动手学深度学习——经典卷积神经LeNet
1、概念及结构
LeNet由Yann Lecun 创建,并将该网络用于邮局的邮政的邮政编码识别,有着良好的学习和识别能力。LeNet又称LeNet-5,具有一个输入层,两个卷积层,两个池化层,3个全连接层(其中最后一个全连接层为输出层)。LeNet网络结构图如下:
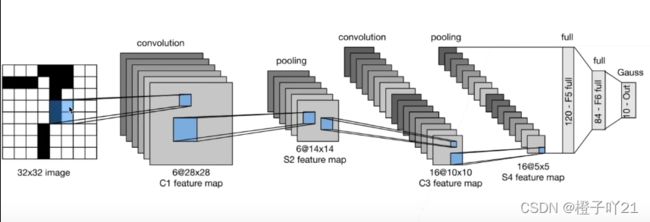
LeNet-5共有7层(不包含输入),每层都包含可训练参数。
输入图像大小为32*32,比MNIST数据集的图片要大一些,这么做的原因是希望潜在的明显特征如笔画断点或角能够出现在最高层特征检测子感受野(receptive field)的中心。因此在训练整个网络之前,需要对28*28的图像加上paddings(即周围填充0)。
C1层:该层是一个卷积层。使用6个大小为5*5的卷积核,步长为1,对输入层进行卷积运算,特征图尺寸为32-5+1=28,因此产生6个大小为28*28的特征图。这么做够防止原图像输入的信息掉到卷积核边界之外。
S2层:该层是一个池化层(pooling,也称为下采样层)。这里采用max_pool(最大池化),池化的size定为2*2,经池化后得到6个14*14的特征图,作为下一层神经元的输入。
C3层:该层仍为一个卷积层,我们选用大小为5*5的16种不同的卷积核。这里需要注意:C3中的每个特征图,都是S2中的所有6个或其中几个特征图进行加权组合得到的。输出为16个10*10的特征图。
S4层:该层仍为一个池化层,size为2*2,仍采用max_pool。最后输出16个5*5的特征图,神经元个数也减少至16*5*5=400。
C5层:该层我们继续用5*5的卷积核对S4层的输出进行卷积,卷积核数量增加至120。这样C5层的输出图片大小为5-5+1=1。最终输出120个1*1的特征图。这里实际上是与S4全连接了,但仍将其标为卷积层,原因是如果LeNet-5的输入图片尺寸变大,其他保持不变,那该层特征图的维数也会大于1*1。
F6层:该层与C5层全连接,输出84张特征图。为什么是84?下面有论文的解释(感谢翻译)。
输出层:该层与F6层全连接,输出长度为10的张量,代表所抽取的特征属于哪个类别。(例如[0,0,0,1,0,0,0,0,0,0]的张量,1在index=3的位置,故该张量代表的图片属于第三类)。
2、例子
典型的例子:手写的数字识别
3、总结
LeNet是早期成功的神经网络;
先使用卷积层来学习图片空间信息;
然后使用全连接层来转换到类别空间。
4、代码实现
import time
import torch
from torch import nn, optim
import matplotlib.pyplot as plt
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
"""经典神经网络LeNet模型"""
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels,kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),#卷积层
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
#查看每个层的形状
net=LeNet()
print(net)
"""获取数据和训练模型"""
#使⽤Fashion-MNIST作为训练数据集。
batch_size = 256
train_iter, test_iter =d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy(data_iter, net,device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')):
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) ==
y.to(device)).float().sum().cpu().item()
net.train() #改回训练模型
else: # ⾃定义的模型, 3.13节之后不会⽤到, 不考虑GPU
if ('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) ==y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs):
net = net.to(device)
print("training on ", device)
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0,time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f,time % .1fsec'% (epoch + 1, train_l_sum / batch_count,train_acc_sum / n, test_acc, time.time() - start))
#学习率采⽤0.001,训练算法使⽤Adam算法,损失函数使⽤交叉熵损失函数。
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device,num_epochs)
plt.show()