一个非教条式的TDD例子
问题背景
数据分批器这个名字是我临时起的一个名字,源于我辅导的客户团队开发人员在当时的核心系统中要解决的一个实际业务问题 —— Oracle的数据库删除每次只支持1000条。这个问题更确切的讲是因为Oracle对下面这句SQL语句的支持约束:
delete from t_table where id in (ids)
问题就出在这个where id in …上,后面传入的集合参数ids最大支持1000条。而实际业务场景中存在大于1000条数据,所以需要进行分批处理。
针对这个问题,我暂时不去探究这个SQL机制本身的合理性[1]。本文我想借这个机会聊聊如何运用TDD的方式去完成这个数据分批处理的设计和开发。
需求分解
基于这样的问题,我的习惯是先对问题进行分解,也就是TDD前要做的一个关键动作 —— Tasking。我快速做了个Tasking:
- 非1000的整数倍,小于1000条
- 1000的整数倍
- 非1000的整数倍,大于1000条
基于Tasking结果,对上述需求场景进行实例化,实例化过程中,边界值是我要考虑的重点:
- 非1000的整数倍,小于1000条
- 0条
- 369条
- 1000的整数倍
- 1000条
- 2000条
- 非1000的整数倍,大于1000条
- 1369条
- 2222条
原有设计
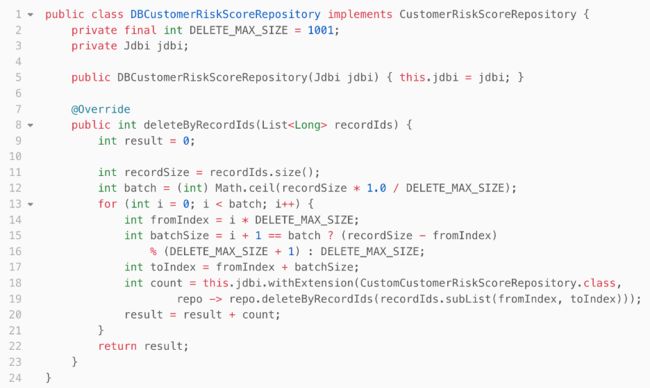
上述代码的for循环中做了两件事,边截取不同范围的recordsId,边调用了 CustomCustomerRiskScoreRepository 来做数据库操作,分批逻辑和存储夹杂在一起的过程式设计的好处是直接了当,当然也让 deleteByRecordIds() 的职责过多。
新的设计
基于我对软件设计浅薄的理解,我认为这个分批逻辑和Repository数据存储逻辑分开会更优雅,支持我的几个主要理由是:
- 数据存储逻辑更加纯粹,它只用关心数据的CRUD。
- 重要:分批逻辑可以很方便地进行自动化测试。
- 分批逻辑独立出来,方便复用和维护。
基于以上的几点理由,我在原来的过程式程序设计的基础上引入一些OO的理念,进行对象建模,比如抽象出一个数据分批器。我把对象建模过程看做在TDD之前的一些简单且必要的设计。
TDD不太提倡在开始前不做任何设计,恰恰它提倡做一些简单且必要的程序接口设计 —— 非教条主义
通过对象建模分析,我设计了两个简单的对象,一个是BatchDivider,另一个是Range,UML如下:
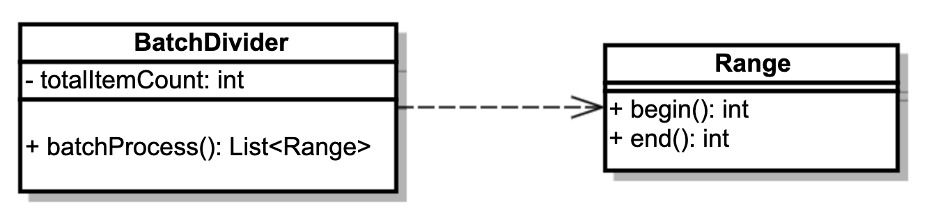
BatchDivider接收一个总数,然后能够返回一个包含了起止的范围的集合,比如接收1369条,返回集合[Range(0, 1000), (1000, 1369)],起止信息我用Range对象来表示。
前期的设计就做到这,我没有花太多时间去纠结细节,因为现在的设计足够让我起步了。如果在后续发现了不完善的地方,交给后续的驱动和重构。
编码落地
至此,我已经把需求进行了分解和实例化,然后也做了简单的程序设计,跑步前的热身完毕,接下来我就打算采用TDD的跑姿小跑起来。
之前的实例化我写得比较简单,由于我习惯用Given-When-Then的方式来描述,我把之前简单的实例化再结合当前的程序设计做了细化:
非1000的整数倍,小于1000条
- 0条
- Given 待分批数据是0条
- When 分批处理
- Then 批次结果为空集合, []
- 369条
- Given 待分批数据是369条
- When 分批处理
- Then 批次结果包含1个Range的集合,[(0, 369)]
1000的整数倍
- 1000条
- Given 待分批数据是1000条
- When 分批处理
- Then 批次结果包含1个Range的集合,[(0, 1000)]
- 2000条
- Given 待分批数据是2000条
- When 分批处理
- Then 批次结果包含2个Range的集合,[(0, 1000), (1000, 2000)]
非1000的整数倍,大于1000条
- 1369条
- Given 待分批数据是1369条
- When 分批处理
- Then 批次结果包含2个Range的集合,[(0, 1000), (1000, 1369)]
- 2222条
- Given 待分批数据是2222条
- When 分批处理
- Then 批次结果包含3个Range的集合,[(0, 1000), (1000, 2000), (2000, 2222)]
第1个测试
- Given 待分批数据是0条
- When 分批处理
- Then 批次结果为空集合, []
在编写测试代码时,有一种做法是从结果往前驱动,比如我会先写assert,然后按照思维意图一步一步往前倒逼我去命名变量,去给变量赋值。下面是我写的第1个测试用例:

你现在看到的5 ~ 11行代码,我的编写顺序是11 --> 5。这仅仅是我个人的习惯,因为受到以终为始和意图导向编程观念的影响,养成了这样的习惯。Kent Beck在《测试驱动开发》也提到了这种方式。
按照反向驱动的方式写出来的代码,我发现测试代码中的一些没必要的临时变量,但我先不着急去重构,我先聚焦让这个测试通过,至少现在的代码可读性也非常好。很快,借助IDE的快捷键,我编写了让测试通过的实现代码:

我使用了伪实现让测试快速通过,紧接着借助Inline手法清除了测试代码中没必要的临时变量totalItemSum和batchCount。
第2个测试
- Given 待分批数据是369条
- When 分批处理
- Then 批次结果包含1个Range的集合,[(0, 369)]
第二个测试起名为 given_item_count_below_1000 ,这里我没有使用具体的实例化数据369,你或许会起名为 given_item_count_is_369。我个人习惯采用抽象场景来命名,因为我觉得能够更直观的提供业务场景的信息。

第二个测试,我直接给ranges添加了一个Range对象,并保留了上一个测试的判断,快速地让测试通过了:

第3个测试
- Given 待分批数据是1000条
- When 分批处理
- Then 批次结果包含1个Range的集合,[(0, 1000)]

这个测试运行之后直接通过了,万事大吉,运气还不错。
第4个测试
- Given 待分批数据是2000条
- When 分批处理
- Then 批次结果包含2个Range的集合,[(0, 1000), (1000, 2000)]

为了通过这个测试,我编写了如下的功能代码,节省篇幅,我只摘取了核心的batchProcess方法:

很顺利,我通过了第四个测试,我发现该方法中1000这个数字出现了好几次,这是个魔法数字,而且重复出现,在我看来这就是一只携带了两种味道的恶魔,于是抽取一个常量ONE_BATCH_SIZE。
正当我准备写下一个测试时,我运行了之前的所有测试,发现第2个测试挂了 —— 我破坏了原来的功能。我回头检查了 batchProcess 方法的实现,原来是 totalItemCount / ONE_BATCH_SIZE 这个运算出了问题,当totalItemCount = 369的时候,整除结果为0。
定位到问题,基于之前的开发经验,我尝试了Math函数的几个方法,最终找到了 Math.ceil(double) 方法:
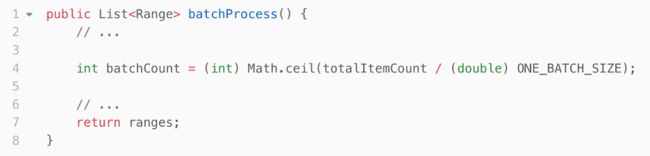
修复第2个测试之后,我心里给TDD点了个赞:TDD所构建的测试安全网可以为重构提供保护,如果功能被破坏,测试很快就能发现,这让我去更有勇气去重构。
第5个测试
- Given 待分批数据是1369条
- When 分批处理
- Then 批次结果包含2个Range的集合,[(0, 1000), (1000, 1369)]

第6个测试
- Given 待分批数据是2222条
- When 分批处理
- Then 批次结果包含3个Range的集合,[(0, 1000), (1000, 2000), (2000, 2222)]
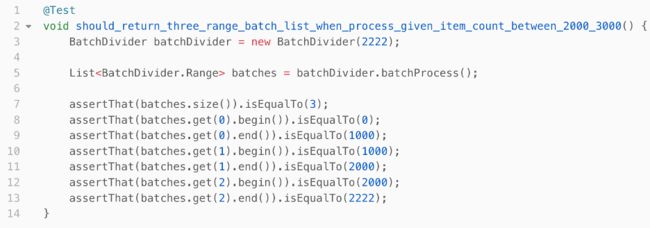
这个测试也直接通过了,到目前为止,所有的测试运行结果都是绿色的。基于当前的6个测试,我对当前的程序非常有信心了,先前实例化的场景也都覆盖了,所以我准备停下来去倒杯水。
可规避的教条
教条:提前设计不可有
不是说TDD指Test-Driven Design,设计是由测试驱动出来的吗,提前设计怎么交待呢?
TDD通常也会被解读为:测试驱动设计。关于测试驱动设计,我觉得一点点提前设计是有必要的,它给了我一个宏观的方向,让我能够顺利地开始。我的个人习惯是,在开始写测试代码前我会做一些简单的纸面设计,做一些简单的对象建模,定义好一些对外的接口。在早期,我也不会写纸面的设计,而是直接开始写测试代码,实际上我在写测试的时候脑海里是有设计的,只是我没有显性化出来。
一方面由于年龄增加,另一方面,面临的问题很多时候没这么简单,显性化出来可以减轻我大脑负载,并且还能带来一些其他的好处。
另外,我发现Uncle Bob在做TDD的时候也会做一些简单必要的提前设计。比如,他在演示TDD Kata 保龄球的时候就这么干过。
教条:新增测试要见红
TDD循环圈红-绿-重构,新增的测试必须要挂掉,上面第3、5、6,三个测试都直接绿了,你这TDD是在骗人的吧?
之前公司有Senior的同事就和我恨恨地讨论过这点,说实话我没有什么理由去反驳这个观点,但我没想明白的是为什么新增一个测试如果直接通过了就不是TDD了呢。测试直接通过了不是更好嘛?当然前提是你的测试是对的。
后来我观察了很多初学者在练习TDD时的做法,搞明白这种想法背后的担心。我看有人写了第一个测试,然后花很多时间去写实现,结果一股脑实现了很多场景的功能。讲真,这样做也未尝不可,但从体会TDD的聚焦性和驱动性上来看,这个做法恐怕难以达到目的,这也是TDD门槛高的原因之一 —— 难以控制自己。但从实用性来看,一股脑写完好几个场景的功能实现,然后补上后面几个场景的测试,也并非不可。要知道咱们写代码的初衷是什么 —— 交付可用软件,或美其名曰交付可用的高质量软件。
所以,为了在学习TDD时更好自控,就有了这样的一个教条 —— 新增的测试一定得是挂的。但很多时候在编码过程中,由于编程语言的便捷性,我们在快速、简单地实现了某个边界场景用例时难免会存在让下一个测试直接通过的情况,比如我在写第4个测试的时候,我直接使用了这个算法:
int batchCount = (int) Math.ceil(totalItemCount / (double) ONE_BATCH_SIZE);
我没有再花心思去想怎么搞个hard code参数是2000,再加一个if判断。因为基于前面几个测试的知识和经验积累,我已经掌握了让当前测试通过的算法,而且不会比我hard code更花时间。要说快,我直接上这个会更快。写完后我其实能预测到后面两个测试会直接通过,但我还是会加上后面两个测试,因为这不仅仅关乎TDD的姿势,更关乎TDD本真的东西 —— 测试保护网。
另外,也可能是由于在拆分任务的时候太细,使用了不同的数据来实例化了同一类场景,导致测试用例有交叉,又或者是拆分场景不合理产生了重复,此时也是一个反馈调整任务列表的契机。
教条:通过测试唯快不破
TDD循环圈强调要以最快的速度、最简单丑陋的方式让测试快速通过,你这写多了啊?
这个教条跟上一个是紧密相关的,在上一条后半部分也在解释这个。有时候我明明写一个功能完整的代码比简单、丑陋的代码要更快,我就不会再去hard code,然后假装庆祝自己是在做“真”TDD。Kent Beck在《测试驱动开发》一书的可运行模式中提到,快速让测试通过的三种方法:
- 伪实现
- 三角法
- 显明实现
我理解这种观点的支撑点在于对伪实现和三角法使用,它认为设计应该是通过大量实例化的测试用例驱动出来的。对于那些很复杂的业务场景,通过简单的几个用例确实没法有效看清抽象模式,浮现不出良好的设计,伪实现和三角法不失为一种好的驱动方式。但有时候,你对设计很清楚,实现很明显,这个时候何不直接上呢?我在第2个测试的实现中采用了伪实现,而在第4个中由于我破坏了之前的测试,我直接上了Math.ceil函数,没想到实现了最终的功能。
我提倡的“教条”
提倡:显性化知识
这么简单的业务需求,我脑袋瓜子完全够用,有必要这么麻烦显性地呈现出来吗?
我认为有必要写出来,俗话说好记性不如烂笔头。在整理呈现的过程中,我会投入更多的时间思考,思考有没有准确理解业务?思考如何能够让别人更容易理解?另外,它还可以作为一个显性的计划工具,帮助我评估我未来的工作。有了它,我跟团队成员沟通起来也更高效,并且在后续非单线程的工作模式中更容易聚焦重点,更方便我去检查任务进展。在我看来,可视化的动作能让Tasking发挥以下四个工具价值:
- 显性的计划工具
- 高效的沟通工具
- 便捷的检查工具
- 进化的思维工具
话说回来,写出来并不会花太多时间吧,写不出来就去做,有可能是因为还想不清楚,想不清楚的话就有危险了。问题域越复杂,这里越值得花时间去想。
提倡:夯实基本功
总是拿玩具代码来忽悠新人,在实际项目中远比这复杂的多,还是搞不定呀?
说到这个,我想起了我跟羽毛球的故事。我是2020年8月份的时候才正式接触羽毛球,在这之前我平均一年打球不到5次,在这之后我最多的时候一周就超过了5次。以前,我无知地以为羽毛球没什么复杂的,拿个拍子,场上跑跑,基本上人人都会,压根用不着花钱找教练。后来场上数次被虐的“耻辱”让我不得不去好好了解一下羽毛球。不学不知道,一学吓一跳,简单罗列一下:
-
身体基本功:体能、爆发力、耐力、反应速度、弹跳
-
基础:发力、握拍、举拍、步伐(6个方向,1~3步)
-
技巧:发球、接发球、吊球、勾对角、平抽、高远球、杀球、接杀球、封网、搓球
-
站位:男单、女单、男双、混双
上面列出来的还不齐全,并且基本功和技巧都涵盖了正手和反手。羽毛球的技巧和战术如此之多,每一个都够练习一阵子,羽毛球的羽字:一分为二,学习 + 练习,这个字让我感慨真不是随意取的(为了帮助广大球友快速成长,我整理了羽球知识库,请在文末获取[2])。
我可以在这些技巧都不会或者都不娴熟的情况下,跳过针对性的基本功练习,直接上场叫嚣要跟高手拉练,难免自取其辱还得不到有效提升。认识到这点之后,唯有日练挥拍近千次来夯实基本功方可让我有勇气尝试挑战高手。
“练球不练功,打球一场空”。我认为学习TDD也是一样的道理,实际项目中确实业务和架构复杂得多,但这不该成为你拒绝以简单的案例入手去练习基本功的理由。再复杂的案例,元能力是类似的。
早在2018年底的,我给武汉某Offshore团队做了一场OOBootcamp,大家觉得ParkingLot不过瘾,在训练营快结束的时候,我带大家探讨了在一个Java SpringBoot后端分层架构中如何落地TDD。有了训练营的刻意练习,团队很快在后端分层架构中实践落地了TDD。
所以,我个人认为基本功是首要的,如果你还没有尝试过TDD,不妨先抛开怀疑,先去尝试一下。
写在最后
我接触TDD有7年多时间了,至今未通透,仍在努力学习中。在实际项目落地TDD以及在TDD训练营中,我会坚持一些原则,主要有以下三点:
- Tasking优先性
- 设计轻量性
- 知识明显性
对业务需求进行Tasking的过程能够让我重新梳理业务,并且减少理解上的偏差和遗漏,避免在后续开发过程出现返工,造成更高的修改成本。即便你做不到测试先行,Tasking也值得去做好。
设计本身就是一种不可言说的知识,何为简单且必要的设计?何为恰到好处的设计?不是看了几本书、借用几个大牛的三两句话就能说清的,更多源自于日常实践中的思考和总结。
针对Tasking的产出物,我会使用可视化和结构化的方式显性化管理起来,以便跟业务人员沟通确认,并更好地在团队内共享。
三条中前两条对个人底层胜任力提出了要求。Tasking做得质量如何,比较依赖个人的分析性思维,设计做的好不好,考验的是一个人对设计的Sense。这些能力不会那么轻易通过短期的培训得到提升,但好在我们每个人都具备一些基础。在这样的基础前提下,结合一些结构化良好的显性知识管理方式,坚持跟时间赛跑吧。
补充说明
改进
在这个数据分批器案例中,测试用例和设计上都有可以改进的地方,比如:
- 测试用例使用jUnit 5的参数化测试,测试断言的优化;
- 消除「域冗余」:方法BatchDivider.batchProcess() --> BatchDivider.process();
- BatchDivider也可以做得更简单,让其成为一个静态工厂方法,变身为工具类;
- BatchDivider还可以将分批处理的结果存起来,方便重复获取;
- BatchDivider再或者后期需要支持动态分批,比如500一批,2000一批;
- 喜欢Java Stream API的小伙伴可以Stream来实现BatchDivider
- 等等其他未知改进;
改进无止境,希望我想分享的点得到传达,更多的优化留给文后有心的你。
手稿
过程我大概花了45分钟的时间,从需求分解、前期设计、代码库的搭建和功能实现,为了节省时间,我原先用的是手稿,文中是我后来另做了文字化。下图是留作纪念的手稿:
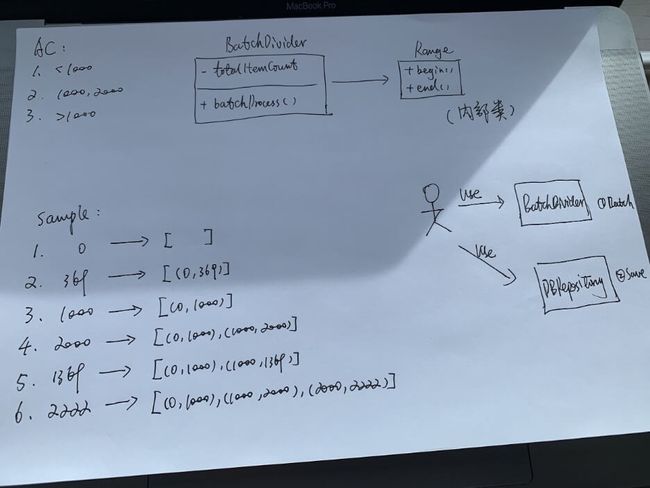
注释
-
Oracle的SQL语句参数不能大于1000,通常where in里参数会很多,如果BATCH_SIZE设置为1000,而SQL语句中还有其他参数的时候,参数总数仍然会超出1000,会导致程序错误
-
羽球知识库链接:羽球资源库(2021持续更新)
-
原文:https://www.yuque.com/yuanshenjian/clean-coder/non-dogmatic-tdd-case
文/Thoughtworks 袁慎建
原文链接:一个TDD的小案例-Thoughtworks洞见