基于深度学习的语义分割初探FCN以及pytorch代码实现
基于深度学习的语义分割初探FCN以及pytorch代码实现
FCN论文
论文地址:https://arxiv.org/abs/1411.4038
FCN是基于深度学习方法的第一篇关于语义分割的开山之作,虽然这篇文章的分割结果现在看起来并不是目前最好的,但其意义还是非常重要的。其中跳跃链接、end-to-end、迁移学习、反卷积实现上采样也是FCN论文中的核心思想。
FCN论文整体结构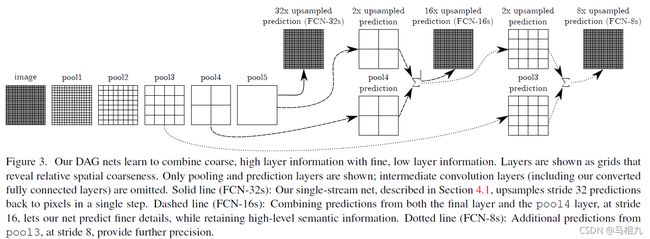
应用
无人车、地理信息系统、医疗影像、机器人。由于目前想在机器人上搭建视觉系统,想结合语义分割这种像素级预测的思想,是否可以与检测任务中的方式做一个结合。例如Mask-RCNN将实例分割与目标检测很好的融合为一体。
pytorch实现FCN_8x
由于让我们的代码更加易于理解以及更好的更正,代码中所有参数以及变量名称均使用我们的母语。
简单使用Camvid数据集做一个室外分割的例子。
Dataset构建
import torch
import os
from PIL import Image
import pandas as pd
import numpy as np
import torchvision.transforms.functional as F
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import cfg
class 标签处理:
def __init__(self, 标签所对应类别文件的路径):
self.像素类别图 = self.读取类别所对应的像素值(标签所对应类别文件的路径)
self.标签哈希表 = self.编码标签像素值(self.像素类别图)
@staticmethod
def 读取类别所对应的像素值(标签所对应类别文件的路径):
标签像素值 = pd.read_csv(标签所对应类别文件的路径, sep=',')
像素类别图 = []
#标签像素值.index # 返回像素值所对应类别的索引 0-12
for i in range(len(标签像素值.index)):
按行读取每一个类别所对应的像素值 = 标签像素值.iloc[i]
类别所对应的RGB像素值 = [按行读取每一个类别所对应的像素值['r'], 按行读取每一个类别所对应的像素值['g'], 按行读取每一个类别所对应的像素值['b']]
像素类别图.append(类别所对应的RGB像素值)
# 类别名称 = 标签像素值['name'].values
# 类别数量 = len(类别名称)
return 像素类别图
@staticmethod
def 编码标签像素值(像素类别图):
# 哈希表(为了形成1对1或1对多的映射关系,加快查找的效率) 一个标签对应一个颜色 将像素类别图中的每一个像素映射到它所表示的类别
# 希函数 像素类别图([0]*256+像素类别图[1])*256+像素类别图[2]
# 哈希映射 像素类别图2lbl(希函数) = 所对应的类别
# 哈希表 像素类别图2lbl
# eg: 一个像素点P(128, 64, 128) 通过编码函数(P[0]*256+P[1])*256+P[2] 转成 整数(8405120)
# 将该数作为像素点P在哈希表中的索引:像素类别图转成哈希表(8405120) 去查询像素点P所对应的类别P
像素类别图转成哈希表 = np.zeros(256 ** 3)
for 类别索引, 类别所对应RGB像素值 in enumerate(像素类别图):
像素类别图转成哈希表[(类别所对应RGB像素值[0]*256 + 类别所对应RGB像素值[1]) * 256 + 类别所对应RGB像素值[2]] = 类别索引
return 像素类别图转成哈希表
def 编码标签图像(self, 图像):
# rgb -> index -> identity
数据 = np.array(图像, dtype='int32')
哈希函数值 = (数据[:, :, 0] * 256 + 数据[:, :, 1]) * 256 + 数据[:, :, 2]
return np.array(self.标签哈希表[哈希函数值], dtype='int64')
class 数据集(Dataset):
def __init__(self, 图像和标签路径=[], 裁剪=None):
if len(图像和标签路径) != 2:
raise Exception('需同时输入图像和标签的路径')
self.图像路径 = 图像和标签路径[0]
self.标签路径 = 图像和标签路径[1]
self.读取路径中的图片 = self.读取文件夹(self.图像路径)
self.读取路径中的标签 = self.读取文件夹(self.标签路径)
self.裁剪尺寸 = 裁剪
def __getitem__(self, 索引):
单张图像 = self.读取路径中的图片[索引]
单个标签 = self.读取路径中的标签[索引]
单张图像 = Image.open(单张图像)
单个标签 = Image.open(单个标签).convert('RGB')
单张图像, 单个标签 = self.中心裁剪(单张图像, 单个标签, self.裁剪尺寸)
单张图像, 单个标签 = self.图像标签转换(单张图像, 单个标签)
图像标签组合成字典 = {'图像': 单张图像, '标签': 单个标签}
return 图像标签组合成字典
def __len__(self):
return len(self.读取路径中的图片)
def 读取文件夹(self, 路径):
文件夹列表 = os.listdir(路径)
拼接图像完整路径 = [os.path.join(路径, 图片) for 图片 in 文件夹列表]
拼接图像完整路径.sort()
return 拼接图像完整路径
def 中心裁剪(self, 图像, 标签, 裁剪尺寸):
图像 = F.center_crop(图像, 裁剪尺寸)
标签 = F.center_crop(标签, 裁剪尺寸)
return 图像, 标签
def 图像标签转换(self, 图像, 标签):
标签 = np.array(标签)
标签 = Image.fromarray(标签.astype('uint8'))
图像转Tensor = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
图像 = 图像转Tensor(图像)
# 原图不需要编码 标签需要编码
标签 = 标签处理实例化.编码标签图像(标签)
标签 = torch.from_numpy(标签)
return 图像, 标签
标签处理实例化 = 标签处理(cfg.类别文件路径)
FCN模型搭建
import torch
import torch.nn as nn
from torchvision import models
import torch.nn.functional as F
import numpy as np
from Bilinear_init_deconv import 双线性插值初始化卷积核
VGG特征提取网络 = models.vgg16_bn(pretrained=True)
class 全卷积网络(nn.Module):
def __init__(self, 类别个数):
super(全卷积网络, self).__init__()
self.特征提取网络中第一个下采样 = VGG特征提取网络.features[:7] # 64
self.特征提取网络中第二个下采样 = VGG特征提取网络.features[7:14] # 128
self.特征提取网络中第三个下采样 = VGG特征提取网络.features[14:24] # 256
self.特征提取网络中第四个下采样 = VGG特征提取网络.features[24:34] # 512
self.特征提取网络中第五个下采样 = VGG特征提取网络.features[34:] # 512
# self.跨度_32的上采样预测图 = nn.Conv2d(512, 类别个数, 1) # 32
# self.跨度_16的采样预测图 = nn.Conv2d(512, 类别个数, 1) # 16
# self.跨度_8的上采样预测图 = nn.Conv2d(128, 类别个数, 1) # 8
self.过渡卷积512 = nn.Conv2d(512, 256, 1)
self.过渡卷积256 = nn.Conv2d(256, 类别个数, 1)
self.上采样_8X = nn.ConvTranspose2d(类别个数, 类别个数, 16, 8, 4, bias=False)
self.上采样_8X.weight.data = 双线性插值初始化卷积核(类别个数, 类别个数, 16)
self.上采样_2X_512 = nn.ConvTranspose2d(512, 512, 4, 2, 1, bias=False)
self.上采样_2X_512.weight.data = 双线性插值初始化卷积核(512, 512, 4)
self.上采样_2X_256 = nn.ConvTranspose2d(256, 256, 4, 2, 1, bias=False)
self.上采样_2X_256.weight.data = 双线性插值初始化卷积核(256, 256, 4)
def forward(self, x):
第一层特征提取 = self.特征提取网络中第一个下采样(x)
第二层特征提取 = self.特征提取网络中第二个下采样(第一层特征提取)
第三层特征提取 = self.特征提取网络中第三个下采样(第二层特征提取)
第四层特征提取 = self.特征提取网络中第四个下采样(第三层特征提取)
第五层特征提取 = self.特征提取网络中第五个下采样(第四层特征提取)
第五层特征提取_2倍还原 = self.上采样_2X_512(第五层特征提取)
第五层与第四层进行特征图融合 = 第四层特征提取 + 第五层特征提取_2倍还原
融合后的图像转换通道数 = self.过渡卷积512(第五层与第四层进行特征图融合)
第四层与第五层融合后的特征_2倍还原 = self.上采样_2X_256(融合后的图像转换通道数)
与第三层特征图进行融合 = 第三层特征提取 + 第四层与第五层融合后的特征_2倍还原
转换成类别个数的通道数 = self.过渡卷积256(与第三层特征图进行融合)
还原原图大小_8X = self.上采样_8X(转换成类别个数的通道数)
return 还原原图大小_8X
FCN论文中使用了双线性插值初始化反卷积核
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import cv2
def 双线性插值(原图, 目标尺寸):
目标图像的高, 目标图像的宽 = 目标尺寸
原图的高, 原图的宽 = 原图.shape[:2]
if 原图的高 == 目标图像的高 and 原图的宽 == 目标图像的宽:
return 原图.copy()
原图与目标图像宽的缩放比例 = float(原图的宽) / 目标图像的宽
原图与目标图像高的缩放比例 = float(原图的高) / 目标图像的高
生成目标图像尺寸相同的空白图 = np.zeros((目标图像的高, 目标图像的宽, 3), dtype=np.uint8)
for RGB in range(3):
for 目标图像高方向 in range(目标图像的高):
for 目标图像宽方向 in range(目标图像的宽):
# src_x + 0.5 = (dst_x + 0.5) * scale_x 0.5为一个像素默认1*1 其中心像素坐标+0.5的位置
目标图像宽方向的像素在原图上的坐标 = (目标图像宽方向 + 0.5) * 原图与目标图像宽的缩放比例 - 0.5
目标图像高方向的像素在原图上的坐标 = (目标图像高方向 + 0.5) * 原图与目标图像高的缩放比例 - 0.5
原图上第一个近邻点 = int(np.floor(目标图像宽方向的像素在原图上的坐标))
原图上第二个近邻点 = int(np.floor(目标图像高方向的像素在原图上的坐标))
原图上第三个近邻点 = min(原图上第一个近邻点 + 1, 原图的宽 - 1)
原图上第四个近邻点 = min(原图上第二个近邻点 + 1, 原图的高 - 1)
比例1 = (原图上第三个近邻点 - 目标图像宽方向的像素在原图上的坐标) * 原图[原图上第二个近邻点, 原图上第一个近邻点, RGB] + (目标图像宽方向的像素在原图上的坐标 - 原图上第一个近邻点) * 原图[原图上第二个近邻点, 原图上第三个近邻点, RGB]
比例2 = (原图上第三个近邻点 - 目标图像宽方向的像素在原图上的坐标) * 原图[原图上第四个近邻点, 原图上第一个近邻点, RGB] + (目标图像宽方向的像素在原图上的坐标 - 原图上第一个近邻点) * 原图[原图上第四个近邻点, 原图上第三个近邻点, RGB]
生成目标图像尺寸相同的空白图[目标图像高方向, 目标图像宽方向, RGB] = int((原图上第四个近邻点 - 原图上第二个近邻点) * 比例1 + (目标图像高方向的像素在原图上的坐标 - 原图上第二个近邻点) * 比例2)
return 生成目标图像尺寸相同的空白图
def 双线性插值初始化卷积核(输入通道, 输出通道, 卷积核大小):
因子 = (卷积核大小 + 1) // 2
if 卷积核大小 % 2 == 1:
中心 = 因子 - 1
else:
中心 = 因子 - 0.5
画网格 = np.ogrid[:卷积核大小, :卷积核大小]
初始化 = (1 - abs(画网格[0] - 中心) / 因子) * (1 - abs(画网格[1] - 中心) / 因子)
权重 = np.zeros((输入通道, 输出通道, 卷积核大小, 卷积核大小), dtype='float32')
权重[range(输入通道), range(输出通道), :, :] = 初始化
return torch.from_numpy(权重)
if __name__ == '__main__':
img = cv2.imread('FCN_model.png')
img_out = 双线性插值(img, (1000, 1000))
cv2.imshow('src', img)
cv2.imshow('dst', img_out)
cv2.waitKey(0)
print(img.shape)
print(img_out.shape)
训练
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
import evalution_segmentation
import cfg
from dataset import 数据集
from build_FCN_model import 全卷积网络
from datetime import datetime
计算单元 = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
训练数据集实例化 = 数据集([cfg.训练数据集, cfg.训练标签数据集], (352, 480))
验证数据集实例化 = 数据集([cfg.验证数据集, cfg.验证标签数据集], (352, 480))
训练数据 = DataLoader(训练数据集实例化, batch_size=16, shuffle=True, num_workers=0)
验证数据 = DataLoader(验证数据集实例化, batch_size=8, shuffle=True, num_workers=0)
模型实例化 = 全卷积网络(类别个数=12)
模型放到GPU = 模型实例化.to(计算单元)
损失函数 = nn.NLLLoss().to(计算单元) # 交叉熵没有本质区别 只是没有封装softmax
优化器 = optim.Adam(模型放到GPU.parameters(), lr=1e-4) # 2D Adam rgb-D SGD
def 训练(模型):
最优权重 = [0]
网络状态 = 模型.train()
for 训练轮次 in range(cfg.循环数据集的总次数):
print('训练次数[{} / {}]'.format(训练轮次 + 1, cfg.循环数据集的总次数))
if 训练轮次 % 50 == 0 and 训练轮次 != 0:
for 学习率 in 优化器.param_groups:
学习率['lr'] *= 0.5
训练损失 = 0
训练准确率 = 0
训练miou = 0
训练分类的准确率 = 0
for 索引, 图像标签数据字典 in enumerate(训练数据):
训练图像数据 = Variable(图像标签数据字典['图像'].to(计算单元))
训练图像标签 = Variable(图像标签数据字典['标签'].to(计算单元))
预测图获取 = 网络状态(训练图像数据)
预测图获取 = F.log_softmax(预测图获取, dim=1)
损失 = 损失函数(预测图获取, 训练图像标签) # 每一次迭代的loss
优化器.zero_grad()
损失.backward()
优化器.step()
训练损失 += 损失.item() # 对于一个epoch总的loss
预测结果中取最大值 = 预测图获取.max(dim=1)[1].data.cpu().numpy() # max 返回两个值 1、最大值本身 2、最大值的索引
预测结果中取最大值 = [序号 for 序号 in 预测结果中取最大值]
真实标签数据 = 训练图像标签.data.cpu().numpy()
真实标签数据 = [序号 for 序号 in 真实标签数据]
混淆矩阵 = evalution_segmentation.验证语义分割指标(预测结果中取最大值, 真实标签数据)
训练准确率 += 混淆矩阵['平均分类精度']
训练miou += 混淆矩阵['miou']
训练分类的准确率 += 混淆矩阵['分类精度']
print('迭代到第[{} / {}]个数据, 损失为 {:.8f}'.format(索引 + 1, len(训练数据), 损失.item()))
每一个大循环下的指标描述 = '训练准确率: {:.5f} 训练miou: {:.5f} 训练类别的准确率: {:}'.format(训练准确率 / len(训练数据), 训练miou / len(训练数据), 训练分类的准确率 / len(训练数据))
print(每一个大循环下的指标描述)
if max(最优权重) <= 训练miou / len(训练数据):
保存权重路径 = 'E:/FCN_8X/weights/'
for name in os.listdir(保存权重路径):
os.remove(os.path.join(保存权重路径, name))
最优权重.append(训练miou / len(训练数据))
torch.save(网络状态.state_dict(), 保存权重路径 + '{}.pth'.format(训练轮次))
验证(模型)
def 验证(模型):
网络状态 = 模型.eval()
验证损失 = 0
验证准确度 = 0
验证miou = 0
验证分类的准确率 = 0
预测初始时间 = datetime.now()
for 序号, 图像标签数据 in enumerate(验证数据):
验证图像数据 = Variable(图像标签数据['图像'].to(计算单元))
验证图像标签 = Variable(图像标签数据['标签'].to(计算单元))
预测图输出 = 网络状态(验证图像数据)
预测图输出 = F.log_softmax(预测图输出, dim=1)
损失 = 损失函数(预测图输出, 验证图像标签)
验证损失 = 损失.item() + 验证损失
预测结果中取最大值 = 预测图输出.max(dim=1)[1].data.cpu().numpy() # max 返回两个值 1、最大值本身 2、最大值的索引
预测结果中取最大值 = [序号 for 序号 in 预测结果中取最大值]
真实标签数据 = 验证图像标签.data.cpu().numpy()
真实标签数据 = [序号 for 序号 in 真实标签数据]
验证混淆矩阵 = evalution_segmentation.验证语义分割指标(预测结果中取最大值, 真实标签数据)
验证准确度 = 验证混淆矩阵['平均分类精度'] + 验证准确度
验证miou += 验证混淆矩阵['miou']
验证分类的准确率 += 验证混淆矩阵['分类精度']
当前时间 = datetime.now()
小时, 分秒 = divmod((当前时间 - 预测初始时间).seconds, 3600)
分钟, 秒 = divmod(分秒, 60)
验证用时 = '验证所用时间为: {:.0f}:{:.0f}:{:.0f}'.format(小时, 分钟, 秒)
验证的指标描述 = ('验证的损失: {:.5f} 验证的准确度: {:.5f} 验证的miou: {:.5f} 验证类精度: {:}').format(验证损失 / len(训练数据), 验证准确度 / len(验证数据), 验证miou / len(验证数据), 验证分类的准确率 / len(验证数据))
print(验证的指标描述)
print(验证用时)
if __name__ == '__main__':
训练(模型放到GPU)
测试
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
import evalution_segmentation
import cfg
from dataset import 数据集
from build_FCN_model import 全卷积网络
from datetime import datetime
计算单元 = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
miou_list = [0]
权重路径 = ''
测试数据实例化 = 数据集([], (352, 480))
测试数据 = DataLoader(测试数据实例化, batch_size=4, shuffle=True, num_workers=0)
网络 = 全卷积网络(类别个数=12)
网络.eval()
网络.to(计算单元)
网络.load_state_dict(torch.load(权重路径))
测试的准确度 = 0
测试的miou = 0
测试的分类精度 = 0
测试像素准确度 = 0
错误 = 0
for 索引, 图像标签数据字典 in enumerate(测试数据):
测试图像数据 = Variable(图像标签数据字典['图像'].to(计算单元))
测试图像标签 = Variable(图像标签数据字典['标签'].to(计算单元))
预测 = 网络(测试图像数据)
预测 = F.log_softmax(预测, dim=1)
预测结果中取最大值 = 预测.max(dim=1)[1].data.cpu().numpy() # max 返回两个值 1、最大值本身 2、最大值的索引
预测结果中取最大值 = [序号 for 序号 in 预测结果中取最大值]
真实标签数据 = 测试图像标签.data.cpu().numpy()
真实标签数据 = [序号 for 序号 in 真实标签数据]
测试混淆矩阵 = evalution_segmentation.验证语义分割指标(预测结果中取最大值, 真实标签数据)
测试的准确度 += 测试混淆矩阵['平均分类精度']
测试的miou += 测试混淆矩阵['miou']
测试像素准确度 += 测试混淆矩阵['像素准确度']
if len(测试混淆矩阵['分类精度']) < 12:
测试混淆矩阵['分类精度'] = 0
测试的分类精度 += 测试混淆矩阵['分类精度']
错误 += 1
else:
测试的分类精度 += 测试混淆矩阵['分类精度']
print(测试混淆矩阵['分类精度'], '=============', 索引)
完整循环一次的指标 = ('测试精度: {:.5f}, 测试miou: {:.5f}, 测试像素准确度: {:.5f}, 测试分类精度: {}'.format(测试的准确度 / (len(测试数据) - 错误),
测试的miou / (len(测试数据) - 错误), 测试像素准确度 / (len(测试数据) - 错误),
测试的分类精度 / (len(测试数据) - 错误)))
if 测试的miou / (len(测试数据) - 错误) > max(miou_list):
miou_list.append(测试的miou / (len(测试数据) - 错误))
print(完整循环一次的指标 + '=============')
评价指标
import numpy as np
import six
def 计算混淆矩阵(预测值, 真实标签):
预测值 = iter(预测值)
真实标签 = iter(真实标签)
类别数量 = 12
混淆矩阵 = np.zeros((类别数量, 类别数量), dtype=np.int64)
for 单个预测值, 单个真实标签 in six.moves.zip(预测值, 真实标签):
if 单个预测值.ndim != 2 or 单个真实标签.ndim != 2:
raise ValueError('预测值或标签必须为2维')
if 单个预测值.shape != 单个真实标签.shape:
raise ValueError('预测值和标签的尺寸必须相同')
预测值变换成一维向量 = 单个预测值.flatten()
标签变换成一维向量 = 单个真实标签.flatten()
预测和真实值中最大的类别索引 = np.max((预测值变换成一维向量, 标签变换成一维向量))
if 预测和真实值中最大的类别索引 >= 类别数量:
扩大混淆矩阵 = np.zeros((预测和真实值中最大的类别索引 + 1, 预测和真实值中最大的类别索引 + 1), dtype=np.int64)
扩大混淆矩阵[0:类别数量, 0:类别数量] = 混淆矩阵
类别数量 = 预测和真实值中最大的类别索引 + 1
混淆矩阵 = 扩大混淆矩阵
掩码 = 单个真实标签 >= 0
混淆矩阵 += np.bincount(类别数量 * 单个真实标签[掩码].astype(int) + 单个预测值[掩码], minlength=类别数量 ** 2).reshape((类别数量, 类别数量)) # N*L+P
for iter_ in (预测值, 真实标签):
# This code assumes any iterator does not contain None as its items.
if next(iter_, None) is not None:
raise ValueError('Length of input iterables need to be same')
return 混淆矩阵
def 计算语义分割的iou(混淆矩阵):
iou并集 = (混淆矩阵.sum(axis=1) + 混淆矩阵.sum(axis=0) - np.diag(混淆矩阵)) # 0列 1行
iou = np.diag(混淆矩阵) / iou并集
return iou[:-1] # 最末尾为背景 舍弃
def 验证语义分割指标(预测值, 真实标签):
混淆矩阵 = 计算混淆矩阵(预测值, 真实标签)
iou = 计算语义分割的iou(混淆矩阵)
像素精度 = np.diag(混淆矩阵).sum() / 混淆矩阵.sum()
类精度 = np.diag(混淆矩阵) / (np.sum(混淆矩阵, axis=1) + 1e10)
return {
'iou': iou,
'miou': np.nanmean(iou),
'像素准确度': 像素精度,
'分类精度': 类精度,
'平均分类精度': np.nanmean(类精度[:-1])
}
预测图像
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
import pandas as pd
import numpy as np
import evalution_segmentation
import cfg
from dataset import 数据集
from build_FCN_model import 全卷积网络
import datetime
from PIL import Image
计算单元 = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
权重路径 = 'E:/FCN_8X/weights/194.pth'
标签文件路径 = 'E:/Camvid-FCN/Datasets/CamVid/class_dict.csv'
测试数据实例化 = 数据集([cfg.测试数据集, cfg.测试标签数据集], (352, 480))
测试数据 = DataLoader(测试数据实例化, batch_size=4, shuffle=True, num_workers=0)
网络 = 全卷积网络(类别个数=12).to(计算单元)
网络.load_state_dict(torch.load(权重路径))
网络.eval()
预测标签的颜色 = pd.read_csv(标签文件路径, sep=',')
标签所对应的类别 = 预测标签的颜色['name'].values
标签类别的数量 = len(标签所对应的类别)
像素类别图 = []
for 类别 in range(标签类别的数量):
按行读取每一个类别所对应的像素值 = 预测标签的颜色.iloc[类别]
类别所对应的RGB像素值 = [按行读取每一个类别所对应的像素值['r'], 按行读取每一个类别所对应的像素值['g'], 按行读取每一个类别所对应的像素值['b']]
像素类别图.append(类别所对应的RGB像素值)
像素类别图转为np = np.array(像素类别图).astype('uint8')
输出图像保存路径 = 'E:/Camvid-FCN/test_pred_img/'
for 索引, 图像标签数据字典 in enumerate(测试数据):
测试图像数据 = 图像标签数据字典['图像'].to(计算单元)
测试图像标签 = 图像标签数据字典['标签'].long().to(计算单元)
预测 = 网络(测试图像数据)
预测 = F.log_softmax(预测, dim=1)
预测标签 = 预测.max(1)[1].squeeze().cpu().data.numpy()
预测标签图 = 像素类别图转为np[预测标签]
预测标签图 = 预测标签图.squeeze()
预测标签图转换格式并保存 = Image.fromarray(预测标签图)
预测标签图转换格式并保存.save(输出图像保存路径 + str(索引) + '.png')
print('完成')