机器学习实战学习笔记(七)预测数值型数据:回归
PS:该系列数据都可以在图灵社区(点击此链接)中随书下载中下载(如下)

1 用线性回归找到最佳拟合直线
线性回归
优点:结果易于理解,计算上不复杂。
缺点:对非线性的数据拟合不好。
适用数据类型:数值型和标称型数据。
假定输入数据存放在矩阵 X X X中,而回归系数存放在向量 w w w中。那么对于给定的数据 X 1 X_1 X1,预测结果将会通过 Y 1 = X 1 T w Y_1=X_1^Tw Y1=X1Tw给出。我们常用的方法极速找出使误差最小的 w w w,误差是指预测y值和真实y值之间的差值,因为该误差的简单累计有正负差值抵消,所以采用平方误差。
平方误差: ∑ i = 1 m ( y i − x i T w ) 2 \sum_{i=1}^{m}\left(y_{i}-x_{i}^{\mathrm{T}} w\right)^{2} i=1∑m(yi−xiTw)2
用矩阵表示还可以写作 ( y − X w ) T ( y − X w ) (y-Xw)^T(y-Xw) (y−Xw)T(y−Xw),对 w w w求导得: − 2 X T ( y − X w ) -2X^T(y-Xw) −2XT(y−Xw)。
这个式子的求导其实是有一定的技巧,观察其形式为平方形式,然后是标量对于向量 w w w的求导,其结果必定与 w w w的维度相同,然后就可以写出。当然也可以按部就班的求导,下面详细介绍这种类型的矩阵求导方法。
1.1 求导详解
关于上面那个式子求导(标量对向量求导),维基百科中有详细的介绍,放上两个链接:维基百科矩阵运算中的求导法则等和[通过一个例子快速上手矩阵求导]。(https://blog.csdn.net/nomadlx53/article/details/50849941)
下图是在维基百科中截取的标量关于向量求导的表格:

问题
∂ ( y − X w ) T ( y − X w ) ∂ w \frac{\partial(y-X w)^{T}(y-X w)}{\partial w} ∂w∂(y−Xw)T(y−Xw)
说明: y 、 w y、w y、w是列向量(一般说向量默认列向量), X X X为矩阵
式子演化
∂ ( y T y − y T X w − w T X T y + w T X T X w ) ∂ w \frac{\partial\left(y^{T} y-y^{T} X w-w^{T} X^{T} y+w^{T} X^{T} X w\right)}{\partial w} ∂w∂(yTy−yTXw−wTXTy+wTXTXw)
∂ y T y ∂ w − ∂ y T X w ∂ w − ∂ w T X T y ∂ w + ∂ w T X T X w ∂ w \frac{\partial y^{T} y}{\partial w}-\frac{\partial y^{T} X w}{\partial w}-\frac{\partial w^{T} X^{T} y}{\partial w}+\frac{\partial w^{T} X^{T} X w}{\partial w} ∂w∂yTy−∂w∂yTXw−∂w∂wTXTy+∂w∂wTXTXw
求导
- ∂ y T y ∂ w \frac{\partial y^{T} y}{\partial w} ∂w∂yTy求导: ∂ y T y ∂ w = 0 \frac{\partial y^{T} y}{\partial w}=0 ∂w∂yTy=0
- ∂ y T X w ∂ w \frac{\partial y^{T} X w}{\partial w} ∂w∂yTXw求导: ∂ y T X w ∂ w = X T y \frac{\partial y^{T} X w}{\partial w}=X^{T} y ∂w∂yTXw=XTy
说明:查找上方表格,在表格中匹配相应形式,对应的求导结果就是 X T y X^Ty XTy
- ∂ w T X T y ∂ w \frac{\partial w^{T} X^{T} y}{\partial w} ∂w∂wTXTy求导: ∂ w T X T y ∂ w = ∂ ( w T X T y ) T ∂ w = ∂ y T X w ∂ w = X T y \frac{\partial w^{T} X^{T} y}{\partial w}=\frac{\partial\left(w^{T} X^{T} y\right)^{T}}{\partial w}=\frac{\partial y^{T} X w}{\partial w}=X^{T} y ∂w∂wTXTy=∂w∂(wTXTy)T=∂w∂yTXw=XTy
- ∂ w T X T X w ∂ w \frac{\partial w^{T} X^{T} X w}{\partial w} ∂w∂wTXTXw求导: ∂ w T X T X w ∂ w = 2 X T X w \frac{\partial w^{T} X^{T} X w}{\partial w}=2 X^{T} X w ∂w∂wTXTXw=2XTXw
说明:同样的,在表格中匹配形式(13行),矩阵的转置乘上本身( X T X X^TX XTX为对称阵相当于表格中的 A A A)。
整合
∂ y T y ∂ w − ∂ y T X w ∂ w − ∂ w T X T y ∂ w + ∂ w T X T X w ∂ w = 0 − X T y − X T y + 2 X T X w = − 2 X T ( y − X w ) \begin{aligned} \frac{\partial y^{T} y}{\partial w}-\frac{\partial y^{T} X w}{\partial w}-\frac{\partial w^{T} X^{T} y}{\partial w}+& \frac{\partial w^{T} X^{T} X w}{\partial w}=0-X^{T} y-X^{T} y+2 X^{T} X w=\\ &-2 X^{T}(y-X w) \end{aligned} ∂w∂yTy−∂w∂yTXw−∂w∂wTXTy+∂w∂wTXTXw=0−XTy−XTy+2XTXw=−2XT(y−Xw)
1.2 最小二乘法
令求导结果等于0,解出 w w w如下: w ^ = ( X T X ) − 1 X T y \hat{w}=\left(\boldsymbol{X}^{\mathrm{T}} \boldsymbol{X}\right)^{-1} \boldsymbol{X}^{\mathrm{T}} \boldsymbol{y} w^=(XTX)−1XTy
w ^ \hat{w} w^表示当前可以估计出的 w w w的最优解(它是 w w w的最佳估计)。该方法称为OLS,“普通最小二乘法”(ordinary least squares)。
创建regression.py文件,把需要的数据文件拷贝到该文件目录,编写代码并在python命令行下进行测试:
import numpy as np
import matplotlib.pyplot as plt
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t')) - 1
dataMat = []; labelMat = []
with open(fileName, 'r') as fileObject:
for line in fileObject.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
def standRegres(xArr, yArr):
'''标准回归函数'''
xMat = np.mat(xArr); yMat = np.mat(yArr).T
xTx = xMat.T * xMat
#调用线性代数库中的函数linalg.det计算行列式
if np.linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T * yMat)
return ws
def plotStandRegres():
xArr, yArr = loadDataSet('ex0.txt')
xMat = np.mat(xArr); yMat = np.mat(yArr)
ws = standRegres(xArr, yArr)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xMat[:, 1].flatten().A[0], yMat.T[:, 0].flatten().A[0])
xCopy = xMat.copy()
print(xCopy)
xCopy.sort(0)
print(xCopy)
yHat = xCopy * ws
ax.plot(xCopy[:, 1], yHat)
plt.show()


我们可以通过计算预测值yHat序列和真实值yMat序列的相关系数判断模型的好坏:

可以看到yHat和yMat的相关系数为0.98。
2 局部加权线性回归
线性回归的一个问题是有可能出现欠拟合现象,因为它求得是具有最小均方误差的无偏估计。所以有些方法允许在估计中引入一些偏差,从而降低预测的均方误差。
其中一个方法是局部加权线性回归(Locally Weighted Linear Regression,LWLR)。在该算法中,我们给待预测点附近的每一个点赋予一定的权重;然后在这个子集上基于最小均方差来进行普通的回归。该算法解出回归系数 w w w的形式如下:
w ^ = ( X T W X ) − 1 X T W y \hat{w}=\left(X^{\mathrm{T}} W X\right)^{-1} X^{\mathrm{T}} W y w^=(XTWX)−1XTWy
其中 w w w是一个矩阵,用于给每个数据点赋予权重。
LWLR使用“核”(与支持向量机中的核类似)来对附近的点赋予更高的权重。最常用的核就是高斯核,高斯核对应的权重如下: w ( i , i ) = exp ( ∣ x ( i ) − x ∣ − 2 k 2 ) w(i, i)=\exp \left(\frac{\left|x^{(i)}-x\right|}{-2 k^{2}}\right) w(i,i)=exp(−2k2∣∣x(i)−x∣∣)
这样就构建了一个只含对角线元素的权重矩阵 w w w,并且点 x x x与 x ( i ) x(i) x(i)越近, w ( i , i ) w(i,i) w(i,i)将会越大;参数 k k k决定了对附近的点赋予多大的权重。
def lwlr(testPoint, xArr, yArr, k=1.0):
'''局部加权先行回归函数'''
xMat = np.mat(xArr); yMat = np.mat(yArr).T
m = np.shape(xMat)[0]
weights = np.mat(np.eye((m)))
for j in range(m):
diffMat = testPoint - xMat[j, :]
weights[j, j] = np.exp(diffMat * diffMat.T / (-2.0 * k**2))
xTx = xMat.T * (weights * xMat)
if np.linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = xTx.I * (xMat.T * (weights * yMat))
return testPoint * ws
def lwlrTest(testArr, xArr, yArr, k=1.0):
m = np.shape(testArr)[0]
yHat = np.zeros(m)
for i in range(m):
yHat[i] = lwlr(testArr[i], xArr, yArr, k)
return yHat
def plotLWLR(k):
xArr, yArr = loadDataSet('ex0.txt')
yHat = lwlrTest(xArr, xArr, yArr, k)
xMat = np.mat(xArr)
strInd = xMat[:, 1].argsort(0)
xSort = xMat[strInd][:, 0, :]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(xSort[:, 1], yHat[strInd])
ax.scatter(xMat[:, 1].flatten().A[0], np.mat(yArr).T.flatten().A[0], s=2, c='red')
plt.show()
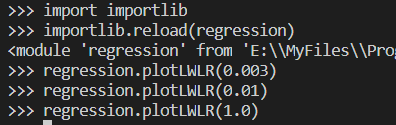



从上到下依次是k=0.003,k=0.01,k=1.0,其中k=0.003纳入了太多的噪声点,拟合的直线与数据点过于贴近造成过拟合;而k=1.0将所有数据视为等权重得出的直线与标准的回归一致;k=0.01时该模型可以挖出数据的潜在规律。
局部加权线性回归增加了计算量,因为它对每个点做预测时都必须使用整个数据集。k=0.01情况有大多数数据点的权重都接近于零,如果避免这些计算将可以减少程序运行时间。
3 预测鲍鱼的年龄
在regression.py中加入误差计算的函数,abalone.txt文件拷贝到该目录,并进行测试:
def rssError(yArr, yHatArr):
return ((yArr - yHatArr) ** 2).sum()
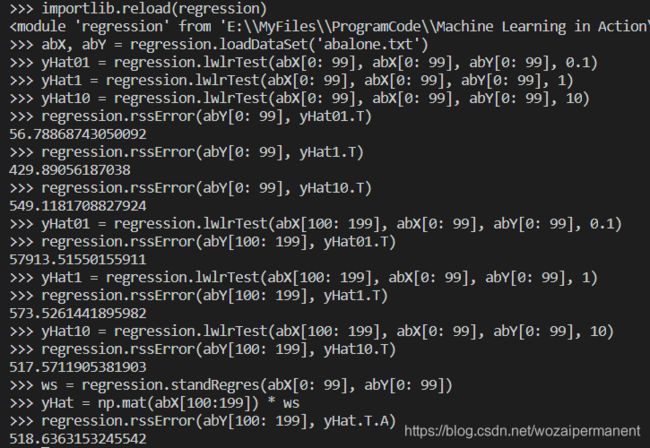
运行结果中可以看出,在训练集上0.1的核误差最小;而在测试集上,10的核误差最小,简单线性回归也达到了局部加权线性回归类似的效果。这也表明,必须在未知数据上比较效果才能选取到最佳模型。
4 缩减系数来“理解”数据
如果特征比样本点还多( n > m n>m n>m),也就是说输入数据的矩阵 X X X不是满秩矩阵,那么 X T X X^TX XTX就无法求逆,这是引入岭回归(ridge regression)。
4.1 岭回归
岭回归在矩阵 X T X X^TX XTX上加上一个 λ I \lambda I λI从而使得矩阵非奇异,进而能对 X T X + λ I X^TX+\lambda I XTX+λI求逆。其中矩阵 I I I是一个 m × m m×m m×m的单位矩阵, λ \lambda λ是用户定义的数值。回归系数计算公式:
w ^ = ( X T X + λ I ) − 1 X T y \hat{w}=\left(\boldsymbol{X}^{\mathrm{T}} \boldsymbol{X}+\lambda \boldsymbol{I}\right)^{-1} \boldsymbol{X}^{\mathrm{T}} y w^=(XTX+λI)−1XTy
岭回归最先用来处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里通过引入 λ \lambda λ来限制了所有 w w w之和,通过引入该惩罚项,能够减少不重要的参数,这个技术在统计学中也叫作缩减(shrinkage)。
def ridgeRegres(xMat, yMat, lam=0.2):
'''岭回归'''
xTx = xMat.T * xMat
denom = xTx + np.eye(np.shape(xMat)[1]) * lam
if np.linalg.det(denom) == 0.0:
print("This matrix is singular, cannot do inverse")
return
ws = denom.I * (xMat.T * yMat)
return ws
def ridgeTest(xArr, yArr):
xMat = np.mat(xArr); yMat = np.mat(yArr).T
#数据标准化:所有调整都减去各自的均值并处以方差
yMean = np.mean(yMat, 0)
yMat = yMat - yMean
xMeans = np.mean(xMat, 0)
xVar = np.var(xMat, 0)
xMat = (xMat - xMeans) / xVar
numTestPts = 30
wMat = np.zeros((numTestPts, np.shape(xMeans)[1]))
for i in range(numTestPts):
ws = ridgeRegres(xMat, yMat, np.exp(i-10))
wMat[i, :] = ws.T
return wMat
def plotRidgeRegres():
abX, abY = loadDataSet('abalone.txt')
ridgeWeights = ridgeTest(abX, abY)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(ridgeWeights)
plt.show()


该图绘出了回归系数与 l o g ( λ ) log(\lambda) log(λ)的关系。在最左边,即 λ \lambda λ最小时,可以得到所有系数的原始值(与现行回归一致);而在右边,系数全部缩减成0;在中间部分的某值将可以取得最好的预测效果。
4.2 lasso
在增加如下约束时,普通的最小二乘法回归会得到与岭回归一样的公式:
∑ k = 1 n w k 2 ⩽ λ \sum_{k=1}^{n} w_{k}^{2} \leqslant \lambda k=1∑nwk2⩽λ
lasso对回归系数做了如下约束条件:
∑ k = 1 n ∣ w k ∣ ⩽ λ \sum_{k=1}^{n}\left|w_{k}\right| \leqslant \lambda k=1∑n∣wk∣⩽λ
唯一的不同点在于,这个约束条件使用了绝对值取代了平方和。在 λ \lambda λ足够小的时候,一些系数会因此被迫缩减到0。
4.3 前向逐步回归
前向逐步回归可以得到与lasso差不多的效果,但更加简单。它是一种贪心算法,即每一步都尽可能减少误差。一开始,所有的权重都设为1,然后每一步所做的决策是对某个权重增加或减少一个很小的值。
伪代码:
数据标准化,使其分布满足0均值和单位方差
在每轮迭代过程中:
设置当前最小误差lowestError为正无穷
对每个特征:
增加或缩小:
改变一个系数得到一个新的W
计算新的W下的误差
如果误差Error小于当前最小误差lowestError:
设置Wbest等于当前的W
将W设置为新的Wbest
def regularize(xMat):
'''标准化'''
inMat = xMat.copy()
inMeans = np.mean(inMat, 0)
inVar = np.var(inMat, 0)
inMat = (inMat - inMeans) / inVar
return inMat
def stageWise(xArr, yArr, eps=0.01, numIt=100):
'''
向前逐步线性回归
eps: 每次迭代需要调整的步长
'''
xMat = np.mat(xArr); yMat = np.mat(yArr).T
#把特征按照均值为0方差为1进行标准化处理
yMean = np.mean(yMat, 0)
yMat = yMat - yMean
xMat = regularize(xMat)
m, n = np.shape(xMat)
returnMat = np.zeros((numIt, n))
ws = np.zeros((n, 1))
wsTest = ws.copy()
wsMax = ws.copy()
for i in range(numIt):
print(ws.T)
lowestError = float('inf')
for j in range(n):
for sign in [-1, 1]:
wsTest = ws.copy()
wsTest[j] += eps * sign
yTest = xMat * wsTest
rssE = rssError(yMat.A, yTest.A)
if rssE < lowestError:
lowestError = rssE
wsMax = wsTest
ws = wsMax.copy()
returnMat[i, :] = ws.T
return returnMat

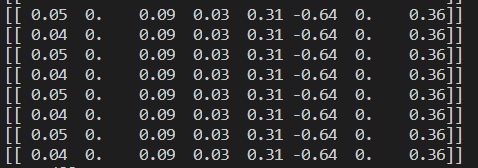
w1和w6都是0,这表明它们不对目标值造成任何影响,也就是说这些特征很有可能是不需要的。另外,在eps=0.01的情况下,一段时间后系数就已经饱和并在特定值之间来回震荡,这是由于步长太大的缘故。这里,第一个权重在0.04和0.05之间来回震荡。改用更小的步长和更多的步数:,观察结果
![]()

5 均衡偏差和方差
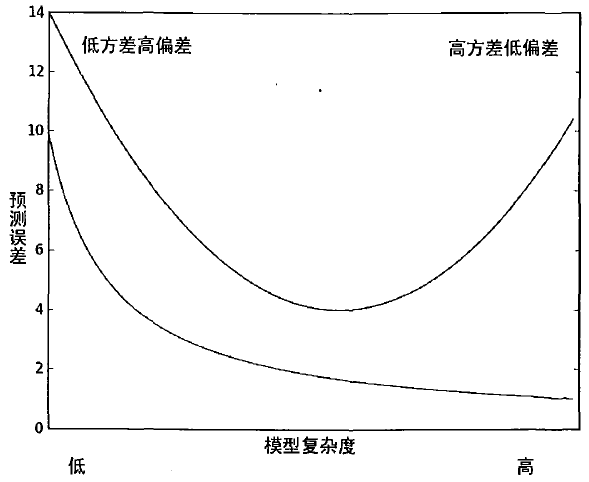
上方曲线是测试误差,下方曲线是训练误差。
方差指的是模型之间的差异,偏差指的是模型预测值和数据之间的差异
6 预测乐高玩具套装的价格
6.1 收集数据
由于提供的API已经过期,我们将直接在下载下来的html文件中进行收集,首先通过pip install beautifulsoup4安装解析HTML的相应包:
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
'''从页面读取数据,生成retX和retY列表'''
from bs4 import BeautifulSoup
#打开并读取HTML文件
fr = open(inFile, 'rb')
soup = BeautifulSoup(fr.read())
i=1
#根据HTML页面结构进行解析
currentRow = soup.findAll('table', r="%d" % i)
while(len(currentRow) != 0):
currentRow = soup.findAll('table', r="%d" % i)
title = currentRow[0].findAll('a')[1].text
lwrTitle = title.lower()
#查找是否有全新标签
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
#查找是否已经标志出售,我们只收集已出售的数据
soldUnicde = currentRow[0].findAll('td')[3].findAll('span')
if len(soldUnicde) == 0:
print("item #%d did not sell" % i)
else:
#解析页面获取当前价格
soldPrice = currentRow[0].findAll('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$', '')
priceStr = priceStr.replace(',', '')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
#去掉不完整的套装价格
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr,numPce,newFlag,origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.findAll('table', r="%d" % i)
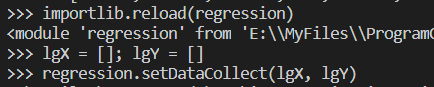
def setDataCollect(retX, retY):
'''依次读取六种乐高套装的数据,并生成数据矩阵'''
scrapePage(retX, retY, 'setHtml/lego8288.html', 2006, 800, 49.99)
scrapePage(retX, retY, 'setHtml/lego10030.html', 2002, 3096, 269.99)
scrapePage(retX, retY, 'setHtml/lego10179.html', 2007, 5195, 499.99)
scrapePage(retX, retY, 'setHtml/lego10181.html', 2007, 3428, 199.99)
scrapePage(retX, retY, 'setHtml/lego10189.html', 2008, 5922, 299.99)
scrapePage(retX, retY, 'setHtml/lego10196.html', 2009, 3263, 249.99)
6.2 训练算法:建立模型
def crossValidation(xArr, yArr, numVal=10):
'''交叉验证测试岭回归'''
m = len(yArr)
indexList = range(m)
errorMat = np.zeros((numVal,30))
#主循环 交叉验证循环
for i in range(numVal):
#随机拆分数据,将数据分为训练集(90%)和测试集(10%)
trainX=[]; trainY=[]
testX = []; testY = []
#对数据进行混洗操作
np.random.shuffle(list(indexList))
#切分训练集和测试集
for j in range(m):
if j < m * 0.9:
trainX.append(xArr[indexList[j]])
trainY.append(yArr[indexList[j]])
else:
testX.append(xArr[indexList[j]])
testY.append(yArr[indexList[j]])
#获得回归系数矩阵
wMat = ridgeTest(trainX, trainY)
#循环遍历矩阵中的30组回归系数
for k in range(30):
matTestX = np.mat(testX); matTrainX = np.mat(trainX)
#对数据进行标准化
meanTrain = np.mean(matTrainX, 0)
varTrain = np.var(matTrainX, 0)
matTestX = (matTestX - meanTrain) / varTrain
yEst = matTestX * np.mat(wMat[k, :]).T + np.mean(trainY)
#计算误差
errorMat[i, k] = ((yEst.T.A - np.array(testY)) ** 2).sum()
#计算误差估计值的均值
meanErrors = np.mean(errorMat, 0)
minMean = float(min(meanErrors))
bestWeights = wMat[np.nonzero(meanErrors == minMean)]
#不要使用标准化的数据,需要对数据进行还原来得到输出结果
xMat = np.mat(xArr); yMat = np.mat(yArr).T
meanX = np.mean(xMat, 0); varX = np.var(xMat, 0)
unReg = bestWeights / varX
print("the best model from Ridge Regression is:\n", unReg)
print("with constant term: ", -1 * sum(np.multiply(meanX, unReg)) + np.mean(yMat))
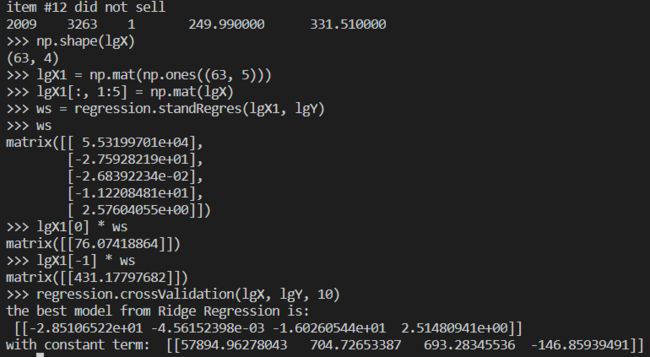
简单线性回归结果得到的套装售价公式:
55319.97 − 27.59 ∗ Year − 0.00268 ∗ Numpieces − 11.22 ∗ NewOrUsed + 2.57 ∗ ori ginal price 55319.97-27.59 * \text {Year}-0.00268 * \text { Numpieces} -11.22 * \text { NewOrUsed }+2.57 * \text { ori ginal price } 55319.97−27.59∗Year−0.00268∗ Numpieces−11.22∗ NewOrUsed +2.57∗ ori ginal price
交叉验证岭回归得到的套装售价公式:
57894.96 − 28.51 ∗ Year − 0.00456 ∗ Numpieces − 16.026 ∗ NewOrUsed + 2.51 ∗ original price 57894.96-28.51 * \text {Year}-0.00456 * \text { Numpieces }-16.026 * \text { NewOrUsed }+2.51 * \text { original price} 57894.96−28.51∗Year−0.00456∗ Numpieces −16.026∗ NewOrUsed +2.51∗ original price
7 小结
回归于分类的不同点在于,前者预测连续型变量,而后者预测离散型变量。
岭回归是缩减法的一种,相当于对回归系数的大小事假了限制。另一种很好的缩减法是lasso。Lasso难以求解,但可以使用计算简便的逐步线性回归方法来求得近似结果。
缩减法还可以看做是对一个模型增加偏差的同时见啥方法。偏差方差折中是一个重要概念。