<C语言>数据文件自动生成(多模块进阶)
功能描述 :基于上一篇“数据文件自动生成的实现”文章,利用工程化组织方式与多文件、多模块程序开发技术,在数据文件自动生成三元组数据的基础功能上,考虑生成数据的参数限制、输入参数是否合法等功能的实现。
关 键 词 :头文件与源文件;结构体使用方法;文件路径合法性判断
读者注意:本文章基于此前一篇文章写作,若对部分代码有疑惑,可查看
<C语言>数据文件自动生成的实现
0 绪论
任何工程项目都是模块的有机结合,C语言程序也不例外。工程可以包含多个文件,多个文件中只有一个文件中含有main函数(主函数),其余文件通过#include进行包含。这种设计给予开发人员极大的便利性,以主函数为树干,各功能函数是对树干进行的枝、丫、叶式的扩充。
1 工程文件划分
工程文件模块划分设计如以下表格所示:
| 序号 | 文件名称 | 说明 |
|---|---|---|
| 1 | Lab3.cpp | 存储main函数的函数实现 |
| 2 | Lab3_run.cpp | 存储run函数的函数实现 |
| 3 | Lab3_fun.cpp | 存储run函数需要调用的各个子函数 |
| 4 | Lab3_run.h | 存储run函数的函数声明 |
| 5 | Lab3_fun.h | 存储各个子函数声明 |
| 6 | Lab3_data.h | 存储结构体声明及常量声明 |
| 7 | base.h | 存储使用到的标准头文件 |

1.1 编译器的工作过程
在C语言工程中,一般包含.cpp文件(源文件)和.h文件(头文件)两种文件,两种文件的划分是由编译器的工作过程决定的,编译器的工作过程大致分为以下几个阶段:
- 预处理阶段 为了节省时间,编译器会在编译源码之前,先预编译头文件,这保证了头文件只编译一次,然后编译器就开始替换掉源码中的头文件和宏;
- 词法与语法分析阶段 词法分析将输入的字符串流进行分析,并按一定的规则将输入的字符串流进行分割,从而形成所使用的源程序语言所允许的记号(token),语法分析是分析词法分析产生的记号序列,并按一定的语法规则识别并生成中间表示形式,以及符号表,将不符合语法规则的记号识别出其位置并产生错误提示语句;
- 编译阶段 首先将目标文件编译成纯汇编语句,再将之编译成跟CPU相关的二进制码,生成各个目标文件(.obj文件);
- 连接阶段 将各个目标文件中的各段代码进行绝对地址定位,生成跟特定平台相关的可执行文件(.exe文件),当然,最后还可以生成纯二进制码,去掉文件格式信息。
文件的作用是为工程提供一个执行路径,由以上介绍可知,这种路径分为两种:第一种是预处理阶段,要把指定头文件包含进来(复制粘贴的过程)所需要的路径;第二种是连接阶段,因为.cpp 文件里的东西都是相对独立的,在编译时不需要与其他文件互通,但函数、变量(全局)及结构体都是一次定义的(在某文件中),其他文件可多次引用(需要声明),只有使各目标文件间的引用和定义形成链接,形成绝对的地址路径,才能生成可执行文件的执行通路。
1.2 头文件的使用
对于.h文件(头文件),可以将其理解为对多个声明进行集中的文件,以便多个声明的批次调用。其内容跟.cpp文件(源文件)中的内容是一样的,但头文件不用被编译。某一个源文件可以通过一个宏命令 “#include”(其在编译器进行编译之前,即在预编译的时候起作用,作用是把后面所写文件的内容,完完整整地包含到当前的文件中来) 将其包含,从而把其内容合并到源文件中去。
【使用头文件应注意重复包含问题】
- 避免头文件重复包含 以下两种方法皆可:
#pragma once
//头文件内容
//实现功能:告诉预编译器只包含一次(在头文件顶端使用)
#ifndef TEST_H_
#define TEST_H_
//头文件内容
#endif
//实现功能:如果未定义宏变量TEST_H_则定义它,若定义了则不再定义
- 避免重复定义 不要将函数定义放置在头文件里面,正确的做法是头文件放置函数声明,源文件放置函数定义。因为源文件是分别编译的,假如头文件放置了函数定义,包含该头文件的每一个源文件都会定义相应的函数,从而导致重复定义。
- 避免头文件互相包含和循环包含 不要使头文件互相包含,这会导致递归包含,头文件互相依赖的逻辑本身就是错误的而且无法实现,头文件循环包含同理。正确的做法是将头文件的依赖降到最小,尽量在源文件中包含头文件,头文件中尽量用前置声明(尽量使用指针和引用,相关定义放到源文件中等)。
在本工程中,Lab3.cpp作为main函数(主函数),只运行了run()函数(需要声明),run()函数在Lab3_run.cpp中被定义,在Lab3_run.h中被声明。而run()函数的定义采用了一种自顶而下的程序设计思想,该函数只从逻辑流程上模块化的描述功能实现,而将模块化拆分为具体功能函数的工作是在Lab3_fun.cpp中完成的,Lab3_fun.h是对Lab3_fun.cpp中定义的具体功能函数的集中声明。在Lab3_data.h中定义了结构体,还对某些参数进行了宏定义,在base.h包含所有用到的标准头文件。以上的工程文件划分正是基于主干、枝叶的结构组织的,为工程的具体实施带来了便利。
2 结构体声明及使用
本工程采用如下结构体描述生成数据的限制参数:
typedef struct configinfo
{
char filesavepath[MAX_STR_LEN]; //用于存放数据记录文件的存储目录
char filename[MAX_STR_LEN]; //用于存储数据记录文件的文件名信息
int number; //用于存放生成的记录条数
int maxvalue1; //用于存放生成的数据记录三元组中第1、2个元素取值的上限
int minvalue1; //用于存放生成的数据记录三元组中第1、2个元素取值的下限
int maxvalue2; //用于存放生成的数据记录三元组中第3个元素取值的上限
int minvalue2; //用于存放生成的数据记录三元组中第3个元素取值的下限
int recordcount1; //用于存放数据记录文件随机生成记录条数时条数值上限
int recordcount2; //用于存放数据记录文件随机生成记录条数时条数值下限
}CONF;
2.1 结构体定义方法
2.1.2 typedef 定义结构体
typedef 为C语言的关键字,作用是为一种数据类型定义一个新名字。这里的数据类型包括内部数据类型(int,char等)和自定义的数据类型(struct等)。在编程中使用 typedef 目的一般有两个:一是给变量一个易记且意义明确的新名字,二是简化一些比较复杂的类型声明。
本工程使用此种方法定义结构体,如以上代码所示,typedef 定义结构体过程完成两个操作:一是定义一个结构体名称 configinfo,struct 关键字和 configinfo 一起构成了这个结构类型,不论是否有 typedef 关键字这个结构都存在;二是 typedef 在结构体末尾为这个新结构起一个名字CONF。 因此CONF实际上相当于 struct configinfo,所以可以使用CONF来定义变量。
【typedef 定义结构体的使用方法】
- 用 typedef 定义的结构体,使结构体末尾空白(不起别名)也是可以的,但之后的结构体变量仍需使用 struct configinfo conf1, conf2; 来定义,否则编译器会报错;
- 结构体末尾有了CONF别名结构体变量,可用CONF conf1, conf2; 来定义结构体变量(常用方式),也可用 struct configinfo conf1, conf2; 来定义(未利用 typedef 特点,故不推荐)。
- 结构体末尾有了CONF别名结构体变量,定义结构体时可缺省结构体名称 configinfo,直接用 typedef struct 定义结构体,结构体变量的定义与上一点所述一致。
2.1.2 直接定义结构体
该方法多有书籍资料详细介绍,对结构体直接使用 struct 关键字定义了结构数据类型。”结构”是一种构造数据类型,现在一般叫做用户自定义数据类型,它是由若干“成员”组成的。 每一个成员可以是一个基本数据类型或者又是一个构造类型。
【三种直接定义结构体方法(基于以上结构体定义实例)】
- 去掉 typedef 关键字,直接使用 struct configinfo 进行定义,结构体末尾空白,在以后定义结构体变量时使用 struct configinfo conf1, conf2; 即可;
- 去掉 typedef 关键字,直接使用 struct configinfo 进行定义,结构体末尾定义需要使用的结构体变量conf1, conf2,以后还可使用 struct configinfo conf3; 定义新的结构体变量;
- 去掉 typedef 关键字,结构体名称缺省,直接使用 struct 进行定义,结构体末尾定义需要使用的结构体变量conf1, conf2,但以后不可再定义新的结构体变量。
2.2 结构体作为函数参数使用方法
- 结构体变量作为函数的参数 这实际上是在栈区复制了结构体信息,修改之后的成员值存在于栈区,在函数结束后被释放,形参结构体变量成员值的改变不影响对应的实参构体变量成员值的改变,其不能返回到主调函数;
- 结构体数组作为函数的参数 形参结构体数组元素修改后的元素成员值的改变将影响对应的实参构体数组成员值的改变,使之能返回到主调函数;
- 结构体指针变量作为函数的参数 形参结构体指针变量指向的变量成员值的改变将影响对应的实参结构体指针变量指向的变量成员值的改变,使之能返回到主调函数。
3 输入参数合法性的判断
本工程是对上一工程 (数据文件自动生成的实现) 的多模块进阶,需要重点考虑的仍然是命令行参数的获取。本工程对命令行参数的输入做了条件扩展,并引入了对输入参数的合法性判断,以下从两次工程对输入参数处理逻辑上的差异性来具体分析。
3.1 记录条数参数
两个工程同样对记录条数参数优先判断(鲜明的特征决定这一点),判断机理相同(首字符是否为数字字符),字符串中提取带权的数值方法相同。相关程序可参见上一工程文章。
不同在于当命令行参数不足时,上一工程直接随机生成条数参数,本工程可再次输入该参数,所以需要对该参数进行合法性判断,在输入参数首字符不为数字字符情况下直接报错并退出程序,在“0”值时触发随机生成功能(随机生成值有上下限)。
void getRecNum(CONF* conf) //通过界面交互获取记录条数
{
char temp[MAX_STR_LEN];
printf("请输入您需要生成的记录条数(输入0表示随机生成记录条数):\n");
scanf("%s", temp);
clearStdin(); //清空输入缓冲区,以防止一次输入多余缓冲干扰二次输入
//判断用户输入是否合法
while(!isNumber(temp))
{
printf("您的输入无法转换为整数,请重新输入:\n");
scanf("%s", temp);
clearStdin();
}
conf->number = strToNumber(temp);
printf("您输入的记录条数为:%d\n", conf->number);
if(conf->number == 0)
{
conf->number = random(conf->recordcount1, conf->recordcount2);
printf("已随机生成记录条数:%d\n", conf->number);
}
}
随机生成值上下限应用上一工程文章中提及的 ((rand() % (max - min + 1)) + min) 来实现。
int random(int max, int min) //随机生成有上下限的值,值域为[min, max]
{
int number;
number = ((rand() % (max - min + 1)) + min);
return number;
}
注意在命令行参数有条数参数(原始输入)且其值为0的情况下,两工程随机生成条数参数的功能是一致的,也就是不必再考虑输入合法性的判断。
3.2 文件路径参数
与在记录条数参数中描述的逻辑类似,当命令行参数不足时,本工程会引导用户输入参数,而不是上一工程中的默认当前目录下的默认文件名。但用户任何时候(包括命令行参数中原始输入和缺失时引导的输入)输入的文件路径参数(包括绝对路径和相对路径),考察其合法性都是必不可少的重中之重。本工程只在输入文件路径参数为“no”时,才默认使用当前目录下的默认文件名。
3.2.1 文件路径合法性规则(windows平台)
1)文件不能以’//’(可以以’\ ’开头,表示从当前盘符位置开始计算)
2)“:\”或“: /”均表示绝对路径,如"E:\abc\111.txt"和"E:/abc\111.txt"均为正确路径
3)路径不能以“\ \”或“/”结尾,以这两个结尾的话就相当于文件名为空
4)相对路径中不能出现’:’,绝对路径中’:’必须与“\ \”或“/”成对出现,并且只能出现一次,其他情况下再出现’:’也为非法
5)目录名或文件名中不能出现非法字符包括:’:’、’*’、’?’、’\ "’、’<’、’>’、’|’
6)路径中‘\ \’和‘/’分隔符可以混用,都是合法的
使用checkFilePath()函数检查文件路径合法性,函数代码如下:
int checkFilePath(char* path) //检查输入的文件路径path是否合法,不合法返回0,合法返回1
{
//不能以'//'开头
if(*path == '//')
{
return 0;
}
//不能以"\\"或"/"结尾,以这两个结尾的话就相当于文件名为空
char* index1 = strrchr(path, '\\');//strrchr函数用于查找一个字符在一个字符串中末次出现的位置
char* index2 = strrchr(path, '/');
if(index1-path+1 == strlen(path) || index2-path+1 == strlen(path))
{
return 0;
}
//判断输入的路径是绝对路径还是相对路径
char* p1 = strstr(path, ":\\"); //strstr函数用于在字符串中查找第一次出现某字符串的位置
char* p2 = strstr(path, ":/");
if(p1 || p2) //输入的是绝对路径
{
//单独将盘符取出
char disk[3];
char *index;
if(p1)
{
strncpy(disk, path, p1-path+1);//strncpy函数用于将指定长度的字符串复制到字符数组中
index = p1;
}
if(p2)
{
strncpy(disk, path, p2-path+1);
index = p2;
}
disk[2] = 0;//disk[0]和disk[1]有值
//判断盘符是否存在
if(_access(disk, 0) != 0)//access函数用来判断指定的文件或目录是否存在,存在返回0,不存在返回-1
{
return 0;
}
//将绝对路径盘符后的字符串取出
int full_len = strlen(path);
int sub_index = index-path+2;//从规范盘符位置起算其值为3
char sub_path[MAX_STR_LEN];
strncpy(sub_path, index+2, full_len-sub_index);//截取文件路径,数组sub_path[]长度为full_len-sub_index
sub_path[full_len-sub_index] = 0;//数组sub_path[]从0到full_len-sub_index-1有值
//判断路径中是否有非法字符
if(strstr(sub_path,":") || strstr(sub_path,"*") || strstr(sub_path,"?") || strstr(sub_path,"\"") || strstr(sub_path,"<") || strstr(sub_path,">") || strstr(sub_path,"|"))
{
return 0;
}
}
else
{
if(strstr(path,":") || strstr(path,"*") || strstr(path,"?") || strstr(path,"\"") || strstr(path,"<") || strstr(path,">") || strstr(path,"|"))
{
return 0;
}
}
return 1;
}
3.2.2 文件路径参数的拆分
若文件路径合法,则使用splitFilePath()函数对其文件路径和文件名进行拆分,以便生成数据文件函数中的进一步的处理。
void splitFilePath(CONF* conf, char* path) //对文件路径和文件名进行拆分,然后存储到结构体成员中
{
//判断输入的路径是绝对路径还是相对路径
char *p1 = strstr(path, ":\\");//在参数path所指向的字符串中查找第一次出现特定字符串的位置,不包含终止符 '\0'
char *p2 = strstr(path, ":/"); //绝对路径
if(p1 || p2) //输入的是绝对路径
{
char *index1 = strrchr(path, '\\');//在参数path所指向的字符串中搜索最后一次出现特定字符串的位置,并输出其后字符串
char *index2 = strrchr(path, '/');
char *index;
if(index1 > index2)
{
index = index1;//index是带有符号的文件名字符串
}
else
{
index = index2;
}
int full_len = strlen(path);
int sub_index = index-path+1;//得到除去文件名的字符串长度
strncpy(conf->filesavepath, path, sub_index);//用于将指定长度的字符串复制到字符数组中
conf->filesavepath[sub_index] = 0;
strncpy(conf->filename, index+1, full_len-sub_index);
conf->filename[full_len-sub_index] = 0;
}
else //输入的是相对路径
{
char *index1 = strrchr(path, '\\');//在参数path所指向的字符串中搜索最后一次出现特定字符串的位置,并输出其后字符串
char *index2 = strrchr(path, '/');
char *index;
if(index1 > index2)
{
index = index1;
}
else
{
index = index2;
}
if(index)
{
//当相对路径中包含目录信息时,将目录信息和文件名信息分别提取
int full_len = strlen(path);
int sub_index = index-path+1;
strncpy(conf->filesavepath, path, sub_index);
conf->filesavepath[sub_index] = 0;
strncpy(conf->filename, index+1, full_len-sub_index);
conf->filename[full_len-sub_index] = 0;
}
else
{
//当相对路径中不含目录信息时,直接作为文件名处理
if(!strcmp(path, "no"))
{
path = "test.txt";
printf("已使用默认文件名:%s\n", conf->filename);
}
strcpy(conf->filename, path);
}
}
fixFileName(conf);
}
代码最后的fixFileName()函数是对文件名后缀的规范操作,与上一工程文章中提及的相似。
4 测试运行
本程序在Visual Studio 2010中进行测试(建议版本不超过VS2013、VC6,编译提示的各系统函数不安全不必理会,更改可能致误),在可执行文件的目录下(如E:\Projects\Lab3\Debug)对文件路径键入cmd可打开命令窗口(或者通过WIN+R,运行cmd到可执行文件所在目录),本工程在程序中添加了多个关键信息的打印语句,所以可根据窗口打印结果初步判定程序运行状态,然后再查看生成文档内容。
在上一工程测试的基础上,针对重点功能输入命令行参数如下:
- “Lab3 0 abc” 一次输入,应:随机生成[50, 500]间的记录条数,生成数据存入“abc.txt”;
- “Lab3 0 no” 一次输入,应:随机生成[50, 500]间的记录条数,生成数据存入“test.txt”;
- “Lab3” 、“0”、“abcd” 依次输入,应:随机生成[50, 500]间的记录条数,生成数据存入“abcd.txt”;
- “Lab3” 、“0ab1234”、“abc.dat” 依次输入,应:记录条数123,生成数据存入“abc.dat”;
- “Lab3” 、“ab1234”、“0ab1234” 、“0ab1234” 依次输入,应:重新输入,记录条数123,生成数据存入“0ab1234.txt”;
- "Lab3 ab1234 0ab1234"一次输入,应:记录条数123,生成数据存入“ab1234.txt”;
- “Lab3 0 E:\Projects\Lab3\Lab3” 一次输入,应:记录条数0,生成数据存入“E:\Projects\Lab3\Lab3.txt”;
- “Lab3 0 E:\Projects\Lab3\Debug\1234” 一次输入,应:随机生成[50, 500]间的记录条数,生成数据存入“E:\Projects\Lab3\Debug\1234.txt”;
- “Lab3 0 D:\Projects\Lab3\Debug\1234!” 一次输入,应:随机生成[50, 500]间的记录条数,文件目录无效,生成数据存入“E:\Projects\Lab3\Debug\1234!.txt”;
- “Lab3 0ab1234”、“E:\Projects\Lab3\Debug|0ab12”、"E:\Projects\Lab3\Debug//0ab12"依次输入,应:记录条数123,重新输入,生成数据存入“E:\Projects\Lab3\Debug\0ab12.txt”;
- “Lab3 0ab1234”、"\Projects\Lab3\Debug//0ab123" 依次输入,应:记录条数123,生成数据存入“E:\Projects\Lab3\Debug\0ab123.txt”;
- “Lab3 0ab1234”、"\Projects\Lab3\Debug"、"\Projects\Lab3\Debug\0ab1"依次输入,应:记录条数123,生成数据存入“E:\Projects\Lab3\Debug\0ab1.txt”;
测试1~7结果如下四图所示:




测试8~12结果如下三图所示:
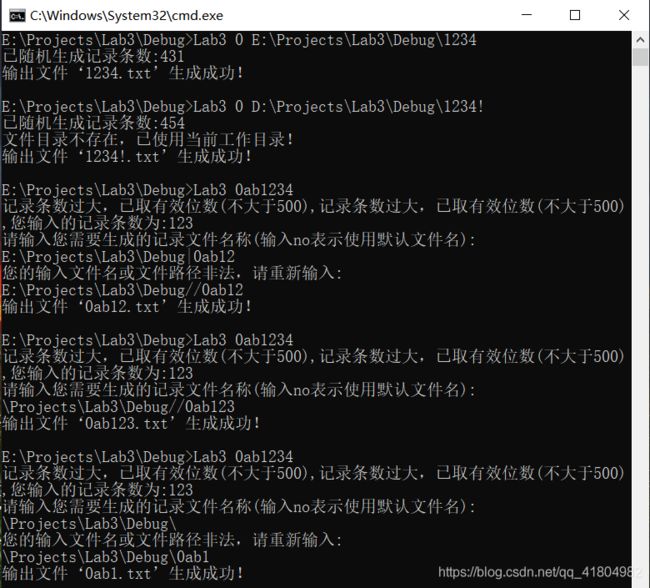


测试所得结果与预期相符,随机生成的记录条数看上去是随机的,三元组内元素数据值遵循结构体中的限制条件,文件路径识别无错误情况。
5 工程代码
工程项目下载链接:https://download.csdn.net/download/qq_41804982/16793716
本工程对各功能模块进行了函数封装,格式规范、注释详细、易于阅读。
6 写在后面
该项目开展过程中被多方事务耽误,所以距上次项目的完成相隔了月余,所幸之后事情不多,有时间赶一赶进度。一般来说,项目工程在完成之后才会着手文章的组织写作,所以项目工程上传会早于文章发布1~2天,但在文章写作中的具体分析和测试可能会发现一些项目工程中潜在的问题,所以一般文章链接的项目工程最终版(重新上传)会有个别修改之处。
若文章内容有误,敬请各位读者评论指出,亦可私信作者。文章内容的组织多是以作者的视角盲点来组织,文字性论述偏多,阅读需要一定耐心。若有读者想探究其他问题,可提前指明。
另外关于文章不设置目录的原因稍作解答:此系列工程项目的探究方向和顺序是基于关键词进行的(关键信息已被提及),文章间的后续组织也具有相似性,所以作者认为缺省目录这并不会给长期读者带来不便,反而是减少了阅读负担,新读者可在电脑阅读界面的左下方看到系统组织的目录。
如果你坚持读到了这里,何不考虑为自己和作者的足够耐心点个赞再走呢?
7 参考资料
<C语言>数据文件自动生成的实现:
https://blog.csdn.net/qq_41804982/article/details/114909367
头文件与源文件:
https://zhidao.baidu.com/question/876995747523059332.html
https://www.cnblogs.com/xxcn/p/10930105.html
https://blog.csdn.net/u012491514/article/details/24590467
结构体定义与使用:
https://blog.csdn.net/weixin_30361641/article/details/97494200
https://blog.csdn.net/ziguo2010/article/details/79897327
https://blog.csdn.net/wang13342322203/article/details/80862204
https://blog.csdn.net/as480133937/article/details/83473208
感谢众多网友的系列参考资料,在此向所列资料作者致谢,也向一些缺漏的作者致歉。尤其感谢好友龙某(可搜索*weixin_40162095的博客* 进行关注)提供的顾问服务。