高性能MySql学习笔记——多版本并发控制算法
AUTOCOMMIT
Mysql默认自动提交,可以通过如下命令查看和修改:
mysql> SHOW VARIABLES LIKE 'AUTOCOMMIT';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> SET AUTOCOMMIT = 1;
隐式锁显式锁
InnoDB在开启事务时,获取隐式锁,在事务提交或者回滚时释放锁,InnoDB根据隔离级别自动处理锁。
但InnoDB也支持显式锁:
SELECT ... FOR UPDATE
SELECT ... LOCK IN SHARE MODE
多版本并发控制(Multiversion Concurrency Controll MVCC)
第一点:
MVCC并不是MySql独有的,Oracle,PostgreSQL等都在使用。
MVCC并没有简单地使用行锁,而是使用“行级别锁”(row-level locking)。MVCC的基本原理是:
在事务中保存数据的快照,这意味着在一个事物里能够看到数据一致的视图,而不用担心这个事务运行多长时间,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
MVCC的基本特征:
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本随意修改,个事务之间无干扰
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
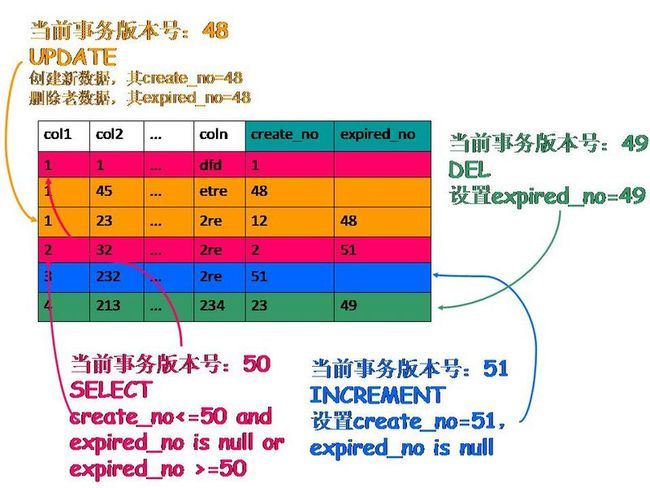
InnoDB存储引擎MVCC的实现策略:
在每一行数据中额外保存两个隐藏字段:当前行创建时的版本号和删除时的版本号(可能为空)。每个事务又有自己的版本号,这样事务内执行CRUD操作时,就通过版本号的比较来达到数据版本控制的目的。具体做法见下面的示意图。
但是在网上又看到另外一种说法:
Innodb的实现方式是:
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
二者最本质的区别是,当修改数据时是否要排他锁定,如果锁定了还算不算是MVCC?
Innodb的实现真算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据时,理想的MVCC据无能为力了。
比如,如果Transaciton1执行理想的MVCC,修改Row1成功,而修改Row2失败,此时需要回滚Row1,但因为Row1没有被锁定,其数据可能又被Transaction2所修改,如果此时回滚Row1的内容,则会破坏Transaction2的修改结果,导致Transaction2违反ACID。
理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。