ES 分词
- 分词
- 分词器
- 分词器构成
- 指定分词器
- 内置分词器
一 分词
1、Analysis(分词) 和 Analyzer(分词器)
Analysis: 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词。Analysis是通过Analyzer来实现的。
当一个文档被索引时,每个Field都可能会创建一个倒排索引(Mapping可以设置不索引该Field)。
倒排索引的过程就是将文档通过Analyzer分成一个一个的Term,每一个Term都指向包含这个Term的文档集合。
当查询query时,Elasticsearch会根据搜索类型决定是否对query进行analyze,然后和倒排索引中的term进行相关性查询,匹配相应的文档。
二 分词器
- 内置分词器
- 扩展分词器
分词器查看命令
POST _analyze
{
"analyzer": "standard",
"text": "Like X 国庆放假的"
}
运行结果
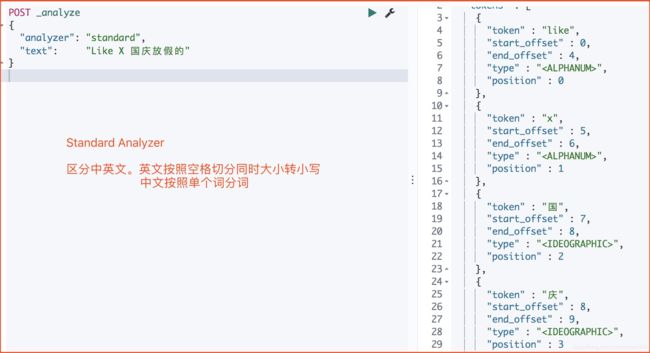
三 分词器构成
- Character Filters:字符过滤器,针对原始文本进行处理,比如去除html标签
- Tokenizer:英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。,将原始文本按照一定规则切分为单词
- Token Filters:针对Tokenizer处理的单词进行再加工,比如转小写、删除或增新等处理。将切分的单词进行加工。大小写转换(例将“Quick”转为小写),去掉词(例如停用词像“a”、“and”、“the”等等),或者增加词(例如同义词像“jump”和“leap”)
执行顺序:
Character Filters--->Tokenizer--->Token Filter
三者个数:
analyzer = CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
四 指定分词器
创建索引时设置分词器
PUT new_index
{
"settings": {
"analysis": {
"analyzer": {
"std_folded": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "std_folded" #指定分词器
},
"content": {
"type": "text",
"analyzer": "whitespace" #指定分词器
}
}
}
}
配置
标准分析器接受下列参数:
max_token_length : 最大token长度,默认255
stopwords : 预定义的停止词列表,如_english_或 包含停止词列表的数组,默认是 none
stopwords_path : 包含停止词的文件路径
PUT new_index
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard", #设置分词器为standard
"max_token_length": 5, #设置分词最大为5
"stopwords": "_english_" #设置过滤词
}
}
}
}
}
五 内置分词器
| 分词器 | 说明 |
|---|---|
| Standard Analyzer | 默认分词器 |
| Simple Analyzer | 简单分词器 |
| Whitespace Analyzer | 空格分词器 |
| Stop Analyzer | 删除停止词的分词器 is the |
| Keyword Analyzer | 不分词 |
| Pattern Analyzer | 正则分词器 |
| Language Analyzers | 多语言特定的分析工具 |
| Fingerprint Analyzer | 指纹分词器 |
| Custom analyzers | 自定义分词器 |
Standard Analyzer
1、描述&特征:
(1)默认分词器,如果未指定,则使用该分词器。
(2)按词切分,支持多语言
(3)小写处理,它删除大多数标点符号、小写术语,并支持删除停止词。
2、组成:
(1)Tokenizer:Standard Tokenizer
(2)Token Filters:Lower Case Token Filter
例:POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
上面的句子会产生下面的条件:
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog's, bone ]
Simple Analyzer
1、描述&特征:
(1)按照非字母切分,简单分词器在遇到不是字母的字符时将文本分解为术语
(2)小写处理,所有条款都是小写的。
2、组成:
(1)Tokenizer:Lower Case Tokenizer
例:
POST _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
上面的句子会产生下面的条件:
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
Whitespace Analyzer
1、描述&特征
(1)空白字符作为分隔符,当遇到任何空白字符,空白分词器将文本分成术语。
2、组成:
(1)Tokenizer:Whitespace Tokenizer
例:
POST _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
上面的句子会产生下面的条件:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]
Stop Analyzer
1、描述&特征:
(1)类似于Simple Analyzer,但相比Simple Analyzer,支持删除停止字
(2)停用词指语气助词等修饰性词语,如the, an, 的, 这等
2、组成 :
(1)Tokenizer:Lower Case Tokenizer
(2)Token Filters:Stop Token Filter
例:
POST _analyze
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
上面的句子会产生下面的条件:
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ]
Keyword Analyzer
1、组成&特征:
(1)不分词,直接将输入作为一个单词输出,它接受给定的任何文本,并输出与单个术语完全相同的文本。
2、组成:
(1)Tokenizer:Keyword Tokenizer
例:
POST _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
上面的句子会产生下面的条件:
[ The 2 QUICK Brown-Foxes jumped over the lazy dog's bone. ]
Pattern Analyzer
模式分词器使用正则表达式将文本拆分为术语。
(1)通过正则表达式自定义分隔符
(2)默认是\W+,即非字词的符号作为分隔符
Language Analyzers
ElasticSearch提供许多语言特定的分析工具,如英语或法语。
Fingerprint Analyzer
指纹分词器是一种专业的指纹分词器,它可以创建一个指纹,用于重复检测。
Custom analyzers
如果您找不到适合您需要的分词器,您可以创建一个自定义分词器,它结合了适当的字符过滤器、记号赋予器和记号过滤器。
参考
- https://www.jianshu.com/p/65bcac286012
- https://www.cnblogs.com/qdhxhz/p/11585639.html