Pytorch 分布式训练
Contents
- `nn.DataParallel()` (DP)
-
- 多卡训练原理
- `nn.DataParallel()` 的用法
- Use `nn.parallel.DistributedDataParallel` instead of `nn.DataParallel`
- `nn.parallel.DistributedDataParallel` (DDP)
-
- 分布式训练常见概念
- DDP 内部机制
- `nn.parallel.DistributedDataParallel` 的用法
- 使用范例
- References
nn.DataParallel() (DP)
多卡训练原理
基本概念
- broadcast 是主进程将相同的数据分发给组里的每一个其它进程
- scatter 是主进程将数据的每一小部分给组里的其它进程
- gather 是将其它进程的数据收集过来;reduce 是将其它进程的数据收集过来并应用某种操作 (e.g. SUM、PRODUCT、MAX、MIN)
- 在 gather 和 reduce 概念前面还可以加上 all,如 all_gather,all_reduce,那就是多对多的关系了
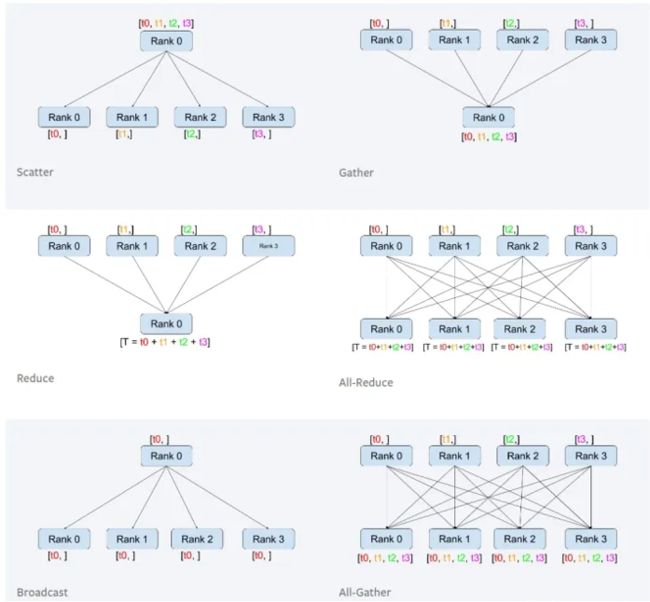
多卡训练原理
- 网络在前向传播时会将 model 从主卡 (默认是逻辑 0 卡) broadcast 到所有 device 上,input data 会在 batch 这个维度被分组后 scatter 到不同的 device 上进行前向计算 (tuple, list and dict types will be shallow copied. The other types will be shared among different threads and can be corrupted if written to in the model’s forward pass.),计算完毕后网络的输出被 gather 到主卡上,loss 随后在主卡上被计算出来 (这也是为什么主卡负载更大的原因,loss 每次都会在主卡上计算,这就造成主卡负载远大于其他显卡)。在反向传播时,loss 会被 scatter 到每个 device 上,每个卡各自进行反向传播计算梯度,然后梯度会被 reduce 到主卡上 (i.e. 求得梯度的均值),再用反向传播在主卡上更新模型参数,最后将更新后的模型参数 broadcast 到其余 GPU 中进行下一轮的前向传播,以此来实现并行
nn.DataParallel() 的用法
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
module(Module): 要放到多卡训练的模型device_ids(list of python:int ortorch.device): 可用的 gpu 卡号output_device(intortorch.device): 模型输出结果存放的卡号 (如果不指定的话,默认放在 0 卡,这也是为什么多 gpu 训练并不是负载均衡的, 一般 0 卡负载更大)dim(int):从哪一维度切分一个 batch 的数据,默认为 0,即从 batch 维度将数据分组后送到不同 device 上运算
Example
nn.DataParallel()的用法十分简单,加一行代码即可
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2]).cuda() # broadcast model parameters to all devices
output = net(input_data) # input_var can be on any device, including CPU
- 事实上 DataParallel 也是一个 Pytorch 的
nn.Module,因此使用nn.DataParallel后,模型需要使用.module来得到实际的模型和优化器:
# 保存模型
torch.save(net.module.state_dict(), path)
Use nn.parallel.DistributedDataParallel instead of nn.DataParallel
- DataParallel 复制一个网络到多个 cuda 设备,然后再 split 一个 batch 的 data 到多个 cuda 设备,通过这种并行计算的方式解决了 batch 很大的问题,但也有自身的不足:
- (1) 单进程多线程带来的问题:DataParallel 是单进程多线程的,无法在多个机器上工作 (不支持分布式),而且不能使用 Apex 进行混合精度训练。同时它基于多线程的方式,确实方便了信息的交换,但受困于 GIL (Python 全局解释器锁),会带来性能开销
- (2) 存在效率问题,主卡性能和通信开销容易成为瓶颈,GPU 利用率通常很低:数据集需要先拷贝到主进程,然后再 split 到每个设备上;权重参数只在主卡上更新,需要每次迭代前向所有设备做一次同步;每次迭代的网络输出需要 gather 到主卡上
- (3) 不支持 model parallel
- 这个时候,DistributedDataParallel 来了,并且自此之后,不管是单机还是多机,都推荐使用 DDP 来代替 DP. DP 和 DDP 的主要差异可以总结为以下几点:
- (1) DP 是单进程多线程的,只用于单机情况,而 DDP 是多进程的,每个 GPU 对应一个进程,适用于单机和多机情况,真正实现分布式训练,并且因为每个进程都是独立的 Python 解释器,DDP 避免了 GIL 带来的性能开销
- (2) DDP 的训练更高效,不存在 DP 中负载不均衡的问题,基本上 DP 已经被弃用
- (3) DDP 支持模型并行,而 DP 并不支持,这意味如果模型太大单卡显存不足时只能使用前者
可能 DDP 唯一不好的地方就是相比 DP 使用起来会有些麻烦
nn.parallel.DistributedDataParallel (DDP)
分布式训练常见概念
- node:节点,可以看作主机
- global_rank:表示进程序号,用于进程间通信,可以用于表示进程的优先级。我们一般设置 global_rank=0 对应的主机为 master 节点
- local_rank:主机内 GPU 编号,非显式参数,由
torch.distributed.run内部指定 (torch.distributed.run是为了代替torch.distributed.launch的新型启动方式,但是由于是新功能, 只有最新的 torch 1.10 支持, 因此出于兼容性考虑还是建议使用torch.distributed.launch)。比方说,node_rank=3,local_rank=0 表示第 3 个主机内的第 1 块 GPU,因此 local_rank 对应的就是 Process 需要使用的 Device (GPU) 编号 - world_size:全局进程个数 (在 DDP 中,一个进程控制一个 GPU,因此 world_size 即为 nnode × \times × nproc_per_node (设备数)
DDP 内部机制
- 每个 GPU 都由一个进程控制,这些 GPU 可以都在同一个节点上 (单机),也可以分布在多个节点上 (多机)。每个进程都执行相同的任务,并且每个进程都与所有其他进程通信。进程或者说 GPU 之间只传递梯度,这样网络通信就不再是瓶颈
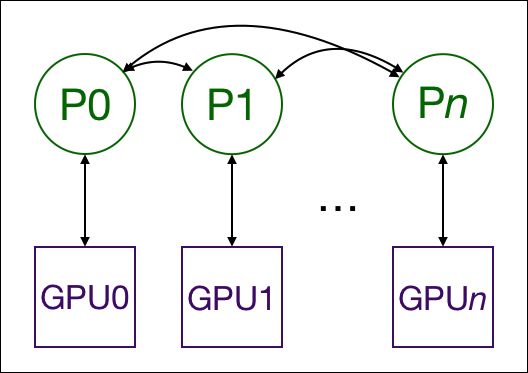
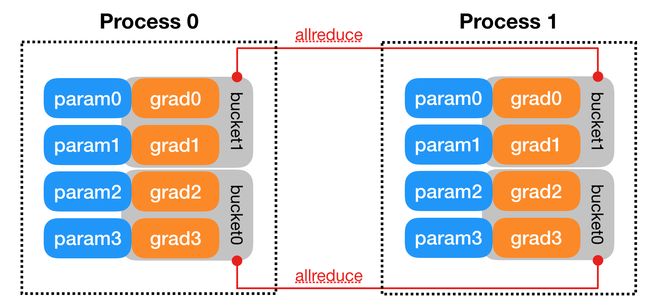
- 首先将 rank=0 进程中的模型参数 (i.e.
state_dict()) broadcast 到进程组中的其他进程,然后每个 DDP 进程都会创建一个 local Reducer 来负责梯度同步。在训练过程中,每个进程从磁盘加载 batch 数据,并将它们传递到其 GPU。每个 GPU 都有自己的前向过程,完成前向传播后梯度在各个 GPUs 间进行 All-Reduce,每个 GPU 都收到其他 GPU 的梯度,从而可以独自进行反向传播和参数更新。同时,每一层的梯度不依赖于前一层,所以梯度的 All-Reduce 和后向过程同时计算,以进一步缓解网络瓶颈。在后向过程的最后,每个节点都得到了平均梯度,这样各个 GPU 中的模型参数保持同步 (回忆一下,DP 是将梯度 reduce 到主卡,在主卡上更新参数,再将参数 broadcast 给其他 GPU,这样无论是主卡的负载还是通信开销都比 DDP 大很多) (具体的实现细节可以参考 DISTRIBUTED DATA PARALLEL)
- 上述过程要求多个进程 (可能在多个节点上) 同步并通信。Pytorch 通过
distributed.init_process_group函数来实现多进程同步通信。它需要知道 rank 0 位置以便所有进程都可以同步,以及预期的进程总数 (world_size)。每个进程都需要知道进程总数及其在进程组中的顺序,以及使用哪个 GPU. 此外,Pytorch 还提供了torch.utils.data.DistributedSampler来为各个进程切分数据,以保证训练数据不重叠
nn.parallel.DistributedDataParallel 的用法
torch.nn.parallel.DistributedDataParallel(
module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None,
bucket_cap_mb=25, find_unused_parameters=False, check_reduction=False, gradient_as_bucket_view=False,
static_graph=False)
module(Module): 要放到多卡训练的模型device_ids(list of python:int ortorch.device): CUDA devices. 1) 对于单卡训练,device_ids可以只包含一个卡号,也可以是None;2) 对于多卡 / CPU 训练,device_ids必须为Noneoutput_device(intortorch.device): 单卡训练时模型输出结果存放的卡号。对于多卡 / CPU 训练,output_device必须为Nonedim(int):从哪一维度切分一个 batch 的数据,默认为 0,即从 batch 维度将数据分组后送到不同 device 上运算- 其余参数保持默认即可,参数详情可参考 torch.nn.parallel.DistributedDataParallel
使用范例
导入需要的库
import os
import torch
import argparse
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.optim as optim
import torch.nn as nn
import torch.distributed as dist
from datetime import timedelta
初始化进程组、配置 Master Node (init_process_group 参数详见 torch.distributed.init_process_group)
def setup(global_rank, world_size):
torch.distributed.init_process_group(
backend="nccl",
init_method='env://', # indicates where/how to discover peers
# 'env://' means environment variable initialization
# 'file:///mnt/nfs/sharedfile' means shared file-system initialization
# 'tcp://10.1.1.20:23456' means TCP initialization
world_size=world_size,
rank=global_rank,
timeout=timedelta(seconds=5)
)
def cleanup():
dist.destroy_process_group()
定义训练过程 (定义在每一个 Process 中我们希望执行的代码)
def run_demo(args):
# get global_rank and world_size
global_rank = args.local_rank + args.node_rank * args.nproc_per_node
world_size = args.nnode * args.nproc_per_node
setup(global_rank=global_rank, world_size=world_size)
# load model to the GPU specified by local_rank
model = ToyModel().to(args.local_rank)
ddp_model = DDP(model,
device_ids=[args.local_rank],
output_device=args.local_rank)
# define loss and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# define data sampler and dataloader
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=transforms.ToTensor(),
download=True
)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
shuffle=True)
trainloader = DataLoader(train_dataset,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
num_workers=args.workers,
sampler=train_sampler,
pin_memory=True)
for epoch in range(args.epoch):
# set epoch
train_sampler.set_epoch(epoch)
for i, data in enumerate(trainloader):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = ddp_model(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
dist.barrier()
cleanup()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, help='automatically set by torch.distributed.launch')
parser.add_argument('--nproc_per_node', type=int, help='#gpus per node')
parser.add_argument('--nnode', type=int, help='#nodes')
parser.add_argument('--node_rank', type=int, help='node rank')
parser.add_argument('--epoch', type=int, help='#epochs to train')
parser.add_argument('--batch_size', type=int, help='batch size')
parser.add_argument('--workers', type=int, help='#workers for dataloader')
args = parser.parse_args()
run_demo(args=args)
分布式训练 (torchrun 可参考 https://pytorch.org/docs/stable/elastic/run.html#launcher-api)
python -m torch.distributed.launch \
--nnodes=1 \ # 节点的数量,通常一个节点对应一个主机,方便记忆,直接表述为主机
--nproc_per_node=2 \ # 一个节点中显卡的数量
--node_rank=0 \ # 节点的序号,从 0 开始
--master_addr="10.103.10.54" \ # master 节点的 ip 地址
--master_port=6005 \ # master 节点的 port 号,在不同的节点上 master_addr 和 master_port 的设置是一样的,用来进行通信
train.py
还要注意:在 DP 中, batch_size 设置必须为单卡的 n n n 倍, 但是在 DDP 内, batch_size 设置与单卡一样即可
torch.distributed.launch在运行进程时会设置相应的环境变量 (对应 “env://” 的初始化方式),在程序中可以通过环境变量获取相应设置
os.environ["MASTER_ADDR"]
os.environ["MASTER_PORT"]
os.environ["RANK"] # global rank (local_rank is passed into python script as arguments)
os.environ["WORLD_SIZE"]
使用 torch.distributed 的 API 进行分布式基本操作
# define tensor on GPU, count and total is the result at each GPU
t = torch.tensor([count, total], dtype=torch.float64, device='cuda')
# synchronizes all processes
dist.barrier()
# Reduces the tensor data across all machines in such a way that all get the final result.
dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,)
# Gathers tensors from the whole group in a list.
t_gather_list = [torch.zeros_like(t) for _ in range(world_size)]
dist.all_gather(t_gather_list, t)
References
- torch.nn.DataParallel, torch.nn.parallel.DistributedDataParallel
- DataParallel & DistributedDataParallel 分布式训练
- Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel
- Pytorch 的 nn.DataParallel
- PyTorch 分布式训练简明教程 (2022 更新版)
- PyTorch 多进程分布式训练实战
- DISTRIBUTED DATA PARALLEL
- torch.nn.parallel.DistributedDataParallel: 快速上手
- 【pytorch 记录】pytorch 的分布式 torch.distributed.launch 命令在做什么呢
- PyTorch 的分布式