python中文分词器pymmseg的安装实录
最近在用python做爬虫项目,感受到了python的强大,这期间要试试python的文本处理,要用到中文分词,故把我安装使用pymmseg的过程记录下来,作为备忘。
pymmseg的项目下载地址是https://code.google.com/p/pymmseg-cpp/downloads/list
选择下载源码包,自己编译,省的出现不兼容的情况。我选择的是pymmseg-cpp-src-1.0.2.tar.gz,下面是windows与linux平台的安装过程
64位win7下pymmseg安装过程:
1,解压,随便怎么解
2,确保你有一个命令行可用的C++编译器和连接器,我装了vs2008,就用了vs带的编译器,在vs开始菜单里找到"Visual Studio Tools"/"Visual Studio 2008 x64 Win64 命令提示",这个命令行窗口启动时会自动配好编译器和连接器的环境变量,可以直接使用cl,link等命令了。(64位的机器要用64位的编译器编译,否则32位编译器编译生成的dll,在64位系统中加载会出问题。同理32位的选32的命令窗口)
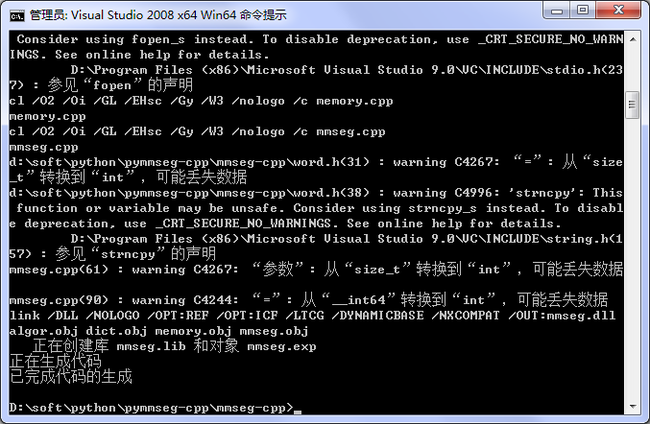
3,通过上面的命令行窗口进入解压后的目录,我这里是pymmseg-cpp,再进入子目录,mmseg-cpp,执行
1 python build.py
然后就是编译生成mmseg的过程,如下图:
4,这时将pymmseg-cpp的整个目录copy到$PYTHON_HOME/Lib/site-packages目录下,并重命名为pymmseg
5,测试是否可用:
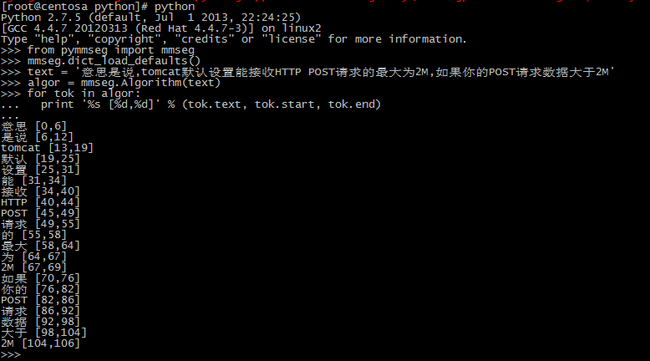
1 from pymmseg import mmseg 2 mmseg.dict_load_defaults() 3 text = '意思是说,tomcat默认设置能接收HTTP POST请求的最大为2M,如果你的POST请求数据大于2M' 4 algor = mmseg.Algorithm(text) 5 for tok in algor: 6 print '%s [%d..%d]' % (tok.text, tok.start, tok.end)
执行结果如下:
意思 [0..6] 是说 [6..12] tomcat [13..19] 默认 [19..25] 设置 [25..31] 能 [31..34] 接收 [34..40] HTTP [40..44] POST [45..49] 请求 [49..55] 的 [55..58] 最大 [58..64] 为 [64..67] 2M [67..69] 如果 [70..76] 你的 [76..82] POST [82..86] 请求 [86..92] 数据 [92..98] 大于 [98..104] 2M [104..106]
到此,说明pymmseg在win7 X64上完全可用了。
centos6.4 64位下pymmseg安装过程:
1,确保你安装了gcc,g++,没安gcc和g++的执行:
yum -y install gcc
yum -y install gcc-c++
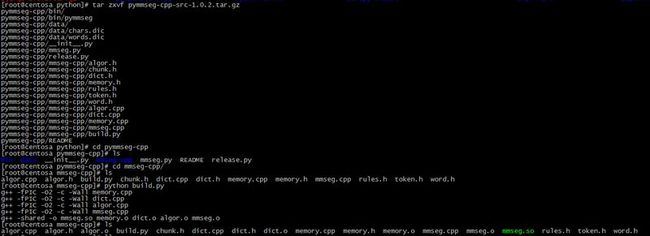
2,通windows上下载源码解压,进入目录,并进入子目录mmseg-cpp,执行:
python build.py
整个过程如下图:
同样将编译好的pymmseg-cpp拷贝到python的lib库下site-packages中并重命名为pymmseg,我是编译安装的python2.75,lib库的地址在/usr/local/lib/python2.7/
试验是否安装成功,如下图:
到此,windows与linux上的pymmseg均已安装完成,可以使劲的用了。