pytorch分布式训练小结
经过了几天的学习和总结,得到了一小点知识。破除理解上的障碍,希望和大家共同分享。
当前的pytorch分布式训练,主要使用两种方法:DataParallel和DistributedDataParallel。本篇文章对这两种方法的使用流程和关键步骤进行介绍,不涉及很复杂的原理和内核,仅仅方便大家理解和使用。
DistributedDataParallel
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
import torch.distributed as dist
import torch.backends.cudnn as cudnn1)设置可使用的GPU:
os.environ['CUDA_DEVICE_ORDER']='PCI_BUS_ID'
os.environ['CUDA_VISIBLE_DEVICES']='1,2'2)引入local_rank参数。 local_rank是赋值给一个分布式进程组组内的每个进程的唯一识别。该参数有两种引入方式:
① --local_rank=LOCAL_PROCESS_RANK这个命令行参数由torch.distributed.launch提供,用于指定每个GPU在本地的rank。该命令行方法最常用:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=0, type=int) # 该参数一定要以这种形式指定(即便不使用),因为命令行的launch工具会默认传递该参数
args = parser.parse_args()
② 在程序内部函数获取,这种情况下不需要命令行引入torch.distributed.launch,但不常用...。命令行键入时,需要在开头添加:CUDA_VISIBLE_DEVICES=0,1
local_rank=torch.distributed.get_rank() 3)初始化通信
torch.distributed.init_process_group(backend='nccl')4)构建数据集采样对象
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)5) 根据local_rank,配置当前进程使用的本地模型及GPU,保证每一个进程使用的GPU是一定的。我们列举出多种方式:
torch.cuda.set_device(args.local_rank)
① device = torch.device('cuda', args.local_rank)
model = model().to(device)
② model = model().to(args.local_rank)
③ model = model().cuda(args.local_rank)
loss_f = loss_function().cuda(args.local_rank)(可选)6)保证进程按次序执行(可选)
dist.barrier()7)将模型移至到DistributedDataParallel中,进行分布式配置
model = torch.nn.parallel.DistriburedDataParallel(model, device_ids = [args.local_rank], output_device = args.local_rank)
# 这里要注意,有时候你需要在DDP后添加model = model.module,否则会出错
my_tensor = my_tensor.to(device)
...optimizer...
cudnn.benchmark = True
.......8)释放内存,消除缓存:
if 'cuda' in str(device):
dist.destroy_process_group()
torch.cuda.empty_cache()注意,命令启动行( 2)——②除外 )或者也可以使用torch.multiprocessing.spawn():
python -m torch.distributed.launch --nproc_per_node=2 main.py命令执行后,local_rank会获取[0, 1]两个值,分别分配给当前两个进程。
应用解释:
python -m torch.distributed.launch main.py相当于使用torch.distributed.launch.py来运行我们的main.py,其中torch.distributed.launch会向我们的运行程序传递一些变量,包括nproc_per_node参数。该参数将会引导当前主机创建nproc_per_node个进程,每个进程会独立执行训练脚本。同时,每个进程会被分配一个local_rank参数来表示进程在当前主机(主机的参数是rank,如果是一个主机,就默认为0)上的编号,用以合理分配和调度本地的GPU资源(这也是为什么需要torch.cuda.set_device(args.local_rank)设定默认的GPU,因为每个进程需要在一个独立的GPU上)。在实际应用中,DDP会自动帮助我们将模型从local_rank=0扩展到其他进程状态。
附,使用torch.multiprocessing.spawn()时(来自pytorch官网):
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2 # 总的进程数, mp.spawn()会根据该值构造出rank=0,1,...
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()同时,注意:
ctrl+c关闭程序后,端口依然会被占用。这时候,使用netstat -nltp来查找被占用的端口的PID,并通过kill -9杀死它。
官网文献:
Distributed Data Parallel — PyTorch master documentation
Getting Started with Distributed Data Parallel — PyTorch Tutorials 1.9.0+cu102 documentation
PyTorch 深度剖析:并行训练的 DP 和 DDP 分别在什么情况下使用及实例
Distributed data parallel training in Pytorch
注:至于有些代码里出现了dist.reduce()或者dist.all_reduce()。可以不用关注,DDP已经优化了相关的操作。具体参见:PyTorch分布式训练详解教程 scatter, gather & isend, irecv & all_reduce & DDP - 天靖居士 - 博客园
DataParallel:
1)设置可用的GPU
os.envicon['CUDA_VISIBAL_DEVICES'] = '1,2' # GPU的物理编号2)构建GPU设备对象,方式包括
① device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
② torch.cuda.set_device('cuda:0')3)获取数据
dataloader = DataLoader(set, batch_size, shuffle=True)4)构建模型
model = model()5)分布式布置模型
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model, device_ids = [0,1], out_put_device = [0], dim=0) # device_ids指的是可见GPU的逻辑编号6)将模型和数据置于GPU上 # 该步到底该置于5)之前还是之后,其实都可以,因为DataParallel不是模型并行。但最好置于之后,随官网。
① 对应2)-①
model.to(device)
loss_f = loss_function().to(device)
my_tensor = my_tensor.to(device)
② 对应2)-②
model.cuda()
loss_f = loss_function().cuda()
my_tensor.cuda()
注意:也可以实现loss = nn.DataParallel(loss_function(reduce=False)).to(device),loss.mean()。但git上实验效果并不好。7)将优化器和学习率规划器进行分布式搭载(可选):
optimizer = nn.DataParallel(optimizer, device_ids = [0,1])
scheduler = nn.DataParallel(scheduler, device_ids = [0,1])8)损失聚合(可选)。由于DataParallel执行的是数据并行,而非模型并行,因此有人讨论过并行数据处理之后的聚合。但实际上,效果并没有多么突出。聚合方式主要是两种:
① loss = loss.sum()/n_gpus
② loss = loss.mean()官网文献:
Optional: Data Parallelism — PyTorch Tutorials 1.9.0+cu102 documentation
关于 DataParallel和DistributedDataParallel:
1) 在 DataParallel 中,batch size 设置必须为单卡的 n 倍,但是在 DistributedDataParallel 内,batch size 设置于单卡一样即可。
2) 和dataparallel不同,dataparallel需要将batchsize设置成n倍的单卡batchsize,而distributedsampler使用的情况下,batchsize设置与单卡设置相同。
3) 在DDP中, 有几个新的参数:world size, local rank, rank。world size指进程总数,在这里就是我们使用的GPU数量;rank指进程序号,local_rank指本地序号,两者的区别在于前者用于进程间通讯,后者用于本地GPU的分配。
关于pytorch中的torch.device("cuda")和torch.device("cuda:X")
解释:
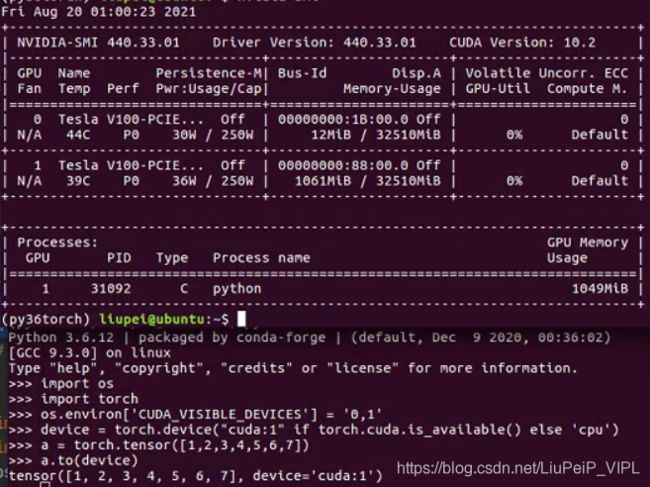
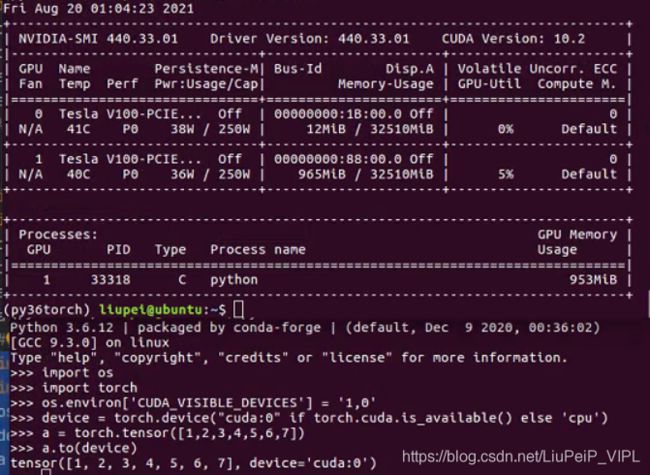
1)当使用os.environ['CUDA_VISIBLE_DEVICES'] = '1,0'或者device_ids=[1,0]选择可用的GPU,这里的编号数字是指GPU的物理编号。而编号的位置(如1的位置是0),是我们使用时的逻辑编号。
2)标题的X表示,需要将缓冲区和并行模块(缓冲区和并行模块的作用,在于进行初始的模型存储、数据分发等操作)的参数设置在逻辑编号X上。该逻辑编号X也应该是device_ids列表的首元素,即device_ids = [X,...]。原因是,官网要求相关设置应该在device_ids[0]上。
3)如上例:如果这里的X=0,则实际上在使用物理编号为1的GPU;如果这里的X=1,则实际上在使用物理编号为0的GPU。如果没有明确参数X,则默认使用逻辑编号为0。

博客参考文献:(欲知更多细节,请阅读参考文献)
分布式训练 | Pytorch的主流做法详解
Pytorch中多GPU训练指北 - Oldpan的个人博客
Distributed data parallel training in Pytorch
Pytorch 分布式训练 - 知乎 分布式系统中常用的一些概念、通信、初始化等等介绍,非常详细
pytorch 分布式训练 distributed parallel 笔记_JPZ的各种笔记-CSDN博客
当代研究生应当掌握的并行训练方法(单机多卡) - 知乎 DP、DDP、apex、Horovod的使用介绍以及样例
pytorch使用记录(三) 多GPU训练_daydayjump的博客-CSDN博客 简单介绍DP
分布式训练 - 单机多卡(DP和DDP)_love1005lin的博客-CSDN博客
https://github.com/tczhangzhi/pytorch-distributed/blob/master/distributed.py
Pytorch:多块GPU调用细节问题及Pytorch的nn.DataParallel解释_yunxiaoMr的博客-CSDN博客 关于DataParallel多块GPU调用细节问题
pytorch多gpu并行训练 - 知乎 比较全面的分布式讲解,包含了DP、DDP以及少量样例
Pytorch多卡训练 - _CHENBIN - 博客园 DataParallel样例展示
【分布式训练】单机多卡的正确打开方式(三):PyTorch - 知乎 DP和DDP的样例展示
PyTorch 20.GPU训练 - 知乎 形式化表示分布式训练
PyTorch 单机多卡操作总结:分布式DataParallel,混合精度,Horovod)-技术圈 非常好的一篇文章,给出了常见的代码实现样例
https://github.com/kamalkraj/BERT-NER/blob/dev/run_ner.py 该代码在实现BERT的finetuning过程中给出了比较好的分布式训练实现
项目代码示例:
https://github.com/erikwijmans/skynet-ddp-slurm-example/blob/master/ddp_example/train_cifar10.py DDP
https://github.com/XiaoyuWant/DDP_Classification_pytorch/blob/main/main.py DDP
https://github.com/dougsouza/pytorch-sync-batchnorm-example DDP
https://github.com/ankur6ue/node2vec_dataparallel/blob/master/node2vec_dp.py DDP
https://github.com/yanxp/ParallelSSD/blob/master/train_logo.py DP
损失聚合示例:
https://github.com/Lance0218/Pytorch-DistributedDataParallel-Training-Tricks/blob/master/DDP_warmupcos.py batch_loss /= len(outputs)
https://github.com/kamalkraj/BERT-NER/blob/dev/run_ner.py scale_loss(loss, optimizer)
https://github.com/lesliejackson/PyTorch-Distributed-Training/blob/master/main.py reduce_loss(tensor, rank, world_size)
https://github.com/bl0/moco/blob/master/train.py scale_loss(loss, optimizer)
BERT-NER/run_ner.py at dev · kamalkraj/BERT-NER · GitHub loss = loss.mean()
变量解释:
Pytorch GPU多卡并行训练实战总结(附代码)-技术圈