基于车联网大数据的不良驾驶行业监控系统(附代码)
摘要
随着我国经济水平的快速发展,当前汽车已经普遍地进入了我国居民的家中,使我国市场上的汽车保有量快速增加。但汽车保有量增加的同时,根据有关调查显示不良汽车驾驶的行为也快速增加,不良汽车驾驶行为的特征过于复杂,且导致不良汽车驾驶行为的因素也较多。本文主要研究驾驶行为对行车安全的影响,选取一运输企业车联网数据,将驾驶行为分成五个类别,每个类别选取两个参数作为行车安全的评价指标,通过耦合层次分析法和熵值法确定的指标权重确定各指标的综合权重,使用基于综合权重的模糊聚类算法,建立基于驾驶行为的行车安全评价模型,实现对驾驶行为对行车安全的归类评价。
关键词:驾驶行为;安全评价模型;层次分析法;熵值法;模糊聚类
一、问题重述
1.1问题背景
随着我国车辆保有率的增加,交通事故的数量也在不断增长,各类交通事故往往是由驾驶员的违规驾驶行为导致的。目前,随着车辆导航系统的普及和车联网等新兴信息技术的不断发展,越来越多的车辆行驶数据通过北斗或者GPS定位系统被收集。如何将这些数据量化,并建立完整客观的司机驾驶行为优劣的评价系,对于控制和预防交通事故的发生有着重要的意义和研究价值。因此我们将指标权重和聚类结合起来,建立一个基于不同权重的不良驾驶行为的行车安全评价模型。对驾驶员的驾驶行为进行分析与评价,以期为提高行车安全提供一定的参考和借鉴。本文数据主要来源于某运输企业上传至车联网系统的数据。
1.2研究意义
通过研究不良驾驶行为,给出有效的管制措施,具有很重要的意义。
(1)驾驶员方面。通过管制能够养成良好的安全的驾驶习惯,既保证了驾驶安全又能够减少财产损失。
(2)交通运营方面。通过管制增加道路使用效率,减少系统延误时间,有效提高通行效率。
(3)交通管理方面。通过管制增加交通安全度,减少交通事故的次数,也降低交通事故的严重程度。
(4)交通保险方面。通过对不良驾驶行为的研究,可以通过全面的风险评估降低理赔成本和准确估计损失确认责任。
二、问题分析
2.1不良驾驶行为定义
不良驾驶行为是指在驾驶过程中,驾驶人的实际驾驶操作偏离标准安全驾驶规范导致发生事故概率较大的驾驶活动。有了不良驾驶行为,就极易发生交通事故。交通事故有重度、中度、轻度之分。可能造成财产受破坏、人员伤亡、车辆损失、交通受阻,道路损坏等后果。
2.2产生不良驾驶行为的原因
原因1:开车速度
开车速度是产生不良驾驶行为的重要原因现在在高速公路上都规定最高时速,其它一级公路、二级公路、乡村公路、城市内道路都规定有最高时速,但有不少司机不按规定的控制时速,而是超速行驶。例如,限时速100公里,很多司机开的时速110公里、120公里。有些司机靠买来的启示仪,以更高速度开车,很危险。常见标语“十次事故九次快”,这是一个实践真理。
原因2:与开车经验有关
开车需要技术,也需要经验,在进入城内物多人多,在一般路上遇到人和物要靠开车经验,在转弯时、遇到对面来车、晚上开车也都要靠经验。现在买新车的人多,经验不足。由此开车人不总结经验,也不虚心向经验丰富的人学习,自己进步不快,危险性就更大了。
原因3:道路的环境差
人的精神状态,头脑的清醒程度与气候的变化,即与晴天、太阳天、下雨、下雾、下雪、风吹的变化而变化。也与道路的类型、质量、路面的平坦程度、路面的宽度、路边的状态有很大的关系。如果天气差、道路环境差就会容易造成驾驶事故。
原因4:与驾驶员不同状态有关
一个人的精神状态在不同的季节、月、日,而且每天早上、中午、晚上都有影响。一个人的精神状态还与每个人的情绪、身体好坏有关。人的情绪不好,身体不好,都可能因为不良驾驶造成事故。
原因5:人的心理健康是引起不良驾驶的原因
心理健康是人类个体对其生存的社会环境的一种高级适应状态。心理健康是对个人,乃至事业成功之本,是开车安全之本、辛福之源,是至关重要的大事。当人在面临来自环境的挑战时,能充分利用其心理机制的调节潜能,作出适应性的行为选择,行车就无事故。
原因6:违纪现象
以下的违纪现象也是不良驾驶行为,有可能造成事故:
①汽车有问题,但未修好就开车,汽车可能出事故。有的汽车保养期已过,但是没有按规定去检查保修,就很容易出故障;
②有不少司机开车时接电话,这是违纪的行为。开车时接电话分散注意力,不集中精力开车,很难避免事故的发生;
③有不少司机喜欢打牌;造成睡眠不足;有些司机还有很多劳动,兼职太多,体力消耗很大;有些司机喝茶太多、太晚,影响睡觉,造成疲劳,想睡觉,精神提不起来,造成不良驾驶行为;
④有些司机,虽然有驾驶证,但这个驾驶证不是这辆车的,不同的车,质量不一样,性能各异,不尽相同,临时用起来,就容易出事;
⑤有些司机可能脾气大,攻击性强,此类人遇到不顺心的事,例如遇到争快速、争车道、遇到交通拥堵、车流量巨大,就易于出现交通事故。
2.3解决问题的方法
对比不良驾驶行为的人的事故发生,明显高于普通职业驾驶人。上述介绍的产生事故原因,太多出自不良驾驶人员。 此外,不良驾驶人员,对运动车辆的速度估计能力和前后车辆的速度估计不足,对复杂交通路面机敏性较差,在行车中对交通场景的变化注意力欠缺,易引发交通意外事故。不良驾驶行为对道路交通安全的影响程度从大到小依次为小客车、大客车、小货车、大货车。
交通安全是一个永恒的话题,其中司机的驾驶行为是交通安全的重要影响因素。因此,对驾驶行为进行研究,选择合适的理论模型分析不良驾驶行为对行车安全的影响,对提高行车安全性方面具有重要的现实意义。目前常见的评价方法主要有层次分析法、熵值法、模糊综合评价法、聚类分析等方法。我们利用层次分析法建立了道路安全评价模型,运用熵值法分配各指标的权重从而建立了基于熵权的评价模型,利用k-means聚类的方法来判定司机驾驶的危险程度,利用模糊C均值聚类得到危险程度较高的样本。聚类的方法可以有效地将危险程度较高的样本聚到一起,但是聚类的方法本身并没有对指标的权重进行处理,而现实生活中不同的不良驾驶行为的严重性是不一样的,所以我们要在对样本进行聚类之前分析并确定每个指标的权重。
(1)提取并分析车辆的运输路线以及其在运输过程中的速度、加速度等行车状态。提交附表中10辆车每辆车每条线路在经纬度坐标系下的运输线路图及对应的行车里程、平均行车速度、急加速急减速情况。
(2)利用所给数据,挖掘每辆运输车辆的不良驾驶行为,建立行车安全的评价模型,并给出评价结果。
(3)综合考虑运输车辆的安全、效率和节能,并结合自然气象条件与道路状况等情况,为运输车辆管理部门建立行车安全的综合评价指标体系与综合评价模型。
在车辆运输过程中,不良驾驶行为主要包括疲劳驾驶、急加速、急减速、怠速预
热、超长怠速、熄火滑行、超速、急变道等。
三、模型建立与求解
3.1 对汽车驾驶中不良驾驶行为数据的收集
3.1.1 汽车驾驶中不良驾驶行为数据的收集工作
在汽车中不良驾驶行为数据进行收集的过程中,实验人员通过在城市中各个交通要道设置监控录像器,来收集驾驶员在参加驾驶中的不规范行为。在进行不良驾驶行为数据采集过程中所设置的采集时间为24小时,在录像采集中将有不良驾驶行为的车辆类型、不良驾驶行为的具体方式、不良驾驶行为发生的路况即车辆行驶位置、不良驾驶行为所导致的交通事故种类、不良驾驶行为所发生的时间、不良驾 驶行为的车辆在调查中所出现的概率等相关因素进行数据收集。
3.1.2 汽车驾驶中不良驾驶行为数据的处理工作
在对汽车驾驶中不良驾驶行为数据进行处理的过程中,实验人员首先需要对所收集的数据进行区别分类,然后将所收集不良汽车驾驶行为的数据,根据汽车的种类和车型大小进行细致化的区分,来确保在后期分析中保证分析结果的准确性。由于所涉及不良驾驶行为的车辆种类过多,所以为了方便实验人员在分析过程中确定车辆的具体行为,实验人员可以将汽车发生的不良驾驶行为分为以下8类:其中分别是车辆强行变换车道、车辆行驶中强行超车、车辆行驶中压线、车辆行驶中出现违规变道、车辆行驶中出现强行制动、车辆在行驶中出现超车道减速、车辆行驶中出现打错转向灯、车辆在正常车道上突然提速行驶等。
3.2 汽车驾驶中不良汽车驾驶行为的具体特征
在对汽车驾驶中不良汽车驾驶行为在具体特征进行分析的过程中,实验人员可以将小、中、大型车辆进行统一分类,然后根据不同型号的车辆进行不良驾驶行为的特征统计。在进行数据统计的过程中发现,小型车辆在行驶过程中出现的超速现象明显多于大型车辆,这主要源于小型车辆的动力系统和行驶性能优于大型车辆;大型车辆在行驶过程中所发生的不良行驶行为持续的时间会比小型车辆更加持久,这主要源于大型车辆在驾驶过程中难以控制,因此当大型车辆的驾驶员发现自己的不良驾驶行为时,想要纠正不良驾驶行为所需要耗费的时间也远多于小型车辆;小型车辆和大型车辆在行驶过程中,会出现占用公共汽车道路的发生平均概率大致相同,也没有一定的规律性。但是小型车辆由于其速度较快所占用公共汽车道路的时间较短,而大型车辆由于其体积较大所占用公共汽车道路的时间较长。因此在上述的对比分析中可以明显看出,由于大型车辆及负载过重体积庞大,在道路行驶的过程中驾驶速度较慢,小型车辆由于其体积较小且动力系统优异,因此在行驶过程中驾驶速度更快;大型车辆由于体积过于庞大且多为货运汽车,因此大型车辆的驾驶时长较长,驾驶员在车辆驾驶中便容易出现不良驾驶行为;大型车辆和小型车辆在驾驶过程中对所占道路的服务程度具有一定的不规律特点。
3.3 汽车驾驶中不良汽车驾驶行为的危险度分析
在汽车驾驶过程中实验人员采用的是模糊评价法,通过模糊评价法可以大致的得到车辆在行驶过程中所出现不良驾驶行为的大致危险度。并根据车辆行驶过程中出现的危险度进行车辆的驾驶行为分析,就可以对车辆在行驶过程中所发生危险事故的概率进行判断,进而得到不同车型的危险度指标。
3.4 规范汽车驾驶行为的具体措施
通过以上对汽车不良驾驶行为的研究和分析过程中可以发现,小型车辆和大型车辆的具体不良驾驶行为的特征和对道路交通所产生的影响。因此可以将此研究成果应用于当前我国的汽车生产领域,通过将上述调查数据与汽车生产中的汽车计算机进行融合,便可以让汽车计算机自带相应的道路预警装置,及时的判断出驾驶员在车辆驾驶过程中的不良行为,从而开启警报提醒规范驾驶员在车辆驾驶中的行为。此外在我国的汽车生产领域,通过对汽车的驾驶行为进行认知建模已经成为当下我国现代汽车生产研究领域中的重点,而本文通过对汽车驾驶过程中的不良行为特征进行研究的主要目的是为了解决当前我国道路交通过程中频发的安全问题,只有这样才可以确保我国道路交通中驾驶员的出行安全,来维护我国社会的稳定性。
3.5讨论
本次职业驾驶人驾驶行为调查结果显示,不良驾驶行为可分为故意违章行为、过失行为和陋习行为三类,其中故意违章行为居于首位,其次为过失行为和陋习行为,这一结果说明当时驾驶人有意违反交通规则是一种普遍现象,因此我国采用信息技术手段惩治驾驶人违章是非常有意义的。调查得出职业驾驶人不良驾驶行为人群发生率高达 94.29%,即几乎每个驾驶人都有过不良驾驶行为的经历或记录,可见不良驾驶行为现象十分严重,然而,根据不良驾驶行为的频数分布人群比例发现不良驾驶行为的发生并非纯随机,而是因人而异,有人高发,有人少发,发生0次不良驾驶行为的人比例极少,约占5.71%,呈不均匀分布,这可能与每个驾驶人自身某些内在的生理、心理因素有关,提示每个驾驶人对不良驾驶行为均可能具有不同程度“易感性”,易感性高可能多发,反之则少发,此易感性的生物学意义有待进一步探讨。另外,本研究并没有发现酒后驾驶、无照驾驶等不良驾驶行为,这与其他研究结果不一致其原因仅仅是由于本研究选择的对象不同,我们选择的公交及客运公司职业驾驶人在驾驶之前是受到多重交通法规的严格约束,酒驾、无证的现象是没有机会的出现的。另外,本调查发现由不良驾驶行为引发的交通事故占事故总数82.17%,其中超速、不按规定让行、跟车过近、随意变道、占道行驶、注意力分散、弯道超车、转向不当、违法倒车、逆行等是最常见的十大诱发交通事故的原因,这与其他研究结果相吻合。建议这些行为应纳入基层安全管理部门日常监控的重点。从时间维度看,不良驾驶行为在春夏季高发,这可能与气候因素及春夏季物流运输露几率增加有关,春季驾驶人大多容易困倦导致注意力难以集中,夏季天气炎热,驾驶人容易情绪浮躁,且春季生产物资的调运、旅客外出春运等导致物流运输量增加,以致春夏季诱发不良驾驶行为的几率增加。不良驾驶行为常年频发,但每8点和17点左右有两个高峰期,这与上下班高峰期相吻合,高峰流量时段,道路拥挤,驾驶员大多情绪焦躁,为了“节约时间”而采取超速、抢行、占道等不良驾驶行为。不良驾驶行为的空间环境分布显示交叉路口不良驾驶行为高发,其次是弯道、直行道,这主要与交叉路口交通冲突点较多,弯道处需要驾驶操作的频数多有关,直行道多发是由于直行道上行驶的时间最长,其暴露的机会比其它路面多,导致发生不良驾驶行为的几率随之较高。 晴天出现不良驾驶行为的频率最高,是由于晴天驾驶时少了一份警惕心理,容易麻痹大意产生过失不良行为。在人群分布上,男性显著多于女性,其中25-30岁年龄段高发。这与我国驾驶员以男性居多有关,驾驶员年龄越小,其驾驶经验越少,且容易冲动,以致不良驾驶行为容易诱发。在不同驾龄资历的职业驾驶员中,因没有低于1年的驾驶员,显示1-3年驾龄驾驶员不良驾驶行为最多,主要与其驾驶技能及经验认知不足有关,1-3年驾龄驾驶员处于技术不稳定时期,由于缺乏足够的驾驶经验,而主观意识上认为自己驾驶经验丰富,能力高估的落差容易滋生不良驾驶行为发生。综上所述,不良驾驶行为可分为故意违章行为、过失行为和陋习行为三类,其发生具有显著的时间、环境、人群分布特征,时间、环境及个体易感性可能是其主要影响因素。
3.6心理因素不良驾驶行为
心理因素产生的不良驾驶行为复杂多样,主要是驾驶员的心理活动产生不良驾驶行为。主要有“无视别人感受”的驾驶行为,有“危险判断不足”的驾驶行为,有“侥幸心理” 的驾驶行为。心理因素产生的不良驾驶行为都比较危险, 对交通安全危害较大。主要有持续远光灯,路上持续鸣笛催促,恶意加塞困难地形不减速,随意穿梭车队,快车道慢行,占用公交车道和非机动车道等。心理因素产生的不良驾驶行为因为不考虑其他驾驶员的感受,容易使其他驾驶员无法忍受,造成斗气车等现象。
3.7 具体方法
(1)提取并分析车辆的运输路线以及其在运输过程中的速度、加速度等行车状态。提交附表中10辆车每辆车每条线路在经纬度坐标系下的运输线路图及对应的行车里程、平均行车速度、急加速急减速情况。
(2)利用所给数据,挖掘每辆运输车辆的不良驾驶行为,建立行车安全的评价模型,并给出评价结果。
(3)综合考虑运输车辆的安全、效率和节能,并结合自然气象条件与道路状况等情况,为运输车辆管理部门建立行车安全的综合评价指标体系与综合评价模型。
四、研究结果
4.1 不良驾驶行为分类特征
根据驾驶人驾驶行为问卷(DBQ) 对不良驾驶行为的表现形式及其动机分析, 得出不良驾驶行为可区分为三类:
(1) 因缺乏认知而产生的习惯性错误行为,即陋习类驾驶行为;
(2) 因疏忽大意而产生的失误操作,即过失类驾驶行为;
(3) 因故意违反交通规则或社会认可的行为规范而产生的错误行为,即故意违章类驾驶行为9-12l,具体表现形式见表1。其中,故意违章行为占53.25%,过失行为占40.06%,陋习行为占6.69%。最常见的高危不良驾驶行为分别是超速、不按规定让行、跟车过近、随意变道、占道行驶、 注意力分散、弯道超车、转向不当、违法倒车、逆行(见图1)。

表1 不良驾驶行为分类特征
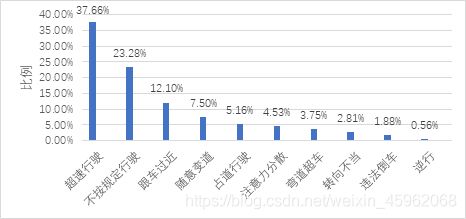
图1 十种高危不良行为分布情况
4.2 不良驾驶行为的事故比例
2003-2007年,我们对杭州、西安、合肥三城市调查的41682 起交通事故中,不良驾驶行为引起的交通事故为34250起,占事故总数的82.17% 。其间三个城市调查的重特大交通事故总数为2479起,由不良驾驶行为引发的特重大交通事故共2248起,占重特大交通事故总数90.68%,超速、注意力分散、急速转弯等不良驾驶行为是重特大交通事故的常见原因。
4.3 不良驾驶行为时间分布特征
根据月分布曲线图可看出,不良驾驶行为常年发生,在夏秋季多发见,图2;时点分布曲线显示不良驾驶行为每天在8点和17点左右有两个高峰期,见图3。
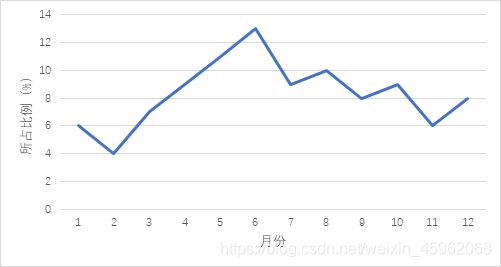
图2 不良驾驶行为月份分布
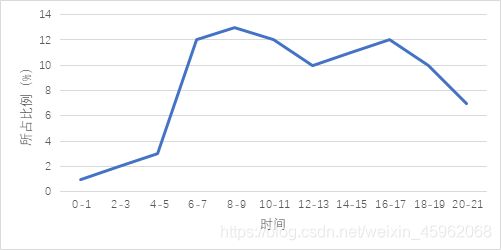
图3 不良驾驶行为时点分布
4.4 不良驾驶行为环境分布特征
(1) 道路形态分布:不良驾驶行为在路口发生的比例最高,占43.41%;其次为弯道,占29.54%和直行道占21.72%(见图4) 。
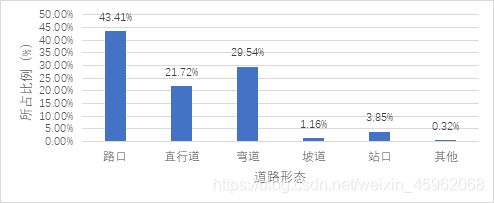
图4 不良驾驶行为道路形态分布
(2) 气候环境分布:天气晴朗时不良驾驶行为的发生率最高,占67.63%;其次为阴天气,占24.31%;其他天气情况占8.06% 。
4.5 不良驾驶行为人群分布特征
(1)发生率:调查的样本中不良驾驶行为人群发生率达94.29%。
(2)性别分布:不良驾驶行为性别分布差异显著,男性显著高于女性,占95.41%。
(3)年龄分布:在各个年龄段的驾驶员中, 25-30岁年龄段驾驶员高发,占61.78%,35-40岁年龄段最低,占7.13%。
(4)驾龄分布:1-3 年驾龄驾驶员不良驾驶行为高发,占47.68% ,其次为3-5年驾龄驾驶员,占35.46%,10年以上驾龄驾驶员最低,占5.62%,见图5。
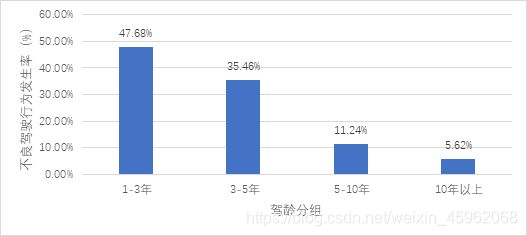
图5 不同驾龄驾驶员不良驾驶行为分布
(5)频数分布:驾驶员发生0次不良驾驶行为人数为1060人,占驾驶员总数的5.71%,驾驶员发生一次不良驾驶行为人数为8894人,占驾驶员总数的47.92%,发生两次不良驾驶行为的驾驶员人数为6871人,占37.02%,发生三次及以上不良驾驶行为的驾驶员人数为1735人,占9.35%,见图6。
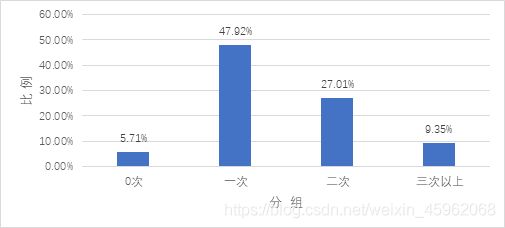
图6 不良驾驶行为频数分布人群比例
4.6 不良驾驶行为人群分布特征
4.6.1 excel的批量处理
首先进行批量excel的处理,通过打印输出csv列表,得到如图7:
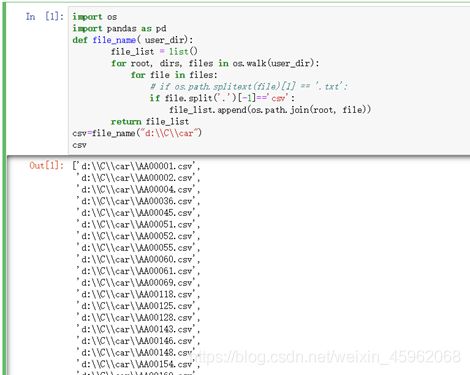
图7 excel的批量处理
对单个excel进行数据处理,如图8。
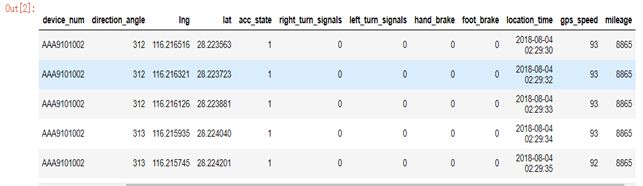
图8 对单个excel进行数据处理
4.6.2 时间、速度、方向角的处理
方向角,经纬度,以及时间轴,acc状态,还有速度里程这几个变量可以为我们所利用。这是一个基于时间序列的操作。我们可以观察到时间轴的数据格式,转换为我们需要的格式,比如第二条时间减去第一条时间就是△t,这样我们就可以通过a=△v/△t,来计算加速度。
这里面的△t和△v在列表t和列表v里面,相应的,我们还可以得到角变化量,进一步得到角加速度,可以用来判断急转弯,通过±a可以来判断急加速急减速。如图9,图10。
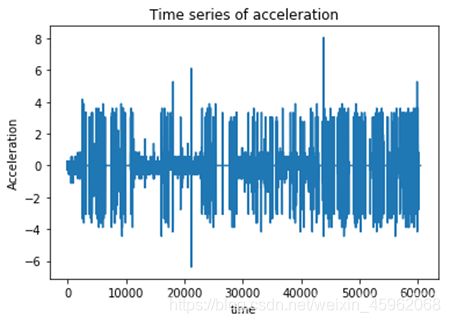
图9 时间、速度、方向角的处理(1)
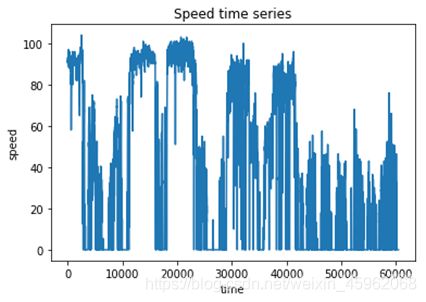
图10 时间、速度、方向角的处理(2)
4.6.3 经纬度的处理
经纬度的处理有很多方法,这里我们用python第三方库中最好用的一个库folium,自带地图。也有plotly,google earth,很多画地图的软件,挑一个最简单的库。得到如下路线图如图11,观察到了存在一些漂移点。
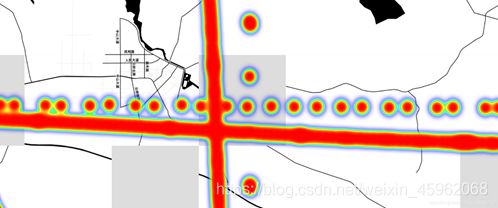
图11 路线图
通过计算速度与实际距离的关联性来判断是否为异常点。这时,我们需要用到下面这个经纬度与实际距离转换的函数来作进一步的优化:
1. def hypot(x,y):
2. return math.sqrt(x**2+y**2)
3. def distance(lat1, lon1, lat2, lon2):
4. PI = 3.1415926535898
5. R = 6.371229 * 1e6
6. x = (lon2 - lon1) * PI * R * math.cos( ( (lat1 + lat2) / 2) * PI / 180) / 180
7. y = (lat2 - lat1) * PI * R / 180
8. out = hypot(x, y)
9. return out
通过实际的经纬度转换距离d是否在gps_speed*△t理论距离这个正常区间范围内。
五、模型优化
当我们把所有的分析代码写完之后,你会很开心地开始运行,你会发现速度会特别的慢,450个excel大约需要等待两个半小时。
这里,我们需要用到一个第三方库numba,pip install numba 即可安装完毕。
@nb.jit 这个函数修饰器加速效果特别明显,也还有其他相关的库,附录有为计算车速稳定性的加速版完整excel处理代码。结果如图12
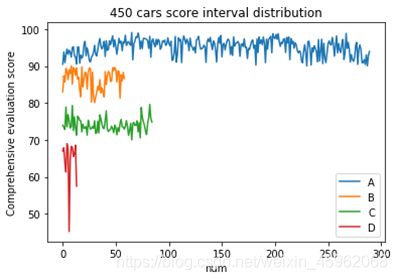
图12 处理结果
六、总结
对不一样车型的不良汽车驾驶行为特性实施分析,对比研究大、小型车、客运与货运车在出现不良汽车驾驶行为时的速度和持续时间以及所居道路的服务程度,总结出产生不良汽车驾驶行为时给道路交通安全带来的严重影响。汽车驾驶员在车辆驾驶中的不良驾驶行为,不仅会对生命财产安全造成严重的危险,还会给整个社会带来不良的影响。因此通过对车辆驾驶员在驾驶中的不良行为具体种类和产生的危害进行研究,通过研究的数据对不良驾驶行为建模处理,这样就可以形成具体的方案来改善驾驶员在车辆驾驶中的个人行为。
参考文献
[1]Royal Society for the Prevention of Accidents (ROSPA). Driver Fatigue and Road Accidents:A Literature Review and Position Paper[R].Washington, D C: Royal Society for Lhe Prevention of Accidents, 2001.
[2]金会庆,车祸流行病学[M].北京:人民交通出版社
[3]Richard Stone. Car-crash Epidemiologist Pushes Systemic Attack on Bad Driving [J]. Science
[4]金会庆,道路交通事故防治工程[M].北京:人民交通出版社.2005:235-276.
[5]Kontogiannis T,Kossiavelou Z,Marmaras N.Self-re- ports of Aberrant Behaviour on the Roads: Errors and Violations in A Sample of Greek Drivers[J].Ac- cid Anal Prev
[6]Young K,Renan M, Hammer M.Driver Distraction: Areview of the literature: Report 206[R].Monash U- niversity Accident Research Centre, Victoria, Aus- tralia, 2003.
[7]Wills AR, Watson B,Biggs HC. Comparing Safety Climate Factors as Predictors of Work-related Driv- ing BehaviorUJ. Joumal of Safety Research
[8]王长君,高岩,张爱红.重点违法行为导致交通事故的数据分析叨,交通运输工程与信息学报
[9]Sundstrom A.Self Assessment of Driving Skill a Re- view from A Measurement Perspective[J].Transporta- tion Research Part F: Traffic Psychology and Be- haviour
[10]Ozkan T,Lajunen T.What Causes the Differences in Driving Between Young Men and Women? The Effects of Gender Roles and Sex on Young Drivers’ Driving Behaviour and Selfassessment of Skills[J]. Transportation Research Pari F:Traffic Psychology and Behaviour
[11]Lajunen T, Parker D, Summala H.The Manchester Driver Behaviour Questionnaire: A Cross -cultural Study[Jl. Accident Analysis and Prevention
[12] 张凤,李永娟,蒋丽.驾驶行为理论模型研究概述.中国安全科学学报
[13] Jeffrey W, Cheryl L,Janel M, er al.Enforcement of Drunken Driving Laws in Cases Involving Injured Injured Intocicated Drivers [J].
附录1
1、excel的批量处理
1. import numpy as np #che su wending xing
2. import pandas as pd
3. import os
4. def file_name( user_dir):
5. file_list = list()
6. for root, dirs, files in os.walk(user_dir):
7. for file in files:
8. # if os.path.splitext(file)[1] == '.txt':
9. if file.split('.')[-1]=='csv':
10. file_list.append(os.path.join(root, file))
11. return file_list
12. path="d:\\car" #此处的路径为存放excel的根目录
13. csv=file_name(path) #得到一个列表,里面为450个excel的存放地址
14. for j in range(len(csv)): #遍历这个列表
15. data=pd.read_csv(csv[j]) #遍历每个excel
16. function(data) #对每辆车的数据进行相应的处理
2、时间、速度、方向角的处理
1. import time
2. import datetime
3. import math
4. def composeTime(time1):
5. time2 = datetime.datetime.strptime(time1, "%Y-%m-%d %H:%M:%S")
6. time3 = time.mktime(time2.timetuple())
7. time4 = int(time3)
8. return time4
9. t=[]
10. v=[]
11. for i in range(len(data["location_time"])):
12. t1=data["location_time"][i]
13. t2=data["location_time"][i+1]
14. v1=data["gps_speed"][i]
15. v2=data["gps_speed"][i+1]
16. t0=t2-t1
17. v0=v2-v1
18. t.append(t0)
19. v.append(v0)
3、经纬度的处理
1. import numpy as np
2. import pandas as pd
3. import seaborn as sns
4. import folium
5. import webbrowser
6. from folium.plugins import HeatMap
7. import os
8.
9. posi=pd.read_csv("D:\\C\\first\\AB00006.csv")
10.
11. lat = np.array(posi["lat"]) # 获取维度之维度值
12. lon = np.array(posi["lng"]) # 获取经度值
13. pop = np.array(posi["gps_speed"]) # 获取人口数,转化为numpy浮点型
14.
15. data1 = [[lat[i],lon[i],pop[i]] for i in range(len(lat))] #将数据制作成[lats,lons,weights]的形式
16. m = folium.Map([ 33., 113.], tiles='stamentoner', zoom_start=5)
17. route = folium.PolyLine( #polyline方法为将坐标用线段形式连接起来
18. data1, #将坐标点连接起来
19. weight=3, #线的大小为3
20. color='orange', #线的颜色为橙色
21. opacity=0.8 #线的透明度
22. ).add_to(m) #将这条线添加到刚才的区域m内
23.
24. m.save(os.path.join(r'd:\\C\\car', 'AA000002.html'))
25. m
优化处理
1. def hypot(x,y):
2. return math.sqrt(x**2+y**2)
3.
4. def distance(lat1, lon1, lat2, lon2):
5. PI = 3.1415926535898
6. R = 6.371229 * 1e6
7. x = (lon2 - lon1) * PI * R * math.cos( ( (lat1 + lat2) / 2) * PI / 180) / 180
8. y = (lat2 - lat1) * PI * R / 180
9. out = hypot(x, y)
10. return out
4、大数据处理的优化
1. import numpy as np #che su wending xing
2. import pandas as pd
3. import seaborn as sns
4. import folium
5. import webbrowser
6. from folium.plugins import HeatMap
7. import os
8. import time
9. import datetime
10. import matplotlib.pyplot as plt
11. import math
12. import numba as nb
13.
14. def composeTime(time1):
15. time2 = datetime.datetime.strptime(time1, "%Y-%m-%d %H:%M:%S")
16. time3 = time.mktime(time2.timetuple())
17. time4 = int(time3)
18. return time4
19.
20. def hypot(x,y):
21. return math.sqrt(x**2+y**2)
22. @nb.jit
23. def distance(lat1, lon1, lat2, lon2):
24. PI = 3.1415926535898
25. R = 6.371229 * 1e6
26. x = (lon2 - lon1) * PI * R * math.cos( ( (lat1 + lat2) / 2) * PI / 180) / 180
27. y = (lat2 - lat1) * PI * R / 180
28. out = hypot(x, y)
29. return out
30.
31. def file_name( user_dir):
32. file_list = list()
33. for root, dirs, files in os.walk(user_dir):
34. for file in files:
35. # if os.path.splitext(file)[1] == '.txt':
36. if file.split('.')[-1]=='csv':
37. file_list.append(os.path.join(root, file))
38. return file_list
39. @nb.jit
40. def ji_wending_jit():
41. for j in range(3):
42. data=pd.read_csv(csv[j])
43. v=[]
44. count=0
45. t=0
46. for i in range(len(data["gps_speed"])-1):
47. t1 = composeTime(data["location_time"][i])
48. t2 = composeTime(data["location_time"][i+1])
49. v1 = data["gps_speed"][i]
50. if t2-t1<=100 and v1>0:
51. count=count+1
52. v.append(v1)
53. t=t+(t2-t1)
54. arr_std_v = np.std(v,ddof=1)
55. arr_std_v_list.append(arr_std_v)
56. T.append(t/(60*60))
57. print("第"+str(j)+"个车分析完成")
58. print("finish")
59.
60. csv=file_name("d:\\C\\car")
61. T=[]
62. arr_std_v_list=[]
63. ji_wending_jit()
64. Data=[]
65. Data.append(arr_std_v_list)
66.
67. print(Data)
68.
69. print(T)
5、源代码整理
car_safety.py
1. import csv
2. import datetime
3. from geopy.distance import geodesic
4. from geopy.distance import geodesic
5. from interval import Interval
6. import matplotlib.pyplot as plt
7. from openpyxl import Workbook
8. def route(fileDir):
9. temp_count_km=0
10. time=0
11. lists = []
12. dictt={}
13. routeDate=[]
14. fatigue_list=[]
15. v_list=[0]
16. vv_list=[]
17. a_list=[0]
18. time_list = [1]
19. changLane_list=[]
20. flameout_list=[]
21. ldleSpeed_list=[]
22. ldleSpeed_time_list=[]
23. FatigueDriving_list=[]
24. FatigueDriving_time_list=[]
25. with open(fileDir, "r") as csvfile:
26. reader = csv.reader(csvfile)
27. for j, line in enumerate(reader):
28. list4 = []
29. if line[5] == '1' and int(line[11]) != 0 and len(FatigueDriving_list)%2 == 0:
30. temp_list = [line[3], line[4],line[10]]
31. FatigueDriving_list.append(temp_list)
32. if line[5] == '1' and int(line[11]) == 0 and len(FatigueDriving_list)%2 != 0 :
33. temp_list = [line[3], line[4],line[10]]
34. FatigueDriving_list.append(temp_list)
35. d1 = datetime.datetime.strptime(FatigueDriving_list[-2][2], '%Y-%m-%d %H:%M:%S')
36. d2 = datetime.datetime.strptime(FatigueDriving_list[-1][2], '%Y-%m-%d %H:%M:%S')
37. d = d2 - d1
38. if d.seconds >180:
39. ldleSpeed_time_list.append(d.seconds/60)
40. if line[5] == '1' and int(line[11]) == 0 and len(ldleSpeed_list)%2 == 0:
41. temp_list = [line[3], line[4],line[10]]
42. ldleSpeed_list.append(temp_list)
43. if line[5] == '1' and int(line[11]) != 0 and len(ldleSpeed_list)%2 != 0:
44. temp_list = [line[3], line[4],line[10]]
45. ldleSpeed_list.append(temp_list)
46. d1 = datetime.datetime.strptime(ldleSpeed_list[-2][2], '%Y-%m-%d %H:%M:%S')
47. d2 = datetime.datetime.strptime(ldleSpeed_list[-1][2], '%Y-%m-%d %H:%M:%S')
48. d = d2 - d1
49. if d.seconds/3600 >4:
50. FatigueDriving_time_list.append(d.seconds/3600)
51. if line[5] == '1' and int(line[11]) > 0:
52. list4.append(line[3:5])
53. list4.append(line[10])
54. list4.append(line[11])
55. list4.append(line[2])
56. if line[5] == '0' and int(line[11]) > 0:
57. temp_list=[line[5],line[11]]
58. flameout_list.append(temp_list)
59. if len(list4) != 0 and len(lists) == 0:
60. lists.append(list4)
61. routeDate.append(lists[-1][0:2])
62. if len(lists) > 0 and len(list4) != 0:
63. if lists[-1][0] != list4[0]:
64. a = lists.append(list4)
65. d1 = datetime.datetime.strptime(lists[-2][1], '%Y-%m-%d %H:%M:%S')
66. d2 = datetime.datetime.strptime(lists[-1][1], '%Y-%m-%d %H:%M:%S')
67. d = d2 - d1
68. h = int(format(d.seconds)) / 3600
69. # print(format(d.seconds))
70. list1 = lists[-2][0]
71. list2 = lists[-1][0]
72. list1 = list(map(float, list1))
73. list2 = list(map(float, list2))
74. list1[0], list1[1] = list1[1], list1[0]
75. list2[0], list2[1] = list2[1], list2[0]
76. tup1 = tuple(list1)
77. tup2 = tuple(list2)
78. # 两个经纬度之间的距离
79. km = geodesic(tup1, tup2).km
80. v = km / h
81. v_list.append(v)
82. if h>4:
83. fatigue_list.append(h)
84. if v>120:
85. vv_list.append(v)
86. time_list.append(d.seconds)
87. a = (v_list[-1] - v_list[-2]) / time_list[-1]
88. temp_a=abs(a)
89. if temp_a>20:
90. a_list.append(a)
91. if int(lists[-1][-1]) in Interval(10, 45) and v_list[-1]>100:
92. changLane_list.append(1)
93. elif int(lists[-1][-1]) in Interval(46, 90) and v_list[-1]>80:
94. changLane_list.append(2)
95. elif int(lists[-1][-1]) in Interval(91, 180) and v_list[-1]>60:
96. changLane_list.append(3)
97. elif int(lists[-1][-1]) in Interval(181, 270) and v_list[-1]>40:
98. changLane_list.append(4)
99. elif int(lists[-1][-1]) in Interval(271, 360) and v_list[-1]>30:
100. changLane_list.append(5)
101. sizes=[len(FatigueDriving_time_list),len(vv_list),len(ldleSpeed_time_list),len(changLane_list),len(flameout_list),len(a_list)]
102. name=['FatigueDriving','Speeding','ldleSpeed','changLane','flameout','Accelerated']
103. explode = (0,0,0,0,0,0)
104. plt.figure()
105. plt.title(fileDir[17:24])
106. plt.pie(sizes, labels=name, autopct="%.2f%%", shadow=False, explode=explode)
107. plt.tight_layout()
108. plt.savefig('F:\\pycharm\\jiqi\\' + '不良驾驶行为饼图'+fileDir[17:24] + '.png')
109. plt.show()
110. print(str(fileDir) + "不良驾驶行为统计数据:" +"--疲劳驾驶次数:" + str(len(FatigueDriving_time_list))+"--超速行驶次数:"+str(len(vv_list))+"--急加速急减速次数:"+str(len(a_list))+"--急变道次数:"+str(len(changLane_list))+"--熄火滑行次数:"+str(len(flameout_list))+"--怠速次数:"+str(len(ldleSpeed_time_list)))
111. wb = Workbook()
112. ws = wb.active
113. ws.title = fileDir[17:24]
114. for i in range(len(name)):
115. ws.cell(row=1, column=i+1).value = name[i]
116. for i in range(len(FatigueDriving_time_list)):
117. ws.cell(row=i+2, column=1).value = FatigueDriving_time_list[i]
118. for i in range(len(vv_list)):
119. ws.cell(row=i+2, column=2).value = vv_list[i]
120. for i in range(len(ldleSpeed_time_list)):
121. ws.cell(row=i+2, column=3).value = ldleSpeed_time_list[i]
122. for i in range(len(changLane_list)):
123. ws.cell(row=i+2, column=4).value = changLane_list[i]
124. for i in range(len(flameout_list)):
125. ws.cell(row=i+2, column=5).value = flameout_list[i]
126. for i in range(len(a_list)):
127. ws.cell(row=i+2, column=6).value = a_list[i]
128. wb.save('F:\\pycharm\\jiqi\\' + '不良驾驶行为具体数据'+fileDir[17:24] + '.xlsx')
129. if __name__ == '__main__':
130. ff = ['AA00001', 'AB00006', 'AD00003', 'AD00013', 'AD00053', 'AD00083', 'AD00419', 'AF00098', 'AF00131', 'AF00373']
131. route_lists=[]
132. for i in ff:
133. fileDir = 'F:\\pycharm\\shuju\\' + i + '.csv'
134. route(fileDir)
emotionAnalysis.py
1. import re
2. import jieba
3. from gensim.models import word2vec
4. from nltk.classify import NaiveBayesClassifier
5. from sklearn import naive_bayes
6. from sklearn.model_selection import train_test_split
7. from sklearn.feature_extraction.text import CountVectorizer
8. import pandas as pd
9. def chinese_word_cut(mytext):
10. return " ".join(jieba.cut(mytext))
11.
12. #把停用词转换为一个列表存储
13. def get_custom_stopwords(stop_words_file):
14. with open(stop_words_file) as f:
15. stopwords = f.read()
16. stopwords_list = stopwords.split('\n')
17. custom_stopwords_list = [i for i in stopwords_list]
18. return custom_stopwords_list
19. df = pd.read_csv('test.csv')
20. X = df[['text']]
21. y = df.type
22. X['cut_text'] = X.text.apply(chinese_word_cut)
23. print(X.cut_text[:5])
24. X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.01, random_state=1)
25. stop_words_file = 'F:\python\数据分析结课实验\data/停用词.txt'
26. stopwords = get_custom_stopwords(stop_words_file)
27. vect = CountVectorizer()
28. print(type(X_train.cut_text))
29. term_matrix = pd.DataFrame(vect.fit_transform(X_train.cut_text[0:1000]).toarray(), columns=vect.get_feature_names())
30. for i in range(1000,len(X_train.cut_text),1000):
31. if 1000+i<len(X_train.cut_text):
32. term_matrix_temp = pd.DataFrame(vect.fit_transform(X_train.cut_text[i:1000+i]).toarray(), columns=vect.get_feature_names())
33. term_matrix.append(term_matrix_temp)
34. print(type(X_train.cut_text))
shuju.py
1. import csv
2. import datetime
3. from geopy.distance import geodesic
4. from geopy.distance import geodesic
5. import xlwings as xw
6. def route(fileDir):
7. temp_count_km=0
8. time=0
9. lists = []
10. dictt={}
11. routeDate=[]
12. v_list=[0]
13. time_list = [1]
14. with open(fileDir, "r") as csvfile:
15. reader = csv.reader(csvfile)
16. for j, line in enumerate(reader):
17. list4 = []
18. if line[5] == '1' and int(line[11]) > 0:
19. list4.append(line[3:5])
20. list4.append(line[10])
21. list4.append(line[11])
22. if len(list4) != 0 and len(lists) == 0:
23. lists.append(list4)
24. routeDate.append(lists[-1][0:2])
25. if len(lists) > 0 and len(list4) != 0:
26. if lists[-1][0] != list4[0]:
27. a = lists.append(list4)
28. d1 = datetime.datetime.strptime(lists[-2][1], '%Y-%m-%d %H:%M:%S')
29. d2 = datetime.datetime.strptime(lists[-1][1], '%Y-%m-%d %H:%M:%S')
30. d = d2 - d1
31. h = int(format(d.seconds)) / 3600
32. # print(format(d.seconds))
33. list1 = lists[-2][0]
34. list2 = lists[-1][0]
35. list1 = list(map(float, list1))
36. list2 = list(map(float, list2))
37. list1[0], list1[1] = list1[1], list1[0]
38. list2[0], list2[1] = list2[1], list2[0]
39. tup1 = tuple(list1)
40. tup2 = tuple(list2)
41. # 两个经纬度之间的距离
42. km = geodesic(tup1, tup2).km
43. v = km / h
44. v_list.append(v)
45. a = (v_list[-1] - v_list[-2]) / time_list[-1]
46. temp_count_km=km+temp_count_km
47. time=time+h
48. routeDate.append(lists[-1][0])
49. distance_v_a=[temp_count_km,v,a]
50. dictt[str(lists[-1][0:2])]=str(distance_v_a)
51. print(a)
52. with open('F:\\pycharm\\jiqi\\'+ fileDir[17:24]+'.txt','a+') as fw:
53. fw.write("汽车总行程公里"+str(temp_count_km)+"km \n"+"汽车总行驶时间:"+str(time)+"h \n"+"汽车总行程公里平均速度:"+str(temp_count_km/time)+"km/h \n"+"运输线路每个经纬度、时间及对应的行车里程、平均行车速度、急加速急减速情况:"+str(dictt))
54. fw.close()
55. return routeDate
56. if __name__ == '__main__':
57. ff = ['AA00001', 'AB00006', 'AD00003', 'AD00013', 'AD00053', 'AD00083', 'AD00419', 'AF00098', 'AF00131', 'AF00373']
58. route_lists=[]
59. for i in ff:
60. fileDir = 'F:\\pycharm\\shuju\\' + i + '.csv'
61. route_list=route(fileDir)
62. dict = {}
63. dict['name'] = fileDir
64. dict['path'] = route_list
65. route_lists.append(dict)
66. with open('F:\\pycharm\\jiqi\\'+'route.txt','a+') as fw:
67. fw.write(str(route_lists))
68. fw.close()
show1.py
1. import csv
2. import datetime
3. from geopy.distance import geodesic
4. from geopy.distance import geodesic
5. import xlwings as xw
6. import xlwt
7. from openpyxl import Workbook
8. wb = Workbook()
9. ws = wb.active
10. def route(fileDir):
11. ws.title = u'AA00001'
12. temp_count_km = 0
13. time = 0
14. lists = []
15. dictt = {}
16. llll = [['lng','lat','location_time','Driving mileage','Average speed','Rapid acceleration','count_km']]
17. routeDate = []
18. v_list = [0]
19. time_list = [1]
20. with open(fileDir, "r") as csvfile:
21. reader = csv.reader(csvfile)
22. for j, line in enumerate(reader):
23. list4 = []
24. if line[5] == '1' and int(line[11]) > 0:
25. list4.append(line[3:5])
26. list4.append(line[10])
27. list4.append(line[11])
28. if len(list4) != 0 and len(lists) == 0:
29. lists.append(list4)
30. routeDate.append(lists[-1][0:2])
31. temp_list=[line[3],line[4],line[10],0,0,0,0]
32. llll.append(temp_list)
33. if len(lists) > 0 and len(list4) != 0:
34. if lists[-1][0] != list4[0]:
35. a = lists.append(list4)
36. d1 = datetime.datetime.strptime(lists[-2][1], '%Y-%m-%d %H:%M:%S')
37. d2 = datetime.datetime.strptime(lists[-1][1], '%Y-%m-%d %H:%M:%S')
38. d = d2 - d1
39. h = int(format(d.seconds)) / 3600
40. # print(format(d.seconds))
41. list1 = lists[-2][0]
42. list2 = lists[-1][0]
43. list1 = list(map(float, list1))
44. list2 = list(map(float, list2))
45. list1[0], list1[1] = list1[1], list1[0]
46. list2[0], list2[1] = list2[1], list2[0]
47. tup1 = tuple(list1)
48. tup2 = tuple(list2)
49. # 两个经纬度之间的距离
50. km = geodesic(tup1, tup2).km
51. v = km / h
52. v_list.append(v)
53. a = (v_list[-1] - v_list[-2]) / time_list[-1]
54. temp_count_km = km + temp_count_km
55. time = time + h
56. # routeDate.append(lists[-1][0])
57. distance_v_a = [temp_count_km, v, a]
58. temp_list = [lists[-1][0][0], lists[-1][0][1], lists[-1][1],km, v, a, temp_count_km]
59. llll.append(temp_list)
60. # dictt[str(lists[-1][0:2])] = str(distance_v_a)
61. wb.save('test.xlsx')
62. return llll
63. if __name__ == '__main__':
64. ff = ['AA00001', 'AB00006', 'AD00003', 'AD00013', 'AD00053', 'AD00083', 'AD00419', 'AF00098', 'AF00131', 'AF00373']
65. route_list = route('F:\\pycharm\\shuju\\AA00001.csv')
66. wb = Workbook()
67. ws = wb.active
68. ws.title = u'AA00001'
69. i = 1
70. r = 1
71. for line in route_list:
72. for col in range(1, len(line) + 1):
73. ColNum = r
74. ws.cell(row=r, column=col).value = line[col - 1]
75. i += 1
76. r += 1
77. # 工作簿保存到磁盘
78. wb.save('test.xlsx')
欢迎大家加我微信学习讨论
