【电商数仓】日志采集架构设计原理、系统表结构解析、数仓分层相关概念、范式理论详解
文章目录
- 一 日志采集架构设计原理
-
- 1 为什么使用Flume将数据生产进kafka
- 2 为什么还需要一个消费的Flume
- 3 深入细节
- 4 业务日志采集
- 二 电商系统表
-
- 1 后台管理系统
- 2 电商业务表
- 三 数仓分层
-
- 1 分为哪几层
- 2 为什么要分层
- 3 数据集市与数据仓库区别
- 4 数仓命名规范
-
- (1)表命名
- (2)脚本命名
- (3)表字段类型
- 四 数仓理论
-
- 1 范式理论
-
- (1)范式概念
- (2)函数依赖
-
- 完全函数依赖
- 部分函数依赖
- 传递函数依赖
- (3)三范式区分
-
- 第一范式
- 第二范式
- 第三范式
一 日志采集架构设计原理
数仓存储了一个公司所用到的所有数据,将数据做集中的存储,统一的指标分析,不会涉及后续复杂的分析,但可以为后续复杂的分析做准备,如公司内部的机器学习部门,机器学习所用到的所有数据会来自于数仓。
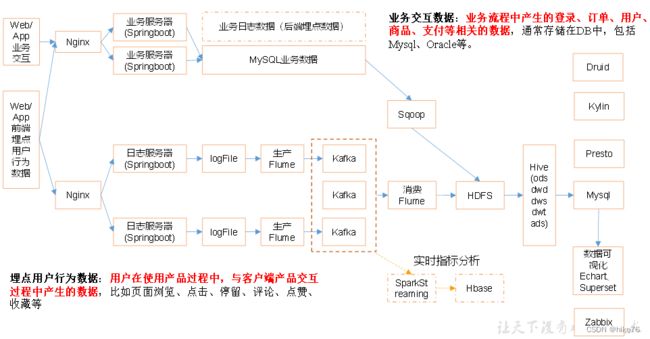
MySql存储的数据为结构化数据,也可以叫做业务数据,传统的JavaEE项目只有这一种数据。在大数据时代到来后,有了用户画像等需求,所以产生了用户行为数据。
那么这时就需要考虑一个问题,如何将公司的业务数据,导入到大数据的存储体系中,也就是HDFS,对于业务数据的采集和保存,JavaEE有一套自己成熟的体系,在这里不需要考虑。
而对于用户行为数据,需要考虑
- 用户行为数据是什么样子的数据 – json
- 如何收集 --> 埋点
- 如何采集 --> 客户端源源不断地将用户的数据通过APP收集进来,形成文件。使用Flume写入到kafka,再使用kafka写入到HDFS
- 采集完成后如何保存到HDFS --> 使用FLume
1 为什么使用Flume将数据生产进kafka
生产Flume使用Taildir Source,这种Source Flume自动将数据写到HDFS,速率可控,Sink写得慢,Flume采集的就慢,所以添加kafka不是为了增加Flume的采集日志的速率。
kafka作为一个消息队列,最大的特点是可以一对多,如果将logFile直接放到HDFS,那么其他人想要使用这些数据,只能从HDFS读取,HDFS的吞吐量不如kafka高。添加了kafka不只是离线项目可用,实时指标分析也可以从kafka中直接读取数据,真正形成流批一体,在线分析与离线分析使用的都是同一份数据源。
放到kafka中的数据为了后续的分析,还是要写入到HDFS。
2 为什么还需要一个消费的Flume
kafka 是一个消息队列,核心任务是中间的存储消息,临时存储以下,作为临时消息队列。
Flume 根本目的是将消息从A 搬运到 B,核心任务是对于头尾地采集。
如果不用Flume,也可以将数据存储到kafka,开文件流,一行一行放到kafka。
Flume的好处是它有很多插件,无论什么样的Source 和 Sink ,都可以使用Flume连接起来,十分方便。
3 深入细节
生产Flume的结构:Taildir Source – kafka Channel
消费Flume的结构:kafka Channel – File Channel – HDFS Sink
上游Flume结构使用Taildir Source – File Channel – kafka Sink 也可以,但是多了一层 File Channel,复杂度上升,效率也会降低,所以采用了Taildir Source – kafka Channel,这种结构上游的采集速度是十分高的,因为kafka Channel 效率非常高,完全可以覆盖Taildir Source 的读取速度。
下游Flume直接使用 kafka Channel – HDFS Sink不行,因为在下游存在一个拦截器。上游同样存在一个拦截器,ETL拦截器,数据的格式为json,通过ETL将所有不是json格式的数据过滤掉。下游拦截器称为TimeStamp,为了解决“零点漂移“,也就是昨天的日志需要昨天收集。日志产生的时间是23.59分,经过采集日志到达系统的时间为0.01分,系统需要将这条日志当做昨天的日志,以产生时间为准。下游的Flume从kafka消费完数据,变为Event,给Event添加一个TimeStamp时间戳,在向HDFS写的时候,可以写到昨天的文件夹中。
如果不用TimeStamp时间戳,可以不用File Channel。TimeStamp可以放在上游,TimeStamp的作用是在Event 的header部分添加一个时间戳的KV对,如果放在上游,上游Flume产生的所有数据Event都是带Header的,那么在向kafka写的时候,也需要带Header,但是带Header会产生一个问题,上游采集的是json格式数据,是通用的数据,在上游Flume后接一个kafka的作用是方便数仓其他结构使用这个数据,其他人使用数据当然希望这个数据是通用类型数据,方便处理,而event是Flume私有数据格式,所以将TimeStamp放在下游方便数据的处理,放在kafka中的数据一定要是通用格式,不能是event格式。
改进的方案:也可以不使用Flume的拦截器,可以使用kafka的拦截器实现TimeStamp时间戳,但是kafka拦截器的代码十分复杂,且会在执行过程中申请大量的对象,在数据高峰期,可能会导致大量的垃圾回收,性能不一定会比带File Channel的高。使用kafka Channel – File Channel – HDFS Sink 这种结构,代码比较少,比较方便,代价是系统的性能会降低一些,但足够,稳定性也还可以。
4 业务日志采集

业务日志是公司内部成熟的业务系统里面的数据,大部分都是存储在MySQL中,关键问题就是如何将MySQL中的数据存放到HDFS上,使用Sqoop。Sqoop的数据一天采集一次,采集完成后直接放到HDFS。
这时,数仓的其他结构也可能会使用到业务数据,如实时平台,这样就可以直接将MySQL中的数据,暂时存放到kafka,之后通过下游Flume一并写入到HDFS。
二 电商系统表
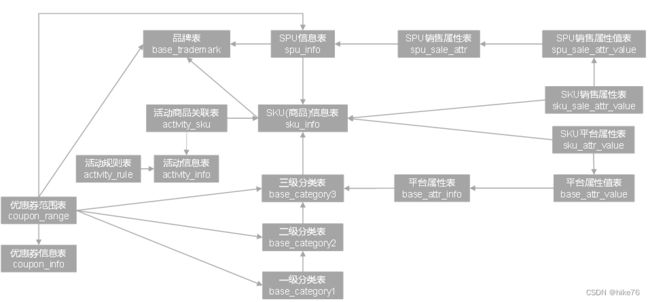
1 后台管理系统
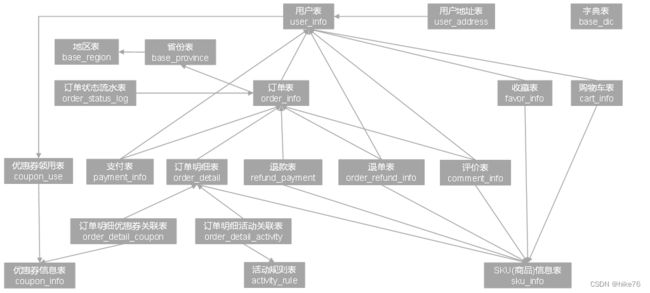
2 电商业务表
三 数仓分层
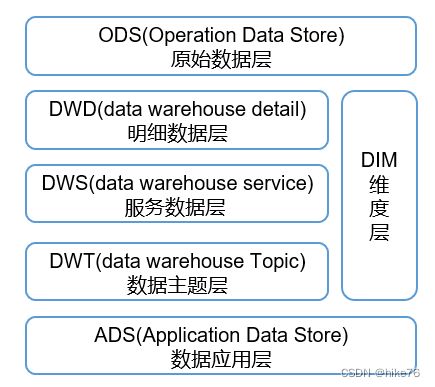
1 分为哪几层
-
ODS层:原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
-
DWD层:对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)、脱敏等。对数据进行重新规划和建模,保存业务事实明细,一行信息代表一次业务行为,例如一次下单。
-
DIM层:维度层,保存维度数据,主要是对业务事实的描述信息,例如何人,何时,何地等。
-
DWS层:以DWD为基础,按天进行轻度汇总。一行信息代表一个主题对象一天的汇总行为,例如
一个用户一天下单次数。
-
DWT层:以DWS为基础,对数据进行累积汇总。一行信息代表一个主题对象的累积行为,例如一个用户从注册那天开始至今一共下了多少次单。
-
ADS层:为各种统计报表提供数据。
2 为什么要分层
- 把复杂问题简单化:将复杂的任务分解成多层来完成,每一层只处理简单的任务,方便定位问题。
- 减少重复开发:规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
- 隔离原始数据:不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
不同的数仓可能分层会不同,但无论怎么分层,主要原因都是以上三点。
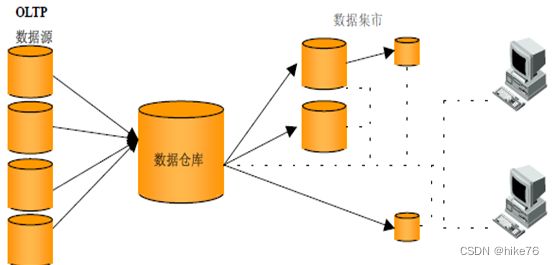
3 数据集市与数据仓库区别
数据集市(Data Market),现在市面上的公司和书籍都对数据集市有不同的概念。
数据集市则是一种微型的数据仓库,它通常有更少的数据,更少的主题区域,以及更少的历史数据,因此是部门级的,一般只能为某个局部范围内的管理人员服务。
数据仓库是企业级的,能为整个企业各个部门的运行提供决策支持手段。
4 数仓命名规范
如果数据命名没有一个统一的规范,那么hive在join时,join的字段不一致会出现严重的问题,并且十分不容易排查,如一串String类型数据,只看表面无法分辨出是哪种类型,这时因为数据类型不一致,join就会出现问题,为开发带来阻碍。
(1)表命名
- ODS层命名为ods_表名
- DIM层命名为dim_表名
- DWD层命名为dwd_表名
- DWS层命名为dws_表名
- DWT层命名为dwt_表名
- ADS层命名为ads_表名
- 临时表命名为tmp_表名
(2)脚本命名
- 数据源_to_目标_db/log.sh
- 用户行为脚本以log为后缀;业务数据脚本以db为后缀。
(3)表字段类型
-
数量类型为bigint
-
金额类型为decimal(16, 2),表示:16位有效数字,其中小数部分2位
decimal 可以理解为精度很高的浮点数
-
字符串(名字,描述信息等)类型为string
-
主键外键类型为string
-
时间戳类型为bigint
四 数仓理论
1 范式理论
范式:数据库建模需要遵循的规范。
(1)范式概念
- 定义:数据建模必须遵循一定的规则,在关系数建模中,这种规则就是范式。
- 优点:采用范式,可以降低数据的冗余性。
- 为什么要降低数据冗余性
- 十几年前,磁盘很贵,为了减少磁盘存储。
- 以前没有分布式系统,都是单机,只能增加磁盘,磁盘个数也是有限的
- 一次修改,需要修改多个表,很难保证数据一致性
- 缺点:范式的缺点是获取数据时,需要通过Join拼接出最后的数据。
- 分类:目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
(2)函数依赖
想要理解范式,就需要理解什么是函数依赖。
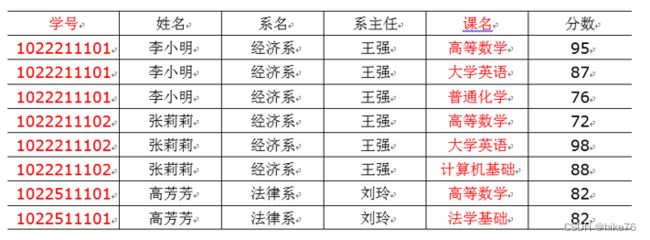
完全函数依赖
设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。记做:![]()
通俗理解:比如通过,(学号,课程) 推出分数 ,但是单独用学号推断不出来分数,那么就可以说:分数
完全依赖于(学号,课程) 。即:通过AB能得出C,但是AB单独得不出C,那么说C完全依赖于AB。
部分函数依赖
假如 Y函数依赖于 X,但同时 Y并不完全函数依赖于 X,那么就称 Y 部分函数依赖于 X,记做:![]()
通俗理解:比如通过,(学号,课程) 推出姓名,因为其实直接可以通过,学号推出姓名,所以:姓名 部分依赖于 (学号,课程)。即:通过AB能得出C,通过A也能得出C,或者通过B也能得出C,那么说C部分依赖于AB。
传递函数依赖
传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。记做:![]()
通俗理解: 比如:学号 推出 系名 , 系名 推出 系主任, 但是,系主任推不出学号,系主任主要依赖于系名。这种情况可以说:系主任 传递依赖于 学号。通过A得到B,通过B得到C,但是C得不到A,那么说C传递依赖于A。
(3)三范式区分
第一范式
第一范式1NF核心原则就是:属性不可切割
不符合第一范式设计的表格
| ID | 商品 | 商家ID | 用户ID |
|---|---|---|---|
| 001 | 3台电脑 | 100 | 010 |
商品列中的数据不是原子数据项(3台电脑),是可以进行分割的,因此对表格进行修改,让表格符合第一范式的要求,修改结果如下所示:
| ID | 商品 | 数量 | 商家ID | 用户ID |
|---|---|---|---|---|
| 001 | 电脑 | 3 | 100 | 010 |
实际上,1NF是所有关系型数据库的最基本要求,在关系型数据库管理系统(RDBMS),例如SQL
Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。
第二范式
第二范式2NF核心原则:不能存在部分函数依赖
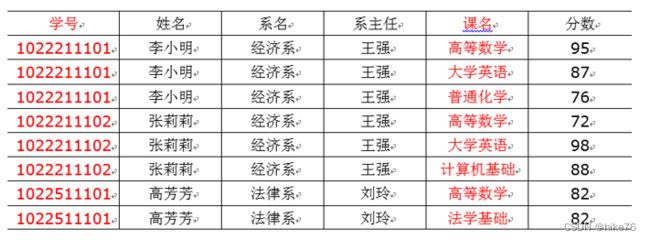
以上表格明显存在部分依赖。比如,这张表的主键是(学号,课名),分数确实完全依赖于(学号,课名),但是姓名并不完全依赖于(学号,课名)
将以上表格进行切分,使其满足第二范式原则
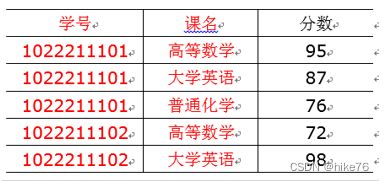

以上符合第二范式,去掉部分函数依赖
第三范式
第三范式3NF核心原则:不能存在传递函数依赖
在下面这张表中,存在传递函数依赖:学号->系名->系主任,但是系主任推不出学号。

上面表需要再次拆解,使其满足第三范式原则
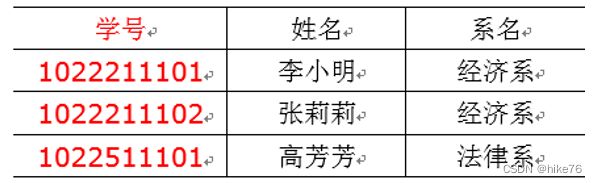
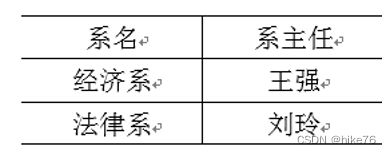
范式越高,数据越简洁,越清晰,数据的一致性也更高,冗余度越低,代价是在查找的时候需要join,查询的效率没有那么高,范式理论实际上也体现了以空间换时间的永恒真理。
早期的电脑存储十分紧张,范式的设计理论主要是为了降低数据的冗余度,使其能够存储更多的数据。
目前,HDFS相对地解决了数据的存储问题,但是查询要更加地要去注重效率问题,尽量少的join,对于数据冗余缺失越来越宽容,所以在数仓项目中,表格不像在关系型数据库中严格遵守关系建模、三范式表格,数仓中的表格,范式都没有那么高,一般只遵循一范式。