数据库原理与应用笔记(二):关系数据库
关系数据库
- 2.1关系数据结构及形式化定义
-
- 2.1.1关系
- 2.1.2关系模式
- 2.1.3关系数据库
- 2.1.4关系模型的存储结构
- 2.2关系操作
-
- 2.2.1 基本的关系操作
- 2.2.2 关系数据语言的分类
- 2.3关系的完整性
-
- 2.3.1 实体完整性
- 2.3.2参照完整性
- 2.3.3用户定义的完整性
- 2.4关系代数
-
- 2.4.1传统的集合运算
- 2.4.2专门的关系运算
2.1关系数据结构及形式化定义
关系数据库系统是支持关系模型的数据库系统,按照数据模型的三个要素,关系模型由关系数据结构、关系操作集合和关系完整性约束三部分组成。
2.1.1关系
定义:1域domain
域是一组具有相同数据类型的值的集合
例如:自然数,整数,{男,女}
定义:2笛卡尔积cartesian product
笛卡尔积是域上的一种集合运算

每一个元素(d1,d2,…dn)叫做一个n元组,元组里每一个d叫做分量
一个域允许的不同取值的个数称为这个域的基数


3关系relation
定义:

这里R表示关系的名字,n是关系的目或度
当n=1时,称该关系为单元关系或一元关系
当n=2时,称该关系为二元关系
若关系中的某一个属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码candidate key
若一个关系有多个候选码,则选定其中一个为主码primary key
候选码的诸属性称为主属性prime attribute。不包含在任何候选码中的属性称为非主属性non-prime attribute或非码属性non-key attribute
在最简单的情况下,候选码只包含一个属性。关系模式的所有属性是这个关系模式的候选码,称为全码
下面这段文字对理解上面概念很重要!!!
例如在一个属性组中有{学号,性别},而学号可以唯一的表示一个人,因为每个人的学号是唯一的,所以这个属性组就是候选码,而这个关系中又有一个{学号,姓名}的属性组的话,就选两个属性组的其中一个为主码,如果一个属性组只有{学号},那这个学号就是全码,{学号,性别}里的学号和性别就是主属性
关系可以有三种类型:基本关系、查询表和视图表(后面章节会介绍,这里不做解释)
基本关系具有以下6条性质
(1)列是同质的,即每一列中的分量是同一类型的数据,来自同一个域
(2)不同的列可出自同一个域,称其中的每一列为一个属性,不同的属性要给与不同的属性名
(3)列的顺序为所谓,即列的次序可以任意交换。所以新增列表属性时永远插入最后一列
(4)任意两个元组的候选码不能取相同的值
(5)行的顺序无所谓,即行的次序可以任意交换
(6)分量必须取原子值,即每一个分量都必须是不可分的数据项(最基本)
| 列 | 名字(同一类型即这列都是名字) |
|---|---|
| 每一列都是一个属性 | 名字都是同一类型的 |
2.1.2关系模式
在数据库中要区分型和值。关系数据库中,关系模式是型,关系是值
定义:关系的描述称为关系模式。可以形式化的表示为R(U,D,DOM,F)
其中R为关系名,U为组成该关系的属性名集合,D为U中所有属性的域,DOM为属性向域的映像集合,F为属性间数据的依赖关系集合
2.1.3关系数据库
关系数据库的型也称为关系数据库模式,是对关系数据库的描述
关系数据库的值是这些关系模式在某一时刻对应的关系的集合,通常就称为关系数据库
2.1.4关系模型的存储结构
组织表,索引等
2.2关系操作
2.2.1 基本的关系操作
关系模式中常用的关系操作包括查询query操作和插入insert、删除delete、修改update操作两大部分(不是四个吗?怎么是两大部分?查询算一操作,其他三个算一操作)
查询操作可以分为选择select、投影project、连接join、除divide、并union、差expect、交intersection、笛卡尔积等,其中选择、投影、并、差、笛卡尔积是5种基本操作
关系操作的特点是集合操作方式,即操作的对象和结果都是集合
2.2.2 关系数据语言的分类
关系代数语言(例如ISBL)
关系演算语言:元组关系演算语言(例如ALPHA、QUEL)、域关系演算语言(例如QBE)
具有关系代数和关系演算双重特点的语言(例如SQL)
2.3关系的完整性
关系模式的完整性规则是对关系的某种约束条件
关系模型中有三类完整性约束:实体完整性(entity integrity)、参照完整性(referential integrity)和用户定义的完整性(user-defind integrity)
2.3.1 实体完整性
实体完整性规则:若属性(指一个或一组属性)A是基本关系R的主属性,则A不能取空值(null value)。所谓空值就是“不知道”或“不存在”或“无意义”的值
例:一组属性{学号,姓名},学号的唯一的,所以学号不能为空值
实体完整性规则说明如下:
(1)实体完整性规则是针对基本关系而言的
(2)现实世界中的实体是可区分的
(3)相应地,关系模型中以主码作为唯一性标识
(4)主码中的属性即主属性不能取空值
2.3.2参照完整性
定义:设F是基本关系R的一个或一组属性,但不是关系R的码,Ks是基本关系S的主码。如果F与Ks相对应,则称F是R的外码foreign key,并称基本关系R为参照关系referencing relation,基本关系S为被参照关系referenced relation或目标关系target relation。
下面这段文字对理解上面概念很重要!!!
例:一个关于学生的属性组为{姓名,年龄,成绩},另一个关于专业课的属性组为{专业课程号,姓名},在学生的属性组中姓名为主码,在专业课属性组中专业课程号为主码,姓名则为外码,专业课属性组为参照关系,学生属性组为被参照关系
参照完整性规则:若属性或属性组F是基本关系R的外码,它与基本关系S的主码Ks相对应,(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须①或者取空值(F的每个属性值均为空值)②或者等于S中某个元组的主码值
比如在上面的例子中,在专业课的属性组中的姓名要么为空(即这个学生没有选这个专业课),要么等于某个学生的属性组中的姓名
2.3.3用户定义的完整性
用户定义的完整性就是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。例如某个属性必须取唯一值,某个数字的范围必须在0-20等
2.4关系代数
关系代数是一种抽象的查询语言,它用对关系的运算来表达查询
关系代数的运算按运算符的不同可分为传统的集合运算和专门的关系运算两类

2.4.1传统的集合运算
传统的集合运算时二目运算,包括并、差、交、笛卡尔积4种运算。
设关系R和关系S具有相同的目n,(即两个关系都有n个属性),且相应的属性取自同一个域,t是元组变量,t∈R表示t是R的一个元组
可以定义并、差、交、笛卡尔积运算如下
(1)并union

结果仍为n目关系,由属于R或属于S的元组组成
例:

(2)差except

结果仍为n目关系,由属于R而不属于S的元组组成
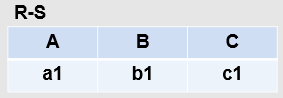
(3)交interscetion


(4)笛卡尔积cartesian product


2.4.2专门的关系运算
专门的关系运算包括选择、投影、连接、除运算等。
先引用几个后面需要用的概念




关于象集是笔者在学习中感到相对比较抽象的一个概念
所以在此进行引例说明:
| x1 | Z1 |
|---|---|
| x1 | Z2 |
| x2 | Z2 |
| x2 | Z3 |
如上关系,可得出,x1在关系中的象集Zx1={Z1,Z2};X2在关系中的象集Zx2={Z2,Z3}
下面给出这些专门的关系运算的定义
1选择selection
选择又称为限制restriction。它是在关系R中选择满足给定条件的诸元组

其中F表示选择条件,它是一个逻辑表达式,取逻辑值“真”或“假”,F的基本形式如下

例如
即查询信息系IS的全体选手,Sdept:系 IS:信息
2投影projection
关系R上的投影是从R中选择出若干属性列组成新的关系

这个很简单,就是从很多列中挑出你喜欢的列再组成一个新的关系
3连接join
是从两个关系的笛卡尔积中选取属性间满足一定条件的元组

连接运算中有两种重要且常用的连接:等值连接equijoin和自然连接natural jion
等值连接是选取属性值相等的元组
自然连接是同名的属性组且没有重复属性列
被舍弃的元组称为悬浮元组
有关悬浮元组的外连接概念如下:

(4)除运算division
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S的属性及其值,且T的元组与S的元组的所有组合都在R中
除运算用上面所述的象集来描述:

笔记使用教材:《数据库系统概论》 王珊 萨师煊 编著
视频课:中国大学MOOC 中国人民大学 数据库系统概论