基于YOLOV5的目标检测模型-口罩检测
好文章
在学习的时候参考了许多大佬的文章,我会在下面一 一列出来
1.手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测-视频教程_肆十二的博客-CSDN博客_opencv yolo训练自己模型
2.Yolov5训练自己的数据集(详细完整版)_缔宇diyu的博客-CSDN博客_yolov5训练自己的数据集
3.【Yolov5】1.认真总结6000字Yolov5保姆级教程(2022.06.28全新版本v6.1)_若oo尘的博客-CSDN博客_查看yolov5版本
出现的问题
本人在训练过程碰到许多奇怪的问题,我会统一放在文末并且不断补充的
由于本文是自己记录向,所以直白的话比较多
环境配置
1.本人使用的是Anaconda+Pycharm的配置,在安装过程中有许多指令,需要自己去学习了解。
Anaconda官网Anaconda | The World's Most Popular Data Science Platform
Pycharm官网PyCharm: the Python IDE for Professional Developers by JetBrains
这两个的安装都很简单,一直点下一步就行了
2.在github上下载YOLOv5的源码
GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite,csdn有加速,速度应该不慢。
3.在Anaconda创建虚拟环境
conda create -n test python==3.8.5 #创建叫test的环境
conda activate test #进入环境
4.安装pytorch
pytorch的官网PyTorch

本人使用的是CUDA 11.7的版本,训练用的是gpu,cpu的速度据说是有点慢,我也懒得等,如果没用gpu的好兄弟也可以使用云服务器来跑训练集
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia5.安装其他工具包
pip install -r requirements.txt
pip install labelme
测试YOLOv5和其他工具包是否完成安装
1.先下载YOLOv5的官方预训练权重 ,按图片来就行了

这里我们下载yolov5s6.pt,下载完之后在yolov5的文件目录下创建一个叫weights的权重文件夹

使用cmd,进入test环境后cd到yolov5的目录下,运行以下代码
python detect.py --source data/images/bus.jpg --weights weights/yolov5s6.pt
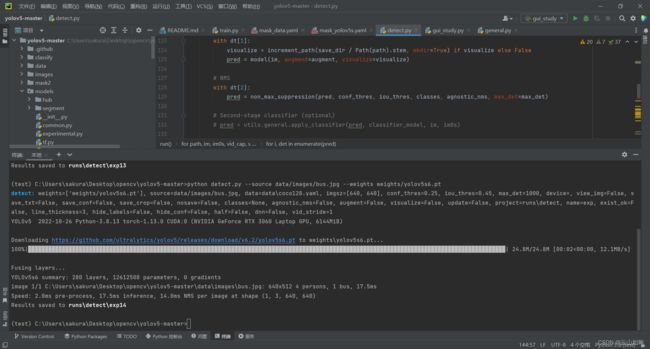
就可以得到运行的结果,至此说明前面的环境配置有部分是正确的
这部分代码在官方的detect.py文件中可以看到

收集并且处理数据
收集(自己上网找或者爬虫爬喽,好像有人出售来着)
在cmd中使用pip命令进行下载 pip install labelimg (要先进入环境) 如果速度太慢可以进行换源,网上教程很多,我就不多加赘述了
下载后直接输入labelimg就可以打开了,网上关于labelimg的使用方法很多,我简单讲点快捷键(标注过程中用的多的)
数据集的结构如下(才疏学浅,用excel给各位见笑了)
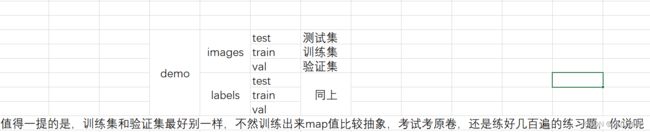
还是要再强调一遍,考试别考原卷!awa
训练出相应的模型
1.我们要建立一个.yaml文件,里面说明我们的训练集和验证集的路径,数据集的类别和名称
我的路径如下C:\Users\sakura\Desktop\opencv\yolov5-master\data\mask_data.yaml

2.复制yolov5s.yaml文件,自己修改名字,然后把数据集的类别修改成你自己标注后的数据数量 C:\Users\sakura\Desktop\opencv\yolov5-master\models\yolov5s.yaml

然后输入
python train.py --data 第一次建立的文件.yaml --cfg 第二次建立的文件.yaml --weights weights/yolov5s.pt --epoch 100 --batch-size 4 --device 0就可以开始训练了,对于以上参数,在train.py中都可以找到,这里我把他归纳出来

模型的使用
这是参数和默认值
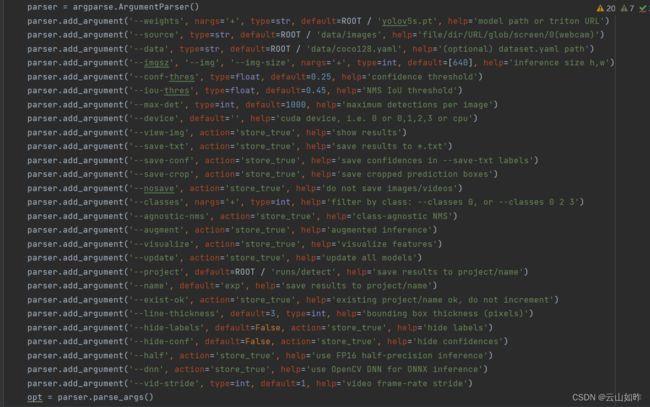
# 检测摄像头
python detect.py --weights runs/train/训练出来的exp名/weights/best.pt --source 0 # webcam
# 检测图片文件
python detect.py --weights runs/train训练出来的exp名/weights/best.pt --source file.jpg # image
# 检测视频文件
python detect.py --weights runs/train/训练出来的exp名/weights/best.pt --source file.mp4 # video
# 检测一个目录下的文件
python detect.py --weights runs/train/训练出来的exp名/weights/best.pt path/ # directory
# 检测网络视频
python detect.py --weights runs/train/训练出来的exp名/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video
# 检测流媒体
python detect.py --weights runs/train/训练出来的exp名/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
值得一提的是exp的weights里面有两个文件,分别是last和best,last是最后一次训练得到的文件,best是表现最好的一次训练得到的文件
发现的问题
1.cuda的版本和pytorch不同

我们可以发现这里cuda是11.8,我也不知道哪次更新的时候变成这样了,我安装的是cuda11.3。然后我不能下载版本太低的pytorch,最后我下的是pytorch的支持cuda11.6的版本(就很6,没有支持cuda11.8的pytorch)
2.Pillow包经常出报错
删了重新下,应该都会把,不会网上查也有