, class_size=41):
super().__init__()
self.class_size = class_size
self.crf = CRF(self.class_size, batch_first=True)
def likelihood(self, x, y):
return self.crf(x, y)
def forward(self, x):
return torch.LongTensor(self.crf.decode(x))
最后能达到的效果是
在第七轮训练时就达到了0.805准确率,但遗憾的是最后还是没有太多的进步还是达不到boss baseline
4.问题
看之前一个博主说的,不用CRF,就直接硬加BiLSTM的隐含层数就可以达到0.83以上的准确率,我直接在 BiLSTM+CRF模型增加隐含层似乎效果不太好,晚点我把CRF去掉试试。
但其实理论上在这种有标注的任务中,CRF层应该是对RNN类的模型是有帮助的,因为RNN类的模型没有考虑类别之间的关联性,在我们的语音中,单词中的音位不是随机的,是有一定顺序的,所以各个音位间是有所联系的,所以CRF可以提取到RNN所不能提取出来的东西,因此BiLSTM-CRF的上限应该高于单纯只用BiLSTM
总结
参考
链接: link
【【ML2021李宏毅机器学习】作业2 TIMIT phoneme classification 思路讲解-哔哩哔哩】
链接: link
链接: link