西瓜书学习第五章---神经网络
神经网络
- 一、神经网络简介
-
- 1.1 神经元模型
- 1.2 神经网络的工作模式
- 二、感知机与多层网络
-
- 2.1 感知机
- 2.2 多层网络
- 三、BP算法
- 四、全局最小和局部最小
-
- 4.1 全局最小
- 4.2 局部最小
- 4.3 跳出局部最小的常用方法
- 五、几种常见的神经网络
-
- 5.1 RBF网络
- 5.2 ART网络
- 5.3 其他神经网络
一、神经网络简介
定义: 普遍采用的定义是“神经网络是指具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反映”
1.1 神经元模型
生物神经网络: 各神经元之间相互连接,某一个神经元兴奋的时候,就会向临近的神经元发送能够改变其电位的化学物质,如果这些神经元的电位超过一个固定的值,那么就会变成激活态,向自己相连的神经元发送一样的化学物质,以此类推,直至产生最终结果
人工神经网络: 人工神经网络里面的神经元模型使用最广泛的是M-P神经元模型 ,这一模型是生物神经网络的抽象表示,即某一神经元收到来自其他神经元传递的输入数据,这些数据是样本数据和连接权重的线性组合,神经元在收到这些数据之后与自身的阈值所比较,满足条件之后通过激活函数对计算结果进行逼近,M-P神经元模型的图解如下:

激活函数: 激活函数可以将输入的线性关系映射成非线性关系或者更加复杂的关系,使神经网络能够逼近任意非线性函数,让我们的神经网络能够处理更加复杂的问题
- 理想中的激活函数
理想的激活函数可以直接将输入数据映射为0或者1,这种函数被成为阶跃函数
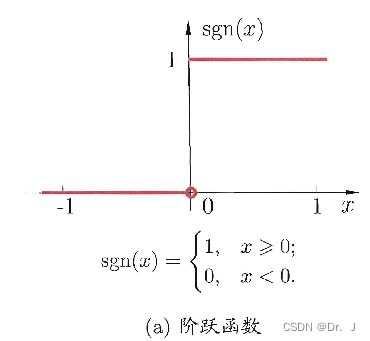
但是阶跃函数是一种分段函数,且不够光滑,对神经网络的优化并不方便
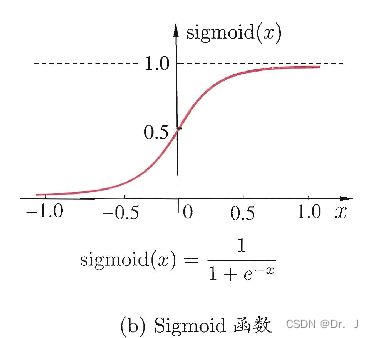
2. 使用较为广泛的是sigmoid函数 ,这是一种能够将很大的数值压缩到(0,1)之间的函数,函数图像如图:
3. 目前常用的激活函数还有ReLU(修正线性单元)
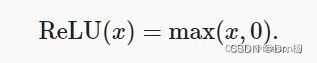
其图像为:
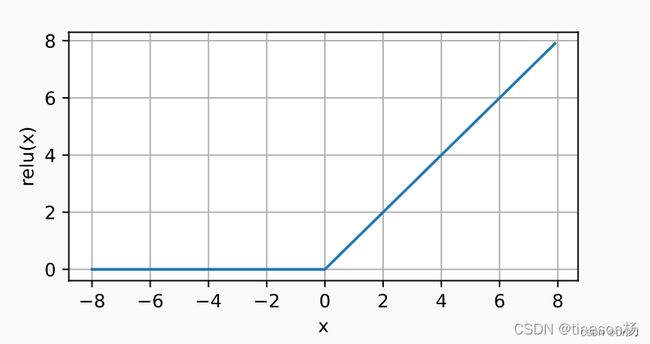
ReLU函数 受到欢迎的主要原因是其训练较为简单,而且在求导的过程中表现的很好,其导数形式为:

可以看出其在求导的时候要么直接保留参数,要么通过0将参数消失,可以在优化的过程中取得更好地效果
上述两张图片来源于网络https://blog.csdn.net/qq_58462637/article/details/123671428
1.2 神经网络的工作模式
将许多个包含激活函数的神经元按照一定的方式连接起来,比如二部图方式,全连接方式等等,就组成了神经网络,事实上我们可以将神经网络看做一个包含了很多参数的数学模型,这个模型是由许多函数互相嵌套组合而成的
二、感知机与多层网络
2.1 感知机
基本概念: 传统感知机的结构是非常简单的,只包含两层神经元——输入层和输出层,输出层的神经元模式是传统的M-P模式,输出层负责接收外部信号,具体如下图:

感知机的训练 :给定训练集之后,通过权重更新规则在迭代过程中调整权重,从而训练出权重w以及阈值 θ \theta θ ,具体的更新规则如下,其中 η \eta η是学习率,通常设为0.1, y ~ \tilde{y} y~是感知机的输出
w i ← w i + Δ w i w i = η ( y − y ~ ) x i \begin{align} _{w_{i}}\overset{}{\leftarrow}_{_{w_{i}}}+\Delta _{w_{i}}\tag{1}\\ _{w_{i}}=\eta \left ( y-\tilde{y}\right ){x_{i}}\tag{2}\\ \end{align} wi←wi+Δwiwi=η(y−y~)xi(1)(2)
根据上式能够看出,如果感知机预测正确,则权重不发生变化,否则根据误差大小来进性参数更新
感知机的缺陷: 感知机的学习能力主要受限于有限的神经元层,其只有输出层神经元包含激活函数,而且只有线性可分的问题感知机能够解决的很好,否则就不会得到一个收敛的结果,比如感知机可以很好的解决与、或、非的问题,因为他们是线性可分的(即可以用一个超平面将其划分为两类),具体见下图,红线即为训练所学到的超平面


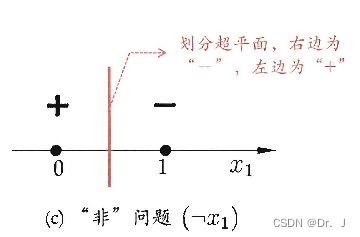
具体的计算过程见西瓜书p99
2.2 多层网络
多层网络可以解决非线性可分的问题,在传统感知机的输出层和输入层之间加入隐层,隐层也是包含激活函数的

上图中的神经网络同层之间的神经元是没有连接的,与下一层的神经元处于全连接状态,这种神经网络又被叫做 “多层前馈神经网络”,下图是较为复杂的多层前馈神经网络

所以综上可以看出,神经网络的学习就是通过训练集在规定的训练次数中来对连接权值以及阈值进行更新,最终收敛得到一个完整的神经网络
三、BP算法
BP算法是众多神经网络训练算法中使用最广泛的
BP算法的流程
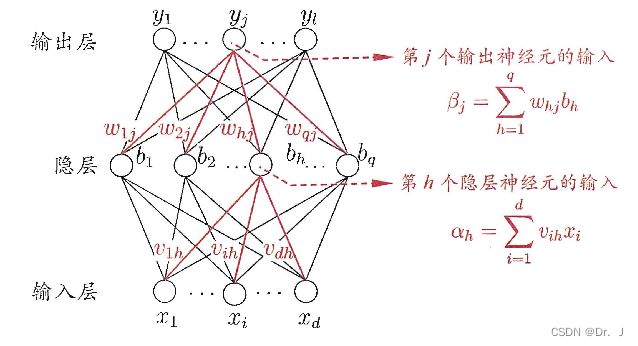
- 神经网络的符号定义
训练集D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . ( x m , y m ) } \left\{ ( x_{1},y_{1} \right ),\left ( x_{2},y_{2} \right ),...\left ( x_{m},y_{m} \right )\} {(x1,y1),(x2,y2),...(xm,ym)}
,且输入样本是d维,输出值为l维
q q q : 隐层神经元个数
\theta_{j}: 输出层第 j ~ \tilde{j} j~个神经元的阈值
γ h \gamma_{h} γh:隐层第 h h h个神经元的阈值
ν i h \nu_{ih} νih:输入层第 i i i个神经元与隐层第 h h h个神经元之间的连接权
ω h j \omega_{hj} ωhj:隐层第 h h h个神经元与输出层第 j j j个神经元之间的连接权
α h = ∑ i = 1 d ν i h x i \alpha_{h}= \sum_{i=1}^{d}\nu _{ih} x_{i} αh=∑i=1dνihxi:隐层第 h h h个单元收到的输入数据
β j = ∑ h = 1 q ω h j b h \beta_{j}= \sum_{h=1}^{q}\omega_{hj} b_{h} βj=∑h=1qωhjbh:输出层第 j j j个神经元收到的输入数据
b h b_{h} bh:隐层第 h h h个神经元的输出
y ^ j k \hat{y}_{j}^{k} y^jk:神经网络的最终输出数据,且 y ^ j k = f ( β j − θ j ) \hat{y}_{j}^{k}=f(\beta_{j}-\theta_{j}) y^jk=f(βj−θj)
E k = 1 2 ∑ j = 1 l ( y j k − y j k ^ ) 2 E_{k}=\frac{1}{2}\sum_{j=1}^{l}\left ( \hat{y_{j}^{k}-y_{j}^{k}} \right )^{2} Ek=21∑j=1l(yjk−yjk^)2:神经网络在单个训练样本的均方误差
学习率: 负责控制每一步迭代的步长,学习率过高可能会导致震荡,过低会使神经网络收敛速度过慢,所以通常采用动态调整的方式
下图为两层前馈神经网络的图示:
2. BP算法的优化目标
BP算法的优化就是最小化训练集上的误差函数
3. 训练过程
BP算法基于梯度下降算法,使用广义的感知机学习规则来对权重和阈值进行更新
以 w h j w_{hj} whj的更新为例:
- 在一定学习率的前提下,用误差函数 E k E_{k} Ek对所要更新的参数求偏导:

- 由于这个误差函数由多个参数所组成,所以其是一个复合函数,在求导过程中需要用到链式求导法则,如下图:

- 根据给定的数据,能求得 ∂ β j ∂ w h j = b h \frac{\partial \beta _{j}}{\partial w_{hj}} = b_{h} ∂whj∂βj=bh
且令
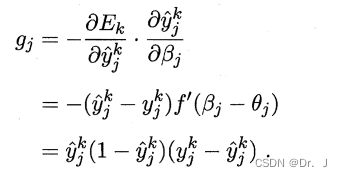
4. 所以最后可求得 Δ ω h j = η g i b h \Delta\omega _{hj} =\eta g_{i}b_{h} Δωhj=ηgibh,神经网络中其他参数的更新也是类似,核心就是链式求导法则,BP算法的工作原理可以概括为下图流程:

- 累积BP算法和标准BP算法
累积BP算法对整个数据集的误差直接进行最小化,会导致优化速度很慢,而标准BP算法先对单个样本误差进行最小化然后依次迭代,最终效果比累积BP算法要好 - BP算法的过拟合解决方案
1.早停法
将数据分为训练集和验证集,训练集用来更新权重,验证集则负责对每次更新完成之后的误差进行计算,当出现验证误差过高时便停止训练
2. 正则化
通过调和的方式使神经网络中的参数不会出现过拟合
四、全局最小和局部最小
4.1 全局最小
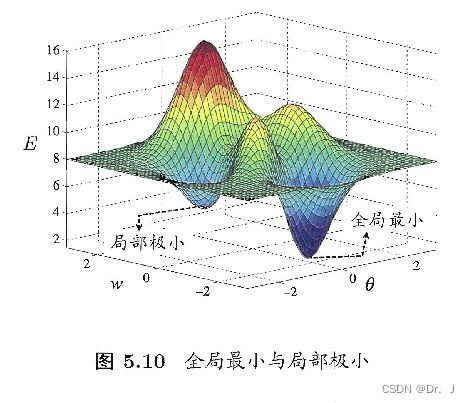
具体就是指参数空间中的任何一对权重和阈值参数都能够使误差函数小于其他参数对的误差函数值,这就是全局最小
4.2 局部最小
参数空间中某一对参数值所求出的误差函数值在这一对参数值的领域中是最小的,这就是局部最小
具体可以看下图,图中最低峰的点既是全局最小,也是它领域的局部最小:
4.3 跳出局部最小的常用方法
- 神经网络的参数值进行多次初始化,根据标准BP算法训练完毕之后,取误差最小的作为最终神经网络模型的参数
- 模拟退火:这种方法的原理是每一步都以一定概率接受比当前解更差的结果,但是随着训练次数的增加,这一概率必须要减少,不然就会无法收敛
- 使用SGD算法
- 遗传算法
五、几种常见的神经网络
5.1 RBF网络
这是一种单隐层的前馈神经网络,它的激活函数叫做径向基函数,是一种沿着径向对称的标量函数,一般地,都将其定义为样本到数据中心的欧氏距离的单调函数,其模型为:
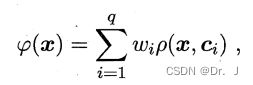
其中 q q q是隐层神经元个数, c i c_{i} ci和 w i w_{i} wi分别表示第 i i i个隐层神经元对应的中心和权重, ρ ( x , c i ) \rho\left ( x,c_{i} \right ) ρ(x,ci)就是径向基函数,使用最广泛的是高斯径向基函数:
ρ ( x , c i ) = e − β i ∥ x − c i ∥ 2 \rho\left ( x,c_{i} \right ) = e^{-\beta _{i}\left\| x-c_{i}\right\|^{2}} ρ(x,ci)=e−βi∥x−ci∥2
5.2 ART网络
这种网络的特点是无监督性,网络的输出层单元是竞争关系,且每时刻只有一个获胜者可以被激活,其余的神经元处于被抑制状态,而且根据可以根据一定的阈值进行神经元数目的动态增加,ART网络属于一种结构自适应的神经网络
5.3 其他神经网络
神经网络种类很多,不做一一介绍,其中波尔曼兹机较为重要,详细见西瓜书p111,这里不做介绍