机器学习模型5——贝叶斯分类器
前置知识
条件概率
贝叶斯公式
(贝叶斯模型还是很好理解的,主要基于高中就学到过的条件概率。)
贝叶斯定理
P(A),P(B)分别是事件A,B发生的概率,而P(A|B)是在事件A在事件B发生的前提下发生的概率,P(AB)是事件A,B同时发生的概率。那么我们的有公式: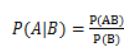 。
。
那么贝叶斯定理是:![clip_image004[8]](http://img.e-com-net.com/image/info8/ac6f6956bb824d2ebe6bf9287c60f97c.jpg)
注:P(AB)=P(A)P(B)的充分必要条件是事件A和事件B相互独立。用通俗的语言讲就是,事件A是否发生不会影响到事件B发生的概率。
朴素贝叶斯
设样本属性集合为x{x1,x2,x3…xn},n为数目,xi为取值;设c为类别集合,把样本划分为某一类,c={y1,y2,y3…ym}.
假设属性特征相互独立,贝叶斯公式可写为: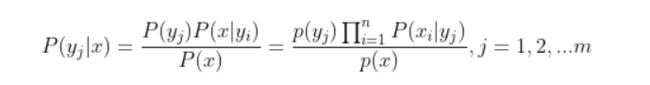
拉普拉斯平滑系数
朴素贝叶斯API
这些是基于应用贝叶斯定理和强(朴素)特征独立性假设的监督学习方法。
naive_bayes.BernoulliNB(*[, alpha, ...])Naive Bayes classifier for multivariate Bernoulli models.
naive_bayes.CategoricalNB(*[, alpha, ...])Naive Bayes classifier for categorical features.
naive_bayes.ComplementNB(*[, alpha, ...])The Complement Naive Bayes classifier described in Rennie et al. (2003).
naive_bayes.GaussianNB(*[, priors, ...])Gaussian Naive Bayes (GaussianNB).
naive_bayes.MultinomialNB(*[, alpha, ...])Naive Bayes classifier for multinomial models.
MultinomialNB多项式模型的朴素贝叶斯分类器。
多项式Naive Bayes分类器适用于具有离散特征的分类(例如,文本分类的字数)。多项式分布通常需要整数特征计数。然而,在实践中,分数计数(如tf-idf)也可能有效。
class sklearn.naive_bayes.MultinomialNB(*, alpha=1.0, fit_prior=True, class_prior=None)
参数:
- alpha: float, default=1.0
添加剂(拉普拉斯/利德斯通)平滑参数(0表示无平滑)。 - fit_prior: bool, default=True
是否学习课堂先验概率。如果错误,将使用统一的优先权。 - class_prior: array-like of shape (n_classes,), default=None
类别的先验概率。如果指定,则不根据数据调整优先级。
BernoulliNB多元贝努利模型的朴素贝叶斯分类器
与MultinomialNB一样,该分类器适用于离散数据。不同之处在于,虽然MultinomalNB可以处理出现次数,但BernoulliNB是为二进制/布尔特征设计的。
class sklearn.naive_bayes.BernoulliNB(*, alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None
参数:
- binarize: float or None, default=0.0
样本特征的二值化(映射到布尔值)阈值。如果无,则假定输入已经包含二进制矢量。
CategoricalNB分类特征的朴素贝叶斯分类器。
分类朴素贝叶斯分类器适用于具有分类分布的离散特征的分类。每个特征的类别都是从分类分布中得出的。
class sklearn.naive_bayes.CategoricalNB(*, alpha=1.0, fit_prior=True, class_prior=None, min_categories=None)
参数:
- min_categories:int or array-like of shape (n_features,), default=None
每个功能的最小类别数。
integer:将每个要素的最小类别数设置为每个要素的n_categories。
array-like:shape(n_features,)其中n_categories[i]包含输入的第i列的最小类别数。
None(default):根据训练数据自动确定类别数。
ComplementNB互补朴素贝叶斯分类器。
互补朴素贝叶斯分类器旨在纠正标准多项式朴素贝叶斯分类器所做的“严重假设”。它特别适合不平衡的数据集。
class sklearn.naive_bayes.ComplementNB(*, alpha=1.0, fit_prior=True, class_prior=None, norm=False)
参数:
- norm: bool, default=False
是否执行权重的第二次规格化。默认行为反映了在Mahout和Weka中发现的实现,它们不遵循本文表9中描述的完整算法。
GaussianNB高斯朴素贝叶斯
可以通过partial_fit在线更新模型参数。
class sklearn.naive_bayes.GaussianNB(*, priors=None, var_smoothing=1e-09)[source]
参数:
- priors:array-like of shape (n_classes,)
类别的先验概率。如果指定,则不根据数据调整优先级。 - var_smoothing:float, default=1e-9
所有特征中最大方差的一部分,添加到方差中以保持计算稳定性。
朴素⻉叶斯优缺点
优点:
- 朴素⻉叶斯模型发源于古典数学理论,有稳定的分类效率
- 对缺失数据不太敏感,算法也⽐较简单,常⽤于⽂本分类
- 分类准确度⾼,速度快
缺点:
- 由于使⽤了样本属性独⽴性的假设,所以如果特征属性有关联时其效果不好
- 需要计算先验概率,⽽先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设 的先验模型的原因导致预测效果不佳
参考
1.黑马学习