JVM虚拟机
推荐书籍:《深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)》
看Java性能优化实战 9.1
JVM是基于栈的解释型机器。这意味着JVM和物理硬件CPU不同,它没有寄存器,而是使用一个包含部分结果的执行栈,并通过操作该栈顶的一个值或多个值来执行计算。
可以把JVM解释器的基本行为理解为一个”包含在while循环中的switch语句”(switch-inside-while),按顺序单独处理程序的每一个字节码,使用求值栈保存中间结果。
JVM提供了3个保存数据的主要区域:
1.求值栈,属于特定方法本地;
2.用与临时存储结果的局部变量(也属于方法本地)
3.对象堆,在方法和线程间共享
在JVM中,每个栈式机器操作码(opcode)用1表示,叫做字节码(bytecode)。相应地,操作码的范围是从0~255,其中大约有200个在java 10中使用。
字节码指令是带类型信息的,iadd和dadd期望在栈顶找到两个正确的基本类型值(分别是两个int和两个double)。
比如,在store一族中,特定指令有特定意义:dstore的意思是”将栈顶的值保存到一个double类型的局部变量中“,而astore的意思是”将栈顶的值保存到一个引用类型的局部变量中“。在这两种情况下,局部变量的类型必须与要存入的值的类型相匹配。
因为Java是为高度可移植设计的,所以JVM规范被设计为无须修改就能在大端(big-endian)和小端(little-endian)的硬件架构上运行同样的字节码。因此,JVM字节码必须决定到底遵循哪种字节顺序(使用相反约定的硬件必须在软件层处理这种差异)。
字节码选择了大端方式,所以对任何多字节序列,高位优先。
JVM运行时功能:
1.命令行选项
2.VM生命周期
启动器启动Hot Spot VM时会执行一系列操作。步骤如下:
(1)解析命令行参数
(2)设置堆大小和JIT编译器
(3)设置环境变量如LD_LIBTARY_PATH和CLASSPATH
(4)如果命令行有-jar 选项,启动器则从指定的Jar的manifest中查找Main-Class,否则从命令行读取Main-Class.
(5)使用标准Jar本地接口(JNI)方式JNI_CreateJavaVM 在新创建的线程中创建HotSpot VM
(6)一旦创建并初始化好HotSpot VM,就会加载Java Main-Cliass,启动器也会从Java Main-Class 中得到Java main方法的参数。
(7)HotSpot VM通过JNI方法CallStaticVoidMethod调用Java main方法,并将命令行选项传递给它。
3. JVM类加载
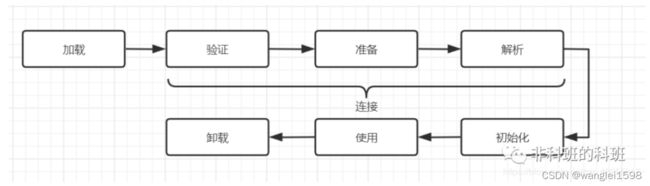
一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称为连接(Linking)。这七个阶段的发生顺序如图7-1所示。
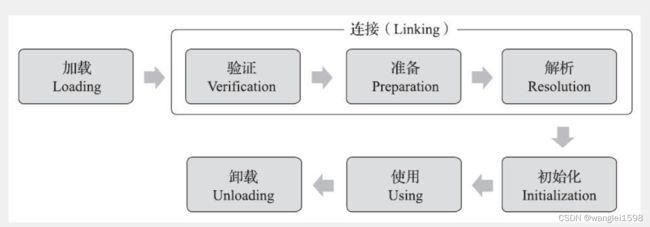
图7-1中,加载、验证、准备、初始化和卸载这五个阶段的顺序是确定的,类型的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定特性(也称为动态绑定或晚期绑定)。请注意,这里笔者写的是按部就班地“开始”,而不是按部就班地“进行”或按部就班地“完成”,强调这点是因为这些阶段通常都是互相交叉地混合进行的,会在一个阶段执行的过程中调用、激活另一个阶段。
关于在什么情况下需要开始类加载过程的第一个阶段“加载”,《Java虚拟机规范》中并没有进行强制约束,这点可以交给虚拟机的具体实现来自由把握。但是对于初始化阶段,《Java虚拟机规范》则是严格规定了有且只有六种情况必须立即对类进行“初始化”(而加载、验证、准备自然需要在此之前开始):
1)遇到new、getstatic、putstatic或invokestatic这四条字节码指令时,如果类型没有进行过初始化,则需要先触发其初始化阶段。能够生成这四条指令的典型Java代码场景有:
· 使用new关键字实例化对象的时候。
· 读取或设置一个类型的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候。
· 调用一个类型的静态方法的时候。
2)使用java.lang.reflect包的方法对类型进行反射调用的时候,如果类型没有进行过初始化,则需要先触发其初始化。
3)当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
4)当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
5)当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。
6)当一个接口中定义了JDK 8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
对于这六种会触发类型进行初始化的场景,《Java虚拟机规范》中使用了一个非常强烈的限定语——“有且只有”,这六种场景中的行为称为对一个类型进行主动引用。除此之外,所有引用类型的方式都不会触发初始化,称为被动引用。
(1)加载
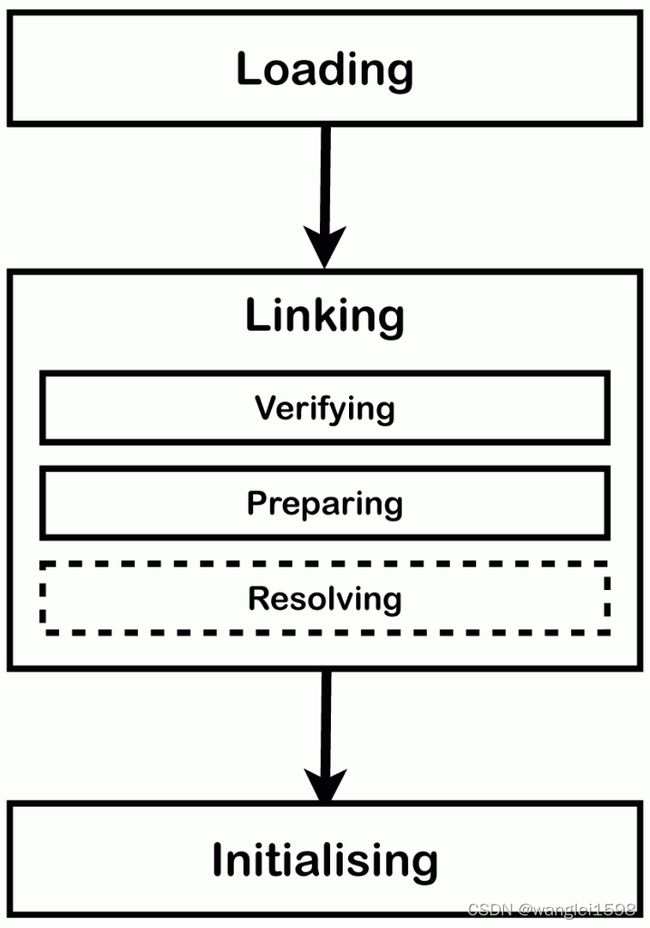
加载(Loading)是这样一个过程,找到代表这个类的 class 文件或根据特定的名字找到接口类型,然后读取到一个字节数组中。接着,这些字节会被解析检验它们是否代表一个 Class 对象并包含正确的 major、minor 版本信息。直接父类的类和接口也会被加载进来。这些操作一旦完成,类或者接口对象就从二进制表示中创建出来了。
(2)链接
链接(Linking)是校验类或接口并准备类型和父类父接口的过程。链接过程包含三步:校验(verifying)、准备(preparing)、部分解析(optionally resolving)。
校验会确认类或者接口表示是否结构正确,以及是否遵循 Java 语言和 JVM 的语义要求,比如会进行下面的检查:
-
格式一致且格式化正确的符号表
-
final 方法和类没有被重载
-
方法遵循访问控制关键词
-
方法参数的数量、类型正确
-
字节码没有不当的操作栈数据
-
变量在读取之前被初始化过
-
变量值的类型正确
在验证阶段做这些检查意味着不需要在运行阶段做这些检查。链接阶段的检查减慢了类加载的速度,但是它避免了执行这些字节码时的多次检查。
准备过程包括为静态存储和 JVM 使用的数据结构(比如方法表)分配内存空间。静态变量创建并初始化为默认值,但是初始化代码不在这个阶段执行,因为这是初始化过程的一部分。
解析是可选的阶段。它包括通过加载引用的类和接口来检查这些符号引用是否正确。如果不是发生在这个阶段,符号引用的解析要等到字节码指令使用这个引用的时候才会进行
(3)初始化
类或者接口初始化由类或接口初始化方法
(4)字节码验证
新生对象的内存分配:
接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定(如何确定将在2.3.2节中介绍),为对象分配空间的任务实际上便等同于把一块确定大小的内存块从Java堆中划分出来。假设Java堆中内存是绝对规整的,所有被使用过的内存都被放在一边,空闲的内存被放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间方向挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”(Bump The Pointer)。但如果Java堆中的内存并不是规整的,已被使用的内存和空闲的内存相互交错在一起,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”(Free List)。选择哪种分配方式由Java堆是否规整决定,而Java堆是否规整又由所采用的垃圾收集器是否带有空间压缩整理(Compact)的能力决定。因此,当使用Serial、ParNew等带压缩整理过程的收集器时,系统采用的分配算法是指针碰撞,既简单又高效;而当使用CMS这种基于清除(Sweep)算法的收集器时,理论上[插图]就只能采用较为复杂的空闲列表来分配内存。除如何划分可用空间之外,还有另外一个需要考虑的问题:对象创建在虚拟机中是非常频繁的行为,即使仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。解决这个问题有两种可选方案:一种是对分配内存空间的动作进行同步处理——实际上虚拟机是采用CAS配上失败重试的方式保证更新操作的原子性;另外一种是把内存分配的动作按照线程划分在不同的空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),哪个线程要分配内存,就在哪个线程的本地缓冲区中分配,只有本地缓冲区用完了,分配新的缓存区时才需要同步锁定。虚拟机是否使用TLAB,可以通过-XX:+/-UseTLAB参数来设定。内存分配完成之后,虚拟机必须将分配到的内存空间(但不包括对象头)都初始化为零值,如果使用了TLAB的话,这一项工作也可以提前至TLAB分配时顺便进行。这步操作保证了对象的实例字段在Java代码中可以不赋初始值就直接使用,使程序能访问到这些字段的数据类型所对应的零值。
接下来,Java虚拟机还要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码(实际上对象的哈希码会延后到真正调用Object::hashCode()方法时才计算)、对象的GC分代年龄等信息。这些信息存放在对象的对象头(Object Header)之中。根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。关于对象头的具体内容,稍后会详细介绍。
在上面工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了。但是从Java程序的视角看来,对象创建才刚刚开始——构造函数,即Class文件中的()方法还没有执行,所有的字段都为默认的零值,对象需要的其他资源和状态信息也还没有按照预定的意图构造好。一般来说(由字节码流中new指令后面是否跟随invokespecial指令所决定,Java编译器会在遇到new关键字的地方同时生成这两条字节码指令,但如果直接通过其他方式产生的则不一定如此),new指令之后会接着执行()方法,按照程序员的意愿对对象进行初始化,这样一个真正可用的对象才算完全被构造出来。
Java对象内存布局(JAVA object layout,JOL)
jol包可以查看对象内存布局 JOL:分析Java对象的内存布局 - 知乎
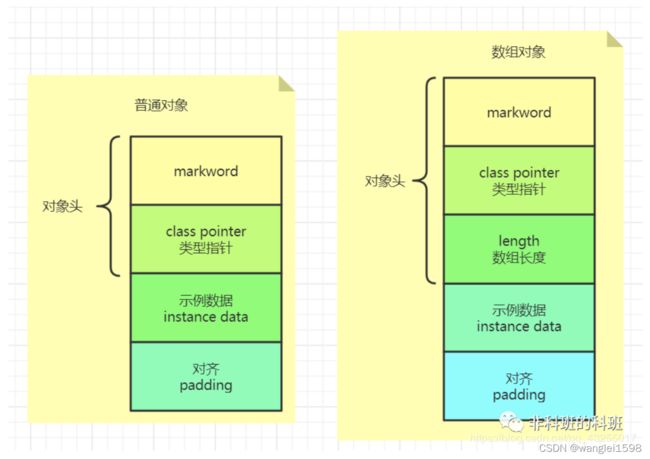
对象在内存中存储的布局可以分为三块区域: 对象头 (Header)、 实例数据 (Instance Data)和对齐填充(Padding)。示意图如下:
(字)Word:指的是计算机内存中占据一个单独的存储单元变好的一组二进制串。一般32位计算机上一个字为4个字节长度。
一、对象头
普通对象的对象头包括两部分:Mark Word和 Class Pointer (Klass Word)(类型指针),如果是数组对象还包括一个额外的Array length数组长度部分。
Mark Word:用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、 锁状态标志 、线程持有的锁、偏向线程ID、偏向时间戳等等,占用内存大小与虚拟机位长一致。
Class Pointer:类型指针指向对象的类元数据,虚拟机通过这个指针确定该对象是哪个类的实例。

JVM中对象头分为两部分:标记信息、元数据信息,代码如下所示:
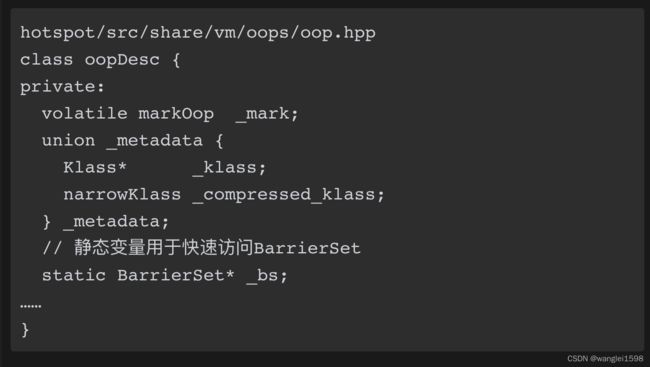
1.Mark Word 也就是标记信息 markoop部分
对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。
对mark word的设计方式上,非常像网络协议报文头:将mark word划分为多个比特位区间,并在不同的对象状态下赋予比特位不同的含义。
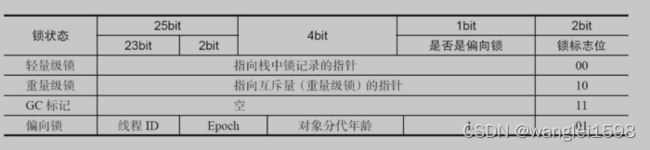
下图描述了在32位虚拟机上,在对象不同状态时mark word各个比特位区间的含义。
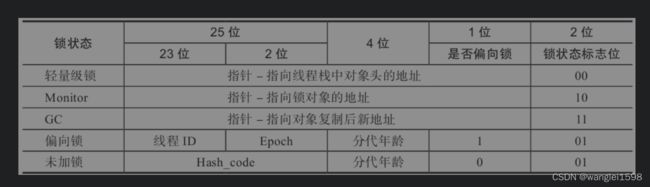
锁标记存放在Java对象头的Mark Word中。

Java对象头长度

32位JVM Mark Word 结构
32位JVM Mark Word 状态变化

64位JVM Mark Word 结构
缺个图
2.Class Meta Address 元数据信息
对象头的另外一部分是类型指针,即对象指向它的类型元数据的指针,Java虚拟机通过这个指针来确定该对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说,查找对象的元数据信息并不一定要经过对象本身,这点我们会在下一节具体讨论。
3.数组长度
如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是如果数组的长度是不确定的,将无法通过元数据中的信息推断出数组的大小。
二、实例数据
实例数据中也拥有两部分数据,一部分是基本类型数据,一部分是引用指针。这两部分数据我们在上面已经讲了。具体占用多少内存我们需要结合具体的对象继续分析,下面我们会有具体的分析。
从父类中继承下来的变量也是需要进行计算的
三、对齐填充
对齐填充并不是必然存在的,也没有特别的含义。它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求 对象起始地址必须是8字节的整数倍 ,换句话说就是对象的大小必须是8字节的整数倍。而如果对象头加上实例数据不是8的整数倍的话那么就会通过对其填充进行补全。
看Java性能优化实践6.2.1
HopSpot通过一个叫做oop的结构来表示运行时Java对象。这是普通对象的指针(ordinary object pointer)的简称,是C语言意义上的真正指针。这些指针可以放置在引用类型的局部变量中,在该变量中它们从Java方法的栈帧指向包含Java对的内存区域。
有几种不同的数据结构组成了oop家族,而用于表示Java类的实例的类型叫做instanceOop。
intanceOop的内存布局是从每个对象上都有的两个机器字的头部开始的。其中的第一个是mark word,它是一个指针,指向特定于该实例的原数据。下一个是class word,它指向类级别的元数据。
-XX:+UseCompressedOops 可以开启压缩指针
对象头中的MarkWord与垃圾回收
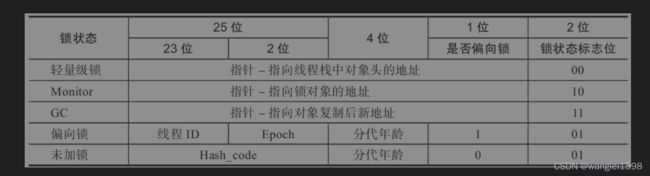
这里和GC直接相关的就是标记位11,前面的30位指针是非常有用的。在GC垃圾回收时,当对象被设置为marked(11)时,ptr指向什么位置?简单来说这个ptr是为了配合对象晋升时发生的对象复制(copy)。在对象复制时,先分配空间,再把原来对象的所有数据都复制过去,再修改对象引用的指针,就完成了。但是我们要思考这样一个问题,当有多个引用对象的字段指向同一个被引用对象时,我们完成一个被引用对象的复制之后,其他引用对象还没有被遍历(即还指向被引用对象老的地址),如何处理这种情况?这个时候简单设置状态为marked,表示被引用对象已经被标记且被复制了,ptr就是指向新的复制的地址。当遍历其他引用对象的时候,发现被引用对象已经完成标记,则不再需要复制对象,直接完成对象引用更新就可以了。
字节码: 图文详解 Java 字节码,想不懂都难!
看深入理解JVM字节码
Class文件结构
可以看JAVA虚拟机 JVM故障诊断与性能优化。深入理解Java虚拟机:JVM高级特性与最佳实践 。6.3
一个编译后的类文件包含下面的结构:

在Java虚拟机规范中,Class文件使用一种类似于C语言结构体的方式进行描述,并且统一使用无符号整数作为基本数据类型,由u1、u2、u4、u8分别代表无符号单字节、2字节、4字节和8字节整数。对于字符串,则使用u1数组进行表示。
使用Java虚拟机规范的定义,一个Class文件可以非常严谨地被描述成:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info contant_pool[constant_pool_count – 1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
|
|
magic, minor_version, major_version
|
魔数(CAFEBABE),类文件的版本信息和用于编译这个类的 JDK 版本。
|
|
constant_pool
|
类似于符号表,尽管它包含更多数据。下面有更多的详细描述。
|
|
access_flags
|
提供这个类的描述符列表。
|
|
this_class
|
提供这个类全名的常量池(constant_pool)索引,比如org/jamesdbloom/foo/Bar。
|
|
super_class
|
提供这个类的父类符号引用的常量池索引。
|
|
interfaces
|
指向常量池的索引数组,提供那些被实现的接口的符号引用。
|
|
fields
|
提供每个字段完整描述的常量池索引数组。
|
|
methods
|
指向constant_pool的索引数组,用于表示每个方法签名的完整描述。如果这个方法不是抽象方法也不是 native 方法,那么就会显示这个函数的字节码。
|
|
attributes
|
不同值的数组,表示这个类的附加信息,包括 RetentionPolicy.CLASS 和 RetentionPolicy.RUNTIME 注解。
|
Java字节码剖析:常量池 Java 字节码结构剖析一 : 常量池
Java字节码剖析:字段表 Java 字节码结构剖析二 : 字段表
class文件常量池:
常量池可以理解为 class 文件中资源仓库 ,它是 class 文件结构中与其它项目关联最多的数据类型,主要用于存放编译器生成的 各种字面量(Literal)和符号引用(Symbolic References) 。 字面量就是我们所说的常量概念,如文本字符串、被声明为 final 的常量值等 。 符号引用是一组符号来描述所引用的目标 ,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可(它与直接引用区分一下,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。一般包括下面三类常量:
-
类和接口的全限定名
-
字段的名称和描述符
-
方法的名称和描述符
从字符串到常量池,一文看懂String类
彻底弄懂java中的常量池
Class装载系统
看 JAVA虚拟机JVM故障诊断与性能优化第10章
Java程序的执行依赖于编译环境和运行环境。源码代码转变成可执行的机器代码,由下面的流程完成:
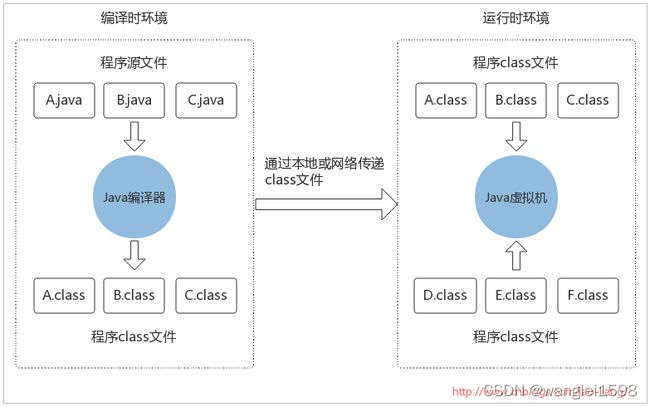
Java虚拟机的主要任务是装载class文件并且执行其中的字节码。由下图可以看出,Java虚拟机包含一个类装载器(class loader),它可以从程序和API中装载class文件,Java API中只有程序执行时需要的类才会被装载,字节码由执行引擎来执行。
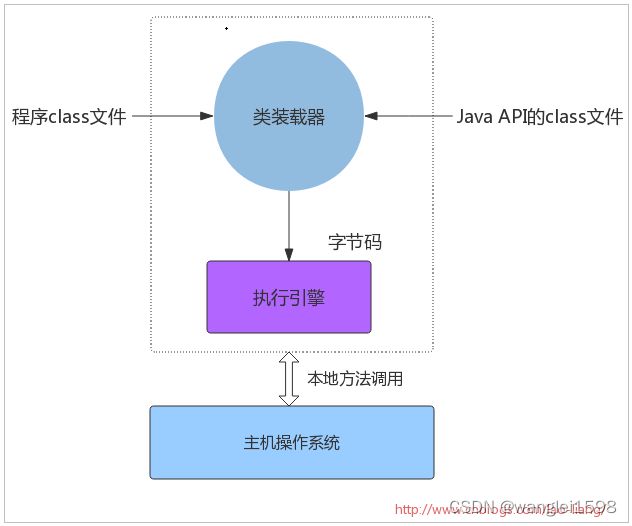
当Java虚拟机由主机操作系统上的软件实现时,Java程序通过调用本地方法和主机进行交互。Java方法由Java语言编写,编译成字节码,存储在class文件中。本地方法由C/C++/汇编语言编写,编译成和处理器相关的机器代码,存储在动态链接库中,格式是各个平台专有。所以本地方法是联系Java程序和底层主机操作系统的连接方式。
由于Java虚拟机并不知道某个class文件是如何被创建的,是否被篡改一无所知,所以它实现了一个class文件检测器,确保class文件中定义的类型可以安全地使用。class文件检验器通过四趟独立的扫描来保证程序的健壮性:
-
class文件的结构检查
-
类型数据的语义检查
-
字节码验证
-
符号引用验证
Java虚拟机在执行字节码时还进行其它的一些内置的安全机制的操作,他们作为Java编程语言保证Java程序健壮性的特性,同时也是Java虚拟机的特性:
-
类型安全的引用转换
-
结构化的内存访问
-
自动垃圾收集
-
数组边界检查
-
空引用检查
Java虚拟机数据类型
Java虚拟机通过某些数据类型来执行计算。数据类型可以分为两种:基本类型和引用类型,如下图:
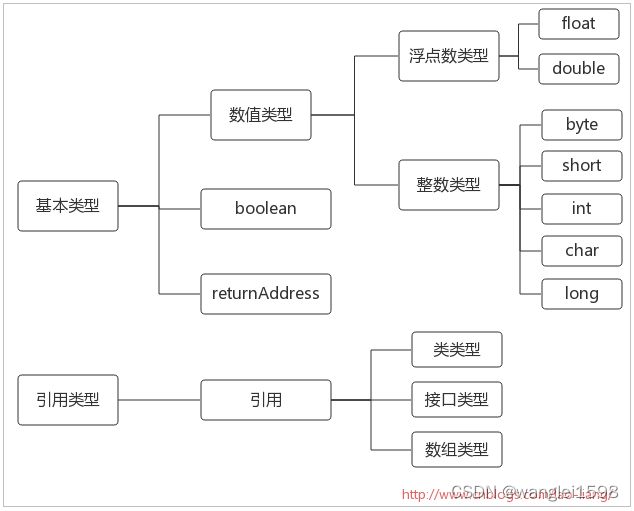
但boolean有点特别,当编译器把Java源码编译为字节码时,它会用int或byte表示boolean。在Java虚拟机中,false是由0表示,而true则由所有非零整数表示。和Java语言一样,Java虚拟机的基本类型的值域在任何地方都是一致的,不管主机平台是什么,一个long在任何虚拟机中总是一个64位二进制补码的有符号整数。
对于returnAddress,这个基本类型被用来实现Java程序中的finally子句,Java程序员不能使用这个类型,它的值指向一条虚拟机指令的操作码。
java虚拟机规范 The Java® Virtual Machine Specification
每运行一个程序就会初始化一个JVM实例
类的生命周期
面试官:你知道java类是怎么跑起来的吗?问的我一脸懵
1.加载
将.class文件读入内存,堆中建立一个Class对象
2.连接:把二进制数据合并到JRE中
验证:确保被导入类型的正确性
准备:在方法区中为类static变量分配内存空间并设置默认值 , 准备:为类变量分配内存,并将其初始化为默认值;
解析:把类型中的符号引用转化为直接引用
3.类的初始化
主要对静态域初始化
4.使用
5.卸载
JVM中使用一个类的全限定类名和类加载器所谓其唯一标识。
ClassLoader类
ClassLoader (Java Platform SE 7 )
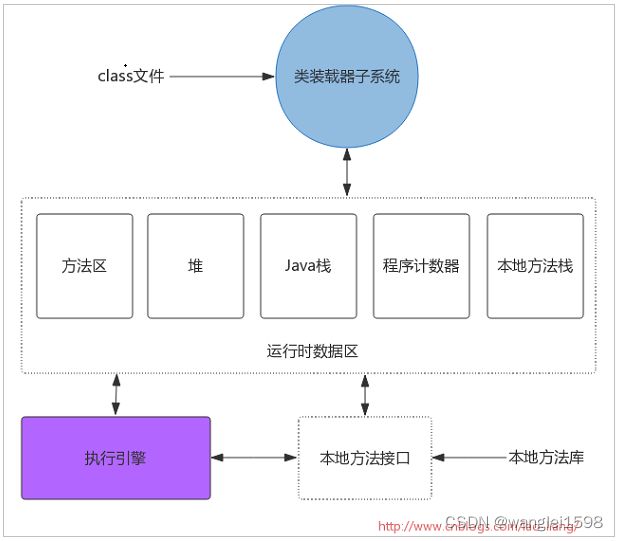
类装载器子系统
类装载器子系统负责查找并装载类型信息。其实Java虚拟机有两种类装载器:系统装载器和用户自定义装载器。前者是Java虚拟机实现的一部分,后者则是Java程序的一部分。
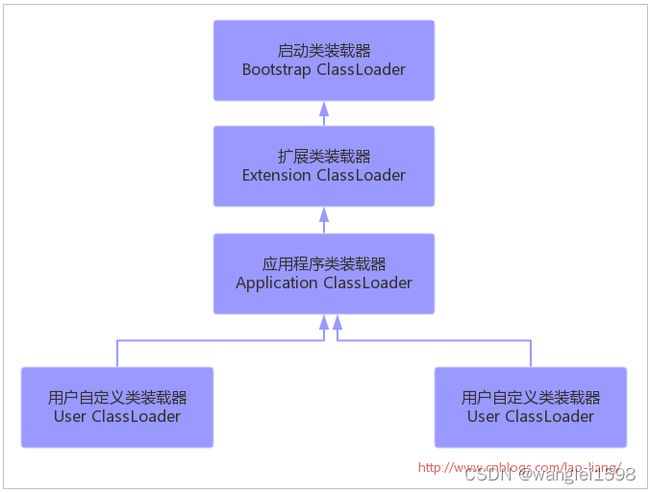
1.Bootstrap 根类加载器。加载/jre/lib/rt.jar中的java核心类. 它用来加载 Java 的核心库,是用原生代码来实现的,并不继承自java.lang.ClassLoader。
2.Extension 扩展类加载器。加载/jre/lib/ext 目录下的类ClassLoader.getSystemClassLoader().getParent()获取
3.System 系统类加载器。加载Classpath中的jar包。通过ClassLoader.getSystemClassLoader()获取
4.用户自定义类加载器。也可以用来加载应用类。使用自定义的类加载器有很多特殊的原因:运行时重新加载类或者把加载的类分隔为不同的组,典型的用法比如 web 服务器 Tomcat。
类装载器子系统涉及Java虚拟机的其它几个组成部分以及来自java.lang库的类。ClassLoader定义的方法为程序提供了访问类装载器机制的接口。此外,对于每一个被装载的类型,Java虚拟机都会为它创建一个java.lang.Class类的实例来代表该类型。和其它对象一样,用户自定义的类装载器以及Class类的实例放在内存中的堆区,而装载的类型信息则位于方法区。
类装载器子系统除了要定位和导入二进制class文件外,还必须负责验证被导入类的正确性,为类变量分配并初始化内存,以及解析符号引用。这些动作还需要按照以下顺序进行:
-
装载(查找并装载类型的二进制数据)
-
连接(执行验证:确保被导入类型的正确性;准备:为类变量分配内存,并将其初始化为默认值;解析:把类型中的符号引用转换为直接引用)
-
初始化(类变量初始化为正确初始值)
-Xbootclasspath:bootclasspath 让jvm从指定的路径中加载bootclass,用来替换jdk的rt.jar。一般不会用到 ,否则要重新写所有Java 核心class 。 完全取代基本核心的Java class 搜索路径
-Xbootclasspath/a:path 后缀在核心class搜索路径后面.常用!!
-Xbootclasspath/p:path 前缀在核心class搜索路径前面.不常用,避免 引起不必要的冲突
双亲委派机制(并不是强制的)
如果一个类加载器收到了加载类的请求,首先不会尝试自己加载,而是把请求为派给父类加载器处理,如果父加载器无法完成这个请求,才会自己加载。
突破双亲模式:重载ClassLoader可以修改该行为。事实上不少应用软件和框架都修改了这种行为,比如Tomcat和OSGi框架,都有各自独特的类加载顺序。
字节码的执行
虚拟机常用指令。 看Java虚拟机JVM故障诊断与性能优化。 深入理解Java虚拟机:JVM高级特性与最佳实践。
Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码,Opcode)以及跟随其后的零至多个代表此操作所需的参数(称为操作数,Operand)构成。由于Java虚拟机采用面向操作数栈而不是面向寄存器的架构(这两种架构的执行过程、区别和影响将在第8章中探讨),所以大多数指令都不包含操作数,只有一个操作码,指令参数都存放在操作数栈中。
JVM架构
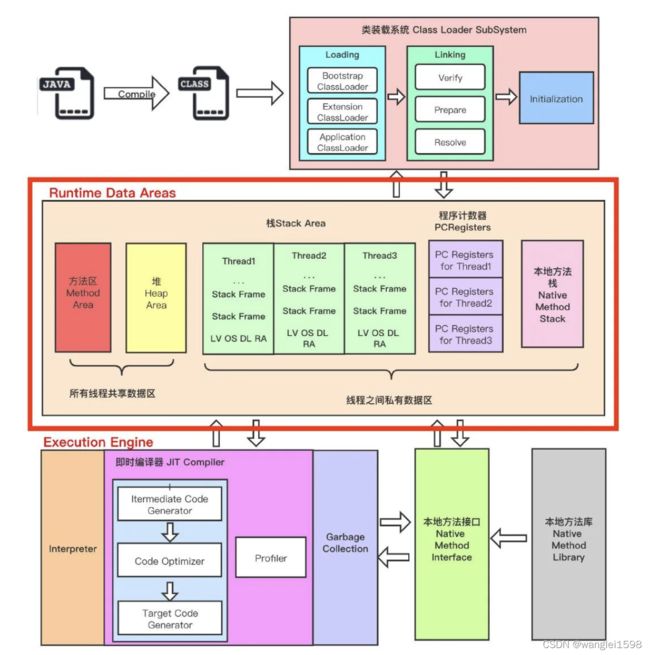
JVM虚拟机的五部分
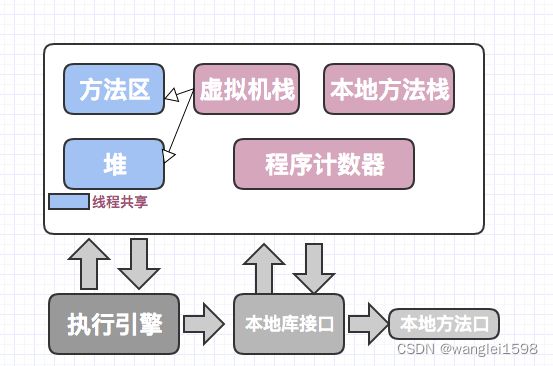
1.堆
根据《Java虚拟机规范》的规定,Java堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的,这点就像我们用磁盘空间去存储文件一样,并不要求每个文件都连续存放。但对于大对象(典型的如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的内存空间。
-Xms 为JVM启动时申请的最小Heap内存,默认为物理内存的1/64但小于1GB;-Xmx 为Java可申请的最大Heap内存,默认为物理内存的1/4但小于1GB,默认当空余堆内存小于 40%( -XX:MinHeapFreeRation= )时,JVM会增大Heap到-Xmx指定的大小;当空余堆内存大于 70%( -XX:MaxHeapFreeRation= )时,JVM会减小Heap的大小到-Xms的指定大小。 因此服务器一般设置-Xms、-Xmx 相等以避免在每次GC 后调整堆的大小。
不必是连续的空间。无内存时抛出OutOfMemoryError: Java heap space。线程共享。
java堆中进行了分代,分为新生代和老年代。新生代占比-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
新生代(New Generation):由一个Eden区,两个survivor区组成,默认大小8:1:1,-XX:SurvivorRatio 来调整 Eden区和Survivor区比例。垃圾回收称为 MinorGC(分代。复制垃圾回收算法) 可以通过-Xmn 指定新生代大小
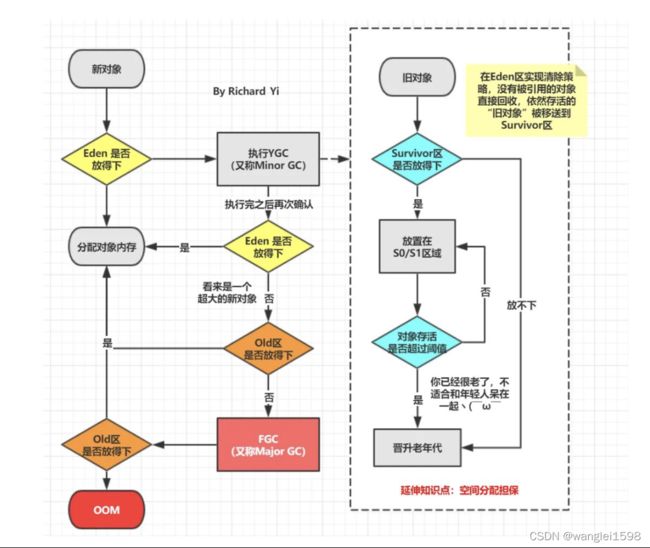
对象优先分配在Eden区,当Eden区满时发生一个MinorGC。仍存活的对象如果能被survivor区容纳,将被移动到survivor区。
并设置对象age为1.Survivor中对象没经过一个MinorGC,age加一。
i.对象年龄达到--XX:MaxTenuringThreshold(默认15),移动到老年代。
ii.动态对象年龄判定:如果YoungGC后,survivor区中相同年龄所有对象的大小总和大于Survivor空间(S0+S1)的一半,大于大于或等于该年龄的对象直接进入老年代
iii.如果 Young GC 后 S0 或 S1 区不足以容纳:未达到晋升老年代条件的新生代存活对象,会导致这些存活对象直接进入老年代,需要尽量避免。
TLAB ( Thread Local Allocation Buffer)线程本地分配缓存(在堆上Eden Space 内)
看Java虚拟机JVM故障诊断和性能优化 5.5.5
看JVM G1源码分析与调优 第三章
一个很好的TLAB文章系列:
全网最硬核 JVM TLAB 分析(单篇版不包含额外加菜) - 知乎
G1提供了两种对象分配策略:基于线程本地分配缓冲区(Thread LocalAllocation Buffer,TLAB)的快速分配和慢速分配;当不能成功分配对象时就会触发垃圾回收。
为了提高效率,JVM将Eden区划分成若干个缓冲区,并将这些缓冲区交给应用程序线程使用,用于新对象的分配。这种分配方法的好处是,每个线程都知道自己不需要考虑其他线程在该区域内分配的可能能性。这些区域叫做线程本地分配缓冲区(thread-local allocation buffer,TLAB)。
HotSpot会动态设置分给应用程序现成的TLAB的大小,所以如果某个线程的内存就要耗尽了,可以为其分配更大的TLAB,以减少向该线程提供缓冲区的开销。
对象创建在虚拟机中是非常频繁的行为,即使仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。解决这个问题有两种可选方案:一种是对分配内存空间的动作进行同步处理——实际上虚拟机是采用CAS配上失败重试的方式保证更新操作的原子性;另外一种是把内存分配的动作按照线程划分在不同的空间之中进行,即每个线程在Java堆中预先分配一小块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),哪个线程要分配内存,就在哪个线程的本地缓冲区中分配,只有本地缓冲区用完了,分配新的缓存区时才需要同步锁定。虚拟机是否使用TLAB,可以通过-XX:+/-UseTLAB参数来设定。
内存分配完成之后,虚拟机必须将分配到的内存空间(但不包括对象头)都初始化为零值,如果使用了TLAB的话,这一项工作也可以提前至TLAB分配时顺便进行。这步操作保证了对象的实例字段在Java代码中可以不赋初始值就直接使用,使程序能访问到这些字段的数据类型所对应的零值。
如果从分配内存的角度看,所有线程共享的Java堆Eden中可以划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)
为了提升内存分配的效率,会为每个新创建的线程在新生代的Eden Space 分配一块独立的空间,这块空间称为TLAB(Thread Local Allocation Buffer),其大小由JVM根据运行情况计算而得。TALB属于Eden区的一部分。可通过
-XX:TLABWasteTargetPercent来设置TLAB可占用的Eden Space的百分比,默认为1%。JVM将根据这个比例、线程数量以及线程是否频繁分配对象来给每个线程分配合适的大小的TLAB空间。在TLAB上分配内存时不需要加锁,因此JVM给线程中的对象分配内存时会尽量在TLAB上分配,如果对象过大或者TLAB已用尽,则仍在堆上分配。


-XX:+PrintTLAB
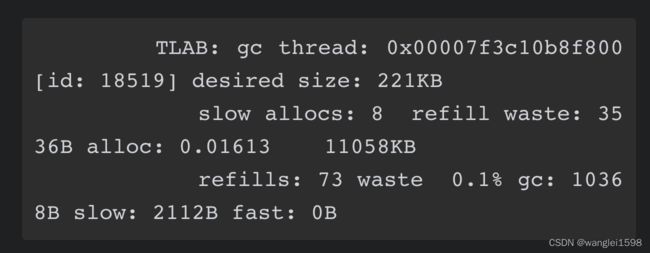
也可以用JFR监控
什么是 TLAB (Thread Local Allocation Buffer)?
-
从内存模型而不是垃圾回收的角度,对 Eden 区域继续进行划分,JVM 为每个线程分配了一个私有缓存区域,它包含在 Eden 空间内
-
多线程同时分配内存时,使用 TLAB 可以避免一系列的非线程安全问题,同时还能提升内存分配的吞吐量,因此我们可以将这种内存分配方式称为 快速分配策略
-
OpenJDK 衍生出来的 JVM 大都提供了 TLAB 设计
为什么要有 TLAB ?
-
堆区是线程共享的,任何线程都可以访问到堆区中的共享数据
-
由于对象实例的创建在 JVM 中非常频繁,因此在并发环境下从堆区中划分内存空间是线程不安全的
-
为避免多个线程操作同一地址,需要使用加锁等机制,进而影响分配速度
尽管不是所有的对象实例都能够在 TLAB 中成功分配内存,但 JVM 确实是将 TLAB 作为内存分配的首选。
TLAB和refill_waste
对象分配:
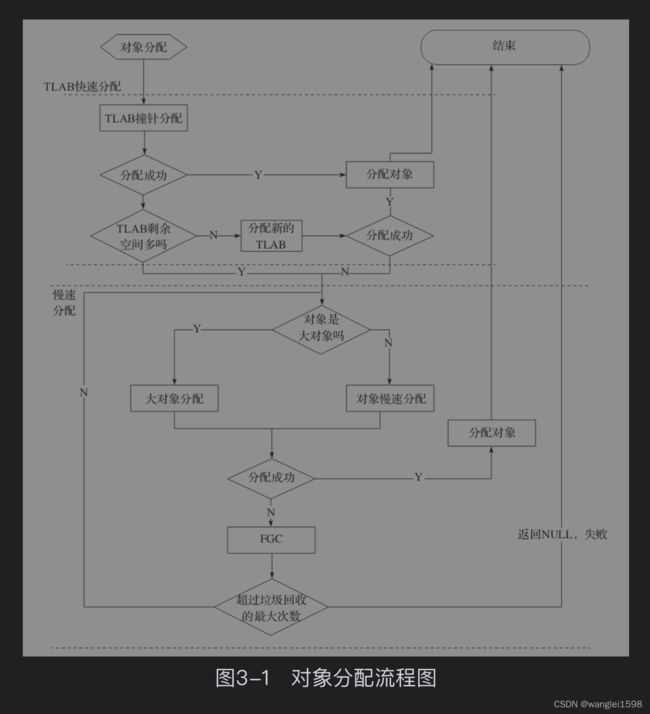
TLAB的快速分配
TLAB产生的目的就是为了进行内存快速分配。通常来说,JVM堆是所有线程的共享区域。因此,从JVM堆空间分配对象时,必须锁定整个堆,以便不会被其他线程中断和影响。为了解决这个问题,TLAB试图通过为每个线程分配一个缓冲区来避免和减少使用锁。在分配线程对象时,从JVM堆中分配一个固定大小的内存区域并将其作为线程的私有缓冲区,这个缓冲区称为TLAB。只有在为每个线程分配TLAB缓冲区时才需要锁定整个JVM堆。由于TLAB是属于线程的,不同的线程不共享TLAB,当 我们尝试分配一个对象时,优先从当前线程的TLAB中分配对象,不需要锁,因此达到了快速分配的目的。更进一步地讲,实际上TLAB是Eden区域中的一块内存,不同线程的TLAB都位于Eden区,所有的TLAB内存对所有的线程都是可见的,只不过每个线程有一个TLAB的数据结构,用于保存待分配内存区间的起始地址(start)和结束地址(end),在分配的时候只在这个区间做分配,从而达到无锁分配,快速分配。另外值得说明的是,虽然TLAB在分配对象空间的时候是无锁分配,但是TLAB空间本身在分配的时候还是需要锁的,G1中使用了CAS来并行分配。

TLAB在分区中的使用在图3-2中,Tn表示第n个线程,深灰色表示该TLAB块已经分配完毕,浅灰色表示该TLAB块还可以分配更多的对象。
从图中我们可以看出,线程T1已经使用了两个TLAB块,T1、T2和T4的TLAB块都有待分配的空间。这里并没有提及Eden和多个分区的概念,实际上一个分区可能有多个TLAB块,但是一个TLAB是不可能跨分区的。从图中我们也可以看出,每个线程的TLAB块并不重叠,所以线程之间对象的分配是可以并行的,且无影响。另外图中还隐藏了一些细节:·T1已经使用完两个TLAB块,这两个块在回收的时候如何处理?·我们可以想象TLAB的大小是固定的,但是对象的大小并不固定,因此TLAB中可能存在内存碎片的问题,这个该如何解决?请继续往下阅读。快速TLAB对象分配也有两步:·从线程的TLAB分配空间,如果成功则返回。·不能分配,先尝试分配一个新的TLAB,再分配对象。
如果TLAB过小,那么TLAB则不能存储更多的对象,所以可能需要不断地重新分配新的TLAB。但是如果TLAB过大,则可能导致内存碎片问题。
如果TLAB过小,那么TLAB则不能存储更多的对象,所以可能需要不断地重新分配新的TLAB。但是如果TLAB过大,则可能导致内存碎片问题。假设TLAB大小为1M,Eden为200M。如果有40个线程,每个线程分配1个TLAB,TLAB被填满之后,发生GC。假设TLAB中对象分配符合均匀分布,那么发生GC时,TLAB总的大小为:40×1×0.5=20M(Eden的10%左右),这意味着Eden还有很多空间时就发生了GC,这并不是我们想要的。最直观的想法是增加TLAB的大小或者增加线程的个数,这样TLAB在分配的时候效率会更高,但是在GC回收的时候则可能花费更长的时间。因此JVM提供了参数TLABSize用于控制TLAB的大小,如果我们设置了这个值,那么JVM就会使用这个值来初始化TLAB的大小。但是这样设置不够优雅,其实TLABSize默认值是0,也就是说JVM会推断这个值多大更合适。采用的参数为TLABWasteTargetPercent,用于设置TLAB可占用的Eden空间的百分比,默认值1%,推断方式为TLABSize=Eden×2×1%/线程个数(乘以2是因为假设其内存使用服从均匀分布)
在Java对象分配时,我们总希望它位于TLAB中,如果TLAB满了之后,如何处理呢?前面提到TLAB其实就是Eden的一块区域,在G1中就是HeapRegion的一块空闲区域。所以TLAB满了之后无须做额外的处理,直接保留这一部分空间,重新在Eden/堆分区中分配一块空间给TLAB,然后再在TLAB分配具体的对象。但这里会有两个小问题。
1.如何判断TLAB满了?按照前面的例子TLAB是1M,当我们使用800K,还是900K,还是950K时被认为满了?问题的答案是如何寻找最大的可能分配对象和减少内存碎片的平衡。实际上虚拟机内部会维护一个叫做refill_waste的值,当请求对象大于refill_waste时,会选择在堆中分配,若小于该值,则会废弃当前TLAB,新建TLAB来分配对象。这个阈值可以使用TLABRefillWasteFraction来调整,它表示TLAB中允许产生这种浪费的比例。默认值为64,即表示使用约为1/64的TLAB空间作为refill_waste,在我们的这个例子中,refill_waste的初始值为16K,即TLAB中还剩(1M-16k=1024-16=1008K)1008K内存时直接分配一个新的,否则尽量使用这个老的TLAB。
2.如何调整TLAB
如果要分配的内存大于TLAB剩余的空间则直接在Eden/HeapRegion中分配。那么这个1/64是否合适?会不会太小,比如通常分配的对象大多是20K,最后剩下16K,这样导致每次都进入Eden/堆分区慢速分配中。所以,JVM还提供了一个参数TLAB WasteIncrement(默认值为4个字)用于动态增加这个refill_waste的值。 默认情况下,TLAB大小和refill_waste都会在运行时不断调整,使系统的运行状态达到最优。在动态调整的过程中,也不能无限制变更,所以JVM提供MinTLABSize(默认值2K)用于控制最小值,对于G1来说,由于大对象都不在新生代分区,所以TLAB也不能分配大对象,HeapRegion/2就会被认定为大对象,所以TLAB肯定不会超过HeapRegionSize的一半。如果想要禁用自动调整TLAB的大小,可以使用-XX:-ResizeTLAB禁用ResizeTLAB,并使用-XX:TLABSize手工指定一个TLAB的大小。-XX:+PrintTLAB可以跟踪TLAB的使用情况。一般不建议手工修改TLAB相关参数,推荐使用虚拟机默认行为。
TLAB慢速分配
继续来看TLAB中的慢速分配,主要的步骤有:
·TLAB的剩余空间是否太小,如果很小,即说明这个空间通常不满足对象的分配,所以最好丢弃,丢弃的方法就是填充一个dummy对象,然后申请新的TLAB来分配对象。
·如果不能丢弃,说明TLAB剩余空间并不小,能满足很多对象的分配,所以不能丢弃这个TLAB,否则内存浪费很多,此时可以把对象分配到堆中,不使用TLAB分配,所以可以直接返回。
慢速分配
当不能进行快速分配,就进入到慢速分配。实际上在TLAB中也有可能进入到慢速分配,就是我们前面提到的attempt_allocation,前面已经解释过。这里的慢速分配是指在TLAB中经过努力分配还不能成功,再次进入慢速分配,我们来看一下这个更慢的慢速分配:·attempt_allocation尝试进行对象分配,如果成功则返回。值得注意的是在attempt_allocation里面可能会进行垃圾回收,这里的垃圾回收是指增量的垃圾回收,主要是新生代或者混合收集,关于收集的内容将在下面的章节介绍,分配相关的代码在3.2节已经介绍过了,不再赘述。·如果大对象在attempt_allocation_humongous,直接分配的老生代。·如果分配不成功,则进行GC垃圾回收,注意这里的回收主要是Full GC,然后再分配。因为这里是分配的最后一步,所以进行几次不同的垃圾回收和尝试。主要代码在satisfy_failed_allocation中。·最终成功分配或者失败达到一定次数,则分配失败。
大对象分配和TLAB中的慢速分配基本类似。唯一的区别就是对象大小不同。步骤主要:·尝试垃圾回收,这里主要是增量回收,同时启动并发标记。·尝试开始分配对象,对于大对象分为两类,一类是大于HeapRegionSize的一半,但是小于HeapRegionSize,即一个完整的堆分区可以保存,则直接从空闲列表直接拿一个堆分区,或者分配一个新的堆分区。如果是连续对象,则需要多个堆分区,思路同上,但是处理的时候需要加锁。·如果失败再次尝试垃圾回收,之后再分配。·最终成功分配或者失败达到一定次数,则分配失败。
先尝试分配一下,因为并发之后可能可以分配:·尝试扩展新的分区,成功则返回。·不成功进行Full GC,但是不回收软引用,再次分配成功则返回。·不成功进行Full GC,回收软引用,最后一次分配成功则返回;不成功返回NULL,即分配失败。
本章详细介绍了G1中对象的快速分配和慢速分配,其中快速分配和TLAB相关。本节给出实际应用中对象分配用到的相关参数和一些个人经验,如下所示:·在优化调试TLAB的时候,在调试环境中可以通过打开PrintTLAB来观察TLAB分配和使用的情况。·参数UseTLAB,指是否使用TLAB。大量的实验可以证明使用TLAB能够加速对象分配;该参数默认是打开的,不要关闭它。·参数ResizeTLAB,指是否允许TLAB大小动态调整。前面提到TLAB会进行动态化调整,主要是基于历史信息(分配大小、线程数等),有基准测试表明使用动态调整TLAB大小效率更高。[插图]·参数MinTLABSize,指设置TLAB的最小值。实际应用需要设置该值,比如64K,一般可以根据情况设置和调整该值。·参数TLABSize,指设置TLAB的大小。实际中不要设置TLABSize,设置之后TLAB就不能动态调整了,即会使用一个固定大小的TLAB,前面我们提到GC可以根据情况动态调整TLAB,在分配效率和内存碎片之间找到一个平衡点,如果设置该值则这种平衡就失效了。·参数TLABWasteTargetPercent,指的是TLAB可占用的Eden空间的百分比,默认值是1。可以根据情况调整TLABWasteTargetPercent,增大则可以分配更多的TLAB,3.1节中给出了具体的计算方式;另外如果实际中线程数目很多,建议增大该值,这样每个线程的TLAB不至于太小。·参数TLABRefillWasteFraction,指的是TLAB中浪费空间和TLAB块的比例,默认值是64。可以根据情况调整TLABRefillWasteFraction,主要考量点是内存碎片和分配效率的平衡,如果发现日志waste中的slow和fast很大,说明浪费严重,可以适当减少该参数值。·参数TLABWasteIncrement,指的是动态的增加浪费空间的字节数,默认值是4。增加该值会增加TLAB浪费的空间;一般不用设置。·参数GCLockerRetryAllocationCount默认值为2,表示当分配中的垃圾回收次数超过这个阈值之后则直接失败。
堆是分配对象存储的唯一选择吗
随着 JIT 编译期的发展和逃逸分析技术的逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。 ——《深入理解 Java 虚拟机》
逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术,它与类型继承关系分析一样,并不是直接优化代码的手段,而是 为其他优化措施提供依据的分析技术。
逃逸分析的基本原理是:分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;甚至还有可能被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸;从不逃逸、方法逃逸到线程逃逸,称为对象由低到高的不同逃逸程度。
如果能证明一个对象不会逃逸到方法或线程之外(换句话说是别的方法或线程无法通过任何途径访问到这个对象),或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化,如:
· 栈上分配(Stack Allocations):在Java虚拟机中,Java堆上分配创建对象的内存空间几乎是Java程序员都知道的常识,Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问到堆中存储的对象数据。虚拟机的垃圾收集子系统会回收堆中不再使用的对象,但回收动作无论是标记筛选出可回收对象,还是回收和整理内存,都需要耗费大量资源。如果确定一个对象不会逃逸出线程之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,完全不会逃逸的局部对象和不会逃逸出线程的对象所占的比例是很大的,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集子系统的压力将会下降很多。栈上分配可以支持方法逃逸,但不能支持线程逃逸。
· 标量替换(Scalar Replacement):若一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型及reference类型等)都不能再进一步分解了,那么这些数据就可以被称为标量。相对的,如果一个数据可以继续分解,那它就被称为聚合量(Aggregate),Java中的对象就是典型的聚合量。如果把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量恢复为原始类型来访问,这个过程就称为标量替换。假如逃逸分析能够证明一个对象不会被方法外部访问,并且这个对象可以被拆散,那么程序真正执行的时候将可能不去创建这个对象,而改为直接创建它的若干个被这个方法使用的成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,很大机会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可以为后续进一步的优化手段创建条件。标量替换可以视作栈上分配的一种特例,实现更简单(不用考虑整个对象完整结构的分配),但对逃逸程度的要求更高,它不允许对象逃逸出方法范围内。
· 同步消除(Synchronization Elimination):线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那么这个变量的读写肯定就不会有竞争,对这个变量实施的同步措施也就可以安全地消除掉。
关于逃逸分析的研究论文早在1999年就已经发表,但直到JDK 6,HotSpot才开始支持初步的逃逸分析,而且到现在这项优化技术尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是逃逸分析的计算成本非常高,甚至不能保证逃逸分析带来的性能收益会高于它的消耗。如果要百分之百准确地判断一个对象是否会逃逸,需要进行一系列复杂的数据流敏感的过程间分析,才能确定程序各个分支执行时对此对象的影响。前面介绍即时编译、提前编译优劣势时提到了过程间分析这种大压力的分析算法正是即时编译的弱项。可以试想一下,如果逃逸分析完毕后发现几乎找不到几个不逃逸的对象,那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成分析。
C和C++语言里面原生就支持了栈上分配(不使用new操作符即可),而C#也支持值类型,可以很自然地做到标量替换(但并不会对引用类型做这种优化)。在灵活运用栈内存方面,确实是Java的一个弱项。在现在仍处于实验阶段的Valhalla项目里,设计了新的inline关键字用于定义Java的内联类型,目的是实现与C#中值类型相对标的功能。有了这个标识与约束,以后逃逸分析做起来就会简单很多。
下面笔者将通过一系列Java伪代码的变化过程来模拟逃逸分析是如何工作的,向读者展示逃逸分析能够实现的效果。初始代码如下所示:
// 完全未优化的代码
public int
test(int x) { int xx
= x + 2; Point p
= new Point(xx, 42); return
p.getX();}
此处笔者省略了Point类的代码,这就是一个包含x和y坐标的POJO类型,读者应该很容易想象它的样子。
第一步,将Point的构造函数和getX()方法进行内联优化:
// 步骤1:构造函数内联后的样子
public int test(i
nt x) { int xx = x +
2; Point p = poi
nt_memory_alloc(); // 在
堆中分配P对象的示意方法 p.x = xx;
// P
oint构造函数被内联后的样子 p.y = 42 return p.x;
// P
oint::getX()被内联后的样子}
第二步,经过逃逸分析,发现在整个test()方法的范围内Point对象实例不会发生任何程度的逃逸,这样可以对它进行标量替换优化,把其内部的x和y直接置换出来,分解为test()方法内的局部变量,从而避免Point对象实例被实际创建,优化后的结果如下所示:
// 步骤2:标量替换后的样子
public int test
(int x) { int xx = x
+ 2; int px = xx
; int py = 42
return px;}
第三步,通过数据流分析,发现py的值其实对方法不会造成任何影响,那就可以放心地去做无效代码消除得到最终优化结果,如下所示:
// 步骤3:做无效代码消除后的样子
public int test(in
t x) { return x + 2;}
从测试结果来看,实施逃逸分析后的程序在MicroBenchmarks中往往能得到不错的成绩,但是在实际的应用程序中,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即时编译的收益)下降,所以曾经在很长的一段时间里,即使是服务端编译器,也默认不开启逃逸分析,甚至在某些版本(如JDK 6 Update 18)中还曾经完全禁止了这项优化,一直到JDK 7时这项优化才成为服务端编译器默认开启的选项。如果有需要,或者确认对程序运行有益,用户也可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析,开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:+EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:+PrintEliminateAllocations查看标量的替换情况。
尽管目前逃逸分析技术仍在发展之中,未完全成熟,但它是即时编译器优化技术的一个重要前进方向,在日后的Java虚拟机中,逃逸分析技术肯定会支撑起一系列更实用、有效的优化技术
例如:
public static StringBuffer craeteStringBuffer (String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffer sb 是一个方法内部变量,上述代码中直接将sb返回,这样这个 StringBuffer 有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
上述代码如果想要 StringBuffer sb 不逃出方法,可以这样写:
public static String createStringBuffer (String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
不直接返回 StringBuffer,那么 StringBuffer 将不会逃逸出方法。
参数设置:
-
在 JDK 6u23版本之后,HotSpot 中默认就已经开启了逃逸分析
-
如果使用较早版本,可以通过 -XX"+DoEscapeAnalysis 显式开启
开发中使用局部变量,就不要在方法外定义。
使用逃逸分析,编译器可以对代码做优化:
-
栈上分配 :将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配
-
同步省略 :如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步
-
分离对象或标量替换 :有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而存储在 CPU 寄存器
JIT 编译器在编译期间根据逃逸分析的结果,发现如果一个对象并没有逃逸出方法的话,就可能被优化成栈上分配。分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。这样就无需进行垃圾回收了。
常见栈上分配的场景:成员变量赋值、方法返回值、实例引用传递
代码优化之同步省略(消除)
-
线程同步的代价是相当高的,同步的后果是降低并发性和性能
-
在动态编译同步块的时候,JIT 编译器可以借助逃逸分析来判断同步块所使用的锁对象是否能够被一个线程访问而没有被发布到其他线程。如果没有,那么 JIT 编译器在编译这个同步块的时候就会取消对这个代码的同步。这样就能大大提高并发性和性能。这个取消同步的过程就叫做同步省略,也叫锁消除。
public void keep () {
Object keeper = new Object();
synchronized (keeper) {
System.out.println(keeper);
}
}
如上代码,代码中对 keeper 这个对象进行加锁,但是 keeper 对象的生命周期只在 keep() 方法中,并不会被其他线程所访问到,所以在 JIT编译阶段就会被优化掉。优化成:
public void keep () {
Object keeper = new Object();
System.out.println(keeper);
}
代码优化之标量替换
标量 (Scalar)是指一个无法再分解成更小的数据的数据。Java 中的原始数据类型就是标量。
相对的,那些的还可以分解的数据叫做 聚合量 (Aggregate),Java 中的对象就是聚合量,因为其还可以分解成其他聚合量和标量。
在 JIT 阶段,通过逃逸分析确定该对象不会被外部访问,并且对象可以被进一步分解时,JVM不会创建该对象,而会将该对象成员变量分解若干个被这个方法使用的成员变量所代替。这些代替的成员变量在栈帧或寄存器上分配空间。这个过程就是 标量替换 。
通过 -XX:+EliminateAllocations 可以开启标量替换, -XX:+PrintEliminateAllocations 查看标量替换情况。
public static void main (String[] args) {
alloc();
}
private static void alloc () {
Point point = new Point( 1 , 2 );
System.out.println( "point.x=" +point.x+ "; point.y=" +point.y);
}
class Point {
private int x;
private int y;
}
以上代码中,point 对象并没有逃逸出 alloc() 方法,并且 point 对象是可以拆解成标量的。那么,JIT 就不会直接创建 Point 对象,而是直接使用两个标量 int x ,int y 来替代 Point 对象。
private static void alloc () {
int x = 1 ;
int y = 2 ;
System.out.println( "point.x=" +x+ "; point.y=" +y);
}
代码优化之栈上分配
我们通过 JVM 内存分配可以知道 JAVA 中的对象都是在堆上进行分配,当对象没有被引用的时候,需要依靠 GC 进行回收内存,如果对象数量较多的时候,会给 GC 带来较大压力,也间接影响了应用的性能。为了减少临时对象在堆内分配的数量,JVM 通过逃逸分析确定该对象不会被外部访问。那就通过标量替换将该对象分解在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
总结:
关于逃逸分析的论文在1999年就已经发表了,但直到JDK 1.6才有实现,而且这项技术到如今也并不是十分成熟的。
其根本原因就是无法保证逃逸分析的性能消耗一定能高于他的消耗。虽然经过逃逸分析可以做标量替换、栈上分配、和锁消除。但是逃逸分析自身也是需要进行一系列复杂的分析的,这其实也是一个相对耗时的过程。
一个极端的例子,就是经过逃逸分析之后,发现没有一个对象是不逃逸的。那这个逃逸分析的过程就白白浪费掉了。
虽然这项技术并不十分成熟,但是他也是即时编译器优化技术中一个十分重要的手段。
2.java栈
如何看栈空间总体大小 NMT
栈与线程同时创建 -Xss 来设置每个线程的堆栈大小
不必连续,线程独享,不需要进行GC。当线程调用一个方法时,虚拟机就会压入一个新的栈帧到该线程的Java栈中。
看《深入理解Java虚拟机:JVM高级特性与最佳实践》8.2 运行时栈帧
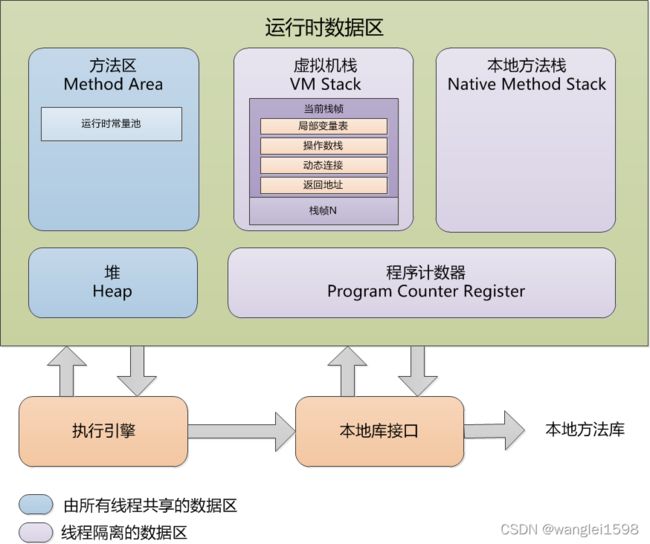
每当启动给一个线程时,Java虚拟机会为它分配一个Java栈。Java栈由许多栈帧组成,一个栈帧包含一个Java方法调用的状态。当线程调用一个Java方法时,虚拟机压入一个新的栈帧到该线程的Java栈中,当该方法返回时,这个栈帧就从Java栈中弹出。Java栈存储线程中Java方法调用的状态--包括局部变量、参数、返回值以及运算的中间结果等。Java虚拟机没有寄存器,其指令集使用Java栈来存储中间数据。这样设计的原因是为了保持Java虚拟机的指令集尽量紧凑,同时也便于Java虚拟机在只有很少通用寄存器的平台上实现。另外,基于栈的体系结构,也有助于运行时某些虚拟机实现的动态编译器和即时编译器的代码优化。 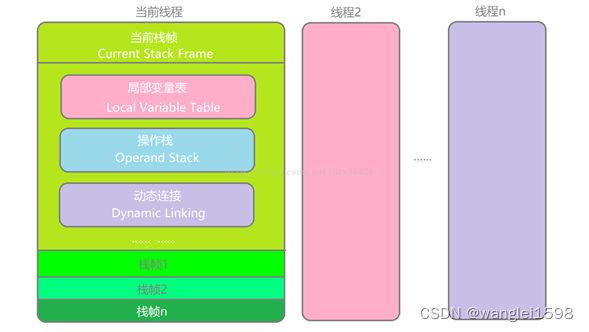
栈帧
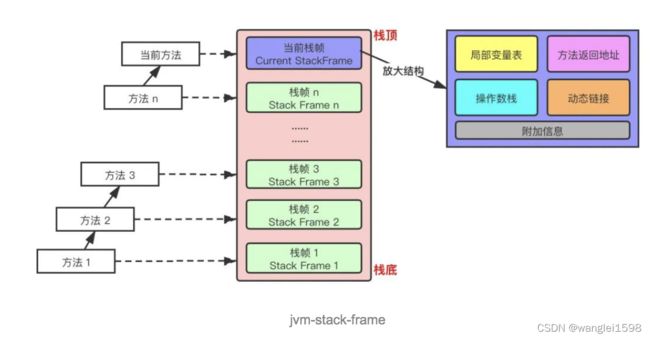
栈帧由局部变量区、操作数栈和帧数据区组成。当虚拟机调用一个Java方法时,它从对应类的类型信息中得到此方法的局部变量区和操作数栈的大小,并根据此分配栈帧内存,然后压入Java栈中。
每个**栈帧(Stack Frame)**中存储着:
-
局部变量表(Local Variables)
-
操作数栈(Operand Stack)(或称为表达式栈)
-
动态链接(Dynamic Linking):指向运行时常量池的方法引用
-
方法返回地址(Return Address):方法正常退出或异常退出的地址
-
一些附加信息
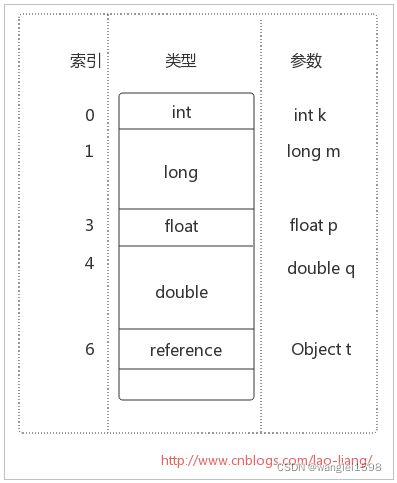
1、局部变量区
局部变量区被组织为以字长为单位、从0开始计数的数组。字节码指令通过从0开始的索引使用其中的数据。类型为int, float, reference和returnAddress的值在数组中占据一项,而类型为byte, short和char的值在存入数组前都被转换为int值,也占据一项。但类型为long和double的值在数组中却占据连续的两项。
-
局部变量表也被称为局部变量数组或者本地变量表
-
是一组变量值存储空间, 主要用于存储方法参数和定义在方法体内的局部变量 ,包括编译器可知的各种 Java 虚拟机 基本数据类型 (boolean、byte、char、short、int、float、long、double)、 对象引用 (reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此相关的位置)和 returnAddress 类型(指向了一条字节码指令的地址,已被异常表取代)
-
由于局部变量表是建立在线程的栈上,是线程的私有数据,因此 不存在数据安全问题
-
局部变量表所需要的容量大小是编译期确定下来的 ,并保存在方法的 Code 属性的 maximum local variables 数据项中。在方法运行期间是不会改变局部变量表的大小的
-
方法嵌套调用的次数由栈的大小决定。一般来说, 栈越大,方法嵌套调用次数越多 。对一个函数而言,它的参数和局部变量越多,使得局部变量表膨胀,它的栈帧就越大,以满足方法调用所需传递的信息增大的需求。进而函数调用就会占用更多的栈空间,导致其嵌套调用次数就会减少。
-
局部变量表中的变量只在当前方法调用中有效 。在方法执行时,虚拟机通过使用局部变量表完成参数值到参数变量列表的传递过程。当方法调用结束后,随着方法栈帧的销毁,局部变量表也会随之销毁。
-
参数值的存放总是在局部变量数组的 index0 开始,到数组长度 -1 的索引结束
槽 Slot
-
局部变量表最基本的存储单元是Slot(变量槽)
-
在局部变量表中,32位以内的类型只占用一个Slot(包括returnAddress类型),64位的类型(long和double)占用两个连续的 Slot
-
byte、short、char 在存储前被转换为int,boolean也被转换为int,0 表示 false,非 0 表示 true
-
long 和 double 则占据两个 Slot
-
JVM 会为局部变量表中的每一个 Slot 都分配一个访问索引,通过这个索引即可成功访问到局部变量表中指定的局部变量值,索引值的范围从 0 开始到局部变量表最大的 Slot 数量
-
当一个实例方法被调用的时候,它的方法参数和方法体内部定义的局部变量将会 按照顺序被复制 到局部变量表中的每一个 Slot 上
-
如果需要访问局部变量表中一个64bit的局部变量值时,只需要使用前一个索引即可 。(比如:访问 long 或double 类型变量,不允许采用任何方式单独访问其中的某一个 Slot)
-
如果当前帧是由构造方法或实例方法创建的,那么该对象引用 this 将会存放在 index 为 0 的 Slot 处,其余的参数按照参数表顺序继续排列(这里就引出一个问题:静态方法中为什么不可以引用 this,就是因为this 变量不存在于当前方法的局部变量表中)
-
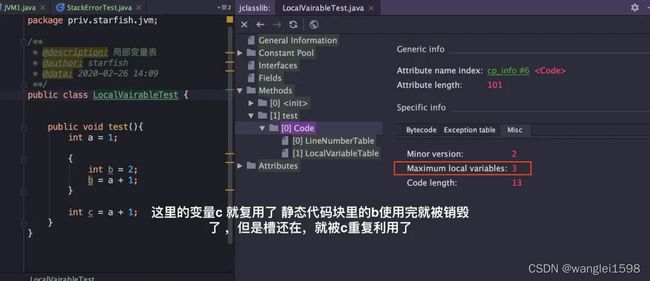
栈帧中的局部变量表中的槽位是可以重用的 ,如果一个局部变量过了其作用域,那么在其作用域之后申明的新的局部变量就很有可能会复用过期局部变量的槽位,从而 达到节省资源的目的 。(下图中,this、a、b、c 理论上应该有 4 个变量,c 复用了 b 的槽)
-
在栈帧中,与性能调优关系最为密切的就是局部变量表。在方法执行时,虚拟机使用局部变量表完成方法的传递
-
局部变量表中的变量也是重要的垃圾回收根节点,只要被局部变量表中直接或间接引用的对象都不会被回收
2 操作数栈
和局部变量区一样,操作数栈也是被组织成一个以字长为单位的数组。它通过标准的栈操作访问--压栈和出栈。由于程序计数器无法被程序指令直接访问,Java虚拟机的指令是从操作数栈中取得操作数,所以它的运行方式是基于栈而不是基于寄存器。虚拟机把操作数栈作为它的工作区,因为大多数指令都要从这里弹出数据,执行运算,然后把结果压回操作数栈。
-
每个独立的栈帧中除了包含局部变量表之外,还包含一个 后进先出 (Last-In-First-Out)的操作数栈,也可以称为 表达式栈 (Expression Stack)
-
操作数栈,在方法执行过程中,根据字节码指令,往操作数栈中写入数据或提取数据,即入栈(push)、出栈(pop)
-
某些字节码指令将值压入操作数栈,其余的字节码指令将操作数取出栈。使用它们后再把结果压入栈。比如,执行复制、交换、求和等操作
概述
-
操作数栈, 主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间
-
操作数栈就是 JVM 执行引擎的一个工作区,当一个方法刚开始执行的时候,一个新的栈帧也会随之被创建出来, 此时这个方法的操作数栈是空的
-
每一个操作数栈都会拥有一个明确的栈深度用于存储数值,其所需的最大深度在编译期就定义好了,保存在方法的 Code 属性的 max_stack 数据项中
-
栈中的任何一个元素都可以是任意的 Java 数据类型
-
32bit 的类型占用一个栈单位深度
-
64bit 的类型占用两个栈单位深度
-
操作数栈并非采用访问索引的方式来进行数据访问的,而是只能通过标准的入栈和出栈操作来完成一次数据访问
-
如果被调用的方法带有返回值的话,其返回值将会被压入当前栈帧的操作数栈中 ,并更新PC寄存器中下一条需要执行的字节码指令
-
操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,这由编译器在编译期间进行验证,同时在类加载过程中的类检验阶段的数据流分析阶段要再次验证
-
另外,我们说 Java虚拟机的解释引擎是基于栈的执行引擎 ,其中的栈指的就是操作数栈
栈顶缓存(Top-of-stack-Cashing)
HotSpot 的执行引擎采用的并非是基于寄存器的架构,但这并不代表 HotSpot VM 的实现并没有间接利用到寄存器资源。寄存器是物理 CPU 中的组成部分之一,它同时也是 CPU 中非常重要的高速存储资源。一般来说,寄存器的读/写速度非常迅速,甚至可以比内存的读/写速度快上几十倍不止,不过寄存器资源却非常有限,不同平台下的CPU 寄存器数量是不同和不规律的。寄存器主要用于缓存本地机器指令、数值和下一条需要被执行的指令地址等数据。
基于栈式架构的虚拟机所使用的零地址指令更加紧凑,但完成一项操作的时候必然需要使用更多的入栈和出栈指令,这同时也就意味着将需要更多的指令分派(instruction dispatch)次数和内存读/写次数。由于操作数是存储在内存中的,因此频繁的执行内存读/写操作必然会影响执行速度。为了解决这个问题,HotSpot JVM设计者们提出了栈顶缓存技术,将栈顶元素全部缓存在物理 CPU 的寄存器中,以此降低对内存的读/写次数,提升执行引擎的执行效率
3.动态链接(指向运行时常量池的方法引用)
-
每一个栈帧内部都包含一个指向运行时常量池中该栈帧所属方法的引用 。包含这个引用的目的就是为了支持当前方法的代码能够实现动态链接(Dynamic Linking)。
-
在 Java 源文件被编译到字节码文件中时,所有的变量和方法引用都作为 符号引用 (Symbolic Reference)保存在 Class 文件的常量池中。比如:描述一个方法调用了另外的其他方法时,就是通过常量池中指向方法的符号引用来表示的,那么 动态链接的作用就是为了将这些符号引用转换为调用方法的直接引用
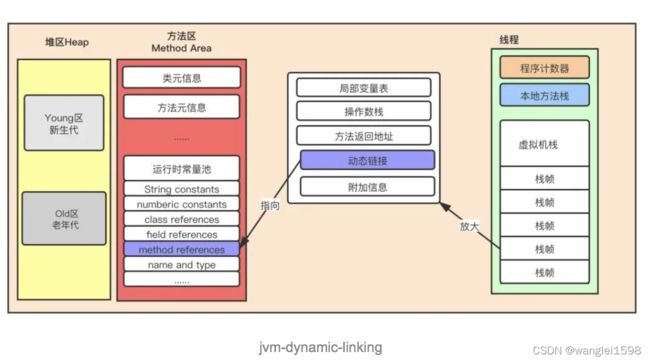
jvm-dynamic-linking
JVM 是如何执行方法调用的
方法调用不同于方法执行,方法调用阶段的唯一任务就是确定被调用方法的版本(即调用哪一个方法),暂时还不涉及方法内部的具体运行过程。Class 文件的编译过程中不包括传统编译器中的连接步骤,一切方法调用在 Class文件里面存储的都是 符号引用 ,而不是方法在实际运行时内存布局中的入口地址( 直接引用 )。也就是需要在类加载阶段,甚至到运行期才能确定目标方法的直接引用。
【这一块内容,除了方法调用,还包括解析、分派(静态分派、动态分派、单分派与多分派),这里先不介绍,后续再挖】
在 JVM 中,将符号引用转换为调用方法的直接引用与方法的绑定机制有关
-
静态链接:当一个字节码文件被装载进 JVM 内部时,如果被调用的 目标方法在编译期可知 ,且运行期保持不变时。这种情况下将调用方法的符号引用转换为直接引用的过程称之为静态链接
-
动态链接:如果被调用的方法在编译期无法被确定下来,也就是说,只能在程序运行期将调用方法的符号引用转换为直接引用,由于这种引用转换过程具备动态性,因此也就被称之为动态链接
对应的方法的绑定机制为:早期绑定(Early Binding)和晚期绑定(Late Binding)。 绑定是一个字段、方法或者类在符号引用被替换为直接引用的过程,这仅仅发生一次 。
-
早期绑定: 早期绑定就是指被调用的目标方法如果在编译期可知,且运行期保持不变时 ,即可将这个方法与所属的类型进行绑定,这样一来,由于明确了被调用的目标方法究竟是哪一个,因此也就可以使用静态链接的方式将符号引用转换为直接引用。
-
晚期绑定:如果被调用的方法在编译器无法被确定下来,只能够在程序运行期根据实际的类型绑定相关的方法,这种绑定方式就被称为晚期绑定。
虚方法和非虚方法
-
如果方法在编译器就确定了具体的调用版本,这个版本在运行时是不可变的。这样的方法称为非虚方法,比如静态方法、私有方法、final方法、实例构造器、父类方法都是非虚方法
-
其他方法称为虚方法
虚方法表
在面向对象编程中,会频繁的使用到动态分派,如果每次动态分派都要重新在类的方法元数据中搜索合适的目标有可能会影响到执行效率。为了提高性能,JVM 采用在类的方法区建立一个虚方法表(virtual method table),使用索引表来代替查找。非虚方法不会出现在表中。
每个类中都有一个虚方法表,表中存放着各个方法的实际入口。
虚方法表会在类加载的连接阶段被创建并开始初始化,类的变量初始值准备完成之后,JVM 会把该类的方法表也初始化完毕。
4. 方法返回地址(return address)
用来存放调用该方法的 PC 寄存器的值。
一个方法的结束,有两种方式
-
正常执行完成
-
出现未处理的异常,非正常退出
无论通过哪种方式退出,在方法退出后都返回到该方法被调用的位置。方法正常退出时,调用者的 PC 计数器的值作为返回地址,即调用该方法的指令的下一条指令的地址。而通过异常退出的,返回地址是要通过异常表来确定的,栈帧中一般不会保存这部分信息。
当一个方法开始执行后,只有两种方式可以退出这个方法:
-
执行引擎遇到任意一个方法返回的字节码指令,会有返回值传递给上层的方法调用者,简称 正常完成出口一个方法的正常调用完成之后究竟需要使用哪一个返回指令还需要根据方法返回值的实际数据类型而定在字节码指令中,返回指令包含 ireturn(当返回值是boolean、byte、char、short和int类型时使用)、lreturn、freturn、dreturn以及areturn,另外还有一个 return 指令供声明为 void 的方法、实例初始化方法、类和接口的初始化方法使用。
-
在方法执行的过程中遇到了异常,并且这个异常没有在方法内进行处理,也就是只要在本方法的异常表中没有搜索到匹配的异常处理器,就会导致方法退出。简称 异常完成出口方法执行过程中抛出异常时的异常处理,存储在一个异常处理表,方便在发生异常的时候找到处理异常的代码。
本质上, 方法的退出就是当前栈帧出栈的过程 。此时,需要恢复上层方法的局部变量表、操作数栈、将返回值压入调用者栈帧的操作数栈、设置PC寄存器值等,让调用者方法继续执行下去。
正常完成出口和异常完成出口的区别在于: 通过异常完成出口退出的不会给他的上层调用者产生任何的返回值
5. 附加信息
栈帧中还允许携带与 Java 虚拟机实现相关的一些附加信息。例如,对程序调试提供支持的信息,但这些信息取决于具体的虚拟机实现。
3.程序计数器
线程独享,不需要GC,永远不会OOM。当前线程所执行的字节码的行号指示器
对于一个运行中的Java程序而言,每一个线程都有它的程序计数器。程序计数器也叫PC寄存器。程序计数器既能持有一个本地指针,也能持有一个returnAddress。当线程执行某个Java方法时,程序计数器的值总是下一条被执行指令的地址。这里的地址可以是一个本地指针,也可以是方法字节码中相对该方法起始指令的偏移量。如果该线程正在执行一个本地方法,那么此时程序计数器的值是“undefined”。
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在Java虚拟机的概念模型里[插图],字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
-
它是一块很小的内存空间,几乎可以忽略不计。也是运行速度最快的存储区域
-
在 JVM 规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程的生命周期一致
-
任何时间一个线程都只有一个方法在执行,也就是所谓的 当前方法 。如果当前线程正在执行的是 Java 方法,程序计数器记录的是 JVM 字节码指令地址,如果是执行 natice 方法,则是未指定值(undefined)
-
它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成
-
字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令
-
它是唯一一个在 JVM 规范中没有规定任何 OutOfMemoryError 情况的区域
4.本地方法栈
-Xoss 设置本地方法栈大小
类似于java栈,不需要GC
所谓本地方法就是一个 java 调用非 java 代码的接口,该方法并非 Java 实现的,可能由 C 或 Python等其他语言实现的, Java 通过 JNI 来调用本地方法, 而本地方法是以库文件的形式存放的(在 WINDOWS 平台上是 DLL 文件形式,在 UNIX 机器上是 SO 文件形式)。
本地方法接口
Java本地接口,也叫JNI(Java Native Interface),是为可移植性准备的。本地方法接口允许本地方法完成以下工作:
-
传递或返回数据
-
操作实例变量
-
操作类变量或调用类方法
-
操作数组
-
对堆的对象加锁
-
装载新的类
-
抛出异常
-
捕获本地方法调用Java方法抛出的异常
-
捕获虚拟机抛出的异步异常
-
指示垃圾收集器某个对象不再需要
4.1 本地方法接口
简单的讲,一个 Native Method 就是一个 Java 调用非 Java 代码的接口。我们知道的 Unsafe 类就有很多本地方法。
为什么要使用本地方法(Native Method)?
Java 使用起来非常方便,然而有些层次的任务用 Java 实现起来也不容易,或者我们对程序的效率很在意时,问题就来了
-
与 Java 环境外交互:有时 Java 应用需要与 Java 外面的环境交互,这就是本地方法存在的原因。
-
与操作系统交互:JVM 支持 Java 语言本身和运行时库,但是有时仍需要依赖一些底层系统的支持。通过本地方法,我们可以实现用 Java 与实现了 jre 的底层系统交互, JVM 的一些部分就是 C 语言写的。
-
Sun's Java:Sun的解释器就是C实现的,这使得它能像一些普通的C一样与外部交互。jre大部分都是用 Java 实现的,它也通过一些本地方法与外界交互。比如,类 java.lang.Thread 的 setPriority() 的方法是用Java 实现的,但它实现调用的是该类的本地方法 setPrioruty() ,该方法是C实现的,并被植入 JVM 内部。
4.2 本地方法栈(Native Method Stack)
-
Java 虚拟机栈用于管理 Java 方法的调用,而本地方法栈用于管理本地方法的调用
-
本地方法栈也是线程私有的
-
允许线程固定或者可动态扩展的内存大小
-
如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java 虚拟机将会抛出一个 StackOverflowError 异常
-
如果本地方法栈可以动态扩展,并且在尝试扩展的时候无法申请到足够的内存,或者在创建新的线程时没有足够的内存去创建对应的本地方法栈,那么 Java虚拟机将会抛出一个 OutofMemoryError 异常
-
本地方法是使用C语言实现的
-
它的具体做法是 Mative Method Stack 中登记native方法,在 Execution Engine 执行时加载本地方法库当某个线程调用一个本地方法时,它就进入了一个全新的并且不再受虚拟机限制的世界。它和虚拟机拥有同样的权限。
-
本地方法可以通过本地方法接口来访问虚拟机内部的运行时数据区,它甚至可以直接使用本地处理器中的寄存器,直接从本地内存的堆中分配任意数量的内存
-
并不是所有 JVM 都支持本地方法。因为 Java 虚拟机规范并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等。如果 JVM 产品不打算支持 native 方法,也可以无需实现本地方法栈
-
在 Hotspot JVM 中,直接将本地方栈和虚拟机栈合二为一
栈是运行时的单位,而堆是存储的单位 。栈解决程序的运行问题,即程序如何执行,或者说如何处理数据。堆解决的是数据存储的问题,即数据怎么放、放在哪。
5.非堆内存
默认大小是16MB,最大为64MB,通过-XX:PermSize 设置初始大小 -XX:MaxPermSize 最大值,按需分配
不必是连续的空间。
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
当Java虚拟机需要加载定义的一个新class,但是在持久代中没有足够的空间就会抛出‘Java.Lang.OutOfMemoryError: PermGen Space’异常。默认分配给持久代的大小在server模式下是64MB ,在client模式下是32MB 。这就有两个原因可能会引起持久代内存溢出问题的发生。
在Java虚拟机中,关于被装载的类型信息存储在一个方法区的内存中。当虚拟机装载某个类型时,它使用类装载器定位相应的class文件,然后读入这个class文件并将它传输到虚拟机中,接着虚拟机提取其中的类型信息,并将这些信息存储到方法区。方法区也可以被垃圾回收器收集,因为虚拟机允许通过用户定义的类装载器来动态扩展Java程序。
方法区中存放了以下信息:
-
这个类型的全限定名(如全限定名java.lang.Object)
-
这个类型的直接超类的全限定名
-
这个类型是类类型还是接口类型
-
这个类型的访问修饰符(public, abstract, final的某个子集)
-
任何直接超接口的全限定名的有序列表
-
该类型的常量池(一个有序集合,包括直接常量[string, integer和floating point常量]和对其它类型、字段和方法的符号引用)
-
字段信息(字段名、类型、修饰符)
-
方法信息(方法名、返回类型、参数数量和类型、修饰符)
-
除了常量以外的所有类(静态)变量
-
指向ClassLoader类的引用(每个类型被装载时,虚拟机必须跟踪它是由启动类装载器还是由用户自定义类装载器装载的)
-
指向Class类的引用(对于每一个被装载的类型,虚拟机相应地为它创建一个java.lang.Class类的实例。比如你有一个到java.lang.Integer类的对象的引用,那么只需要调用Integer对象引用的getClass()方法,就可以得到表示java.lang.Integer类的Class对象)
运行时常量池(Java 7开始就放到了堆里)
运行时常量池(Runtime Constant Pool)是方法区的一部分,理解运行时常量池的话,我们先来说说字节码文件(Class 文件)中的常量池(常量池表)
常量池
一个有效的字节码文件中除了包含类的版本信息、字段、方法以及接口等描述信息外,还包含一项信息那就是常量池表(Constant Pool Table),包含各种字面量和对类型、域和方法的符号引用。
为什么需要常量池?
一个 java 源文件中的类、接口,编译后产生一个字节码文件。而 Java 中的字节码需要数据支持,通常这种数据会很大以至于不能直接存到字节码里,换另一种方式,可以存到常量池,这个字节码包含了指向常量池的引用。在动态链接的时候用到的就是运行时常量池。
如下,我们通过jclasslib 查看一个只有 Main 方法的简单类,字节码中的 #2 指向的就是 Constant Pool
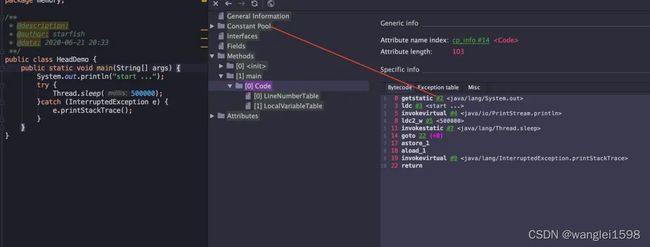
常量池可以看作是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等类型。
运行时常量池
-
在加载类和结构到虚拟机后,就会创建对应的运行时常量池
-
常量池表(Constant Pool Table)是 Class 文件的一部分,用于存储编译期生成的各种字面量和符号引用, 这部分内容将在类加载后存放到方法区的运行时常量池中
-
JVM 为每个已加载的类型(类或接口)都维护一个常量池。池中的数据项像数组项一样,是通过索引访问的
-
运行时常量池中包含各种不同的常量,包括编译器就已经明确的数值字面量,也包括到运行期解析后才能够获得的方法或字段引用。此时不再是常量池中的符号地址了,这里换为真实地址
-
运行时常量池,相对于 Class 文件常量池的另一个重要特征是: 动态性 ,Java 语言并不要求常量一定只有编译期间才能产生,运行期间也可以将新的常量放入池中,String 类的 intern() 方法就是这样的
-
当创建类或接口的运行时常量池时,如果构造运行时常量池所需的内存空间超过了方法区所能提供的最大值,则 JVM 会抛出 OutOfMemoryError 异常。
java 8。PermGen空间 被移除了,取而代之的是Metaspace ( JEP 122 )。也不能算是取而代之。
MetaSpace存放在本地内存中。原因是永久代经常内存不够用,或者发生内存泄漏。
MetaSpace(元空间):元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。
元数据区回垃圾回收,会内存泄露
元空间 只存类型信息。 其他移走了。
方法区,Java8 之后的变化(并不是简单的替代):
-
移除了永久代(PermGen),替换为元空间(Metaspace);
-
永久代中的 class metadata 转移到了 native memory(本地内存,而不是虚拟机);
-
永久代中的 interned Strings 和 class static variables 转移到了 Java heap;
-
永久代参数 (PermSize MaxPermSize) -> 元空间参数(MetaspaceSize MaxMetaspaceSize)
元数据区
-
元数据区大小可以使用参数 -XX:MetaspaceSize 和 -XX:MaxMetaspaceSize 指定,替代上述原有的两个参数
-
默认值依赖于平台。Windows 下, -XX:MetaspaceSize 是 21M, -XX:MaxMetaspacaSize 的值是 -1,即没有限制
-
与永久代不同,如果不指定大小,默认情况下,虚拟机会耗尽所有的可用系统内存。如果元数据发生溢出,虚拟机一样会抛出异常 OutOfMemoryError:Metaspace
-
-XX:MetaspaceSize :设置初始的元空间大小。对于一个 64 位的服务器端 JVM 来说,其默认的 -XX:MetaspaceSize 的值为20.75MB,这就是初始的高水位线,一旦触及这个水位线,Full GC 将会被触发并卸载没用的类(即这些类对应的类加载器不再存活),然后这个高水位线将会重置,新的高水位线的值取决于 GC 后释放了多少元空间。如果释放的空间不足,那么在不超过 MaxMetaspaceSize 时,适当提高该值。如果释放空间过多,则适当降低该值
-
如果初始化的高水位线设置过低,上述高水位线调整情况会发生很多次,通过垃圾回收的日志可观察到 Full GC 多次调用。为了避免频繁 GC,建议将 -XX:MetaspaceSize 设置为一个相对较高的值。
· -XX:MaxMetaspaceSize:设置元空间最大值,默认是-1,即不限制,或者说只受限于本地内存大小。
· -XX:MetaspaceSize:指定元空间的初始空间大小,以字节为单位,达到该值就会触发垃圾收集进行类型卸载,同时收集器会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过-XX:MaxMetaspaceSize(如果设置了的话)的情况下,适当提高该值。
· -XX:MinMetaspaceFreeRatio:作用是在垃圾收集之后控制最小的元空间剩余容量的百分比,可减少因为元空间不足导致的垃圾收集的频率。类似的还有-XX:Max-MetaspaceFreeRatio,用于控制最大的元空间剩余容量的百分比。
-XX:MaxMetaspaceSize=N
这个参数用于限制Metaspace增长的上限,防止因为某些情况导致Metaspace无限的使用本地内存,影响到其他程序。在本机上该参数的默认值为4294967295B(大约4096MB)。
-XX:MinMetaspaceFreeRatio=N
当进行过Metaspace GC之后,会计算当前Metaspace的空闲空间比,如果空闲比小于这个参数,那么虚拟机将增长Metaspace的大小。在本机该参数的默认值为40,也就是40%。设置该参数可以控制Metaspace的增长的速度,太小的值会导致Metaspace增长的缓慢,Metaspace的使用逐渐趋于饱和,可能会影响之后类的加载。而太大的值会导致Metaspace增长的过快,浪费内存。
-XX:MaxMetasaceFreeRatio=N
当进行过Metaspace GC之后, 会计算当前Metaspace的空闲空间比,如果空闲比大于这个参数,那么虚拟机会释放Metaspace的部分空间。在本机该参数的默认值为70,也就是70%。
-XX:MaxMetaspaceExpansion=N
Metaspace增长时的最大幅度。在本机上该参数的默认值为5452592B(大约为5MB)。
-XX:MinMetaspaceExpansion=N
Metaspace增长时的最小幅度。在本机上该参数的默认值为340784B(大约330KB为)
方法区在 JDK6、7、8中的演进细节
只有 HotSpot 才有永久代的概念
jdk1.6及之前
有永久代,静态变量存放在永久代上
|
jdk1.7
|
有永久代,但已经逐步“去永久代”,字符串常量池、静态变量移除,保存在堆中
|
|
jdk1.8及之后
|
取消永久代,类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池、静态变量仍在堆中
|
移除永久代原因
JEP 122: Remove the Permanent Generation

-
为永久代设置空间大小是很难确定的。在某些场景下,如果动态加载类过多,容易产生 Perm 区的 OOM。如果某个实际 Web 工程中,因为功能点比较多,在运行过程中,要不断动态加载很多类,经常出现 OOM。而元空间和永久代最大的区别在于,元空间不在虚拟机中,而是使用本地内存,所以默认情况下,元空间的大小仅受本地内存限制
-
对永久代进行调优较困难
方法区的垃圾回收
方法区的垃圾收集主要回收两部分内容: 常量池中废弃的常量和不再使用的类型 。
先来说说方法区内常量池之中主要存放的两大类常量:字面量和符号引用。字面量比较接近 java 语言层次的常量概念,如文本字符串、被声明为 final 的常量值等。而符号引用则属于编译原理方面的概念,包括下面三类常量:
-
类和接口的全限定名
-
字段的名称和描述符
-
方法的名称和描述符
HotSpot 虚拟机对常量池的回收策略是很明确的,只要常量池中的常量没有被任何地方引用,就可以被回收
判定一个类型是否属于“不再被使用的类”,需要 同时 满足三个条件:
-
该类所有的实例都已经被回收,也就是 Java 堆中不存在该类及其任何派生子类的实例
-
加载该类的类加载器已经被回收,这个条件除非是经过精心设计的可替换类加载器的场景,如 OSGi、JSP 的重加载等,否则 通常很难达成
-
该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
Java 虚拟机被允许堆满足上述三个条件的无用类进行回收,这里说的仅仅是“被允许”,而并不是和对象一样,不使用了就必然会回收。是否对类进行回收,HotSpot 虚拟机提供了 -Xnoclassgc 参数进行控制,还可以使用 -verbose:class 以及 -XX:+TraceClassLoading 、 -XX:+TraceClassUnLoading 查看类加载和卸载信息。
在大量使用反射、动态代理、CGLib 等 ByteCode 框架、动态生成 JSP 以及 OSGi 这类频繁自定义 ClassLoader 的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
方法区回收
方法区垃圾收集的“性价比”通常也是比较低的:在Java堆中,尤其是在新生代中,对常规应用进行一次垃圾收集通常可以回收70%至99%的内存空间,相比之下,方法区回收囿于苛刻的判定条件,其区域垃圾收集的回收成果往往远低于此。
虚拟机规范中不要求方法区一定要实现垃圾回收,而且方法区中进行垃圾回收的效率也确实比较低,但是HotSpot对方法区也是进行回收的,主要回收的是废弃常量和无用的类两部分。判断一个常量是否“废弃常量”比较简单,只要当前系统中没有任何一处引用该常量就好了,但是要判定一个类是否“无用的类”条件就要苛刻很多,类需要同时满足以下三个条件:
-
该类所有实例都已经被回收,也就是说Java堆中不存在该类的任何实例
-
加载该类的ClassLoader已经被回收
-
该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
Java虚拟机被允许对满足上述三个条件的无用类进行回收,这里说的仅仅是“被允许”,而并不是和对象一样,没有引用了就必然会回收。关于是否要对类型进行回收,HotSpot虚拟机提供了-Xnoclassgc参数进行控制,还可以使用-verbose:class以及-XX:+TraceClass-Loading、-XX:+TraceClassUnLoading查看类加载和卸载信息,其中-verbose:class和-XX:+TraceClassLoading可以在Product版的虚拟机中使用,-XX:+TraceClassUnLoading参数需要FastDebug版的虚拟机支持。
在大量使用反射、动态代理、CGLib等ByteCode框架、动态生成JSP以及OSGi这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载功能,以保证方法区不会溢出。
6.非堆内存
线程共享区域,Java 8 中,本地内存,也是我们通常说的 堆外内存
top、ps命令返回内存大小指标和java jstat之间的关系: Java应用Top命令RES内存占用高分析 - 简书 top的RSS和committed有关。
java 内存 commited used https://zhanjindong.com/2016/03/02/jvm-memory-tunning-notes
JVM运行时内存
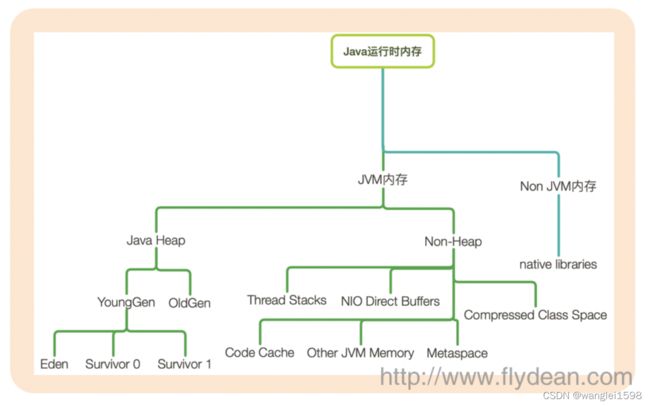
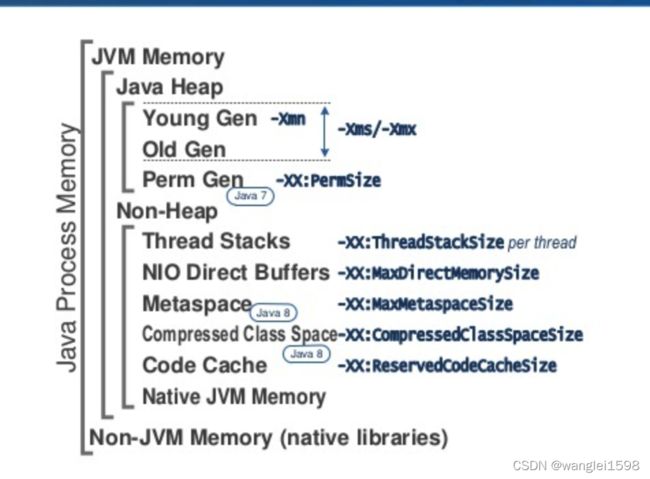
java运行时内存可以分为JVM内存和非JVM内存。
JVM内存又可以分为堆内存和非堆内存。
堆内存大家都很熟悉了,YoungGen中的Eden,Survivor和OldGen。
非堆内存中存储的有thread Stack,Code Cache, NIO Direct Buffers,Metaspace等。
Code Cache
聊聊jvm的Code Cache - 云+社区 - 腾讯云 存放JIT编译的机器码
Compressed ClassCache
Java 内存分区之什么是 CCS区 Compressed Class Space 类压缩空间_请叫我大师兄_的博客-CSDN博客_ccsc java
直接内存区:
怎么分析使用情况
聊聊jvm的-XX:MaxDirectMemorySize - 云+社区 - 腾讯云
NIO使用。
Direct Buffer: Direct Buffer - 知乎 这是一块在Java堆外分配的,可以在Java程序中访问的内存。
DirectBufferPool 和 MappedBufferPool :
聊聊openjdk的BufferPoolMXBean - 云+社区 - 腾讯云
java - What is Mapped Buffer Pool / Direct Buffer Pool and how to increase their size? - Stack Overflow
如果说,我们使用普通的ByteBuffer,那么这个ByteBuffer就会在Java堆内,被JVM所管理:
ByteBuffer buf = ByteBuffer.allocate(1024);
当 buf 被JVM所管理时,它会在变成垃圾以后,自动被回收,这个不需要我们来操心。但它有个问题,后面会讲到,在执行GC的时候,JVM实际上会做一些整理内存的工作,也就说buf这个对象在内存中的实际地址是会发生变化的。有些时候,ByteBuffer里都是大量的字节,这些字节在JVM GC整理内存时就显得很笨重,把它们在内存中拷来拷去显然不是一个好主意。
那这时候,我们就会想能不能给我一块内存,可以脱离JVM的管理呢?在这样的背景下,就有了DirectBuffer。先看一下用法:
ByteBuffer buf = ByteBuffer.allocateDirect(1024);
DirectBuffer优缺点
堆外内存的申请与普通的Java对象是有巨大的差别的。在以后的课程里,大家会发现,Java对象在Java堆里申请内存的时候,实际上是比malloc要快的,所以DirectBuffer的创建效率往往是比Heap Buffer差的。
但是,如果进行网络读写或者文件读写的时候,DirectBuffer就会比较快了
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现,所以我们放到这里一起讲解。
在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
显然,本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,则肯定还是会受到本机总内存(包括物理内存、SWAP分区或者分页文件)大小以及处理器寻址空间的限制,一般服务器管理员配置虚拟机参数时,会根据实际内存去设置-Xmx等参数信息,但经常忽略掉直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现OutOfMemoryError异常。
直接内存(Direct Memory)的容量大小可通过-XX:MaxDirectMemorySize参数来指定,如果不去指定,则 默认与Java堆最大值(由-Xmx指定)一致,代码清单2-10越过了DirectByteBuffer类直接通过反射获取Unsafe实例进行内存分配(Unsafe类的getUnsafe()方法指定只有引导类加载器才会返回实例,体现了设计者希望只有虚拟机标准类库里面的类才能使用Unsafe的功能,在JDK 10时才将Unsafe的部分功能通过VarHandle开放给外部使用),因为虽然使用DirectByteBuffer分配内存也会抛出内存溢出异常,但它抛出异常时并没有真正向操作系统申请分配内存,而是通过计算得知内存无法分配就会在代码里手动抛出溢出异常,真正申请分配内存的方法是Unsafe::allocateMemory()。
由直接内存导致的内存溢出,一个明显的特征是在Heap Dump文件中不会看见有什么明显的异常情况,如果读者发现内存溢出之后产生的Dump文件很小,而程序中又直接或间接使用了DirectMemory(典型的间接使用就是NIO),那就可以考虑重点检查一下直接内存方面的原因了。
NativeMemoryTracing
JVM NativeMemoryTracking ;jcmd process_id VM.native_memory;Native memory tracking is not enabled_himal-himal的博客-CSDN博客
doc
Native Memory Tracking
Native Memory Tracking diagnostic-tools
NMT Memory Categories
Memory footprint of the JVM
Native Memory Tracking in JVM
NMT Memory Categories
List of native memory tracking memory categories used by NMT.
Table 2-1 describes native memory categories used by NMT. These categories may change with a release.
Table 2-1 Native Memory Tracking Memory Categories
|
Category
|
Description
|
|
Java Heap
|
The heap where your objects live
|
|
Class
|
Class meta data
|
|
Code
|
Generated code
|
|
GC
|
Data use by the GC, such as card table
|
|
Compiler
|
Memory tracking used by the compiler when generating code
|
|
Symbol
|
Symbols
|
|
Memory Tracking
|
Memory used by NMT.
|
|
Pooled Free Chunks
|
Memory used by chunks in the arena chunk pool
|
|
Shared space for classes
|
Memory mapped to class data sharing archive
|
|
Thread
|
Memory used by threads, including thread data structure, resource area, handle area, and so on.
|
|
Thread stack
|
Thread stack. It is marked as committed memory, but it might not be completely committed by the OS.
|
|
Internal
|
Memory that does not fit the previous categories, such as the memory used by the command line parser, JVMTI, properties, and so on.
|
|
Unknown
|
When the memory category cannot be determined.
Arena: When the arena is used as a stack or value object
Virtual Memory: When the type information has not yet arrived
|
Memory footprint of the JVM
Memory footprint of the JVM
The JVM can be a complex beast. Thankfully, much of that complexity is under the hood, and we as application developers and deployers often don’t have to worry about it too much. With the rise of container-based deployment strategies, one area of complexity that needs some attention is the JVM’s memory footprint.
Two kinds of memory
The JVM divides its memory into two main categories: heap memory and non-heap memory. Heap memory is the part with which people are typically the most familiar. It’s where objects that are created by the application are stored. They remain there until they are no longer referenced and are garbage collected. Typically, the amount of heap that an application is using will fluctuate as a function of the current load.
The JVM’s non-heap memory is divided into several different areas. We can use the HotSpot VM’s native memory tracking (NMT) to examine its memory usage across these areas. Note that, while NMT does not track all native memory usage (it does not track third party native code memory allocations , for example), it is sufficient for a large class of typical Spring applications. NMT can be used by starting the application with -XX:NativeMemoryTracking=summary and then using jcmd VM.native_memory summary to display the memory usage summary.
Let’s illustrate the use of NMT by looking at an application, in this case our old friend, Petclinic. The following pie chart shows the JVM’s memory usage as reported by NMT (minus its own overhead) when starting Petclinic with a 48MB max heap ( -Xmx48M ):
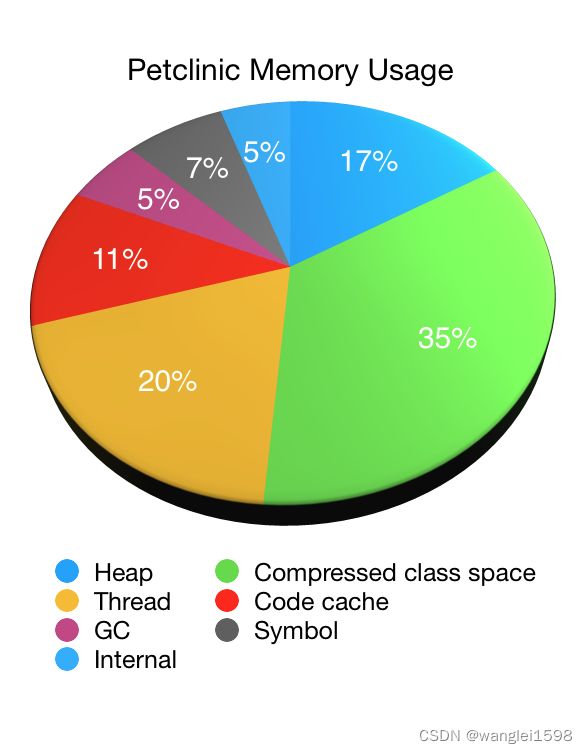
As you can see non-heap memory accounts for the vast majority of the JVM’s memory usage with the heap memory accounting for only one sixth of the total. In this case it was roughly 44MB (with 33MB of that being used immediately after garbage collection). The non-heap memory usage was 223MB in total.
Native Memory areas
-
Compressed class space : used to store information about the classes that have been loaded. Constrained by MaxMetaspaceSize . A function of the number of classes that have been loaded.
-
Thread : memory used by threads in the JVM. A function of the number of threads that are running.
-
Code cache : memory used by the JIT to store its output. A function of the number of classes that have been loaded. Constrained by ReservedCodeCacheSize . Can be reduced by tuning the JIT to, for example, disable tiered compilation.
-
GC : stores data used by the GC. Varies depending on which garbage collector is being used.
-
Symbol : stores symbols such as field names, method signatures, and interned strings. Excessive symbol memory usage can be an indicator that Strings have been interned too aggressively.
-
Internal : stores other internal data that does not fit into any of the other areas.
Differences
Compared to heap memory, non-heap memory is less likely to vary under load. Once an application has loaded all of the classes that it will use and the JIT is fully warmed up, things will settle into a steady state. To see a reduction in compressed class space usage, the class loader that loaded the classes needs to be garbage collected. This was more common in the past when applications were deployed to servlet containers or app servers – the application’s class loader would be garbage collected when the application was undeployed – but rarely happens with modern approaches to application deployment.
Java编译器们
看深入理解Java虚拟机:JVM高级特性与最佳实践
在Java技术下谈“编译期”而没有具体上下文语境的话,其实是一句很含糊的表述,因为它可能是指一个前端编译器(叫“编译器的前端”更准确一些)把*.java文件转变成*.class文件的过程;也可能是指Java虚拟机的即时编译器(常称JIT编译器,Just In Time Compiler)运行期把字节码转变成本地机器码的过程;还可能是指使用静态的提前编译器(常称AOT编译器,Ahead Of Time Compiler)直接把程序编译成与目标机器指令集相关的二进制代码的过程。下面笔者列举了这3类编译过程里一些比较有代表性的编译器产品:
· 前端编译器(把*.java文件转变成*.class文件的过程):JDK的Javac、Eclipse JDT中的增量式编译器(ECJ)。
· 即时编译器(JIT编译器,Just In Time Compiler):HotSpot虚拟机的C1、C2编译器,Graal编译器。
· 提前编译器(常称AOT编译器,Ahead Of Time Compiler):JDK的Jaotc、GNU Compiler for the Java(GCJ)、Excelsior JET。
1.前端编译器
从Javac代码的总体结构来看,编译过程大致可以分为1个准备过程和3个处理过程,它们分别如下所示。
1)准备过程:初始化插入式注解处理器。
2)解析与填充符号表过程,包括:
· 词法、语法分析。将源代码的字符流转变为标记集合,构造出抽象语法树。
· 填充符号表。产生符号地址和符号信息。
3)插入式注解处理器的注解处理过程:插入式注解处理器的执行阶段,本章的实战部分会设计一个插入式注解处理器来影响Javac的编译行为。
4)分析与字节码生成过程,包括:
· 标注检查。对语法的静态信息进行检查。
· 数据流及控制流分析。对程序动态运行过程进行检查。
· 解语法糖。将简化代码编写的语法糖还原为原有的形式。
· 字节码生成。将前面各个步骤所生成的信息转化成字节码。
上述3个处理过程里,执行插入式注解时又可能会产生新的符号,如果有新的符号产生,就必须转回到之前的解析、填充符号表的过程中重新处理这些新符号,从总体来看,三者之间的关系与交互顺序如图10-4所示。

以把上述处理过程对应到代码中,Javac编译动作的入口是com.sun.tools.javac.main.JavaCompiler类,上述3个过程的代码逻辑集中在这个类的compile()和compile2()方法里,其中主体代码如图10-5所示,整个编译过程主要的处理由图中标注的8个方法来完成。
注解处理器
看《深入理解JVM字节码》第8章
JDK 5之后,Java语言提供了对注解(Annotations)的支持,注解在设计上原本是与普通的Java代码一样,都只会在程序运行期间发挥作用的。但在JDK 6中又提出并通过了JSR-269提案,该提案设计了一组被称为“插入式注解处理器”的标准API,可以提前至编译期对代码中的特定注解进行处理,从而影响到前端编译器的工作过程。我们可以把插入式注解处理器看作是一组编译器的插件,当这些插件工作时,允许读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行过修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环过程称为一个轮次(Round),这也就对应着图10-4的那个回环过程。
有了编译器注解处理的标准API后,程序员的代码才有可能干涉编译器的行为,由于语法树中的任意元素,甚至包括代码注释都可以在插件中被访问到,所以通过插入式注解处理器实现的插件在功能上有很大的发挥空间。只要有足够的创意,程序员能使用插入式注解处理器来实现许多原本只能在编码中由人工完成的事情。譬如Java著名的编码效率工具Lombok,它可以通过注解来实现自动产生getter/setter方法、进行空置检查、生成受查异常表、产生equals()和hashCode()方法,等等,帮助开发人员消除Java的冗长代码,这些都是依赖插入式注解处理器来实现的
HotSpot VM有三个主要组件:JVM运行时,JIT编译器以及内存管理器。
2.JIT(Just-In-Time)即时编译
看深入理解Java虚拟机:JVM高级特性与最佳实践 11.2
看Java性能优化实践 10
JVM JIT optimization techniques - Advanced Web Machinery
JIT编译器是Java虚拟机的执行机制的性能保证。由于Java的字节码是解释执行的效率很低。在Java发展历史中,有两套解释执行器:古老的字节码解释器、现在被广泛使用的模板解释器。字节码解释器在执行时通过纯软件代码模拟字节码的执行,效率非常低。相比之下,模板解释器将每一条字节码和一个模板函数相关联,而模板函数中直接产生这条字节码执行时的机器码,从而提升了解释器的性能。但即便如此,仅凭借解释器,虚拟机的执行效率依然很低,为了解决这个问题,虚拟机平台支持一种叫作及时编译的技术。
及时编译的目的是避免函数被解释执行,而是将整个函数体编译成机器码,每次函数执行时,只执行编译后的机器码即可,这种方式可以使执行效率大幅度提升。
Java虚拟机有3种执行模式,分别是 解释执行、 混合模式和 编译执行,默认情况下处于混合模式中。可以使用java -version查看。
在 混合模式中,部分函数会被解释执行,部分函数可能被编译执行。虚拟机决定函数是否需要编译执行的依据是判断该函数是否为热点代码。如果函数的调用频率很高,被反复调用,那么就会被认为是热点,就会被编译执行。-Xmixed
解释执行模式表示全部代码均解释执行,不做任何JIT编译,可以使用参数-Xint来开启解释执行模式。 java -Xint version查看。 -Xint禁止编译器运作。
编译执行模式和解释执行模式相反,对于所有函数,无论是否是热点代码,都会被编译执行,使用参数-Xcomp可以设置为编译模式。java -Xcomp version查看。
解释器与JIT编译器
解释器
解释器(interpreter),是一种计算机程序,能够把高级编程语言 一行一行 解释 运行 。
划重点:一行一行运行,说白了就是效率低
解释器每次运行程序时都要一行一行先转成另一种语言再作运行,因此解释器的程序运行速度比较缓慢。它不会一次把整段代码翻译出来,而是每翻译一行程序叙述就立刻运行,然后再翻译下一行,再运行,如此不停地进行下去。
JIT编译器
即时编译(Just-in-time compilation)是一种提高程序运行效率的方法。通常,程序在执行前全部被翻译为机器码。
Java最初的版本没有JIT编译器,完全靠解释器来运行的,但是为了提升性能便引入了JIT编译器。
重点说明:当我们说编译的时候基本上指的是上面的从源码到字节码的编译过程,而不是指JIT编译器。
JIT编译器工作阶段基本是java程序运行期的最后阶段了,它的工作是将加载的字节码转换为机器码。当使用JIT编译器时,硬件可以执行JIT编译器生成的机器码,而不是让JVM 重复解释执行 相同的字节码导致相对冗长的翻译过程。这样可以带来执行速度的性能提升。
尽管并不是所有的Java虚拟机都采用解释器与编译器并存的运行架构,但目前主流的商用Java虚拟机,譬如HotSpot、OpenJ9等,内部都同时包含解释器与编译器,解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即运行。当程序启动后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更高的执行效率。当程序运行环境中内存资源限制较大,可以使用解释执行节约内存(如部分嵌入式系统中和大部分的JavaCard应用中就只有解释器的存在),反之可以使用编译执行来提升效率。同时,解释器还可以作为编译器激进优化时后备的“逃生门”(如果情况允许,HotSpot虚拟机中也会采用不进行激进优化的客户端编译器充当“逃生门”的角色),让编译器根据概率选择一些不能保证所有情况都正确,但大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,如加载了新类以后,类型继承结构出现变化、出现“罕见陷阱”(Uncommon Trap)时可以通过逆优化(Deoptimization)退回到解释状态继续执行,因此在整个Java虚拟机执行架构里,解释器与编译器经常是相辅相成地配合工作,其交互关系如图11-1所示。
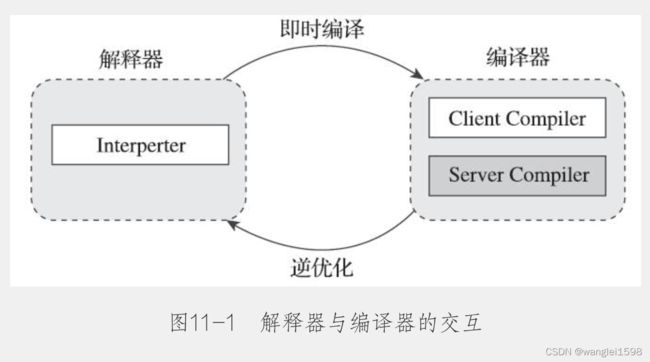
HotSpot虚拟机中内置了两个(或三个)即时编译器,其中有两个编译器存在已久,分别被称为“客户端编译器”(Client Compiler)和“服务端编译器”(Server Compiler),或者简称为C1编译器和C2编译器(部分资料和JDK源码中C2也叫Opto编译器),第三个是在JDK 10时才出现的、长期目标是代替C2的Graal编译器。Graal编译器目前还处于实验状态,本章将安排出专门的小节对它讲解与实战,在本节里,我们将重点关注传统的C1、C2编译器的工作过程。
在分层编译(Tiered Compilation)的工作模式出现以前,HotSpot虚拟机通常是采用解释器与其中一个编译器直接搭配的方式工作,程序使用哪个编译器,只取决于虚拟机运行的模式,HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用“-client”或“-server”参数去强制指定虚拟机运行在客户端模式还是服务端模式。
无论采用的编译器是客户端编译器还是服务端编译器,解释器与编译器搭配使用的方式在虚拟机中被称为“混合模式”(Mixed Mode),用户也可以使用参数“-Xint”强制虚拟机运行于“解释模式”(Interpreted Mode),这时候编译器完全不介入工作,全部代码都使用解释方式执行。另外,也可以使用参数“-Xcomp”强制虚拟机运行于“编译模式”(Compiled Mode),这时候将优先采用编译方式执行程序,但是解释器仍然要在编译无法进行的情况下介入执行过程。可以通过虚拟机的“-version”命令的输出结果显示出这三种模式,内容如代码清单11-1所示,请读者注意黑体字部分。

分层编译
由于即时编译器编译本地代码需要占用程序运行时间,通常要编译出优化程度越高的代码,所花费的时间便会越长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行阶段的速度也有所影响。为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot虚拟机在编译子系统中加入了分层编译的功能,分层编译的概念其实很早就已经提出,但直到JDK 6时期才被初步实现,后来一直处于改进阶段,最终在JDK 7的服务端模式虚拟机中作为默认编译策略被开启。分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包括:
· 第0层。程序纯解释执行,并且解释器不开启性能监控功能(Profiling)。
· 第1层。使用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开启性能监控功能。
· 第2层。仍然使用客户端编译器执行,仅开启方法及回边次数统计等有限的性能监控功能。
· 第3层。仍然使用客户端编译器执行,开启全部性能监控,除了第2层的统计信息外,还会收集如分支跳转、虚方法调用版本等全部的统计信息。
· 第4层。使用服务端编译器将字节码编译为本地代码,相比起客户端编译器,服务端编译器会启用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化。
以上层次并不是固定不变的,根据不同的运行参数和版本,虚拟机可以调整分层的数量。各层次编译之间的交互、转换关系如图11-2所示。
实施分层编译后,解释器、客户端编译器和服务端编译器就会同时工作,热点代码都可能会被多次编译,用客户端编译器获取更高的编译速度,用服务端编译器来获取更好的编译质量,在解释执行的时候也无须额外承担收集性能监控信息的任务,而在服务端编译器采用高复杂度的优化算法时,客户端编译器可先采用简单优化来为它争取更多的编译时间。
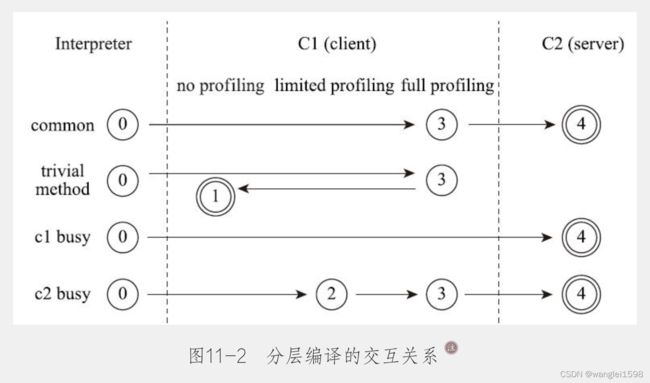
多级编译器:-XX:TieredCompilation打开多级编译器 默认打开
HotSpot虚拟机中内置了两个 即时编译器 ,分别称为Client Compiler和Server Compiler,或者简称为C1编译器和C2编译器,默认采用解释器与其中一个编译器直接配合的方式工作,程序使用哪个编译器,取决于虚拟机运行的模式,用户也可以使用“-client”或“-server”参数去强制指定虚拟机运行在Client模式或Server模式。C1编译器的特点是编译速度快,C2编译器的特点是会做更多的编译时优化,因此编译时间会长于C1,但是编译后的代码质量会高于C1。为了使C1和C2在编译速度和执行效率之间取得平衡,虚拟机支持一种叫做多级编译的策略。多级编译将编译层次分为以下5级。
0级(解释执行):采用解释执行,不采集性能监控数据。
1级(简单的C1编译):采用C1编译器,进行简单的快速编译,根据需要采集性能数据。
2级(有限的C1编译):采用C1编译器,进行更多的优化编译,可能会根据第1级采集的性能统计数据进一步优化编译代码。
3级(完全C1编译):完全使用C1编译器的所有功能,会采集性能数据进行优化。
4级(C2编译):完全使用C2编译器进行编译,进行完全的优化。
剖析制导优化
HotSpot将运行程序的配偶洗数据存储在成为方法数据对象(method data object,MOD)的结构中。
字节码解释器和C1编译器使用MDO记录JIT编译器在确定要进行什么优化时使用的信息。MOD存储诸如调用的方法、选取的分支以及在调用点中观察到的类型信息。
系统会维护一些计数器(counter),用来记录所剖析属性的”热度”(hotness),其中的值会在剖析过程中衰减。这样可以确保方法只有在到达编译队列的头部而且仍有足够的热度时才会被编译。
什么时候触发即时编译?
-
被多次调用的方法
-
被多次执行的循环体
上面两个条件又叫做 热点代码(Hot Spot Code) ,至于如何界定这个多次或者热点,Java提供了两种策略:
热点探测: 虚拟机定期检查线程的栈顶,如果某个方法经常出现在栈顶 则推断为热点代码
计数器: 统计方法的调用次数,维护一个计数器列表
基于计数器来推断热点代码是HotSpot虚拟机采用的策略
JIT 编译阈值:当函数调用次数超过这个阈值是,就会被认为是热点代码,进行即时编译。在Client模式下,这个阈值为1500次,在Server模式下,这个阈值是10000次。使用参数-XX:CompileThreshold可以设置这个阈值
JIT过程也会消耗一些CPU,但貌似不会造成应用暂停
编译优化技术:


1.内联:选定某个被调用的方法(callee),将其内容复制到被调用处,即调用点中。
决定是否内联某个方法时会考虑几个因素,包括:
要内联的方法的字节码大小
要内联的方法在当前调用链中的深度
该方法的编译版本在代码缓存中已占用的空间量
相关开关:
-XX:+Inline开启方法内联
-XX:MaxInlineSize= 内联方法的最大值为这个
-XX:FreqInlineSize= 可以控制热点方法进行内联的体积上限。
-XX:InlineSmallCode= 如果最后一层编译在代码缓存中占用的空间已经超过这个值,不要内联方法。
-XX:MaxInlineLevel= 调用栈帧的深度不能超过这个值
2.循环展开
3.逃逸分析
逃逸分析的含义:
HopSpot可以执行基于作用域的分析,以确定某个方法内完成的工作在该方法的边界之外是否可见以及是否有副作用。这种逃逸分析技术可以用来确定在方法内分配的对象在该方法的作用域之外是否可见。
逃逸分析技术的应用:
应用一、标量替换(scalar replacement):逃逸分析技术证明一个已分配的对象不会套一处当前方法(被归类为NoEscape),虚拟机可以应用一种叫作标量替换的优化。对象中的字段会变成标量值,类型于他们是局部变量而非对象变量。然后,他们就可以被一个叫做寄存器分配器(register allocator)的HotSpot组件安排到CPU寄存器中。
如果没有足够的空闲寄存器,那么标量值就可以放到当前的栈帧上(这被称为栈溢出,stack pill)。
目的是减少对分配,减少垃圾收集的压力。
应用二、锁
锁消除(lock elision):移除不会逃逸的对象上的锁。
锁合并(lock coarsening):合并使用同一把锁的连续锁定区域。
嵌套锁(nested lock):检测重复获取同一把锁但是没有解锁的地方。
逃逸分析的限制:
默认情况下,超过64个元素的数组将无法从逃逸分析中收益。-XX:EliminateAllocationArraySizeLimtit=
4.锁消除和锁合并
5.单态分发
看看Java性能优化实践 10.6
6.内部函数
内部函数(intrinsic)指的是一个方法的高度优化的原生实现,他们是JVM预先知道的,而非由JIT子系统动态生成。它们用于性能关键的核心方法,其功能由操作系统或CPU架构的特定特性来支持。这使得它们和平台相关联,并且有些内部函数可能不是每个平台都支持。
JVM启动时,会在运行时对CPU进行探测,并建立一个可用处理器特性的列表。这意味着关于使用哪一种优化的决策可以推迟到运行时再做,而不必在代码编译时做。
7.栈上替换(on-stack replacement,OSR)
当在方法内包含热循环(hot loop)的代码,该方法调用的次数不足以触发编译,比如Java程序的main()方法。
HopSpot仍然可以使用一种叫作栈上替换的技术来优化这样的代码。这个技巧会计算解释器重向后跳转的循环分支数;当计数达到某个阈值时,这个解释的循环将被编译,执行将切换到这个编译的版本。
代码缓存(Code Cache):字节码被编译成机器码后,得到的结果需要在内存中保存,以便下次函数调用时可以直接使用。存放这些代码的内存区域成为代码缓存。一旦代码缓存空间被用完,虚拟机并不会像堆或者永久区那样暴力地直接抛出内存溢出错误,而是简单地停止JIT编译,并保持系统继续运行。系统停止JIT编译后,后续未编译的代码全部以解释方式运行,故系统同性能会受影响。代码缓存空间的清理工作也是在系统GC时完成的。代码缓存空间的大小可以使用参数-XX:ReservedCodeCacheSize指定。可以在Jconsole中看到Code Cache大小。
编译线程:
当方法(或循环)适合编译时,就会进入到编译队列。队列则由一个或多个后台线程处理。这是件好事,意味着 编译过程是异步的;这使得即便是代码正在编译的时候,程序也能持续执行。如果是用标准编译所编译的方法,那下次调用该方法时就会执行编译后的方法;如果是用OSR编译的循环,那下次循环迭代时就会执行编译后的代码。编译队列并不严格遵守先进先出的原则:调用计数次数多的方法有更高的优先级。所以,即便在程序开始执行并有大量代码需要编译时,这样的优先顺序仍然有助于确保最重要的代码优先编译。(这是为何PrintCompilation输出中的ID为乱序的另一个原因。)当使用client编译器时,JVM会开启一个编译线程;使用server编译器时,则会开启两个这样的线程。当启用分层编译时,JVM默认开启多个client和server线程,线程数依据一个略复杂的等式而定,包括目标平台CPU数取双对数之后的数值。表4-7中显示的值即为计算出的数值。
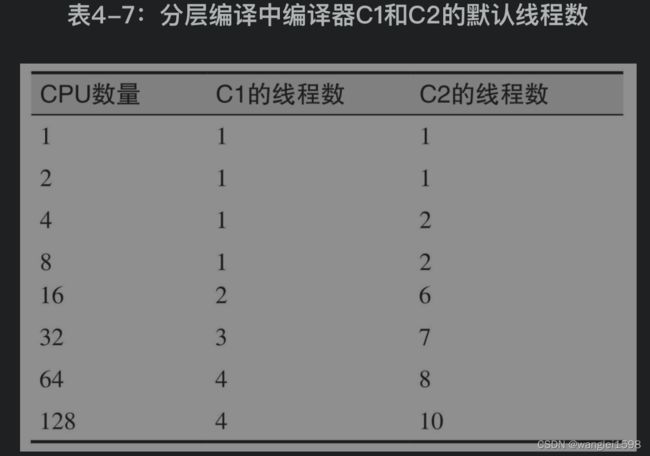
编译器的线程数(3种编译器都是如此)可通过-XX:CICompilerCount=N标志来设置(默认值参见前表)。这是JVM处理队列的线程总数;对分层编译来说,其中三分之一(至少一个)将用来处理client编译器队列,其余的线程(至少一个)用来处理server编译器队列。你何时需要考虑调整该参数值?如果程序运行在单CPU系统上,那么只有设置成单个编译器线程才可以得到些好处:对可用CPU受限的系统来说,在许多情况下只有减少争抢资源的线程数才有利于性能提升。但是,这种好处也仅限于初始的热身阶段;在此之后,已编译过的方法将不会再引起CPU竞争。当股票配比处理应用运行在单CPU机器上,并且编译器线程数限制为一时,初始计算会快大约10%(因为不用经常争抢CPU)。运行的轮次越多,初始时的整体收益就越小,直到所有热点方法都被编译之后,这种收益就消失了。使用分层编译时,线程数很容易超过系统限制,特别是有多个JVM同时运行的时候(每个都开启很多编译线程)。在这种情况下,减少线程数有助于提升整体的吞吐量(尽管代价可能是热身期会持续得更长)。与此类似,如果有额外可用的CPU周期,理论上程序将会受益——至少在热身期间——此时编译器线程数会增加。在实际工作中,这样的好处很难获得。进一步来说,如果有很多可用的CPU,那么在应用的整个执行过程中,你都可以去尝试那些能充分发挥可用CPU周期的方法(而不仅仅在开始时加快编译),这样会好得多。另外一个编译线程的设定参数是-XX:+BackgroundCompilation标志,默认值为true。这意味着,和参数所描述的一样,编译队列的处理是异步执行的。但这个参数也可以设置为false,在这种情况下,当一个方法适合编译,执行该方法的代码将一直等到它确实被编译之后才执行(而不是继续在解释器中执行)。用-Xbatch可以禁止后台编译。
JIT编译日志:
使用参数-XX:+PrintCompilation可以打印及时编译的日志(打印在STDOUT标准输出)。
-XX:+LogCompilation可以打印更多JIT的详细信息。需要先解锁(-XX:+UnlockDiagnosticVMOptions )才能用。这只是虚拟机输出一个包含XML标记的日志文件,该标记表示从字节码向原生代码转换过程中与队列和优化相关的信息。LogCompilation标志会很冗长,并声称数百MB的XML输出。
如果开启PrintCompilation,每次编译一个方法(或循环)时,JVM就会打印一行被编译的内容信息。输出的信息在不同的Java发布版之间会有所不同,这里的输出是Java 7中已经标准化的信息。绝大多数编译日志的行具有以下格式:

此处的时间戳timestamp是编译完成的时间(相对于JVM开始的时间0)。compilation id是内部的任务ID。通常这个数字只是简单地单调增长,不过在使用server编译器时(或者某个时刻编译器的线程数增加时),你有时会发现乱序的compilation id。这表明编译线程相对于其他线程快或者慢了,但不能就以此下结论,某个特定的编译任务因为某种原因变得特别慢了,因为这通常只是线程调度的缘故(尽管OSR编译比较慢,经常出现乱序)。attributes是一组5个字符长的串,表示代码编译的状态。如果给定的编译被赋予了特定属性,就会打印下面列表中所显示的字符,否则该属性就打印一个空格。因此,5字符属性串可以同时出现2个或多个字符。不同的属性如下所列。• %:编译为OSR。• s:方法是同步的。• ! :方法有异常处理器。• b:阻塞模式时发生的编译。• n:为封装本地方法所发生的编译。其中前3个可以自解释。阻塞标志在当前版本的Java中默认永远都不会打印,表明编译不会发生在后台(详情请参见4.5.1节“编译线程”)。最后,n属性表明JVM生成了一些编译代码以便于调用本地方法。
如果程序没有使用分层编译的方式运行,下一个字段tieredlevel就是空的。否则就会是数字,以表明所完成编译的级别(参见4.7节“分层编译级别”)。下面一个是被编译方法(或者是被OSR编译的包含循环的方法)的名字,打印格式为ClassName::method。接下来是编译后代码的大小(单位是字节)。这是Java字节码的大小,不是被编译代码的大小(所以很不幸,不能用来预估代码缓存的大小)。最后,在某些情况下,编译日志行的结尾会有一条信息,表明发生了某种逆优化,通常是“made not entrant”或“madezombie”。详情参见4.6节“逆优化”。
编译日志还会包括类似下面这行信息:

这行信息(包括文本文字COMPILE SKIPPED)表示编译给定的方法有错误。出现这个错可能有以下两种原因。代码缓存满了需用ReservedCodeCache标志增大代码缓存的大小。编译的同时加载类编译类的时候会发生修改。JVM之后会再次编译,你可以在之后的日志中看到方法被再次编译。在所有这些情况(除了代码缓存被填满)中,编译都可以再次尝试。如果不能,说明代码编译出了错。虽然通常是编译器的缺陷,但常用的解决方法是将代码重构得更简单,以使编译器能够处理。
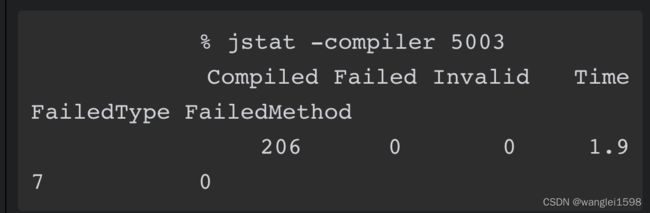
可以通过jstat 查看JIT编译器状态
-compiler标志提供了关于多少方法被编译的概要信息
可以用-printcompilation标志获取最近被编译的方法。jstat借助一个可选参数反复执行操作,你可以看到随时间变化有哪些方法被编译了。
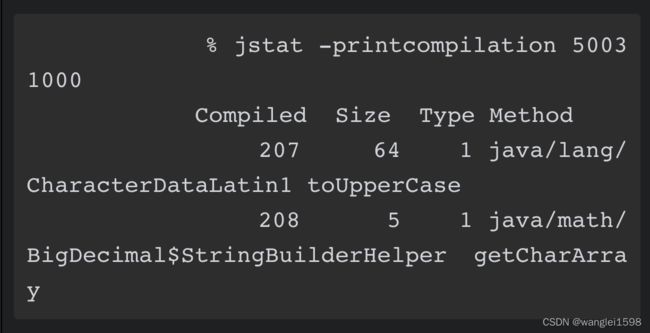
JITWatch
看Java性能优化实战 10.1
可以使用JITWatch工具查看即时编译情况 https://github.com/AdoptOpenJDK/jitwatch
JITWatch分析必须要开启:-XX:+LogCompilation -XX:+UnlockDiagnosticVMOptions
逆优化
有两种逆优化的情形:代码状态分别为“made not entrant”(代码被丢弃)和“made zombie”(产生僵尸代码)时。
代码缓存(Code Cache):存放JIT编译的代码。该区域还存储了属于虚拟机本身的其他原生代码,比如解释器的部分内容。
代码缓存在虚拟机启动时设置了一个固定的最大值。它不能超过这个限制,所以有可能被填满。如果被填满,就不能再进行JIT编译,并且未编译的代码只能在解释器中执行。这个对应用程序的性能产生影响,并可能导致它明显低于潜在的最大性能。
代码缓存被实现为一个堆,其中包含一个未分配区域和一个空闲链表(指向被释放的块)。当原生代码被删除时,该代码对应的块会被添加到空闲链表中。会有一个叫做清扫器(sweeper)的进程来负责回收这些块。
当要存储一个新的原生方法时,可以在空闲链表中搜索一个足够大的块来存储编译后的代码。如果没有找到,那么只要代码缓存有足够的空闲空间,就会从未分配的空间中创建一个新块。
在以下情况中,原生代码可以从代码缓存中删除:
1.它被取消了优化(基于某种假设进行了推测性优化,结果证明条件不成立);
2.它被替换为另一个编译版本(在分层编译情况下);
3.包含该方法的类被卸载了。
可以使用以下这个虚拟机开关来控制代码缓存的最大值:-XX:ReservedCodeCacheSize=
注意,在启用了分层编译之后,因为C1客户端编译器的编译阈值更低,所以将有更多方法大道与之。因此,会设置更大的默认值来容纳这些额外的编译方法。
3.AOT提前编译
机器码直接从源代码生成,与编译单元相对应的机器码可以直接以编译的形式获得,从而让代码具有直接的性能特征成为可能。
在AOT编译过程中,针对处理起得特定特性,将产生一个只与该处理器兼容的可执行文件。这种技术对于要求低延迟或极端性能的应用程序很有用。如果构建应用程序所用的硬件和它的运行环境完全相同,那么编译器可以利用所有可用的处理器进行优化。
安全点
要求所有线程处于安全点的活动:
1.GC STW事件
2.取消对一个方法的优化
3.创建堆转储
4.撤销偏向锁
5.重定义一个类(比如用于注入)
在编译后的代码中,JIT编译器会负责生成安全点检查代码;在HopSpot中,它会在循环里向后的分支中,以及在方法的返回处,生成安全检查代码。
这意味着,有时线程可能需要一定的时间才会走到安全点(比如,线程正在执行一个包含大量算数运算代码而没有任何方法调用的循环)。如果这个循环被展开了,那可能要相当长一段时间才会遇到安全点。
安全点多了,轮训检查的成本就高;安全点少了,线程等待较长时间才能到达安全点,这样已经到达安全点的线程就要等待其他线程到达安全点。编译器会尽量在二者之间取得平衡。
-XX:+PrintGCApplicationStoppedTime来查看程序在安全点所花费的时间,包括等待所有线程到达安全点的时间。结合-XX:+PrintSafepointStatistics可以了解更多关于安全点的信息。
打印安全点日志: JVM-安全点 - 简书
-XX:+PrintSafepointStatistics 打印安全点统计信息,
-XX:PrintSafepointStatisticsCount=n 设置打印安全点统计信息的次数;
排查安全点超时:
-XX:+SafepointTimeout和-XX:SafepointTimeoutDelay=<毫秒> 输出进入安全点超时的线程名。打印看安全点超时日志:

进入安全点超时有可能是因为在可数循环里,可数循环里默认是不放置安全点的。
HotSpot原本提供了-XX:+UseCountedLoopSafepoints参数去强制在可数循环中也放置安全点,不过这个参数在JDK 8下有Bug,有导致虚拟机崩溃的 风险。
排查安全点问题: Total time for which application threads were stopped
安全点导致停顿时间过长的排查:
由安全点导致长时间停顿有一个比较大的承担公共计算任务的离线HBase集群,运行在JDK 8上,使用G1收集器。每天都有大量的MapReduce或Spark离线分析任务对其进行访问,同时有很多其他在线集群Replication过来的数据写入,因为集群读写压力较大,而离线分析任务对延迟又不会特别敏感,所以将-XX:MaxGCPauseMillis参数设置到了500毫秒。不过运行一段时间后发现垃圾收集的停顿经常达到3秒以上,而且实际垃圾收集器进行回收的动作就只占其中的几百毫秒,现象如以下日志所示。
[Times: user=1.51 sys=0.67, real=0.14 secs]
2019-06-25T 12:12:43.376+0800: 3448319.277:
Total time for which application threads were stopped: 2.2645818 seconds
考虑到不是所有读者都了解计算机体系和操作系统原理,笔者先解释一下user、sys、real这三个时间的概念:
· user:进程执行用户态代码所耗费的处理器时间。
· sys:进程执行核心态代码所耗费的处理器时间。
· real:执行动作从开始到结束耗费的时钟时间。
请注意,前面两个是处理器时间,而最后一个是时钟时间,它们的区别是处理器时间代表的是线程占用处理器一个核心的耗时计数,而时钟时间就是现实世界中的时间计数。如果是单核单线程的场景下,这两者可以认为是等价的,但如果是多核环境下,同一个时钟时间内有多少处理器核心正在工作,就会有多少倍的处理器时间被消耗和记录下来。
在垃圾收集调优时,我们主要依据real时间为目标来优化程序,因为最终用户只关心发出请求到得到响应所花费的时间,也就是响应速度,而不太关心程序到底使用了多少个线程或者处理器来完成任务。
日志显示这次垃圾收集一共花费了0.14秒,但其中用户线程却足足停顿了有2.26秒,两者差距已经远远超出了正常的TTSP(Time To Safepoint)耗时的范畴。所以先加入参数-XX:+PrintSafepointStatistics和-XX:PrintSafepointStatisticsCount=1去查看安全点日志,具体如下所示:
vmop [threads: total initially_running wait_to_block]
65968.203: ForceAsyncSafepoint [931 1 2][time: spin block sync cleanup vmop] page_trap_count[2255 0 2255 11 0] 1
日志显示当前虚拟机的操作(VM Operation,VMOP)是等待所有用户线程进入到安全点,但是有两个线程特别慢,导致发生了很长时间的自旋等待。日志中的2255毫秒自旋(Spin)时间就是指由于部分线程已经走到了安全点,但还有一些特别慢的线程并没有到,所以垃圾收集线程无法开始工作,只能空转(自旋)等待。
解决问题的第一步是把这两个特别慢的线程给找出来,这个倒不困难,添加-XX:+SafepointTimeout和-XX:SafepointTimeoutDelay=2000两个参数,让虚拟机在等到线程进入安全点的时间超过2000毫秒时就认定为超时,这样就会输出导致问题的线程名称,得到的日志如下所示:
# SafepointSynchronize::begin: Timeout detected:
# SafepointSynchronize::begin: Timed out while s
pinning to reach a safepoint.# SafepointSynchronize::begin: Threads which did
not reach the safepoint:# "RpcServer.listener,port=24600" #32 daemon pri
o=5 os_prio=0 tid=0x00007f4c14b22840 nid=0xa621 runnable [0x0000000000000000]java.lang.Thread.State: RUNNABLE# SafepointSynchronize::begin: (End of list)
从错误日志中顺利得到了导致问题的线程名称为“RpcServer.listener,port=24600”。但是为什么它们会出问题呢?有什么因素可以阻止线程进入安全点?在第3章关于安全点的介绍中,我们已经知道安全点是以“是否具有让程序长时间执行的特征”为原则进行选定的,所以方法调用、循环跳转、异常跳转这些位置都可能会设置有安全点,但是HotSpot虚拟机为了避免安全点过多带来过重的负担,对循环还有一项优化措施,认为循环次数较少的话,执行时间应该也不会太长,所以使用int类型或范围更小的数据类型作为索引值的循环默认是不会被放置安全点的。这种循环被称为可数循环(Counted Loop),相对应地,使用long或者范围更大的数据类型作为索引值的循环就被称为不可数循环(Uncounted Loop),将会被放置安全点。通常情况下这个优化措施是可行的,但循环执行的时间不单单是由其次数决定,如果循环体单次执行就特别慢,那即使是可数循环也可能会耗费很多的时间。
HotSpot原本提供了-XX:+UseCountedLoopSafepoints参数去强制在可数循环中也放置安全点,不过这个参数在JDK 8下有Bug,有导致虚拟机崩溃的风险,所以就不得不找到RpcServer线程里面的缓慢代码来进行修改。最终查明导致这个问题是HBase中一个连接超时清理的函数,由于集群会有多个MapReduce或Spark任务进行访问,而每个任务又会同时起多个Mapper/Reducer/Executer,其每一个都会作为一个HBase的客户端,这就导致了同时连接的数量会非常多。更为关键的是,清理连接的索引值就是int类型,所以这是一个可数循环,HotSpot不会在循环中插入安全点。当垃圾收集发生时,如果RpcServer的Listener线程刚好执行到该函数里的可数循环时,则必须等待循环全部跑完才能进入安全点,此时其他线程也必须一起等着,所以从现象上看就是长时间的停顿。找到了问题,解决起来就非常简单了,把循环索引的数据类型从int改为long即可,但如果不具备安全点和垃圾收集的知识,这种问题是很难处理的。
也有可能会是偏向锁导致的: (干货篇) JVM stop the world - 知乎
做Profiling的时候可能会有安全点偏差:
1.所有的线程都必须到达某个安全点才能被采样。(采样会带来额外的开销)
2.样本只能是应用程序处于某个安全点的状态。 (会扭曲样本点的分布)
虚拟机字节码执行引擎
看深入理解Java虚拟机:JVM高级特性与最佳实践第8章
常见配置汇总
官网参数大全: java
通过命令查询全部参数和默认值和是否可以动态修改:java -XX:+PrintFlagsFinal -version
参数:
标准选项:
非标准选项 -X
非稳定选项 -XX
1. 空间设置。 新生代的大小一般设置为整个对空间的1/3到1/4。
堆
-Xms:初始堆大小 相当于-XX:InitialHeapSize
-Xmx:最大堆大小 相当于-XX:MaxHeapSize
-XX:NewSize=n:设置年轻代初始大小
-XX:MaxnewSize:表示新生代可被分配的内存的最大上限;当然这个值应该小于-Xmx的值
-Xmn:至于这个参数则是对 -XX:newSize、-XX:MaxnewSize两个参数的同时配置,也就是说如果通过-Xmn来配置新生代的内存大小,那么-XX:newSize = -XX:MaxnewSize = -Xmn
-XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值=eden/from=eden/to。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:+UsePSAdaptiveSurvivorSizePolicy 根据生成对象的速率,以及 Survivor 区的使用情况动态调整 Eden 区和 Survivor 区的比例
-XX:+NeverTenure and -XX:+AlwaysTenure 最后,我们介绍2个颇为少见的参数,对应2种极端的新生代GC情况.设置参数 -XX:+NeverTenure , 对象永远不会晋升到老年代.当我们确定不需要老年代时,可以这样设置。这样设置风险很大,并且会浪费至少一半的堆内存。相反设置参数 -XX:+AlwaysTenure, 表示没有幸存区,所有对象在第一次GC时,会晋升到老年代。
·-XX:MinHeapFreeRatio:设置堆空间的最小空闲比例,默认是40。当堆空间的空闲内存小于这个数值时,JVM便会扩展堆空间。
·-XX:MaxHeapFreeRatio:设置堆空间的最大空闲比例,默认是70。当堆空间的空闲内存大于这个数值时,JVM便会压缩堆空间,得到一个较小的堆。
当-Xms和-Xmx相等时,-XX:MinHeapFreeRatio和-XX:MaxHeapFreeRatio这两个参数是无效的。
栈
-Xss:每个线程的堆大小
方法区
-XX:PermSize=n:初始分配的持久化大小
-XX:MaxPermSize=n:设置持久代大小
元数据区 默认情况值为系统内存上限
-XX:MetaspaceSize:指定元数据区的初始大小
-XX:MaxMetaspaceSize:指定元数据区的最大可用值。
直接内存 默认值为最大堆空间。会进行垃圾回收,内存溢出会引起系统OOM。
-XX:MaxDirectMemorySize:最大可用直接内存
2.工作模式 有Server和Client两种工作模式。默认情况下会根据当前计算机系统环境自动选择运行模式。可以通过Java -version查看默认模式。与Client模式相比,Server模式的启动比较慢,因为Server模式会尝试收集更多的系统性能信息,使用更复杂的优化算法对程序进行优化。因此,当系统完全启动并进入运行稳定期后,Server模式的执行速度会远远快于Client模式。所以,对于后台长期运行的系统来说,使用-server参数启动对系统的整体性能可以有不晓得版主。但对于用户界面程序而言,运行时间不长,又追求启动速度,Client模式也是不错的选择。64位系统中虚拟机更倾向于使用server模式。
-client 使用Client模式
-server 使用Server模式
3.辅助信息
-XX:+PrintCommandLineFlags:打印传递给虚拟机的显式和隐式参数。
-XX:+PrintFlagsFinal 会打印所有的JVM参数 打印JVM所有参数列表的方法 java -XX:+PrintFlagsFinal -version_zhkchi的博客-CSDN博客_java printflagsfinal
-XX:+PrintVMOptions在程序运行时打印虚拟机接收到的命令行显示参数。
4.类加载
-verbose:class 跟踪类加载。
- XX:+TraceClassLoading 跟踪类的加载信息
-XX:+TraceClassUnloading 跟踪类的卸载信息
-Xlog:class+load=info 跟踪类的加载信息(Java9)
-Xlog:class+unload=info 跟踪类的卸载信息(Java9)
-XX:+PrintClassHistogram:控制台按下Ctrl-Break后打印类实例的柱状信息,与jmap -histo功能相同
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
5.gc日志和异常日志
-verbose[:class|gc|jni] 在输出设备上显示虚拟机运行信息
-verbose:gc 测量有多少时间和资源用于垃圾收集。
-XX:+DisableExplicitGC 禁用System.gc(),是它变成一个空函数。
-XX:+ExplicitGCInvokesConcurrent 使用并发方式处理显示GC。
-XX:+PrintGC:每次GC时打印相关信息
-XX:+PrintGCDetails:每次GC时打印详细信息
-XX:+UseGCLogFileRotation 实现GC日志轮转
-XX:+PrintGCTimeStamps:打印每次GC的时间( jvm启动直到垃圾收集发生所经历的时间)
-XX:+ PrintGCDateStamps : 打印每次GC的时间(人类读起来友好的时间 )
-Xlog:gc*: JAVA9 Java10打印日志
-Xloggc:文件名 指定日志文件位置 可以使用功能变量 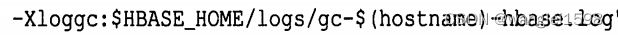
-XX:NumberOfGCLogFIles GC文件数
-XX:GCLogFIleSize GC文件大小
-XX:+PrintGCApplicationConcurrentTime 打印每次垃圾回收前,程序未中断的执行时间。 输出形式:Application time: 0.5291524 seconds
-XX:+PrintGCApplicationStoppedTime打印垃圾回收期间程序暂停的时间。 输出形式:Total time for which application threads were stopped: 0.0468229 seconds
-XX:PrintHeapAtGC:打印GC前后的堆信息 -XX:+PrintHeapAtGC参数使用了解_绅士jiejie的博客-CSDN博客
-XX:HeapDumpAfterFullGC
-XX:HeapDumpBeforeFullGC
-XX:PrintTenuringDistribution JVM 在每次新生代GC时,打印出幸存区中对象的年龄分布。

-XX:PrintClassHistogramAfterFullGC 打印 class histogram
-XX:PrintClassHistogramBeforeFullGC 打印 class histogram
-XX:PrintReferenceGC 可以记录回收了多少不同引用类型的引用。
-XX:HeapDumpPath=./java_pid.hprof:指定导出堆信息时的路径或文件名
-XX:+HeapDumpOnOutOfMemoryError:OutOfMemoryError的时候存储堆内数据,生成java_pid$pid.hprof二进制文件。可以使用MAT来分析。
-XX:OnOutOfMemoryError=";":当首次遭遇内存溢出时执行自定义命令
-XX:ErrorFile=./hs_err_pid.log:保存错误日志或者数据到指定文件中.Java 致命错误文件(hs_err_pig.log)。 JVM 致命错误日志(hs_err_pid.log)解读 | 四火的唠叨 可以使用 Smart Java thread dump analyzer - thread dump analysis in seconds、visualvm分析
-XX:OnError=";":出现致命ERROR之后运行自定义命令
6.其他参数
-
-XX:+MaxFDLimit:最大化文件描述符的数量限制。
-
-XX:+UseThreadPriorities:启用本地线程优先级API,即使 java.lang.Thread.setPriority() 生效,反之无效。
-
-XX:SoftRefLRUPolicyMSPerMB=0:“软引用”的对象在最后一次被访问后能存活0毫秒(默认为1秒)。
-
辅助信息,调试程序很重要
-
-XX:-CITime:打印消耗在JIT编译的时间
-
-XX:-PrintCompilation:当一个方法被JIT编译时打印相关信息。
-
-XX:-ExtendedDTraceProbes:开启solaris特有的dtrace探针
-
-XX:-PrintConcurrentLocks:遇到Ctrl-Break后打印并发锁的相关信息,与jstack -l功能相同
-
-XX:-TraceClassLoadingPreorder:跟踪被引用到的所有类的加载信息
-
-XX:-TraceClassResolution:跟踪常量池
-
-XX:-TraceLoaderConstraints:跟踪类加载器约束的相关信息
-
-XX:ReservedCodeCacheSize=256m code cache的最大大小
-
-XX:CompressedClassSpaceSize compressed class space大小
-
-XX:+DoEscapeAnalysis 逃逸分析
-
-XX:+EliminateAllocations开启标量替换(默认打开),允许将对象打散分配在栈上。
-
-XX:+PreserveFramePointer 优化perf火焰图采集
-
-XX:+UnlockDiagnosticVMOptions 进入诊断模式
-
-XX:+ OmitStackTraceInFastThrow JVM参数分享 OmitStackTraceInFastThrow - 简书 不打印堆栈。不利于排查
-
-XX:+AlwaysPreTouch 启动时不止分配虚拟内存,也分配物理内存 https://www.jikewenku.com/11377.html
-
-XX:+UseLargePages -XX:LargePageSizeInBytes JVM优化之调整大内存分页(LargePage)_zero__007的博客-CSDN博客_java uselargepages
GC日志分析
Young GC Full GC 日志格式
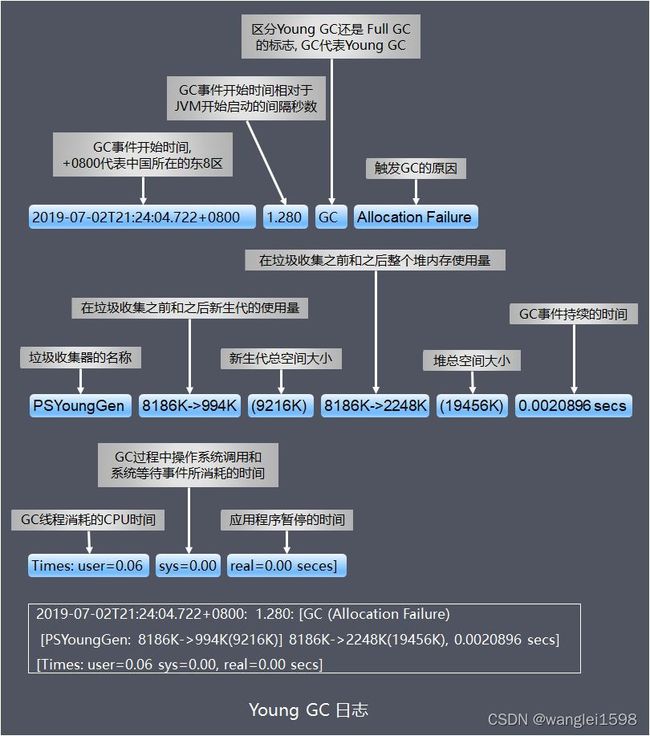

Times:
-
user:GC 线程在垃圾收集期间所使用的 CPU 总时间;
-
sys:系统调用或者等待系统事件花费的时间;
-
real:应用 被暂停的时钟时间 ,由于 GC 线程是多线程的,导致了 real 小于 (user+real),如果是 gc 线程是单线程的话,real 是接近于 (user+real) 时间。
请注意,前面两个是处理器时间,而最后一个是时钟时间,它们的区别是处理器时间代表的是线程占用处理器一个核心的耗时计数,而时钟时间就是现实世界中的时间计数。如果是单核单线程的场景下,这两者可以认为是等价的,但如果是 多核环境下,同一个时钟时间内有多少处理器核心正在工作,就会有多少倍的处理器时间被消耗和记录下来 。
在垃圾收集调优时,我们主要依据real时间为目标来优化程序,因为最终用户只关心发出请求到得到响应所花费的时间,也就是响应速度,而不太关心程序到底使用了多少个线程或者处理器来完成任务。
JVM 之 ParNew 和 CMS 日志分析
matt33.com/2018/07/28/jvm-cms/
分析GC日志工具 。不仅可以看GC 也能看堆的使用情况
-
GCViewer, 下载 jar 包直接运行(很有用) 。 GitHub - chewiebug/GCViewer: Fork of tagtraum industries' GCViewer. Tagtraum stopped development in 2008, I aim to improve support for Sun's / Oracle's java 1.6+ garbage collector logs (including G1 collector)
-
gceasy, Web 工具,上传 GC 日志在线使用。
GC日志可视化分析工具GCeasy和GCViewer_没头脑遇到不高兴的博客-CSDN博客_gceasy
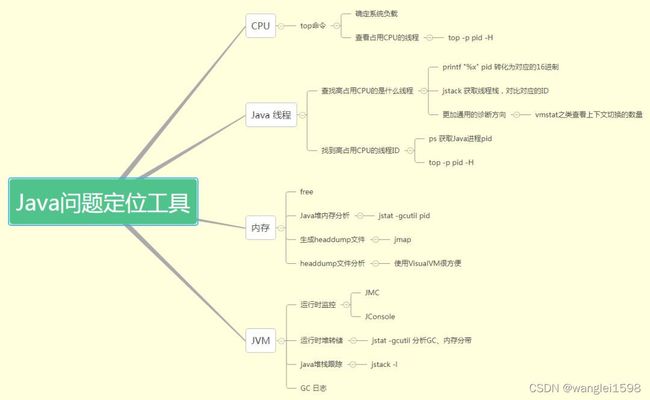
java 问题定位 Java 应用线上问题排查思路、常用工具小结
常见现象:CPU 利用率高/飙升
场景预设:
监控系统突然告警,提示服务器负载异常。
预先说明:
CPU飙升只是一种现象,其中具体的问题可能有很多种,这里只是借这个现象切入。
注:CPU使用率是衡量系统繁忙程度的重要指标。但是 CPU使用率的安全阈值是相对的,取决于你的系统的IO密集型还是计算密集型 。一般计算密集型应用CPU使用率偏高load偏低,IO密集型相反。
常见原因:
-
频繁 gc
-
死循环、线程阻塞、io wait...etc
模拟
这里为了演示,用一个最简单的死循环来模拟CPU飙升的场景,下面是模拟代码,
在一个最简单的SpringBoot Web 项目中增加 CpuReaper 这个类,
/**
* 模拟 cpu 飙升场景
* @author Richard_yyf
*/
@Component
public class CpuReaper {
@PostConstruct
public void cpuReaper () {
int num = 0 ;
long start = System.currentTimeMillis() / 1000 ;
while ( true ) {
num = num + 1 ;
if (num == Integer.MAX_VALUE) {
System.out.println( "reset" );
num = 0 ;
}
if ((System.currentTimeMillis() / 1000 ) - start > 1000 ) {
return ;
}
}
}
}
打包成jar之后,在服务器上运行。 java -jar cpu-reaper.jar &
第一步:定位出问题的线程
方法 a: 传统的方法
-
top 定位CPU 最高的进程执行 top 命令,查看所有进程占系统CPU的排序,定位是哪个进程搞的鬼。在本例中就是咱们的java进程。PID那一列就是进程号。(对指示符含义不清楚的见【附录】)
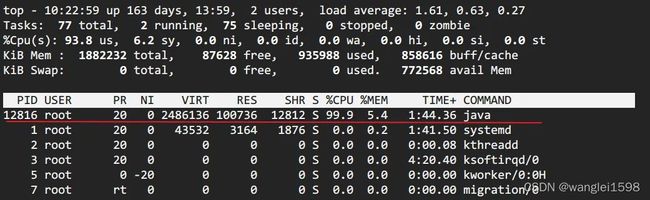
-
top -Hp pid 定位使用 CPU 最高的线程
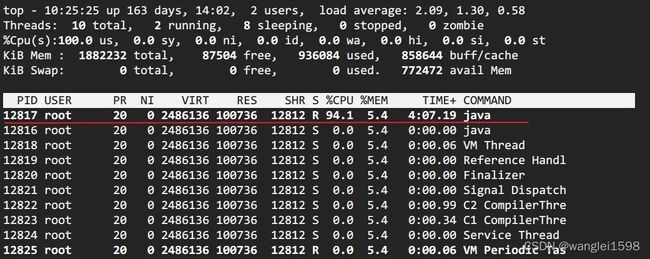
-
printf '0x%x' tid 线程 id 转化 16 进制
> printf '0x%x' 12817> 0x3211
-
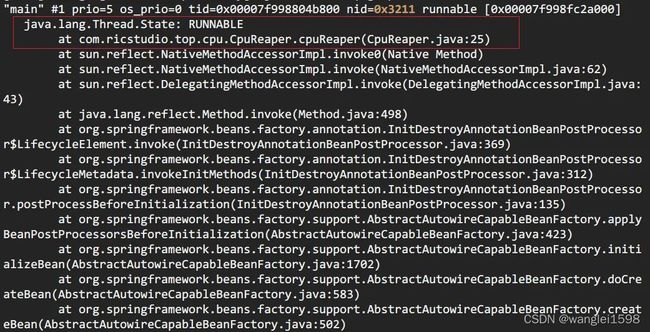
jstack pid | grep tid 找到线程堆栈
> jstack 12816 | grep 0x3211 -A 30
方法 b: show-busy-java-threads
这个脚本来自于github上一个开源项目,项目提供了很多有用的脚本, show-busy-java-threads 就是其中的一个。使用这个脚本,可以直接简化方法A中的繁琐步骤。如下,
> wget --no-check-certificate https://raw.github.com/oldratlee/useful-scripts/release-2.x/bin/show-busy-java-threads
> chmod +x show-busy-java-threads
> ./show-busy-java-threads
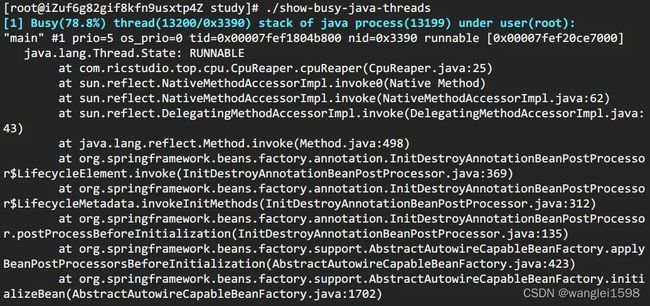
show-busy-java-threads
# 从所有运行的Java进程中找出最消耗CPU的线程(缺省5个),打印出其线程栈
# 缺省会自动从所有的Java进程中找出最消耗CPU的线程,这样用更方便
# 当然你可以手动指定要分析的Java进程Id,以保证只会显示你关心的那个Java进程的信息
show-busy-java-threads -p <指定的Java进程Id>
show-busy-java-threads -c <要显示的线程栈数>
方法 c: arthas thread
阿里开源的arthas现在已经几乎包揽了我们线上排查问题的工作,提供了一个很完整的工具集。在这个场景中,也只需要一个 thread -n 命令即可。
> curl -O https://arthas.gitee.io/arthas-boot.jar # 下载
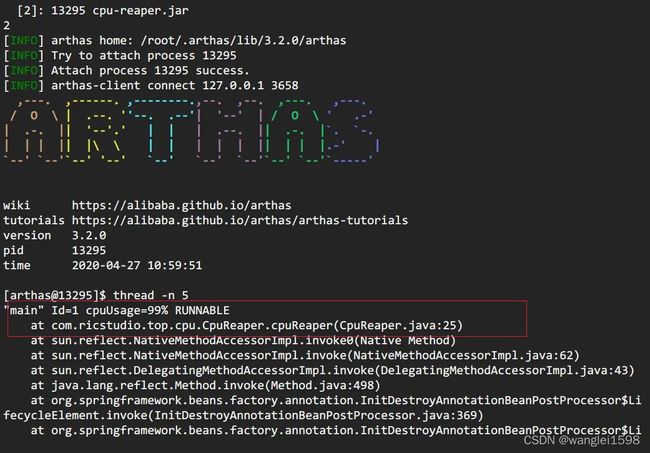
要注意的是,arthas的cpu占比,和前面两种cpu占比统计方式不同。前面两种针对的是Java进程启动开始到现在的cpu占比情况,arthas这种是一段采样间隔内,当前JVM里各个线程所占用的cpu时间占总cpu时间的百分比。具体见官网: https://alibaba . github.io/arthas/thread.html
后续
通过第一步,找出有问题的代码之后,观察到线程栈之后。我们 就要根据具体问题来具体分析 。这里举几个例子。
情况一:发现使用CPU最高的都是GC 线程。
GC task thread# 0 (ParallelGC) " os_prio=0 tid=0x00007fd99001f800 nid=0x779 runnableGC task thread#1 (ParallelGC)" os_prio= 0 tid= 0x00007fd990021800 nid= 0x77a runnable GC task thread# 2 (ParallelGC) " os_prio=0 tid=0x00007fd990023000 nid=0x77b runnable GC task thread#3 (ParallelGC)" os_prio= 0 tid= 0x00007fd990025000 nid= 0x77c runnabl
gc 排查的内容较多,所以我决定在后面单独列一节讲述。
情况二:发现使用CPU最高的是业务线程
-
io wait
-
比如此例中,就是因为磁盘空间不够导致的io阻塞
-
等待内核态锁,如 synchronized
-
jstack -l pid | grep BLOCKED 查看阻塞态线程堆栈
-
dump 线程栈,分析线程持锁情况。
-
arthas提供了 thread -b ,可以找出当前阻塞其他线程的线程。针对 synchronized 情况
常见现象:频繁 GC
1. 回顾GC流程
在了解下面内容之前,请先花点时间回顾一下GC的整个流程。
接前面的内容,这个情况下,我们自然而然想到去查看gc 的具体情况。
-
方法a : 查看gc 日志
-
方法b : jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一致统计
-
方法c : 如果所在公司有对应用进行监控的组件当然更方便(比如Prometheus + Grafana)
这里对开启 gc log 进行补充说明。一个常常被讨论的问题(惯性思维)是在生产环境中GC日志是否应该开启。因为它所产生的开销通常都非常有限,因此我的答案是需要 开启 。但并不一定在启动JVM时就必须指定GC日志参数。
HotSpot JVM有一类特别的参数叫做可管理的参数。对于这些参数,可以在运行时修改他们的值。我们这里所讨论的所有参数以及以“PrintGC”开头的参数都是可管理的参数。这样在任何时候我们都可以开启或是关闭GC日志。比如我们可以使用JDK自带的jinfo工具来设置这些参数,或者是通过JMX客户端调用 HotSpotDiagnostic MXBean的 setVMOption方法来设置这些参数。这里再次大赞arthas❤️,它提供的 vmoption 命令可以直接查看,更新VM诊断相关的参数。
获取到gc日志之后,可以上传到GC easy帮助分析,得到可视化的图表分析结果。
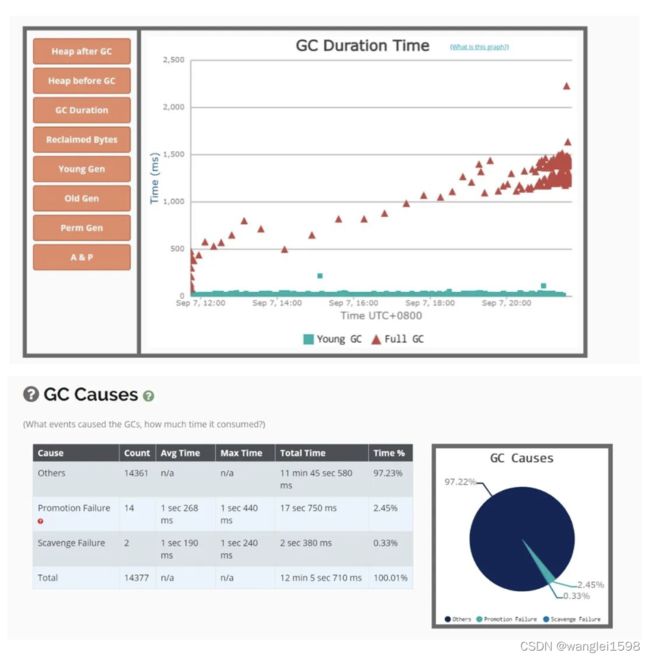
2. GC 原因及定位
prommotion failed
从S区晋升的对象在老年代也放不下导致 FullGC(fgc 回收无效则抛 OOM)。
可能原因:
-
survivor 区太小,对象过早进入老年代查看 SurvivorRatio 参数
-
大对象分配,没有足够的内存dump 堆,profiler/MAT 分析对象占用情况
-
old 区存在大量对象dump 堆,profiler/MAT 分析对象占用情况
你也可以从full GC 的效果来推断问题,正常情况下,一次full GC应该会回收大量内存,所以 正常的堆内存曲线应该是呈锯齿形 。如果你发现full gc 之后堆内存几乎没有下降,那么可以推断:**堆中有大量不能回收的对象且在不停膨胀,使堆的使用占比超过full GC的触发阈值,但又回收不掉,导致full GC一直执行。换句话来说,可能是内存泄露了。
一般来说,GC相关的异常推断都需要涉及到 内存分析 ,使用 jmap 之类的工具dump出内存快照(或者 Arthas的 heapdump )命令,然后使用MAT、JProfiler、JVisualVM等可视化内存分析工具。
至于内存分析之后的步骤,就需要小伙伴们根据具体问题具体分析啦。
常见现象:线程池异常
场景预设:
业务监控突然告警,或者外部反馈提示大量请求执行失败。
异常说明:
Java 线程池以有界队列的线程池为例,当新任务提交时,如果运行的线程少于 corePoolSize,则创建新线程来处理请求。如果正在运行的线程数等于 corePoolSize 时,则新任务被添加到队列中,直到队列满。当队列满了后,会继续开辟新线程来处理任务,但不超过 maximumPoolSize。当任务队列满了并且已开辟了最大线程数,此时又来了新任务,ThreadPoolExecutor 会拒绝服务。
常见问题和原因
这种线程池异常,一般可以通过开发查看日志查出原因,有以下几种原因:
-
下游服务 响应时间(RT)过长这种情况有可能是因为下游服务异常导致的,作为消费者我们要设置合适的超时时间和熔断降级机制。另外针对这种情况,一般都要有对应的监控机制:比如日志监控、metrics监控告警等,不要等到目标用户感觉到异常,从外部反映进来问题才去看日志查。
-
数据库慢 sql 或者数据库死锁
查看日志中相关的关键词。
-
Java 代码死锁jstack –l pid | grep -i –E 'BLOCKED | deadlock'