10分钟教你如何hack掉Java编译器
10分钟教你如何hack掉Java编译器
-
- 1、程序编译执行流程
-
- 1.1、一般执行流程
- 1.2、编译案例
- 2、Java程序编译类型
-
- 2.1、Java程序编译执行过程
- 3、javac
-
- 3.1、javac中的主要类
- 3.2、javac主要处理流程
- 4、注解处理器
-
- 4.1、注解处理器与反射的区别
- 4.2、如何实现一个注解处理器
-
- 4.2.1、写一个注解
- 4.2.2、写一个注解处理器
- 4.2.3、通过SPI注册你的注解处理器
- 4.2.4、打包并且使用你的lib包
- 4.2.5、使用案例
- 4.3、注解处理器其他相关应用
-
- 4.3.1、Lombok
- 4.3.2、Dagger
- 4.3.3、Checker
- References
导读:
如标题所述,我们如何才能hack掉java编译器,也就是javac呢?为了摸索到这个套路,我们需要从一般的编译流程,javac的编译流程,以及插入式注解处理器说起,最后通过一个例子演示如何在编译期间篡改代码,并且介绍业界常见的应用场景。读完该篇文章,你可以了解到:
- 编译器一般编译流程
- javac的编译流程是怎样的
- 如何hack掉Java编译器
- 运行时DI和编译期DI的区别
1、程序编译执行流程
1.1、一般执行流程
一般情况下,一个程序从编译到执行,有以下这些阶段:

1.2、编译案例
如下,以龙书中的例子为例,一个语句的编译流程:
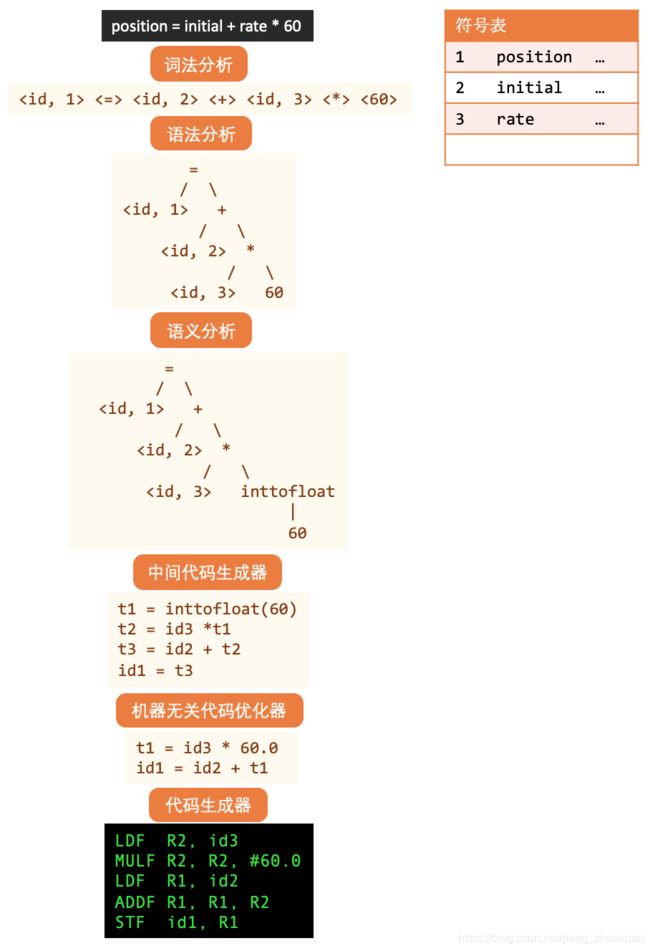
符号表:是一种用于数据结构,源程序中的每个标识符都和它的声明或使用信息绑定在一起,比如其数据类型、作用域以及内存地址。
在编译程序工作过程中,会不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息,这些信息一般以表格形式存储于系统中,如常数表、变量表、数组名表、过程名表、标号表等,这些统称为符号表。
2、Java程序编译类型
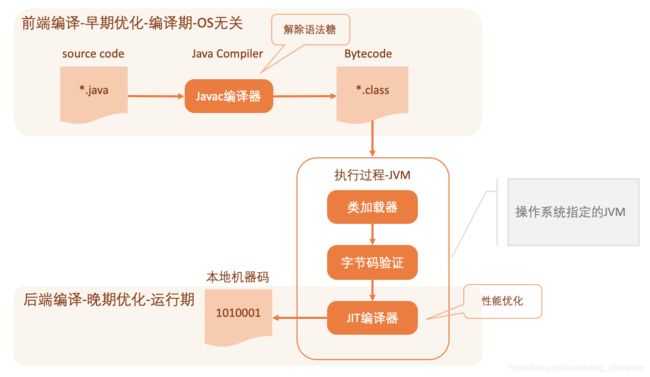
而在Java中,有几种编译模式,如果用的是前端编译+后端编译,则把以上流程进行划分,常用的组合是:javac前端编译器+JIT后端编译器:

而在执行过程中,会进行混合模式执行:部分函数会解释执行,部分会编译执行。
2.1、Java程序编译执行过程
如下图,为Java代码从编译到执行的过程:
-
在前端编译时,把Java源文件编译为Class文件;
-
在解释执行时,会收集运行数据,根据热点代码进行JIT编译优化,生成本地机器码,加快程序的执行。
更多关于类加载器,系统初始化,以及加载Class文件到JVM的过程,参考之前发布的两篇文章:
-
关于类加载器以及系统启动执行流程:一篇图文彻底弄懂类加载器与双亲委派机制
-
具体的加载Class文件到JVM的流程:一篇图文彻底弄懂Class文件是如何被加载进JVM的
3、javac
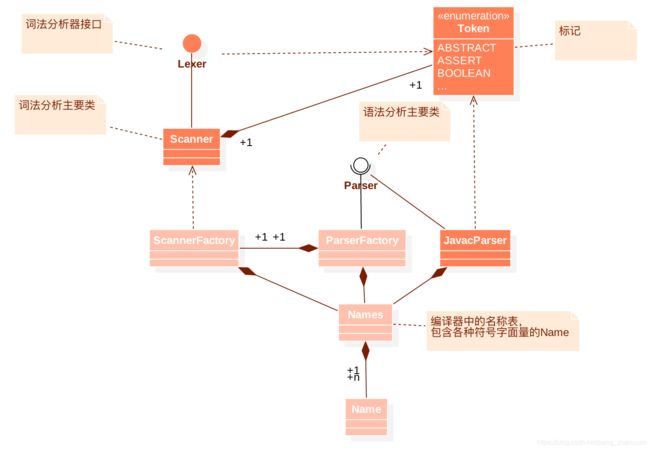
3.1、javac中的主要类
3.2、javac主要处理流程
主要处理流程入口:JavaCompiler.compile()

compile2()方法中的默认编译策略:
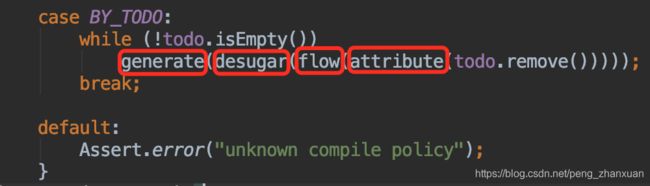
梳理一下以上的代码流程,如下图所示:

-
initProcessAnnotations:- 准备过程:初始化插入式注解处理器
-
Parse:parseFiles(sourceFileObjects) 解析步骤,读取一系列的Java源文件,把解析的Token序列结果映射到AST-Nodes(抽象语法树各个节点):词法分析:将字符流转换为标记(Token)集合(符号流);语法分析:根据token序列构造抽象语法树,后续操作都建立在语法树上,语法分析相关类:Parser;
-
Enter:enterTrees 填充符号表,编译器将在其作用域范围内找到所有定义的符号,主要包含以下两个阶段:- 第一阶段:注册所有类到其相应的作用域范围,在这一步编译器为每个类符号记录一个MemberEnter对象,该对象将用于第二阶段;
- 第二阶段:使用上面的MemberEnter对象继续完善类符号相关信息。主要包括:确定类的参数,超类和接口。
-
Annotate:processAnnotations():- 注解处理器的执行过程。如果存在注解处理器,并且请求了注解处理,则将处理在指定的编译单元中找到的所有注解。JSR 269定义了用于编写此类插件的接口,后面会有详细介绍。
-
delegateCompiler.compile2():分析及字节码生成-
Attribute:语义分析过程,标注检查,主要包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等;同时会进行常量折叠(int a = 1+2 折叠为 int a =3); -
Flow:语义分析过程,数据及控制流分析。这一步是对程序上下文逻辑更进一步的验证,可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受检验异常都被正确处理了等问题。-
final类型的局部变量就是通过在这一步分析来保证不被重新赋值的;因为局部变量不像类变量,在Class文件中有CONSTANT_Fieldref_info符号引用,记录了访问标志。
-
-
Desugar:解除语法糖(inner classes, class literals, assertions, foreach loops),重写AST; -
Generate:生成字节码,同时会进行少量代码添加和转换工作。如:- 添加实例构造器
() () - 把字符串相加操作替换为StringBuffer或者StringBuilder(JDK 1.5+);
- 添加实例构造器
-
4、注解处理器
我们上一节讲解了javac的主要处理流程,其中在解析成抽象语法树之后,有一个处理注解流程,这个流程是通过提供一组插入式注解处理器的标准API(Java规范提案 JSR 269: Pluggable Annotation Processing API )在编译期间对注解进行处理。我们可以把它看做是一组编译器的插件,在插件中可以读取,修改和添加抽象语法树中的任意元素。
JSR269是从Java6开始提供;
在Java5 之前注解处理器尚未成熟,注解处理器的API并不是JDK标准,而是通过独立的apt工具(Annotation Processor Tool,分发于
com.sun.mirror包下)来编写自定义处理器。
如果插入式注解处理器在处理注解期间修改了AST(抽象语法树),编译器将回到解析与填充符号表的过程重新处理,直到所有插入式注解处理器都没有在修改AST为止,每一次循环成为一个Round,如下图:

我们也可以自己实现JSR 269的API,自定义一个插入式注解处理器,为javac自定义编译行为。
4.1、注解处理器与反射的区别
我们可以通过反射获取注解,但是这只能在运行时通过反射获取注解,运行效率比较低;另外反射无法做到在编译阶段进行代码检查;
Java 6开始,可以使用JSR 269的API编写注解处理器。JSR 269可以在javac编译期利用注解进行检查和改写语法树的能力,与反射的运行期干预不同,大大提高了执行效率。
4.2、如何实现一个注解处理器
自定义注解处理器的接口
注解处理器实现了javax.annotation.processing.Processor接口,遵循给定的协定。为了方便实现,同时提供了javax.annotation.processing.AbstractProcessor类实现具有自定义处理器通用功能的抽象实现。以下是该接口的关键需要实现的方法,注释处理期间,Java编译器将调用这两个方法:
/**
*第一个方法被调用一次以初始化插件
*/
public synchronized void init(ProcessingEnvironment processingEnv)
/**
* 在每次注释循环中被调用,在所有回合完成后再被调用一次
* @return 这些annotations注解是否由此 Processor 处理,返回ture表示该注解已经被处理, 不会再有后续其他处理器处理进行处理; 返回false表示仍可被其他后续处理器处理
*/
public boolean process(Set<? extends TypeElement> annotations,
RoundEnvironment roundEnv)
自定义注解处理器使用到的注解
javax.annotation.processing.SupportedAnnotationTypes:用于注册处理器支持的注解。有效值是注释类型的标准名称,允许使用通配符。javax.annotation.processing.SupportedSourceVersion:用于注册处理器支持的源代码版本。javax.annotation.processing.SupportedOptions:此注释用于注册允许通过命令行传递的自定义选项。
下面是一个注解处理器的例子,该例子源于:The Hacker’s Guide to Javac
这个例子主要是把以下格式的断言:
assert cond : detail;
在编译阶段替换为异常:
if (!cond) throw new AssertionError(detail);
4.2.1、写一个注解
public @interface ForceAssertions {
}
4.2.2、写一个注解处理器
注意,本例基于Java8,由于该例子中使用到了sun.tools包中的类,该包中的类非Java平台标准类,不同Java版本类方法有所不同,如果是Java6,参考上面源例子中的代码。
/**
* 注意,此例使用到了sun.tools中的类,可能会导致不稳定.
* 开发者不应该调用sun包,Oracle一直在提醒开发者,调用sun.*包里面的方法是危险的。
* sun包并不包含在Java平台的标准中,它与操作系统相关,
* 在不同的操作系统如Solaris,Windows,Linux,Mac等中的实现也各不相同,并且可能随着JDK版本而变化。详细说明:
* http://www.oracle.com/technetwork/java/faq-sun-packages-142232.html
*
* Created by arthinking on 30/1/2020.
*/
@SupportedAnnotationTypes("com.itzhai.annotation.process.demo.ForceAssertions")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class ForceAssertionsProcessor extends AbstractProcessor {
// 计数器用于向用户报告已应用的替换次数
private int tally;
// Trees JSR269的工具类,连接程序元素和树节点的桥梁。
// 例如,给定一个method元素,我们可以获得其关联的AST树节点
private Trees trees;
// TreeMaker 编译器的内部组件,用于创建树节点的工厂
private TreeMaker make;
// Name.Table 编译器的一个内部组件, Name是内部编译器字符串的抽象。
// 出于效率原因,Javac使用存储在公共大型缓冲区中的哈希字符串。
private Names names;
@Override
public synchronized void init(ProcessingEnvironment env) {
super.init(env);
trees = Trees.instance(env);
// 我们使用处理环境来处理必要的编译器组件。在编译器内,对编译器的每次调用都使用单个处理环境(或context上下文,内部称为上下文)。
// 把JSR269的ProcessingEnvironment转换为实际的编译器类型JavacProcessingEnvironment,以便能够调用更多的内部方法
JavacProcessingEnvironment javacProcessingEnvironment = (JavacProcessingEnvironment)env;
// 使用context上下文来确保每个编译器调用都存在每个编译器组件的单个副本。
Context context = javacProcessingEnvironment.getContext();
// 在编译器中,我们仅使用 Component.instance(context) 来获取对该阶段的引用
make = TreeMaker.instance(context);
names = Names.instance(context);
// tally 计数器用于向用户报告已应用的替换次数。
tally = 0;
}
@Override
public boolean process(Set<? extends TypeElement> annotations,
RoundEnvironment roundEnv) {
if (!roundEnv.processingOver()) {
// 遍历所有的程序元素,并且重写每个类的AST
Set<? extends Element> elements = roundEnv.getRootElements();
for (Element each : elements) {
if (each.getKind() == ElementKind.CLASS) {
// 把JSR269的 Tree 转换为实际的JCTree类型,以便可以访问所有的AST元素。
JCTree tree = (JCTree) trees.getTree(each);
// 通过对TreeTranslator进行子类化来完成树翻译,
// TreeTranslator本身是TreeVisitor的子类。
// 这些类都不是JSR269的一部分,而是Java编译器内部的类。
TreeTranslator visitor = new Inliner();
tree.accept(visitor);
}
}
} else {
// 输出处理的断言语句的数量
processingEnv.getMessager().printMessage(
Diagnostic.Kind.NOTE, tally + " assertions inlined.");
}
return false;
}
/**
* Inliner类实现了AST的重写
*/
private class Inliner extends TreeTranslator {
/**
* 为了改变assert语句,我们这里重写了 visitAssert(JCAssert tree) 方法
* @param tree
*/
@Override
public void visitAssert(JCAssert tree) {
// 必须调用超类方法,以确保将转换也应用于节点的子代。
super.visitAssert(tree);
// 改写逻辑在makeIfThrowException这个方法中,结果赋值给 TreeTranslator.result
result = makeIfThrowException(tree);
tally++;
}
/**
* 具体的assert语句转换逻辑:
* assert cond : detail;
* 转换为:
* if (!cond) throw new AssertionError(detail);
*
* 该方法将一个断言语句作为参数,并返回一个if语句。
* 这是一个有效的返回值,因为两个树节点都是语句,因此与Java语法等效。
*
* @param node
* @return
*/
private JCStatement makeIfThrowException(JCAssert node) {
// make: if (!(condition) throw new AssertionError(detail);
// 获取断言的 detail
List<JCExpression> args = node.getDetail() == null
? List.<JCExpression>nil()
: List.of(node.detail);
// 创建了一个AST节点,该节点创建了“AssertionError”的新实例。
JCExpression expr = make.NewClass(
null,
null,
// 使用Name.Table获取编译器内部字符串表示形式
make.Ident(names.fromString("AssertionError")),
args,
null);
// 返回一个if语句
return make.If(
// 倒置 assert的条件
make.Unary(JCTree.Tag.NOT, node.cond),
// 创建一个 throw 表达式
make.Throw(expr),
null);
}
}
}
4.2.3、通过SPI注册你的注解处理器
项目目录如下:
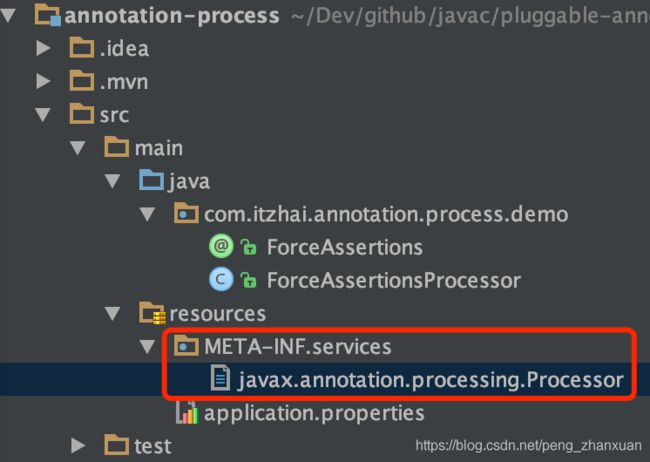
注意,红框部分的目录结构和命名要保持一致。
javax.annotation.processing.Processor文件中填写注解处理器,一行一个,本例子中该文件的内容为:
com.itzhai.annotation.process.demo.ForceAssertionsProcessor
4.2.4、打包并且使用你的lib包
这里以maven打包为例,您需要使用如下的maven插件:
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<verbose>trueverbose>
<fork>truefork>
<compilerVersion>1.8compilerVersion>
<source>1.8source>
<target>1.8target>
<encoding>utf-8encoding>
<proc>noneproc>
<compilerArguments>
<classpath>${JAVA_HOME}/lib/tools.jarclasspath>
compilerArguments>
configuration>
plugin>
注意以上标明重点!的地方,不能配错了,否则可能导致打包失败。
然后通过Maven打包成jar包,这样就可以在其他项目中引入jar包,在代码编译的时候编译器会自动查找到该注解处理器,对需要处理的类进行处理了。
4.2.5、使用案例
我们在一个新的项目中引入上面打的注解处理器jar包:
<dependencies>
<dependency>
<groupId>com.itzhaigroupId>
<artifactId>annotation-processartifactId>
<version>0.0.1-SNAPSHOTversion>
<scope>compilescope>
dependency>
dependencies>
编写如下代码进行测试:
public class ForceAssertExample {
/**
* java -ea com.itzhai.annotation.process.demo.ForceAssertExample
* @param args
*/
public static void main(String[] args) {
String str = null;
assert str != null : "Must not be null";
}
}
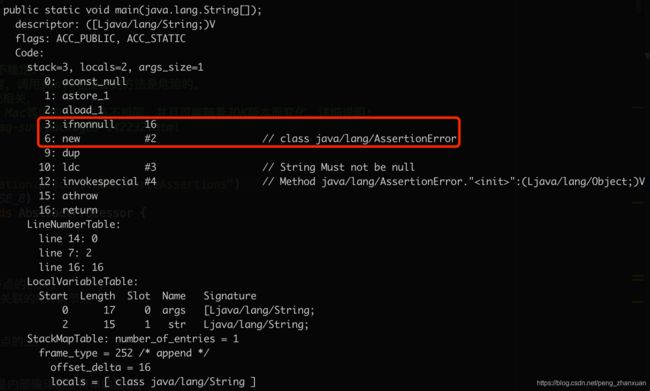
直接编译发现assert并没有被替换掉,可以通过javap -v查看对应的反汇编代码:

原因是少了注解处理器对应的注解@ForceAssertions,我们把它加到类上面,重新编译,发现assert已经被替换掉了:
该例子完整代码:https://github.com/arthinking/pluggable-annotation-processor
4.3、注解处理器其他相关应用
4.3.1、Lombok
使用Lombok,可以消除POJO中冗长的get, set, hashCode, equals, 构造参数等代码,这也是通过注解处理器来实现的。Lombok基于JSR 269,并且hack了javac和jdt以便能够访问和修改类的抽象语法树的内部实现。
如何编写一个类似Lombok的@Builder功能更,可以参考此文:Java奇技淫巧-插件化注解处理API(Pluggable Annotation Processing API)
4.3.2、Dagger
Dagger是一种快速,轻量级的依赖注入框架,该框架可用于Java和Android,该框架在编译时注入以获得更高的行能。Dagger是第一个实现标准javax.inject注解的DI框架(JSR 330)。其底层也是通过注解处理器实现的,其核心处理类是ComponentProcessor,继承了Google Auto提供的抽象注解处理框架的BasicAnnotationProcessor实现的。
依赖注入是控制反转原理的具体应用,不同的框架以不同的方式实现依赖注入,这里我们对比以下两类:
- 运行时
依赖注入,通常基于反射,更易于使用,但是会导致运行时更慢,Spring就是运行时的DI框架; - 编译时生成具体的代码,这意味着所有繁重的操作都是在编译期间执行的,编译时DI增加了复杂性,但是通常执行的更快,Dagger就是编译时
依赖注入。
4.3.3、Checker
Checker是一个通过向Java语言中添加可插入类型系统来增加Java类型系统的框架。
在定义类类型限定符以及语义和编译器插件(注解处理器)之后,开发人员可以在其程序中编写类型限定符,并使用该插件检测或者防止错误,例如空指针异常,SQL注入,并发错误等等。
下面是一个使用例子,我们使用@NonNull注解表明ref必须引用到非空的对象:
import org.checkerframework.checker.nullness.qual.*;
public class Example {
void sample() {
@NonNull Object ref = null;
}
}
如果我们执行Checker:
javac -processor org.checkerframework.checker.nullness.NullnessChecker Example.java
会发现提示如下错误:
Example.java:4: incompatible types.
found : @Nullable
required: @NonNull Object
@NonNull Object ref = null;
^
1 error
更多Checker的注解:Checker Framework Manual.
References
What is JIT in Java?
Compilation and Execution of a Java Program
Javac编译器详解
Compiler Theory(编译原理)、词法/语法/AST/中间代码优化在Webshell检测上的应用
《The Dragon Book》
The Hacker’s Guide to Javac
十分钟搞懂Lombok使用与原理
Java奇技淫巧-插件化注解处理API(Pluggable Annotation Processing API)
JSR 269: Pluggable Annotation Processing API
Gwt and JSR 269’s Pluggable Annotation Processing API
Code Generation using Annotation Processors in the Java language – part 2: Annotation Processors
Introduction to Dagger 2
Java Annotation: Dependency Injection and Beyond
本文作者: arthinking
本文链接: https://www.itzhai.com/jvm/java-code-from-compilation-to-execution.html
10分钟教你如何hack掉Java编译器
版权声明: 版权归作者所有,未经许可不得转载,侵权必究!联系作者请加公众号。
更多内容欢迎关注我的公众号:Java架构杂谈
