李宏毅机器学习之RNN
一、应用举例
- Slot Filling
- 假设订票系统听到用户说:“ i would like to arrive Taipei on November 2nd”,你的系统有一些slot(有一个slot叫做Destination,一个slot叫做time of arrival),系统要自动知道这边的每一个词汇是属于哪一个slot,比如Taipei属于Destination这个slot,November 2nd属于time of arrival这个slot。

- 也可以使用一个feedforward neural network来解,也就是说我叠一个feedforward neural network,input是一个词汇(把Taipei变成一个vector)丢到这个neural network里面去(你要把一个词汇丢到一个neural network里面去,就必须把它变成一个向量来表示)。

- 以下是把词汇用向量来表示的方法:
- 如果只是用1-of-N encoding来描述一个词汇的话你会遇到一些问题,因为有很多词汇你可能都没有见过,所以你需要在1-of-N encoding里面多加dimension,这个dimension代表other。然后所有的词汇,如果它不是在我们词言有的词汇就归类到other里面去(Gandalf,Sauron归类到other里面去)。你可以用每一个词汇的字母来表示它的vector,比如说,你的词汇是apple,apple里面有出现app、ppl、ple,那在这个vector里面对应到app,ple,ppl的dimension就是1,而其他都为0。

- 假设把词汇表示为vector,把这个vector丢到feedforward neural network里面去,在这个task里面,你就希望你的output是一个probability distribution。这个probability distribution代表着我们现在input这词汇属于每一个slot的几率,比如Taipei属于destination的几率和Taipei属于time of departure的几率。
- 但是光只有这个是不够的,feedforward neural network是没有办法解决这个问题。为什么呢,假设现在有一个使用者说:“arrive Taipei on November 2nd”(arrive-other,Taipei-dest, on-other,November-time,2nd-time)。那现在有人说:"leave Taipei on November 2nd",这时候Taipei就变成了“place of departure”,它应该是出发地而不是目的地。但是对于neural network来说,input一样的东西output就应该是一样的东西(input "Taipei",output要么是destination几率最高,要么就是place of departure几率最高),你没有办法一会让出发地的几率最高,一会让它目的地几率最高。这个怎么办呢?这时候就希望我们的neural network是有记忆力的。如果今天我们的neural network是有记忆力的,它记得它看过红色的Taipei之前它就已经看过arrive这个词汇;它记得它看过绿色之前,它就已经看过leave这个词汇,它就可以根据上下文产生不同的output。如果让我们的neural network是有记忆力的话,它就可以解决input不同的词汇,output不同的问题。
二、什么是RNN?
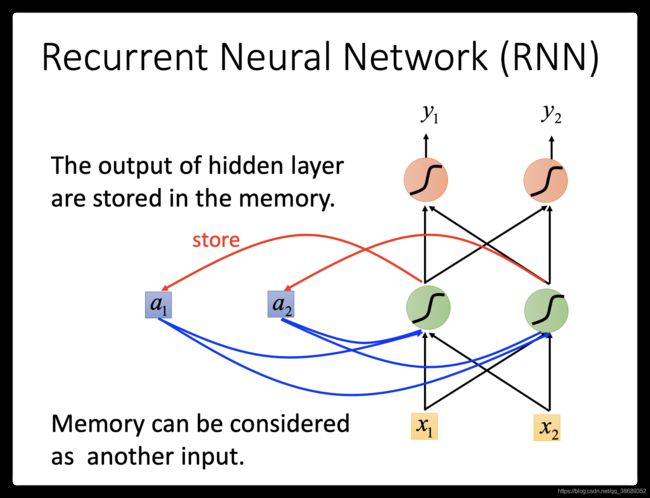
2.1 RNN的介绍
- 这种有记忆的neural network就叫做Recurrent Neural network(RNN)。在RNN里面,每一次hidden layer的neuron产生output的时候,这个output会被存到memory里去(用蓝色方块表示memory)。那下一次当有input时,这些neuron不只是考虑input的
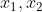 ,还会考虑存到memory里的值。对它来说除了以外,这些存在memory里的值
,还会考虑存到memory里的值。对它来说除了以外,这些存在memory里的值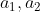 也会影响它的output。
也会影响它的output。
2.2 举例
- 举个例子,假设我们现在图上这个neural network,它所有的weight都是1,所有的neuron没有任何的bias。假设所有的activation function都是linear(这样可以不要让计算太复杂)。现在假设我们的input 是sequence
 把这个sequence输入到neural network里面去会发生什么事呢?在你开始要使用这个Recurrent Neural Network的时候,你必须要给memory初始值(假设他还没有放进任何东西之前,memory里面的值是0)。现在输入第一个
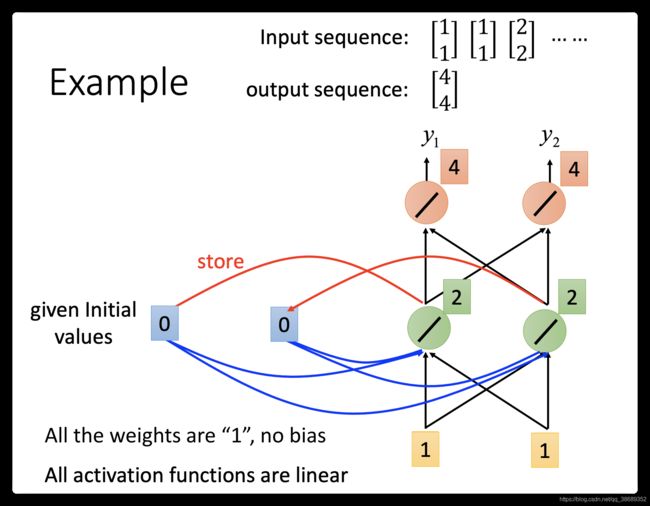
把这个sequence输入到neural network里面去会发生什么事呢?在你开始要使用这个Recurrent Neural Network的时候,你必须要给memory初始值(假设他还没有放进任何东西之前,memory里面的值是0)。现在输入第一个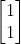 ,接下来对发生什么事呢?,对左边的那个neural来说(第一个hidden layer),它除了接到input的还接到了memory(0跟0),output就是2(所有的weight都是1),右边也是一样output为2。第二层hidden laeyer output为4。
,接下来对发生什么事呢?,对左边的那个neural来说(第一个hidden layer),它除了接到input的还接到了memory(0跟0),output就是2(所有的weight都是1),右边也是一样output为2。第二层hidden laeyer output为4。
-
接下来Recurrent Neural Network会将绿色neuron的output存在memory里去,所以memory里面的值被update为2。
接下来再输入
,接下来绿色的neuron输入有四个 ,output为
,output为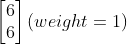 ,第二层的neural output为
,第二层的neural output为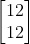 。所以对Recurrent Neural Network来说,你就算input一样的东西,它的output是可能不一样了(因为有memory)
。所以对Recurrent Neural Network来说,你就算input一样的东西,它的output是可能不一样了(因为有memory)

-
现在
 存到memory里去,接下来input是
存到memory里去,接下来input是 ,output为
,output为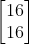 ,第二层hidden layer为
,第二层hidden layer为 。那在做Recurrent Neural Network时,有一件很重要的事情就是这个input sequence调换顺序之后output不同(Recurrent Neural Network里,它会考虑sequence的order)
。那在做Recurrent Neural Network时,有一件很重要的事情就是这个input sequence调换顺序之后output不同(Recurrent Neural Network里,它会考虑sequence的order)
2.3 RNN架构
-
今天我们要用Recurrent Neural Network处理slot filling这件事,就像是这样,使用者说:“arrive Taipei on November 2nd”,arrive就变成了一个vector丢到neural network里面去,neural network的hidden layer的output写成
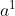 (是一排neural的output,是一个vector),产生
(是一排neural的output,是一个vector),产生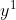 ,就是“arrive”属于每一个slot filling的几率。接下来会被存到memory里面去,"Taipei会变为input",这个hidden layer会同时考虑“Taipei”这个input和存在memory里面的,得到
,就是“arrive”属于每一个slot filling的几率。接下来会被存到memory里面去,"Taipei会变为input",这个hidden layer会同时考虑“Taipei”这个input和存在memory里面的,得到 ,根据得到
,根据得到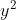 ,是属于每一个slot filling的几率。以此类推(
,是属于每一个slot filling的几率。以此类推(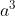 得到)。有人看到这里,说这是有三个network,这个不是三个network,这是同一个network在三个不同的时间点被使用了三次。(我这边用同样的weight用同样的颜色表示)
得到)。有人看到这里,说这是有三个network,这个不是三个network,这是同一个network在三个不同的时间点被使用了三次。(我这边用同样的weight用同样的颜色表示)
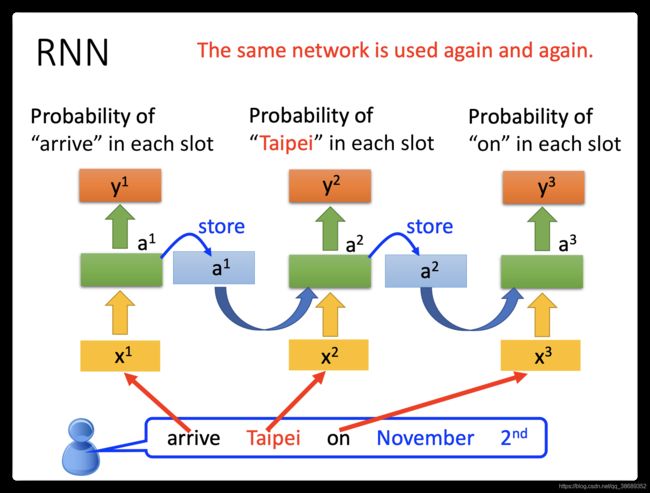
- 那所以我们有了memory以后,刚才我们讲了输入同一个词汇,我们希望output不同的问题就有可能被解决。比如说,同样是输入“Taipei”这个词汇,但是因为红色“Taipei”前接了“leave”,绿色“Taipei”前接了“arrive”(因为“leave”和“arrive”的vector不一样,所以hidden layer的output会不同),所以存在memory里面的值会不同。现在虽然x_2x2的值是一样的,因为存在memory里面的值不同,所以hidden layer的output会不一样,所以最后的output也就会不一样。这是Recurrent Neural Network的基本概念。
2.4 其他RNN
-
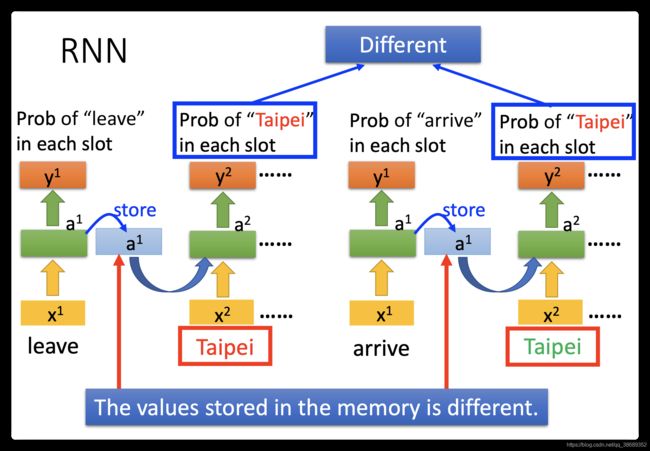
Recurrent Neural Networ的架构是可以任意设计的,比如说,它当然是deep(刚才我们看到的Recurrent Neural Networ它只有一个hidden layer),当然它也可以是deep Recurrent Neural Networ。比如说,我们把x^txt丢进去之后,它可以通过一个hidden layer,再通过第二个hidden layer,以此类推(通过很多的hidden layer)才得到最后的output。每一个hidden layer的output都会被存在memory里面,在下一个时间点的时候,每一个hidden layer会把前一个时间点存的值再读出来,以此类推最后得到output,这个process会一直持续下去。
2.4.1 Elman network &Jordan network
-
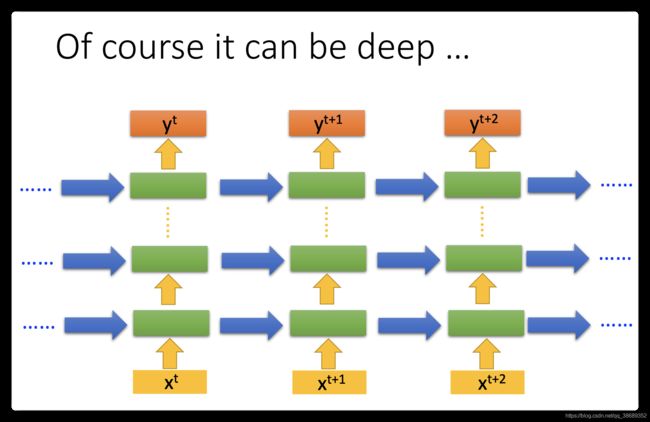
Recurrent Neural Networ会有不同的变形,我们刚才讲的是Elman network。(如果我们今天把hidden layer的值存起来,在下一个时间点在读出来)。还有另外一种叫做Jordan network,Jordan network存的是整个network output的值,它把output值在下一个时间点在读进来(把output存到memory里)。传说Jordan network会得到好的performance。
-
Elman network是没有target,很难控制说它能学到什么hidden layer information(学到什么放到memory里),但是Jordan network是有target,今天我们比较很清楚我们放在memory里是什么样的东西。
2.4.2 Bidirectional neural network
- Recurrent Neural Networ还可以是双向,什么意思呢?我们刚才Recurrent Neural Networ你input一个句子的话,它就是从句首一直读到句尾。假设句子里的每一个词汇我们都有
 表示它。他就是先读在读
表示它。他就是先读在读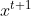 在读
在读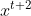 。但是它的读取方向也可以是反过来的,它可以先读,再读,再读。你可以同时train一个正向的Recurrent Neural Network,又可以train一个逆向的Recurrent Neural Network,然后把这两个Recurrent Neural Network的hidden layer拿出来,都接给一个output layer得到最后的
。但是它的读取方向也可以是反过来的,它可以先读,再读,再读。你可以同时train一个正向的Recurrent Neural Network,又可以train一个逆向的Recurrent Neural Network,然后把这两个Recurrent Neural Network的hidden layer拿出来,都接给一个output layer得到最后的 。所以你把正向的network在input的时候跟逆向的network在input时,都丢到output layer产生,然后产生
。所以你把正向的network在input的时候跟逆向的network在input时,都丢到output layer产生,然后产生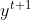 ,
,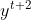 ,以此类推。用Bidirectional neural network的好处是,neural在产生output的时候,它看的范围是比较广的。如果你只有正向的network,再产生,的时候,你的neural只看过
,以此类推。用Bidirectional neural network的好处是,neural在产生output的时候,它看的范围是比较广的。如果你只有正向的network,再产生,的时候,你的neural只看过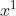 到的input。但是我们今天是Bidirectional neural network,在产生的时候,你的network不只是看过,到所有的input,它也看了从句尾到的input。那network就等于整个input的sequence。假设你今天考虑的是slot filling的话,你的network就等于看了整个sentence后,才决定每一个词汇的slot应该是什么。这样会比看sentence的一半还要得到更好的performance。
到的input。但是我们今天是Bidirectional neural network,在产生的时候,你的network不只是看过,到所有的input,它也看了从句尾到的input。那network就等于整个input的sequence。假设你今天考虑的是slot filling的话,你的network就等于看了整个sentence后,才决定每一个词汇的slot应该是什么。这样会比看sentence的一半还要得到更好的performance。
2.4.3 Long Short-term Memory(LSTM)
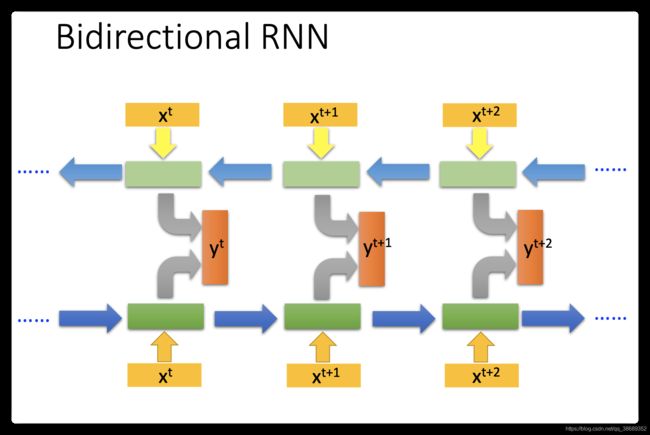
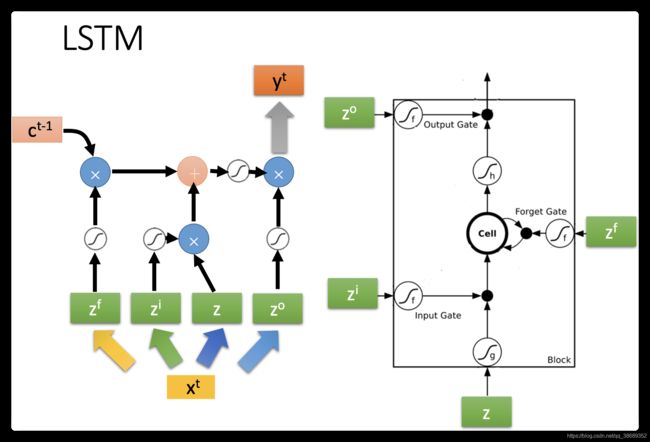
- 那我们刚才讲的memory是最单纯的,我们可以随时把值存到memory去,也可以把值读出来。但现在最常用的memory称之为Long Short-term Memory(长时间的短期记忆),简写LSTM.这个Long Short-term Memor是比较复杂的。
- 这个Long Short-term Memor是有三个gate,当外界某个neural的output想要被写到memory cell里面的时候,必须通过一个input Gate,那这个input Gate要被打开的时候,你才能把值写到memory cell里面去,如果把这个关起来的话,就没有办法把值写进去。至于input Gate是打开还是关起来,这个是neural network自己学的(它可以自己学说,它什么时候要把input Gate打开,什么时候要把input Gate关起来)。那么输出的地方也有一个output Gate,这个output Gate会决定说,外界其他的neural可不可以从这个memory里面把值读出来(把output Gate关闭的时候是没有办法把值读出来,output Gate打开的时候,才可以把值读出来)。那跟input Gate一样,output Gate什么时候打开什么时候关闭,network是自己学到的。那第三个gate叫做forget Gate,forget Gate决定说:什么时候memory cell要把过去记得的东西忘掉。这个forget Gate什么时候会把存在memory的值忘掉,什么时候会把存在memory里面的值继续保留下来),这也是network自己学到的。
- 那整个LSTM你可以看成,它有四个input 1个output,这四个input中,一个是想要被存在memory cell的值(但它不一定存的进去)还有操控input Gate的讯号,操控output Gate的讯号,操控forget Gate的讯号,有着四个input但它只会得到一个output.
- 冷知识:这个“-”应该在short-term中间,是长时间的短期记忆。想想我们之前看的Recurrent Neural Network,它的memory在每一个时间点都会被洗掉,只要有新的input进来,每一个时间点都会把memory 洗掉,所以的short-term是非常short的,但如果是Long Short-term Memory,它记得会比较久一点(只要forget Gate不要决定要忘记,它的值就会被存起来)。
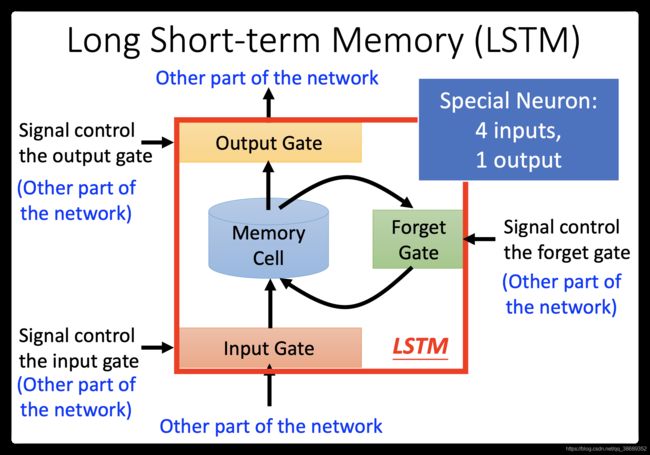
- 这个memory cell更仔细来看它的formulation,它长的像这样。
- 底下这个是外界传入cell的input,还有input gate,forget gate,output gate。现在我们假设要被存到cell的input叫做z,操控input gate的信号叫做
 (一个数值),所谓操控forget gate的信号叫做
(一个数值),所谓操控forget gate的信号叫做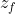 ,操控output gate叫做
,操控output gate叫做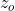 ,综合这些东西会得到一个output 记为a。假设cell里面有这四个输入之前,它里面已经存了值c。
,综合这些东西会得到一个output 记为a。假设cell里面有这四个输入之前,它里面已经存了值c。 - 假设要输入的部分为z,那三个gate分别是由,,所操控的。那output a会长什么样子的呢。我们把z通过activation function得到g(z),那通过另外一个activation function得到
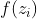 ( ,, 通过的activation function 通常我们会选择sigmoid function),选择sigmoid function的意义是它的值是介在0到1之间的。这个0到1之间的值代表了这个gate被打开的程度(如果这个f的output是1,表示为被打开的状态,反之代表这个gate是关起来的)。
( ,, 通过的activation function 通常我们会选择sigmoid function),选择sigmoid function的意义是它的值是介在0到1之间的。这个0到1之间的值代表了这个gate被打开的程度(如果这个f的output是1,表示为被打开的状态,反之代表这个gate是关起来的)。 - 那接下来,把g(z)g(z)乘以得到
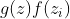 ,对于forget gate的,也通过sigmoid的function得到
,对于forget gate的,也通过sigmoid的function得到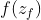
- 接下来把存到memory里面的值c乘以得到
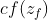 ,然后加起来
,然后加起来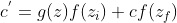 ,那么c′就是重新存到memory里面的值。所以根据目前的运算说,这个cortrol这个g(z),可不可以输入一个关卡(假设输入
,那么c′就是重新存到memory里面的值。所以根据目前的运算说,这个cortrol这个g(z),可不可以输入一个关卡(假设输入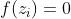 ,那就等于0,那就好像是没有输入一样,如果等于1就等于是把g(z)当做输入) 。那这个决定说:我们要不要把存在memory的值洗掉假设为1(forget gate 开启的时候),这时候c会直接通过(就是说把之前的值还会记得)。如果f(z_f)f(zf)等于0(forget gate关闭的时候)等于0。然后把这个两个值加起来()写到memory里面得到c′。这个forget gate的开关是跟我们的直觉是相反的,那这个forget gate打开的时候代表的是记得,关闭的时候代表的是遗忘。那这个c′通过h(c′),将h(c′)乘以
,那就等于0,那就好像是没有输入一样,如果等于1就等于是把g(z)当做输入) 。那这个决定说:我们要不要把存在memory的值洗掉假设为1(forget gate 开启的时候),这时候c会直接通过(就是说把之前的值还会记得)。如果f(z_f)f(zf)等于0(forget gate关闭的时候)等于0。然后把这个两个值加起来()写到memory里面得到c′。这个forget gate的开关是跟我们的直觉是相反的,那这个forget gate打开的时候代表的是记得,关闭的时候代表的是遗忘。那这个c′通过h(c′),将h(c′)乘以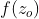 得到
得到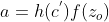 (output gate受f(z_o)f(zo)所操控,等于1的话,就说明h(c′)能通过,等于0的话,说明memory里面存在的值没有办法通过output gate被读取出来)
(output gate受f(z_o)f(zo)所操控,等于1的话,就说明h(c′)能通过,等于0的话,说明memory里面存在的值没有办法通过output gate被读取出来)
2.4.3.1 LSTM举例
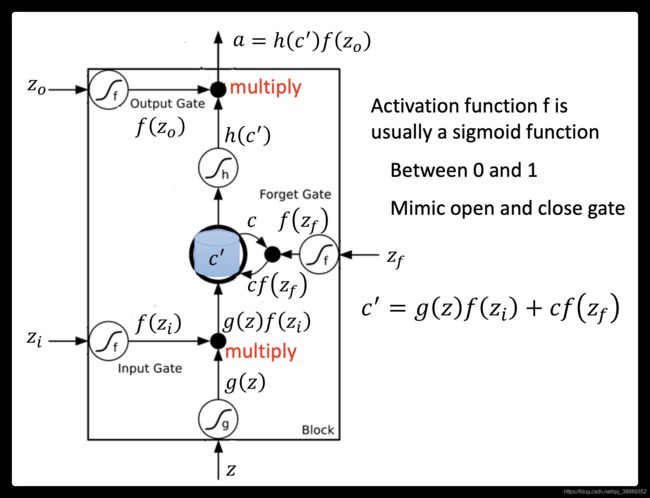
- 我们的network里面只有一个LSTM的cell,那我们的input都是三维的vector,output都是一维的output。那这三维的vector跟output还有memory的关系是这样的。假设第二个dimension
 的值是1时,
的值是1时, 的值就会被写到memory里,假设的值是-1时,就会reset the memory,假设
的值就会被写到memory里,假设的值是-1时,就会reset the memory,假设 的值为1时,你才会把output打开才能看到输出。
的值为1时,你才会把output打开才能看到输出。 - 假设我们原来存到memory里面的值是0,当第二个dimension的值是1时,3会被存到memory里面去。第四个dimension的等于,所以4会被存到memory里面去,所以会得到7。第六个dimension的等于1,这时候7会被输出。第七个dimension的的值为-1,memory里面的值会被洗掉变为0。第八个dimension的的值为1,所以把6存进去,因为的值为1,所以把6输出。
 2.4.3.2 LSTM运算举例
2.4.3.2 LSTM运算举例
- 那我们就做一下实际的运算,这个是一个memory cell。这四个input scalar是这样来的:input的三维vector乘以linear transform以后所得到的结果(
 乘以权重再加上bias),这些权重和bias是哪些值是通过train data用GD学到的。 假设我已经知道这些值是多少了,那用这样的输入会得到什么样的输出。那我们就实际的运算一下。
乘以权重再加上bias),这些权重和bias是哪些值是通过train data用GD学到的。 假设我已经知道这些值是多少了,那用这样的输入会得到什么样的输出。那我们就实际的运算一下。 - 在实际运算之前,我们先根据它的input,参数分析下可能会得到的结果。底下这个外界传入的cell,乘以1,其他的vector乘以0,所以就直接把当做输入。在input gate时,乘以100,bias乘以-10(假设是没有值的话,通常input gate是关闭的(bias等于-10)因为-10通过sigmoid函数之后会接近0,所以就代表是关闭的,若的值大于1的话,结果会是一个正值,代表input gate会被打开) 。forget gate通常会被打开的,因为他的bias等于10(它平常会一直记得东西),只有当的值为一个很大的负值时,才会把forget gate关起来。output gate平常是被关闭的,因为bias是一个很大的负值,若有一个很大的正值的话,压过bias把output打开。
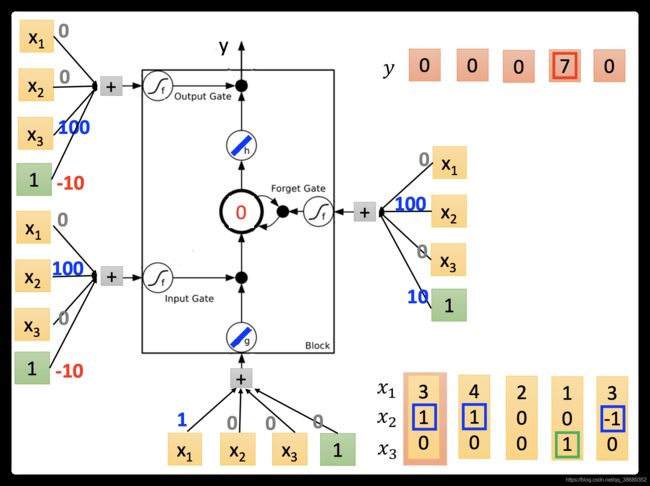
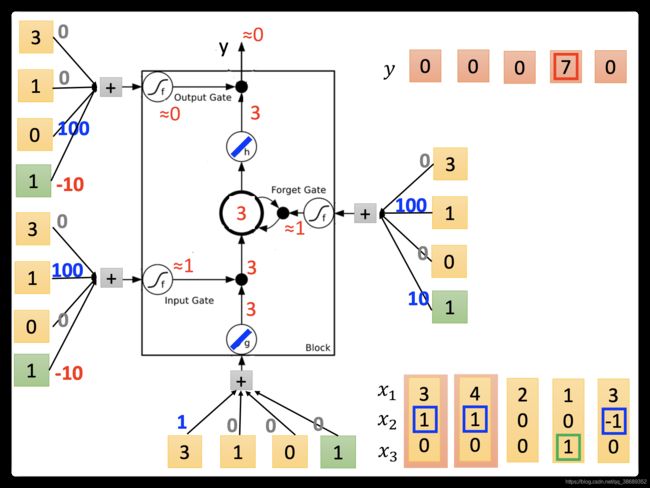
- 接下来,我们实际的input一下看看。我们假设g和h都是linear(因为这样计算会比较方便)。假设存到memory里面的初始值是0,我们input第一个vector(3,1,0),input这边3*1=3,这边输入的是的值为3。input gate这边(
 )是被打开(input gate约等于1)。(
)是被打开(input gate约等于1)。( )。forget gate(1∗100+10≈1)是被打开的(forget gate约等于1)。现在0 *1+3=3(),所以存到memory里面的现在为3。output gate(-10)是被关起来的,所以3无关通过,所以输出值为0。
)。forget gate(1∗100+10≈1)是被打开的(forget gate约等于1)。现在0 *1+3=3(),所以存到memory里面的现在为3。output gate(-10)是被关起来的,所以3无关通过,所以输出值为0。
- 接下来input(4,1,0),传入input的值为4,input gate会被打开,forget gate也会被打开,所以memory里面存的值等于7(3+4=7),output gate仍然会被关闭的,所以7没有办法被输出,所以整个memory的输出为0。
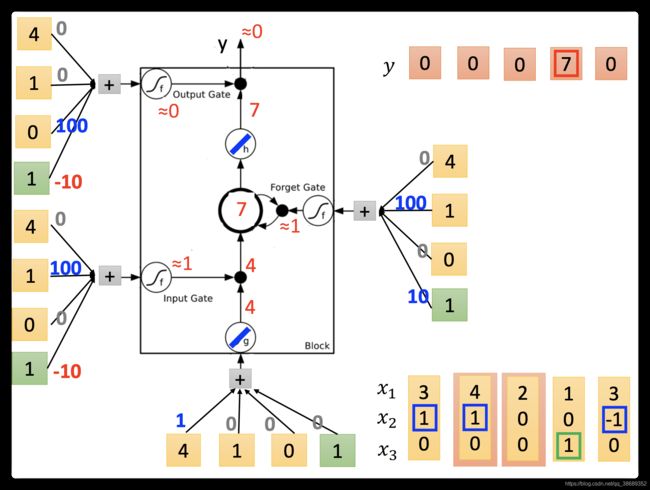
接下来input(2,0,0),传入input的值为2,input gate关闭(\approx≈ 0),input被input gate给挡住了(0 *2=0),forget gate打开(10)。原来memory里面的值还是7(1 *7+0=7).output gate仍然为0,所以没有办法输出,所以整个output还是0。
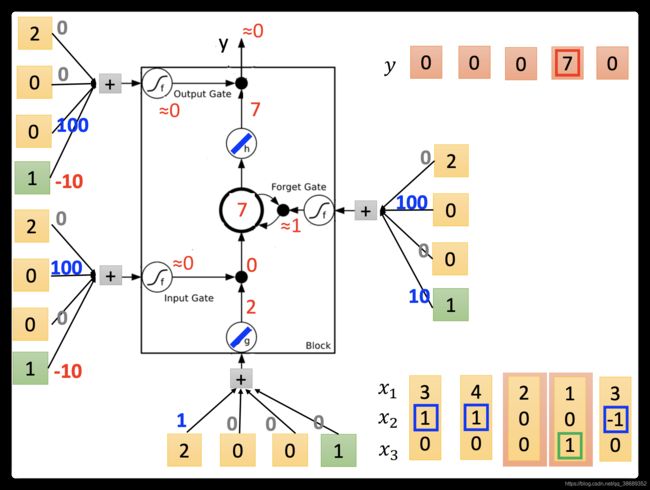
- 接下来input(1,0,1),传入input的值为1,input gate是关闭的,forget gate是打开的,memory里面存的值不变,output gate被打开,整个output为7(memory里面存的7会被读取出来)
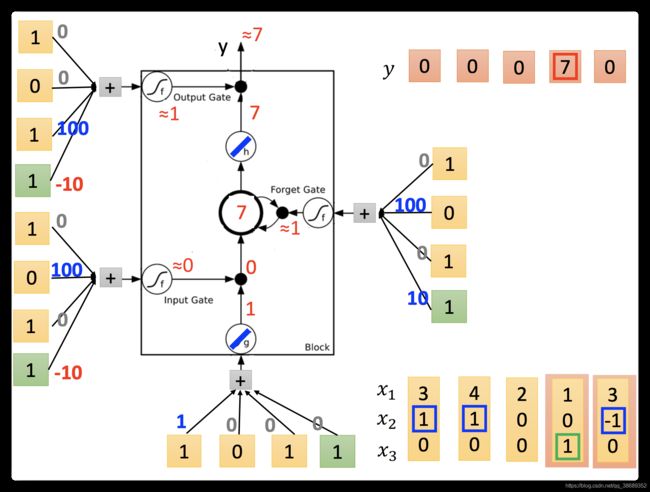
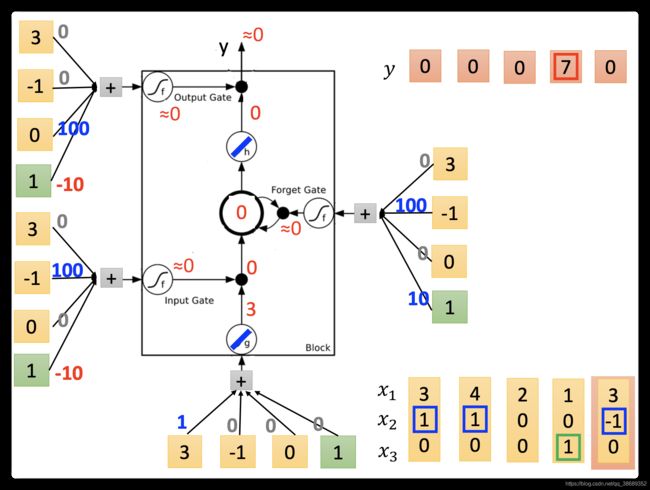
- 最后input(3,-1,0),传入input的值为3,input gate 关闭,forget gate关闭,memory里面的值会被洗掉变为0,output gate关闭,所以整个output为0。
2.4.3.3 LSTM原理
- 我们可能会想这个跟我们的neural network有什么样的关系呢。你可以这样想,在我们原来的neural network里面,我们会有很多的neural,我们会把input乘以不同的weight当做不同neural的输入,每一个neural都是一个function,输入一个值然后输出一个值。但是如果是LSTM的话,其实你只要把LSTM那么memory的cell想成是一个neuron就好了。

- 所以我们今天要用一个LSTM的neuron,你做的事情其实就是原来简单的neuron换成LSTM。现在的input(
 )会乘以不同的weight当做LSTM不同的输入(假设我们这个hidden layer只有两个neuron,但实际上是有很多的neuron)。input()会乘以不同的weight会去操控output gate,乘以不同的weight操控input gate,乘以不同的weight当做底下的input,乘以不同的weight当做forget gate。第二个LSTM也是一样的。所以LSTM是有四个input跟一个output,对于LSTM来说,这四个input是不一样的。在原来的neural network里是一个input一个output。在LSTM里面它需要四个input,它才能产生一个output。
)会乘以不同的weight当做LSTM不同的输入(假设我们这个hidden layer只有两个neuron,但实际上是有很多的neuron)。input()会乘以不同的weight会去操控output gate,乘以不同的weight操控input gate,乘以不同的weight当做底下的input,乘以不同的weight当做forget gate。第二个LSTM也是一样的。所以LSTM是有四个input跟一个output,对于LSTM来说,这四个input是不一样的。在原来的neural network里是一个input一个output。在LSTM里面它需要四个input,它才能产生一个output。 - LSTM因为需要四个input,而且四个input都是不一样,原来的一个neuron就只有一个input和output,所以LSTM需要的参数量(假设你现在用的neural的数目跟LSTM是一样的)是一般neural network的四倍。这个跟Recurrent Neural Network 的关系是什么,这个看起来好像不一样,所以我们要画另外一张图来表示。
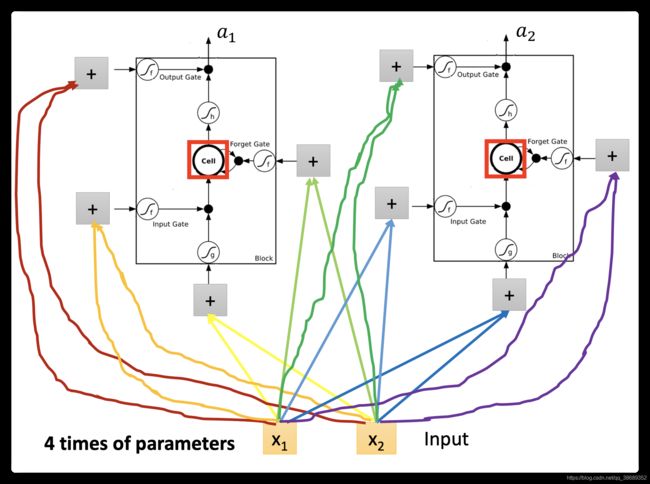
- 假设我们现在有一整排的neuron(LSTM),这些LSTM里面的memory都存了一个值,把所有的值接起来就变成了vector,写为
 (一个值就代表一个dimension)。现在在时间点t,input一个vector,这个vector首先会乘上一matrix(一个linear transform变成一个vector z,z这个vector的dimension就代表了操控每一个LSTM的input(z这个dimension正好就是LSTM memory cell的数目)。z的第一维就丢给第一个cell(以此类推)
(一个值就代表一个dimension)。现在在时间点t,input一个vector,这个vector首先会乘上一matrix(一个linear transform变成一个vector z,z这个vector的dimension就代表了操控每一个LSTM的input(z这个dimension正好就是LSTM memory cell的数目)。z的第一维就丢给第一个cell(以此类推) - 这个x^txt会乘上另外的一个transform得到
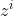 ,然后这个的dimension也跟cell的数目一样,的每一个dimension都会去操控input gate(forget gate 跟output gate也都是一样,这里就不在赘述)。所以我们把乘以四个不同的transform得到四个不同的vector,四个vector的dimension跟cell的数目一样,这四个vector合起来就会去操控这些memory cell运作。
,然后这个的dimension也跟cell的数目一样,的每一个dimension都会去操控input gate(forget gate 跟output gate也都是一样,这里就不在赘述)。所以我们把乘以四个不同的transform得到四个不同的vector,四个vector的dimension跟cell的数目一样,这四个vector合起来就会去操控这些memory cell运作。

- 一个memory cell就长这样,现在input分别就是
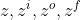 (都是vector),丢到cell里面的值其实是vector的一个dimension,因为每一个cell input的dimension都是不一样的,所以每一个cell input的值都会是不一样。所以cell是可以共同一起被运算的,怎么共同一起被运算呢?我们说,通过activation function跟z相乘,
(都是vector),丢到cell里面的值其实是vector的一个dimension,因为每一个cell input的dimension都是不一样的,所以每一个cell input的值都会是不一样。所以cell是可以共同一起被运算的,怎么共同一起被运算呢?我们说,通过activation function跟z相乘,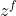 通过activation function跟之前存在cell里面的值相乘,然后将z跟相乘的值加上跟相乘的值,
通过activation function跟之前存在cell里面的值相乘,然后将z跟相乘的值加上跟相乘的值, 通过activation function的结果output,跟之前相加的结果再相乘,最后就得到了output
通过activation function的结果output,跟之前相加的结果再相乘,最后就得到了output
- 之前那个相加以后的结果就是memory里面存放的值
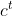 ,这个process反复的进行,在下一个时间点input,把z跟input gate相乘,把forget gate跟存在memory里面的值相乘,然后将前面两个值再相加起来,在乘上output gate的值,然后得到下一个时间点的输出。
,这个process反复的进行,在下一个时间点input,把z跟input gate相乘,把forget gate跟存在memory里面的值相乘,然后将前面两个值再相加起来,在乘上output gate的值,然后得到下一个时间点的输出。 - 你可能认为说这很复杂了,但是这不是LSTM的最终形态,真正的LSTM,会把上一个时间的输出接进来,当做下一个时间的input,也就说下一个时间点操控这些gate的值不是只看那个时间点的input,还看前一个时间点的output
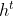 。其实还不止这样,还会加一个东西叫做“peephole”,这个peephole就是把存在memory cell里面的值也拉过来。那操控LSTM四个gate的时候,你是同时考虑了
。其实还不止这样,还会加一个东西叫做“peephole”,这个peephole就是把存在memory cell里面的值也拉过来。那操控LSTM四个gate的时候,你是同时考虑了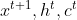 ,你把这三个vector并在一起乘上不同的transform得到四个不同的vector再去操控LSTM。
,你把这三个vector并在一起乘上不同的transform得到四个不同的vector再去操控LSTM。

- LSTM通常不会只有一层,若有五六层的话。大概是这个样子。每一个第一次看这个的人,反映都会很难受。现在还是 quite standard now,当有一个人说我用RNN做了什么,你不要去问他为什么不用LSTM,因为他其实就是用了LSTM。现在当你说,你在做RNN的时候,其实你指的就用LSTM。Keras支持三种RNN:‘’LSTM‘’,“GRU”,"SimpleRNN"

2.4.4 GRU
- GRU是LSTM稍微简化的版本,它只有两个gate,虽然少了一个gate,但是performance跟LSTM差不多(少了1/3的参数,也是比较不容易overfitting)。如果你要用这堂课最开始讲的那种RNN,你要说是simple RNN才行。
三、RNN怎么学习?
3.1 RNN 怎么学习?
- 如果要做learning的话,你要定义一个cost function来evaluate你的model是好还是不好,选一个parameter要让你的loss 最小。那在Recurrent Neural Network里面,你会怎么定义这个loss呢,下面我们先不写算式,先直接举个例子。
- 假设我们现在做的事情是slot filling,那你会有train data,那这个train data是说:我给你一些sentence,你要给sentence一些label,告诉machine说第一个word它是属于other slot,“Taipei是”Destination slot,"on"属于other slot,“November”和“2nd”属于time slot,然后接下来你希望说:你的cost咋样定义呢。那“arrive”丢到Recurrent Neural Network的时候,Recurrent Neural Network会得到一个output ,接下来这个会看它的reference vector算它的cross entropy。你会希望说,如果我们丢进去的是“arrive”,那他的reference vector应该对应到other slot的dimension(其他为0),这个reference vector的长度就是slot的数目(这样四十个slot,reference vector的dimension就是40),那input的这个word对应到other slot的话,那对应到other slot dimension为1,其它为0。
- 那现在把“Taipei”丢进去之后,因为“Taipei”属于destination slot,就希望说把
 丢进去的话,它要跟reference vector距离越近越好。那的reference vector是对应到destination slot是1,其它为0。
丢进去的话,它要跟reference vector距离越近越好。那的reference vector是对应到destination slot是1,其它为0。 - 那这边注意的事情就是,你在丢之前,你一定要丢(在丢“Taipei”之前先把“arrive''丢进去),不然你就不知道存到memory里面的值是多少。所以在做training的时候,你也不能够把这些word打散来看,word sentence仍然要当做一个整体来看。把“on”丢进去,reference vector对应的other的dimension是1,其它是0.
- RNN的损失函数output和reference vector的entropy的和就是要最小化的对象。

- 有了这个loss function以后,对于training,也是用梯度下降来做。也就是说我们现在定义出了loss function(L),我要update这个neural network里面的某个参数w,就是计算对w的偏微分,偏微分计算出来以后,就用GD的方法去update里面的参数。在讲feedforward neural network的时候,我们说GD用在feedforward neural network里面你要用一个有效率的算法叫做Backpropagation。那Recurrent Neural Network里面,为了要计算方便,所以也有开发一套算法是Backpropagation的进阶版,叫做BPTT。它跟Backpropagation其实是很类似的,只是Recurrent Neural Network它是在high sequence上运作,所以BPTT它要考虑时间上的information。

- 不幸的是,RNN的training是比较困难的。一般而言,你在做training的时候,你会期待,你的learning curve是像蓝色这条线,这边的纵轴是total loss,横轴是epoch的数目,你会希望说:随着epoch的数目越来越多,随着参数不断的update,loss会慢慢的下降最后趋向收敛。但是不幸的是你在训练Recurrent Neural Network的时候,你有时候会看到绿色这条线。如果你是第一次trai Recurrent Neural Network,你看到绿色这条learning curve非常剧烈的抖动,然后抖到某个地方,这时候你会有什么想法,我相信你会:这程序有bug啊。
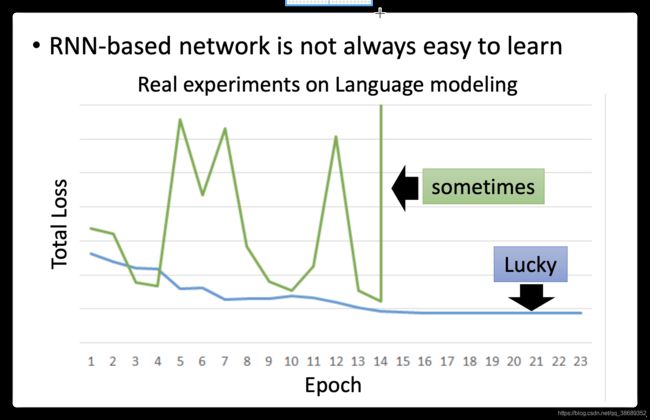
- 分析了下RNN的性质,他发现说RNN的error surface是total loss的变化是非常陡峭的/崎岖的(error surface有一些地方非常的平坦,一些地方非常的陡峭,就像是悬崖峭壁一样),纵轴是total loss,x和y轴代表是两个参数。这样会造成什么样的问题呢?假设你从橙色的点当做你的初始点,用GD开始调整你的参数(updata你的参数,可能会跳过一个悬崖,这时候你的loss会突然爆长,loss会非常上下剧烈的震荡)。有时候你可能会遇到更惨的状况,就是以正好你一脚踩到这个悬崖上,会发生这样的事情,因为在悬崖上的gradient很大,之前的gradient会很小,所以你措手不及,因为之前gradient很小,所以你可能把learning rate调的比较大。很大的gradient乘上很大的learning rate结果参数就update很多,整个参数就飞出去了。
- 用工程的思想来解决,这一招蛮关键的,在很长的一段时间,只有他的code可以把RNN的model给train出来。
- 这一招就是clipping(当gradient大于某一个threshold的时候,不要让它超过那个threshold),当gradient大于15时,让gradient等于15结束。因为gradient不会太大,所以你要做clipping的时候,就算是踩着这个悬崖上,也不飞出来,会飞到一个比较近的地方,这样你还可以继续做你得RNN的training。
- 问题:为什么RNN会有这种奇特的特性。有人会说,是不是来自sigmoid function,我们之前讲过Relu activation function的时候,讲过一个问题gradient vanish,这个问题是从sigmoid function来的,RNN会有很平滑的error surface是因为来自于gradient vanish,这问题我是不认同的。等一下来看这个问题是来自sigmoid function,你换成Relu去解决这个问题就不是这个问题了。跟大家讲个秘密,一般在train neural network时,一般很少用Relu来当做activation function。为什么呢?其实你把sigmoid function换成Relu,其实在RNN performance通常是比较差的。所以activation function并不是这里的关键点。
- 如果说我们今天讲BPTT,你可能会从式子更直观的看出为什么会有这个问题。那今天我们没有讲BPTT。没有关系,我们有更直观的方法来知道一个gradient的大小。
- 你把某一个参数做小小的变化,看它对network output的变化有多大,你就可以测出这个参数的gradient的大小。
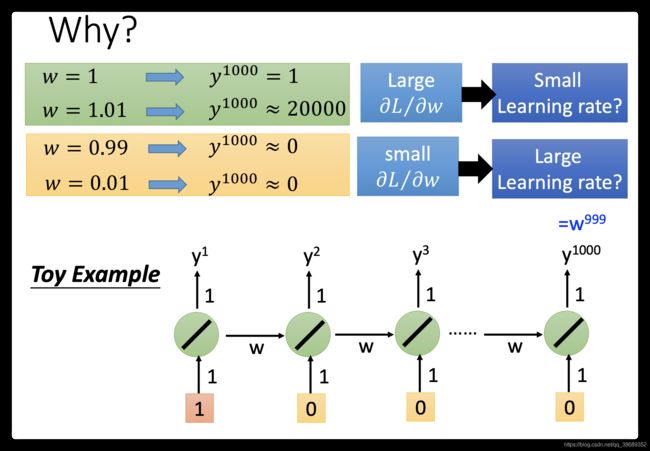
- 举一个很简单的例子,只有一个neuron,这个neuron是linear。input没有bias,input的weight是1,output的weight也是1,transition的weight是w。也就是说从memory接到neuron的input的weight是w。
- 现在我假设给neural network的输入是(1,0,0,0),那这个neural network的output会长什么样子呢?比如说,neural network在最后一个时间点(1000个output值是
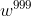 )。
)。 - 现在假设w是我们要learn的参数,我们想要知道它的gradient,所以是知道当我们改变w的值时候,对neural的output有多大的影响。现在假设w=1,那现在
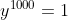 ,假设w=1.01,
,假设w=1.01,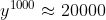 ,这个就跟蝴蝶效应一样,w有一点小小的变化,会对它的output影响是非常大的。所以w有很大的gradient。有很大的gradient也并没有,我们把learning rate设小一点就好了。但我们把w设为0.99,那
,这个就跟蝴蝶效应一样,w有一点小小的变化,会对它的output影响是非常大的。所以w有很大的gradient。有很大的gradient也并没有,我们把learning rate设小一点就好了。但我们把w设为0.99,那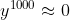 ,那如果把w设为0.01,那。也就是说在1的这个地方有很大的gradient,但是在0.99这个地方就突然变得非常非常的小,这个时候你就需要一个很大的learning rate。设置learning rate很麻烦,你的error surface很崎岖,你的gardient是时大时小的,在非常小的区域内,gradient有很多的变化。从这个例子你可以看出来说,为什么RNN会有问题,RNN training的问题其实来自它把同样的东西在transition的时候反复使用。所以这个w只要一有变化,它完全由可能没有造成任何影响,一旦造成影响,影响都是天崩地裂的(所以gradient会很大,gradient会很小)。
,那如果把w设为0.01,那。也就是说在1的这个地方有很大的gradient,但是在0.99这个地方就突然变得非常非常的小,这个时候你就需要一个很大的learning rate。设置learning rate很麻烦,你的error surface很崎岖,你的gardient是时大时小的,在非常小的区域内,gradient有很多的变化。从这个例子你可以看出来说,为什么RNN会有问题,RNN training的问题其实来自它把同样的东西在transition的时候反复使用。所以这个w只要一有变化,它完全由可能没有造成任何影响,一旦造成影响,影响都是天崩地裂的(所以gradient会很大,gradient会很小)。 - 所以RNN不好训练的原因不是来自activation function而是来自于它有high sequence同样的weight在不同的时间点被反复的使用。
3.2 如何解决RNN梯度消失或爆炸
- 有什么样的技巧可以告诉我们可以解决这个问题呢?其实广泛被使用的技巧就是LSTM,LSTM可以让你的error surface不要那么崎岖。它可以做到的事情是,它会把那些平坦的地方拿掉,解决gradient vanish的问题,不会解决gradient explode的问题。有些地方还是非常的崎岖的(有些地方仍然是变化非常剧烈的,但是不会有特别平坦的地方)。
- 如果你要做LSTM时,大部分地方变化的很剧烈,所以当你做LSTM的时候,你可以放心的把你的learning rate设置的小一点,保证在learning rate很小的情况下进行训练。
- 那为什么LSTM 可以解决梯度消失的问题呢,为什么可以避免gradient特别小呢?RNN跟LSTM在面对memory的时候,它处理的操作其实是不一样的。你想想看,在RNN里面,在每一个时间点,memory里面的值都是会被洗掉,在每一个时间点,neuron的output都要memory里面去,所以在每一个时间点,memory里面的值都是会被覆盖掉。但是在LSTM里面不一样,它是把原来memory里面的值乘上一个值再把input的值加起来放到cell里面。所以它的memory input是相加的。所以今天它和RNN不同的是,如果今天你的weight可以影响到memory里面的值的话,一旦发生影响会永远都存在。不像RNN在每个时间点的值都会被format掉,所以只要这个影响被format掉它就消失了。但是在LSTM里面,一旦对memory造成影响,那影响一直会被留着(除非forget gate要把memory的值洗掉),不然memory一旦有改变,只会把新的东西加进来,不会把原来的值洗掉,所以它不会有gradient vanishing的问题
- 那你想说们现在有forget gate可能会把memory的值洗掉。其实LSTM的第一个版本其实就是为了解决gradient vanishing的问题,所以它是没有forget gate,forget gate是后来才加上去的。甚至,现在有个传言是:你在训练LSTM的时候,你要给forget gate特别大的bias,你要确保forget gate在多数的情况下都是开启的,只要少数的情况是关闭的
- 那现在有另外一个版本用gate操控memory cell,叫做Gates Recurrent Unit(GRU),LSTM有三个Gate,而GRU有两个gate,所以GRU需要的参数是比较少的。因为它需要的参数量比较少,所以它在training的时候是比较鲁棒的。如果你今天在train LSTM,你觉得overfitting的情况很严重,你可以试下GRU。GRU的精神就是:旧的不去,新的不来。它会把input gate跟forget gate联动起来,也就是说当input gate打开的时候,forget gate会自动的关闭(format存在memory里面的值),当forget gate没有要format里面的值,input gate就会被关起来。也就是说你要把memory里面的值清掉,才能把新的值放进来。

3.3 其他方式
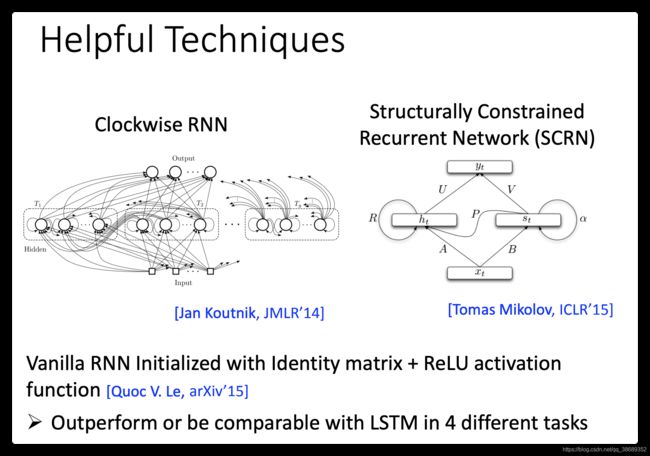
- 其实还有其他的technique是来handle gradient vanishing的问题。比如说clockwise RNN或者说是Structurally Constrained Recurrent Network (SCRN)等等。
- 有一个蛮有趣的paper是这样的:一般的RNN用identity matrix(单位矩阵)来initialized transformation weight+ReLU activaton function它可以得到很好的performance。刚才不是说用ReLU的performance会比较呀,如果你说一般train的方法initiaed weight是random,那ReLU跟sigmoid function来比的话,sigmoid performance 会比较好。但是你今天用了identity matrix的话,这时候用ReLU performance会比较好。
四、Attention-based Model
- 现在除了RNN以外,还有另外一种有用到memory的network,叫做Attention-based Model,这个可以想成是RNN的进阶的版本。
- 那我们知道说,人的大脑有非常强的记忆力,所以你可以记得非常非常多的东西。比如说,你现在同时记得早餐吃了什么,同时记得10年前夏天发生的事,同时记得在这几门课中学到的东西。那当然有人问你说什么是deep learning的时候,那你的脑中会去提取重要的information,然后再把这些information组织起来,产生答案。但是你的脑中会自动忽略那些无关的事情,比如说,10年前夏天发生的事情等等。
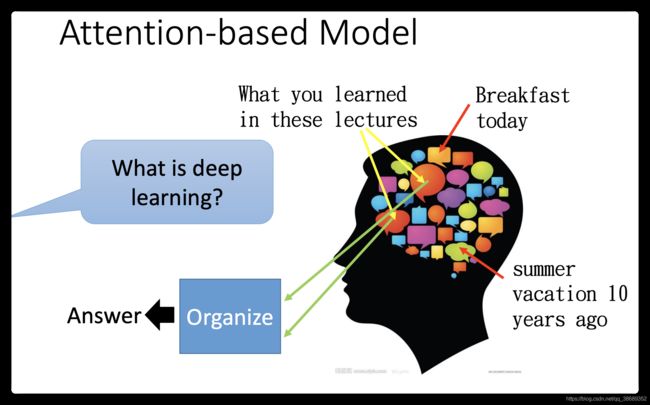
- 其实machine也可以做到类似的事情,machine也可以有很大的记忆的容量。它可以有很大的data base,在这个data base里面,每一个vector就代表了某种information被存在machine的记忆里面。
- 当你输入一个input的时候,这个input会被丢进一个中央处理器,这个中央处理器可能是一个DNN/RNN,那这个中央处理器会操控一个Reading Head Controller,这个Reading Head Controller会去决定这个reading head放的位置。machine再从这个reading head 的位置去读取information,然后产生最后的output

- 这个model还有一个2.0的版本,它会去操控writing head controller。这个writing head controller会去决定writing head 放的位置。然后machine会去把它的information通过这个writing head写进它的data base里面。所以,它不仅有读的功能,还可以discover出来的东西写入它的memory里面去。这个就是大名鼎鼎的Neural Turing Machine
