面试常背八股文
可能部分本地图片上传出现问题,需要完整文件私信我发你压缩文件哈~
Java基础
为什么Java代码可以实现一次编写、到处运行?
Java源代码(.java)需要经过编译器编译成字节码(.class)。在程序运行时,JVM负责将字节码翻译成特定平台下的机器码并运行。只要在不同的平台上安装对应的JVM,就可以运行字节码文件。
python相对于java的缺点
1)Python的执行速度不够快:Python的缺点主要是执行速度还不够快。当然,这并不是一个很严重的问题,一般情况下,我们不会拿Python语言与C/C++这样的语言进行直接比较。在Python语言的执行速度上,一方面,网络或磁盘的延迟会抵消部分Python本身消耗的时间;另一方面,因为Python特别容易和C结合使用,所以我们可以通过分离一部分需要优化速度的应用,将其转换为编译好的扩展,并在整个系统中使用Python脚本将这部分应用连接起来,以提高程序的整体效率。
2)无法有效利用多线程:因为python内部有一个锁,导致多线程的cpu效率提升不大。Python的GIL锁限制并发:Python的另一个大问题是,对多处理器支持不好。如果你接触Python的时间比较长,那就一定听说过GIL。GIL是指Python全局解释器锁(Global Interpreter Lock),当Python的默认解释器要执行字节码时,都需要先申请这个锁。这意味着,如果试图通过多线程扩展应用程序,将总是被这个全局解释器锁限制。当然,我们可以使用多进程的架构来提高程序的并发,也可以选择不同的Python实现来运行我们的程序。
3)Python 2与Python 3不兼容:如果一个普通的软件或者库不能够做到向后兼容,它一定会被用户无情地抛弃。在Python中,一个大的槽点就是Python 2与Python 3不兼容。这给所有Python工程师带来了无数烦恼。
4)Python在编译时不检查变量类型
Python将类型与对象关联,而不是与变量关联,这就意味着Python 解释器无法识别出变量类型不符的错误。假设变量count本来是用来保 存整数的,但如果将字符串"two"赋给它,在Python里也完全没问题。 传统的程序员将这种处理方式算作一个缺点,因为对代码失去了额外的 免费检查。
Java中主要有八种基本数据类型?
- 整型:byte、short、int、long
- 字符型:char
- 浮点型:float、double
- 布尔型:boolean
Java 语言有哪些特点?
- 简单易学;
- 面向对象(封装,继承,多态);
- 平台无关性( Java 虚拟机实现平台无关性);
- 支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
- 可靠性;
- 安全性。
JVM vs JDK vs JRE
- Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
- JDK 是 Java Development Kit 缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
- **JRE 是 Java 运行时环境。**它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
Java 和 C++ 的区别?
- Java 不提供指针来直接访问内存,程序内存更加安全
- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
- Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
- C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
基本类型和包装类型的区别?为啥会有包装类?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HqrV5gUb-1666488157629)(image-20220906210849738.png)]
Java语言是面向对象的语言。但8种基本数据类型却出现了例外,它们不具备对象的特性。正是为了解决这个问题,Java为每个基本数据类型都定义了一个对应的引用类型,这就是包装类。
深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- **深拷贝 :**深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
- **引用拷贝:**就是两个不同的引用指向同一个对象。
面向对象和面向过程的区别
两者的主要区别在于解决问题的方式不同:
- 面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
- 面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。
创建一个对象用什么运算符?对象实体与对象引用有何不同?
new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向 0 个或 1 个对象;一个对象可以有 n 个引用指向它。
对象的相等和引用相等的区别
- 对象的相等一般比较的是内存中存放的内容是否相等。
- 引用相等一般比较的是他们指向的内存地址是否相等
一个Java文件里可以有多个类吗(不含内部类)?
一个java文件里可以有多个类,但最多只能有一个被public修饰的类;如果这个java文件中包含public修饰的类,则这个类的名称必须和java文件名一致。
说一说你对Java访问权限的了解?
Java中的变量分为成员变量和局部变量,它们的区别如下:
-
成员变量:成员变量是在类的范围里定义的变量;成员变量有默认初始值;
-
实例变量:未被static修饰的成员变量也叫实例变量,它存储于对象所在的堆内存中,生命周期与对象相同;
-
类变量:被static修饰的成员变量也叫类变量,它存储于方法区中,生命周期与当前类相同。
-
-
局部变量:局部变量是在方法里定义的变量;局部变量没有默认初始值;局部变量存储于栈内存中,作用的范围结束,变量空间会自动的释放。
如何对Integer和Double类型判断相等?
- 不能用==进行直接比较,因为它们是不同的数据类型;
- 不能转为字符串进行比较,因为转为字符串后,浮点值带小数点,整数值不带,这样它们永远都不相等;
- 不能使用compareTo方法进行比较,虽然它们都有compareTo方法,但该方法只能对相同类型进行比较。
- 可以将Integer、Double先转为转换为相同的基本数据类型(如double),然后使用==进行比较。
说说自动装箱、自动拆箱的应用场景?
- 自动装箱、自动拆箱是JDK1.5提供的功能。
- 自动装箱:可以把一个基本类型的数据直接赋值给对应的包装类型;
- 自动拆箱:可以把一个包装类型的对象直接赋值给对应的基本类型;
- 某个方法的参数类型为包装类型,调用时我们所持有的数据却是基本类型的值,则可以不做任何特殊的处理,直接将这个基本类型的值传入给方法即可。
面向对象的三大特征是什么?
面向对象的程序设计方法具有三个基本特征:封装、继承、多态。
- 封装指的是将对象的实现细节隐藏起来,然后通过一些公用方法来暴露该对象的功能;
- 继承是面向对象实现软件复用的重要手段,当子类继承父类后,子类作为一种特殊的父类,将直接获得父类的属性和方法;
- 多态指的是子类对象可以直接赋给父类变量,但运行时依然表现出子类的行为特征,这意味着同一个类型的对象在执行同一个方法时,可能表现出多种行为特征。Person p = new Student();
封装的目的是什么,为什么要有封装?
封装是面向对象编程语言对客观世界的模拟,在客观世界里,对象的状态信息都被隐藏在对象内部,外界无法直接操作和修改。对一个类或对象实现良好的封装,可以实现以下目的:
- 隐藏类的实现细节;
- 让使用者只能通过事先预定的方法来访问数据,从而可以在该方法里加入控制逻辑,限制对成员变量的不合理访问;
- 可进行数据检查,从而有利于保证对象信息的完整性;
- 便于修改,提高代码的可维护性。
说一说你对多态的理解?
因为子类其实是一种特殊的父类,因此Java允许把一个子类对象直接赋给一个父类引用变量,无须任何类型转换,或者被称为向上转型,向上转型由系统自动完成。当把一个子类对象直接赋给父类引用变量时,例如 BaseClass obj = new SubClass();,这个obj引用变量的编译时类型是BaseClass,而运行时类型是SubClass,当运行时调用该引用变量的方法时,其方法行为总是表现出子类方法的行为特征,而不是父类方法的行为特征,这就可能出现:相同类型的变量、调用同一个方法时呈现出多种不同的行为特征,这就是多态。
Java中的多态是怎么实现的?
多态的实现离不开继承,在设计程序时,我们可以将参数的类型定义为父类型。在调用程序时,则可以根据实际情况,传入该父类型的某个子类型的实例,这样就实现了多态。对于父类型,可以有三种形式,即普通的类、抽象类、接口。对于子类型,则要根据它自身的特征,重写父类的某些方法,或实现抽象类/接口的某些抽象方法。
Java为什么是单继承,为什么不能多继承?
- 首先,Java是单继承的,指的是Java中一个类只能有一个直接的父类。Java不能多继承,则是说Java中一个类不能直接继承多个父类。
- 其次,Java在设计时借鉴了C++的语法,而C++是支持多继承的。Java语言之所以摒弃了多继承的这项特征,是因为多继承容易产生混淆。比如,两个父类中包含相同的方法时,子类在调用该方法或重写该方法时就会迷惑。
说一说重写与重载的区别

构造方法能不能重写?
构造方法不能重写。因为构造方法需要和类保持同名,而重写的要求是子类方法要和父类方法保持同名。如果允许重写构造方法的话,那么子类中将会存在与类名不同的构造方法,这与构造方法的要求是矛盾的。
介绍一下Object类中的方法?
Object类提供了如下几个常用方法:
- getClass():返回该对象的运行时类。
- equals(Object obj):判断指定对象与该对象是否相等。
- hashCode():返回该对象的hashCode值。在默认情况下,Object类的hashCode()方法根据该对象的地址来计算。但很多类都重写了Object类的hashCode()方法,不再根据地址来计算其hashCode()方法值。
- toString():返回该对象的字符串表示,当程序使用System.out.println()方法输出一个对象,或者把某个对象和字符串进行连接运算时,系统会自动调用该对象的toString()方法返回该对象的字符串表示。Object类的toString()方法返回 运行时类名@十六进制hashCode值 格式的字符串,但很多类都重写了Object类的toString()方法,用于返回可以表述该对象信息的字符串。
- 另外,Object类还提供了wait()、notify()、notifyAll()这几个方法,通过这几个方法可以控制线程的暂停和运行。Object类还提供了一个clone()方法,该方法用于帮助其他对象来实现“自我克隆”
说一说hashCode()和equals()的关系?
hashCode()用于获取哈希码(散列码),eauqls()用于比较两个对象是否相等,它们应遵守如下规定:
- 如果两个对象相等,则它们必须有相同的哈希码。
- 如果两个对象有相同的哈希码,则它们未必相等。
HashSet如何判断加入的元素是否重复?
- 在Java中,Set接口代表无序的、元素不可重复的集合,HashSet则是Set接口的典型实现。
- 当向HashSet中加入一个元素时,它需要判断集合中是否已经包含了这个元素,从而避免重复存储。实际上,HashSet是通过获取对象的哈希码,以及调用对象的equals()方法来解决这个判断问题的。
- HashSet首先会调用对象的hashCode()方法获取其哈希码,并通过哈希码确定该对象在集合中存放的位置。假设这个位置之前已经存了一个对象,则HashSet会调用equals()对两个对象进行比较。若相等则说明对象重复,此时不会保存新加的对象。若不等说明对象不重复,此时HashSet会采用链式结构在同一位置保存多个对象,即将新加对象链接到原来对象的之后。之后,再有新添加对象也映射到这个位置时,就需要与这个位置中所有的对象进行equals()比较,若均不相等则将其链到最后一个对象之后。
==和equals()有什么区别?
==运算符:
- 作用于基本数据类型时,是比较两个数值是否相等;
- 作用于引用数据类型时,是比较两个对象的内存地址是否相同,即判断它们是否为同一个对象;
equals()方法:
- 没有重写时,Object默认以 == 来实现,即比较两个对象的内存地址是否相同;
- 进行重写后,一般会按照对象的内容来进行比较,若两个对象内容相同则认为对象相等,否则认为对象不等。
怎么重写equal方法?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EMkHrmWO-1666488157630)(%E6%88%AA%E5%B1%8F2022-09-13%2019.19.53-16630716078925.png)]
第一步、判断 从上边的equals传过来的参数name2对应的也就是o是否为空,如果为空那么没有比较的意义了返回false
第二步、判断 o是不是一个Object 因为我们要比较的两个肯定是相同类型的 不是相同类型的 那就不是相同的了 返回false
第三步判断 他们的内存地址是否相同 this表示当前的调用的 通俗点就是谁调用我谁就是this 由上面我们可以看出来 name1是this 然后o是name2 如果两个住在一个家 那就为一个人了 返回true
如果o不是null 又是Object 同时 和this(也就是name1)的内存地址不同 没有返回值返回
那么判断第四步 :
首先由于o是Obejct 因此进行向下类型转换 把它转换为Name
然后再由this.name也就是 调用者(name1)的name和强转之后的o(也就是n)的name
进行比较 判断两个成员变量的值是否相同 也就是比较名字 名字相同那么这两个值就相同 返回true
String类有哪些方法?
char charAt(int index)//返回指定索引处的字符;
String substring(int beginIndex, int endIndex)//从此字符串中截取出一部分子字符串;
String[] split(String regex)//以指定的规则将此字符串分割成数组;
String trim()//删除字符串前导和后置的空格;
int indexOf(String str)//返回子串在此字符串首次出现的索引;
int lastIndexOf(String str)//返回子串在此字符串最后出现的索引;
boolean startsWith(String prefix)//判断此字符串是否以指定的前缀开头;
boolean endsWith(String suffix)//判断此字符串是否以指定的后缀结尾;
String toUpperCase()//将此字符串中所有的字符大写;
String toLowerCase()//将此字符串中所有的字符小写;
String replaceFirst(String regex, String replacement)//用指定字符串替换第一个匹配的子串;
String replaceAll(String regex, String replacement)//用指定字符串替换所有的匹配的子串。
String可以被继承吗?
String类由final修饰,所以不能被继承。
说一说String和StringBuffer有什么区别
String类是不可变类,即一旦一个String对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁。
StringBuffer对象则代表一个字符序列可变的字符串,当一个StringBuffer被创建以后,通过StringBuffer提供的append()、insert()、reverse()、setCharAt()、setLength()等方法可以改变这个字符串对象的字符序列。一旦通过StringBuffer生成了最终想要的字符串,就可以调用它的toString()方法将其转换为一个String对象。
说一说StringBuffer和StringBuilder有什么区别?
StringBuffer、StringBuilder都代表可变的字符串对象,它们有共同的父类 AbstractStringBuilder,并且两个类的构造方法和成员方法也基本相同。不同的是,StringBuffer是线程安全的,而StringBuilder是非线程安全的,所以StringBuilder性能略高,速度快。一般情况下,要创建一个内容可变的字符串,建议优先考虑StringBuilder类。
Stringbuffer如何实现线程安全?
通过查看源码,可以知道:StringBuffer和StringBuilder来源出处是一致的,继承相同的类,实现相同的接口
而StringBuffer从JDK1.0时就有了,StringBuilder从JDK1.5才出现;所以我们可以清楚,StringBuilder就是为了提升StringBuffer效率而出现的
通过查看二者的源码,可以发现:
StringBuffer重写了length()和capacity()、append等方法,在他们的方法上面都有synchronized 关键字实现线程同步- StringBuilder并没有
“hello” 和 new String(“hello”) 的区别:
- 当Java程序直接使用 “hello” 的字符串直接量时,JVM将会使用常量池来管理这个字符串;在执行这句话时,JVM会先检查常量池中是否已经存有"hello",若没有则将"hello"存入常量池,否则就复用常量池中已有的"hello",将其引用赋值给变量a。
- 当使用 new String(“hello”) 时,JVM会先使用常量池来管理 “hello” 直接量,再调用String类的构造器来创建一个新的String对象,新创建的String对象被保存在堆内存中。
- 显然,采用new的方式会多创建一个对象出来,会占用更多的内存,所以一般建议使用直接量的方式创建字符串。
两个字符串相加的底层是如何实现的?字符串拼接的理解?
拼接字符串有很多种方式,其中最常用的有4种,下面列举了这4种方式各自适合的场景。
- + 运算符:**如果拼接的都是字符串直接量,则在编译时编译器会将其直接优化为一个完整的字符串,则适合使用 + 运算符实现拼接;如果拼接的字符串中包含变量,则在编译时编译器采用StringBuilder对其进行优化,即自动创建StringBuilder实例并调用其append()方法**,将这些字符串拼接在一起,效率也很高。
- **StringBuilder:**如果拼接的字符串中包含变量,并不要求线程安全,则适合使用StringBuilder;
- **StringBuffer:**如果拼接的字符串中包含变量,并且要求线程安全,则适合使用StringBuffer;
- **String类的concat方法:**如果只是对两个字符串进行拼接,并且包含变量,则适合使用concat方法;先创建一个足以容纳待拼接的两个字符串的字符数组,然后先后将两个字符串拼到这个数组里,最后将此数组转换为字符串。
接口中可以有构造函数吗?
由于接口定义的是一种规范,因此接口里不能包含构造器和初始化块定义。接口里可以包含成员变量(只能是静态常量)、方法(只能是抽象实例方法、类方法、默认方法或私有方法)、内部类(包括内部接口、枚举)定义。
抽象类含有构造器(构造函数)吗?
抽象类可以有构造方法,只是不能直接创建抽象类的实例对象而已。在继承了抽象类的子类中通过super()或super(参数列表)调用抽象类中的构造方法。
接口和抽象类有什么相同点和区别?
从设计目的上来说,二者有如下的区别:
- 接口体现的是一种规范。对于接口的实现者而言,接口规定了实现者必须向外提供哪些服务;对于接口的调用者而言,接口规定了调用者可以调用哪些服务,以及如何调用这些服务。当在一个程序中使用接口时,接口是多个模块间的耦合标准;当在多个应用程序之间使用接口时,接口是多个程序之间的通信标准。
- 抽象类体现的是一种模板式设计。抽象类作为多个子类的抽象父类,可以被当成系统实现过程中的中间产品,这个中间产品已经实现了系统的部分功能,但这个产品依然不能当成最终产品,必须有更进一步的完善,这种完善可能有几种不同方式。
从使用方式上来说,二者有如下的区别:
- 接口里只能包含抽象方法、静态方法、默认方法和私有方法,不能为普通方法提供方法实现;抽象类则完全可以包含普通方法。
- 接口里只能定义静态常量,不能定义普通成员变量;抽象类里则既可以定义普通成员变量,也可以定义静态常量。
- 接口里不包含构造器;抽象类里可以包含构造器,抽象类里的构造器并不是用于创建对象,而是让其子类调用这些构造器来完成属于抽象类的初始化操作。
- 接口里不能包含初始化块;但抽象类则完全可以包含初始化块。
- 一个类最多只能有一个直接父类,包括抽象类;但一个类可以直接实现多个接口,通过实现多个接口可以弥补Java单继承的不足。
(共同点)接口和抽象类很像,它们都具有如下共同的特征:
- 接口和抽象类都不能被实例化,它们都位于继承树的顶端,用于被其他类实现和继承。
- 接口和抽象类都可以包含抽象方法,实现接口或继承抽象类的普通子类都必须实现这些抽象方法。
如何处理异常
在Java中,可以按照如下三个步骤处理异常:
- 捕获异常
- 将业务代码包裹在try块内部,当业务代码中发生任何异常时,系统都会为此异常创建一个异常对象。创建异常对象之后,JVM会在try块之后寻找可以处理它的catch块,并将异常对象交给这个catch块处理。
- 处理异常
- 在catch块中处理异常时,应该先记录日志,便于以后追溯这个异常。然后根据异常的类型、结合当前的业务情况,进行相应的处理。比如,给变量赋予一个默认值、直接返回空值、向外抛出一个新的业务异常交给调用者处理,等等。
- 回收资源
- 如果业务代码打开了某个资源,比如数据库连接、网络连接等,则需要在这段业务代码执行完毕后关闭这项资源。并且,无论是否发生异常,都要尝试关闭这项资源。将关闭资源的代码写在finally块内,可以满足这种需求,即无论是否发生异常,finally块内的代码总会被执行
说一说Java的异常机制
- 关于异常处理:
- 在Java中,处理异常的语句由try、catch、finally三部分组成。其中,try块用于包裹业务代码,**catch块用于捕获并处理某个类型的异常,finally块则用于回收资源。**当业务代码发生异常时,系统会创建一个异常对象,然后由JVM寻找可以处理这个异常的catch块,并将异常对象交给这个catch块处理。若业务代码打开了某项资源,则可以在finally块中关闭这项资源,因为无论是否发生异常,finally块一定会执行。
- 关于抛出异常:
- **当程序出现错误时,系统会自动抛出异常。**除此以外,Java也允许程序主动抛出异常。当业务代码中,判断某项错误的条件成立时,可以使用throw关键字向外抛出异常。在这种情况下,如果当前方法不知道该如何处理这个异常,可以在方法签名上通过throws关键字声明抛出异常,则该异常将交给JVM处理。
- 关于异常跟踪栈:
- 程序运行时,经常会发生一系列方法调用,从而形成方法调用栈。异常机制会导致异常在这些方法之间传播,而异常传播的顺序与方法的调用相反。异常从发生异常的方法向外传播,首先传给该方法的调用者,再传给上层调用者,以此类推。最终会传到main方法,若依然没有得到处理,则JVM会终止程序,并打印异常跟踪栈的信息
请介绍Java的异常接口
Throwable是异常的顶层父类,代表所有的非正常情况。它有两个直接子类,分别是Error、Exception。
- Error是错误,一般是指与虚拟机相关的问题,如系统崩溃、虚拟机错误、动态链接失败等,这种错误无法恢复或不可能捕获,将导致应用程序中断。通常应用程序无法处理这些错误,因此应用程序不应该试图使用catch块来捕获Error对象。在定义方法时,也无须在其throws子句中声明该方法可能抛出Error及其任何子类。
- Exception是异常,它被分为两大类,分别是Checked异常和Runtime异常。所有的RuntimeException类及其子类的实例被称为Runtime异常;不是RuntimeException类及其子类的异常实例则被称为Checked异常。Java认为Checked异常都是可以被处理(修复)的异常,所以Java程序必须显式处理Checked异常。如果程序没有处理Checked异常,该程序在编译时就会发生错误,无法通过编译。Runtime异常则更加灵活,Runtime异常无须显式声明抛出,如果程序需要捕获Runtime异常,也可以使用try…catch块来实现。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fzYmMKzb-1666488157631)(v2-ec78fb9835b93c102aa113208173486c_720w.jpg)]
编译时异常与运行时异常的区别?
- 运行时异常:都是
RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。 - 非运行时异常 (编译异常):是
RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
Throwable 类常用方法有哪些?
String getMessage()// 返回异常发生时的简要描述
String toString()// 返回异常发生时的详细信息
String getLocalizedMessage()// 返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同
void printStackTrace()// 在控制台上打印 Throwable 对象封装的异常信息
finally是无条件执行的吗?
不管try块中的代码是否出现异常,也不管哪一个catch块被执行,甚至在try块或catch块中执行了return语句,finally块总会被执行。
try catch finally 用法
正常情况下,先执行try里面的代码,捕获到异常后执行catch中的代码,最后执行finally中代码,但当在try catch中执行到return时,要判断finally中的代码是否执行,如果没有,应先执行finally中代码再返回。
为什么要用static关键字?
通常来说,用new创建类的对象时,数据存储空间才被分配,方法才供外界调用。但**有时我们只想为特定域分配单一存储空间,不考虑要创建多少对象或者说根本就不创建任何对象,再就是我们想在没有创建对象的情况下也想调用方法。**在这两种情况下,static关键字,满足了我们的需求。
说一说你对static关键字的理解
在Java类里只能包含成员变量、方法、构造器、初始化块、内部类(包括接口、枚举)5种成员,而static可以修饰成员变量、方法、初始化块、内部类(包括接口、枚举),以static修饰的成员就是类成员。类成员属于整个类,而不属于单个对象。
- static是静态的意思,可以用来修饰成员变量、成员方法。
- static修饰成员变量之后称为静态成员变量(类变量),修饰方法之后称为静态方法(类方法)。
- static修饰后的成员变量,可以被类的所有对象共享(访问、修改)。
static能修饰abstract类/方法吗?
因为抽象类是不能被实例化的,即不能分配内存。而static修饰的方法,在实例化之前就已经分配了内存,所以抽象类中不能有静态的抽象方法。
静态代码块的作用是什么?
如果要在启动系统时对静态资源进行初始化,则建议使用静态代码块完成数据的初始化操作。
"static"关键字是什么意思?Java中是否可以覆盖(override)一个private或者是static的方法?
"static"关键字表明一个成员变量或者是成员方法可以在没有所属的类的实例变量的情况下被访问。Java中static方法不能被覆盖,因为**方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。**static方法跟类的任何实例都不相关,所以概念上不适用。
static修饰的类能不能被继承?
static修饰的类可以被继承。
如果使用static来修饰一个内部类,则这个内部类就属于外部类本身,而不属于外部类的某个对象。因此使用static修饰的内部类被称为类内部类,有的地方也称为静态内部类。
外部类的上一级程序单元是包,所以不可使用static修饰;而内部类的上一级程序单元是外部类,使用static修饰可以将内部类变成外部类相关,而不是外部类实例相关。因此static关键字不可修饰外部类,但可修饰内部类。
静态内部类需满足如下规则:
- 静态内部类可以包含静态成员,也可以包含非静态成员;
- 静态内部类不能访问外部类的实例成员,只能访问它的静态成员;
- 外部类的所有方法、初始化块都能访问其内部定义的静态内部类;
- 在外部类的外部,也可以实例化静态内部类,语法如下:
外部类.内部类 变量名 = new 外部类.内部类构造方法();
static和final有什么区别?
static关键字可以修饰成员变量、成员方法、初始化块、内部类,被static修饰的成员是类的成员,它属于类、不属于单个对象。以下是static修饰这4种成员时表现出的特征:
- 类变量:被static修饰的成员变量叫类变量(静态变量)。类变量属于类,它随类的信息存储在方法区,并不随对象存储在堆中,类变量可以通过类名来访问,也可以通过对象名来访问,但建议通过类名访问它。
- **类方法:**被static修饰的成员方法叫类方法(静态方法)。类方法属于类,可以通过类名访问,也可以通过对象名访问,建议通过类名访问它。
- 静态块:被static修饰的初始化块叫静态初始化块。静态块属于类,它在类加载的时候被隐式调用一次,之后便不会被调用了。
- **静态内部类:**被static修饰的内部类叫静态内部类。静态内部类可以包含静态成员,也可以包含非静态成员。静态内部类不能访问外部类的实例成员,只能访问外部类的静态成员。外部类的所有方法、初始化块都能访问其内部定义的静态内部类。
final关键字可以修饰类、方法、变量,以下是final修饰这3种目标时表现出的特征:
- final类:final关键字修饰的类不可以被继承。
- final方法:final关键字修饰的方法不可以被重写。
- final变量:final关键字修饰的变量,一旦获得了初始值,就不可以被修改。
什么是泛型?有什么作用?
Java 泛型(Generics) 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。
编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 ArrayList 这行代码就指明了该 ArrayList 对象只能传入 Persion 对象,如果传入其他类型的对象就会报错。并且,原生 List 返回类型是 Object ,需要手动转换类型才能使用,使用泛型后编译器自动转换。
泛型中的限定通配符和非限定通配符是什么?
- 限定通配符
- 限定通配符对类型进行了限制。有两种限定通配符,**一种是它通过确保类型必须是T的子类来设定类型的上界,另一种是它通过确保类型必须是T的父类来设定类型的下界。**泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。
- 非限定通配符
- 非限定通配符?,可以用任意类型来替代。如List的意思是这个集合是一个可以持有任意类型的集合,它可以是(List,也可以是(List ,或者List等等。
说一说Java的四种引用方式
- **强引用:**这是Java程序中最常见的引用方式,即程序创建一个对象,并把这个对象赋给一个引用变量,程序通过该引用变量来操作实际的对象。当一个对象被一个或一个以上的引用变量所引用时,它处于可达状态,不可能被系统垃圾回收机制回收。
- 软引用:当一个对象只有软引用时,它有可能被垃圾回收机制回收。对于只有软引用的对象而言,当系统内存空间足够时,它不会被系统回收,程序也可使用该对象。**当系统内存空间不足时,系统可能会回收它。**软引用通常用于对内存敏感的程序中。
- **弱引用:**弱引用和软引用很像,但弱引用的引用级别更低。对于只有弱引用的对象而言,当系统垃圾回收机制运行时,不管系统内存是否足够,总会回收该对象所占用的内存。当然,并不是说当一个对象只有弱引用时,它就会立即被回收,正如那些失去引用的对象一样,必须等到系统垃圾回收机制运行时才会被回收。
- **虚引用:**虚引用完全类似于没有引用。虚引用对对象本身没有太大影响,对象甚至感觉不到虚引用的存在。如果一个对象只有一个虚引用时,那么它和没有引用的效果大致相同。虚引用主要用于跟踪对象被垃圾回收的状态,虚引用不能单独使用,虚引用必须和引用队列联合使用。
说一说你对Java反射机制的理解?
反射的概念:
- 在 Java 中的反射机制是指 在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法; **并且对于任意一个对象,都能够调用它的任意一个方法;**这种动态获取信息以及动态调用对象方法的功能成为 Java 语言的反射机制。
编译时根本无法预知该对象和类可能属于哪些类,程序只依靠运行时信息来发现该对象和类的真实信息,这就必须使用反射。获取 Class 对象的 3 种方法 / 获取反射的3种方法
- 通过new对象实现反射机制,调用某个对象的 getClass()方法;
Person p = new Person();
Class clazz = p.getClass();
- 通过类名实现反射机制,调用某个类的 class 属性来获取该类对应的 Class 对象;
Class clazz = Person.class();
- 通过相对路径实现反射机制,使用 Class 类中的 forName()静态方法(最安全/性能最好)(最常用)。
Class clazz = Class.forName("类的全路径");
反射的优缺点
- 优点: 运行期类型的判断,动态加载类,提高代码灵活度。
- 缺点: 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
Java反射在实际项目中有哪些应用场景?
- 使用JDBC时,如果要创建数据库的连接,则需要先通过反射机制加载数据库的驱动程序;
- 多数框架都支持注解/XML配置(IOC控制反转),从配置中解析出来的类是字符串,需要利用反射机制实例化;
- 面向切面编程(AOP)的实现方案,是在程序运行时创建目标对象的代理类,这必须由反射机制来实现。
——————Java中有哪些容器(集合类)?
Java中的集合类主要由Collection和Map这两个接口派生而出.
其中Collection接口又派生出三个子接口,分别是Set、List。
List:代表有序的,元素可以重复的集合
- **ArrayList:**底层用Object数组实现,特点是查询效率高,增删效率低,线程不安全
- **LinkedList:**底层使用双向循环链表实现,特点是查询效率低,增删效率高,线程不安全,因为线程不同步
- **Vector:**底层用长度可以动态增长的对象数组实现,它的相关方法用 Synchronized 进行了线程同步,所以线程安全,效率低
- **Stack:**栈。特点是:先进后出。继承于Vector
Set:代表无序的,元素不可重复的集合
- HashSet:底层用HashMap实现,本质是一个简化版的HashMap,因此查询效率和增删效率都比较高。其add方法就是在map中增加一个键值对,键对象就是这个元素,值对象是PRESENT的对象
- LinkedHashSet: 继承自HashSet,内部使用的是LinkHashMap。这样做的意义或者好处就是LinkedHashSet中的元素顺序是可以保证的,也就是说遍历序和插入序是一致的。
- TreeSet: 底层用TreeMap实现,底层是一种二叉查找树(红黑树),需要对元素做内部排序。内部维持了一个简化版的TreeMap,并通过key来存储Set元素。使用时,要对放入的类实现Comparable接口,且不能放入null
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mWQPDI42-1666488157631)(image-20220911150444891.png)]
Map接口有很多实现类,其中比较常用的有HashMap、LinkedHashMap、HashTable、TreeMap、ConcurrentHashMap。
- HashMap:采用散列算法来实现,底层用哈希表来存储数据,因此要求键不能重复。线程不安全,HashMap在查找、删除、修改方面效率都非常高。允许key或value为null
- **LinkedHashMap:HashMap和双向链表合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表的HashMap。虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。**特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
- HashTable:与HashMap类似,只是其中的方法添加了synchronized关键字以确保线程同步检查,线程安全,但效率较低。 不允许key或value为null。
- TreeMap: 红黑树的典型实现。TreeMap和HashMap实现了同样的接口Map。在需要Map中Key按照自然排序时才选用TreeMap
- ConcurrentHashMap:HashMap不支持并发操作,没有同步方法,ConcurrentHashMap支持并发操作
- 通过继承 ReentrantLock(JDK1.7重入锁)/CAS和synchronized(JDK1.8内置锁)来进行加锁(分段锁),每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。JDK1.8之前HashMap的结构为数组+链表,JDK1.8之后HashMap的结构为数组+链表+红黑树;JDK1.8之前ConcurrentHashMap的结构为segment数组+数组+链表,JDK1.8之后ConcurrentHashMap的结构为数组+链表+红黑树。
- 如果需要保证线程安全,则可以使用ConcurrentHashMap。它的性能好于Hashtable,因为它在put时采用分段锁/CAS的加锁机制,而不是像Hashtable那样,无论是put还是get都做同步处理。
Collection和Collections的区别?
-
Collection是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的的子类,比如List,Set等
-
Collections是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法,Collections.sort(list)
Array和ArrayList有什么区别?
- Array可以存储基本数据类型和对象,而ArrayList只能存储对象
- Array是指定固定大小的,而ArrayList大小是自动扩展的
- Array内置方法比ArrayList多,比如addAll,removeAll,iteration等方法
ArrayList 迭代的方式
使用Iterator最快(it.hasNext()),转化为数组进行迭代(toArray)次之,forEach最慢。
ArrayList和LinkedList的区别?
- **数据结构实现:**ArrayList是动态数组的数据结构实现,而LinkedList是双向链表的数据结构实现
- **随机访问效率:**ArrayList在随机访问时的效率要比Linkedlist高,因为LinkedList是线性的数据存储方式,因此访问时需要从前往后的依此查找
- **增加和删除效率:**在非首尾的增加和删除操作,LinkedList要比ArrayList效率高,因为ArrayList的增删操作会影响数组中其他数据的下标
综上来说,在需要频繁读取集合中的数据时,更推荐使用ArrayList,而在插入和删除操作较多时,更推荐LinkedList
ArrayList和Vector的区别?
- **线程安全:**Vector使用了Synchronized来实现线程同步,是线程安全的,而ArrayList是线程不安全的
- **性能:**ArrayList在性能方面要强于Vector
- **扩容:**ArrayList和Vector都会根据实际的需求动态的调整容量。只不过Vector每次扩容会增加1倍,而ArrayList每次只会增加50%
如何实现数组和List之间的转换?
- 数组转List:使用Arrays.asList(array)进行转换
- List转数组:使用List自带的toArray( )方法
HashMap和HashTable的区别?
- **存储:**HashMap允许key和value为null,HashTable不允许
- **线程安全:**HashMap线程不安全,HashTable安全
- 推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
说一下HashSet的实现原理?
HashSet 是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
说一下HashMap的实现原理?
HashMap是线程不安全的实现;HashMap可以使用null作为key或value。
- **回答1:**它基于hash算法,通过put方法和get方法存储和获取对象。存储对象时,我们将K/V传给put方法时,它调用K的hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,HashMap通过链表将产生碰撞冲突的元素组织起来。在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
- **回答2:**HashMap是基于Hash算法实现的,我们通过put(key,value)存储,get(key)来获取。当传入key值时,HashMap通过 key. hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。当 hash 冲突的个数比较少时,使用链表,(默认超过8个元素)否则使用红黑树。
描述一下Map put的过程?
首次扩容:
- 先判断数组是否为空,若数组为空则进行第一次扩容(resize);
计算索引:
- 通过hash算法,计算键值对在数组中的索引;
插入数据:
- 如果当前位置元素为空,则直接插入数据;
- 如果当前位置元素非空,且key已存在,则直接覆盖其value;
- 如果当前位置元素非空,且key不存在,则将数据链到链表末端;
- 若链表长度达到8,则将链表转换成红黑树,并将数据插入树中;
再次扩容:
- 如果数组中元素个数(size)超过threshold,则再次进行扩容操作。
介绍一下HashMap的扩容机制?
- 数组的初始容量为16,而容量是以2的次方扩充的,一是为了提高性能使用足够大的数组,二是为了能使用位运算代替取模预算(据说提升了5~8倍)。
- 数组是否需要扩充是通过负载因子判断的,如果当前元素个数为数组容量的0.75时,就会扩充数组。这个0.75就是默认的负载因子,可由构造器传入。我们也可以设置大于1的负载因子,这样数组就不会扩充,牺牲性能,节省内存。
- 为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时(7或8),会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时(6),又会将红黑树转换回单向链表提高性能。
- 对于第三点补充说明,检查链表长度转换成红黑树之前,还会先检测当前数组数组是否到达一个阈值(64),如果没有到达这个容量,会放弃转换,先去扩充数组。所以上面也说了链表长度的阈值是7或8,因为会有一次放弃转换的操作。
HashMap为什么用红黑树而不用B树?
B/B+树多用于外存上时,B/B+也被成为一个磁盘友好的数据结构。
HashMap本来是数组+链表的形式,链表由于其查找慢的特点,所以需要被查找效率更高的树结构来替换。如果用B/B+树的话,在数据量不是很多的情况下,数据都会“挤在”一个结点里面,这个时候遍历效率就退化成了链表。
HashMap为什么线程不安全?
HashMap在并发执行put操作时,可能会导致形成循环链表,从而引起死循环。
HashMap如何实现线程安全?
- 直接使用Hashtable类;
- 直接使用ConcurrentHashMap;
- 使用Collections将HashMap包装成线程安全的Map。
HashMap是如何解决哈希冲突的?
为了解决碰撞,数组中的元素是单向链表类型。当链表长度到达一个阈值时,会将链表转换成红黑树提高性能。而当链表长度缩小到另一个阈值时,又会将红黑树转换回单向链表提高性能。
说一说HashMap和HashTable的区别?
- Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable的性能高一点。
- Hashtable不允许使用null作为key和value,如果试图把null值放进Hashtable中,将会引发空指针异常,但HashMap可以使用null作为key或value。
HashMap与ConcurrentHashMap有什么区别?
- HashMap不支持并发操作,没有同步方法,ConcurrentHashMap支持并发操作,通过继承 ReentrantLock(JDK1.7重入锁)/CAS和synchronized(JDK1.8内置锁)来进行加锁(分段锁),每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
- JDK1.8之前HashMap的结构为数组+链表,JDK1.8之后HashMap的结构为数组+链表+红黑树。JDK1.8之前ConcurrentHashMap的结构为segment数组+数组+链表,JDK1.8之。ConcurrentHashMap的结构为数组+链表+红黑树。
HashMap是非线程安全的,这意味着不应该在多线程中对这些Map进行修改操作,否则会产生数据不一致的问题,甚至还会因为并发插入元素而导致链表成环,这样在查找时就会发生死循环,影响到整个应用程序。
Collections工具类可以将一个Map转换成线程安全的实现,其实也就是通过一个包装类,然后把所有功能都委托给传入的Map,而包装类是基于synchronized关键字来保证线程安全的(Hashtable也是基于synchronized关键字),底层使用的是互斥锁,性能与吞吐量比较低。
ConcurrentHashMap的实现细节远没有这么简单,因此性能也要高上许多。它没有使用一个全局锁来锁住自己,而是采用了减少锁粒度的方法,尽量减少因为竞争锁而导致的阻塞与冲突,而且ConcurrentHashMap的检索操作是不需要锁的。
介绍一下ConcurrentHashMap是怎么实现的?
- **在 jdk 1.7 中,**ConcurrentHashMap 是由 Segment 数据结构和 HashEntry 数组结构构成,采取分段锁来保证安全性。Segment 是 ReentrantLock 重入锁,在 ConcurrentHashMap 中扮演锁的角色,HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,Segment 的结构是一个数组和链表结构。
- JDK1.8 的实现已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 Synchronized 和 CAS 来操作,整个看起来就像是优化过且线程安全的 HashMap。
说一说你对LinkedHashMap的理解?
LinkedHashMap使用双向链表来维护key-value对的顺序(其实只需要考虑key的顺序),该链表负责维护Map的迭代顺序,迭代顺序与key-value对的插入顺序保持一致。
LinkedHashMap可以避免对HashMap、Hashtable里的key-value对进行排序(只要插入key-value对时保持顺序即可),同时又可避免使用TreeMap所增加的成本。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能。但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。
请介绍TreeMap的底层原理?
**TreeMap基于红黑树(Red-Black tree)实现。**映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作containsKey、get、put、remove方法,它的时间复杂度是log(N)。
TreeMap包含几个重要的成员变量:root、size、comparator。其中root是红黑树的根节点。它是Entry类型,Entry是红黑树的节点,它包含了红黑树的6个基本组成:key、value、left、right、parent和color。Entry节点根据根据Key排序,包含的内容是value。Entry中key比较大小是根据比较器comparator来进行判断的。size是红黑树的节点个数。
说一说TreeSet和HashSet的区别?
- HashSet、TreeSet中的元素都是不能重复的,并且它们都是线程不安全的,二者的区别是:
- HashSet中的元素可以是null,但TreeSet中的元素不能是null;
- HashSet不能保证元素的排列顺序,而TreeSet支持自然排序、定制排序两种排序的方式;
- HashSet底层是采用哈希表实现的,而TreeSet底层是采用红黑树实现的。
HashMap与HashTable 区别
- 默认容量不同,扩容不同。
- 线程安全性,HashTable 安全。
- 效率不同 HashTable 要慢因为加锁。
说一说HashSet的底层结构?
HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。它封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。
comparable 和 Comparator 的区别?
- comparable接口实际上是出自java.lang包它有一个compareTo(Object obj)方法用来排序
- comparator接口实际上是出自java.util包它有一个compare(0bject obj1,object obj2)方法用来排序
java8新特性有哪些?
java8新特性有:1、Lambda表达式;2、方法引用;3、默认方法;4、新编译工具;5、Stream API;6、Date Time API;7、Option;8、Nashorn javascript引擎。
原文链接:https://www.php.cn/java/guide/461886.html
throw 和 throws 有什么区别
位置不同。throws用在函数上,后边跟的是异常类,可以跟多个异常类。throw用在函数内,后面跟的是异常对象。
功能不同。①throws用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先得处理方式。throw抛出具体的问题对象,执行到throw。功能就已经结束了跳转到调用者,并将具体的问题对象抛给调用者,也就是说throw语句独立存在时,下面不要定义其他语句,因为执行不到。②throws表示出现异常的一种可能性,并不一定会发生这些异常,throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
Java虚拟机JVM
说出类加载的过程?
Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
系统加载 Class 类型的文件主要三步:加载->连接->初始化。连接过程又可分为三步:验证->准备->解析。
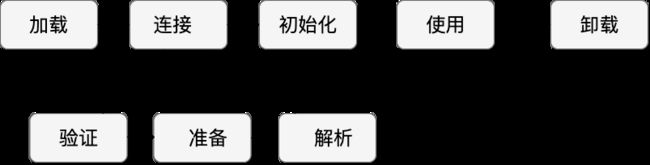
加载,主要完成下面 3 件事情:
-
通过全类名获取定义此类的二进制字节流
-
将字节流所代表的静态存储结构转换为方法区的运行时数据结构
-
在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
验证:确保加载的类符合 JVM 规范和安全,保证被校验类的方法在运行时不会做出危害虚拟机的事件。
准备:为static变量在方法区中分配内存空间,设置变量的初始值。准备阶段只设置类中的静态变量(方法区中),不包括实例变量(堆内存中),实例变量是对象初始化时赋值的。
解析:虚拟机将常量池内的符号引用替换为直接引用的过程(符号引用比如我现在import java.util.ArrayList这就算符号引用,直接引用就是指针或者对象地址,注意引用对象一定是在内存进行)。
初始化:初始化阶段是执行初始化方法 < c l i n i t > ()方法的过程,是类加载的最后一步,这一步 JVM 才开始真正执行类中定义的 Java 程序代码(字节码)。
卸载:GC将无用对象从内存中卸载。
说出一个对象实例化的过程(如何创建一个对象)?

- **类加载检查:**虚拟机遇到⼀条 new 指令时,⾸先将去检查这个指令的参数是否能在常量池中定位到这个类的 符号引⽤,并且检查这个符号引⽤代表的类是否已被加载过、解析和初始化过。如果没有,那必 须先执⾏相应的类加载过程。
- 分配内存:在类加载检查通过后,接下来虚拟机将为新⽣对象分配内存。对象所需的内存⼤⼩在类加载完成后便可确定,为对象分配空间的任务等同于把⼀块确定⼤⼩的内存从 Java 堆中划分出来。分配*⽅式有 “指针碰撞” 和 “空闲列表”两种,选择哪种分配⽅式由 Java 堆是否规整决定,⽽ Java堆是否规整⼜由所采⽤的垃圾收集器是否带有压缩整理功能决定。
- **初始化零值:**内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),这⼀步操作保证了对象的实例字段在 Java 代码中可以不赋初始值就直接使⽤,程序能访问到这些字段的数据类型所对应的零值。
- **设置对象头:**初始化零值完成之后,虚拟机要对对象进⾏必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中。
- **执行init方法:**在上⾯⼯作都完成之后,从虚拟机的视⻆来看,⼀个新的对象已经产⽣了,但从 Java 程序的视⻆来看,对象创建才刚开始, ⽅法还没有执⾏,所有的字段都还为零。所以⼀般来说,执⾏ new 指令之后会接着执⾏ ⽅法,把对象按照程序员的意愿进⾏初始化,这样⼀个真正可⽤的对象才算完全产⽣出来。
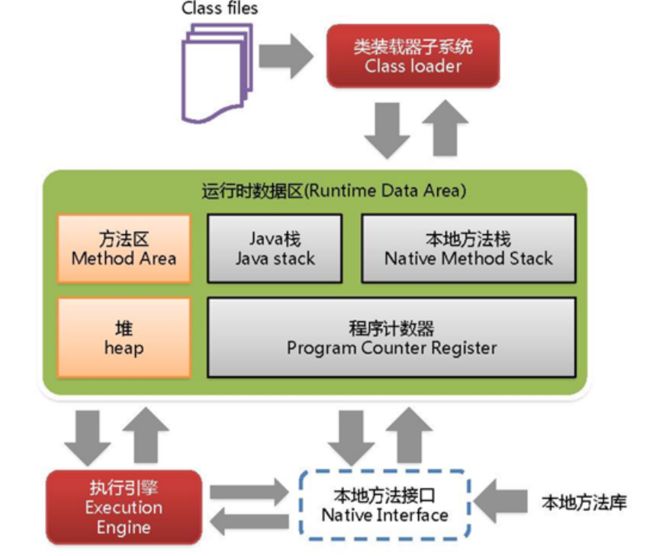
JVM包含哪几部分?
JVM 主要由四大部分组成:ClassLoader(类加载器),Runtime Data Area(运行时数据区,内存分区),Execution Engine(执行引擎),Native Interface(本地库接口),下图可以大致描述 JVM 的结构。
- ClassLoader:负责加载字节码文件即 class 文件,class 文件在文件开头有特定的文件标示,并且 ClassLoader 只负责class 文件的加载,至于它是否可以运行,则由 Execution Engine 决定。
- Runtime Data Area:是存放数据的,分为五部分:**Stack(虚拟机栈),Heap(堆),Method Area(方法区),PC Register(程序计数器),Native Method Stack(本地方法栈)。**几乎所有的关于 Java 内存方面的问题,都是集中在这块。
- Execution Engine:执行引擎,也叫 Interpreter。Class 文件被加载后,会把指令和数据信息放入内存中,Execution Engine 则负责把这些命令解释给操作系统,即将 JVM 指令集翻译为操作系统指令集。
- Native Interface:负责调用本地接口的。他的作用是调用不同语言的接口给 JAVA 用,他会在 Native Method Stack 中记录对应的本地方法,然后调用该方法时就通过 Execution Engine 加载对应的本地 lib。原本多用于一些专业领域,如JAVA驱动,地图制作引擎等,现在关于这种本地方法接口的调用已经被类似于Socket通信,WebService等方式取代。
JVM的内存模型和分区,详细到每个区放什么?
jvm将虚拟机分为5大区域,程序计数器、虚拟机栈、本地方法栈、java堆、方法区;
**线程私有的:**程序计数器,虚拟机栈,本地方法栈
**线程共享的:**堆,方法区,直接内存 (非运行时数据区的一部分)
- 程序计数器:线程私有的,是一块很小的内存空间,作为当前线程的行号指示器,用于记录当前虚拟机正在执行的线程指令地址;字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理;在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
- **虚拟机栈:**线程私有的,每个方法执行的时候都会创建一个栈帧,用于存储局部变量表、操作数、动态链接和方法返回等信息,当线程请求的栈深度超过了虚拟机允许的最大深度时,就会抛出StackOverFlowError;**它的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡。**方法调用的数据需要通过栈进行传递,每一次方法调用都会有一个对应的栈帧被压入栈中,每一个方法调用结束后,都会有一个栈帧被弹出。
- 本地方法栈:线程私有的,保存的是native方法的信息,当一个jvm创建的线程调用native方法后,jvm不会在虚拟机栈中为该线程创建栈帧,而是简单的动态链接并直接调用该方法;本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种错误。
- 堆: java堆是所有线程共享的一块内存,几乎所有对象的实例和数组都要在堆上分配内存,因此该区域经常发生垃圾回收的操作;
- **方法区:**存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码数据。即永久代,在jdk1.8中不存在方法区了,被元数据区替代了,原方法区被分成两部分;1:加载的类信息,2:运行时常量池;加载的类信息被保存在元数据区中,运行时常量池保存在堆中;方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
- 运行时常量池:Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)的 常量池表(Constant Pool Table) 。常量池表会在类加载后存放到方法区的运行时常量池中。
- 字符串常量池:字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
说说双亲委派机制?
双亲委派机制:是为了保证安全
类加载顺序:自定义类加载器 ---->APP(应用程序加载器)----> EXC(扩展类加载器)----->BOOT(启动类(根)加载器)(最终执行)
双亲委派机制流程:
- 类加载器收到类加载请求;
- 将这个请求向上委托给父类加载器去完成,一直向上请求,直到启动类(根)加载器;
- 启动类加载器检查是否能够加载当前这个类,如果能加载就结束,使用当前的加载器,否则抛出异常(Class Not Found),通知子加载器进行加载;
- 重复步骤③
为什么自己写的java.lang.String不能代替jdk的被使用
由于双亲委派模式优势:
-
沙箱安全机制:自己写的String.class类不会被加载,这样便可以防止核心API库被随意篡改
-
避免类的重复加载:当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次
沙箱安全机制(问的不多)?
Java安全模型的核心就是Java沙箱(sandbox),**什么是沙箱?沙箱是一个限制程序运行的环境
沙箱机制就是将Java代码限定在虚拟机(JVM)特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。**沙箱主要限制系统资源访问,那系统资源包括什么?CPU、内存、文件系统、网络。不同级别的沙箱对这些资源访问的限制也可以不一样。
什么是OOM?什么是栈溢出Stack OverFlowError?
- StackOverFlowError: 若栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。
- OutOfMemoryError: 如果栈的内存大小可以动态扩展, 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。
①OutOfMemoryError:
除了程序计数器,其他内存区域都有OOM的风险。
- Java堆溢出。Java堆用于储存对象实例,我们只要不断地创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么随着对象数量的增加,总容量触及最大堆的容量限制后就会产生内存溢出异常。
- **虚拟机栈和本地方法栈溢出。**HotSpot虚拟机中并不区分虚拟机栈和本地方法栈,如果虚拟机的栈内存允许动态扩展,当扩展栈容量无法申请到足够的内存时,将抛出OutOfMemoryError异常。
- 方法区和运行时常量池溢出。 **方法区溢出也是一种常见的内存溢出异常,在经常运行时生成大量动态类的应用场景里,就应该特别关注这些类的回收状况。**这类场景常见的包括:程序使用了CGLib字节码增强和动态语言、大量JSP或动态产生JSP文件的应用(JSP第一次运行时需要编译为Java类)、基于OSGi的应用(即使是同一个类文件,被不同的加载器加载也会视为不同的类)等。
- **本地直接内存溢出。**直接内存(Direct Memory)的容量大小可通过-XX:MaxDirectMemorySize参数来指定,如果不去指定,则默认与Java堆最大值(由-Xmx指定)一致。如果直接通过反射获取Unsafe实例进行内存分配,并超出了上述的限制时,将会引发OOM异常
②StackOverFlowError栈溢出:
- 栈是线程私有的,栈的生命周期和线程一样,每个方法在执行的时候就会创建一个栈帧,它包含局部变量表、操作数栈、动态链接、方法出口等信息,局部变量表又包括基本数据类型和对象的引用;
- 当线程请求的栈深度超过了虚拟机允许的最大深度时,会抛出StackOverFlowError异常,方法递归调用肯可能会出现该问题;
- 调整参数-xss去调整jvm栈的大小
内存泄漏和内存溢出有什么区别?
- 内存泄漏(memory leak):内存泄漏指程序运行过程中分配内存给临时变量,用完之后却没有被GC回收,始终占用着内存,既不能被使用也不能分配给其他程序,于是就发生了内存泄漏。
- 内存溢出(out of memory):简单地说内存溢出就是指程序运行过程中申请的内存大于系统能够提供的内存,导致无法申请到足够的内存,于是就发生了内存溢出。
什么是内存泄漏,怎么解决?
内存泄漏的根本原因是长生命周期的对象持有短生命周期对象的引用,尽管短生命周期的对象已经不再需要,但由于长生命周期对象持有它的引用而导致不能被回收。以发生的方式来分类,内存泄漏可以分为4类:
- **常发性内存泄漏。**发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
- 偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
- 一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。
- **隐式内存泄漏。****程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。**严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
避免内存泄漏的几点建议:
- 尽早释放无用对象的引用。
- 避免在循环中创建对象。
- 使用字符串处理时避免使用String,应使用StringBuffer。
- 尽量少使用静态变量,因为静态变量存放在永久代,基本不参与垃圾回收。
什么是内存溢出,怎么解决?
内存溢出(out of memory):简单地说**内存溢出就是指程序运行过程中申请的内存大于系统能够提供的内存,导致无法申请到足够的内存,**于是就发生了内存溢出。引起内存溢出的原因有很多种,常见的有以下几种:
- 内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
- 集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
- 代码中存在死循环或循环产生过多重复的对象实体;
- 使用的第三方软件中的BUG;
- 启动参数内存值设定的过小。
内存溢出的解决方案:
- 第一步,修改JVM启动参数,直接增加内存。
- 第二步,检查错误日志,查看“OutOfMemory”错误前是否有其它异常或错误。
- 第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
- 第四步,使用内存查看工具动态查看内存使用情况。
JVM的调优参数有哪些?
- jps: JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
- jstat: jstat(VM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
- jmap: jmap(JVM Memory Map)命令用于生成heap dump文件,如果不使用这个命令,还阔以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候自动生成dump文件。jmap不仅能生成dump文件,还阔以查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
- jhat: jhat(VM Heap Analysis Tool)命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。在此要注意,一般不会直接在服务器上进行分析,因为jhat是一个耗时并且耗费硬件资源的过程,一般把服务器生成的dump文件复制到本地或其他机器上进行分析。
- jstack: jstack用于生成java虚拟机当前时刻的线程快照。jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。
内存快照如何抓取?怎么分析Dump文件?
专业工具:内存快照分析工具:Jpro
- 分析Dump内存文件,快速定位内存泄露;
-Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
//-Xms 设置初始化内存分配大小,默认为电脑内存1/64
//-Xmx 设置最大分配内存,默认为电脑内存1/4
//-XX:PringGCDetails 打印GC垃圾回收信息
//-XX:+HeapDumpOnOutOfMemoryError 打印OOM信息
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFfkgwHY-1666488157632)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
谈谈你对JVM中的类加载器的认识?
所有的类都由类加载器加载,加载的作用就是将 .class文件加载到内存。
JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他类加载器均由 Java 实现且全部继承自java.lang.ClassLoader:
- BootstrapClassLoader(启动类加载器) :最顶层的加载类,由 C++实现,负责加载 %JAVA_HOME%/lib目录下的 jar 包和类或者被 -Xbootclasspath参数指定的路径中的所有类。
- ExtensionClassLoader(扩展类加载器) :主要负责加载 %JRE_HOME%/lib/ext 目录下的 jar 包和类,或被 java.ext.dirs 系统变量所指定的路径下的 jar 包。
- ppClassLoader(应用程序类加载器) :面向我们用户的加载器,负责加载当前应用 classpath 下的所有 jar 包和类。
- 自定义类加载器:
定义一个类,继承ClassLoader
重写loadClass方法
实例化class对象
堆里面的分区有哪些,说下他们特点?
堆里面分为新生代和老生代(java8取消了永久代,采用了Metaspace**(元空间)**),新生代包Eden+Survivor区,survivor区里面分为from和to区,内存回收时,如果用的是复制算法,从from复制到to,当经过一次或者多次GC之后,存活下来的对象会被移动到老年区,当JVM内存不够用的时候,会触发Full GC,清理JVM老年区。当新生区满了之后会触发YGC,先把存活的对象放到其中一个Survice区,然后进行垃圾清理。因为如果仅仅清理需要删除的对象,这样会导致内存碎片,因此一般会把Eden 进行完全的清理,然后整理内存。那么下次GC 的时候,就会使用下一个Survive,这样循环使用。如果有特别大的对象,新生代放不下,就会使用老年代的担保,直接放到老年代里面。因为JVM 认为,一般大对象的存活时间一般比较久远。
如何确定对象是可回收的?
引用计数算法:
在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。
可达性分析算法:
当前主流的商用程序语言的内存管理子系统,都是通过可达性分析(Reachability Analysis)算法来判定对象是否存活的。这个算法的基本思路就是通过一系列称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(Reference Chain),如果某个对象到GC Roots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
GC算法有哪些(垃圾回收机制)?
标记清除,标记整理(压缩),复制算法,引用计数
引用计数法
给每个对象分配一个计数器,用一次加一次,清理计数为 0 的对象,下图中 C 就会被干掉~

复制算法
- 首先将伊甸园GC一次,将活着的对象放到幸存区;
- 每次进行GC的时候L将幸存区 from 的对象复制到幸存区 to ,可以理解为:谁空谁是to;(每一次垃圾回收之后Eden和一个幸存区 to 区 都是空的)
- GC过程中,然后两个幸存区的对象调换,每次保证一个幸存区为空,在一个对象经历(默认)15 (也可以自行设定次数)次之后,如果对象还活着,将进入老年区;
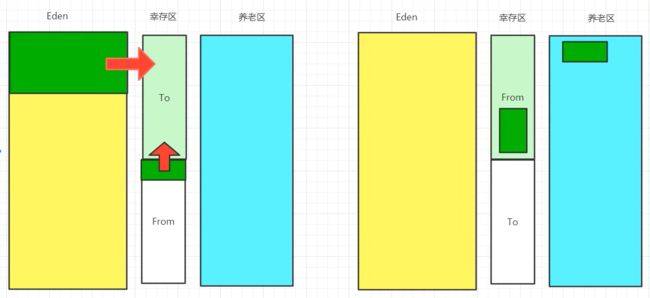
- 好处:没有内存碎片;
- 坏处:浪费了内存空间~ 因为一直会有一半空间是空的,对象存活度较低的时候比较适合。
标记清除算法
扫描整个对象空间并对存活的对象标记,然后清除没有标记的对象。
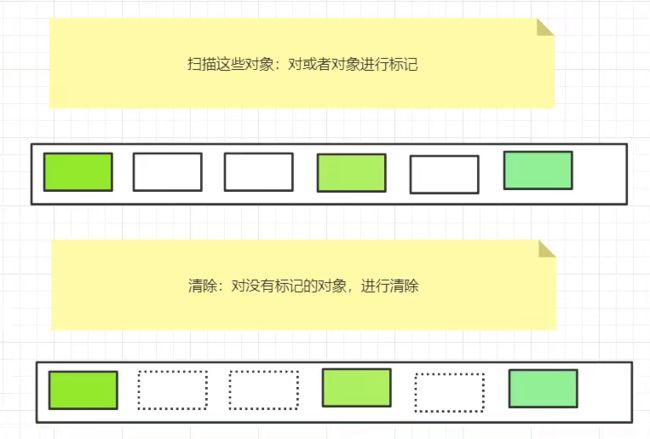
- 优点:不需要额外的空间;
- 缺点:两次扫描浪费时间,会产生内存碎片。
标记压缩算法
是标记清除的再优化!
压缩:通过再次扫描,减少内存碎片,将空的坑位平移。
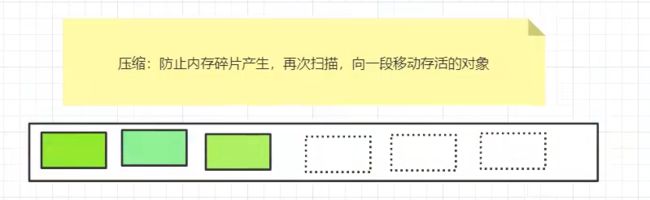
最后两种算法可以合并为一种算法——标记-清除-压缩算法
但是扫描时间长的缺点还是没有克服!

- 内存效率:复制 > 标记清除 > 标记压缩(时间复杂度)
- 内存整齐度:复制 = 标记压缩 > 标记清除
- 内存利用率: 标记压缩 = 标记清除 > 复制
分代收集算法(为什么新生代和老年代要采用不同的回收算法?)
比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
为什么老年代不能使用标记复制?
因为老年代保留的对象都是难以消亡的,而标记复制算法在对象存活率较高时就要进行较多的复制操作,效率将会降低,所以在老年代一般不能直接选用这种算法。
轻GC和重GC分别在什么时候发生?
新生成的对象首先放到年轻代Eden区,当 Eden空间满了,触发轻 GC,存活下来的对象移动到幸存0区,幸存0区满后触发执行轻 GC,幸存0区存活对象移动到幸存1区,这样保证了一段时间内总有一个幸存区为空。经过多次轻 GC仍然存活的对象移动到老年代。老年代存储长期存活的对象,占满时会触发重 GC,GC期间会停止所有线程等待GC完成,所以对相应要求高的应用尽量减少发生Major GC,避免响应超时。
JVM什么时候触发GC,如何减少FullGC的次数?
当 Eden 区的空间耗尽时 Java 虚拟机便会触发一次 新生代 GC 来收集新生代的垃圾,存活下来的对象,则会被送到 Survivor 区,简单说就是当新生代的Eden区满的时候触发 新生代 GC 。
serial GC 串行垃圾收集器中,老年代内存剩余已经小于之前年轻代晋升老年代的平均大小,则进行 Full GC。而在 CMS 等并发收集器中则是每隔一段时间检查一下老年代内存的使用量,超过一定比例时进行 Full GC 回收。
可以采用以下措施来减少Full GC的次数:
增加方法区的空间;
增加老年代的空间;
减少新生代的空间;
禁止使用System.gc()方法;
使用标记-整理算法,尽量保持较大的连续内存空间;
排查代码中无用的大对象。
jvm是怎么给对象分配内存的(堆内存分配机制)?
- 对象优先在 eden 区分配,当 eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC,进入From Survivor0区,From Survivor0区 Minor GC到To Survivor1年龄加1,达到最大年龄,再进入老年代。
- 大对象直接进入老年代。
- 长期存活的对象将进入老年代
对象如何晋升到老年代?
虚拟机给每个对象定义了一个对象年龄(Age)计数器,存储在对象头中。对象通常在Eden区里诞生,如果经过第一次MinorGC后仍然存活,并且能被Survivor容纳的话,该对象会被移动到Survivor空间中,并且将其对象年龄设为1岁。对象在Survivor区中每熬过一次MinorGC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15),就会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
JVM是如何运行的?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SxdENGzP-1666488157632)(image-20220912111942426.png)]
介绍一下Java代码的编译过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4hvmj9eJ-1666488157633)(image-20220912112459278.png)]
类存放在哪里?
方法区(Method Area)。与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
局部变量存放在哪里?
Java虚拟机栈(Java Virtual Machine Stack)。**线程私有的,**它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
新生代为什么要分为Eden和Survivor,它们的比例是多少?
Appel式回收的具体做法是把新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次分配内存只使用Eden和其中一块Survivor。发生垃圾搜集时,将Eden和Survivor中仍然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和已用过的那块Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也即每次新生代中可用内存空间为整个新生代容量的90%(Eden的80%加上一个Survivor的10%),只有一个Survivor空间,即10%的新生代是会被“浪费”的。
为什么要设置两个Survivor区域?
- 设置两个 Survivor 区最大的好处就是解决内存碎片化。
- 因为 Survivor 有 2 个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责兑换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
- 这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。
本地方法native是abstract的吗?
定义一个native方法,不提供方法体(类似于抽象方法)。因为其方法体是由非java语言在外面实现的。
jvm的指令重排
为了提高性能,编译器和处理器常常会对既定的代码执行顺序进行指令重排序,JMM内部会有指令重排,并且会有af-if-serial和happen-before的理念来保证指令的正确性。
- af-if-serial:不管怎么重排序,单线程下的执行结果不能被改变;
- 先行发生原则(happen-before):先行发生原则有很多,其中程序次序原则,在一个线程内,按照程序书写的顺序执行,书写在前面的操作先行发生于书写在后面的操作,准确地讲是控制流顺序而不是代码顺序。
常见的垃圾收集器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YnrxTFkQ-1666488157633)(image-20220916211426069.png)]
JMM和JVM之间的区别?
JMM
-
Java Memory Model Java内存模型
-
作用:缓存一致性协议,用于定义数据读写的规则
-
JMM定义了线程工作内存和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory java就一个)中,每个线程都有一个私有的本地内存(Local Memory)(每个线程都有自己的工作区域,是从主内存拷贝的)
-
volilate关键字:解决共享对象可见性问题
-
线程每次修改后立刻同步到主内存中,保证其它线程可以看到变量的修改
-
线程每次使用变量前,先从主内存中刷新最新到工作内存(本地内存),保证能看见其它线程对变量的修改的同步
-
JVM
- JVM是 Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。
- 引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
数据库
SQL必会50题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AhdZe4bJ-1666488157633)(v2-ef8dec436662045c7c15ec7fbb3cfe1b_1440w.jpg)]
建表建库
-- 创建数据库exercise
create database exercise;
-- 使用数据库exercise
use exercise;
-- 创建学生表student
create table student
(Sno varchar(10) not null,
Sname varchar(10) ,
Sage date ,
Ssex varchar(10) ,
primary key (Sno));
start transaction;
insert into student values ('01', '赵雷', '1990-01-01', '男');
insert into student values ('02', '钱电', '1990-12-21', '男');
insert into student values ('03', '孙风', '1990-05-20', '男');
insert into student values ('04', '李云', '1990-08-06', '男');
insert into student values ('05', '周梅', '1991-12-01', '女');
insert into student values ('06', '吴兰', '1992-03-01', '女');
insert into student values ('07', '郑竹', '1989-07-01', '女');
insert into student values ('08', '王菊', '1990-01-20', '女');
commit;
-- 创建科目表course
create table course
(Cno varchar(10) not null,
Cname varchar(10) ,
Tno varchar(10) ,
primary key (Cno));
start transaction;
insert into course values ('01', '语文', '02');
insert into course values ('02', '数学', '01');
insert into course values ('03', '英语', '03');
commit;
-- 创建教师表teacher
create table teacher
(Tno varchar(10) not null,
Tname varchar(10) ,
primary key (Tno));
strat transaction;
insert into teacher values ('01', '张三');
insert into teacher values ('02', '李四');
insert into teacher values ('03', '王五');
commit;
-- 创建成绩表 sc
create table sc
(Sno varchar (10) ,
Cno varchar (10) ,
score decimal(18,1),
primary key (Sno, Cno));
start transaction;
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 80);
insert into SC values('03' , '01' , 80);
insert into SC values('03' , '02' , 80);
insert into SC values('03' , '03' , 80);
insert into SC values('04' , '01' , 50);
insert into SC values('04' , '02' , 30);
insert into SC values('04' , '03' , 20);
insert into SC values('05' , '01' , 76);
insert into SC values('05' , '02' , 87);
insert into SC values('06' , '01' , 31);
insert into SC values('06' , '03' , 34);
insert into SC values('07' , '02' , 89);
insert into SC values('07' , '03' , 98);
commit;
1. 查询「李」姓老师的数量 【Like】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select count(*)
from teacher
where tname like '李%';
+----------+
| count(*) |
+----------+
| 1 |
+----------+
2. 查询名字中含有「风」字的学生信息【Like】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Sno,Sname,Sage,Ssex --也可以用select * 替换
from student
where Sname like '%风%';
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 03 | 孙风 | 1990-05-20 | 男 |
+-----+-------+------------+------+
3. 查询男生、女生人数【聚合函数】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Ssex 性别,count(*) 人数
from student
group by Ssex;
+------+------+
| 性别 | 人数 |
+------+------+
| 男 | 4 |
| 女 | 4 |
+------+------+
4. 查询课程编号为02的总成绩【聚合函数】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Cno 课程号,sum(Score) 总成绩
from sc
where Cno = '02';
+--------+--------+
| 课程号 | 总成绩 |
+--------+--------+
| 02 | 436.0 |
+--------+--------+
5. 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列【聚合函数】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Cno 课程号,avg(Score) as 平均成绩
from sc
group by Cno
order by 平均成绩 desc,课程号 asc;
+--------+----------+
| 课程号 | 平均成绩 |
+--------+----------+
| 02 | 72.66667 |
| 03 | 68.50000 |
| 01 | 64.50000 |
+--------+----------+
6. 求每门课程的学生人数 【聚合函数】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Cno as 课程号, count(Sno) as 学生人数
from sc
group by 课程号;
+--------+----------+
| 课程号 | 学生人数 |
+--------+----------+
| 01 | 6 |
| 02 | 6 |
| 03 | 6 |
+--------+----------+
7. 统计每门课程的学生选修人数(超过 5 人的课程才统计)【聚合函数】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Cno as 课程号, count(Sno) as 学生人数
from sc
group by 课程号
having count(Sno)>5;
+--------+----------+
| 课程号 | 学生人数 |
+--------+----------+
| 01 | 6 |
| 02 | 6 |
| 03 | 6 |
+--------+----------+
8. 检索至少选修两门课程的学生学号 【聚合函数】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select sno 学生学号
from sc
group by sno
having count(sno)>= 2;
+----------+
| 学生学号 |
+----------+
| 01 |
| 02 |
| 03 |
| 04 |
| 05 |
| 06 |
| 07 |
+----------+
9. 查询在 SC 表存在成绩的学生信息【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select *
from student
where sno in (select sno from sc);
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-03-01 | 女 |
| 07 | 郑竹 | 1989-07-01 | 女 |
+-----+-------+------------+------+
10. 查询不存在" 01 “课程但存在” 02 "课程的情况【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select * from student
where sno not in (select sno from sc where cno =01)
and sno in (select sno from sc where cno=02);
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 07 | 郑竹 | 1989-07-01 | 女 |
+-----+-------+------------+------+
11. 查询同时存在" 01 “课程和” 02 "课程的情况【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select * from student
where sno in(select sno from sc where cno='01')
and sno in (select sno from sc where cno='02');
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
+-----+-------+------------+------+
12. 查询出只选修两门课程的学生学号和姓名【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select Sno,Sname
from student
where sno in (select sno from sc group by sno having count(cno)=2);
+-----+-------+
| Sno | Sname |
+-----+-------+
| 05 | 周梅 |
| 06 | 吴兰 |
| 07 | 郑竹 |
+-----+-------+
13. 查询没有学全所有课程的同学的信息 【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select *
from student
where sno not in (select sno from sc group by sno having count(cno)=(select count(*) from course));
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-03-01 | 女 |
| 07 | 郑竹 | 1989-07-01 | 女 |
| 08 | 王菊 | 1990-01-20 | 女 |
+-----+-------+------------+------+
14. 查询选修了全部课程的学生信息【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
select *
from student
where sno in (select sno from sc group by sno having count(cno)= (select count(*) from course));
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
+-----+-------+------------+------+
15. 查询所有课程成绩均小于60分的学号、姓名【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
找的是所有课程都小于60的人,所以把大于60的人都给排除了,然后发现有的学生每月选课,所以还需要确保他的学号出现在sc表中。
select sno,sname
from student
where sno not in (select distinct sno from sc
where score >= 60) and sno in(select distinct sno from sc);
+-----+-------+
| sno | sname |
+-----+-------+
| 04 | 李云 |
| 06 | 吴兰 |
+-----+-------+
16. 查询课程编号为 01 且课程成绩在 80 分及其以上的学生的学号和姓名【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
elect sno ,sname from student
where sno in(select distinct sno from sc
where cno = '01' and score >= 80);
+-----+-------+
| sno | sname |
+-----+-------+
| 01 | 赵雷 |
| 03 | 孙风 |
+-----+-------+
17. 查询学过「张三」老师授课的同学的信息 【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
方法一:嵌套子查询
select *
from student
where sno in (select distinct sno from sc
where cno = (select cno from course
where tno = (select tno from teacher
where tname = '张三')));
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 01 | 赵雷 | 1990-01-01 | 男 |
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 07 | 郑竹 | 1989-07-01 | 女 |
+-----+-------+------------+------+
方法二:串联查询
select * from student
where sno in(select sno from sc,course,teacher
where teacher.tno = course.tno and tname= '张三' and sc.cno = course.cno);
18. 查询没学过"张三"老师讲授的任一门课程的学生姓名 【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
和上题思路一致,写法比较多,是求17题的补集。
select sname from student
where sno not in (select sno from sc,course,teacher
where sc.cno = course.cno and course.tno = teacher.tno and teacher.tname = '张三');
+-------+
| sname |
+-------+
| 吴兰 |
| 王菊 |
+-------+
19.查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息 【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
以为查询出来可能会包含’01’同学的信息,所以要把它去掉!
select *
from student
where sno in (select distinct sno from sc
where cno in (select cno from sc where sno = '01')) and sno != '01';
+-----+-------+------------+------+
| Sno | Sname | Sage | Ssex |
+-----+-------+------------+------+
| 02 | 钱电 | 1990-12-21 | 男 |
| 03 | 孙风 | 1990-05-20 | 男 |
| 04 | 李云 | 1990-08-06 | 男 |
| 05 | 周梅 | 1991-12-01 | 女 |
| 06 | 吴兰 | 1992-03-01 | 女 |
| 07 | 郑竹 | 1989-07-01 | 女 |
+-----+-------+------------+------+
20.查询和" 01 "号的同学学习的课程完全相同的其他同学的信息【子查询】
- student【Sno,Sname,Sage,Ssex】
- sc【Sno,Cno,Score】
- course【Cno,Cname,Tno】
- teacher【Tno,Tname】
SQL语言包括哪几部分?每部分都有哪些操作关键字?
- 数据定义:Create Table,Alter Table,Drop Table, Craete/Drop Index 等
- 数据操纵:Select ,insert,update,delete,
- 数据控制:grant,revoke
- 数据查询:select
介绍一下数据库分页(分页的关键字)?
SELECT语句默认返回所有匹配的行,它们可能是指定表中的每个行。为了返回第一行或前几行,可使用LIMIT子句,以实现分页查询。
说一下SQL中有哪些聚合函数?
COUNT()函数:
- COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数,它有两种用法:
- COUNT(*)计算表中总的行数,不管某列是否有数值或者为空值。
- COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行。
- COUNT()函数可以与GROUP BY一起使用来计算每个分组的总和。
AVG()函数():
- AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
- AVG()函数可以与GROUP BY一起使用,来计算每个分组的平均值。
SUM()函数:
- SUM()是一个求总和的函数,返回指定列值的总和。
- SUM()可以与GROUP BY一起使用,来计算每个分组的总和。
MAX()函数:
- MAX()返回指定列中的最大值。
- MAX()也可以和GROUP BY关键字一起使用,求每个分组中的最大值。
- MAX()函数不仅适用于查找数值类型,也可应用于字符类型。
MIN()函数:
- MIN()返回查询列中的最小值。
- MIN()也可以和GROUP BY关键字一起使用,求出每个分组中的最小值。
- MIN()函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型。
表跟表是怎么关联的?(内连接,外连接、自然连接)
表与表之间常用的关联方式有两种:内连接、外连接,下面以MySQL为例来说明这两种连接方式。
内连接:内连接通过INNER JOIN来实现,它将返回两张表中满足连接条件的数据,不满足条件的数据不会查询出来。
外连接:
外连接通过OUTER JOIN来实现,它会**返回两张表中满足连接条件的数据,同时返回不满足连接条件的数据。**外连接有两种形式:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)。
- **左外连接:**可以简称为左连接(LEFT JOIN),它会返回左表中的所有记录和右表中满足连接条件的记录。
- **右外连接:**可以简称为右连接(RIGHT JOIN),它会返回右表中的所有记录和左表中满足连接条件的记录。
- **全外连接:**连接的表中不匹配的数据全部会显示出来。
**自然关联:**自关联就是一张表自己与自己相关联,为了避免表名的冲突,需要在关联时通过别名将它们当做两张表来看待。一般在表中数据具有层级(树状)时,可以采用自关联一次性查询出多层级的数据。
Where和Having有什么区别?
- WHERE是一个约束声明,使用WHERE约束来自数据库的数据,WHERE是在结果返回之前起作用的,WHERE中不能使用聚合函数。
- HAVING是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在HAVING中可以使用聚合函数。另一方面,HAVING子句中不能使用除了分组字段和聚合函数之外的其他字段。
何为索引?有什么作用?
索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B 树, B+树和 Hash。索引的作用就相当于书的目录。
索引的优点:
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
索引的缺点 :
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
索引有哪些类型?
-
普通索引是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。
-
唯一索引要求索引列的值必须唯一,但允许有空值,避免重复的列出现,唯一索引可以有多个,多个列都可以标识为唯一索引。。
-
主键索引是一种特殊的唯一索引,不允许有空值,只能有一个,只能有一列作为主键。
-
单列索引即一个索引只包含单个列,一个表可以有多个单列索引。
-
组合索引是指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合。
-
全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建。
-
空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING和POLYGON。MySQL使用SPATIAL关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MyISAM的表中创建。
如何创建及保存MySQL的索引?
在创建表的时候创建索引:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FuwpZMAs-1666488157634)(image-20220912153340732.png)]
在已经存在的表中创建索引。可以使用ALTER TABLE语句或者CREATEINDEX语句。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NcunbXP3-1666488157634)(image-20220912153359912.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rGyihuzW-1666488157634)(image-20220912153405816.png)]
MySQL怎么判断要不要加索引?
建议按照如下的原则来创建索引:
- 当唯一性是某种数据本身的特征时,指定唯一索引。使用唯一索引需能确保定义的列的数据完整性,以提高查询速度。
- 在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引,如果待排序的列有多个,可以在这些列上建立组合索引。
如何判断数据库的索引有没有生效?
在select语句前面加EXPLAIN语句查看索引是否正在使用。
EXPLAIN语句将为我们输出详细的SQL执行信息,其中:possible_keys行给出了MySQL在搜索数据记录时可选用的各个索引。key行是MySQL实际选用的索引。
如何评估一个索引创建的是否合理?
建议按照如下的原则来设计索引:
- 避免对经常更新的表进行过多的索引,并且索引中的列要尽可能少。应该经常用于查询的字段创建索引,但要避免添加不必要的字段。
- 数据量小的表最好不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
- **在条件表达式中经常用到的不同值较多的列上建立索引,在不同值很少的列上不要建立索引。**比如在学生表的“性别”字段上只有“男”与“女”两个不同值,因此就无须建立索引,如果建立索引不但不会提高查询效率,反而会严重降低数据更新速度。
- **当唯一性是某种数据本身的特征时,指定唯一索引。**使用唯一索引需能确保定义的列的数据完整性,以提高查询速度。
- 在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引,如果待排序的列有多个,可以在这些列上建立组合索引。
所有的字段都适合创建索引吗?
不是。
下列几种情况,是不适合创建索引的:
- 频繁更新的字段不适合建立索引;
- where条件中用不到的字段不适合建立索引;
- 数据比较少的表不需要建索引;
- 数据重复且分布比较均匀的的字段不适合建索引,例如性别、真假值;
- 参与列计算的列不适合建索引。
索引底层的数据结构
索引底层结构通常指的是B+Tree(多路平衡搜索树), 我们平时使用的如 ,聚集索引,复合索引,唯一索引等都默
认使用的是B+TREE,除此以外还有hash索引,或二叉树索引底层结构
聚簇索引和非聚簇索引
- 聚簇索引: 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
- 非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
说一说索引的实现原理?
- MyISAM 引擎中,**B+Tree 叶节点的 data 域存放的是数据记录的地址。**在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
- InnoDB 引擎中,**其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。**这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在 根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
说下B树和B+树的区别?
B 树也称 B-树,全称为 多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 Balanced (平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
B 树& B+树两者有何异同呢?
- B 树的所有节点既存放键(key) 也存放 数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
MySQL的索引为什么用B+树?
- **从磁盘I/O效率方面来看:**B+树的非叶子节点不存储数据,所以树的每一层就能够存储更多的索引数量,也就是说,B+树在层高相同的情况下,比B树的存储数据量更多,间接会减少磁盘I/O的次数。
- 从范围查询效率方面来看:在MySQL中,范围查询是一个比较常用的操作,而B+树的所有存储在叶子节点的数据使用了双向链表来关联,所以B+树在查询的时候只需查两个节点进行遍历就行,而B树需要获取所有节点,因此,B+树在范围查询上效率更高。
- 从全表扫描方面来看:因为,B+树的叶子节点存储所有数据,所以B+树的全局扫描能力更强一些,因为它只需要扫描叶子节点。而B树需要遍历整个树。
- **从自增ID方面来看:**基于B+树的这样一种数据结构,如果采用自增的整型数据作为主键,还能更好的避免增加数据的时候,带来叶子节点分裂导致的大量运算的问题。
B树
B+树
B+树相比于B树,做了这样的升级:B+树中的非叶子节点都不存储数据,而是只作为索引。由叶子节点存放整棵树的所有数据。而叶子节点之间构成一个从小到大有序的链表互相指向相邻的叶子节点,也就是叶子节点之间形成了有序的双向链表。如下图B+树的结构。
MySQL的Hash索引和B树索引有什么区别?
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树,对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。它们有以下的不同:
- hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
- hash索引不支持使用索引进行排序,原理同上。
- hash索引不支持模糊查询以及多列索引的最左前缀匹配,原理也是因为hash函数的不可预测。
- hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
- hash索引虽然在等值查询上较快,但是不稳定,性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
什么时候用Hash,什么时候用B+树?
hash索引的应用场景:如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,特别适合采用哈希索引。
B+树的应用场景:大多数场景下,都会有组合查询,范围查询、排序、分组、模糊查询等查询特征,Hash 索引无法满足要求,我们就需要B+树索引进行操作。
说一说你对数据库事务(事务的特性)的了解ACID
事务可由一条非常简单的SQL语句组成,也可以由一组复杂的SQL语句组成。在事务中的操作,要么都执行修改,要么都不执行,这就是事务的目的,也是事务模型区别于文件系统的重要特征之一。事务需遵循ACID四个特性:
- A(atomicity),原子性。原子性指整个数据库事务是不可分割的工作单位。只有使事务中所有的数据库操作都执行成功,整个事务的执行才算成功。事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
- C(consistency),一致性。一致性指事务将数据库从一种状态转变为另一种一致的状态。**在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。**例如转账前后总金额一定。
- I(isolation),隔离性。事务的隔离性要求每个读写事务的对象与其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,这通常使用锁来实现。
- D(durability) ,持久性。事务一旦提交,其结果就是永久性的,即使发生宕机等故障,数据库也能将数据恢复。持久性保证的是事务系统的高可靠性,而不是高可用性。
数据库如何保证原子性?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3gelSXyn-1666488157635)(image-20220912201535837.png)]
数据库如何保证一致性?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rpenHe40-1666488157635)(image-20220912201628209.png)]
数据库如何保证持久性?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FwxGh6mO-1666488157635)(image-20220912201657271.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6R49P7hy-1666488157636)(image-20220912201732639.png)]
数据库如何保证隔离性?
隔离性追求的是并发情形下事务之间互不干扰。那么隔离性的探讨,主要可以分为两个方面。MySQL 的隔离级别基于锁和 MVCC 机制(多版本并发控制机制)共同实现的。
-
(一个事务)写操作对(另一个事务)写操作的影响:锁机制保证隔离性。
-
要求同一时刻只能有一个事务对数据进行写操作,事务在修改数据之前,需要先获得相应的锁。事务在修改数据之前,需要先获得相应的锁。获得锁之后,事务便可以修改数据。该事务操作期间,这部分数据是锁定的,其他事务如果需要修改数据,需要等待当前事务提交或回滚后释放锁。
-
锁可以分为表锁、行锁以及其他位于二者之间的锁。
表锁在操作数据时会锁定整张表,并发性能较差。
行锁则只锁定需要操作的数据,并发性能好。
出于性能考虑,绝大多数情况下使用的都是行锁。
-
-
(一个事务)写操作对(另一个事务)读操作的影响:MVCC (多版本并发控制机制)保证隔离性。
- 它最大的优点是读不加锁,因此读写不冲突,并发性能好。
说下事务隔离级别有哪些?

- READ-UNCOMMITTED(读取未提交) : 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交) : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读) : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- (MySQL 的默认隔离级别是什么?)
- SERIALIZABLE(可串行化) : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
并发操作可能造成哪些问题?
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 方法1:事务隔离级别设置为:read committed。
方法2:读取时加排它锁(select…for update),事务提交才会释放锁,修改时加共享锁(update …lock in share mode)。加排它锁后,不能对该条数据再加锁,能查询但不能更改数据。
- 方法1:事务隔离级别设置为:read committed。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
- 不可重复读(Unrepeatable read): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
- 方法1:事务隔离级别设置为Repeatable read。
方法2:读取数据时加共享锁,写数据时加排他锁,都是事务提交才释放锁。读取时候不允许其他事物修改该数据,不管数据在事务过程中读取多少次,数据都是一致的,避免了不可重复读问题。
- 方法1:事务隔离级别设置为Repeatable read。
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
MySQL如何消除幻读?
MySQL的InnoDB引擎,在默认的REPEATABLE READ的隔离级别下,实现了可重复读,同时也解决了幻读问题。它使用Next-Key Lock算法实现了行锁,并且不允许读取已提交的数据,所以解决了不可重复读的问题。另外,该算法包含了间隙锁,会锁定一个范围,因此也解决了幻读的问题。
MySQL事务如何回滚?
在MySQL默认的配置下,事务都是自动提交和回滚的。当显示地开启一个事务时,可以使用ROLLBACK语句进行回滚。该语句有两种用法:
- ROLLBACK:要使用这个语句的最简形式,只需发出ROLLBACK。同样地,也可以写为ROLLBACK WORK,但是二者几乎是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
- ROLLBACK TO [SAVEPOINT] identifier :这个语句与SAVEPOINT命令一起使用。可以把事务回滚到标记点,而不回滚在此标记点之前的任何工作。
MySQL 中有哪几种锁?
当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
- 表级锁:是针对非索引字段加的锁,对当前操作的整张表加锁,开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:是针对索引字段加的锁,只针对当前操作的行记录进行加锁,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
说下共享锁和排他锁?
- 共享锁(S 锁) :又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
- 排他锁(X 锁) :又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
什么是意向锁?
意向锁是表级锁,共有两种:
- 意向共享锁(Intention Shared Lock,IS 锁):事务有意向对表中的某些加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(Intention Exclusive Lock,IX 锁):事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
在为数据行加共享 / 排他锁之前,InooDB 会先获取该数据行所在在数据表的对应意向锁。意向锁之间是互相兼容的。意向锁和共享锁和排它锁互斥
死锁的特点?
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。若无外力作用,事务都将无法推进下去。
- 解决死锁问题最简单的一种方法是超时,即当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务进行回滚,另一个等待的事务就能继续进行。
- 除了超时机制,当前数据库还都普遍采用wait-for graph(等待图)的方式来进行死锁检测。较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用的这种方式。wait-for graph要求数据库保存以下两种信息:锁的信息链表;事务等待链表;*通过上述链表可以构造出一张图,而在这个图中若存在回路,就代表存在死锁,因此资源间相互发生等待。*这是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常来说InnoDB存储引擎选择回滚undo量最小的事务。
简述在 MySQL 数据库中 MyISAM 和 InnoDB 的区别?
- MYISAM:节约空间,速度较快
- INNODB:安全性高,能够处理事务,能够多表多用户操作
什么情况下设置了索引但无法使用?索引失效
- 以“%”开头的 LIKE 语句,模糊匹配
- OR 语句前后没有同时使用索引
- 数据类型出现隐式转化(如 varchar 不加单引号的话可能会自动转换为 int 型)
什么叫视图?游标是什么?
-
视图是从一个或几个基本表导出的表。视图本身不独立存储在数据库中,是一个虚表视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
- (1) 视图能够简化用户的操作
- (2) 视图使用户能以多种角度看待同一数据;
- (3) 视图为数据库提供了一定程度的逻辑独立性;
- (4) 视图能够对机密数据提供安全保护。
-
**游标是对查询出来的结果集作为一个单元来有效的处理。可以将游标简单的看成是查询的结果集的一-个指针,可以根据需要在结果集上面来回滚动,浏览需要的数据。**游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
-
遍历数据行;
-
保存查询结果,方便下文调用。概念中提到使用游标会保存数据行的副本,那么创建游标后,下文查询即可从副本中查询,要比直接查数据库快很多。
-
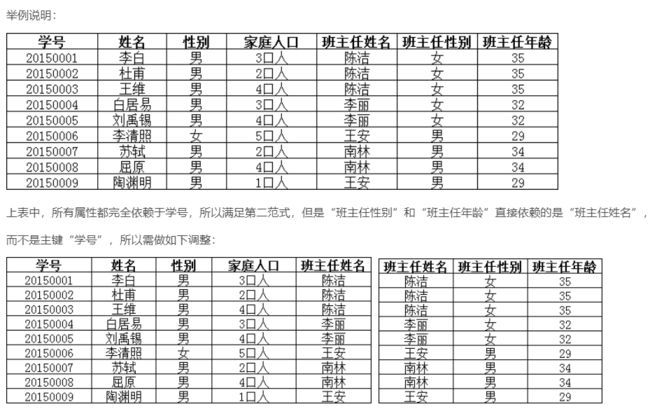
什么是三大范式?
- 第一范式:1NF 是对属性的原子性约束,要求属性具有原子性,不可再分解;原子性:保证每一列不可再分
- 第二范式:2NF 是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;**非主属性必须完全依赖于候选码(在1NF的基础上消除非主属性对主码的部分函数依赖) ** 每张表只描述一件事情
- 第三范式:3NF 是对字段冗余性的约束,即任何字段不能由其他字段派生出来,任何非主属性不依赖于其他主属性(在2NF的基础上消除传递依赖),第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。 第三范式需要确保表中的每一列数据都与主键直接相关,而不能间接相关。


范式的优缺点
- 优点:
数据的标准化有助于消除数据库中的数据冗余
第三范式通常被认为在性能,扩展性和数据完整性方面达到了最好的平衡
- 缺点:
降低了查询效率,因为范式等级越高,设计出来的表就越多,进行数据查询的时候就可能需要关联多张表,不仅代价昂贵,而且可能会使得一些索引失效
范式只是提出设计的标标准,实际设计的时候,我们可能为了性能和读取效率违反范式的原则,通过增加少量的冗余或重复的数据来提高数据库的读取性能,减少关联查询,实现空间换时间的目的
反范式化
- 概述
- 遵循业务优先的原则
- 首先满足业务需求,再进来减少冗余
- 有时候我们想要对查询效率进行优化,反范式化也是一种优化思路,我们可以通过在数据表中增加冗余字段来提高数据库的读性能。
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1mazVp3z-1666488157636)(%E6%88%AA%E5%B1%8F2022-09-13%2011.45.49-16630714167591.png)]
- 反范式的新问题
- 反范式的适用场景
主键、外键和索引的区别?
- 主键–唯一标识一条记录,不能有重复的,不允许为空。
- 主键–用来保证数据完整性
- 主键–主键只能有一个
- 外键–表的外键是另一表的主键, 外键可以有重复的, 可以是空值。
- 外键–用来和其他表建立联系用的
- 外键–一个表可以有多个外键
- 索引–该字段没有重复值,但可以有一个空值
- 索引–是提高查询排序的速度
- 索引–一个表可以有多个唯一索引
数据库优化有哪些?
架构优化
一般来说在高并发的场景下对架构层进行优化其效果最为明显,常见的优化手段有:分布式缓存,读写分离,分库分表等,每种优化手段又适用于不同的应用场景。
分布式缓存
有句老话说的好,性能不够,缓存来凑。当需要在架构层进行优化时我们第一时间就会想到缓存这个神器,在应用与数据库之间增加一个缓存服务,如Redis或Memcache。
当接收到查询请求后,我们先查询缓存,判断缓存中是否有数据,有数据就直接返回给应用,如若没有再查询数据库,并加载到缓存中,这样就大大减少了对数据库的访问次数,自然而然也提高了数据库性能。
不过需要注意的是,引入分布式缓存后系统需要考虑如何应对缓存穿透、缓存击穿和缓存雪崩的问题。
读写分离
一主多从,读写分离,主动同步,是一种常见的数据库架构优化手段。
一般来说当你的应用是读多写少,数据库扛不住读压力的时候,采用读写分离,通过增加从库数量可以线性提升系统读性能。
主库,提供数据库写服务;从库,提供数据库读能力;主从之间,通过binlog同步数据。
当准备实施读写分离时,为了保证高可用,需要实现故障的自动转移,主从架构会有潜在主从不一致性问题。
水平切分
水平切分,也是一种常见的数据库架构优化手段。
当你的应用业务数据量很大,单库容量成为性能瓶颈后,采用水平切分,可以降低数据库单库容量,提升数据库写性能。
当准备实施水平切分时,需要结合实际业务选取合理的分片键(sharding-key)。
架构优化小结
-
读写分离主要是用于解决 “数据库读性能问题”
-
水平切分主要是用于解决“数据库数据量大的问题”
-
分布式缓存架构可能比读写分离更适用于高并发、大数据量大场景。
硬件优化
我们使用数据库,不管是读操作还是写操作,最终都是要访问磁盘,所以说磁盘的性能决定了数据库的性能。一块PCIE固态硬盘的性能是普通机械硬盘的几十倍不止。这里我们可以从吞吐率、IOPS两个维度看一下机械硬盘、普通固态硬盘、PCIE固态硬盘之间的性能指标。
吞吐率:单位时间内读写的数据量
-
机械硬盘:约100MB/s ~ 200MB/s
-
普通固态硬盘:200MB/s ~ 500MB/s
-
PCIE固态硬盘:900MB/s ~ 3GB/s
IOPS:每秒IO操作的次数
-
机械硬盘:100 ~200
-
普通固态硬盘:30000 ~ 50000
-
PCIE固态硬盘:数十万
通过上面的数据可以很直观的看到不同规格的硬盘之间的性能差距非常大,当然性能更好的硬盘价格会更贵,在资金充足并且迫切需要提升数据库性能时,尝试更换一下数据库的硬盘不失为一个非常好的举措,你之前遇到SQL执行缓慢问题在你更换硬盘后很可能将不再是问题。
DB优化
SQL执行慢有时候不一定完全是SQL问题,手动安装一台数据库而不做任何参数调整,再怎么优化SQL都无法让其性能最大化。要让一台数据库实例完全发挥其性能,首先我们就得先优化数据库的实例参数。
数据库实例参数优化遵循三句口诀:日志不能小、缓存足够大、连接要够用。
数据库事务提交后需要将事务对数据页的修改刷( fsync)到磁盘上,才能保证数据的持久性。这个刷盘,是一个随机写,性能较低,如果每次事务提交都要刷盘,会极大影响数据库的性能。数据库在架构设计中都会采用如下两个优化手法:
-
先将事务写到日志文件RedoLog(WAL),将随机写优化成顺序写
-
加一层缓存结构Buffer,将单次写优化成顺序写
所以日志跟缓存对数据库实例尤其重要。而连接如果不够用,数据库会直接抛出异常,系统无法访问。
SQL优化
SQL优化很容易理解,就是通过给查询字段添加索引或者改写SQL提高其执行效率,一般而言,SQL编写有以下几个通用的技巧:
-
合理使用索引
- 索引少了查询慢;索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能 选择率高(重复值少)且被where频繁引用需要建立B树索引;一般join列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得平衡;复合索引创建时要注意基于非前导列查询的情况
-
使用UNION ALL替代UNION
- UNION ALL的执行效率比UNION高,因为UNION执行时需要排重;
-
避免select * 写法
- 执行SQL时优化器需要将 * 转成具体的列;每次查询都要回表,不能走覆盖索引。
-
JOIN字段建议建立索引
- 一般JOIN字段都提前加上索引
-
避免复杂SQL语句
- 提升可阅读性;避免慢查询的概率;可以转换成多个短查询,用业务端处理
-
避免where 1=1写法
-
避免order by rand()类似写法
- RAND()导致数据列被多次扫描
执行计划
要想优化SQL必须要会看执行计划,执行计划会告诉你哪些地方效率低,哪里可以需要优化。通过explain sql 可以查看执行计划
SQL优化小结
-
查看执行计划 explain sql
-
如果有告警信息,查看告警信息 show warnings;
-
查看SQL涉及的表结构和索引信息
-
根据执行计划,思考可能的优化点
-
按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
-
查看优化后的执行时间和执行计划
-
如果优化效果不明显,重复第四步操作
blob和text的区别?
1、定义:
- text:text是非二进制字符串,并且需要指定字符集,并按照该字符集进行校验和排序。只能存储纯文本,可以看作是VARCHAR在长度不足时的扩展。
- blob:blob存储的是二进制数据,因此无需字符集校验,blob除了存储文本信息外,由于二进制存储格式,所以还可以保存图片等信息,blob可以看作是VARBINARY在长度不足时的扩展。
2、相同点
- 都不允许有默认值。
- 保存或检索数据不删除尾部空格。
- 索引在blob或者text上必须执行索引前缀的长度。
3、不同点
- text大小写不敏感,而blob排序和比较以大小写敏感的方式执行。
- text是非二进制字符串,blob存储的是二进制数据。
- text需要指定字符集,blob无需字符集校验。
- blob可以储存图片, text只能储存纯文本文件。
mysql货币使用什么字段类型?
在mysql中,货币常使用Decimal和Numric类型的字段表示,这两种类型被MySQL实现为同样的类型;它们被用于保存值,该值的准确精度是极其重要的值,例如与金钱有关的数据。
聚簇索引和非聚簇索引有什么区别?
- 聚簇索引叶子节点存储的是行数据;而非聚簇索引叶子节点存储的是聚簇索引(通常是主键 ID)。
- 聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,因此性能不如聚簇索引。
- 聚簇索引一般为主键索引,而主键一个表中只能有一个,因此聚簇索引一个表中也只能有一个,而非聚簇索引则没有数量上的限制。
数据结构
排序算法&时间复杂度?
排序方法有十种,分别是:一、冒泡排序;二、选择排序;三、插入排序;四、希尔排序;五、归并排序;六、快速排序;七、堆排序;八、计数排序;九、桶排序;十、基数排序。
一、冒泡排序O(n^2)
冒泡排序是排序算法中较为简单的一种,英文称为Bubble Sort。它遍历所有的数据,每次对相邻元素进行两两比较,如果顺序和预先规定的顺序不一致,则进行位置交换;这样一次遍历会将最大或最小的数据上浮到顶端,之后再重复同样的操作,直到所有的数据有序。
二、选择排序O(n^2)
选择排序简单直观,英文称为Selection Sort,先在数据中找出最大或最小的元素,放到序列的起始;然后再从余下的数据中继续寻找最大或最小的元素,依次放到排序序列中,直到所有数据样本排序完成。
三、插入排序O(n^2)
插入排序英文称为Insertion Sort,它通过构建有序序列,对于未排序的数据序列,在已排序序列中从后向前扫描,找到相应的位置并插入,类似打扑克牌时的码牌。插入排序有一种优化的算法,可以进行拆半插入。
基本思路是先将待排序序列的第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列;然后从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置,直到所有数据都完成排序;如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。
四、希尔排序O(nlogn)
希尔排序也称递减增量排序,是插入排序的一种改进版本,英文称为Shell Sort,效率虽高,但它是一种不稳定的排序算法。
插入排序在对几乎已经排好序的数据操作时,效果是非常好的;但是插入排序每次只能移动一位数据,因此插入排序效率比较低。
希尔排序在插入排序的基础上进行了改进,它的基本思路是先将整个数据序列分割成若干子序列分别进行直接插入排序,待整个序列中的记录基本有序时,再对全部数据进行依次直接插入排序。
五、归并排序O(nlogn)
归并排序英文称为Merge Sort,归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。它首先将数据样本拆分为两个子数据样本, 并分别对它们排序, 最后再将两个子数据样本合并在一起; 拆分后的两个子数据样本序列, 再继续递归的拆分为更小的子数据样本序列, 再分别进行排序, 直到最后数据序列为1,而不再拆分,此时即完成对数据样本的最终排序。
归并排序严格遵循从左到右或从右到左的顺序合并子数据序列, 它不会改变相同数据之间的相对顺序, 因此归并排序是一种稳定的排序算法.
作为一种典型的分而治之思想的算法应用,归并排序的实现分为两种方法:
1、自上而下的递归;
2、自下而上的迭代;
六、快速排序O(nlogn)
快速排序,英文称为Quicksort,又称划分交换排序 partition-exchange sort 简称快排。
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。首先从数列中挑出一个元素,并将这个元素称为「基准」,英文pivot。重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。之后,在子序列中继续重复这个方法,直到最后整个数据序列排序完成。
七、堆排序O(nlogn)
堆排序,英文称Heapsort,是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序实现分为两种方法:
1、大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
2、小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
算法步骤:
1、创建一个堆 H[0……n-1];
2、把堆首(最大值)和堆尾互换;
3、把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
4、重复步骤 2,直到堆的尺寸为 1
八、计数排序O(n+k)
计数排序英文称Counting sort,是一种稳定的线性时间排序算法。计数排序使用一个额外的数组C,其中第i个元素是待排序数组A中值等于 i的元素的个数。然后根据数组C来将A中的元素排到正确的位置。基本的步骤如下:
1、找出待排序的数组中最大和最小的元素
2、统计数组中每个值为i的元素出现的次数,存入数组C的第i项
3、对所有的计数累加,从C中的第一个元素开始,每一项和前一项相加
4、反向填充目标数组,将每个元素i放在新数组的第C[i]项,每放一个元素就将C[i]减去1
九、桶排序O(n+k)
桶排序也称为箱排序,英文称为 Bucket Sort。它是将数组划分到一定数量的有序的桶里,然后再对每个桶中的数据进行排序,最后再将各个桶里的数据有序的合并到一起。
十、基数排序O(n*k)
基数排序英文称Radix sort,是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串和特定格式的浮点数,所以基数排序也仅限于整数。它首先将所有待比较数值,统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XkooLQ6J-1666488157637)(%E6%88%AA%E5%B1%8F2022-09-13%2018.59.54-16630715078703.png)]
平衡二叉树和红黑树的区别
- 平衡二叉树的左右子树的高度差绝对值不超过1,但是红黑树在某些时刻可能会超过1,只要符合红黑树的五个条件即可。
- 二叉树只要不平衡就会进行旋转,而红黑树不符合规则时,有些情况只用改变颜色不用旋转,就能达到平衡。
- 红黑树的高度只比高度平衡的AVL树的高度([外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pHj4B6Rd-1666488157637)(gif.latex)])仅仅大了一倍,红黑树的查询性能略微逊色于AVL树,AVL树为了维持这种高度的平衡,就要付出更多代价。每次插入、删除都要做调整,就比较复杂、耗时。所以,对于有频繁的插入、删除操作的数据集合,使用AVL树的代价就有点高了。红黑树只是做到了近似平衡,并不严格的平衡,所以在维护的成本上,要比AVL树要低。
红黑树的5个条件(性质)
-
每个结点不是红色就是黑色
-
根节点是黑色的
-
如果一个节点是红色的,则它的两个孩子结点必须是黑色的(这就约束了红黑树里面没有连续的红色节点)
-
对于每个结点,从该结点到其所有可到达的叶结点的路径中,均包含相同数目的黑色结点(即每条路径都有相同数量的黑色节点,注意:路径是走到 NIL 空节点)
-
每个 NIL 叶子结点都是黑色的(此处的叶子结点指的是空结点)
计算机网络
简述OSI七层协议 ?
OSI七层协议包括:物理层,数据路层,网络层,运输层,会话层,表示层, 应用层
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UC8yecRv-1666488157637)(%E4%B8%83%E5%B1%82%E4%BD%93%E7%B3%BB%E7%BB%93%E6%9E%84%E5%9B%BE.png)]
网络层的主要协议?
网络层有四个协议:ARP协议,IP协议,ICMP协议,IGMP协议。ARP协议为IP协议提供服务,IP协议为ICMP协议提供服务,ICMP协议为IGMP协议提供服务。
ARP协议:
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。
主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。
地址解析协议是建立在网络中各个主机互相信任的基础上的,局域网络上的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机ARP缓存;由此攻击者就可以向某一主机发送伪ARP应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个ARP欺骗。
ARP命令可用于查询本机ARP缓存中IP地址和MAC地址的对应关系、添加或删除静态对应关系等。相关协议有RARP、代理ARP。NDP用于在IPv6中代替地址解析协议。
IP协议:
IP是Internet Protocol(网际互连协议)的缩写,是TCP/IP体系中的网络层协议。设计IP的目的是提高网络的可扩展性:一是解决互联网问题,实现大规模、异构网络的互联互通;二是分割顶层网络应用和底层网络技术之间的耦合关系,以利于两者的独立发展。根据端到端的设计原则,IP只为主机提供一种无连接、不可靠的、尽力而为的数据包传输服务。
ICMP协议:
ICMP(Internet Control Message Protocol)Internet控制报文协议。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。
ICMP使用IP的基本支持,就像它是一个更高级别的协议,但是,ICMP实际上是IP的一个组成部分,必须由每个IP模块实现。
IGMP协议:
互联网组管理协议(IGMP,Internet Group Management Protocol)是因特网协议家族中的一个组播协议。
TCP/IP协议族的一个子协议,用于IP主机向任一个直接相邻的路由器报告他们的组成员情况。允许Internet主机参加多播,也是IP主机用作向相邻多目路由器报告多目组成员的协议。多目路由器是支持组播的路由器,向本地网络发送IGMP查询。主机通过发送IGMP报告来应答查询。组播路由器负责将组播包转发到所有网络中组播成员。
互联网组管理协议(IGMP)是对应于开源系统互联(OSI)七层框架模型中网络层的协议。在互联网工程任务组(The Internet Engineering Task Force,简称IETF)编写的标准文档(RFC)2236.中对Internet组管理协议(IGMP)做了详尽的描述。
IPv4格式、首部各字段意义及地址分类知识点总结?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4jFVRigJ-1666488157638)(watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3JpY2hlbnl1bnFp,size_16,color_FFFFFF,t_70.png)]
- 版本:占4位。指IP协议是IPv4还是IPv6,通信双方的版本必须一致。
- 首部长度:占4位。以4B为单位,最大值为60B。默认情况下首部长度看成20B,此时不使用任何选项(即可选字段)。
- 总长度:占16位。指首部和数据之和的长度,以1B为单位,因此数据报最大长度为2^16 − 1 =65535B。以太网的最大传送单元(MTU)为1500B,因此当一个IP数据包封装成帧时,数据包总长度一定不能超过数据链路层的MTU值。
- 标识:占16位。它是一个计数器,每产生一个数据报就加1,但它并不是“序号”(IP是无连接服务)。当一个数据报长度超过网络的MTU时,必须分片,此时每个数据报片都复制一次标识号以便能重装成原来的数据报。重装数据报是在目的端主机完成的。
- 标志:占3位。目前只有前两位有效,即MF和DF。MF=1表示后面还有分片;MF=0表示这是最后一个分片。DF=0允许分片;DF=1不允许分片。
- 片偏移:占13位。指明了每个分片相对于原始报文开头的偏移量,以8B为单位,即每个分片的长度必须是8B的整数倍。
- 生存时间(TTL):占8位。报文经过的每个路由器都将此字段减1,当此字段等于0时,丢弃该报文,确保报文不会永远在网络中循环。
- 协议:占8位。指出携带的数据应交给那个传输层协议,值为6表示TCP;值为17表示UDP。
- 首部检验和:占16位。只检验数据报首部,不检验数据部分。
- 源地址:占32位。表示发送方的IP地址。
- 目的地址:占32位。表示接收方的IP地址。
简述TCP/IP五层协议 ?
TCP/IP五层协议包括:物理层,数据链路层,网络层,运输层,应用层
物理层有什么作用 ?
主要解决两台物理机之间的通信,通过二进制比特流的传输来实现,二进制数据表现为电流电压上的强弱,到达目的地再转化为二进制机器码。网卡、集线器工作在这一层。
数据链路层有什么作用 ?
**在不可靠的物理介质上提供可靠的传输,接收来自物理层的位流形式的数据,并封装成帧,传送到上一层;**同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层。**这一层在物理层提供的比特流的基础上,通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路。**提供物理地址寻址功能。交换机工作在这一层。
网络层有什么作用 ?
将网络地址翻译成对应的物理地址,并决定如何将数据从发送方路由到接收方,通过路由选择算法为分组通过通信子网选择最佳路径。路由器工作在这一层。
传输层有什么作用 ?
传输层提供了进程间的逻辑通信,传输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看起来像是在两个传输层实体之间有一条端到端的逻辑通信信道。
会话层有什么作用 ?
**建立会话:身份验证,权限鉴定等;**保持会话:对该会话进行维护,在会话维持期间两者可以随时使用这条会话传输局;断开会话:当应用程序或应用层规定的超时时间到期后,OSI会话层才会释放这条会话。
表示层有什么作用 ?
对数据格式进行编译,对收到或发出的数据根据应用层的特征进行处理,如处理为文字、图片、音频、视频、文档等,还可以对压缩文件进行解压缩、对加密文件进行解密等。
应用层有什么作用 ?
提供应用层协议,如HTTP协议,FTP协议等等,方便应用程序之间进行通信。
TCP与UDP区别 ?
TCP作为面向流的协议,提供可靠的、面向连接的运输服务,并且提供点对点通信 UDP作为面向报文的协议,不提供可靠交付,并且不需要连接,不仅仅对点对点,也支持多播和广播 。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fx3H289r-1666488157638)(image-20220914102855862-16636424517972.png)]
TCP 用于在传输层有必要实现可靠传输的情况,UDP 用于对高速传输和实时性有较高要求的通信。TCP
和 UDP 应该根据应用目的按需使用。
TCP 协议如何保证可靠传输?
TCP有三次握手建立连接,四次挥手关闭连接的机制。除此之外还有滑动窗口和拥塞控制算法。最最关键的是还保留超时重传的机制。对于每份报文也存在校验,保证每份报文可靠性。
-
检验和:
通过检验和的方式,接收端可以检测出来数据是否有差错和异常,假如有差错就会直接丢
弃TCP段,重新发送。
-
序列号/确认应答:
序列号的作用不仅仅是应答的作用,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据。TCP传输的过程中,每次接收方收到数据后,都会对传输方进行确认应答。也就是发送ACK报文,这个ACK报文当中带有对应的确认序列号,告诉发送方,接收到了哪些数据,下一次的数据从哪里发。
-
滑动窗口:
滑动窗口既提高了报文传输的效率,也避免了发送方发送过多的数据而导致接收方无法正常处理的异常。
-
超时重传:
超时重传是指发送出去的数据包到接收到确认包之间的时间,如果超过了这个时间会被认为是丢包了,需要重传。最大超时时间是动态计算的。
-
拥塞控制:
在数据传输过程中,可能由于网络状态的问题,造成网络拥堵,此时引入拥塞控制机制,在保证TCP可靠性的同时,提高性能。
-
流量控制:
如果主机A 一直向主机B发送数据,不考虑主机B的接受能力,则可能导致主机B的接受缓冲区满了而无法再接受数据,从而会导致大量的数据丢包,引发重传机制。而在重传的过程中,若主机B的接收缓冲区情况仍未好转,则会将大量的时间浪费在重传数据上,降低传送数据的效率。所以引入流量控制机制,主机B通过告诉主机A自己接收缓冲区的大小,来使主机A控制发送的数据量。流量控制与TCP协议报头中的窗口大小有关。
为何UDP不可靠 ?
UDP面向数据报无连接的,数据报发出去,就不保留数据备份了。仅仅在IP数据报头部加入校验和复用。UDP没有服务器和客户端的概念。UDP报文过长的话是交给IP切成小段,如果某段报废报文就废了。
UDP 和 TCP 对应的应用场景是什么?
TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
- FTP文件传输
- HTTP / HTTPS
UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
- 包总量较少的通信,如 DNS 、SNMP等
- 视频、音频等多媒体通信
- 广播通信
简述TCP粘包现象 ?
TCP是面向流协议,发送的单位是字节流,因此会将多个小尺寸数据被封装在一个tcp报文中发出去的可能性。可以简单的理解成客户端调用了两次send,服务器端一个recv就把信息都读出来了。
TCP粘包现象处理方法 ?
固定发送信息长度,或在两个信息之间加入分隔符。
简述TCP协议的滑动窗口 ?
滑动窗口是传输层进行流量控制的一种措施,接收方通过通告发送方自己的窗口大小,从而控制发送方的发送速度,防止发送方发送速度过快而导致自己被淹没。
在进行数据传输时,如果传输的数据比较大,就需要拆分为多个数据包进行发送。TCP 协议需要对数据进行确认后,才可以发送下一个数据包。这样一来,就会在等待确认应答包环节浪费时间。为了避免这种情况TCP引入了窗口概念。窗口大小指的是不需要等待确认应答包而可以继续发送数据包的最大值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K7fJ57UR-1666488157638)(image-20220914104634239-16636424517973.png)]
可以看到滑动窗口左边的是已发送并且被确认的分组,滑动窗口右边是还没有轮到的分组。
滑动窗口里面也分为两块,一块是已经发送但是未被确认的分组,另一块是窗口内等待发送的分组。随着已发送的分组不断被确认,窗口内等待发送的分组也会不断被发送。整个窗口就会往右移动,让还没轮到的分组进入窗口内。
可以看到滑动窗口起到了一个限流的作用,也就是说当前滑动窗口的大小决定了当前 TCP 发送包的速率,而滑动窗口的大小取决于拥塞控制窗口和流量控制窗口的两者间的最小值。
简述TCP协议的拥塞控制
拥塞是指一个或者多个交换点的数据报超载,TCP又会有重传机制,导致过载。**为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量。**TCP 一共使用了四种算法来实现拥塞控制:
- 慢开始 (slow-start);
- 拥塞避免 (congestion avoidance);
- 快速重传 (fast retransmit);
- 快速恢复 (fast recovery)。
当cwnd(拥塞窗口) < ssthresh(门限值) 时,使用慢开始算法。当cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。当cwnd = ssthresh 时,即可使用慢开始算法,也可使用拥塞避免算法。
-
慢开始:
由小到大逐渐增加拥塞窗口的大小,每接一次报文,cwnd指数增加。
-
拥塞避免:
cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1。
-
快重传:
如果在超时重传定时器溢出之前,接收到连续的三个重复冗余ACK,发送端便知晓哪个报文段在传输过程中丢失了,于是重发该报文段,不需要等待超时重传定时器溢出再发送该报文。
-
快恢复之前的策略:
发送方判断网络出现拥塞,就把ssthresh设置为出现拥塞时发送方窗口值的一半,继续执行慢开始,之后进行拥塞避免。
-
快恢复:
主要是配合快重传。当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半(为了预防网络发生拥塞),但接下来并不执行慢开始算法,因为如果网络出现拥塞的话就不会收到好几个重复的确认,收到三个重复确认说明网络状况还可以。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-riegBGw0-1666488157639)(image-20220914105715573-16636424517974.png)]
TCP三次握手过程(详细版&简单版)?
回答1:
- 第一次握手:客户端将标志位SYN置为1,随机产生一个值序列号seq=x,并将该数据包发送给服务端,客户端 进入syn_sent状态,等待服务端确认。
- 第二次握手:服务端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务端将标志位SYN和 ACK都置为1,ack=x+1,随机产生一个值seq=y,并将该数据包发送给客户端以确认连接请求,服务端进入syn_rcvd状态。
- 第三次握手:客户端收到确认后检查,如果正确则将标志位ACK为1,ack=y+1,并将该数据包发送给服务端,服务端进行检查如果正确则连接建立成功,客户端和服务端进入established状态,完成三次握手,随后客户端和服务端之间可以开始传输数据了
回答2:
- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aM4nntpP-1666488157639)(%E4%B8%89%E6%AC%A1%E6%8F%A1%E6%89%8B2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6dqc7cCm-1666488157639)(%E4%B8%89%E6%AC%A1%E6%8F%A1%E6%89%8B.png)]
为什么TCP握手需要三次,两次行不行?
回答1:
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
- 第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
- 第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
- 第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
所以三次握手就能确认双发收发功能都正常,缺一不可。
回答2:
不行。TCP进行可靠传输的关键就在于维护一个序列号,三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值。 如果只是两次握手, 至多只有客户端的起始序列号能被确认, 服务器端的序列号则得不到确认。
主要有三个原因:
- **防止已过期的连接请求报文突然又传送到服务器,因而产生错误和资源浪费。**在双方两次握手即可建立连接的情况下,假设客户端发送 A 报文段请求建立连接,由于网络原因造成 A 暂时无法到达服务器,服务器接收不到请求报文段就不会返回确认报文段。客户端在长时间得不到应答的情况下重新发送请求报文段 B,这次 B 顺利到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,客户端在收到 确认报文后也进入 ESTABLISHED 状态,双方建立连接并传输数据,之后正常断开连接。此时姗姗来迟的 A 报文段才到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,但是已经进入 CLOSED 状态的客户端无法再接受确认报文段,更无法进入 ESTABLISHED 状态,这将导致服务器长时间单方面等待,造成资源浪费。
- **三次握手才能让双方均确认自己和对方的发送和接收能力都正常。**第一次握手:客户端只是发送处请求报文段,什么都无法确认,而服务器可以确认自己的接收能力和对方的发送能力正常;第二次握手:客户端可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;第三次握手:服务器可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;可见三次握手才能让双方都确认自己和对方的发送和接收能力全部正常,这样就可以愉快地进行通信了。
- **告知对方自己的初始序号值,并确认收到对方的初始序号值。**TCP 实现了可靠的数据传输,原因之一就是 TCP 报文段中维护了序号字段和确认序号字段,通过这两个字段双方都可以知道在自己发出的数据中,哪些是已经被对方确认接收的。这两个字段的值会在初始序号值得基础递增,如果是两次握手,只有发起方的初始序号可以得到确认,而另一方的初始序号则得不到确认。
为什么要传回 SYN?
接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
传了 SYN,为啥还要传 ACK?
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
简述半连接队列 ?
TCP握手中,当服务器处于SYN_RCVD 状态,服务器会把此种状态下请求连接放在一个队列里,该队列称为半连接队列。
简述SYN泛洪攻击 ?
SYN攻击即利用TCP协议缺陷,通过发送大量的半连接请求,占用半连接队列,耗费CPU和内存资源。
解决方法:
-
记录IP,若连续受到某个IP的重复SYN报文,从这个IP地址来的包会被一概丢弃。
-
通过防火墙、路由器等过滤网关防护。
-
通过加固 TCP/IP 协议栈防范,如增加最大半连接数,缩短超时时间(缩短SYN Timeout时间 )。
-
SYN cookies技术。SYN Cookies 是对 TCP 服务器端的三次握手做一些修改,专门用来防范 SYN
洪泛攻击的一种手段
TCP四次挥手过程 (详细版&简单版)?
回答1:
- 第一次挥手:客户端发送一个FIN,用来关闭客户端到服务端的数据传送,客户端进入fin_wait_1状态。
- 第二次挥手:服务端收到FIN后,发送一个ACK给客户端,确认序号为收到序号+1,服务端进入Close_wait状态。此时TCP连接处于半关闭状态,即客户端已经没有要发送的数据了,但服务端若发送数据,则客户端仍要接收。
- 第三次挥手:服务端发送一个FIN,用来关闭服务端到客户端的数据传送,服务端进入Last_ack状态。
- 第四次挥手:客户端收到FIN后,客户端进入Time_wait状态,接着发送一个ACK给服务端,确认后,服务端进入Closed状态,完成四次挥手。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gJMkrHCc-1666488157640)(image-20220919101333184.png)]
回答2:
断开一个 TCP 连接则需要“四次挥手”:
- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送;
- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加1 。和 SYN 一样,一个 FIN 将占用一个序号;
- 服务器-关闭与客户端的连接,发送一个FIN给客户端;
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PK3OCIte-1666488157640)(TCP%E5%9B%9B%E6%AC%A1%E6%8C%A5%E6%89%8B.png)]
为什么TCP挥手需要4次 ?
主要原因是当服务端收到客户端的 FIN 数据包后,服务端可能还有数据没发完,不会立即close。 所以服务端会先将 ACK 发过去告诉客户端我收到你的断开请求了,但请再给我一点时间,这段时间用来发送剩下的数据报文,发完之后再将 FIN 包发给客户端表示现在可以断了。之后客户端需要收到 FIN 包后发送 ACK 确认断开信息给服务端。
为什么四次挥手释放连接时需要等待2MSL ?
MSL即报文最大生存时间。设置2MSL可以保证上一次连接的报文已经在网络中消失,不会出现与新TCP连接报文冲突的情况。
打开一个网页的过程(显示主页的过程)?
回答1:
总体来说分为以下几个过程:
- DNS解析
- TCP连接
- 发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析渲染页面
- 连接结束
参考链接:https://segmentfault.com/a/1190000006879700
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mWxX4bKO-1666488157641)(url%E8%BE%93%E5%85%A5%E5%88%B0%E5%B1%95%E7%A4%BA%E5%87%BA%E6%9D%A5%E7%9A%84%E8%BF%87%E7%A8%8B.jpg)]
回答2:
- 域名解析(域名 www.baidu.com 变为 ip 地址)。
- 浏览器搜索自己的DNS缓存(维护一张域名与IP的对应表);若没有,则搜索操作系统的DNS缓存(维护一张域名与IP的对应表);若没有,则搜索操作系统的hosts文件(维护一张域名与IP的对应表)。
- 若都没有,则找 tcp/ip 参数中设置的首选 dns 服务器,即本地 dns 服务器(递归查询),本地 域名服务器查询自己的dns缓存,如果没有,则进行迭代查询。将本地dns服务器将IP返回给操作系统,同时缓存IP。
- 发起 tcp 的三次握手,建立 tcp 连接。浏览器会以一个随机端口(1024-65535)向服务端的 web程序 80 端口发起 tcp 的连接。
- 建立 tcp 连接后发起 http 请求。
- 服务器响应 http 请求,客户端得到 html 代码。服务器 web 应用程序收到 http 请求后,就开始处理请求,处理之后就返回给浏览器 html 文件。
- 浏览器解析 html 代码,并请求 html 中的资源。
- 浏览器对页面进行渲染,并呈现给用户。
简述DNS协议 ?
DNS协议是基于UDP的应用层协议,它的功能是根据用户输入的域名,解析出该域名对应的IP地址,从而给客户端进行访问。
简述DNS解析过程 ?
-
客户机发出查询请求,在本地计算机缓存查找,若没有找到,就会将请求发送给dns服务器
-
本地dns服务器会在自己的区域里面查找,找到即根据此记录进行解析,若没有找到,就会在本地的缓存里面查找
-
本地服务器没有找到客户机查询的信息,就会将此请求发送到根域名dns服务器
-
根域名服务器解析客户机请求的根域部分,它把包含的下一级的dns服务器的地址返回到客户机的dns服务器地址
-
客户机的dns服务器根据返回的信息接着访问下一级的dns服务器
-
这样递归的方法一级一级接近查询的目标,最后在有目标域名的服务器上面得到相应的IP信息
-
客户机的本地的dns服务器会将查询结果返回给我们的客户机
-
客户机根据得到的ip信息访问目标主机,完成解析过程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3oxKzaNI-1666488157641)(view.png)]
简述HTTP协议
http协议是超文本传输协议。它是基于TCP协议的应用层传输协议,即客户端和服务端进行数据传输的一种规则。该协议本身HTTP 是一种无状态的协议。
各种协议与HTTP协议之间的关系.?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mJx83MgR-1666488157642)(%E5%90%84%E7%A7%8D%E5%8D%8F%E8%AE%AE%E4%B8%8EHTTP%E5%8D%8F%E8%AE%AE%E4%B9%8B%E9%97%B4%E7%9A%84%E5%85%B3%E7%B3%BB.png)]
简述cookie ?
HTTP 协议本身是无状态的,为了使其能处理更加复杂的逻辑,HTTP1.1 引入 Cookie 来保存状态信息。
Cookie是由服务端产生的,再发送给客户端保存,当客户端再次访问的时候,服务器可根据cookie辨识客户端是哪个,以此可以做个性化推送,免账号密码登录等等。
HTTP Cookie(也叫 Web Cookie或浏览器 Cookie)是**服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。**通常,**它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。**Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。Cookie 主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
简述session ?
session用于标记特定客户端信息,存在在服务器的一个文件里。一般客户端带Cookie对服务器进行访问,可通过cookie中的session id从整个session中查询到服务器记录的关于客户端的信息。
**Session 代表着服务器和客户端一次会话的过程。Session 对象存储特定用户会话所需的属性及配置信息。**这样,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当客户端关闭会话,或者 Session 超时失效时会话结束。
Cookie 和 Session 是如何配合的呢?
**用户第一次请求服务器的时候,服务器根据用户提交的相关信息,创建对应的 Session ,请求返回时将此 Session 的唯一标识信息 SessionID 返回给浏览器,浏览器接收到服务器返回的 SessionID 信息后,会将此信息存入到 Cookie 中,同时 Cookie 记录此 SessionID 属于哪个域名。**当用户第二次访问服务器的时候,请求会自动判断此域名下是否存在 Cookie 信息,如果存在自动将Cookie 信息也发送给服务端,服务端会从 Cookie 中获取 SessionID,再根据 SessionID 查找对应的Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到 Session 证明用户已经登录可执行后面操作。
根据以上流程可知,SessionID 是连接 Cookie 和 Session 的一道桥梁,大部分系统也是根据此原理来验证用户登录状态。
Cookie和Session的区别?
- 作用范围不同,Cookie 保存在客户端(浏览器),Session 保存在服务器端。
- 存取方式的不同,Cookie 只能保存 ASCII,Session 可以存任意数据类型,一般情况下我们可以在Session 中保持一些常用变量信息,比如说 UserId 等。
- 有效期不同,Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭或者 Session 超时都会失效。
- 隐私策略不同,Cookie 存储在客户端,比较容易遭到不法获取,早期有人将用户的登录名和密码存储在 Cookie 中导致信息被窃取;Session 存储在服务端,安全性相对 Cookie 要好一些。
- 存储大小不同, 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie。
什么是DDos攻击?
DDos全称Distributed Denial of Service,分布式拒绝服务攻击。最基本的DOS攻击过程如下:
- 客户端向服务端发送请求链接数据包。
- 服务端向客户端发送确认数据包。
- 客户端不向服务端发送确认数据包,服务器一直等待来自客户端的确认
DDoS则是采用分布式的方法,通过在网络上占领多台“肉鸡”,用多台计算机发起攻击。
DOS攻击现在基本没啥作用了,因为服务器的性能都很好,而且是多台服务器共同作用,1V1的模式黑
客无法占上风。对于DDOS攻击,预防方法有:
- 减少SYN timeout时间。在握手的第三步,服务器会等待30秒-120秒的时间,减少这个等待时间就能释放更多的资源。
- 限制同时打开的SYN半连接数目。
什么是XSS攻击?
XSS也称 cross-site scripting,跨站脚本。这种攻击是由于服务器将攻击者存储的数据原原本本地显示给其他用户所致的。比如一个存在XSS漏洞的论坛,用户发帖时就可以引入带有<script>标签的 代码,导致恶意代码的执行。预防措施有:
- 前端:过滤。
- 后端:转义,比如go自带的处理器就具有转义功能。
SQL注入是什么?如何避免SQL注入?
SQL 注入就是在用户输入的字符串中加入 SQL 语句,如果在设计不良的程序中忽略了检查,那么这些注入进去的 SQL 语句就会被数据库服务器误认为是正常的 SQL 语句而运行,攻击者就可以执行计划外的命令或访问未被授权的数据。 SQL注入的原理主要有以下 4 点:
- 恶意拼接查询
- 利用注释执行非法命令
- 传入非法参数
- 添加额外条件
避免SQL注入的一些方法:
- 限制数据库权限,给用户提供仅仅能够满足其工作的最低权限。
- 对进入数据库的特殊字符(’”\尖括号&*;等)转义处理。
- 提供参数化查询接口,不要直接使用原生SQL。
负载均衡算法有哪些?
多台服务器以对称的方式组成一个服务器集合,每台服务器都具有等价的地位,能互相分担负载。
-
轮询法:将请求按照顺序轮流的分配到服务器上。大锅饭,不能发挥某些高性能服务器的优势。
-
随机法:随机获取一台,和轮询类似。
-
哈希法:通过ip地址哈希化来确定要选择的服务器编号。好处是,每次客户端访问的服务器都是同一
个服务器,能很好地利用session或者cookie。
-
加权轮询:根据服务器性能不同加权。
HTTP常见的状态码有哪些?
常见状态码:
- 200:服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
- 301 : (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
- 302:(临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 400 :客户端请求有语法错误,不能被服务器所理解。
- 403 :服务器收到请求,但是拒绝提供服务。
- 404 :(未找到) 服务器找不到请求的网页。
- 500: (服务器内部错误) 服务器遇到错误,无法完成请求。
状态码301和302的区别是什么?
共同点:301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取(用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)。
不同点:****301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。 SEO中302好于301。
补充,重定向原因:
- 网站调整(如改变网页目录结构);
- 网页被移到一个新地址;
- 网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
转发和重定向的区别 ?
转发是服务器行为。服务器直接向目标地址访问URL,将相应内容读取之后发给浏览器,用户浏览器地址栏URL不变,转发页面和转发到的页面可以共享request里面的数据。
重定向是利用服务器返回的状态码来实现的,如果服务器返回301或者302,浏览器收到新的消息后自动跳转到新的网址重新请求资源。用户的地址栏url会发生改变,而且不能共享数据。
简述http1.0 ?
-
规定了请求头和请求尾,响应头和响应尾(get post)
-
每一个请求都是一个单独的连接,做不到连接的复用
简述http1.1的改进 ?
-
HTTP1.1默认开启长连接,**在一个TCP连接上可以传送多个HTTP请求和响应。**使用 TCP 长连接的方式改善了 HTTP1.0 短连接造成的性能开销。
-
支持管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
-
服务端无法主动push
HTTP1.0和HTTP1.1的区别**?**
- **长连接:HTTP 1.1支持长连接(Persistent Connection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启 Connection: keep-alive , 一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
- **缓存处理:**在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略,可供选择的缓存头来控制缓存策略。
- 带宽优化及网络连接的使用: HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 错误通知的管理: 在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
- Host头处理: 在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。 HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
简述HTTP短连接与长连接区别 ?
HTTP中的长连接短连接指HTTP底层TCP的连接。
-
短连接:客户端与服务器进行一次HTTP连接操作,就进行一次TCP连接,连接结束TCP关闭连接。
-
长连接:如果HTTP头部带有参数keep-alive,即开启长连接网页完成打开后,底层用于传输数据的TCP连接不会直接关闭,会根据服务器设置的保持时间保持连接,保持时间过后连接关闭。
HTTP请求报文和响应报文的格式?
请求报文格式:
- 请求行(请求方法+URI协议+版本)
- 请求头部
- 空行
- 请求主体
GET/sample.jspHTTP/1.1 请求行
Accept:image/gif.image/jpeg, 请求头部
Accept-Language:zh-cn
Connection:Keep-Alive Host:localhost
User-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)
Accept-Encoding:gzip,deflate
username=jinqiao&password=1234 请求主体
响应报文:
- 状态行(版本+状态码+原因短语)
- 响应首部
- 空行
- 响应主体
HTTP/1.1 200 OK
Server:Apache Tomcat/5.0.12
Date:Mon,6Oct2003 13:23:42 GMT
Content-Length:112
<html>
<head>
<title>HTTP响应示例<title>
head>
<body>Hello HTTP!
body>
html>
简述http2.0的改进
-
**提出多路复用。**多路复用前,文件时串行传输的,请求a文件,b文件只能等待,并且连接数过多。引入多路复用,a文件b文件可以同时传输。
-
**引入了二进制数据帧。**其中帧对数据进行顺序标识,有了序列id,服务器就可以进行并行传输数据。
HTTP1.1和 HTTP2.0的区别?
HTTP2.0相比HTTP1.1支持的特性:
- 新的二进制格式: HTTP1.1的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
- 多路复用:即连接共享,即每一个request都是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
- 头部压缩: HTTP1.1的头部(header)带有大量信息,而且每次都要重复发送;HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- 服务端推送: 服务器除了对最初请求的响应外,服务器还可以额外的向客户端推送资源,而无需
客户端明确的请求。
http与https的区别
- http所有传输的内容都是明文,并且客户端和服务器端都无法验证对方的身份。
- https具有安全性的ssl加密传输协议,加密采用对称加密, https协议需要到ca申请证书,一般免费证书很少,需要交费。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G7LZuof4-1666488157643)(image-20220919152210376.png)]
HTTPS 的优缺点**?**
优点:
- 安全性:
- 使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
- HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
- HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
- SEO方面:谷歌曾在2014年8月份调整搜索引擎算法,并称“比起同等HTTP网站,采用HTTPS加密的网站在搜索结果中的排名将会更高”。
缺点:
- 在相同网络环境中,HTTPS 相比 HTTP 无论是响应时间还是耗电量都有大幅度上升。
- HTTPS 的安全是有范围的,在黑客攻击、服务器劫持等情况下几乎起不到作用。
- 在现有的证书机制下,中间人攻击依然有可能发生。
- HTTPS 需要更多的服务器资源,也会导致成本的升高。
简述TLS/SSL, HTTP, HTTPS的关系 ?
-
SSL全称为Secure Sockets Layer即安全套接层,其继任为TLSTransport Layer Security传输层安全协议,均用于在传输层为数据通讯提供安全支持。
-
可以将HTTPS协议简单理解为HTTP协议+TLS/SSL
https的连接过程 ?
- 浏览器将支持的加密算法信息发给服务器
- 服务器选择一套浏览器支持的加密算法,以证书的形式回发给浏览器
- 客户端(SSL/TLS)解析证书验证证书合法性,生成对称加密的密钥,我们将该密钥称之为client key,即客户端密钥,用服务器的公钥对客户端密钥进行非对称加密。
- 客户端会发起HTTPS中的第二个HTTP请求,将加密之后的客户端对称密钥发送给服务器
- 服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后的明文就是客户端密钥,然后用客户端密钥对数据进行对称加密,这样数据就变成了密文。
- 服务器将加密后的密文发送给客户端
- 客户端收到服务器发送来的密文,用客户端密钥对其进行对称解密,得到服务器发送的数据。这样HTTPS中的第二个HTTP请求结束,整个HTTPS传输完成
HTTP 常用的请求方式?
为了方便记忆,可以将PUT、DELETE、POST、GET理解为客户端对服务端的增删改查。
- PUT:上传文件,向服务器添加数据,可以看作增
- DELETE:删除文件
- POST:传输数据,向服务器提交数据,对服务器数据进行更新。
- GET:获取资源,查询服务器资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BR0qXMMp-1666488157643)(image-20220919155651862.png)]
Get与Post区别 ?
-
Get:指定资源请求数据,刷新无害,Get请求的数据会附加到URL中,传输数据的大小受到url的限制。
-
Post:向指定资源提交要被处理的数据。刷新会使数据会被重复提交。post在发送数据前会先将请求头发送给服务器进行确认,然后才真正发送数据。
Get方法参数有大小限制吗 ?
一般HTTP协议里并不限制参数大小限制。但一般由于get请求是直接附加到地址栏里面的,由于浏览器地址栏有长度限制,因此使GET请求在浏览器实现层面上看会有长度限制。
了解REST API吗 ?
REST API全称为表述性状态转移(Representational State Transfer,REST)即利用HTTP中get、post、put、delete以及其他的HTTP方法构成REST中数据资源的增删改查操作:
- Create :POST
- Read :GET
- Update :PUT/PATCH
- Delete:DELETE
http请求包含了什么 ?
包含:请求方法字段、URL字段、HTTP协议版本
产生请求的浏览器类型,请求数据,主机地址。
Put与Delete区别 ?
- Put规定默认为更新某一资源,和Post一样,一般该操作会对服务器资源进行改变
- Delete规定默认为删除某一资源,和Post一样,一般该操作会对服务器资源进行改变
简述DNS劫持
DNS是指将网页域名翻译为对应的IP的一种方法。DNS劫持指攻击者篡改结果,使用户对域名的解析IP变成了另一个IP。
操作系统
什么是操作系统?
我通过以下四点向您介绍一下什么是操作系统吧!
- 操作系统(Operating System,简称 OS)是管理计算机硬件与软件资源的程序,是计算机的基石。
- 操作系统本质上是一个运行在计算机上的软件程序 ,用于管理计算机硬件和软件资源。 举例:运行在你电脑上的所有应用程序都通过操作系统来调用系统内存以及磁盘等等硬件。
- 操作系统存在屏蔽了硬件层的复杂性。 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
- 操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。 内核是连接应用程序和硬件的桥梁,决定着系统的性能和稳定性。
什么是系统调用呢?
介绍系统调用之前,我们先来了解一下用户态和系统态。
根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
- 用户态(user mode) : 用户态运行的进程可以直接读取用户程序的数据。
- 系统态(kernel mode):可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。
说了用户态和系统态之后,那么什么是系统调用呢?
我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的系统态级别的子功能咋办呢?那就需要系统调用了!
也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
这些系统调用按功能大致可分为如下几类:
- 设备管理。完成设备的请求或释放,以及设备启动等功能。
- 文件管理。完成文件的读、写、创建及删除等功能。
- 进程控制。完成进程的创建、撤销、阻塞及唤醒等功能。
- 进程通信。完成进程之间的消息传递或信号传递等功能。
- 内存管理。完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
操作系统的特征
操作系统的基本特征包括并发、共享、虚拟和异步。这些概念对理解和堂握操作系统的核心至关重要,将一直贯穿于各个章节中。
1.并发(Concurrence)
并发是指两个或多个事件在同一时间间隔(时间段)内发生。操作系统的并发性是指计算机系统中同时在在多个运行的程序,因此它且有处理和调度多个程序同时执行的能力。在操作系统中,引入进程的目的就是使程序能并发地执行。
注意同一时间间隔(并发)和同一时刻(并行)的区别:
并发:关注的是同一时间间隔——即时间段内发生的事件数量,比如午餐时段内,学校餐厅共接纳了2000名同学用餐,那么,该餐厅在午餐时段的并发量就是2000。
并行:并行性是指系统具有同时进行运算或操作的特性,在同一时刻能完成两种或两种以上的工作。比如说,学校餐厅有四个出餐口,那么该餐厅的并行数为4,即同一时间点最多能同时为四名同学打餐。
并行性需要有相关硬件的支持,如多流水线或多处理机硬件环境。并发性体现系统在某段时间内的工作效率,并行性体现该系统“三心二意”的能力。
在多道程序环境下,一段时间内,宏观上有多道程序在同时执行,而在每个时刻,实际仅有一道程序执行(单处理机环境下),因此微观上这些程序仍是分时交替执行的。操作系统的并发性通过分时得以实现。
2.共享(Sharing)
共享即资源共享,是指系统中的资源可供内存中多个并发执行的进程共同使用。共享可分为以下两种资源共享方式。
(1)互斥共享方式
系统中的某些资源,如打印机、磁带机,虽然可供多个进程伸用,但为使得所打印或记录的结果不致造成混淆,应规定在一段时间内只允许一个进程访问该资源。为此,当进程A访问某个资源时,必须先提出请求,若此时该资源空闲,则系统便将之分配给进程A使用,此后有其它进程也要访问该资源时,只要A未用完,其它进程就必须等待。仅当进程A访问完并释放该资源后,才允许另一个进程对该资源进行访问。我们把这种资源共享方式称为互斥式共享,而把在一段时间内只允许一个进程访问的资源称为临界资源或独占资源,计算机系统中的大多数物理设各及其此软件中所用的栈,变最和表格,都是于临界咨源,它们都被要求互斥地进行享。
(2)同时访问方式
系统中还有另一类资源,这类资源允许在一段时间内由多个进程“同时”访问(这里所说的“同时”通常是宏观上的,而在微观上,这些进程可能是交替地对该资源进行访问即“分时共享的)。可供多个进程“同时”访问的典型资源是磁盘设备。
注意,互斥共享要求一种资源在一段时间内(哪怕是一段很小的时间)只能满足一个请求,否则就会出现数据的错乱,比如多个进程同时访问打印机,打印的内容交错地出现在不同的文件上,那太糟糕了!同时访问共享通常要求一个请求分几个时间片段间隔地完成,其效果与连续完成的效果相同。
并发和共享是操作系统两个最基本的特征,两者互为存在条件:
①资源共享是以程序的并发为条件的,若系统不允许程序并发执行,则自然不存在资源共享问题;
②若系统不能对资源共享实施有效的管理,则必将影响到程序的并发执行,甚至根本无法并发执行。
3.虚拟(Virtual)
虚拟是指把一个物理上的实体变为若干逻辑上的对应物。物理实体(前者)是实际存在的,而后者是虚的,是用户“感觉上”的现象。用于实现虚拟的技术,称为虚拟技术。操作系统中利用了多种虚拟技术来实现虚拟处理器、虚拟内存和虚拟外部设备等。
虚拟处理器技术:通过多道程序设计技术,采用让多道程序并发执行的方法,来分时使用一个处理器。此时,虽然只有一个处理器,但它能同时为多个用户服务,使每个终端用户都感觉有一个中央外理器(CPU)在专门为它服务。利用多道程序设计技术把一个物理上的CPU虚拟为多个逻辑上的CPU,称为虚拟处理器。
虚拟存储器技术:将一台机器的物理存储器变为虚拟存储器,以便从逻辑上扩充存储器的容量。当然,这时用户所感觉到的内存容量是虚的。我们把用户感觉到(但实际不存在)的存储器称为虚拟存储器。
虚拟设备技术:将一台物理Ⅰ/O设备虚拟为多台逻辑上的Ⅰ/O设备,并允许每个用户占用一台逻辑上的/设备,使原来仅允许在一段时间内由一个用户访问的设备(即临界资源)变为在一段时间内允许多个用户同时访问的共享设备。
操作系统的虚拟技术可归纳为两类:
- 时分复用技术(TDM,Time Division Multiplexing):如处理器的分时共享;
- 空分复用技术(SDM,Space Division Multiplexing):如虚拟存储器。
4.异步(Asynchronism)
多道程序环境下,允许多个程序并发执行,但由于资源有限,进程的执行并不是一贯到底的,而是走走停停的,它以不可预知的速度向前推进,这就是进程的异步性。
异步性使得操作系统运行在一种随机的环境下,可能导致进程产生与时间有关的错误(就像对全局变量的访问顺序不当会导致程序出错一样)。然而,只要运行环境相同,操作系统就须保证多次运行进程后都能获得相同的结果。
什么是进程?
进程的结构
- 控制块(PCB)
- 数据段
- 程序段
进程和线程的区别?
- 调度:进程是资源管理的基本单位,线程是程序执行的基本单位。
- 切换:线程上下文切换比进程上下文切换要快得多。
- 拥有资源: 进程是拥有资源的一个独立单位,线程不拥有系统资源,但是可以访问隶属于进程的资源。
- 系统开销: 创建或撤销进程时,系统都要为之分配或回收系统资源,如内存空间,I/O设备等,OS所付出的开销显著大于在创建或撤销线程时的开销,进程切换的开销也远大于线程切换的开销。
进程的状态?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W7kcm1KZ-1666488157644)(image-20220920111514292.png)]
- 运行状态就是进程正在 CPU 上运行。在单处理机环境下,每一时刻最多只有一个进程处于运行状态。
- 就绪状态就是说进程已处于准备运行的状态,即进程获得了除 CPU 之外的一切所需资源,一旦得到 CPU 即可运行。
- 阻塞状态就是进程正在等待某一事件而暂停运行,比如等待某资源为可用或等待 I/O 完成。即使CPU 空闲,该进程也不能运行
运行态→阻塞态:往往是由于等待外设,等待主存等资源分配或等待人工干预而引起的。
阻塞态→就绪态:则是等待的条件已满足,只需分配到处理器后就能运行。
运行态→就绪态:不是由于自身原因,而是由外界原因使运行状态的进程让出处理器,这时候就变成就绪态。例如时间片用完,或有更高优先级的进程来抢占处理器等。
就绪态→运行态:系统按某种策略选中就绪队列中的一个进程占用处理器,此时就变成了运行态。
进程是怎么运行的?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-31gKfppi-1666488157644)(image-20220920111919200.png)]
进程控制:挂起与激活
为了系统和用户观察和分析进程
挂起原语: suspend
- 静止就绪:放外存,不调度
- 静止阻塞:等待事件
激活原语:active
- 活动就绪:等待调度
- 活动阻塞:等待唤醒
什么是原语?
- 原语的概念:
- 由若干条指令组成,完成特定的功能,是一种原子操作(Action Operation)
- 原语的特点:
- 原子操作,要么全做,要么全不做,执行过程不会被中断
- 在管态/系统态/内核态下执行,常驻内存
- 是内核三大支撑功能(中断处理/时钟管理/原语操作)之一
协程与线程的区别?
- 线程和进程都是同步机制,而协程是异步机制。
- 线程是抢占式,而协程是非抢占式的。需要用户释放使用权切换到其他协程,因此同一时间其实只有一个协程拥有运行权,相当于单线程的能力。
- 一个线程可以有多个协程,一个进程也可以有多个协程。
- 协程不被操作系统内核管理,而完全是由程序控制。线程是被分割的CPU资源,协程是组织好的代码流程,线程是协程的资源。但协程不会直接使用线程,协程直接利用的是执行器关联任意线程或线程池。
- 协程能保留上一次调用时的状态。
并发和并行有什么区别?
- 并发就是在一段时间内,多个任务都会被处理;但在某一时刻,只有一个任务在执行。 **单核处理器可以做到并发。**比如有两个进程 A 和 B , A 运行一个时间片之后,切换到 B , B 运行一个时间片之后又切换到 A 。因为切换速度足够快,所以宏观上表现为在一段时间内能同时运行多个程序。
- 并行就是在同一时刻,有多个任务在执行。这个需要多核处理器才能完成,在微观上就能同时执行多条指令,不同的程序被放到不同的处理器上运行,这个是物理上的多个进程同时进行。
进程与线程的切换流程?
进程切换分两步:
-
切换页表以使用新的地址空间,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作
废了。
-
切换内核栈和硬件上下文。
对于linux来说,线程和进程的最大区别就在于地址空间,
对于线程切换,第1步是不需要做的,第2步是进程和线程切换都要做的。因为每个进程都有自己的虚拟地址空间,而线程是共享所在进程的虚拟地址空间的,因此同一个进程中的线程进行线程切换时不涉及虚拟地址空间的转换。
为什么虚拟地址空间切换会比较耗时?
进程都有自己的虚拟地址空间,把虚拟地址转换为物理地址需要查找页表,页表查找是一个很慢的过程,因此通常使用Cache来缓存常用的地址映射,这样可以加速页表查找,这个Cache就是TLB(translation Lookaside Buffer,TLB本质上就是一个Cache,是用来加速页表查找的)。
由于每个进程都有自己的虚拟地址空间,那么显然每个进程都有自己的页表,那么当进程切换后页表 也要进行切换,页表切换后TLB就失效了,Cache失效导致命中率降低,那么虚拟地址转换为物理地址就会变慢,表现出来的就是程序运行会变慢,而线程切换则不会导致TLB失效,因为线程无需切换地址空间,因此我们通常说线程切换要比较进程切换块,原因就在这里。
进程间通信方式有哪些?
管道:管道这种通讯方式有两种限制,一是半双工的通信,数据只能单向流动,二是只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。管道可以分为两类:匿名管道和命名管道。匿名管道是单向的,只能在有亲缘关系的进程间通信;命名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
信号 : 信号是一种比较复杂的通信方式,信号可以在任何时候发给某一进程,而无需知道该进程的状态。
Linux系统中常用信号:
(1)SIGHUP:用户从终端注销,所有已启动进程都将收到该进程。系统缺省状态下对该信号的处理是终止进程。
(2)SIGINT:程序终止信号。程序运行过程中,按 Ctrl+C 键将产生该信号。
(3)SIGQUIT:程序退出信号。程序运行过程中,按 Ctrl+\ \键将产生该信号。
(4)SIGBUS和SIGSEGV:进程访问非法地址。
(5)SIGFPE:运算中出现致命错误,如除零操作、数据溢出等。
(6)SIGKILL:用户终止进程执行信号。shell下执行 kill -9 发送该信号。
(7)SIGTERM:结束进程信号。shell下执行 kill 进程pid 发送该信号。
(8)SIGALRM:定时器信号。
(9)SIGCLD:子进程退出信号。如果其父进程没有忽略该信号也没有处理该信号,则子进程退出后将形成僵尸进程。
信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列:消息队列是消息的链接表,包括Posix消息队列和System V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
Socket:与其他通信机制不同的是,它可用于不同机器间的进程通信。
进程间同步的方式有哪些?
回答1:
- 临界区:当多个线程访问一个独占性共享资源时,可以使用临界区对象。拥有临界区的线程可以访问被保护起来的资源或代码段,其他线程若想访问,则被挂起,直到拥有临界区的线程放弃临界区为止,以此达到用原子方式操作共享资源的目的。
- 事件:事件机制,则允许一个线程在处理完一个任务后,主动唤醒另外一个线程执行任务。
- 互斥量:互斥对象和临界区对象非常相似,只是其允许在进程间使用,而临界区只限制与同一进程的各个线程之间使用,但是更节省资源,更有效率。
- 信号量:当需要一个计数器来限制可以使用某共享资源的线程数目时,可以使用“信号量”对象。
区别:
- 互斥量与临界区的作用非常相似,但互斥量是可以命名的,也就是说互斥量可以跨越进程使用,但创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量 。因为互斥量是跨进程的互斥量一旦被创建,就可以通过名字打开它。
- 互斥量,信号量,事件都可以被跨越进程使用来进行同步数据操作。
回答2:
临界区:通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
- 优点:保证在某一时刻只有一个线程能访问数据的简便办法。
- 缺点:虽然临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程。
互斥量:为协调共同对一个共享资源的单独访问而设计的。互斥量跟临界区很相似,比临界区复杂,互斥对象只有一个,只有拥有互斥对象的线程才具有访问资源的权限。
- 优点:使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享。
- 缺点:互斥量是可以命名的,也就是说它可以跨越进程使用,所以创建互斥量需要的资源更多,所以如果只为了在进程内部是用的话使用临界区会带来速度上的优势并能够减少资源占用量。
- 通过互斥量可以指定资源被独占的方式使用,但如果有下面一种情况通过互斥量就无法处理,比如现在一位用户购买了一份三个并发访问许可的数据库系统,可以根据用户购买的访问许可数量来决定有多少个线程/进程能同时进行数据库操作,这时候如果利用互斥量就没有办法完成这个要求,信号量对象可以说是一种资源计数器。
信号量:为控制一个具有有限数量用户资源而设计。它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。互斥量是信号量的一种特殊情况,当信号量的最大资源数=1就是互斥量了。
- 优点:适用于对Socket(套接字)程序中线程的同步。
- 缺点:
- 信号量机制必须有公共内存,不能用于分布式操作系统,这是它最大的弱点;
- 信号量机制功能强大,但使用时对信号量的操作分散, 而且难以控制,读写和维护都很困难,加重了程序员的编码负担;
- 核心操作P-V分散在各用户程序的代码中,不易控制和管理,一旦错误,后果严重,且不易发现和纠正。
事件: 用来通知线程有一些事件已发生,从而启动后继任务的开始。
- 优点:事件对象通过通知操作的方式来保持线程的同步,并且可以实现不同进程中的线程同步操作。
什么是临界区,如何解决冲突?
每个进程中访问临界资源的那段程序称为临界区,一次仅允许一个进程使用的资源称为临界资源。
解决冲突的办法:
- 如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入,如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待;
- 进入临界区的进程要在有限时间内退出。
- 如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
线程的分类?
从线程的运行空间来说,分为用户级线程(user-level thread, ULT)和内核级线程(kernel-level,KLT)
- 内核级线程:这类线程依赖于内核,又称为内核支持的线程或轻量级进程。无论是在用户程序中的线程还是系统进程中的线程,它们的创建、撤销和切换都由内核实现。比如英特尔i5-8250U是4核8线程,这里的线程就是内核级线程
- 用户级线程:它仅存在于用户级中,这种线程是不依赖于操作系统核心的。应用进程利用线程库来完成其创建和管理,速度比较快,操作系统内核无法感知用户级线程的存在。
什么是死锁?死锁产生的条件?
什么是死锁:
在两个或者多个并发进程中,如果每个进程持有某种资源而又等待其它进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗的讲就是两个或多个进程无限期的阻塞、相互等待的一种状态。
死锁产生的四个必要条件:
有一个条件不成立,则不会产生死锁
- 互斥条件:一个资源一次只能被一个进程使用
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得资源保持不放
- 不剥夺条件:进程获得的资源,在未完全使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾相接的环形等待资源关系
如何处理死锁问题
常用的处理死锁的方法有:死锁预防、死锁避免、死锁检测、死锁解除、鸵鸟策略。
死锁的预防:
基本思想就是确保死锁发生的四个必要条件中至少有一个不成立:
- 破除资源互斥条件
- 破除“请求与保持”条件:实行资源预分配策略,进程在运行之前,必须一次性获取所有的资源。缺点:在很多情况下,无法预知进程执行前所需的全部资源,因为进程是动态执行的,同时也会降低资源利用率,导致降低了进程的并发性。
- 破除“不可剥夺”条件:允许进程强行从占有者那里夺取某些资源。当一个已经保持了某些不可被抢占资源的进程,提出新的资源请求而不能得到满足时,它必须释放已经保持的所有资源,待以后需要时再重新申请。这意味着进程已经占有的资源会被暂时被释放,或者说被抢占了。
- 破除“循环等待”条件:实行资源有序分配策略,对所有资源排序编号,按照顺序获取资源,将紧缺的,稀少的采用较大的编号,在申请资源时必须按照编号的顺序进行,一个进程只有获得较小编号的进程才能申请较大编号的进程。
死锁避免:
死锁预防通过约束资源请求,防止4个必要条件中至少一个的发生,可以通过直接或间接预防方法,但是都会导致低效的资源使用和低效的进程执行。而死锁避免则允许前三个必要条件,但是通过动态地检测资源分配状态,以确保循环等待条件不成立,从而确保系统处于安全状态。所谓安全状态是指:如果系统能按某个顺序为每个进程分配资源(不超过其最大值),那么系统状态是安全的,换句话说就是,如果存在一个安全序列,那么系统处于安全状态。银行家算法是经典的死锁避免的算法。
死锁检测:
死锁预防策略是非常保守的,他们通过限制访问资源和在进程上强加约束来解决死锁的问题。死锁检测则是完全相反,它不限制资源访问或约束进程行为,只要有可能,被请求的资源就被授权给进程。但是操作系统会周期性地执行一个算法检测前面的循环等待的条件。死锁检测算法是通过资源分配图来检测是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有存在环,也就是检测到死锁的发生。
- 如果进程-资源分配图中无环路,此时系统没有死锁。
- 如果进程-资源分配图中有环路,且每个资源类中只有一个资源,则系统发生死锁。
- 如果进程-资源分配图中有环路,且所涉及的资源类有多个资源,则不一定会发生死锁
死锁解除:
死锁解除的常用方法就是终止进程和资源抢占,回滚。所谓进程终止就是简单地终止一个或多个进程以打破循环等待,包括两种方式:终止所有死锁进程和一次只终止一个进程直到取消死锁循环为止;所谓资源抢占就是从一个或者多个死锁进程那里抢占一个或多个资源。
鸵鸟策略:
把头埋在沙子里,假装根本没发生问题。因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任何措施的方案会获得更高的性能。当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
进程调度策略有哪几种?
- 先来先服务:非抢占式的调度算法,按照请求的顺序进行调度。有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。另外,对 I/O 密集型进程也不利,因为这种进程每次进行 I/O 操作之后又得重新排队。
- 短作业优先:非抢占式的调度算法,按估计运行时间最短的顺序进行调度。长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
- 最短剩余时间优先:最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
- 时间片轮转:将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。时间片轮转算法的效率和时间片的大小有很大关系:因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。 而如果时间片过长,那么实时性就不能得到保证。
- 优先级调度:为每个进程分配一个优先级,按优先级进行调度。为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
- 多级反馈队列调度算法 :前面介绍的几种进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程 。多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业(进程)迅速完成。,因而它是目前被公认的一种较好的进程调度算法,UNIX 操作系统采取的便是这种调度算法。
内存管理的集中方式?
简单分为连续分配管理方式和非连续分配管理方式这两种。连续分配管理方式是指为一个用户程序分配一个连续的内存空间,常见的如 块式管理 。同样地,非连续分配管理方式允许一个程序使用的内存分布在离散或者说不相邻的内存中,常见的如页式管理 和 段式管理。
- 块式管理 : 远古时代的计算机操作系统的内存管理方式。将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为碎片。
- 页式管理 :把主存分为大小相等且固定的一页一页的形式,页较小,相比于块式管理的划分粒度更小,提高了内存利用率,减少了碎片。页式管理通过页表对应逻辑地址和物理地址。
- 段式管理 : 页式管理虽然提高了内存利用率,但是页式管理其中的页并无任何实际意义。 段式管理把主存分为一段段的,段是有实际意义的,每个段定义了一组逻辑信息,例如,有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。 段式管理通过段表对应逻辑地址和物理地址。
- 段页式管理机制:段页式管理机制结合了段式管理和页式管理的优点。简单来说段页式管理机制就是把主存先分成若干段,每个段又分成若干页,也就是说 段页式管理机制 中段与段之间以及段的内部的都是离散的。
简单来说:页是物理单位,段是逻辑单位。分页可以有效提高内存利用率,分段可以更好满足用户需求。
什么是分页?
把内存空间划分为大小相等且固定的块,作为主存的基本单位。因为程序数据存储在不同的页面中,而页面又离散的分布在内存中,因此需要一个页表来记录映射关系,以实现从页号到物理块号的映射。
访问分页系统中内存数据需要两次的内存访问 (一次是从内存中访问页表,从中找到指定的物理块号,加上页内偏移得到实际物理地址;第二次就是根据第一次得到的物理地址访问内存取出数据)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GPnV3MvE-1666488157645)(image-20220920155822029.png)]
什么是分段?
分页是为了提高内存利用率,而分段是为了满足程序员在编写代码的时候的一些逻辑需求(比如数据共享,数据保护,动态链接等)。
分段内存管理当中,地址是二维的,一维是段号,二维是段内地址;其中每个段的长度是不一样 的,而且每个段内部都是从0开始编址的。由于分段管理中,每个段内部是连续内存分配,但是段和段之间是离散分配的,因此也存在一个逻辑地址到物理地址的映射关系,相应的就是段表机制。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1EMGYUOu-1666488157645)(image-20220920160116926.png)]
分页和分段有什区别?
回答1:
- 共同点:
- 分页机制和分段机制都是为了提高内存利用率,减少内存碎片。
- 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
- 区别:
- 页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
- 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。
回答2:
- 分页对程序员是透明的,但是分段需要程序员显式划分每个段。
- 分页的地址空间是一维地址空间,分段是二维的。
- 页的大小不可变,段的大小可以动态改变。
- 分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
什么是交换空间?
操作系统把物理内存(physical RAM)分成一块一块的小内存,每一块内存被称为页**(page)。当内存资源不足时,Linux把某些页的内容转移至硬盘上的一块空间上,以释放内存空间。硬盘上的那块空间叫做交换空间**(swap space),而这一过程被称为交换(swapping)。物理内存和交换空间的总容量就是虚拟内存的可用容量。
用途:
- 物理内存不足时一些不常用的页可以被交换出去,腾给系统。
- 程序启动时很多内存页被用来初始化,之后便不再需要,可以交换出去。
页面置换算法的作用?
地址映射过程中,若在页面中发现所要访问的页面不在内存中,则发生缺页中断 。
缺页中断 就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。 在这个时候,被内存映射的文件实际上成了一个分页交换文件。
当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则。
页面替换算法有哪些?
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
- OPT 页面置换算法(最佳页面置换算法) :最佳(Optimal, OPT)置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现。一般作为衡量其他置换算法的方法。
- FIFO(First In First Out) 页面置换算法(先进先出页面置换算法) : 总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
- LRU (Least Recently Used)页面置换算法(最近最久未使用页面置换算法) :LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。
- LFU (Least Frequently Used)页面置换算法(最少使用页面置换算法) : 该置换算法选择在之前时期使用最少的页面作为淘汰页。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WjdbEDyU-1666488157645)(image-20220920161651902.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aM2pgAlV-1666488157645)(image-20220920201019877.png)]
谈一谈「互斥锁、自旋锁、读写锁、乐观锁、悲观锁」的选择和使用?
总结:
开发过程中,最常见的就是互斥锁的了,互斥锁加锁失败时,会用「线程切换」来应对,当加锁失败的线程再次加锁成功后的这一过程,会有两次线程上下文切换的成本,性能损耗比较大。
如果我们明确知道被锁住的代码的执行时间很短,那我们应该选择开销比较小的自旋锁,因为自旋锁加锁失败时,并不会主动产生线程切换,而是一直忙等待,直到获取到锁,那么如果被锁住的代码执行时间很短,那这个忙等待的时间相对应也很短。
如果能区分读操作和写操作的场景,那读写锁就更合适了,它允许多个读线程可以同时持有读锁,提高了读的并发性。根据偏袒读方还是写方,可以分为读优先锁和写优先锁,读优先锁并发性很强,但是写线程会被饿死,而写优先锁会优先服务写线程,读线程也可能会被饿死,那为了避免饥饿的问题,于是就有了公平读写锁,它是用队列把请求锁的线程排队,并保证先入先出的原则来对线程加锁,这样便保证了某种线程不会被饿死,通用性也更好点。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
另外,互斥锁、自旋锁、读写锁都属于悲观锁,悲观锁认为并发访问共享资源时,冲突概率可能非常高,所以在访问共享资源前,都需要先加锁。
相反的,如果并发访问共享资源时,冲突概率非常低的话,就可以使用乐观锁,它的工作方式是,在访问共享资源时,不用先加锁,修改完共享资源后,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
但是,一旦冲突概率上升,就不适合使用乐观锁了,因为它解决冲突的重试成本非常高。
不管使用的哪种锁,我们的加锁的代码范围应该尽可能的小,也就是加锁的粒度要小,这样执行速度会比较快。再来,使用上了合适的锁,就会快上加快了。
互斥锁与自旋锁
最底层的两种就是会「互斥锁和自旋锁」,有很多高级的锁都是基于它们实现的,你可以认为它们是各种锁的地基,所以我们必须清楚它俩之间的区别和应用。
加锁的目的就是保证共享资源在任意时间里,只有一个线程访问,这样就可以避免多线程导致共享数据错乱的问题。
当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁对于加锁失败后的处理方式是不一样的:
- 互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
- 自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
互斥锁是一种「独占锁」,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为「睡眠」状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执行。如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NGO6zcsd-1666488157646)(%E4%BA%92%E6%96%A5%E9%94%81%E5%B7%A5%E4%BD%9C%E6%B5%81%E7%A8%8B.png)]
所以,互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮我们切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本。
那这个开销成本是什么呢?会有两次线程上下文切换的成本:
- 当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
- 接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
线程的上下文切换的是什么?当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下切换的耗时有大佬统计过,大概在几十纳秒到几微秒之间,如果你锁住的代码执行时间比较短,那可能上下文切换的时间都比你锁住的代码执行时间还要长。
所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
自旋锁是通过 CPU 提供的 CAS 函数(Compare And Swap),在「用户态」完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。
一般加锁的过程,包含两个步骤:
- 第一步,查看锁的状态,如果锁是空闲的,则执行第二步;
- 第二步,将锁设置为当前线程持有;
CAS 函数就把这两个步骤合并成一条硬件级指令,形成原子指令,这样就保证了这两个步骤是不可分割的,要么一次性执行完两个步骤,要么两个步骤都不执行。
比如,设锁为变量 lock,整数 0 表示锁是空闲状态,整数 pid 表示线程 ID,那么 CAS(lock, 0, pid) 就表示自旋锁的加锁操作,CAS(lock, pid, 0) 则表示解锁操作。
使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这里的「忙等待」可以用 while 循环等待实现,不过最好是使用 CPU 提供的 PAUSE 指令来实现「忙等待」,因为可以减少循环等待时的耗电量。
自旋锁是最比较简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
自旋锁开销少,在多核系统下一般不会主动产生线程切换,适合异步、协程等在用户态切换请求的编程方式,但如果被锁住的代码执行时间过长,自旋的线程会长时间占用 CPU 资源,所以自旋的时间和被锁住的代码执行的时间是成「正比」的关系,我们需要清楚的知道这一点。
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。
它俩是锁的最基本处理方式,更高级的锁都会选择其中一个来实现,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。
读写锁
读写锁从字面意思我们也可以知道,它由「读锁」和「写锁」两部分构成,如果只读取共享资源用「读锁」加锁,如果要修改共享资源则用「写锁」加锁。
所以,读写锁适用于能明确区分读操作和写操作的场景。
读写锁的工作原理是:
- 当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为「读锁」是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
- 但是,一旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
所以说,写锁是独占锁,因为任何时刻只能有一个线程持有写锁,类似互斥锁和自旋锁,而读锁是共享锁,因为读锁可以被多个线程同时持有。
知道了读写锁的工作原理后,我们可以发现,读写锁在读多写少的场景,能发挥出优势。
另外,根据实现的不同,读写锁可以分为「读优先锁」和「写优先锁」。
读优先锁期望的是,读锁能被更多的线程持有,以便提高读线程的并发性,它的工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取写锁。如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJx7nXnJ-1666488157646)(%E8%AF%BB%E4%BC%98%E5%85%88%E9%94%81%E5%B7%A5%E4%BD%9C%E6%B5%81%E7%A8%8B.png)]
而「写优先锁」是优先服务写线程,其工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取写锁。如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KeQhil9M-1666488157646)(%E5%86%99%E4%BC%98%E5%85%88%E9%94%81%E5%B7%A5%E4%BD%9C%E6%B5%81%E7%A8%8B.png)]
读优先锁对于读线程并发性更好,但也不是没有问题。我们试想一下,如果一直有读线程获取读锁,那么写线程将永远获取不到写锁,这就造成了写线程「饥饿」的现象。
写优先锁可以保证写线程不会饿死,但是如果一直有写线程获取写锁,读线程也会被「饿死」。
既然不管优先读锁还是写锁,对方可能会出现饿死问题,那么我们就不偏袒任何一方,搞个「公平读写锁」。
公平读写锁比较简单的一种方式是:用队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现「饥饿」的现象。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
乐观锁与悲观锁
前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
放弃后如何重试,这跟业务场景息息相关,虽然重试的成本很高,但是冲突的概率足够低的话,还是可以接受的。
可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。
这里举一个场景例子:在线文档。
我们都知道在线文档可以同时多人编辑的,如果使用了悲观锁,那么只要有一个用户正在编辑文档,此时其他用户就无法打开相同的文档了,这用户体验当然不好了。
那实现多人同时编辑,实际上是用了乐观锁,它允许多个用户打开同一个文档进行编辑,编辑完提交之后才验证修改的内容是否有冲突。
怎么样才算发生冲突?这里举个例子,比如用户 A 先在浏览器编辑文档,之后用户 B 在浏览器也打开了相同的文档进行编辑,但是用户 B 比用户 A 提交早,这一过程用户 A 是不知道的,当 A 提交修改完的内容时,那么 A 和 B 之间并行修改的地方就会发生冲突。
服务端要怎么验证是否冲突了呢?通常方案如下:
- 由于发生冲突的概率比较低,所以先让用户编辑文档,但是浏览器在下载文档时会记录下服务端返回的文档版本号;
- 当用户提交修改时,发给服务端的请求会带上原始文档版本号,服务器收到后将它与当前版本号进行比较,如果版本号不一致则提交失败,如果版本号一致则修改成功,然后服务端版本号更新到最新的版本号。
实际上,我们常见的 SVN 和 Git 也是用了乐观锁的思想,先让用户编辑代码,然后提交的时候,通过版本号来判断是否产生了冲突,发生了冲突的地方,需要我们自己修改后,再重新提交。
乐观锁虽然去除了加锁解锁的操作,但是一旦发生冲突,重试的成本非常高,所以只有在冲突概率非常低,且加锁成本非常高的场景时,才考虑使用乐观锁。
什么是缓冲区溢出?有什么危害?
缓冲区溢出是指当计算机向缓冲区填充数据时超出了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
危害有以下两点:
- 程序崩溃,导致拒绝额服务
- 跳转并且执行一段恶意代码
造成缓冲区溢出的主要原因是程序中没有仔细检查用户输入。
为什么需要虚拟地址空间?
为什么要有虚拟地址空间呢?
先从没有虚拟地址空间的时候说起吧!没有虚拟地址空间的时候,程序直接访问和操作的都是物理内存 。但是这样有什么问题呢?
- 用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易(有意或者无意)破坏操作系统,造成操作系统崩溃。
- 想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行。为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
总结来说:如果直接把物理地址暴露出来的话会带来严重问题,比如可能对操作系统造成伤害以及给同时运行多个程序造成困难。
通过虚拟地址访问内存有以下优势:
- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
- 不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
什么是虚拟内存?
回答1:
这个在我们平时使用电脑特别是 Windows 系统的时候太常见了。很多时候我们使用了很多占内存的软件,这些软件占用的内存可能已经远远超出了我们电脑本身具有的物理内存。为什么可以这样呢? 正是因为 虚拟内存 的存在,通过 虚拟内存 可以让程序可以拥有超过系统物理内存大小的可用内存空间。另外,虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)。这样会更加有效地管理内存并减少出错。
虚拟内存就是说,让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。虚拟内存使用部分加载的技术,让一个进程或者资源的某些页面加载进内存,从而能够加载更多的进程,甚至能加载比内存大的进程,这样看起来好像内存变大了,这部分内存其实包含了磁盘或者硬盘,并且就叫做虚拟内存。
回答2:
虚拟内存是操作系统管理内存的一种技术,它使应用程序有一段连续可用的地址空间的假象,实际上是很多个物理内存碎片,它可以使应用程序拥有比实际物理内存更大的逻辑内存,实际上上将程序中不需要的数据放到硬盘上,需要时在进行数据交换。
主要原理:每个进程拥有独立地址空间,这个地址空间被分多个大小相等的快,称为页,这些页被映射到物理内存,但不需要映射的连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
虚拟内存转换为物理内存?
虚拟地址通过mmu(内存管理单元)进行物理地址和虚拟地址的转化。其中每个进程都有一个也表里面映射着页号与帧号,通过页号查询到帧号,cpu判断当前的帧号是否访问越界,如果是就中断,否则就通过页内偏移量和帧号计算出物理地址。但是这样访问速度较慢,所以MMU里面就会有TLB,可以看成是个缓存,操作系统会先查TLB中虚拟地址与物理地址的映射,如果有的话,就不要查页表了,否则查询页表,然后更新TLB的数据。
查询页表的时候还要检测标志为是否为1,如果是1说明有页在内存中,如果0的话说明没有页在内存中这是时候就发生缺页中断从而将该页调入内存中,此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。这时候就会用到页面置换算法 。
虚拟内存的实现方式有哪些?
虚拟内存中,允许将一个作业分多次调入内存。釆用连续分配方式时,会使相当一部分内存空间都处于暂时或永久的空闲状态,造成内存资源的严重浪费,而且也无法从逻辑上扩大内存容量。因此,虚拟内存的实需要建立在离散分配的内存管理方式的基础上。虚拟内存的实现有以下三种方式:
- 请求分页存储管理。
- 请求分段存储管理。
- 请求段页式存储管理。
讲一讲IO多路复用?
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。IO多 路复用适用如下场合:
- 当客户处理多个描述字时(一般是交互式输入和网络套接口),必须使用I/O复用。
- 当一个客户同时处理多个套接口时,而这种情况是可能的,但很少出现。
- 如果一个TCP服务器既要处理监听套接口,又要处理已连接套接口,一般也要用到I/O复用。
- 如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用。
- 如果一个服务器要处理多个服务或多个协议,一般要使用I/O复用。
- 与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
中断的处理过程**?**
- 保护现场:将当前执行程序的相关数据保存在寄存器中,然后入栈。
- 开中断:以便执行中断时能响应较高级别的中断请求。
- 中断处理
- 关中断:保证恢复现场时不被新中断打扰
- 恢复现场:从堆栈中按序取出程序数据,恢复中断前的执行状态。
中断和轮询有什么区别?
- 轮询:CPU对特定设备轮流询问。
- 轮询:效率低等待时间长,CPU利用率不高。
- 中断:通过特定事件提醒CPU。
- 中断:容易遗漏问题,CPU利用率不高。
什么是用户态和内核态?
用户态和系统态是操作系统的两种运行状态:
内核态:内核态运行的程序可以访问计算机的任何数据和资源,不受限制,包括外围设备,比如网卡、硬盘等。处于内核态的 CPU 可以从一个程序切换到另外一个程序,并且占用CPU 不会发生抢占情况。
用户态:用户态运行的程序只能受限地访问内存,只能直接读取用户程序的数据,并且不允许访问外围设备,用户态下的 CPU 不允许独占,也就是说 CPU 能够被其他程序获取。
将操作系统的运行状态分为用户态和内核态,主要是为了对访问能力进行限制,防止随意进行一些比较危险的操作导致系统的崩溃,比如设置时钟、内存清理,这些都需要在内核态下完成 。
Spring
使用Spring框架的好处是什么?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIlNogX7-1666488157646)(image-20220913102958261.png)]
什么是 spring bean?
它们是构成用户应用程序主干的对象。Bean 由 Spring IoC 容器管理。它们由 Spring IoC 容器实例化,配置,装配和管理。Bean 是基于用户提供给容器的配置元数据创建。
Spring 注入 Bean 的方式
- 通过xml 方式注入,它的注入方式分为:
set方法注入、构造方法注入、字段注入,而注入类型分为值类型注入(8 种基本数据类型)和引用类型注入(将依赖对象注入)。 - 注解方式。除了我们经常使用的
@Controller、@Service、@Repository、@Component之外,还有一些比较常用的方式**@Configuration + @Bean**,@Import。 - FactoryBean。先定义实现了
FactoryBean接口的类TeacherFactoryBean,然后通过@Configuration+@Bean的方式将TeacherFactoryBean加入到容器中。 - BDRegistryPostProcessor。
什么是依赖注入?可以通过多少种方式完成依赖注入?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VQCCEMON-1666488157647)(image-20220913103110078.png)]
区分构造函数注入和 setter注入
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W8TfLvd3-1666488157647)(image-20220913103223540.png)]
spring提供了哪些配置方式?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8yXhtBVG-1666488157647)(image-20220913103301339.png)]
Spring是如何管理Bean的?
Spring通过IoC容器来管理Bean,我们可以通过XML配置或者注解配置,来指导IoC容器对Bean的管理。因为注解配置比XML配置方便很多,所以现在大多时候会使用注解配置的方式。
以下是管理Bean时常用的一些注解:
@ComponentScan用于声明扫描策略,通过它的声明,容器就知道要扫描哪些包下带有声明的类,也可以知道哪些特定的类是被排除在外的。
@Component、@Repository、@Service、@Controller用于声明Bean,它们的作用一样,但是语义不同。@Component用于声明通用的Bean,@Repository用于声明DAO层的Bean,@Service用于声明业务层的Bean,@Controller用于声明视图层的控制器Bean,被这些注解声明的类就可以被容器扫描并创建。
@Autowired、@Qualifier用于注入Bean,即告诉容器应该为当前属性注入哪个Bean。其中,@Autowired是按照Bean的类型进行匹配的,如果这个属性的类型具有多个Bean,就可以通过@Qualifier指定Bean的名称,以消除歧义。
@Scope用于声明Bean的作用域,默认情况下Bean是单例的,即在整个容器中这个类型只有一个实例。可以通过@Scope注解指定prototype值将其声明为多例的,也可以将Bean声明为session级作用域、request级作用域等等,但最常用的还是默认的单例模式。
@PostConstruct、@PreDestroy用于声明Bean的生命周期。其中,被@PostConstruct修饰的方法将在Bean实例化后被调用,@PreDestroy修饰的方法将在容器销毁前被调用。
@Component, @Controller, @Repository,@Service 有何区别?
@Component、@Repository、@Service、@Controller用于声明Bean,它们的作用一样,但是语义不同。@Component用于声明通用的Bean,@Repository用于声明DAO层的Bean,@Service用于声明业务层的Bean,@Controller用于声明视图层的控制器Bean,被这些注解声明的类就可以被容器扫描并创建。
IOC & AOP
我们是在使用Spring框架的过程中,其实就是为了使用IOC,依赖注入,和AOP,面向切面编程,这两个是Spring的灵魂。主要用到的设计模式有工厂模式和代理模式。
IOC就是典型的工厂模式,通过sessionfactory去注入实例。AOP就是典型的代理模式的体现。
代理模式是常用的java设计模式,他的特征是代理类与委托类有同样的接口,代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。代理类与委托类之间通常会存在关联关系,一个代理类的对象与一个委托类的对象关联,代理类的对象本身并不真正实现服务,而是通过调用委托类的对象的相关方法,来提供特定的服务。
spring的IoC容器是spring的核心,spring AOP是spring框架的重要组成部分。
在传统的程序设计中,当调用者需要被调用者的协助时,通常由调用者来创建被调用者的实例。但在spring里创建被调用者的工作不再由调用者来完成,因此控制反转(IoC);创建被调用者实例的工作通 常由spring容器来完成,然后注入调用者,因此也被称为依赖注入(DI),依赖注入和控制反转是同一 个概念。
面向方面编程(AOP)是以另一个角度来考虑程序结构,通过分析程序结构的关注点来完善面向对象编程(OOP)。OOP将应用程序分解成各个层次的对象,而AOP将程序分解成多个切面。spring AOP 只实现了方法级别的连接点,在J2EE应用中,AOP拦截到方法级别的操作就已经足够。在spring中,未来使IoC方便地使用健壮、灵活的企业服务,需要利用spring AOP实现为IoC和企业服务之间建立联系。
IOC:控制反转也叫依赖注入。利用了工厂模式
将对象交给容器管理,你只需要在 spring 配置文件总配置相应的 bean ,以及设置相关的属性,让spring 容器来生成类的实例对象以及管理对象。在 spring 容器启动的时候, spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调用这些 bean 的类(假设这个类名是 A ),分配的方法就是调用 A的 setter 方法来注入,而不需要你在 A 里面 new 这些 bean 了。
spring ioc初始化流程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PC63vGKP-1666488157648)(image-20220923205713854.png)]
AOP:面向切面编程。(Aspect-Oriented Programming)
AOP可以说是对OOP的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。将程序中的交叉业务逻辑(比如安全,日志,事务等),封装成一个切面,然后注入到目标对象(具体业务逻辑)中去。
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。
简单点解释,比方说你想在你的biz层所有类中都加上一个打印‘你好’的功能,这时就可以用aop思想来做。你先写个类写个类方法,方法经实现打印‘你好’,然后Ioc这个类 ref="biz.*"让每个类都注入即可实现。
如何理解IOC和DI?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LNdWomWC-1666488157648)(image-20220913103758032.png)]
将一个类声明为Spring的bean的注解有哪些?
@Component、@Repository、@Service、@Controller用于声明Bean,它们的作用一样,但是语义不同。@Component用于声明通用的Bean,@Repository用于声明DAO层的Bean,@Service用于声明业务层的Bean,@Controller用于声明视图层的控制器Bean,被这些注解声明的类就可以被容器扫描并创建。
@Component 和 @Bean 的区别是什么?
- 作⽤对象不同: @Component 注解作⽤于类,⽽ @Bean 注解作⽤于⽅法。
- @Component 通常是通过类路径扫描来⾃动侦测以及⾃动装配到Spring容器中(我们可以使⽤ @ComponentScan 注解定义要扫描的路径从中找出标识了需要装配的类⾃动装配到Spring 的 bean 容器中)。 @Bean 注解通常是我们在标有该注解的⽅法中定义产⽣这个bean, @Bean 告诉了Spring这是某个类的示例,当我需要⽤它的时候还给我。
- @Bean 注解⽐ Component 注解的⾃定义性更强,⽽且很多地⽅我们只能通过 @Bean 注解来注册bean。⽐如当我们引⽤第三⽅库中的类需要装配到 Spring 容器时,则只能通过@Bean 来实现
spring支持几种bean scope(Bean的作用域)?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gSduqyWp-1666488157649)(image-20220913104419315.png)]
什么是 spring 装配(注入Bean)?
当 bean 在 Spring 容器中组合在一起时,它被称为装配或 bean 装配。Spring容器需要知道需要什么 bean 以及容器应该如何使用依赖注入来将 bean 绑定在一起,同时装配 bean。
怎样开启注解装配?
注解装配在默认情况下是不开启的,为了使用注解装配,我们必须在 Spring 配置文件中配置 context:annotation-config/元素。
解释不同方式的自动装配 。
有五种自动装配的方式,可以用来指导 Spring 容器用自动装配方式来进行依赖注入。
- no:默认的方式是不进行自动装配,通过显式设置 ref 属性来进行装配。第 402 页 共 485 页
- byName:通过参数名 自动装配,Spring 容器在配置文件中发现 bean的 autowire 属性被设置成 byname,之后容器试图匹配、装配和该 bean 的属性具有相同名字的 bean。
- byType:通过参数类型自动装配,Spring 容器在配置文件中发现 bean 的 autowire 属性被设置成 byType,之后容器试图匹配、装配和该 bean 的属性具有相同类型的 bean。如果有多个 bean 符合条件,则抛出错误。
- constructor:这个方式类似于 byType, 但是要提供给构造器参数,如果没有确定的带参数的构造器参数类型,将会抛出异常。
- autodetect:首先尝试使用 constructor 来自动装配,如果无法工作,则使用 byType 方式。
自动装配有哪些局限性 ?
重写:你仍需用 和 配置来定义依赖,意味着总要重写自动装配。
基本数据类型:你不能自动装配简单的属性,如基本数据类型,String 字符串,和类。
模糊特性:自动装配不如显式装配精确,如果有可能,建议使用显式装配。
@Autowired和@Resource注解有什么区别?
@Autowired是Spring提供的注解,@Resource是JDK提供的注解。
@Autowired是只能按类型注入,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。@Resource默认按名称注入,也支持按类型注入。@Resource如果没有指定name属性,并且按照默认的名称仍然找不到依赖对象时, @Resource注解会回退到按类型装配。但一旦指定了name属性,就只能按名称装配了。
spring的bean为什么是单例的?
为了提高性能。
-
由于不会每次都新创建新对象,所以就减少了新生成实例的消耗。因为spring会通过反射或者cglib来生成bean实例这都是耗性能的操作,其次给对象分配内存也会涉及复杂算法。
-
减少JVM垃圾回收,由于不会给每个请求都新生成bean实例,所以自然回收的对象少了。
-
可以快速获取到bean,因为单例的获取bean操作除了第一次生成之外其余的都是从缓存里获取的所以很快。
-
缺点就是在并发环境下可能会出现线程安全问题。
spring如何配置多例?
在bean时,加一个scope = “singleton”;如果不写个默认是true,也就是单例的,写了就是多例的。
Spring是怎么解决循环依赖的?
首先,需要明确的是spring对循环依赖的处理有三种情况:
-
构造器的循环依赖:这种依赖spring是处理不了的,直接抛出BeanCurrentlylnCreationException异常。
-
单例模式下的setter循环依赖:通过“三级缓存”处理循环依赖。
-
非单例循环依赖:无法处理。
接下来,我们具体看看spring是如何处理第二种循环依赖的。Spring单例对象的初始化大略分为三步:
-
createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象;
-
populateBean:填充属性,这一步主要是多bean的依赖属性进行填充;
-
initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一步、第二步。也就是构造器循环依赖和field循环依赖。 Spring为了解决单例的循环依赖问题,使用了三级缓存。这三级缓存的作用分别是:
-
singletonFactories : 进入实例化阶段的单例对象工厂的cache (三级缓存);
-
earlySingletonObjects :完成实例化但是尚未初始化的,提前暴光的单例对象的Cache (二级缓存);
-
singletonObjects:完成初始化的单例对象的cache(一级缓存)。
Bean的生命周期
1.创建前准备
2.正式创建bean (实例化,在堆区分配内存,属性为默认值)
3.依赖注入,主要是给属性赋值 (初始化)
4.执行相关的初始化方法 (初始化)
使用bean
5.bean的销毁
Bean 的生命周期,就是一个 Bean 从创建到销毁,所经历的各种方法调用。 简单的来说,一个Bean的生命周期分为四个阶段:实例化(Instantiation)、 属性设置(populate)、初始化(Initialization)、销毁(Destruction)。
实例化:程序启动后,Spring把注解或者配置文件定义好的Bean对象转换成一个BeanDefination对象,然后完成整个BeanDefination的解析和加载的过程。Spring获取到这些完整的对象之后,会对整个BeanDefination进行实例化操作,实例化是通过反射的方式创建对象。
属性设置:实例化后的对象被封装在BeanWrapper对象中,并且此时对象仍然是一个原生的状态,并没有进行依赖注入。Spring根据BeanDefinition中的信息进行依赖注入, populateBean方法来完成属性的注入。
初始化
- 调用Aware接口相关的方法:invokeAwareMethod(完成beanName, beanClassLoader, beanFactory对象的属性设置)
- 调用beanPostProcessor中的前置处理方法(applyBeanPostProcessorsBeforeInitialization)
- 调用InitMethod方法:invokeInitMethod(),判断是否实现了initializingBean接口,如果有,调用afterPropertiesSet方法,没有就不调用
- 调用BeanPostProcessor后置处理方法(applyBeanPostProcessorsAfterInitialization),Spring 的Aop就是在此处实现的
销毁:判断是否实现了DisposableBean接口,调用destoryMethod方法
什么是 Spring 的内部 bean?
当一个 bean 仅被用作另一个 bean 的属性时,它能被声明为一个内部 bean,为了定义 inner bean,在 Spring 的 基于 XML 的 配置元数据中,可以在或元素内使用 元素,内部 bean 通常是匿名的,它们的 Scope 一般是 prototype。
什么是 AOP?
AOP(Aspect-Oriented Programming), 即面向切面编程, 它与 OOP( Object-Oriented Programming,面向对象编程) 相辅相成, 提供了与 OOP 不同的抽象软件结构的视角。
在 OOP 中, 我们以类(class)作为我们的基本单元,而 AOP 中的基本单元是 Aspect(切面)。
AOP的术语:
连接点(join point):对应的是具体被拦截的对象,因为Spring只能支持方法,所以被拦截的对象往往就是指特定的方法,AOP将通过动态代理技术把它织入对应的流程中。
切点(point cut):有时候,我们的切面不单单应用于单个方法,也可能是多个类的不同方法,这时,可以通过正则式和指示器的规则去定义,从而适配连接点。切点就是提供这样一个功能的概念。
通知(advice):就是按照约定的流程下的方法,分为前置通知、后置通知、环绕通知、事后返回通知和异常通知,它会根据约定织入流程中。
目标对象(target):即被代理对象。
引入(introduction):是指引入新的类和其方法,增强现有Bean的功能。
织入(weaving):它是一个通过动态代理技术,为原有服务对象生成代理对象,然后将与切点定义匹配的连接点拦截,并按约定将各类通知织入约定流程的过程。
切面(aspect):是一个可以定义切点、各类通知和引入的内容,SpringAOP将通过它的信息来增强Bean的功能或者将对应的方法织入流程。
在 Spring AOP 中,关注点和横切关注的区别是什么?
关注点是应用中一个模块的行为,一个关注点可能会被定义成一个我们想实现的 一个功能。
横切关注点是一个关注点,此关注点是整个应用都会使用的功能,并影响整个应用,比如日志,安全和数据传输,几乎应用的每个模块都需要的功能。因此这些 都属于横切关注点。
Spring 切面可以应用五种类型的通知:
before:前置通知,在一个方法执行前被调用。
after: 在方法执行之后调用的通知,无论方法执行是否成功。
after-returning: 仅当方法成功完成后执行的通知。
after-throwing: 在方法抛出异常退出时执行的通知。
around: 在方法执行之前和之后调用的通知。
AOP 有哪些实现方式?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lXCtgjh8-1666488157649)(image-20220913110121474.png)]
JDK动态代理和CGLIB有什么区别?
JDK动态代理:这是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
CGLib动态代理:采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
既然有没有接口都可以用CGLIB,为什么Spring还要使用JDK动态代理?
在性能方面,CGLib创建的代理对象比JDK动态代理创建的代理对象高很多。但是,CGLib在创建代理对象时所花费的时间比JDK动态代理多很多。
所以,对于单例的对象因为无需频繁创建代理对象,采用CGLib动态代理比较合适。反之,对于多例的对象因为需要频繁的创建代理对象,则JDK动态代理更合适。
Spring AOP and AspectJ AOP 有什么区别?
Spring AOP 基于动态代理方式实现;AspectJ 基于静态代理方式实现。
Spring AOP 仅支持方法级别的 PointCut;提供了完全的 AOP 支持,它还支持属性级别的 PointCut。
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单。
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比Spring AOP 快很多。
请你说说AOP的应用场景
Spring AOP为IoC的使用提供了更多的便利,一方面,应用可以直接使用AOP的功能,设计应用的横切关注点,把跨越应用程序多个模块的功能抽象出来,并通过简单的AOP的使用,灵活地编制到模块中,比如可以通过AOP实现应用程序中的日志功能。另一方面,在Spring内部,一些支持模块也是通过Spring AOP来实现的,比如事务处理。从这两个角度就已经可以看到Spring AOP的核心地位了。
Spring AOP不能对哪些类进行增强?
-
Spring AOP只能对IoC容器中的Bean进行增强,对于不受容器管理的对象不能增强。
-
由于CGLib采用动态创建子类的方式生成代理对象,所以不能对final修饰的类进行代理。
Spring 框架中用到了哪些设计模式?
-
工厂设计模式 : Spring使用工厂模式通过 BeanFactory 、 ApplicationContext 创建 bean 对象。
-
代理设计模式 : Spring AOP 功能的实现。
-
单例设计模式 : Spring 中的 Bean 默认都是单例的。
-
模板方法模式 : Spring 中 jdbcTemplate 、 hibernateTemplate 等以 Template 结尾的对数据库操作
的类,它们就使用到了模板模式。
-
包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不
同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
-
观察者模式*** Spring 事件驱动模型就是观察者模式很经典的一个应用。
-
适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器
模式适配 Controller 。
spring事务定义的传播规则(事务传播行为)
- PROPAGATION_REQUIRED: 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
- PROPAGATION_SUPPORTS: 支持当前事务,如果当前没有事务,就以非事务方式执行。
- PROPAGATION_MANDATORY: 支持当前事务,如果当前没有事务,就抛出异常。
- PROPAGATION_REQUIRES_NEW: 新建事务,如果当前存在事务,把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED: 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER: 以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。
DAO层是做什么的?
DAO是Data Access Object的缩写,即数据访问对象,在项目中它通常作为独立的一层,专门用于访问数据库。这一层的具体实现技术有很多,常用的有Spring JDBC、Hibernate、JPA、MyBatis等,在Spring框架下无论采用哪一种技术访问数据库,它的编程模式都是统一的。
Spring容器
Spring主要提供了两种类型的容器:BeanFactory和ApplicationContext。
BeanFactory:是基础类型的IoC容器,提供完整的IoC服务支持。如果没有特殊指定,默认采用延迟初始化策略。只有当客户端对象需要访问容器中的某个受管对象的时候,才对该受管对象进行初始化以及依赖注入操作。所以,相对来说,容器启动初期速度较快,所需要的资源有限。对于资源有限,并且功能要求不是很严格的场景,BeanFactory是比较合适的IoC容器选择。
说一说你对BeanFactory的了解
BeanFactory是一个类工厂,与传统类工厂不同的是,BeanFactory是类的通用工厂,它可以创建并管理各种类的对象。这些可被创建和管理的对象本身没有什么特别之处,仅是一个POJO,Spring称这些被创建和管理的Java对象为Bean。并且,Spring中所说的Bean比JavaBean更为宽泛一些,所有可以被Spring容器实例化并管理的Java类都可以成为Bean。
BeanFactory是Spring容器的顶层接口,Spring为BeanFactory提供了多种实现,最常用的是XmlBeanFactory。但它在Spring 3.2中已被废弃,建议使用XmlBeanDefinitionReader、DefaultListableBeanFactory替代。BeanFactory最主要的方法就是 getBean(String beanName),该方法从容器中返回特定名称的Bean。
BeanFactory 实现举例。
Bean 工厂是工厂模式的一个实现,提供了控制反转功能,用来把应用的配置和依赖从正真的应用代码中分离。最常用的 BeanFactory 实现是 XmlBeanFactory 类。
XMLBeanFactory
最常用的就是 org.springframework.beans.factory.xml.XmlBeanFactory ,它根据 XML 文件中的定义加载 beans。该容器从 XML 文件读取配置元数据并用它去创建一个完全配置的系统或应用。
ApplicationContext
-
ApplicationContext:它是在BeanFactory的基础上构建的,是相对比较高级的容器实现,除了拥有BeanFactory的所有支持,
-
ApplicationContext还提供了其他高级特性,比如事件发布、国际化信息支持等。
-
ApplicationContext所管理的对象,在该类型容器启动之后,默认全部初始化并绑定完成。所以,相对于BeanFactory来说,ApplicationContext要求更多的系统资源,同时,因为在启动时就完成所有初始化,容器启动时间较之BeanFactory也会长一些。在那些系统资源充足,并且要求更多功能的场景中,ApplicationContext类型的容器是比较合适的选择。
介绍一下 WebApplicationContext
WebApplicationContext 是 ApplicationContext 的扩展。它具有 Web 应用 程序所需的一些额外功能。它与普通的 ApplicationContext 在解析主题和决定 与哪个 servlet 关联的能力方面有所不同。
ApplicationContext 通常的实现是什么?
-
FileSystemXmlApplicationContext :此容器从一个 XML 文件中加载 beans 的定义,XML Bean 配置文件的全路径名必须提供给它的构造函数。
-
ClassPathXmlApplicationContext:此容器也从一个 XML 文件中加载 beans 的定义,这里,你需要正确设置 classpath 因为这个容器将在 classpath里找 bean 配置。
-
WebXmlApplicationContext:此容器加载一个 XML 文件,此文件定义了一个 WEB 应用的所有 bean。
Spring如何管理事务?(声明式事务,编程式事务)
编程式事务:
Spring提供了TransactionTemplate模板,利用该模板我们可以通过编程的方式实现事务管理,而无需关注资源获取、复用、释放、事务同步及异常处理等操作。相对于声明式事务来说,这种方式相对麻烦一些,但是好在更为灵活,我们可以将事务管理的范围控制的更为精确。
声明式事务:
Spring事务管理的亮点在于声明式事务管理,它允许我们通过声明的方式,在IoC配置中指定事务的边界和事务属性,Spring会自动在指定的事务边界上应用事务属性。相对于编程式事务来说,这种方式十分的方便,只需要在需要做事务管理的方法上,增加@Transactional注解,以声明事务特征即可。
Spring的事务如何配置,常用注解有哪些?
事务的打开、回滚和提交是由事务管理器来完成的,我们使用不同的数据库访问框架,就要使用与之对应的事务管理器。在Spring Boot中,当你添加了数据库访问框架的起步依赖时,它就会进行自动配置,即自动实例化正确的事务管理器。
对于声明式事务,是使用@Transactional进行标注的。这个注解可以标注在类或者方法上。当它标注在类上时,代表这个类所有公共(public)非静态的方法都将启用事务功能。当它标注在方法上时,代表这个方法将启用事务功能。
另外,在@Transactional注解上,我们可以使用isolation属性声明事务的隔离级别,使用propagation属性声明事务的传播机制。
Spring的事务传播方式有哪些?
- propagation_required:如果当前没有事务,就新建一个事务,如果已经存在一个事务中,则加入到这个事务中,(最常见的选择)
- propagation_supports:支持当前事务,如果没有当前事务,就以非事务方法执行。
- propagation_mandatory:使用当前事务,如果没有当前事务,就抛出异常。
- propagation_required_new:新建事务,如果当前存在事务,就把当前事务挂起。
- propagation_not_supported:以非事务方式执行操作,如果当前存事务,就把当前事务挂起。
- propagation_never:以非事务方式执行操作,如果当前事务存在则抛出异常。
- propagation_nested:如果当前存在事务,则在嵌套事务执行。如果当前没有事务,则执行与propagation_required类似的操作。
Spring默认的事务传播行为是PROPAGATION_REQUIRED,它适用于绝大多数情况。
Spring 事务中的隔离级别有哪⼏种?
TransactionDefinition 接⼝中定义了五个表示隔离级别的常量:
-
TransactionDefinition.ISOLATION_DEFAULT: 使⽤后端数据库默认的隔离级别,Mysql默认采⽤的 REPEATABLE_READ隔离级别, Oracle 默认采⽤的 READ_COMMITTED隔离级别.
-
TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
-
TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻⽌脏读,但是幻读或不可重复读仍有可能发⽣
-
TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同⼀字段的多次读取结果都是⼀致的,除⾮数据是被本身事务⾃⼰所修改,可以阻⽌脏读和不可重复读,但幻读仍有可能发⽣。
-
TransactionDefinition.ISOLATION_SERIALIZABLE: 最⾼的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执⾏,这样事务之间就完全不可能产⽣⼲扰,也就是说,该级别可以防⽌脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会⽤到该级别。
解释 WEB 模块。
Spring 的 WEB 模块是构建在 application context 模块基础之上,提供一个适合 web 应用的上下文。这个模块也包括支持多种面向 web 的任务,如透明地处理多个文件上传请求和程序级请求参数的绑定到你的业务对象。它也有对 Jakarta Struts 的支持。
在 Spring 中如何注入一个 java 集合?
Spring 提供以下几种集合的配置元素:
- 类型用于注入一列值,允许有相同的值。
- 类型用于注入一组值,不允许有相同的值。
- 类型用于注入一组键值对,键和值都可以为任意类型。
- 类型用于注入一组键值对,键和值都只能为 String 类型。
@RequestMapping 注解有什么用?
@RequestMapping 注解用于将特定 HTTP 请求方法映射到将处理相应请求的控制器中的特定类/方法。此注释可应用于两个级别:
类级别:映射请求的 URL
方法级别:映射 URL 以及 HTTP 请求方法
Spring DAO 使得 JDBC,Hibernate 或 JDO 这样的数据访问技术更容易以一种统一的方式工作。这使得用户容易在持久性技术之间切换。它还允许您在编写代码时,无需考虑捕获每种技术不同的异常。
SpringMVC
什么是MVC?
MVC是一种设计模式,在这种模式下软件被分为三层,即Model(模型)、View(视图)、Controller(控制器)。Model代表的是数据,View代表的是用户界面,Controller代表的是数据的处理逻辑,它是Model和View这两层的桥梁。将软件分层的好处是,可以将对象之间的耦合度降低,便于代码的维护。
SpringMVC 工作原理(执行流程)了解吗**?**
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e7TVeYWc-1666488157650)(image-20220913113834399.png)]
主要组件
- 前端控制器(DisatcherServlet):接收请求,响应结果,返回可以是json,String等数据类型,也可以是页面Model。
- 处理器映射器(HandlerMapping):根据URL去查找处理器,一般通过xml配置或者注解进行查找。
- 处理器 Handler:就是我们常说的controller控制器啦,由程序员编写。
- 处理器适配器(HandlerAdapter):可以将处理器包装成适配器,这样就可以支持多种类型的处理器。
- 视图解析器(ViewResovler):进行视图解析,返回view对象(常见的有JSP,FreeMark等)。
SpingMVC的工作原理
- 客户端(浏览器)发送请求,直接请求到 DispatcherServlet 。
- DispatcherServlet 根据请求信息调用 HandlerMapping ,解析请求对应的 Handler 。
- 解析到对应的 Handler (也就是我们平常说的 Controller 控制器)后,开始由HandlerAdapter 适配器处理。
- HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑。
- 处理器处理完业务后,会返回一个 ModelAndView 对象, Model 是返回的数据对象, View 是个逻辑上的 View 。
- ViewResolver 会根据逻辑 View 查找实际的 View 。
- DispaterServlet 把返回的 Model 传给 View (视图渲染)。
- 把 View 返回给请求者(浏览器)
简单介绍 Spring MVC 的核心组件?
| 组件 | 说明 |
|---|---|
| DispatcherServlet | Spring MVC 的核心组件,是请求的入口,负责协调各个组件工作 |
| MultipartResolver | 内容类型( Content-Type )为 multipart/* 的请求的解析器,例如解析处理文件上传的请求,便于获取参数信息以及上传的文件 |
| HandlerMapping | 请求的处理器匹配器,负责为请求找到合适的HandlerExecutionChain 处理器执行链,包含处理器( handler )和拦截器( interceptors ) |
| HandlerAdapter | 处理器的适配器。因为处理器 handler 的类型是 Object 类型,需要有一个调用者来实现 handler 是怎么被执行。Spring 中的处理器的实现多变,比如用户处理器可以实现Controller 接口、HttpRequestHandler 接口,也可以用@RequestMapping 注解将方法作为一个处理器等,这就导致 Spring MVC 无法直接执行这个处理器。所以这里需要一个处理器适配器,由它去执行处理器 |
| HandlerExceptionResolver | 处理器异常解析器,将处理器( handler )执行时发生的异常,解析( 转换 )成对应的 ModelAndView 结果 |
| RequestToViewNameTranslator | 视图名称转换器,用于解析出请求的默认视图名 |
| LocaleResolver | 本地化(国际化)解析器,提供国际化支持 |
| ThemeResolver | 主题解析器,提供可设置应用整体样式风格的支持 |
| ViewResolver | 视图解析器,根据视图名和国际化,获得最终的视图 View对象 |
| FlashMapManager | FlashMap 管理器,负责重定向时,保存参数至临时存储(默认 Session) |
Spring MVC的拦截器
拦截器会对处理器进行拦截,这样通过拦截器就可以增强处理器的功能。Spring MVC中,所有的拦截器都需要实现HandlerInterceptor接口,该接口包含如下三个方法:preHandle()、postHandle()、afterCompletion()。
通过上图可以看出,Spring MVC拦截器的执行流程如下:
- 执行preHandle方法,它会返回一个布尔值。如果为false,则结束所有流程,如果为true,则执行下一步。
- 执行处理器逻辑,它包含控制器的功能。
- 执行postHandle方法。
- 执行视图解析和视图渲染。
- 执行afterCompletion方法。
Spring MVC拦截器的开发步骤如下:
-
开发拦截器:实现handlerInterceptor接口,从三个方法中选择合适的方法,实现拦截时要执行的具体业务逻辑。
-
注册拦截器:定义配置类,并让它实现WebMvcConfigurer接口,在接口的addInterceptors方法中,注册拦截器,并定义该拦截器匹配哪些请求路径。
怎么去做请求拦截?
-
如果是对Controller记性拦截,则可以使用Spring MVC的拦截器。
-
如果是对所有的请求(如访问静态资源的请求)进行拦截,则可以使用Filter。
-
如果是对除了Controller之外的其他Bean的请求进行拦截,则可以使用Spring AOP。
说一说你知道的Spring MVC注解
@RequestMapping:
作用:该注解的作用就是用来处理请求地址映射的,也就是说将其中的处理器方法映射到url路径上。
属性:
method:是让你指定请求的method的类型,比如常用的有get和post。
value:是指请求的实际地址,如果是多个地址就用{}来指定就可以啦。
produces:指定返回的内容类型,当request请求头中的Accept类型中包含指定的类型才可以返回的。
consumes:指定处理请求的提交内容类型,比如一些json、html、text等的类型。
headers:指定request中必须包含那些的headed值时,它才会用该方法处理请求的。
params:指定request中一定要有的参数值,它才会使用该方法处理请求。
@RequestParam:
作用:是将请求参数绑定到你的控制器的方法参数上,是Spring MVC中的接收普通参数的注解。
属性:
value是请求参数中的名称。
required是请求参数是否必须提供参数,它的默认是true,意思是表示必须提供。
@RequestBody:
作用:如果作用在方法上,就表示该方法的返回结果是直接按写入的Http responsebody中(一般在异步获取数据时使用的注解)。
属性:required,是否必须有请求体。它的默认值是true,在使用该注解时,值得注意的当为true时get的请求方式是报错的,如果你取值为false的话,get的请求是null。
@PathVaribale:
作用:该注解是用于绑定url中的占位符,但是注意,spring3.0以后,url才开始支持占位符的,它是Spring MVC支持的rest风格url的一个重要的标志。
Mybatis
什么是Mybatis?
Mybatis是一个半ORM框架,它内部封装了JDBC,开发时只需要关注SQL语句本身,使用 XML 或注解来配置和映射原生信息,将java对象映射成数据库中的记录,通过xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java对象和statement中sql的动态参数进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射为java对象并返回。
为什么说Mybatis是半ORM框架?与Hibernate有哪些不同?
ORM是对象和关系之间的映射,包括对象->关系和关系->对象两方面。Hibernate是个完整的ORM框架,而MyBatis只完成了关系->对象,准确地说MyBatis是SQL映射框架而不是ORM框架,因为其仅有字段映射,对象数据以及对象实际关系仍然需要通过手写SQL来实现和管理。
- Hibernate为完整的ORM框架,Mybatis为半ORM框架。
- Mybatis程序员直接编写原生sql,可严格控制sql执行性能,灵活度高,适用于对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等;Hibernate只能通过编写hql实现数据库查询(hql好难用哦)。
- Hibernate对象/关系映射能力强,数据库无关性好,适用于对关系模型要求高的软件; Mybatis的数据库无关性较差,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件。
Mybatis的优点?
- 基于SQL语句编程,不会对应用程序或者数据库的现有设计造成任何影响,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,重用性高。
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接;
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)。
- 能够与Spring很好的集成;
- 提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护。
MyBatis框架的缺点?
- SQL语句的编写工作量较大,尤其当字段多、关联表多时,
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
Mybatis都有哪些Executor执行器?区别是什么?
- **BaseExecutor:**基础抽象类,实现了executor接口的大部分方法,主要提供了缓存管理和事务管理的能力。
- **CachingExecutor:**直接实现Executor接口,使用装饰器模式提供二级缓存能力。先从二级缓存查,缓存没有命中再从数据库查,最后将结果添加到缓存中。
- **BatchExecutor:**BaseExecutor具体子类实现,在doUpdate方法中,提供批量执行多条SQL语句的能力。
- **SimpleExecutor:**BaseExecutor具体子类实现且为默认配置,在doQuery方法中使用PrepareStatement对象访问数据库, 每次访问都要创建新的 PrepareStatement对象;
- **ReuseExecutor:**BaseExecutor具体子类实现,与SimpleExecutor不同的是,在doQuery方法中,使用预编译PrepareStatement对象访问数据库,访问时,会重用缓存中的statement对象,而不是每次都创建新的PrepareStatement。
#{}和${}的区别?
- ${}是properties文件中的变量占位符,它可以用于标签属性值和sql内部,属于静态文本替换。传递的参数会被当成sql语句中的一部分
- #{}是sql的参数占位符,传入的数据都当成一个字符串,会对自动传入的数据加一个双引号,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值。
MyBatis的接口绑定有哪些实现方式?
- 通过xml里面写SQL来绑定,在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名.,name space一般在mapper标签中
- 还有一种是通过注解绑定,就是在接口的方法上面加上@Select@Update等注解里面包含Sql语句来绑定
使用MyBatis Mapper接口开发时有哪些要求?
- Mapper接口方法名和mapper.xml中定义的每个sql的id相同;
- Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;
- Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;
- Mapper.xml文件中的namespace即是mapper接口的类路径。
Mybatis的一级、二级缓存实现原理?
- 一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,Mybatis默认打开一级缓存,一级缓存存放在BaseExecutor的localCache变量中:
- 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace)级别。Mybatis默认不打开二级缓存,可以在config文件中xml开启全局的二级缓存,但并不会为所有的Mapper设置二级缓存,每个mapper.xml文件中使用标签来开启当前mapper的二级缓存,二级缓存存放在MappedStatement类cache变量中:
- 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被清除并重新更新,如果开启了二级缓存,则只根据配置判断是否刷新
什么是动态sql?
可以让我们在xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能:if 标签 、choose 标签、when 标签、otherwise 标签、foreach、set 标签、trim 标签、prefix 、suffix 、prefixesToOverride 、suffixesToOverride 。
MyBatis 是如何进行分页的?分页插件的原理是什么?
mybatis是使用分页插件PageHelper进行分页的, 其原理就是底层通过拦截器,进行拦截,然后根据传入的参数拼接sql中的limit,达到分页的效果。
mybatis工作原理是?
- 读取mybatis-config.xml配置文件,配置了mybatis运行环境等信息,例如数据库的连接信息
- 加载xml映射文件,其中主要配置了操作数据库的sql语句,在mybatis-config.xml可以加载多个映射文件,每一个映射文件相当于一张表,
- 构建会话工厂,sql session factory
- 会话工厂创建对应的sql session对象,该对象包含执行sql语句的所有方法
- Executor执行器,主要是在mybatis底层定义,能够根据sql session传递过来的对象动态生成需要执行所有的sql语句
- MappedStatement 是Executor对应的一个参数,是对映射信息的封装,用于存储sql语句的id,参数等信息,MappedStatement维护了一条
- 最后是sql session commit和 close关闭会话等操作
Mybatis动态sql执行原理?
- 初始化阶段:通过XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder解析XML文件中的信息存储到Configuration类中;
- 代理阶段:先从Configuration配置类MapperRegistry对象中获取mapper接口和对应的代理对象工厂信息,再利用代理对象工厂MapperProxyFactory创建实际代理类,最后在MapperProxy类中通过MapperMethod类对象内保存的中对应方法的信息,以及对应的sql语句的信息进行分析,最终确定对应的增强方法进行调用。
- 数据读写阶段:通过四种Executor调用四种Handler进行查询和封装数据;
resultType 与resultMap 的区别?
- 类的名字和数据库相同时,可以直接设置 resultType 参数为 Pojo 类
- 若不同,需要设置 resultMap 将结果名字和 Pojo 名字进行转换
JDBC编程有哪些不足之处,MyBatis是如何解决的?
- 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。**解决方法:**在mybatis-config.xml中配置数据链接池,使用连接池管理数据库连接。
- Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。**解决方法:**将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
- 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数——对应。解决方法: Mybatis自动将java对象映射至sql语句。
- 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。**解决方法:**Mybatis自动将sql执行结果映射至java对象。
简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系?
Mybatis将所有Xml配置信息都封装到Al-In-One重量级对象Contfiguration 内部。在Xml映射文件中,标签会被解析为ParameterMap对象,其每个子元素会被解析为ParameterMapping对象。标签会被解析为ResultMap对象,其每个子元素会被解析为ResutMapping对象。每一个、、、标签均会被解析为MappedStatement对象,标签内的sql会被解析为BoundSql对象。
为什么MyBatis Mapper接口中的方法不支持重载?
当不进行方法的重载时,即:每个方法都有唯一的命名时,在xml中进行映射后,就可以执行,不会出现异常。所以mybatis中mapper.xml是不会准确映射到Java中的重载方法的。最好不要在mapper接口中使用方法重载。
通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应, Dao 的工作原理,是否可以重载?
Dao 接口即 Mapper 接口。接口的全限名,就是映射文件中的 namespace 的值;接口的方法名,就是映射文件中 Mapper 的 Statement 的 id 值;接口方法内的参数,就是传递给 sql 的参数。Mapper 接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个 MapperStatement。在 Mybatis 中,每一个标签,都会被解析为一个MapperStatement 对象。
Mapper 接口里的方法,是不能重载的,因为是使用 全限名+方法名 的保存和寻找策略。Mapper 接口的工作原理是 JDK 动态代理,Mybatis 运行时会使用 JDK动态代理为 Mapper 接口生成代理对象 proxy,代理对象会拦截接口方法,转而执行 MapperStatement 所代表的 sql,然后将 sql 执行结果返回。
Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。
原因就是namespace+id是作为Map
什么是Xml标签?
Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?还有很多其他的标签,、、、、加上动态sql的9个标签:trim|wherelset|foreach|if|choose|when[otherwise|bind等。其中为sql片段标签,通过标签引入sql片段为不支持自增的主键生成策略标签。
Mapper 编写有哪几种方式?
- 第一种:接口实现类继承SqlSessionDaoSupport。使用此种方法需要编写mapper接口,mapper接口实现类、mapper.xml文件。
- 第二种:使用 org.mybatis.spring.mapper.MapperFactoryBean:在sqlMapConfig.xml中配置mapper.xml的位置,如果mapper.xml和mappre接口的名称相同且在同一个目录,这里可以不用配置;定义mapper接口;Spring中定义。
- 第三种:使用 mapper 扫描器:mapper.xml文件编写,定义 mapper 接口,配置 mapper 扫描器。
Mybatis中如何指定使用哪一种Executor执行器?
在Mybatis配置文件中,可以指定默认的ExecutorType执行器类型,也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数。
public Sqlsession openSession (ExecutorType execType)
当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
- 通过在查询的 sql 语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
- 通过来映射字段名和实体类属性名的一一对应的关系。
Mybatis是如何将sql执行结果封装为目标对象并返回的?
- 通过在查询的 sql 语句中定义字段名的别名,让字段名的别名和实体类的属性名一致。
- 使用 标签,定义数据库列名和对象属性名之间的映射关系。
- 使用注解 select 的字段名保持与接口方法返回的 Java 类或集合的元素类的属性名称一致。
Like如何使用?
where bar like "%"# {value}"%"
简述 Mybatis 的插件运行原理,以及如何编写一个插件?
Mybatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口的插件,Mybatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的 invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
编写插件:实现 Mybatis 的 Interceptor 接口并复写 intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
Mybatis 是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 Mybatis配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled = true|false。
它的原理是,使用 CGLIB 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用 a.getB().getName(),拦截器 invoke()方法发现 a.getB()是null 值,那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,然后调用 a.setB(b),于是 a 的对象 b 属性就有值了,接着完成 a.getB().getName()方法的调用。这就是延迟加载的基本原理。
如何执行批量插入?
创建简单的sql语句,存储对应的,比如说要插入一个name值list < string > names = new arraylist();往里面add对应的值,然后利用一个sql sessionfactory创建一个sql session,拿到对应的mapper后,利用循环往里面多次添加值,最后将sql session commit和close集合foreach标签主要是用于迭代 包括item index open close separator collection array list
如何获取自动生成的(主)键值?
insert 方法总是返回一个 int 值 ,这个值代表的是插入的行数。如果采用自增长策略,自动生成的键值在 insert 方法执行完后可以被设置到传入的参数对象中。比如说要插入对应的name值,调用insert方法后,通过name.getid可以获取,配置文件设置 usegeneratedkeys 为 true
在 mapper 中如何传递多个参数?
- DAO 层的函数:比如说用户对象public UserselectUser(String name,String area);对应的 xml,#{0}代表接收的是 dao 层中的第一个参数,#{1}代表 dao 层中第二参数,更多参数一致往后加即可。
- 使用 @param 注解:多个参数封装成 map。map.put(“start”, start);
Linux
Linux里如何查看一个想知道的进程?
查看进程运行状态的指令:ps命令。“ps -aux | grep PID”,用来查看某PID进程状态
Linux里如何查看带有关键字的日志文件?
cat 路径/文件名 | grep 关键词
Linux查看内存的命令是什么?
查看内存使用情况的指令:free命令。“free -m”,命令查看内存使用情况。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0HKjk9sv-1666488157650)(%E6%88%AA%E5%B1%8F2022-09-14%2016.06.01.png)]
total:内存总数
used:已使用的内存数
free:空闲的内存数
shared:当前已废弃不用
buffers:系统分配但未被使用的缓冲区
cached:系统分配但未被使用的缓存
top命令
显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
Linux中,如何通过端口查进程,如何通过进程查端口?
linux下通过进程名查看其占用端口:
(1)先查看进程pid
ps -ef | grep 进程名
(2)通过pid查看占用端口
netstat -nap | grep 进程pid
linux通过端口查看进程:
netstat -nap | grep 端口号
请你说说ping命令?
Linux ping命令用于检测主机。
执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。
文件权限怎么修改
Linux文件的基本权限就有九个,分别是owner(user)/group/others三种身份各有自己的read/write/execute权限
修改权限指令:chmod 权限名 文件名
(1)只读:表示允许读取内容,而禁止其对该文件做其他任何操作
字母表示:r
数字表示:权限值4
(2)只写:表示只允许对该文件进行编辑,而禁止对其进行其他任何操作
字母表示:w
数字表示:权限值2
(3)可执行:允许将该文件作为一个可执行程序
字母表示:x
数字表示:权限值1
(4)无任何权限
字母表示:-
数字表示:权限值0
说说常用的Linux命令
cd命令:用于切换当前目录
ls命令:查看当前文件与目录
grep命令:该命令常用于分析一行的信息,若当中有我们所需要的信息,就将该行显示出来,该命令通常与管道命令一起使用,用于对一些命令的输出进行筛选加工。
cp命令:复制命令
mv命令:移动文件或文件夹命令
rm命令:删除文件或文件夹命令
ps命令:查看进程情况
kill命令:向进程发送终止信号
tar命令:对文件进行打包,调用gzip或bzip对文件进行压缩或解压
cat命令:查看文件内容,与less、more功能相似
top命令:可以查看操作系统的信息,如进程、CPU占用率、内存信息等
pwd命令:命令用于显示工作目录。
说说软链接和硬链接的区别。
1.定义不同
软链接又叫符号链接,这个文件包含了另一个文件的路径名。可以是任意文件或目录,可以链接不同文件系统的文件。
硬链接就是一个文件的一个或多个文件名。把文件名和计算机文件系统使用的节点号链接起来。因此我们可以用多个文件名与同一个文件进行链接,这些文件名可以在同一目录或不同目录。
2.限制不同
硬链接只能对已存在的文件进行创建,不能交叉文件系统进行硬链接的创建;
软链接可对不存在的文件或目录创建软链接;可交叉文件系统;
3.创建方式不同
硬链接不能对目录进行创建,只可对文件创建;
软链接可对文件或目录创建;
4.影响不同
删除一个硬链接文件并不影响其他有相同 inode 号的文件。
删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
说说什么是大端小端,如何判断大端小端?
小端模式:低的有效字节存储在低的存储器地址。小端一般为主机字节序
大端模式:高的有效字节存储在低的存储器地址。大端为网络字节序
请你说说Linux的fork的作用
fork函数用来创建一个子进程。对于父进程,fork()函数返回新创建的子进程的PID。对于子进程,fork()函数调用成功会返回0。如果创建出错,fork()函数返回-1。
请你说说什么是孤儿进程,什么是僵尸进程,如何解决僵尸进程
孤儿进程:是指一个父进程退出后,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并且由init进程对它们完整状态收集工作。
僵尸进程:是指一个进程使用fork函数创建子进程,如果子进程退出,而父进程并没有调用wait()或者waitpid()将子进程释放,那么子进程的进程描述符仍然保存在系统中,占用系统资源,这种进程称为僵尸进程。
僵尸进程的危害
- 如果系统中存在很多僵尸进程,会一直占用系统资源,进程号会被它们一直占用。
- 这时,有限的进程号将会耗尽,使得系统无法fork新的子进程。
如何解决僵尸进程:
一般,为了防止产生僵尸进程,在fork子进程之后我们都要及时使用wait系统调用;同时,当子进程退出的时候,内核都会给父进程一个SIGCHLD信号,所以我们可以建立一个捕获SIGCHLD信号的信号处理函数,在函数体中调用wait(或waitpid),就可以清理退出的子进程以达到防止僵尸进程的目的。
请你说说什么是守护进程,如何实现?
守护进程:守护进程是运行在后台的一种生存期长的特殊进程。它独立于控制终端,处理一些系统级别任务。
如何实现:
(1)创建子进程,终止父进程。方法是调用fork() 产生一个子进程,然后使父进程退出。
(2)调用setsid() 创建一个新会话。
(3)将当前目录更改为根目录。使用fork() 创建的子进程也继承了父进程的当前工作目录。
(4)重设文件权限掩码。文件权限掩码是指屏蔽掉文件权限中的对应位。
(5)关闭不再需要的文件描述符。子进程从父进程继承打开的文件描述符。
互斥量能不能在进程中使用?
能。不同的进程之间,存在资源竞争或并发使用的问题,所以需要互斥量。
进程中也需要互斥量,因为一个进程中可以包含多个线程,线程与线程之间需要通过互斥的手段进行同步,避免导致共享数据修改引起冲突。可以使用互斥锁,属于互斥量的一种。
说说常见信号有哪些,表示什么含义?
| SIGHUP | 该信号让进程立即关闭.然后重新读取配置文件之后重启 |
|---|---|
| SIGINT | 程序中止信号,用于中止前台进程。相当于输出 Ctrl+C 快捷键 |
说说sleep和wait的区别?
Sleep:sleep是一个延时函数,让进程或线程进入休眠。休眠完毕后继续运行。
Wait:wait是父进程回收子进程PCB资源的一个系统调用。进程一旦调用了wait函数,就立即阻塞自己本身,然后由wait函数自动分析当前进程的某个子进程是否已经退出,当找到一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞,直到有一个出现为止。
说说线程池的设计思路,线程池中线程的数量由什么确定?
设计思路:
线程池在内部实际上构建了一个生产者–消费者模型,将线程和任务解耦,不直接关联。所以我们可以将线程池的运行分为两部分:线程管理、任务管理。
任务管理部分充当生产者
线程管理部分充当消费者
实现线程池有以下几个步骤:
(1)设置一个生产者消费者队列,作为临界资源。
(2)初始化n个线程,并让其运行起来,加锁去队列里取任务运行
(3)当任务队列为空时,所有线程阻塞。
(4)当生产者队列来了一个任务后,先对队列加锁,把任务挂到队列上,然后使用条件变量去通知阻塞中的一个线程来处理。
提前申请好对应的内存,放到内存池里面,用一个链表管理对应的内存池
线程池也是,提前准备好线程,放到这里面
创建线程使用的是pthread_create
使对应的线程睡眠pthread_cond_wait
唤醒对应的线程pthread_cond_signal 条件变量
线程池第一步:首先声明一个任务队列里面每一个节点存放对应的任务指针,指向相应的任务函数,然后还需要准备,任务函数需要的参数,以及下一个元素的地址
第二步:再定义一个线程池的结构体:线程池里面也需要定义对应的任务队列的头指针,尾指针,线程的数量,以及线程号,用一个指针来表示pthread_t,同时还有对应的线程号,互斥锁pthread_mutext_tmutex,还有对应的条件按变量pthread_cond_t,同时还需要线程池的状态,是否关闭
使用到互斥锁,访问队列,主线程,往队列中放任务,子线程取出对应的队列开始执行
还有任务队列 ,来了一个任务,唤醒线程,从队列中获取
第三步:在线程池的构造函数里面,我们首先申请线程池的内存,初始化线程池,然后初始化任务队列,对于第一个任务队列的节点,头指针和尾指针均指向这个任务队列
还要初始化线程数量,以及对应的线程号,线程号也需要利用pthrea_t申请多个内存空间用来存放不同的线程
接下来使用的是循环通过pthread_create来创建10个对应的线程,其中主要是传入对应的线程id以及线程的工作函数,还有对应的线程池,每一个线程运行结束之后释放内存pthread_detach
我们在对应的线程的工作函数中,传入的变量是线程池,获取对应的线程池,因为同时个线程池上锁(访问任务队列要先给线程池上锁,利用的是pthread_mytex_lock这个函数)
也要加一个while循环进行判断,如果任务队列队头与队尾相同,并且线程没有关闭,需要将线程进行睡眠,(使用的是pthread_con_wait传入对应的条件变量以及互斥锁,要把互斥锁进行释放)
第四步:创建号主线程之后,我们需要往任务队列中添加50个任务,每一个节点包括对应的函数地址,参数,并且唤醒线程池中的线程,发送对应的信号,pthread_cond_signal
唤醒所有线程后,又进入了线程池的工作函数,从任务队列中获取任务,执行节点的任务函数,然后如果所有任务被执行完了, 线程池就会继续关闭,进入休眠状态
接下来,判断任务队列如果不为空,我们需要从任务队列当中获取一个任务,同时将线程池的队列头指针指向下一个节点,再继续释放对应的互斥锁,同时唤醒相应的线程
说说多路IO复用技术有哪些,区别是什么?
select,poll,epoll都是IO多路复用的机制,I/O多路复用就是通过一种机制,可以监视多个文件描述符,一旦某个文件描述符就绪(一般是读就绪或者写就绪),能够通知应用程序进行相应的读写操作。
区别:
(1)poll与select不同,通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制,pollfd中的events字段和revents分别用于标示关注的事件和发生的事件,故pollfd数组只需要被初始化一次。
(2)select,poll实现需要自己不断轮询所有fd(文件描述符)集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。
(3)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把当前进程往设备等待队列中挂一次,而epoll只要一次拷贝,而且把当前进程往等待队列上挂也只挂一次,这也能节省不少的开销。
简述socket中select,epoll的使用场景和区别,epoll水平触发与边缘触发的区别
select,epoll的使用场景:都是IO多路复用的机制,应用于高并发的网络编程的场景。I/O多路复用就是通过一种机制,可以监视多个文件描述符,一旦某个文件描述符就绪(一般是读就绪或者写就绪),能够通知应用程序进行相应的读写操作。
select,epoll的区别:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;而epoll保证了每个fd在整个过程中只会拷贝一次。
(2)每次调用select都需要在内核遍历传递进来的所有fd;而epoll只需要轮询一次fd集合,同时查看就绪链表中有没有就绪的fd就可以了。
(3)select支持的文件描述符数量太小了,默认是1024;而epoll没有这个限制,它所支持的fd上限是最大可以打开文件的数目,这个数字一般远大于2048。
epoll水平触发与边缘触发的区别
LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
说一下epoll的原理,它的查询速度是O(1)的吗
epoll是一种更加高效的IO多路复用的方式,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。时间复杂度为O(1)。
(1)创建红黑树,调用epoll_create()创建一颗空的红黑树,用于存放FD及其感兴趣事件;
(2)注册感兴趣事件,调用epoll_ctl()向红黑树中添加节点(FD及其感兴趣事件),时间复杂度O(logN),向内核的中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它添加到就绪队列中。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到就绪队列中了;
(3)获取就绪事件,调用epoll_wait()返回就绪队列中的就绪事件,时间复杂度O(1);
说说Reactor、Proactor模式。
在高性能的I/O设计中,有两个比较著名的模式Reactor和Proactor模式,其中Reactor模式用于同步I/O,而Proactor运用于异步I/O操作。
BIO、NIO有什么区别
BIO(Blocking I/O):阻塞IO。调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的检查这个函数有没有返回,必须等这个函数返回后才能进行下一步动作。
NIO(New I/O):同时支持阻塞与非阻塞模式,NIO的做法是叫一个线程不断的轮询每个IO的状态,看看是否有IO的状态发生了改变,从而进行下一步的操作。
请介绍一下5种IO模型
阻塞IO:调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的检查这个函数有没有返回,必须等这个函数返回后才能进行下一步动作。
非阻塞IO:非阻塞等待,每隔一段时间就去检查IO事件是否就绪。没有就绪就可以做其他事情。
信号驱动IO:Linux用套接口进行信号驱动IO,安装一个信号处理函数,进程继续运行并不阻塞,当IO事件就绪,进程收到SIGIO信号,然后处理IO事件。
IO多路复用:Linux用select/poll函数实现IO复用模型,这两个函数也会使进程阻塞,但是和阻塞IO所不同的是这两个函数可以同时阻塞多个IO操作。而且可以同时对多个读操作、写操作的IO函数进行检查。知道有数据可读或可写时,才真正调用IO操作函数。
异步IO:Linux中,可以调用aio_read函数告诉内核描述字缓冲区指针和缓冲区的大小、文件偏移及通知的方式,然后立即返回,当内核将数据拷贝到缓冲区后,再通知应用程序。用户可以直接去使用数据。
答案解析
前四种模型–阻塞IO、非阻塞IO、多路复用IO和信号驱动IO都属于同步模式,因为其中真正的IO操作(函数)都将会阻塞进程,只有异步IO模型真正实现了IO操作的异步性。
异步和同步的区别就在于,异步是内核将数据拷贝到用户区,不需要用户再自己接收数据,直接使用就可以了,而同步是内核通知用户数据到了,然后用户自己调用相应函数去接收数据。
请说一下socket网络编程中客户端和服务端用到哪些函数?
服务器端函数:
(1)socket创建一个套接字
(2)bind绑定ip和port
(3)listen使套接字变为可以被动链接
(4)accept等待客户端的链接
(5)write/read接收发送数据
(6)close关闭连接
客户端函数:
(1)创建一个socket,用函数socket()
(2)bind绑定ip和port
(3)连接服务器,用函数connect()
(4)收发数据,用函数send()和recv(),或read()和write()
(5)close关闭连接
CPU调度的最小单位是什么?线程需要CPU调度吗?
进程是CPU分配资源的最小单位,线程是CPU调度的最小单位。
线程是比进程更小的能独立运行的基本单位,需要通过CPU调度来切换上下文,达到并发的目的。
内存和缓存有什么区别?
内存和缓存是计算机不同的组成部件。
内存特性
内存也被称作内存储器,其作用是用于暂时存放CPU的运算数据,以及与硬盘等外部存储交换的数据。只要计算机在运行中,CPU就会把需要进行运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
缓存特性
CPU芯片面积和成本的因素影响,决定了缓存都很小。现在一般的缓存不过几M,CPU缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。
什么是文件描述符
当打开一个现存文件或创建一个新文件时,内核就向进程返回一个文件描述符;当需要读写文件时,也需要把文件描述符作为参数传递给相应的函数。
文件描述符是一个非负的整数,它是一个索引值,并指向在内核中每个进程打开文件的记录表。
创建文件:Creat传入文件名,以及对应的权限00400 00200表示当前用户可读可写,返回文件描述符
系统io
Int fd=Open(“hello.c”,O_RDWR)
Ssize_t size=write(fd,s,strlen(s))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pCeWHvWv-1666488157651)(image-20220915152548830.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W9Ls0N8H-1666488157651)(image-20220915152558350.png)]
系统io拷贝:用open分别打开两个文件,再利用write往其中写入数据
标准io
标准io:采用的是标准io库比如说c语言的fopen,fwrite
标准I/O提供缓存的目的就是减少调用read和write的次数,它对每个I/O流自动进行缓存管理(标准I/O函数通常调用malloc来分配缓存) 。
它提供了三种类型的缓存:
1)全缓存。当填满标准I/O缓存后才执行I/O操作。磁盘上的文件通常是全缓存的。
2)行缓存。当输入输出遇到新行符或缓存满时,才由标准I/O库执行实际I/O操作。stdin、 stdout通常是行缓存的。
3)无缓存。相当于read、write 了。stderr通常是无缓存的,因为它必须尽快输出。
进程与程序的区别
进程是动态的,程序是静态的:程序是有序代码的集合;进程是程序的执行。
进程不可在计算机之间迁移;而程序通常对应着文件、静态和可以复制
进程是暂时的,程序使长久的
进程是一个状态变化的过程, 程序可长久保存
进程与程序组成不同:进程的组成包括程序、数据和进程控制块(即进程状态信息)
进程与程序的对应关系:通过多次执行,一个程序可对应多个进程;一个进程可包括多个程序。
进程互斥
是指当有若干进程都要使用某一共享资源时, 任何时刻最多允许一个进程使用,其他要使用该资源的进程必须等待,直到占用该资源者释放了该资源为止;
操作系统中将一次只允许一个进程访问的资源称为临界资源;
进程中访问临界资源的那段程序代码称为临界区,为实现对临界资源的互斥访问,应保证诸进程互斥地进入各自的临界区;
Vfork创建子进程需要指定退出方式
vfork(void)功能:创建子进程
vfork()会产生一个新的子进程, 其子进程会共享父进程的数据与堆栈空间,并继承父进程的用户代码、组代码、环境变量、已打开的文件代码、工作目录和资源限制等;
子进程不会继承父进程的文件锁定和未处理的信号;
注意,vfork产生的子进程,一定是子进程先执行、父进程后执行。
exec用于启动一个不相关的新的进程,被执行的程序替换调用它的程序。exec和fork区别:
fork创建一个新的进程(子进程) ,产生一个新的PID.
exec启动一个新程序,替换原有的进程,因此进程的PID不会改变。
消息队列
主要是msgget用来获取创建消息队列,要设置消息的类型,msgsnd和msgrcv用来发送和读取数据,主要是传递字符串的地址
int msgget(key_t key, int msgflg);
参数:
key:ftok() 返回的 key 值。
msgflg:标识函数的行为及消息队列的权限,其取值如下:
IPC_CREAT:创建消息队列;
IPC_EXCL: 检测消息队列是否存在;
位或权限位:消息队列位或权限位后可以设置消息队列的访问权限,格式和open() 函数的 mode_t 一样(open() 的使用请点此链接),但可执行权限未使用。
返回值:成功:消息队列的标识符,失败:-1。
int msgsnd( int msqid, const void *msgp, size_t msgsz, int msgflg);
参数:
msqid: 消息队列的标识符;
msgp: 待发送消息结构体的地址;
msgsz: 消息正文的字节数;
msgflg:函数的控制属性,其取值如下:
0:msgsnd() 调用阻塞直到条件满足为止。
IPC_NOWAIT:若消息没有立即发送则调用该函数的进程会立即返回。
返回值:成功:0,失败:-1。
删除消息队列msgctl
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
redis
Redis可以用来做什么?
-
Redis最常用来做缓存,是实现分布式缓存的首先中间件;
-
Redis可以作为数据库,实现诸如点赞、关注、排行等对性能要求极高的互联网需求;
-
Redis可以作为计算工具,能用很小的代价,统计诸如PV/UV、用户在线天数等数据;
-
Redis还有很多其他的使用场景,例如:可以实现分布式锁,可以作为消息队列使用。
Redis和传统的关系型数据库有什么不同?
Redis是一种基于键值对的NoSQL数据库,而键值对的值是由多种数据结构和算法组成的。Redis的数据都存储于内存中,因此它的速度惊人,读写性能可达10万/秒,远超关系型数据库。
关系型数据库是基于二维数据表来存储数据的,它的数据格式更为严谨,并支持关系查询。关系型数据库的数据存储于磁盘上,可以存放海量的数据,但性能远不如Redis。
Redis有哪些数据类型?
-
Redis支持5种核心的数据类型,分别是字符串、哈希、列表、集合、有序集合;
-
Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的;
-
Redis在5.0新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列。
Redis是单线程的,为什么还能这么快?
-
对服务端程序来说,线程切换和锁通常是性能杀手,而单线程避免了线程切换和竞争所产生的消耗;
-
Redis的大部分操作是在内存上完成的,这是它实现高性能的一个重要原因;
-
Redis采用了IO多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率。
Redis在持久化时fork出一个子进程,这时有两个进程了,怎么能说是单线程呢?
Redis是单线程的,主要是指Redis的网络IO和键值对读写是由一个线程来完成的。而Redis的其他功能,如持久化、异步删除、集群数据同步等,则是依赖其他线程来执行的。所以,说Redis是单线程的只是一种习惯的说法,事实上它的底层不是单线程的。
set和zset有什么区别?
set:
-
集合中的元素是无序、不可重复的,一个集合最多能存储232-1个元素;
-
集合除了支持对元素的增删改查之外,还支持对多个集合取交集、并集、差集。
zset:
-
有序集合保留了集合元素不能重复的特点;
-
有序集合会给每个元素设置一个分数,并以此作为排序的依据;
-
有序集合不能包含相同的元素,但是不同元素的分数可以相同。
zset对象的底层数据结构包括:压缩列表、字典、跳跃表。
压缩列表:压缩列表(ziplist),是Redis为了节约内存而设计的一种线性数据结构,它是由一系列具有特殊编码的连续内存块构成的。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或一个整数值。
字典:字典(dict)又称为散列表,是一种用来存储键值对的数据结构。C语言没有内置这种数据结构,所以Redis构建了自己的字典实现。
跳跃表:跳跃表的查找复杂度为平均O(logN),最坏O(N),效率堪比红黑树,却远比红黑树实现简单。跳跃表是在链表的基础上,通过增加索引来提高查找效率的。
Redis中的watch命令
很多时候,要确保事务中的数据没有被其他客户端修改才执行该事务。Redis提供了watch命令来解决这类问题,这是一种乐观锁的机制。客户端通过watch命令,要求服务器对一个或多个key进行监视,如果在客户端执行事务之前,这些key发生了变化,则服务器将拒绝执行客户端提交的事务,并向它返回一个空值。
Redis中List结构的相关操作
列表是线性有序的数据结构,它内部的元素是可以重复的,并且一个列表最多能存储2^32-1个元素。列表包含如下的常用命令:
lpush/rpush:从列表的左侧/右侧添加数据;
lrange:指定索引范围,并返回这个范围内的数据;
lindex:返回指定索引处的数据;
lpop/rpop:从列表的左侧/右侧弹出一个数据;
blpop/brpop:从列表的左侧/右侧弹出一个数据,若列表为空则进入阻塞状态。
你要如何设计Redis的过期时间?
热点数据不设置过期时间,使其达到“物理”上的永不过期,可以避免缓存击穿问题;
在设置过期时间时,可以附加一个随机数,避免大量的key同时过期,导致缓存雪崩。
Redis中,sexnx命令的返回值是什么,如何使用该命令实现分布式锁?
setnx命令返回整数值,当返回1时表示设置值成果,当返回0时表示设置值失败(key已存在)。
一般我们不建议直接使用setnx命令来实现分布式锁,因为为了避免出现死锁,我们要给锁设置一个自动过期时间。而setnx命令和设置过期时间的命令不是原子的,可能加锁成果而设置过期时间失败,依然存在死锁的隐患。对于这种情况,Redis改进了set命令,给它增加了nx选项,启用该选项时set命令的效果就会setnx一样了。
何时需要分布式锁?
在分布式的环境下,当多个server并发修改同一个资源时,为了避免竞争就需要使用分布式锁。那为什么不能使用Java自带的锁呢?因为Java中的锁是面向多线程设计的,它只局限于当前的JRE环境。而多个server实际上是多进程,是不同的JRE环境,所以Java自带的锁机制在这个场景下是无效的。
加锁:
-
第一版,这种方式的缺点是容易产生死锁,因为客户端有可能忘记解锁,或者解锁失败。setnx key value
-
第二版,给锁增加了过期时间,避免出现死锁。但这两个命令不是原子的,第二步可能会失败,依然无法避免死锁问题。setnx key value expire key seconds
-
第三版,通过“set…nx…”命令,将加锁、过期命令编排到一起,它们是原子操作了,可以避免死锁。set key value nx ex seconds
解锁:解锁就是删除代表锁的那份数据。del key。
说一说Redis的持久化策略
Redis支持RDB持久化、AOF持久化、RDB-AOF混合持久化这三种持久化方式。
RDB:RDB(Redis Database)是Redis默认采用的持久化方式,它以快照的形式将进程数据持久化到硬盘中。RDB会创建一个经过压缩的二进制文件,文件以“.rdb”结尾,内部存储了各个数据库的键值对数据等信息。RDB持久化的触发方式有两种:
-
手动触发:通过SAVE或BGSAVE命令触发RDB持久化操作,创建“.rdb”文件;
-
自动触发:通过配置选项,让服务器在满足指定条件时自动执行BGSAVE命令。
RDB持久化的优缺点如下:
-
优点:RDB生成紧凑压缩的二进制文件,体积小,使用该文件恢复数据的速度非常快;
-
缺点:BGSAVE每次运行都要执行fork操作创建子进程,属于重量级操作,不宜频繁执行,所以RDB持久化没办法做到实时的持久化。
AOF:AOF(Append Only File),解决了数据持久化的实时性,是目前Redis持久化的主流方式。AOF以独立日志的方式,记录了每次写入命令,重启时再重新执行AOF文件中的命令来恢复数据。AOF的工作流程包括:命令写入(append),在缓冲里面文件同步(sync)、Aof文件重写(rewrite)、重启加载(load):
AOF持久化的文件同步机制:
为了提高程序的写入性能,现代操作系统会把针对硬盘的多次写操作优化为一次写操作。当程序调用write对文件写入时,系统不会直接把书记写入硬盘,而是先将数据写入内存的缓冲区中;当达到特定的时间周期或缓冲区写满时,系统才会执行flush操作,将缓冲区中的数据冲洗至硬盘中;
这种优化机制虽然提高了性能,但也给程序的写入操作带来了不确定性。对于AOF这样的持久化功能来说,冲洗机制将直接影响AOF持久化的安全性;为了消除上述机制的不确定性,Redis向用户提供了appendfsync选项,来控制系统冲洗AOF的频率;
Linux的glibc提供了fsync函数,可以将指定文件强制从缓冲区刷到硬盘,上述选项正是基于此函数。
AOF持久化的优缺点如下:
优点:与RDB持久化可能丢失大量的数据相比,AOF持久化的安全性要高很多。通过使用everysec选项,用户可以将数据丢失的时间窗口限制在1秒之内。
缺点:AOF文件存储的是协议文本,它的体积要比二进制格式的”.rdb”文件大很多。AOF需要通过执行AOF文件中的命令来恢复数据库,其恢复速度比RDB慢很多。AOF在进行重写时也需要创建子进程,在数据库体积较大时将占用大量资源,会导致服务器的短暂阻塞。
如何实现Redis的高可用?(哨兵,集群)
哨兵:Redis Sentinel(哨兵)是一个分布式架构,它包含若干个哨兵节点和数据节点。每个哨兵节点会对数据节点和其余的哨兵节点进行监控,当发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它就会与其他的哨兵节点进行协商,当多数哨兵节点都认为主节点不可达时,它们便会选举出一个哨兵节点来完成自动故障转移的工作,同时还会将这个变化实时地通知给应用方。整个过程是自动的,不需要人工介入,有效地解决了Redis的高可用问题!
集群:使用一个或者多个哨兵(Sentinel)实例组成的系统,对redis节点进行监控,在主节点出现故障的情况下,能将从节点中的一个升级为主节点,进行故障转义,保证系统的可用性。
故障转义:当一个Master不能正常工作时,哨兵通过投票协议会开始一次自动故障迁移操作,它会将其他一个Slave升级为新的Master。该模式主从可以切换,故障可以转移,系统的可用性就会更好。但是需要额外的资源来启动哨兵进程。
如果并发量超过30万,怎么设计Redis架构?
主从架构 -> 读写分离 -> 支持10万+读QPS架构。
Redis集群的通信方案:
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障等状态信息。常见的元数据维护方式分为:集中式和P2P方式。
Redis集群采用P2P的Gossip(流言)协议,Gossip协议的工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播。通信的大致过程如下:
- 集群中每个节点都会单独开辟一个TCP通道,用于节点之间彼此通信,通信端口号在基础端口号上加10000;
- 每个节点再固定周期内通过特定规则选择几个节点发送ping消息;
- 接收ping消息的节点用pong消息作为响应。
Gossip协议的主要职责就是信息交换Gossip消息分为:meet消息、ping消息、pong消息、fail消息等。
meet消息:用于通知新节点加入,消息发送者通知接受者加入到当前集群。meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换。
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息。ping消息封装了自身节点和一部分其他节点的状态数据。
pong消息:当接收到meet、ping消息时,作为响应消息回复给发送方确认消息正常通信。pong消息内封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新。
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态。
Redis集群的分片机制(多台Redis抗高并发访问)
Redis集群采用虚拟槽分区来实现数据分片,它把所有的键根据哈希函数映射到0-16383整数槽内,计算公式为slot=CRC16(key)&16383,每一个节点负责维护一部分槽以及槽所映射的键值数据。虚拟槽分区具有如下特点:
-
解耦数据和节点之间的关系,简化了节点扩容和收缩的难度;
-
节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据;
-
支持节点、槽、键之间的映射查询,用于数据路由,在线伸缩等场景。
说一说Redis集群的应用和优劣势
**优势:**Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
劣势:
-
key批量操作支持有限。如mset、mget,目前只支持具有相同slot值的key执行批量操作。对于映射为不同slot值的key由于执行mset、mget等操作可能存在于多个节点上所以不被支持。
-
key事务操作支持有限。同理只支持多key在同一节点上的事务操作,当多个key分布在不同的节点上时无法使用事务功能。
-
key作为数据分区的最小粒度,因此不能将一个大的键值对象(如hash、list等)映射到不同的节点。
-
不支持多数据库空间。单机下的Redis可以支持16个数据库,集群模式下只能使用一个数据库空间,即DB0。
-
复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
缓存穿透、缓存击穿、缓存雪崩有什么区别,该如何解决?
缓存穿透:
问题描述:
客户端查询根本不存在的数据,使得请求直达存储层,导致其负载过大,甚至宕机。出现这种情况的原因,可能是业务层误将缓存和库中的数据删除了,也可能是有人恶意攻击,专门访问库中不存在的数据。
解决方案:
缓存空对象:存储层未命中后,仍然将空值存入缓存层,客户端再次访问数据时,缓存层会直接返回空值。
布隆过滤器:将数据存入布隆过滤器,访问缓存之前以过滤器拦截,若请求的数据不存在则直接返回空值。
缓存击穿:
问题描述:
一份热点数据,它的访问量非常大。在其缓存失效的瞬间,大量请求直达存储层,导致服务崩溃。
解决方案:
永不过期:热点数据不设置过期时间,所以不会出现上述问题,这是“物理”上的永不过期。或者为每个数据设置逻辑过期时间,当发现该数据逻辑过期时,使用单独的线程重建缓存。
加互斥锁:对数据的访问加互斥锁,当一个线程访问该数据时,其他线程只能等待。这个线程访问过后,缓存中的数据将被重建,届时其他线程就可以直接从缓存中取值。
缓存雪崩:
问题描述:
在某一时刻,缓存层无法继续提供服务,导致所有的请求直达存储层,造成数据库宕机。可能是缓存中有大量数据同时过期,也可能是Redis节点发生故障,导致大量请求无法得到处理。
解决方案:
避免数据同时过期:设置过期时间时,附加一个随机数,避免大量的key同时过期。
启用降级和熔断措施:在发生雪崩时,若应用访问的不是核心数据,则直接返回预定义信息/空值/错误信息。或者在发生雪崩时,对于访问缓存接口的请求,客户端并不会把请求发给Redis,而是直接返回。
构建高可用的Redis服务:采用哨兵或集群模式,部署多个Redis实例,个别节点宕机,依然可以保持服务的整体可用。
如何保证缓存与数据库的双写一致性?
想要保证缓存与数据库的双写一致,一共有4种方式,即4种同步策略:
-
先更新缓存,再更新数据库;
-
先更新数据库,再更新缓存;
-
先删除缓存,再更新数据库;
-
先更新数据库,再删除缓存。
更新缓存
优点:每次数据变化都及时更新缓存,所以查询时不容易出现未命中的情况。
缺点:更新缓存的消耗比较大。如果数据需要经过复杂的计算再写入缓存,那么频繁的更新缓存,就会影响服务器的性能。如果是写入数据频繁的业务场景,那么可能频繁的更新缓存时,却没有业务读取该数据。
删除缓存
优点:操作简单,无论更新操作是否复杂,都是将缓存中的数据直接删除。
缺点:删除缓存后,下一次查询缓存会出现未命中,这时需要重新读取一次数据库。
从上面的比较来看,一般情况下,删除缓存是更优的方案。
Redis的主从同步是如何实现的?
Redis使用psync命令完成主从数据同步,同步过程分为全量复制和部分复制。全量复制一般用于初次复制的场景,部分复制则用于处理因网络中断等原因造成数据丢失的场景。psync命令需要以下参数的支持:
复制偏移量:主节点处理写命令后,会把命令长度做累加记录,从节点在接收到写命令后,也会做累加记录;从节点会每秒钟上报一次自身的复制偏移量给主节点,而主节点则会保存从节点的复制偏移量。
积压缓冲区:保存在主节点上的一个固定长度的队列,默认大小为1M,当主节点有连接的从节点时被创建;主节点处理写命令时,不但会把命令发送给从节点,还会写入积压缓冲区;缓冲区是先进先出的队列,可以保存最近已复制的数据,用于部分复制和命令丢失的数据补救。
主节点运行ID:每个Redis节点启动后,都会动态分配一个40位的十六进制字符串作为运行ID;如果使用IP和端口的方式标识主节点,那么主节点重启变更了数据集(RDB/AOF),从节点再基于复制偏移量复制数据将是不安全的,因此当主节点的运行ID变化后,从节点将做全量复制。
Redis为什么存的快,内存断电数据怎么恢复?
Redis存的快是因为它的数据都存放在内存里,并且为了保证数据的安全性,Redis还提供了三种数据的持久化机制,即RDB持久化、AOF持久化、RDB-AOF混合持久化。若服务器断电,那么我们可以利用持久化文件,对数据进行恢复。理论上来说,AOF/RDB-AOF持久化可以将丢失数据的窗口控制在1S之内。
Redis为什么会比MySQL快
-
Redis是基于内存存储的,MySQL是基于磁盘存储的
-
Redis存储的是k-v格式的数据。时间复杂度是O(1),常数阶,而MySQL引擎的底层实现是B+Tree,时间复杂度是O(logn),对数阶。Redis会比MySQL快一点点。
-
MySQL数据存储是存储在表中,查找数据时要先对表进行全局扫描或者根据索引查找,这涉及到磁盘的查找,磁盘查找如果是按条点查找可能会快点,但是顺序查找就比较慢;而Redis不用这么麻烦,本身就是存储在内存中,会根据数据在内存的位置直接取出。
-
Redis是单线程的多路复用IO,单线程避免了线程切换的开销,而多路复用IO避免了IO等待的开销,在多核处理器下提高处理器的使用效率可以对数据进行分区,然后每个处理器处理不同的数据。
Redis的过期策略(删除策略)
惰性删除:客户端访问一个key的时候,Redis会先检查它的过期时间,如果发现过期就立刻删除这个key。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
定期删除:Redis会将设置了过期时间的key放到一个独立的字典中,并对该字典进行每秒10次的过期扫描,对内存友好。
过期扫描不会遍历字典中所有的key,而是采用了一种简单的贪心策略。该策略的删除逻辑如下:
从过期字典中随机选择20个key;
删除这20个key中已过期的key;
如果已过期key的比例超过25%,则重复步骤1。
Redis的缓存淘汰策略
- volatile-lru,针对设置了过期时间的key,使用lru算法进行淘汰。
- allkeys-lru,针对所有key使用lru算法进行淘汰。
- volatile-lfu,针对设置了过期时间的key,使用lfu算法进行淘汰。
- allkeys-lfu,针对所有key使用lfu算法进行淘汰。
- volatile-random,从所有设置了过期时间的key中使用随机淘汰的方式进行淘汰。
- allkeys-random,针对所有的key使用随机淘汰机制进行淘汰。
- volatile-ttl,删除生存时间最近的一个键。
- noeviction(默认),不删除键,值返回错误。
如何利用Redis实现分布式Session?
在web开发中,我们会把用户的登录信息存储在session里。而session是依赖于cookie的,即服务器创建session时会给它分配一个唯一的ID,并且在响应时创建一个cookie用于存储这个SESSIONID。当客户端收到这个cookie之后,就会自动保存这个SESSIONID,并且在下次访问时自动携带这个SESSIONID,届时服务器就可以通过这个SESSIONID得到与之对应的session,从而识别用户的身。
MQ(消息队列)有什么用?
消息队列有很多使用场景,比较常见的有3个:解耦、异步、削峰。
解耦:传统的软件开发模式,各个模块之间相互调用,数据共享,每个模块都要时刻关注其他模块的是否更改或者是否挂掉等等,使用消息队列,可以避免模块之间直接调用,将所需共享的数据放在消息队列中,对于新增业务模块,只要对该类消息感兴趣,即可订阅该类消息,对原有系统和业务没有任何影响,降低了系统各个模块的耦合度,提高了系统的可扩展性。
异步:消息队列提供了异步处理机制,在很多时候应用不想也不需要立即处理消息,允许应用把一些消息放入消息中间件中,并不立即处理它,在之后需要的时候再慢慢处理。
削峰:在访问量骤增的场景下,需要保证应用系统的平稳性,但是这样突发流量并不常见,如果以这类峰值的标准而投放资源的话,那无疑是巨大的浪费。使用消息队列能够使关键组件支撑突发访问压力,不会因为突发的超负荷请求而完全崩溃。消息队列的容量可以配置的很大,如果采用磁盘存储消息,则几乎等于“无限”容量,这样一来,高峰期的消息可以被积压起来,在随后的时间内进行平滑的处理完成,而不至于让系统短时间内无法承载而导致崩溃。在电商网站的秒杀抢购这种突发性流量很强的业务场景中,消息队列的强大缓冲能力可以很好的起到削峰作用。
说一说生产者与消费者模式
所谓生产者-消费者问题,实际上主要是包含了两类线程。一种是生产者线程用于生产数据,另一种是消费者线程用于消费数据,为了解耦生产者和消费者的关系,通常会采用共享的数据区域,就像是一个仓库。生产者生产数据之后直接放置在共享数据区中,并不需要关心消费者的行为。而消费者只需要从共享数据区中去获取数据,就不再需要关心生产者的行为。但是,这个共享数据区域中应该具备这样的线程间并发协作的功能:
如果共享数据区已满的话,阻塞生产者继续生产数据放置入内;如果共享数据区为空的话,阻塞消费者继续消费数据。
在Java语言中,实现生产者消费者问题时,可以采用三种方式
-
使用 Object 的 wait/notify 的消息通知机制;
-
使用 Lock 的 Condition 的 await/signal 的消息通知机制;
-
使用 BlockingQueue 实现。
消息队列如何保证消息不丢? 确保消息不丢失
丢数据一般分为两种,一种是mq把消息丢了,一种就是消费时将消息丢了。下面从rabbitmq和kafka分别说一下,丢失数据的场景。
RabbitMQ丢失消息分为如下几种情况:
生产者丢消息:
生产者将数据发送到RabbitMQ的时候,可能在传输过程中因为网络等问题而将数据弄丢了。
RabbitMQ自己丢消息:
如果没有开启RabbitMQ的持久化,那么RabbitMQ一旦重启数据就丢了。所以必须开启持久化将消息持久化到磁盘,这样就算RabbitMQ挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢失。除非极其罕见的情况,RabbitMQ还没来得及持久化自己就挂了,这样可能导致一部分数据丢失。
消费端丢消息:
主要是因为消费者消费时,刚消费到还没有处理,结果消费者就挂了,这样你重启之后,RabbitMQ就认为你已经消费过了,然后就丢了数据。
针对上述三种情况,RabbitMQ可以采用如下方式避免消息丢失:
生产者丢消息:
(1)可以选择使用RabbitMQ提供是事务功能,就是生产者在发送数据之前开启事务,然后发送消息,如果消息没有成功被RabbitMQ接收到,那么生产者会受到异常报错,这时就可以回滚事务,然后尝试重新发送。如果收到了消息,那么就可以提交事务。这种方式有明显的缺点,即RabbitMQ事务开启后,就会变为同步阻塞操作,生产者会阻塞等待是否发送成功,太耗性能会造成吞吐量的下降。
(2)可以开启confirm模式。在生产者那里设置开启了confirm模式之后,每次写的消息都会分配一个唯一的id,然后如何写入了RabbitMQ之中,RabbitMQ会给你回传一个ack消息,告诉你这个消息发送OK了。如果RabbitMQ没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
事务机制是同步的,你提交了一个事物之后会阻塞住,但是confirm机制是异步的,发送消息之后可以接着发送下一个消息,然后RabbitMQ会回调告知成功与否。 一般在生产者这块避免丢失,都是用confirm机制。
RabbitMQ自己丢消息:
(1)设置消息持久化到磁盘,设置持久化有两个步骤:
创建queue的时候将其设置为持久化的,这样就可以保证RabbitMQ持久化queue的元数据,但是不会持久化queue里面的数据。
发送消息的时候讲消息的deliveryMode设置为2,这样消息就会被设为持久化方式,此时RabbitMQ就会将消息持久化到磁盘上。 必须要同时开启这两个才可以。
而且持久化可以跟生产的confirm机制配合起来,只有消息持久化到了磁盘之后,才会通知生产者ack,这样就算是在持久化之前RabbitMQ挂了,数据丢了,生产者收不到ack回调也会进行消息重发。
消费端丢消息:
**使用RabbitMQ提供的ack机制,首先关闭RabbitMQ的自动ack,然后每次在确保处理完这个消息之后,在代码里手动调用ack。**这样就可以避免消息还没有处理完就ack。
消息队列如何保证不重复消费?
-
比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下。
-
比如你是写redis,那没问题了,反正每次都是set,天然幂等性。
-
比如你不是上面两个场景,那做的稍微复杂一点,你需要让生产者发送每条数据的时候,里面加一个全局唯一的id,类似订单id之类的东西,然后你这里消费到了之后,先根据这个id去比如redis里查一下,之前消费过吗?如果没有消费过,你就处理,然后这个id写redis。如果消费过了,那你就别处理了,保证别重复处理相同的消息即可。
MQ处理消息失败了怎么办?
一般生产环境中,都会在使用MQ的时候设计两个队列:一个是核心业务队列,一个是死信队列。核心业务队列,就是比如专门用来让订单系统发送订单消息的,然后另外一个死信队列就是用来处理异常情况的。
比如说要是第三方物流系统故障了,此时无法请求,那么仓储系统每次消费到一条订单消息,尝试通知发货和配送,都会遇到对方的接口报错。**此时仓储系统就可以把这条消息拒绝访问,或者标志位处理失败!**注意,这个步骤很重要。
**一旦标志这条消息处理失败了之后,MQ就会把这条消息转入提前设置好的一个死信队列中。**然后你会看到的就是,在第三方物流系统故障期间,所有订单消息全部处理失败,全部会转入死信队列。然后你的仓储系统得专门有一个后台线程,监控第三方物流系统是否正常,能否请求的,不停的监视。一旦发现对方恢复正常,这个后台线程就从死信队列消费出来处理失败的订单,重新执行发货和配送的通知逻辑。死信队列的使用,其实就是MQ在生产实践中非常重要的一环,也就是架构设计必须要考虑的。
请介绍消息队列推和拉的使用场景
推模式:推模式是服务器端根据用户需要,由目的、按时将用户感兴趣的信息主动发送到用户的客户端。
优点:对用户要求低,方便用户获取需要的信息;及时性好,服务器端及时地向客户端推送更新动态信息,吞吐量大。
缺点:不能确保发送成功,推模式采用广播方式,只有服务器端和客户端在同一个频道上,推模式才有效,用户才能接收到信息;没有信息状态跟踪,推模式采用开环控制技术,一个信息推送后的状态,比如客户端是否接收等,无从得知;针对性较差。推送的信息可能并不能满足客户端的个性化需求。
拉模式:拉模式是客户端主动从服务器端获取信息。
优点:针对性强,能满足客户端的个性化需求;信息传输量较小,网络中传输的只是客户端的请求和服务器端对该请求的响应;服务器端的任务轻。服务器端只是被动接收查询,对客户端的查询请求做出响应。
缺点:实时性较差,针对于服务器端实时更新的信息,客户端难以获取实时信息;对于客户端用户的要求较高,需要对服务器端具有一定的了解。
RabbitMQ和Kafka有什么区别?
在实际生产应用中,**通常会使用Kafka作为消息传输的数据管道,RabbitMQ作为交易数据作为数据传输管道,主要的取舍因素则是是否存在丢数据的可能。**RabbitMQ在金融场景中经常使用,具有较高的严谨性,数据丢失的可能性更小,同事具备更高的实时性。而Kafka优势主要体现在吞吐量上,虽然可以通过策略实现数据不丢失,但从严谨性角度来讲,大不如RabbitMQ。而且由于Kafka保证每条消息最少送达一次,有较小的概率会出现数据重复发送的情况。详细来说,它们之间主要有如下的区别:
应用场景方面
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。
Kafka:用于处于活跃的流式数据,大数据量的数据处理上。
架构模型方面
RabbitMQ:以broker为中心,有消息的确认机制。
Kafka:以consumer为中心,没有消息的确认机制。
吞吐量方面
RabbitMQ:支持消息的可靠的传递,支持事务,不支持批量操作,基于存储的可靠性的要求存储可以采用内存或硬盘,吞吐量小。
Kafka:内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。
集群负载均衡方面
RabbitMQ:本身不支持负载均衡,需要loadbalancer的支持。
Kafka:采用zookeeper对集群中的broker,consumer进行管理,可以注册topic到zookeeper上,通过zookeeper的协调机制,producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上,producer可以基于语义指定分片,消息发送到broker的某个分片上。
IO
字节流和字符流的区别?
字符流和字节流的使用非常相似,但是实际上字节流的操作不会经过缓冲区(内存)而是直接操作文本本身的,而字符流的操作会先经过缓冲区(内存)然后通过缓冲区再操作文件 。
以字节为单位输入输出数据,字节流按照8位传输,以字符为单位输入输出数据,字符流按照16位传输。
字节流如何转为字符流?
-
字节输入流转字符输入流通过 InputStreamReader 实现,该类的构造函数可以传入 InputStream 对象。
-
字节输出流转字符输出流通过 OutputStreamWriter 实现,该类的构造函数可以传入 OutputStream 对象。
Java中的IO流
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SAh68wYS-1666488157652)(image-20220921145945701-16640896969071.png)]
怎么用流打开一个大文件?
打开大文件,应避免直接将文件中的数据全部读取到内存中,可以采用分次读取的方式。
使用缓冲流。缓冲流内部维护了一个缓冲区,通过与缓冲区的交互,减少与设备的交互次数。使用NIO。NIO采用内存映射文件的方式来处理输入/输出,NIO将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样来访问文件了(这种方式模拟了操作系统上的虚拟内存的概念),通过这种方式来进行输入/输出比传统的输入/输出要快得多。
说说BIO、NIO和AIO的区别
Java BIO: 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO: 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO: 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
NIO比BIO的改善之处是把一些无效的连接挡在了启动线程之前,减少了这部分资源的浪费(因为我们都知道每创建一个线程,就要为这个线程分配一定的内存空间)
AIO比NIO的进一步改善之处是将一些暂时可能无效的请求挡在了启动线程之前,比如在NIO的处理方式中,当一个请求来的话,开启线程进行处理,但这个请求所需要的资源还没有就绪,此时必须等待后端的应用资源,这时线程就被阻塞了。
NIO的实现原理
Java的NIO主要由三个核心部分组成:Channel、Buffer、Selector。
-
基本上,所有的IO在NIO中都从一个Channel开始,数据可以从Channel读到Buffer中,也可以从Buffer写到Channel中。
-
Buffer本质上是一块可以写入数据,然后可以从中读取数据的内存。Buffer对象包含三个重要的属性,分别是capacity、position、limit,其中position和limit的含义取决于Buffer处在读模式还是写模式。capacity:作为一个内存块,Buffer有个固定的最大值,就是capacity。position:当写数据到Buffer中时,position表示当前的位置。limit:在写模式下,Buffer的limit表示最多能往Buffer里写多少数据,此时limit等于capacity。当切换Buffer到读模式时, limit表示你最多能读到多少数据,此时limit会被设置成写模式下的position值。
-
Selector允许单线程处理多个 Channel,如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。
NIO 和传统的 IO 有什么区别?
-
传统 IO 一般是一个线程等待连接,连接过来之后分配给 processor 线程,processor 线程与通道连接后如果通道没有数据过来就会阻塞(线程被动挂起)不能做别的事情。NIO 则不同,首先,在 selector 线程轮询的过程中就已经过滤掉了不感兴趣的事件,其次,在 processor处理感兴趣事件的 read 和 write 都是非阻塞操作即直接返回的,线程没有被挂起。
-
传统 io 的管道是单向的,nio 的管道是双向的。
-
两者都是同步的,也就是 java 程序亲力亲为的去读写数据,不管传统 io 还是 nio 都需要read 和 write 方法,这些都是 java 程序调用的而不是系统帮我们调用的,nio2.0 里这点得到了改观,即使用异步非阻塞 AsynchronousXXX 四个类来处理。
Java的序列化与反序列化
序列化机制可以将对象转换成字节序列,这些字节序列可以保存在磁盘上,也可以在网络中传输,并允许程序将这些字节序列再次恢复成原来的对象。其中,对象的序列化(Serialize),是指将一个Java对象写入IO流中,对象的反序列化(Deserialize),则是指从IO流中恢复该Java对象。
若对象要支持序列化机制,则它的类需要实现Serializable接口,该接口是一个标记接口,它没有提供任何方法,只是标明该类是可以序列化的,Java的很多类已经实现了Serializable接口,如包装类、String、Date等。
若要实现序列化,则需要使用对象流ObjectInputStream和ObjectOutputStream。其中,在序列化时需要调用ObjectOutputStream对象的writeObject()方法,以输出对象序列。在反序列化时需要调用ObjectInputStream对象的readObject()方法,将对象序列恢复为对象。
Serializable接口为什么需要定义serialVersionUID变量?
serialVersionUID代表序列化的版本,通过定义类的序列化版本,在反序列化时,只要对象中所存的版本和当前类的版本一致,就允许做恢复数据的操作,否则将会抛出序列化版本不一致的错误。
除了Java自带的序列化之外,你还了解哪些序列化工具?
JSON:目前使用比较频繁的格式化数据工具,简单直观,可读性好,有jackson,gson,fastjson等等。如果不用JSON工具,该如何实现对实体类的序列化?可以使用Java原生的序列化机制,但是效率比较低一些,适合小项目;可以使用其他的一些第三方类库,比如Protobuf、Thrift、Avro等。
如何实现对象克隆?
有两种方式:
-
实现 Cloneable 接口并重写 Object 类中的 clone()方法;
-
实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
Java 中 3 种常见 IO 模型
-
BIO (Blocking I/O):BIO 属于同步阻塞 IO 模型 。同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
-
NIO: IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
-
AIO (Asynchronous I/O):异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
什么是缓冲区?有什么作用?
缓冲区就是一段特殊的内存区域,很多情况下当程序需要频繁地操作一个资源(如文件或数据库)则性能会很低,所以为了提升性能就可以将一部分数据暂时读写到缓存区,以后直接从此区域中读写数据即可,这样就可以显著的提升性能。
对于 Java 字符流的操作都是在缓冲区操作的,所以如果我们想在字符流操作中主动将缓冲区刷新到文件则可以使用 flush() 方法操作。
并发
JAVA中有那些锁
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-obgehf4K-1666488157652)(4de4a864434073b848a3fb3d914356dc.png)]
Java中乐观锁和悲观锁的区别
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。Java中悲观锁是通过synchronized关键字或Lock接口来实现的。
乐观锁:顾名思义,就是很乐观,**每次去拿数据的时候都认为别人不会修改,所以不会上锁,**但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁适用于多读的应用类型,这样可以提高吞吐量。
了解Java中的锁升级吗?
JVM为了提高锁的获取与释放效率对synchronized 进行了优化,引入了偏向锁和轻量级锁 ,从此以后锁的状态就有了四种:无锁、偏向锁、轻量级锁、重量级锁。并且四种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级,这四种锁的级别由低到高依次是:无锁、偏向锁,轻量级锁,重量级锁。
-
无锁:无锁是指没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
-
偏向锁:初次执行到synchronized代码块的时候,锁对象变成偏向锁(通过CAS修改对象头里的锁标志位),字面意思是“偏向于第一个获得它的线程”的锁。偏向锁是指当一段同步代码一直被同一个线程所访问时,即不存在多个线程的竞争时,那么该线程在后续访问时便会自动获得锁,从而降低获取锁带来的消耗,即提高性能。
-
轻量级锁:轻量级锁是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,线程不会阻塞,从而提高性能。轻量级锁的获取主要由两种情况:1当关闭偏向锁功能时;2由于多个线程竞争偏向锁导致偏向锁升级为轻量级锁。
-
重量级锁:如果锁竞争情况严重,某个达到最大自旋次数的线程,会将轻量级锁升级为重量级锁。当后续线程尝试获取锁时,发现被占用的锁是重量级锁,则直接将自己挂起,等待将来被唤醒。
如何实现互斥锁(mutex)?
在Java里面,最基本的互斥同步手段就是synchronized关键字,这是一种块结构(Block Structured)的同步语法。synchronized关键字经过Javac编译之后,会在同步块的前后分别形成monitorenter和monitorexit这两个字节码指令。这两个字节码指令都需要一个reference类型的参数来指明要锁定和解锁的对象。如果Java源码中的synchronized明确指定了对象参数,那就以这个对象的引用作为reference。如果没有明确指定,那将根据synchronized修饰的方法类型(如实例方法或类方法),来决定是取代码所在的对象实例还是取类型对应的Class对象来作为线程要持有的锁。
分段锁是怎么实现的?
在并发程序中,串行操作是会降低可伸缩性,并且上下文切换也会减低性能。在锁上发生竞争时将通水导致这两种问题,使用独占锁时保护受限资源的时候,基本上是采用串行方式—-每次只能有一个线程能访问它。所以对于可伸缩性来说最大的威胁就是独占锁。
我们一般有三种方式降低锁的竞争程度:
-
减少锁的持有时间;
-
降低锁的请求频率;
-
使用带有协调机制的独占锁,这些机制允许更高的并发性。
说说你对读写锁的了解
与传统锁不同的是读写锁的规则是可以共享读。
在Java中ReadWriteLock的主要实现为ReentrantReadWriteLock,其提供了以下特性:
公平性选择:支持公平与非公平(默认)的锁获取方式,吞吐量非公平优先于公平。
可重入:读线程获取读锁之后可以再次获取读锁,写线程获取写锁之后可以再次获取写锁。
可降级:写线程获取写锁之后,其还可以再次获取读锁,然后释放掉写锁,那么此时该线程是读锁状态,也就是降级操作。
说说你对JUC的了解
JUC这个包下的类基本上包含了我们在并发编程时用到的一些工具,大致可以分为以下几类:
-
原子更新:Java从JDK1.5开始提供了java.util.concurrent.atomic包,方便程序员在多线程环境下,无锁的进行原子操作。在Atomic包里一共有12个类,四种原子更新方式,分别是原子更新基本类型,原子更新 数组,原子更新引用和原子更新字段。
-
锁和条件变量:java.util.concurrent.locks包下包含了同步器的框架 AbstractQueuedSynchronizer,基于AQS构建的Lock以及与Lock配合可以实现等待/通知模式的Condition。JUC 下的大多数工具类用到了Lock和Condition来实现并发。
-
**线程池:**涉及到的类比如:Executor、Executors、ThreadPoolExector、 AbstractExecutorService、Future、Callable、ScheduledThreadPoolExecutor等等。
-
**阻塞队列:**涉及到的类比如:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、LinkedBlockingDeque等等。
-
**并发容器:**涉及到的类比如:ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentLinkedQueue、CopyOnWriteArraySet等等
-
**同步器:**剩下的是一些在并发编程中时常会用到的工具类,主要用来协助线程同步。比如:CountDownLatch、CyclicBarrier、Exchanger、Semaphore、FutureTask等等。
说说你对AQS的理解
抽象队列同步器AbstractQueuedSynchronizer (以下都简称AQS),是用来构建锁或者其他同步组件的骨架类,减少了各功能组件实现的代码量,也解决了在实现同步器时涉及的大量细节问题,例如等待线程采用FIFO队列操作的顺序。在不同的同步器中还可以定义一些灵活的标准来判断某个线程是应该通过还是等待。
基于AQS实现的组件,诸如:
-
ReentrantLock 可重入锁(支持公平和非公平的方式获取锁);
-
Semaphore 计数信号量;
-
ReentrantReadWriteLock 读写锁。
AQS内部维护了一个int成员变量来表示同步状态,通过内置的FIFO(first-in-first-out)同步队列来控制获取共享资源的线程。AQS其实主要做了这么几件事情:
-
同步状态(state)的维护管理;
-
等待队列的维护管理;
-
线程的阻塞与唤醒。
base理论
核心思想:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
三要素:
- 基本可用:基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
- **软状态:**软状态指允许系统中的数据存在中间状态(CAP 理论中的数据不一致),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
- **最终一致性:**最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
什么叫允许损失部分可用性呢?
-
响应时间上的损失: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
-
系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
RPC(Remote Procedure Call) 即远程过程调用
**因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。**并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP还是UDP)、序列化方式等等方面。
最全的常用 Git 指令
一.配置
-
git config user.name "lamplcc" //设置用户名 -
设置邮箱
git config user.email "[email protected]" -
设置全局用户名
git config --global user.name "lamplcc" -
设置全局邮箱
git config --global user.email "[email protected]" -
查看配置
git config --list
二.仓库
- 当前目录新建y一个代码库
git init - 检出仓库
git clone - 检出标签处的仓库
git clone --branch [tags标签] [git地址] - 查看远程仓库
git remote -v - 添加远程仓库
git remote add [name] [url] - 删除远程仓库
git remote rm [name] - 拉取远程仓库
git pull - 添加指定文件到暂存区
git add - 删除工作区和暂存区文件
git rm - 停止追踪指定文件,保留该文件在指定区
git rm --cached - 工作区和暂存区文件重命名
git mv - 提交暂存区到仓库
git commit -m 'message' - 提交时显示所有diff信息
git commit -v - 替换上一次提交
git commit --amend -m [message] - 推送到远程仓库
git push
三.信息查看与对比
- 查看提交日志
git log - 查看指定文件的提交日志
git log -p [file] - 以列表方式查看指定文件的提交历史
git blame [file] - 查看状态
git status - 查看变更的内容
git diff
四.查询详细指令
git --helpgit help -agit help -ggit help
五.撤销
- 恢复暂存区的指定文件到工作区
git checkout [file] - 恢复某个 commit 的指定文件到工作区
git checkout [commit] [file] - 恢复上一个 commit 的所有文件到工作区
git checkout . - 重置暂存区的指定文件与上一次 commit 保持一致,工作区不变
git reset [file] - 重置暂存区与工作区,与上一次 commit 保持一致
git reset --hard - 重置当前分支的 HEAD 为指定 commit,同时重置暂存区和工作区,与指定 commit 一致
git reset --hard [commit] - 重置当前分支的指针为指定 commit,同时重置暂存区,工作区不变
git reset [commit] - 重置当前 HEAD 为指定 commit,但保持暂存区和工作区不变
git reset --keep [commit] - 撤销指定的提交
git revert [commit]
六.分支
- 查看本地分支
git branch - 查看远程分支
git branch -v - 创建分支
git branch [branch-name] - 切换分支
git checkout [branch-name] - 创建并切换分支
git checkout -b [branch-name] - 删除分支
git branch -d [branch-name] - 合并分支
git merge [branch-name]
七.标签
- 查看标签
git tag - 查看远程标签
git tag -r - 创建标签
git tag [tag-name] - 创建带注释的标签
git tag -a [tag-name] -m 'message' - 删除标签
git tag -d [tag-name]
Spring boot
SpringBoot事务管理有几种?
在Spring中,事务有两种实现方式,分别是编程式事务管理和声明式事务管理两种方式。
- 编程式事务管理: 编程式事务管理使用TransactionTemplate或者直接使用底层的PlatformTransactionManager。对于编程式事务管理,spring推荐使用TransactionTemplate。
- 声明式事务管理: 建立在AOP之上的。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。声明式事务管理不需要入侵代码,通过@Transactional就可以进行事务操作,更快捷而且简单。推荐使用
说说你对Spring Boot的理解
参考答案
从本质上来说,Spring Boot就是Spring,它做了那些没有它你自己也会去做的Spring Bean配置。Spring Boot使用“习惯优于配置”的理念让你的项目快速地运行起来,使用Spring Boot很容易创建一个能独立运行、准生产级别、基于Spring框架的项目,使用Spring Boot你可以不用或者只需要很少的Spring配置。
简而言之,Spring Boot本身并不提供Spring的核心功能,而是作为Spring的脚手架框架,以达到快速构建项目、预置三方配置、开箱即用的目的。Spring Boot有如下的优点:
可以快速构建项目;
可以对主流开发框架的无配置集成;
项目可独立运行,无需外部依赖Servlet容器;
提供运行时的应用监控;
可以极大地提高开发、部署效率;
可以与云计算天然集成。
Spring Boot Starter有什么用?
参考答案
Spring Boot通过提供众多起步依赖(Starter)降低项目依赖的复杂度。起步依赖本质上是一个Maven项目对象模型(Project Object Model, POM),定义了对其他库的传递依赖,这些东西加在一起即支持某项功能。很多起步依赖的命名都暗示了它们提供的某种或某类功能。
举例来说,你打算把这个阅读列表应用程序做成一个Web应用程序。与其向项目的构建文件里添加一堆单独的库依赖,还不如声明这是一个Web应用程序来得简单。你只要添加Spring Boot的Web起步依赖就好了。
介绍Spring Boot的启动流程
参考答案
首先,Spring Boot项目创建完成会默认生成一个名为 *Application 的入口类,我们是通过该类的main方法启动Spring Boot项目的。在main方法中,通过SpringApplication的静态方法,即run方法进行SpringApplication类的实例化操作,然后再针对实例化对象调用另外一个run方法来完成整个项目的初始化和启动。
SpringApplication调用的run方法的大致流程,如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kingr0sE-1666488157653)(wps14.jpg)]
其中,SpringApplication在run方法中重点做了以下操作:
获取监听器和参数配置;
打印Banner信息;
创建并初始化容器;
监听器发送通知。
当然,除了上述核心操作,run方法运行过程中还涉及启动时长统计、异常报告、启动日志、异常处理等辅助操作。
Spring Boot项目是如何导入包的?
参考答案
通过Spring Boot Starter导入包。
Spring Boot通过提供众多起步依赖(Starter)降低项目依赖的复杂度。起步依赖本质上是一个Maven项目对象模型(Project Object Model, POM),定义了对其他库的传递依赖,这些东西加在一起即支持某项功能。很多起步依赖的命名都暗示了它们提供的某种或某类功能。
举例来说,你打算把这个阅读列表应用程序做成一个Web应用程序。与其向项目的构建文件里添加一堆单独的库依赖,还不如声明这是一个Web应用程序来得简单。你只要添加Spring Boot的Web起步依赖就好了。
请描述Spring Boot自动装配的过程
参考答案
使用Spring Boot时,我们只需引入对应的Starters,Spring Boot启动时便会自动加载相关依赖,配置相应的初始化参数,以最快捷、简单的形式对第三方软件进行集成,这便是Spring Boot的自动配置功能。Spring Boot实现该运作机制锁涉及的核心部分如下图所示:
整个自动装配的过程是:Spring Boot通过@EnableAutoConfiguration注解开启自动配置,加载spring.factories中注册的各种AutoConfiguration类,当某个AutoConfiguration类满足其注解@Conditional指定的生效条件(Starters提供的依赖、配置或Spring容器中是否存在某个Bean等)时,实例化该AutoConfiguration类中定义的Bean(组件等),并注入Spring容器,就可以完成依赖框架的自动配置。
说说你对Spring Boot注解的了解
**@SpringBootApplication注解:**在Spring Boot入口类中,唯一的一个注解就是@SpringBootApplication。它是Spring Boot项目的核心注解,用于开启自动配置,准确说是通过该注解内组合的@EnableAutoConfiguration开启了自动配置。
@EnableAutoConfiguration注解:@EnableAutoConfiguration的主要功能是启动Spring应用程序上下文时进行自动配置,它会尝试猜测并配置项目可能需要的Bean。自动配置通常是基于项目classpath中引入的类和已定义的Bean来实现的。在此过程中,被自动配置的组件来自项目自身和项目依赖的jar包中。
@Import注解:@EnableAutoConfiguration的关键功能是通过@Import注解导入的ImportSelector来完成的。从源代码得知@Import(AutoConfigurationImportSelector.class)是@EnableAutoConfiguration注解的组成部分,也是自动配置功能的核心实现者。
@Conditional注解:@Conditional注解是由Spring 4.0版本引入的新特性,可根据是否满足指定的条件来决定是否进行Bean的实例化及装配,比如,设定当类路径下包含某个jar包的时候才会对注解的类进行实例化操作。总之,就是根据一些特定条件来控制Bean实例化的行为。
**@Conditional衍生注解:**在Spring Boot的autoconfigure项目中提供了各类基于@Conditional注解的衍生注解,它们适用不同的场景并提供了不同的功能。通过阅读这些注解的源码,你会发现它们其实都组合了@Conditional注解,不同之处是它们在注解中指定的条件(Condition)不同。
@ConditionalOnBean:在容器中有指定Bean的条件下。
@ConditionalOnClass:在classpath类路径下有指定类的条件下。
@ConditionalOnCloudPlatform:当指定的云平台处于active状态时。
@ConditionalOnExpression:基于SpEL表达式的条件判断。
@ConditionalOnJava:基于JVM版本作为判断条件
@ConditionalOnJndi:在JNDI存在的条件下查找指定的位置。
@ConditionalOnMissingBean:当容器里没有指定Bean的条件时。
@ConditionalOnMissingClass:当类路径下没有指定类的条件时。
@ConditionalOnNotWebApplication:在项目不是一个Web项目的条件下。
@ConditionalOnProperty:在指定的属性有指定值的条件下。
@ConditionalOnResource:类路径是否有指定的值。
@ConditionalOnSingleCandidate:当指定的Bean在容器中只有一个或者有多个但是指定了首选的Bean时。
@ConditionalOnWebApplication:在项目是一个Web项目的条件下。
SpringBoot的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是SpringBoot的核心注解 主要组合包含了以下 3 个注解:
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能, 也可以关闭某个自动配置的选项,比如关闭数据源自动配置功能:
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
@ComponentScan:Spring组件扫描。
SpringBoot读取配置相关注解有?
@PropertySource
@Value
@Environment
@ConfifigurationProperties
编写测试用例的注解?
@SpringBootTest
SpringBoot异常处理相关注解?
@ControllerAdvice
@ExceptionHandler
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JJUP8VG7-1666488157653)(wps15.jpg)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ukx7zjFe-1666488157654)(wps16.jpg)]
@RestController vs @Controller
单独使⽤ @Controller 不加 @ResponseBody 的话⼀般使⽤在要返回⼀个视图的情况,@RestController 返回JSON 或 XML 形式数据,但 @RestController 只返回对象,对象数据直接以 JSON 或 XML 形式写⼊ HTTP 响应,(Response)中,这种情况属于 RESTful Web服务
@Controller +@ResponseBody 返回JSON 或 XML 形式数据
@ResponseBody 注解的作⽤是将 Controller 的⽅法返回的对象通过适当的转换器转换为指定的格式之后,写⼊到HTTP 响应(Response)对象的 body 中,通常⽤来返回 JSON 或者XML 数据,返回 JSON 数据的情况⽐多。
多线程
线程的五种状态
-
新建状态(New):
创建一个新的线程对象。
-
就绪状态(Runnable):
线程创建对象后,其他线程调用start()方法,该线程处于就绪状态,资源已经准备就绪,等待CPU资源。
-
运行状态(Running):
处于就绪状态的线程获取到CPU资源后进入运行状态。
-
阻塞状态(Blocked):
阻塞状态是线程由于某些原因放弃CPU使用,暂时停止运行。
等待阻塞:线程调用start()方法,JVM会把这个线程放入等待池中,该线程需要其他线程调用notify()或notifyAll()方法才能被唤醒。
同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被其他线程占用,则JVM会把该线程放入锁池中。
其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
-
终止状态(Terminated):
线程run()方法运行完毕,该线程结束。
创建线程有哪几种方式?
创建线程有三种方式,分别是继承Thread类(单继承)、实现Runnable接口(多继承)、实现Callable接口。
一、继承Thread类创建线程类
(1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
(2)创建Thread子类的实例,即创建了线程对象。
(3)调用线程对象的start()方法来启动该线程。
二、通过Runnable接口创建线程类
(1)定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
(2)创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
(3)调用线程对象的start()方法来启动该线程。
三、通过Callable和Future创建线程
(1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
(3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
run()和start()有什么区别?
用start方法来启动线程,真正实现了多线程运行,它的方法体代表了线程需要完成的任务。
如果直接调用线程对象的run()方法,系统把线程对象当成一个普通对象,而run()方法也是一个普通方法,而不是线程执行体。
线程是否可以重复启动,会有什么后果?
只能对处于新建状态的线程调用start()方法,否则将引发IllegalThreadStateException异常。
Thread类的常用方法
Thread类常用静态方法:
currentThread():返回当前正在执行的线程;
interrupted():返回当前执行的线程是否已经被中断;
sleep(long millis):使当前执行的线程睡眠多少毫秒数;
yield():使当前执行的线程自愿暂时放弃对处理器的使用权并允许其他线程执行;
Thread类常用实例方法:
getId():返回该线程的id;
getName():返回该线程的名字;
getPriority():返回该线程的优先级;
interrupt():使该线程中断;
isInterrupted():返回该线程是否被中断;
isAlive():返回该线程是否处于活动状态;
isDaemon():返回该线程是否是守护线程;
setDaemon(boolean on):将该线程标记为守护线程或用户线程,如果不标记默认是非守护线程;
setName(String name):设置该线程的名字;
setPriority(int newPriority):改变该线程的优先级;
join():等待该线程终止;
join(long millis):等待该线程终止,至多等待多少毫秒数。
介绍一下线程的生命周期
在线程的生命周期中,它要经过新建(New)、就绪(Ready)、运行(Running)、阻塞(Blocked)和死亡(Dead)5种状态。CPU需要在多条线程之间切换,于是线程状态也会多次在运行、就绪之间切换。
(1)当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,仅仅由Java虚拟机为其分配内存,并初始化其成员变量的值。程序也不会执行线程的线程执行体。
(2)当线程对象调用了start()方法之后,该线程处于就绪状态,Java虚拟机会为其创建方法调用栈和程序计数器,处于这个状态中的线程并没有开始运行,只是表示该线程可以运行了
(3)如果处于就绪状态的线程获得了CPU,开始执行run()方法的线程执行体,则该线程处于运行状态。
(4)当发生如下情况时,线程将会进入阻塞状态:
线程调用sleep()方法主动放弃所占用的处理器资源。
线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞。
线程试图获得一个同步监视器,但该同步监视器正被其他线程所持有。
线程在等待某个通知(notify)。
程序调用了线程的suspend()方法将该线程挂起。但这个方法容易导致死锁,所以应该尽量避免使用该方法。
(5)当发生如下特定的情况时可以解除阻塞,让该线程重新进入就绪状态:
调用sleep()方法的线程经过了指定时间。
线程调用的阻塞式IO方法已经返回。
线程成功地获得了试图取得的同步监视器。
线程正在等待某个通知时,其他线程发出了一个通知。
处于挂起状态的线程被调用了resume()恢复方法。
(6)线程会以如下三种方式结束,结束后就处于死亡状态:run()或call()方法执行完成,线程正常结束。
如何保证多线程安全?
- 第一种方法,使用Hashtable线程安全类;Hashtable 几乎所有的添加、删除、查询方法都加了synchronized同步锁!
- 第二种方法,使用Collections.synchronizedMap方法,对方法进行加同步锁;
- 第三种方法,**使用并发包中的ConcurrentHashMap类;**ConcurrentHashMap 类所采用的正是分段锁的思想,将 HashMap 进行切割,把 HashMap 中的哈希数组切分成小数组,每个小数组有 n 个 HashEntry 组成,其中小数组继承自ReentrantLock(可重入锁)。
在Java中线程通信方式
(1)wait()、notify()、notifyAll()
如果线程之间采用synchronized来保证线程安全,则可以利用wait()、notify()、notifyAll()来实现线程通信。这三个方法都不是Thread类中所声明的方法,而是Object类中声明的方法。另外,这三个方法都是本地方法,并且被final修饰,无法被重写。
wait()方法可以让当前线程释放对象锁并进入阻塞状态。notify()方法用于唤醒一个正在等待相应对象锁的线程,使其进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。notifyAll()用于唤醒所有正在等待相应对象锁的线程,使它们进入就绪队列,以便在当前线程释放锁后竞争锁,进而得到CPU的执行。
(2)await()、signal()、signalAll()
**如果线程之间采用Lock来保证线程安全,则可以利用await()、signal()、signalAll()来实现线程通信。**这三个方法都是Condition接口中的方法,该接口是在Java 1.5中出现的,它用来替代传统的wait+notify实现线程间的协作,它的使用依赖于 Lock。相比使用wait+notify,使用Condition的await+signal这种方式能够更加安全和高效地实现线程间协作。
(3)BlockingQueue
Java 5提供了一个BlockingQueue接口,虽然BlockingQueue也是Queue的子接口,但它的主要用途并不是作为容器,而是作为线程通信的工具。BlockingQueue具有一个特征:当生产者线程试图向BlockingQueue中放入元素时,如果该队列已满,则该线程被阻塞;当消费者线程试图从BlockingQueue中取出元素时,如果该队列已空,则该线程被阻塞。线程之间需要通信,最经典的场景就是生产者与消费者模型,而BlockingQueue就是针对该模型提供的解决方案。
说一说sleep()和wait()的区别
sleep()是Thread类中的静态方法,而wait()是Object类中的成员方法;
sleep()可以在任何地方使用,而wait()只能在同步方法或同步代码块中使用;
sleep()不会释放锁,而wait()会释放锁,并需要通过notify()/notifyAll()重新获取锁。
如何实现子线程先执行,主线程再执行?
Thread类提供了让一个线程等待另一个线程完成的方法_join()方法。当在某个程序执行流中调用其他线程的join()方法时,调用线程将被阻塞,直到被join()方法加入的join线程执行完为止。
Synchronized关键字的了解?
synchronized是Java多线程中经常使用的一个关键字。synchronized可以保证原子性、可见性、有序性。它包括两种用法:synchronized 方法和 synchronized 代码块。它可以用来给对象、方法或代码块进行加锁。当它锁定一个方法或者一个代码块时,同一时刻最多只有一个线程可以执行这段代码,其他线程想在此时调用该方法只能排队等候。当它锁定一个对象时,同一时刻最多只有一个线程可以对这个类进行操作,没有获得锁的线程,在该类所有对象上的任何操作都不能进行。
synchronized 和lock 还有 volatile的区别
synchronized是Java关键字,在JVM层面实现加锁和解锁;Lock是一个接口,在代码层面实现加锁和解锁。volatile本质是告诉JVM当前变量在寄存器中的值是不确定的,需要从主存中读取。
synchronized可以用在代码块上、方法上、变量、类;Lock只能写在代码里;volatile仅能用在变量级别。
synchronized在代码执行完或出现异常时自动释放锁;Lock不会自动释放锁,需要在finally中显示释放锁。
synchronized会导致线程拿不到锁一直等待;Lock可以设置获取锁失败的超时时间。
synchronized无法得知是否获取锁成功;Lock则可以通过tryLock得知加锁是否成功。
synchronized锁可重入、不可中断、非公平;Lock锁可重入、可中断、可公平/不公平,并可以细分读写锁以提高效率。
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性。
volatile不会造成线程阻塞,synchronized可能会造成线程阻塞。
说一说synchronized的底层实现原理
synchronized作用在代码块时,它的底层是通过monitorenter、monitorexit指令来实现的。
monitorenter:每个对象都是一个监视器锁(monitor),当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权。
monitorexit:执行monitorexit的线程必须是objectref所对应的monitor持有者。monitorexit指令出现了两次,第1次为同步正常退出释放锁,第2次为发生异步退出释放锁。
方法的同步并没有通过 monitorenter 和 monitorexit 指令来完成,不过相对于普通方法,其常量池中多了 ACC_SYNCHRONIZED 标示符。JVM就是根据该标示符来实现方法的同步的。
volatile关键字有什么用?
当一个变量被定义成volatile之后,它将具备两项特性:
保证可见性:当写一个volatile变量时,JMM会把该线程本地内存中的变量强制刷新到主内存中去,这个写会操作会导致其他线程中的volatile变量缓存无效。
禁止指令重排:使用volatile关键字修饰共享变量可以禁止指令重排序,volatile禁止指令重排序有一些规则:
-
当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行;
-
在进行指令优化时,不能将对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
Volatile如何保证可见性和有序性?
- Volatile是通过MESI缓存一致性协议来保证可见性的。
首先cpu会根据共享变量是否带有Volatile字段,来决定是否使用MESI协议保证缓存一致性。
如果有Volatile,汇编层面会对变量加上Lock前缀,当一个线程修改变量的值后,会马上经过store、write等原子操作修改主内存的值(如果不加Lock前缀不会马上同步),为什么监听到修改会马上同步呢?就是为了触发cpu的嗅探机制,及时失效其他线程变量副本。
- Volatile保证有序性:多线程环境下,有序性问题产生的主要原因就是执行重排优化,而Volatile的另一个作用就是禁止指令重排优化。具体是通过对Volatile修饰的变量增加内存屏障来完成的!
谈谈ReentrantLock的实现原理
ReentrantLock是基于AQS实现的,AQS即AbstractQueuedSynchronizer的缩写,这个是个内部实现了两个队列的抽象类,分别是同步队列和条件队列。
其中同步队列是一个双向链表,里面储存的是处于等待状态的线程,正在排队等待唤醒去获取锁。
而条件队列是一个单向链表,里面储存的也是处于等待状态的线程,只不过这些线程唤醒的结果是加入到了同步队列的队尾,
AQS所做的就是管理这两个队列里面线程之间的等待状态-唤醒的工作。
如果不使用synchronized和Lock,如何保证线程安全?
- volatile:volatile关键字为域变量的访问提供了一种免锁机制,使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,因此每次使用该域就要重新计算,而不是使用寄存器中的值。
- 原子变量:在java的util.concurrent.atomic包中提供了创建了原子类型变量的工具类,使用该类可以简化线程同步。
- 本地存储:可以通过ThreadLocal类来实现线程本地存储的功能。
- 不可变的:只要一个不可变的对象被正确地构建出来,那其外部的可见状态永远都不会改变,永远都不会看到它在多个线程之中处于不一致的状态。
线程池
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统交互。在这种情形下,使用线程池可以很好地提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
线程池在系统启动时即创建大量空闲的线程,程序将一个Runnable对象或Callable对象传给线程池,线程池就会启动一个空闲的线程来执行它们的run()或call()方法,当run()或call()方法执行结束后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个Runnable对象的run()或call()方法。
Java 5新增了一个Executors工厂类来产生线程池,该工厂类包含如下几个静态工厂方法来创建线程池。创建出来的线程池,都是通过ThreadPoolExecutor类来实现的。
newCachedThreadPool():创建一个具有缓存功能的线程池,系统根据需要创建线程,这些线程将会被缓存在线程池中。
newFixedThreadPool(int nThreads):创建一个可重用的、具有固定线程数的线程池。
newSingleThreadExecutor():创建一个只有单线程的线程池,它相当于调用newFixedThread Pool()方法时传入参数为1。
newScheduledThreadPool(int corePoolSize):创建具有指定线程数的线程池,它可以在指定延迟后执行线程任务。corePoolSize指池中所保存的线程数,即使线程是空闲的也被保存在线程池内。
newSingleThreadScheduledExecutor():创建只有一个线程的线程池,它可以在指定延迟后执行线程任务。
线程池的工作流程
判断核心线程池是否已满,没满则创建一个新的工作线程来执行任务。
判断任务队列是否已满,没满则将新提交的任务添加在工作队列。
判断整个线程池是否已满,没满则创建一个新的工作线程来执行任务,已满则执行饱和(拒绝)策略。
线程池都有哪些状态?
线程池一共有五种状态, 分别是:
RUNNING :能接受新提交的任务,并且也能处理阻塞队列中的任务。
SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。
STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态。
TIDYING:如果所有的任务都已终止了,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
TERMINATED:在terminated() 方法执行完后进入该状态,默认terminated()方法中什么也没有做。进入TERMINATED的条件如下:线程池不是RUNNING状态;线程池状态不是TIDYING状态或TERMINATED状态;线程池状态是SHUTDOWN并且workerQueue为空;workerCount为0;设置TIDYING状态成功。
谈谈线程池的拒绝策略
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略,通常有以下四种策略:
AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
DiscardPolicy:也是丢弃任务,但是不抛出异常。
DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复该过程)。
CallerRunsPolicy:由调用线程处理该任务。
线程池有哪些参数,各个参数的作用是什么?
线程池主要有如下6个参数:
corePoolSize(核心工作线程数):若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时。
maximumPoolSize(最大线程数):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
keepAliveTime(多余线程存活时间):当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数。
workQueue(队列):用于传输和保存等待执行任务的阻塞队列。
threadFactory(线程创建工厂):用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
handler(拒绝策略):当线程池和队列都满了,再加入线程会执行此策略
ThreadPoolExecutor的核心参数
public ThreadPoolExecutor(
int corePoolSize, //核心池的大小。
int maximumPoolSize, //池中允许的最大线程数,这个参数表示了线程池中最多能创建的线程数量
long keepAliveTime, //当线程数大于corePoolSize时,终止前多余的空闲线程等待新任务的最长时间
TimeUnit unit, //keepAliveTime时间单位
BlockingQueue<Runnable> workQueue, //存储还没来得及执行的任务
ThreadFactory threadFactory, //执行程序创建新线程时使用的工厂
RejectedExecutionHandler handler //由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序
)
介绍下ThreadLocal和它的应用场景
ThreadLocal、可以理解成每个线程都有自己专属的存储容器,它用来存储线程私有变量,内部真正存取是一个Map。每个线程可以通过set()和get()存取变量,多线程间无法访问各自的局部变量,相当于在每个线程间建立了一个隔板。只要线程处于活动状态,它所对应的ThreadLocal实例就是可访问的,线程被终止后,它的所有实例将被垃圾收集。总之记住一句话:ThreadLocal存储的变量属于当前线程。
ThreadLocal经典的使用场景是为每个线程分配一个 JDBC 连接 Connection,这样就可以保证每个线程的都在各自的 Connection 上进行数据库的操作,不会出现 A 线程关了B线程正在使用的 Connection。 另外ThreadLocal还经常用于管理Session会话,将Session保存在ThreadLocal中,使线程处理多次处理会话时始终是同一个Session。
请介绍ThreadLocal的实现原理,它是怎么处理hash冲突的?
Thread类中有个变量threadLocals,它的类型为ThreadLocal中的一个内部类ThreadLocalMap,这个类没有实现map接口,就是一个普通的Java类,但是实现的类似map的功能。每个线程都有自己的一个map,map是一个数组的数据结构存储数据,每个元素是一个Entry,entry的key是ThreadLocal的引用,也就是当前变量的副本,value就是set的值。
ThreadLocal中的set方法的实现逻辑,先获取当前线程,取出当前线程的ThreadLocalMap,如果不存在就会创建一个ThreadLocalMap,如果存在就会把当前的threadlocal的引用作为键,传入的参数作为值存入map中。
ThreadLocal中get方法的实现逻辑,获取当前线程,取出当前线程的ThreadLocalMap,用当前的threadlocak作为key在ThreadLocalMap查找,如果存在不为空的Entry,就返回Entry中的value,否则就会执行初始化并返回默认的值。
ThreadLocal中remove方法的实现逻辑,还是先获取当前线程的ThreadLocalMap变量,如果存在就调用ThreadLocalMap的remove方法。
设计模式
常用的5种设计模式?
工厂模式
这是一个最基础的设计模式,也是最常用的设计模式,它有简单工厂模式,工厂模式,抽象工厂模式。各有各的优缺点。
故名思意,它就是一个加工厂,不同于现实的是,此处生产的不是生活用品,而是我们面向对象编程中最重要的对象。工厂模式比简单工厂模式更弹性化,遵循了开发-封闭原则。
抽象工厂就像现实中的工厂一样,好处大家都知道,可以批量生产与定制,因为有不一样的模具,就可以生产出大家需要的各种类型产品。
软件开发中,我们更关注的是使用对象的方法,至于如何创建对象我们并不关心,抽象工厂只要定制我们所需的产品功能接口,然后让工厂实现接口生产对象即可。
单例模式
这是一个非常简单的模式,只包含了一个类,重点要管理单例实例的创建,一般为了避免使用者错误创建多余的对象,单例的构造函数和析构函数声明为私有函数。多种单例如果有依赖关系,就要仔细处理构建顺序。它有几个优点,使用简单,可以避免使用全局变量,隐藏对象的构建细节,避免多次构建容易引起的错误。总之,使用它不要急于一时的需求,因为如果将某类设计为单例就限制了可扩展性,也会形成在各种可以随意引用的一种趋向,不过这正也是它的便利之处。
装饰器模式
人靠衣装马靠鞍,好的衣服可以提升一个人的气质,但不会改变外貌与功能,这就是装饰器模式,通过装饰一个对象让它更强大却不会改变它的本质。
举一个软件开发中的例子,比如你们已经做好一个图片传送功能,也经过了测试和线上测试这个功能很完美没毛病,可是突然出现了一个新的需求,想要发送图片时,还能语音提醒,你们怎样在不影响原有的功能情况下实现它呢,现在就可以使用装饰器,也就是给图片发送类装饰一个语音功能。
适配器模式
适配器是什么?就比如耳机,它可以连接在你的手机上也可以连上别人的手机,电脑也可以,它就是一种适配器。
程序员们几乎不可能离开数据库去单独开发一款应用,所以选择什么数据库是最需要关心的事情,一旦选择错误,后期在性能上就会遇见很多瓶颈,适配器模式可以让程序员们在不用修改或者改很少代码的情况下进行数据库的随意切换。
第一步要定义好适配器接口,接着让各种数据库实现我们定义好的接口,在代码里用定义好的方法,当你想要切换数据库时,将该数据库实现对应接口的方法,就可以做到无缝连接啦。
策略模式
策略就是实现目标方案的集合,它们都是用来实现一件事情的。
在软件开发中,一个对象可以对不同场景使用不同的策略去实现同一个功能,比如在学习中老师会制定一个本学期期末目标是多少,但是每个同学怎样去完成它这个过程都是不一样的,但是结果是一样的。
某宝首页的千人千面也是策略模式,都显示了商品,但面对不同的人不同的喜好,商品就是不一样的,这就是由策略决定的。
总结
设计模式一定源于生活,其实,万物都是来源于生活,但经过我们的学习提炼之后,它便高于生活。设计模式可以帮助你解决大部分问题,使用它会让你的代码看起来更加清晰,有条理。
Java设计模式之七大设计原则
- 单一职责原则: 每个类只负责自己的事情,而不是变成万能的
- 接口隔离原则:各个类建立自己的专用接口,而不是建立万能接口
- 依赖倒转原则:面向接口编程,而不是面向实现类
- 里氏替换原则:继承父类而不去改变父类
- 开闭原则:拓展新类而不是修改旧类
- 迪米特法则:无需直接交互的两个类,如果需要交互,使用中间者
- 合成复用原则:优先组合,其次继承
什么是单例模式?
**可以保证系统中,应用该模式的这个类永远只有一个实例,即一个类永远只能创建一个对象。**例如任务管理器对象我们只需要一个就可以解决问题了,这样可以节省内存空间。
饿汉单例的实现步骤?
在用类获取对象的时候,对象已经提前为你创建好了。饿汉式更容易理解就是很着急的初始化对象,因此在创建对象的时候会直接初始化对象为对象分配内存空间(生声明对象的时候就初始化),不管这个对象要不要使用都会占据内存空间。线程安全的,效率比懒汉式高。
- 定义一个类,把构造器私有。
- 定义一个静态变量存储一个对象
/** a、定义一个单例类 */
public class SingleInstance {
/** c.定义一个静态变量存储一个对象即可 :属于类,与类一起加载一次 */
public static SingleInstance instance = new SingleInstance ();
/** b.单例必须私有构造器*/
private SingleInstance (){
System.out.println("创建了一个对象");
}
}
懒汉单例设计模式实现步骤?
在真正需要该对象的时候,才去创建一个对象(延迟加载对象)。懒汉式顾名思义就是比较懒,在创建对象之后并不会直接初始化这个对象,只是将对象设置为null,因此并不会占用内存,在静态方法中进行初始化对象。线程不安全的,需要加同步锁,同步锁影响效率。
- 定义一个类,把构造器私有。
- 定义一个静态变量存储一个对象。
- 提供一个返回单例对象的方法
/** 定义一个单例类 */
class SingleInstance{
/** 定义一个静态变量存储一个对象即可 :属于类,与类一起加载一次 */
public static SingleInstance instance ; // null
/** 单例必须私有构造器*/
private SingleInstance(){}
/** 必须提供一个方法返回一个单例对象 */
public static SingleInstance getInstance(){
...
return ...;
}
}
饿汉式和懒汉式两种单例模式的优缺点?
两种单例模式的优缺点:
饿汉式单例模式
优点:对象提前创建好了,使用的时候无需等待,效率高
缺点:对象提前创建,所以会占据一定的内存,内存占用大
以空间换时间
懒汉式单例模式
优点:使用对象时,对象才创建,所以不会提前占用内存,内存占用小
缺点:首次使用对象时,需要等待对象的创建,而且每次都需要判断对象是否为空,运行效率较低
以时间换空间
因为饿汉式单例效率高,实现简单,推荐使用饿汉式单例
饿汉式
/*
保证别人使用该类的时候,只能获取一个对象(Singleton只能有一个对象)
步骤:
1.私有类的构造器
2.提供该类的静态修饰的对象
3.提供公开的静态方法,返回该类的唯一对象
*/
public class Singleton {
//1.私有类的构造器,目的是不让外界创建对象
private Singleton(){
}
//2.提供该类的静态修饰的对象(饿汉式,对象是直接创建的)
private static Singleton single = new Singleton();
//3.提供公开的静态方法,返回该类的唯一对象
public static Singleton getInstance(){
return single;
}
}
懒汉式
/*懒汉式单例
1.私有构造方法
2.提供该类的静态变量,不是马上创建
3.提供公开的获取唯一对象的静态方法
*/
public class Single {
//1.私有构造方法
private Single(){}
//2.提供该类的静态变量,不是马上创建
private static Single single = null;
//3.提供公开的获取唯一对象的静态方法
public static Single getInstance(){
//如果对象为空,则创建,否则直接返回
if(single==null){
single = new Single();
}
return single;
}
}
普通工厂模式
普通工厂模式:普通工厂模式中,其实是对实现了同一接口的类进行实例的创建,在工厂中进行类的创建。
代码示例如下
创建一个其它类都需要继承的接口,其中接口中定义一个方法。
public interface Animal {
public void create();
}
创建两个实现类,继承接口同时重写接口中的方法。两个实现类中对重写的方法输出不同的值。
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
创建一个工厂,工厂中创建一个方法,在方法中通过判断来决定创建哪一个实体类。
public class AnimalFactory {
public Animal create(String type){
if ("dog".equals(type)){
return new Dog();
}else if ("cat".equals(type)){
return new Cat();
}else {
System.out.println("请输入正确的动物");
return null;
}
}
}
创建一个工厂测试类
public class FactoryTest {
public static void main(String[] args) {
AnimalFactory animalFactory = new AnimalFactory();
Animal animal = animalFactory.create("dog");
animal.create();
}
}
总结:通过工厂模式,我们不需要对我们要使用的类一个一个来创建了,我们可以通过工厂类,通过一定的算法来实现我们需要的实体类的创建。这样减轻了内存的负载,只创建需要的类,同时减少冗余。
多个工厂模式
多个工厂模式是对工厂方法的改进,在普通工厂模式中,如果传递的字符串出错,那么就无法正确的创建对象,而多个工厂模式是提供多个工厂方法,分别创建对象。
public interface Animal {
public void create();
}
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
public class AnimalFactory {
public Animal createDog(){
return new Dog();
}
public Animal createCat(){
return new Cat();
}
}
public class FactoryTest {
public static void main(String[] args) {
AnimalFactory animalFactory = new AnimalFactory();
Animal animal = animalFactory.createCat();
animal.create();
}
}
在多个工厂模式中我们无需通过传递字符串确定我们需要创建哪个对象,只需要通过调用接口中的实现方法就可以实现创建对象。
抽象工厂模式
public interface Animal {
public void create();
}
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
public interface Action {
public Animal action();
}
public class CatFactory implements Action {
@Override
public Animal action() {
return new Cat();
}
}
public class DogFactory implements Action {
@Override
public Animal action() {
return new Dog();
}
}
public class Test {
public static void main(String[] args) {
Action action = new CatFactory();
Animal animal = action.action();
animal.create();
}
}
其实这个模式的好处就是,如果你现在想增加一个功能:发及时信息,则只需做一个实现类,实现Animal接口,同时做一个工厂类,实现Action接口,就OK了,无需去改动现成的代码。这样做,拓展性较好!
建造者模式
将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。主要的作用是实现在用户不知道对象的建造过程和细节的情况下就可以直接创建复杂的对象。很好的解决了用户创建复杂对象的类型和内容。
public interface Animal {
public void create();
}
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
public class Builder {
private List<Animal> list = new ArrayList <>();
public void createCat(int count){
for (int i = 0; i < count; i++) {
list.add(new Cat());
}
System.out.println(list);
}
public void createDog(int count){
for (int i = 0; i < count; i++) {
list.add(new Dog());
}
}
}
public class Test {
public static void main(String[] args) {
Builder builder = new Builder();
builder.createCat(3);
}
}
建造者模式将很多功能集成到一个类里,这个类可以创造出比较复杂的东西。所以与工厂模式的区别就是:工厂模式关注的是创建单个产品,而建造者模式则关注创建符合对象,多个部分。因此,是选择工厂模式还是建造者模式,依实际情况而定。
c.定义一个静态变量存储一个对象即可 :属于类,与类一起加载一次 /
public static SingleInstance instance = new SingleInstance ();
/* b.单例必须私有构造器*/
private SingleInstance (){
System.out.println(“创建了一个对象”);
}
}
## 懒汉单例设计模式实现步骤?
在真正需要该对象的时候,才去创建一个对象(延迟加载对象)。懒汉式顾名思义就是比较懒,**在创建对象之后并不会直接初始化这个对象,只是将对象设置为null,因此并不会占用内存**,在静态方法中进行初始化对象。**线程不安全的,需要加同步锁,同步锁影响效率**。
- 定义一个类,把构造器私有。
- 定义一个静态变量存储一个对象。
- 提供一个返回单例对象的方法
```java
/** 定义一个单例类 */
class SingleInstance{
/** 定义一个静态变量存储一个对象即可 :属于类,与类一起加载一次 */
public static SingleInstance instance ; // null
/** 单例必须私有构造器*/
private SingleInstance(){}
/** 必须提供一个方法返回一个单例对象 */
public static SingleInstance getInstance(){
...
return ...;
}
}
饿汉式和懒汉式两种单例模式的优缺点?
两种单例模式的优缺点:
饿汉式单例模式
优点:对象提前创建好了,使用的时候无需等待,效率高
缺点:对象提前创建,所以会占据一定的内存,内存占用大
以空间换时间
懒汉式单例模式
优点:使用对象时,对象才创建,所以不会提前占用内存,内存占用小
缺点:首次使用对象时,需要等待对象的创建,而且每次都需要判断对象是否为空,运行效率较低
以时间换空间
因为饿汉式单例效率高,实现简单,推荐使用饿汉式单例
饿汉式
/*
保证别人使用该类的时候,只能获取一个对象(Singleton只能有一个对象)
步骤:
1.私有类的构造器
2.提供该类的静态修饰的对象
3.提供公开的静态方法,返回该类的唯一对象
*/
public class Singleton {
//1.私有类的构造器,目的是不让外界创建对象
private Singleton(){
}
//2.提供该类的静态修饰的对象(饿汉式,对象是直接创建的)
private static Singleton single = new Singleton();
//3.提供公开的静态方法,返回该类的唯一对象
public static Singleton getInstance(){
return single;
}
}
懒汉式
/*懒汉式单例
1.私有构造方法
2.提供该类的静态变量,不是马上创建
3.提供公开的获取唯一对象的静态方法
*/
public class Single {
//1.私有构造方法
private Single(){}
//2.提供该类的静态变量,不是马上创建
private static Single single = null;
//3.提供公开的获取唯一对象的静态方法
public static Single getInstance(){
//如果对象为空,则创建,否则直接返回
if(single==null){
single = new Single();
}
return single;
}
}
普通工厂模式
普通工厂模式:普通工厂模式中,其实是对实现了同一接口的类进行实例的创建,在工厂中进行类的创建。
代码示例如下
创建一个其它类都需要继承的接口,其中接口中定义一个方法。
public interface Animal {
public void create();
}
创建两个实现类,继承接口同时重写接口中的方法。两个实现类中对重写的方法输出不同的值。
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
创建一个工厂,工厂中创建一个方法,在方法中通过判断来决定创建哪一个实体类。
public class AnimalFactory {
public Animal create(String type){
if ("dog".equals(type)){
return new Dog();
}else if ("cat".equals(type)){
return new Cat();
}else {
System.out.println("请输入正确的动物");
return null;
}
}
}
创建一个工厂测试类
public class FactoryTest {
public static void main(String[] args) {
AnimalFactory animalFactory = new AnimalFactory();
Animal animal = animalFactory.create("dog");
animal.create();
}
}
总结:通过工厂模式,我们不需要对我们要使用的类一个一个来创建了,我们可以通过工厂类,通过一定的算法来实现我们需要的实体类的创建。这样减轻了内存的负载,只创建需要的类,同时减少冗余。
多个工厂模式
多个工厂模式是对工厂方法的改进,在普通工厂模式中,如果传递的字符串出错,那么就无法正确的创建对象,而多个工厂模式是提供多个工厂方法,分别创建对象。
public interface Animal {
public void create();
}
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
public class AnimalFactory {
public Animal createDog(){
return new Dog();
}
public Animal createCat(){
return new Cat();
}
}
public class FactoryTest {
public static void main(String[] args) {
AnimalFactory animalFactory = new AnimalFactory();
Animal animal = animalFactory.createCat();
animal.create();
}
}
在多个工厂模式中我们无需通过传递字符串确定我们需要创建哪个对象,只需要通过调用接口中的实现方法就可以实现创建对象。
抽象工厂模式
public interface Animal {
public void create();
}
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
public interface Action {
public Animal action();
}
public class CatFactory implements Action {
@Override
public Animal action() {
return new Cat();
}
}
public class DogFactory implements Action {
@Override
public Animal action() {
return new Dog();
}
}
public class Test {
public static void main(String[] args) {
Action action = new CatFactory();
Animal animal = action.action();
animal.create();
}
}
其实这个模式的好处就是,如果你现在想增加一个功能:发及时信息,则只需做一个实现类,实现Animal接口,同时做一个工厂类,实现Action接口,就OK了,无需去改动现成的代码。这样做,拓展性较好!
建造者模式
将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。主要的作用是实现在用户不知道对象的建造过程和细节的情况下就可以直接创建复杂的对象。很好的解决了用户创建复杂对象的类型和内容。
public interface Animal {
public void create();
}
public class Cat implements Animal {
@Override
public void create() {
System.out.println("this is cat");
}
}
public class Dog implements Animal {
@Override
public void create(){
System.out.println("this is dog");
}
}
public class Builder {
private List<Animal> list = new ArrayList <>();
public void createCat(int count){
for (int i = 0; i < count; i++) {
list.add(new Cat());
}
System.out.println(list);
}
public void createDog(int count){
for (int i = 0; i < count; i++) {
list.add(new Dog());
}
}
}
public class Test {
public static void main(String[] args) {
Builder builder = new Builder();
builder.createCat(3);
}
}
建造者模式将很多功能集成到一个类里,这个类可以创造出比较复杂的东西。所以与工厂模式的区别就是:工厂模式关注的是创建单个产品,而建造者模式则关注创建符合对象,多个部分。因此,是选择工厂模式还是建造者模式,依实际情况而定。