CVPR2022Oral专题系列(三):图像增强主干网络MAXIM

图1.MAXIM主干网络示意图。
目录
一. 简介
二. 多轴MLP
三. 交叉结构MLP
四. 实验结果
五. 总结
Reference
一. 简介
随着Transformer和多层感知机技术的普及,一些过去难以解决的计算机视觉问题,能够被处理,并在实际的应用中加以使用。但是,这里仍然存在一些挑战,包括:对高分辨率图像的兼容性较差;对局部注意力缺乏有效的处理方法。今天,我们来介绍一篇CVPR2022Oral论文,即多轴MLP结构(MAXIM)[1],以解决上述问题。MAXIM构建一个多轴MLP的网络结构,作为一个新的主网络的骨架,用于解决一般性视觉任务。该结构使用了一个类UNet的多层级联并支持长距离交互。具体来说,MAXIM包含两个基于MLP的blocks:一个多轴控制MLP,用于提供高效的局部全局混合视觉线索;一个交叉控制block,用于替换用于交叉特征调整的交叉注意力机制。上面的两个模块都是基于MLP,也继承了全连接层的优点,因此对于图像处理任务具有不错的优势。实验证明,相比目前已经存在的主干网络,MAXIM对于一般的视觉任务均有不错的性能,包括去噪,去模糊,以及其他图像增强任务。总结,MAXIM提出了多轴结构MLP和交叉结构MLP以构建自身的主干网络结构,以平衡全局与局部特征的关系,并解决高分辨率图片的处理问题。
二. 多轴MLP
多轴(Multi-axis)MLP结构用于同时捕获局部和全局的交互,通过为每个branch混合在每个轴上的信息,使得基于MLP的操作变成了一个全连接的结构,在尺度上与图像的size线性相关。这明显的增加了该结构的灵活性,以便于处理高分辨率图片。该想法受到工作[2]的启发,在两个轴上计算注意力。在两个轴上的注意力关联于稀疏的两种自注意力形式,取名为区域性和扩张性注意力。尽管该结构能够同时捕获全局与局部的信息,它对于图像的尺寸是敏感的。

图2.多轴MLP结构。
MAXIM重新设计了多轴结构MLP用于解决该问题。通过构建一个多轴门控MLP块来实现该目标,其结构如图2所示。相比于工作[2],MAXIM首先将头(这个Head,是将原图shape成一个6*4*C的东西后,切成两个6*4*C/2之后的东西)切成两半,每一个都独立分区。在局部的branch,半个头的特征(H,W,C/2)被封装成一个张量的形状(H/b*W/b,b*b,C/2),表示分割到一个没有重叠的窗口(b*b),在全局branch,另一半头被网格化成(d*d,H/d*W/d,C/2),网格的尺度固定(d*d),每一个窗口的size为(H/d*W/d)。对于可视化,我们设置b=2,d=2,见图2。为了使得该机构具有全连接功能,MAXIM只在对应branch的单轴上应用gMLP[3]块,第二个轴对应局部的branch,第一个轴对应全局的branch,并且与其他的轴共享参数(这里我理解其他的轴,就是另外一个轴的意思,因为全文安,只有两个轴)。直觉上,并行应用多轴 gMLP 能够对应空间信息的局部和全局(扩张)混合。最后被处理的head被组合,并通过从输入获得的long ship-connection以减少通道数。值得一提的优点是通过处理固定尺寸的图像patch来避免人造patch边界。
这里写点我对多轴MLP结构的阅读感受。虽然基本没看懂实现细节,但是感觉作者是想把全局编码后的多层表示切成两个部分来分别做MLP,一个专注做局部特征的学习,一个做全局特征的学习。这样做的好处是,由于是从一个head切成的两个部分,使得两部分本身就保持了内部的关联。然后对每一个部分独立做计算,使得能够平衡多个任务目标。共享权重是一个符合直觉的设计,使得在融合过程更加自然。
三. 交叉结构MLP
对于传统UNet的一个基本的改善方法是使用skip-connections[4]。MAXIM基于该思路,设计了一个cross-gating block(CGB),作为multi-axis gated MLP block(MAB)的扩展。CGB能够被认为是一个通用的条件层,实现多特征交互。具体来说,让X,Y作为两个输入特征,X_1,Y_1\in R^{H*W*C}作为估计特征由第一个稠密层实现(图1C)。输入的估计被应用于:

σ表示GELU激活[5],LN是归一化层[6]。W_1和W_2是MLP预测度量。MAB权重由X_2和Y_2计算获得,但会相互作用:
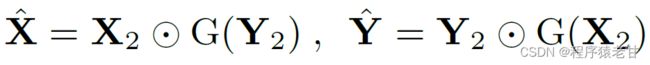
运算符表示逐元素乘法,函数G利用多轴MLP从输入中提取CGB权重:

[.,.]表示融合。(z_1, z_2)是两个独立的分割头,获取自Z的对应通道维度。z表示经过激活项的预测特征x,表示为:

W_3和W_4为空间预测度量应用于第一个和第二个轴上的块或网格特征(具有固定的窗口尺寸,block:b*b;grid:d*d)。最后,MAXIM从输入使用一个残差连接,紧跟着一个输出通道预测,以保留于输入(X_1,Y_1)相同的通道维数。使用预测度量W_7和W_8,表示为:

这里感觉是对两个独立的特征分析做信息交换,直觉上觉得这个东西可以用在图像多帧合成的相关应用,让多帧交叉的应用CGB,可能由不错的效果,当然这是纯瞎想。
之后,MAXIM还应用了一个Multi-Stage Multi-Scale框架,以解决高分辨率图像处理问题。简单说,就是用上下采样对应,建立损失函数,以实现对图片尺度的处理。因为这部分内容并非本文的精髓,这里不再赘述。
四. 实验结果
这里展示MAXIM在几个视觉任务中的效果:

图3.去噪结果对比。

图4.去模糊结果对比。
图5.去雨结果对比。 
图6.去雾结果对比。
图7.低光增强结果对比。
五. 总结
我对MAXIM的理解是,设计了一个双通道特征处理结构,使得针对同一幅图片,通过编码切成一组特征图,然后一分为二,一部分针对局部优化,一部分针对全局优化。这样做的好处是,由于是从一幅图的特征图里切出来的两个branch,那么就不存在对准问题,使得两个branch天然具有准确的对应关系。之后,针对两个branch做全局与局部的学习,而后做融合,这样的结果更准确。至于其他的内容,基本上是用来提升性能的微调。
Reference
[1] Tu Z, Talebi H, Zhang H, et al. Maxim: Multi-axis mlp for image processing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 5769-5780.
[2] Long Zhao, Zizhao Zhang, Ting Chen, Dimitris N Metaxas, and Han Zhang. Improved transformer for high-resolution gans. arXiv preprint arXiv:2106.07631, 2021. 3.
[3] Hanxiao Liu, Zihang Dai, David R So, and Quoc V Le. Pay attention to mlps. arXiv preprint arXiv:2105.08050, 2021.1, 2, 3, 4, 8.
[4] Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee,Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, et al. Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999, 2018. 3, 4.
[5] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016. 4.
[6] Vladimir Bychkovsky, Sylvain Paris, Eric Chan, and Fr´edo Durand. Learning photographic global tonal adjustment with a database of input/output image pairs. In CVPR, pages 97–104. IEEE, 2011. 1, 5, 6, 8.