pytorch实现LSTM(附code)
目录
一、数据集介绍
二、数据预处理
三、python代码实现
参考
最近搞了一个NASA PCoE的IGBT加速老化数据,想基于pytorch框架写一个LSTM模型进行IGBT退化状态的预测,于是有了这篇文章。
注:LSTM的原理就不多讲了,网上一大堆,不懂的自己去百度,本文主要侧重代码实现。
一、数据集介绍
本数据集是NASA PCoE研究中心公布的IGBT加速老化数据集。数据集含有四种实验条件下的IGBT加速老化数据,以下是实验条件:
(1)新设备的源测量单元(SMU data for new devices)
该文件中含有一组原始实验条件下的电气特性数据,分别是型号为IRG4BC30K的20组IGBT和型号为IRG520Npbf的20组MOSFET,实验中测量的参数分别有泄漏电压、击穿电压、阀值电压,其中数据集中还有IGBT的开通和关断数据。
(2)在直流门电压下的加速热老化实验(Thermal Overstress Aging with DC at gate)
该文件包含器件型号为IRF-G4BC30KD的IGBT在门极施加高压时,由红外传感器进行温度测量,直至包装温度超出限定值,然后关闭门极电源。实验表明器件失效原因是闩锁效应(寄生的PNPN晶间管导通),失效过程中对集电极电流进行监测。
结果证明,集电极电流的变化是导致器件失效的原因,该实验测量数据是取自一个独立的IGBT模块。实验中测量参数分别有集电极电流、集电极电压、门极电压、包装温度,实验参数设置如下:

(3)在栅极施加方波电压下的加速老化实验(Thermal Overstress Aging with Square Signal at gate)
该文件包含了在栅极施加方波电压下的IGBT加速热老化实验数据。通过对功率器件IRG4BC30K的栅极施加频率为1kHz,占空比为40%,幅值为0-8V的方波信号,将封装温度控制在260°C-270°C,对器件进行持续过流高温老化实验。
其中有PWM(pwm temp controller state)工作条件下,低速(steady state)测量数据和开关装置瞬态(transient)特性下的高分辨率数据。在门极施加方波信号进行热循环实验,通过设备开关时刻收集瞬态数据。该实验目的是:当条件远远超出器件工作安全区时,把该器件作为一个开关使用。
实验中测量的主要参数分别有集电极电流、集电极电压、门极电压、包装温度。实验数据包中记录了器件工作时的集电极电流、集电极电压、门极电压、门极电流、包装温度、散热器温度、数据记录时间等参数。
(4)在栅极施加方波电压下和源测量单元下的热加速老化数据(Thermal Overstress Aging with Square Signal at gate and SMU data)
该文件包含在门极施加方波信号进行热循环,通过设备的开关时刻收集瞬态数据。
其中老化数据包含有三个参数:阈值电压,击穿电压和漏电流。
源测量单元(SMU)参数表征数据包含四个设备的数据,包装温度控制在一定范围内。由于器件开关速度难以控制,在输出波形的上升和下降处存在一些瞬态数据(高速测量下的集电极电流、门极电压、集射极电压)没有采集到,数据采集系统中由于缺乏校正分压器,故低速(过滤)数据没有办法度量。
实验中测量的主要参数分别有集电极电流、集电极电压、门极电圧、包装温度。实验过程中,由于设备老化过程中经历了几个问题,导致部分瞬态数据丢失,使得集电极电流数据存在600mA的漂移,而且稳态数据也不是非常精确。
博主选用数据集(3)中的IGBT集射极关断尖峰电压值(如下图)做为特征参数进行预测算法研究。
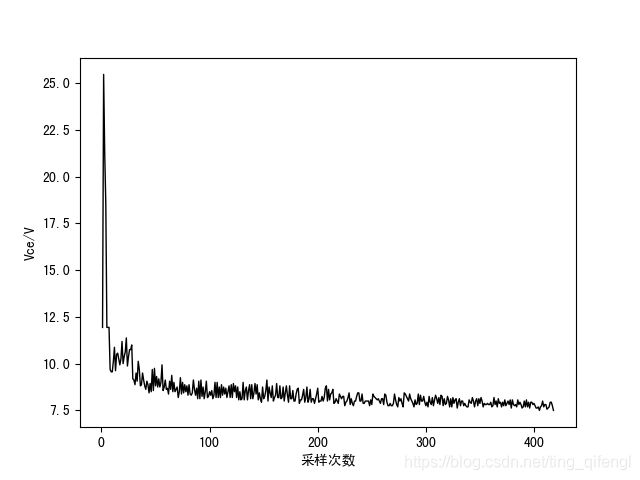
二、数据预处理
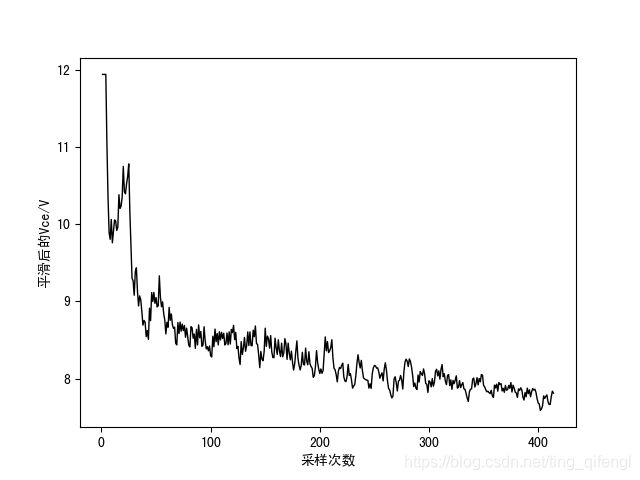
为了提高预测准确率,首先对数据进行异常值剔除、平滑和标准化处理。
使用二次指数平滑算法对数据进行平滑处理:
使用下图所示公式进行标准化处理:


由于尖峰电压值为离散的数据值,因此为输入LSTM网络需要构造自相关性时间序列数据样本。
使用滑动时间窗方法构造用于网络训练的数据样本,窗口大小设置为5。如:
使用![]() 作为样本,
作为样本,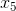 为样本标签,以此类推。
为样本标签,以此类推。
三、python代码实现
在保证输入样本参数和学习率不变的情况下,即input_size = 5,out_oput = 1,lr = 0.01,试了很多参数,发现在训练集80%,测试集20%,hidden_size = 20,加一个全连接层时结果最好(代码为CPU版本哦)。
import scipy.io as sio
import numpy as np
import torch
from torch import nn
import matplotlib.pyplot as plt
import matplotlib
import pandas as pd
from torch.autograd import Variable
import math
import csv
# Define LSTM Neural Networks
class LstmRNN(nn.Module):
"""
Parameters:
- input_size: feature size
- hidden_size: number of hidden units
- output_size: number of output
- num_layers: layers of LSTM to stack
"""
def __init__(self, input_size, hidden_size=1, output_size=1, num_layers=1):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers) # utilize the LSTM model in torch.nn
self.linear1 = nn.Linear(hidden_size, output_size) # 全连接层
def forward(self, _x):
x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
x = x.view(s * b, h)
x = self.linear1(x)
x = x.view(s, b, -1)
return x
if __name__ == '__main__':
# checking if GPU is available
device = torch.device("cpu")
if (torch.cuda.is_available()):
device = torch.device("cuda:0")
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')
# 数据读取&类型转换
data_x = np.array(pd.read_csv('Data_x.csv', header=None)).astype('float32')
data_y = np.array(pd.read_csv('Data_y.csv', header=None)).astype('float32')
# 数据集分割
data_len = len(data_x)
t = np.linspace(0, data_len, data_len + 1)
train_data_ratio = 0.8 # Choose 80% of the data for training
train_data_len = int(data_len * train_data_ratio)
train_x = data_x[5:train_data_len]
train_y = data_y[5:train_data_len]
t_for_training = t[5:train_data_len]
test_x = data_x[train_data_len:]
test_y = data_y[train_data_len:]
t_for_testing = t[train_data_len:]
# ----------------- train -------------------
INPUT_FEATURES_NUM = 5
OUTPUT_FEATURES_NUM = 1
train_x_tensor = train_x.reshape(-1, 1, INPUT_FEATURES_NUM) # set batch size to 1
train_y_tensor = train_y.reshape(-1, 1, OUTPUT_FEATURES_NUM) # set batch size to 1
# transfer data to pytorch tensor
train_x_tensor = torch.from_numpy(train_x_tensor)
train_y_tensor = torch.from_numpy(train_y_tensor)
lstm_model = LstmRNN(INPUT_FEATURES_NUM, 20, output_size=OUTPUT_FEATURES_NUM, num_layers=1) # 20 hidden units
print('LSTM model:', lstm_model)
print('model.parameters:', lstm_model.parameters)
print('train x tensor dimension:', Variable(train_x_tensor).size())
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=1e-2)
prev_loss = 1000
max_epochs = 2000
train_x_tensor = train_x_tensor.to(device)
for epoch in range(max_epochs):
output = lstm_model(train_x_tensor).to(device)
loss = criterion(output, train_y_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if loss < prev_loss:
torch.save(lstm_model.state_dict(), 'lstm_model.pt') # save model parameters to files
prev_loss = loss
if loss.item() < 1e-4:
print('Epoch [{}/{}], Loss: {:.5f}'.format(epoch + 1, max_epochs, loss.item()))
print("The loss value is reached")
break
elif (epoch + 1) % 100 == 0:
print('Epoch: [{}/{}], Loss:{:.5f}'.format(epoch + 1, max_epochs, loss.item()))
# prediction on training dataset
pred_y_for_train = lstm_model(train_x_tensor).to(device)
pred_y_for_train = pred_y_for_train.view(-1, OUTPUT_FEATURES_NUM).data.numpy()
# ----------------- test -------------------
lstm_model = lstm_model.eval() # switch to testing model
# prediction on test dataset
test_x_tensor = test_x.reshape(-1, 1,
INPUT_FEATURES_NUM)
test_x_tensor = torch.from_numpy(test_x_tensor) # 变为tensor
test_x_tensor = test_x_tensor.to(device)
pred_y_for_test = lstm_model(test_x_tensor).to(device)
pred_y_for_test = pred_y_for_test.view(-1, OUTPUT_FEATURES_NUM).data.numpy()
loss = criterion(torch.from_numpy(pred_y_for_test), torch.from_numpy(test_y))
print("test loss:", loss.item())
# ----------------- plot -------------------
plt.figure()
plt.plot(t_for_training, train_y, 'b', label='y_trn')
plt.plot(t_for_training, pred_y_for_train, 'y--', label='pre_trn')
plt.plot(t_for_testing, test_y, 'k', label='y_tst')
plt.plot(t_for_testing, pred_y_for_test, 'm--', label='pre_tst')
plt.xlabel('t')
plt.ylabel('Vce')
plt.show()结果如下图所示:

蓝线代表训练集真实值,黄线代表训练集预测值
黑线代表测试集真实值,紫线代表测试集预测值
test_loss=0.004276850726
完整代码及处理好的数据集请点击。
参考
点击
喜欢的话就麻烦动动小手点个赞吧~~~万分感谢啦!