cycleGAN模型构建及代码解读及细节
cycleGAN模型及代码
- cycleGAN简介
- cycleGAN中的网络和图片们♂
- generator的构建
-
- 编码器
- 残差块
- 解码器
- Discriminator
- 其余准备工作
-
- 数据读取
- 生成图片缓冲区
- 学习率更新
- 模型初始化
- 图片保存
- 损失函数
-
- generator中的loss
- discriminator中的loss
- 训练的细节
- 效果展示
cycleGAN简介
论文原文地址:cyclegan论文
cycleGAN是一种由Generative Adversarial Networks发展而来的一种无监督机器学习,是在pix2pix的基础上发展起来的,主要应用于非配对图片的图像生成和转换,可以实现风格的转换,比如把照片转换为油画风格,或者把照片的橘子转换为苹果、马与斑马之间的转换等。因为不需要成对的数据集就能够转换,所以在数据准备上会简单很多,十分具有应用前景。
cycleGAN中的网络和图片们♂
cycleGAN由两个生成网络和两个判别网络构成
------------------- ⊕ , ⊖ , ⊗ , ⊘ , ⊙ , ⊕ , ⊖ , ⊗ , ⊘ , ⊙ , ⊕ , ⊖ , ⊗ , ⊘ , ⊙ \oplus, \ominus, \otimes, \oslash, \odot,\oplus, \ominus, \otimes, \oslash, \odot,\oplus, \ominus, \otimes, \oslash, \odot ⊕,⊖,⊗,⊘,⊙,⊕,⊖,⊗,⊘,⊙,⊕,⊖,⊗,⊘,⊙-----------------------
G_AtoB() 看作是风格A向风格B的生成网络
G_BtoA() 看作是风格B向风格A的生成网络
dis_A() 看作是判别输入图片是否属于风格A的判别网络
dis_B() 看作是判别输入图片是否属于风格B的判别网络
其中G_AtoB()和G_BtoA()的输入为[B, C, W, H],即batchsize, channels, width, height,输出一般与输入相同;
其中dis_A()和dis_B()的输入为[B, C, W, H],即batchsize, channels, width, height,输出的维度是[B, 1],里面的是经过sigmoid函数输出的,所以取值范围在[0, 1]进行分类。
------------------- ⊕ , ⊖ , ⊗ , ⊘ , ⊙ , ⊕ , ⊖ , ⊗ , ⊘ , ⊙ , ⊕ , ⊖ , ⊗ , ⊘ , ⊙ \oplus, \ominus, \otimes, \oslash, \odot,\oplus, \ominus, \otimes, \oslash, \odot,\oplus, \ominus, \otimes, \oslash, \odot ⊕,⊖,⊗,⊘,⊙,⊕,⊖,⊗,⊘,⊙,⊕,⊖,⊗,⊘,⊙--------------------------
real_A 看作是从风格A中sample出的真实的照片
real_B 看作是从风格B中sample出的真实的照片
AtoB = G_AtoB(real_A) 看作是real_A经过生成网络转换得到的风格B的照片
BtoA = G_BtoA(real_B) 看作是real_B经过生成网络转换得到的风格A的照片
cycleGAN名字中之所以有一个cycle,我觉得应该是原图经过一种生成网络转换后得到另一种风格的图片,然后还要经过另一种生成网络转换后尽可能的接近原图,形成了一个循环,所以被称为cycleGAN。
所以有:
AtoBtoA = G_BtoA(AtoB) = G_BtoA(G_AtoB(real_A)) 从A风格转换到B风格,又转换为A风格
BtoAtoB = G_AtoB(BtoA) = G_AtoB(G_BtoA(real_B)) 从B风格转换到A风格,又转换为B风格
再次插入一张广为流传的图:

generator的构建
原文中对于generator的描述是:
We adopt the architecture for our generative networks from Johnson et al. who have shown impressive results for neural style transfer and super-resolution. This network contains three convolutions, several residual blocks, two fractionally-strided convolutions with stride 1/2 , and one convolution that maps features to RGB. We use 6 blocks for 128 × 128 images and 9 blocks for 256 × 256 and higher-resolution training images.Similar to Johnson et al. we use instance normalization.
生成器由三个部分组成:
- 编码器
- 转换器
- 解码器
编码器
编码器由三层卷积网络构成,假设编码器的输入为[1 3 256 256],经过一层卷积层,变成[1 64 256 256],经过第二层卷积层变成[1 128 128 128],经过第三层卷积层变成[1 256 64 64]
用pytorch实现就是:
nn.Conv2d(3, 64,7,1,3,padding_mode='reflect'),
nn.InstanceNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,128,3,2,1),
nn.InstanceNorm2d(128),
nn.ReLU(),
nn.Conv2d(128,256,3,2,1),
nn.InstanceNorm2d(256),
nn.ReLU(),
nn,Conv2d(输入通道数,输出通道数,卷积核大小, 步长,填充大小(默认填充0),填充模式=‘reflect’)
其中采用的是InstanceNorm2d,并没有采用Normalization进行归一化。
Batch Normalization是指batchsize图片中的每一张图片的同一个通道一起进行Normalization操作。而Instance Normalization是指单张图片的单个通道单独进行Noramlization操作。
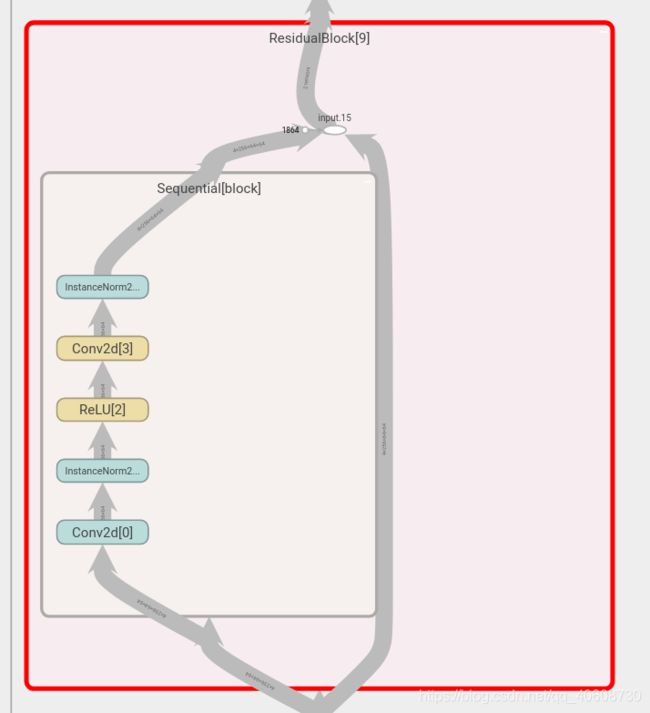
残差块
残差块除了减弱梯度消失外,还可以理解为这是一种自适应深度,也就是网络可以自己调节层数的深浅,至少可以退化为输入,不会变得更糟糕。可以使网络变得更深,更加的平滑,使深度神经网络的训练成为了可能。
原文中的描述是如果输入的图片大小是128x128就用6个残差块,如果图片大小是256x256就用9个残差块,残差网络的输入个输出大小一致,所以都是编码器的[1 256 64 64]
用pytorch实现一个残差结构的代码:
class ResidualBlock(nn.Module):
def __init__(self):
super(ResidualBlock, self).__init__()
block = [
nn.Conv2d(256,256,3,1,1, padding_mode = 'reflect'),
nn.InstanceNorm2d(256),
nn.ReLU(),
nn.Conv2d(256,256,3,1,1, padding_mode = 'reflect'),
nn.InstanceNorm2d(256),
]
self.block = nn.Sequential(*block)
def forward(self, x):
return x + self.block(x)
由于要用到9个残差模块,所以只要:
for _ in range(9):
model += [
ResidualBlock(),
]
经过可视化之后的残差结构图:
解码器
解码器中用到的是反卷积(逆卷积)和卷积层,经过残差结构的tensor为[1 256 64 64],经过第一层反卷积得到[1 128 128 128]经过第二层反卷积层得到[1 64 256 256],再经过卷积层得到[1 3 256 256],得到一三通道的256x256的图片。
用pytorch实现就是:
nn.ConvTranspose2d(256,128,3,2,1,output_padding=1),
nn.InstanceNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(128,64,3,2,1,output_padding=1),
nn.InstanceNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,3,7,1,3,padding_mode='reflect'),
nn.Tanh()
最后经过Tanh映射到[-1 1]上,对应数据读取时候的transforms.Normalize。
Discriminator
判别网络用的是5层卷积,将通道数减为1,最后进行池化平均,再reshape成[batchsize 1]
比较简单就不计算每一步的大小了。
用pytorch实现:
nn.Conv2d(3,64,4,2,1),
nn.LeakyReLU(0.2),
nn.Conv2d(64,128,4,2,1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128,256,4,2,1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256,512,4,1,1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512,1,4,1,1)
最后再经过:
F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)
最后输出的就是判别的结果。
其余准备工作
数据读取
class ImageDataset(Dataset):
def __init__(self, root = arg.train_dataroot, unaligned=False):
self.transform = transforms.Compose([
transforms.Resize(int(arg.size*1.2), interpolation = Image.BICUBIC), #调整输入图片的大小
transforms.RandomCrop(arg.size), #随机裁剪
transforms.RandomHorizontalFlip(),#随机水平翻转图像
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
#归一化,这两行不能颠倒顺序呢,归一化需要用到tensor型
])
self.unaligned = unaligned
self.files_A = sorted(glob.glob(root + (arg.train_dataroot.split('/')[0]).split('2')[0] + '/*.jpg'))
self.files_B = sorted(glob.glob(root + (arg.train_dataroot.split('/')[0]).split('2')[-1] + '/*.jpg'))
def __getitem__(self, index):
item_A = self.transform(Image.open(self.files_A[index % len(self.files_A)]).convert('RGB'))
if self.unaligned:
item_B = self.transform(Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]).convert('RGB'))
else:
item_B = self.transform(Image.open(self.files_B[index % len(self.files_B)]).convert('RGB'))
return {'A': item_A, 'B': item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))
def train_data_loader():
train_data_loader = DataLoader(ImageDataset(unaligned=True),batch_size=arg.batchSize, shuffle=True, pin_memory=True, drop_last=True)
return train_data_loader
其中的root代表着存放的文件夹,命名格式为:A2B/train
-A2B
----train
----------A
--------------A_images
.
.
.
----------B
--------------B_images
.
.
.
因为其中有split操作,所以对命名要求较高。
只需要调用train_data_loader()函数即可,得到的是字典格式的数据,可以通过data[‘A’],和data[‘B’]操作将不同类型的图片取出来。
其中的图片还会经过:
- 调整图片大小至[1.2size 1.2size]
- 随机裁减至[size size]大小
- 随机水平反转
- 归一化
生成图片缓冲区
论文中提到,在更新discriminators的时候,用的是之前生成的图片,而不是最新的图片,所以设立图片缓冲区,可以存放50张之前生成的图片。
update the discriminators using a history of generated images rather than the ones produced by the latest generators. We keep an image buffer that stores the 50 previously created images.
代码实现:
class ReplayBuffer():
def __init__(self, max_size=50):
assert (max_size > 0), 'Empty buffer or trying to create a black hole. Be careful.'
self.max_size = max_size
self.data = []
def push_and_pop(self, data):
to_return = []
for element in data.data:
element = torch.unsqueeze(element, 0)
if len(self.data) < self.max_size:
self.data.append(element)
to_return.append(element)
else:
if random.uniform(0,1) > 0.5:
i = random.randint(0, self.max_size-1)
data_index.append(i)
to_return.append(self.data[i].clone())
self.data[i] = element
else:
to_return.append(element)
return Variable(torch.cat(to_return))
根据代码中可知,缓冲区的数据初始化大小为50,当缓冲区没有图片的时候,我们把输入的data写入缓冲区,并且返回输入图片,当缓冲区满的时候,50%的可能会随机更新缓冲区数据,将新的数据放进来,替换掉之前生成的数据,之前的数据返回,也会有50%的可能直接返回输入的data数据。
学习率更新
在原文中,学习率初始为0.0002,总的epoch为200,在0-100的时候,学习率为0.0002,在100-200的时候,学习率逐渐线性减小为0,所以需要进行学习率的更新。
We keep the same learning rate for the first 100 epochs and linearly decay the rate to zero over the next 100 epochs.
pytorch中提供了torch.optim.lr_scheduler.LambdaLR()函数,但是其中的学习率衰减需要自己编写函数设定。
利用python实现为:
class MyLambdaLR():
def __init__(self, n_epochs, offset, decay_start_epoch):
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - max(0, epoch + self.offset - self.decay_start_epoch)/(self.n_epochs - self.decay_start_epoch)
需要的变量有:总的训练epoch,当前的epoch,和开始进行衰减的epoch,即可实现lr的线性变化。
模型初始化
在第一次训练的时候可以使用以下函数进行模型中数据的初始化。经过测试在没有加入dis的情况下,未经初始化的generator的loss在30左右,在进行初始化后的模型loss在18左右,有一定的减小,但是经过迭代都可以降到很低,有一定的加速作用。
参数初始化代码:
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
将卷积层和BatchNorm2d的参数进行初始化。
图片保存
同时我们还要解决图片保存的问题,在训练中得到的都是tensor,如何由张量得到图片进行存储和查看,也是十分重要。下面的代码使gpu上的 -1~1 之间的数据转化为0-255之间的值。
python实现:
def TensorToImage(T):
real_image = 255*(T.cpu().float().numpy()*0.5 + 0.5)
real_image = real_image.astype(np.uint8).transpose(1, 2, 0)
real_image = real_image[:,:,[2,1,0]]
return real_image
其中输入的T的大小为[3 256 256],取值范围是[-1 1],并且是在gpu上进行加速计算的值。
由于在数据初始化的时候,进行了: transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) 操作。
其操作就是:
x = x / 255 − 0.5 0.5 x = \frac{x/255 - 0.5}{0.5} x=0.5x/255−0.5
所以在进行反变化的时候,需要先把tensor搬到cpu上,转化为numpy数据,再进行:
x = ( x ∗ 0.5 + 0.5 ) ∗ 255 x = (x*0.5+0.5)*255 x=(x∗0.5+0.5)∗255
此时得到的数据为[3 256 256],需要转换为[256 256 3],所以进行transpose操作,但是在进行变换的时候,rgb通道变成了bgr通道,需要把[256 256 0]和[256 256 2]再交换一下。
综上输出的real_image就是[256 256 3]的rgb图像。
损失函数
cycleGAN中用到了两种损失函数,一种是MSE(torch.nn.MSELoss()),另一种是L1(torch.nn.L1Loss()),MSE主要应用再标签中,用来判断discriminator输出的label和真实lable之间的loss。L1主要用在图片中,衡量图片与图片之间的loss。
MSE应用的场合:
- gen_AtoB中,Dis_B判断AtoB生成的图片与真实标签之间的loss
- gen_BtoA中,Dis_A判断BtoA生成的图片与真实标签之间的loss
- Dis_A中 real_A与真实标签之间的loss | | B2A与虚假标签之间的loss
- Dis_B中 real_B与真实标签之间的loss | | A2B与虚假标签之间的loss
L1应用的场合:
- real_A和A2B2A之间
- real_B和B2A2B之间
- real_A和B2A(real_A)
- real_B和A2B(real_B)
其中的第三种和第四种情况可以理解为:经过生成该图片风格的生成器生成的图片应该尽量与原图保持一致。也被成为identity loss。
generator中的loss
- identity loss
identity loss论文中好像没有提到,但是在上面已经大致说过了,也就是可以理解成生成器Gen_AtoB负责x域(domain)到y域图像的生成,如果输入y域的图片,输出仍然是y域的图片,比较符合直觉,用的是L1函数。
用代码表示就是:
same_A = genB2A(real_A)
identity_loss_A = criterion_identity(same_A, real_A)
我们希望其中的same_A能够和real_A越接近越好。
- GAN loss
GAN loss主要就是生成器生成的图片,送到相应的判别器中得到相应的标签值,希望标签值能够越接近于1越好,用的是MSE函数。
用代码表示就是:
AtoB = genA2B(real_A)
fake_A_target = disB(AtoB)
AtoB_loss = criterion_GAN(fake_A_target, target_real)
希望生成的照片能够骗过判别器。
- cycle loss
cycle loss 就是我们期望,图像从x域生成到y域,经过另一个生成器再生成到x域能够和原本的x域的图像越接近越好。这个应该就是cycle GAN的核心,也是能够实现无配对(unpaired)图像相互转换的核心。
用代码表示就是:
# cycle loss
AtoBtoA = genB2A(AtoB)
cycle_A_loss = criterion_cycle(AtoBtoA, real_A)
ps:本人写到这里,突然感到一丝不对劲,一看正在跑的代码,之前写错了。。。上面是修改后的。
AtoBtoA:代表从A类转换到B类再转换到A类的图像。和real_A进行L1 loss,希望能够尽量接近原图。
- generator loss之和
generator loss由以上的三个loss加权组合而成。
g e n A 2 B l o s s = i d e n t i t y l o s s A ∗ 2 + A t o B l o s s + c y c l e A l o s s ∗ 10 genA2Bloss = identitylossA*2 + AtoBloss + cycleAloss*10 genA2Bloss=identitylossA∗2+AtoBloss+cycleAloss∗10
其中的权值越大,也代表着越重要。
之后就可以进行backward和参数更新了。即使gen_AtoB是主要生成器但是也得更新gen_BtoA的参数,毕竟人家也参与了。
值得一提的是:有的在训练的时候,把两个generator一起训练,也就是得到了6的loss,再求和,更新一次参数就可以同时更新两个生成器的参数,我这里没有那样用。
两个一起更新的话,优化器的参数设置如下:
optimizer_G = torch.optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()),
lr=opt.lr, betas=(0.5, 0.999))
通过itertools.chain函数将两个生成器连接起来,同时更新参数,但是需要的内存也会更大。
discriminator中的loss
discriminator的loss函数与generator相比要简单很多,大致由两部分构成,一部分就是真实图片,另一部分就是生成的图片,我们要训练判别器区分出真实的图片和生成的图片。
以dis_A为例:
pred_real_A = disA(real_A)
loss_D_A_real = criterion_GAN(pred_real_A, target_real)
fake_A = fake_A_buffer.push_and_pop(BtoA)
pred_fake_A = disA(fake_A.detach())
loss_D_A_fake = criterion_GAN(pred_fake_A, target_fake)
loss_D_A = (loss_D_A_real + loss_D_A_fake) * 0.5
我们要让pred_real_A接近1,pred_fake_A接近0,也就是把两者能够很好的区分出来,注意fake_A是从缓冲区之中取出来的之前所生成的图片,并不是立即生成的。
discriminator的水平和generator的水平随着训练次数增加共同进步,进而生成我们需要的另一种风格的图片。
训练的细节
- learning rate设为0.0002,好像GAN网络公认的lr都是这个,效果比较好。
- 优化器都采用的Adam优化器,也是在GAN中应用较多,torch.optim.Adam(parameters(), lr, betas=(0.5, 0.999)),其中的betas也都是(0.5, 0.999)
- batchsize设为1,至于为什么是1,论文中好像没说,cycleGAN由pix2pix发展而来,pix2pix中的batchsize也是1,好像是为了减小Normalize的影响。
- cycleGAN的loss不能准确反应训练的好坏,不代表着训练进度,甚至不能代表结果优劣。所以还是要输出样张看效果,或许可以借鉴WGAN的思想?
- 还会有人一个epoch训练k次discriminator,训练1次generator。
写到这里,我已经我会的的基本上都说了。
如果有什么地方不对,还希望能够批评指出,我也只是初学者。
相应的模型还在训练,敬请期待!!!
效果展示
来填坑了,模型训练的差不多了。
照片向油画的转换:


油画向照片的转换:




emm
我的代码找不到了
在这里推荐:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix