【毕业设计】深度学习人脸表情识别系统 - python 卷积神经网络
文章目录
- 0 简介
- 1 项目说明
- 2 数据集介绍:
- 3 思路分析及代码实现
-
- 3.1 数据可视化
- 3.2 数据分离
- 3.3 数据可视化
- 3.4 在pytorch下创建数据集
-
- 3.4.1 创建data-label对照表
- 3.4.2 重写Dataset类
- 3.4.3 数据集的使用
- 4 网络模型搭建
-
- 4.1 训练模型
- 4.2 模型的保存与加载
- 5 相关源码
- 6 最后
0 简介
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
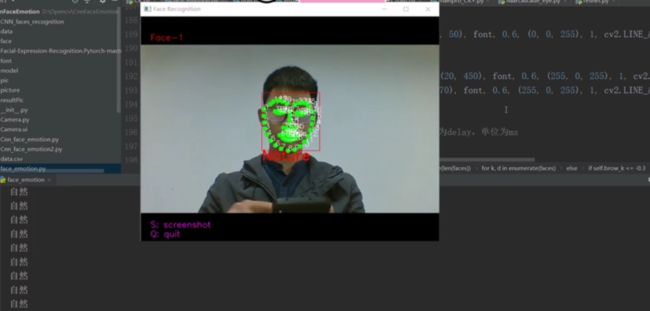
基于深度学习的人脸表情识别
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
1 项目说明
给定数据集train.csv,要求使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情。在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过,(5)惊讶和(6)中立(即面无表情,无法归为前六类)。所以,本项目实质上是一个7分类问题。

2 数据集介绍:
-
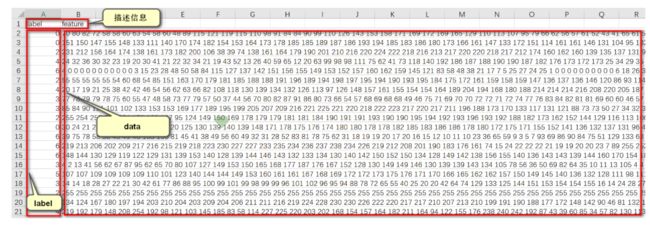
(1)、CSV文件,大小为28710行X2305列;
-
(2)、在28710行中,其中第一行为描述信息,即“label”和“feature”两个单词,其余每行内含有一个样本信息,即共有28709个样本;
-
(3)、在2305列中,其中第一列为该样本对应的label,取值范围为0到6。其余2304列为包含着每个样本大小为48X48人脸图片的像素值(2304=48X48),每个像素值取值范围在0到255之间;
3 思路分析及代码实现
给定的数据集是csv格式的,考虑到图片分类问题的常规做法,决定先将其全部可视化,还原为图片文件再送进模型进行处理。
借助深度学习框架Pytorch1.0 CPU(穷逼)版本,搭建模型,由于需用到自己的数据集,因此我们需要重写其中的数据加载部分,其余用现成的API即可。
学长这里使用CNN实现功能,因此基本只能在调参阶段自由发挥(不要鄙视调参,参数也不是人人都能调得好的,比如我)。
3.1 数据可视化
我们需要将csv中的像素数据还原为图片并保存下来,在python环境下,很多库都能实现类似的功能,如pillow,opencv等。由于笔者对opencv较为熟悉,且opencv又是专业的图像处理库,因此决定采用opencv实现这一功能
3.2 数据分离
原文件中,label和人脸像素数据是集中在一起的。为了方便操作,决定利用pandas库进行数据分离,即将所有label 读出后,写入新创建的文件label.csv;将所有的像素数据读出后,写入新创建的文件data.csv。
# 将label和像素数据分离
import pandas as pd
# 修改为train.csv在本地的相对或绝对地址
path = './/ml2019spring-hw3//train.csv'
# 读取数据
df = pd.read_csv(path)
# 提取label数据
df_y = df[['label']]
# 提取feature(即像素)数据
df_x = df[['feature']]
# 将label写入label.csv
df_y.to_csv('label.csv', index=False, header=False)
# 将feature数据写入data.csv
df_x.to_csv('data.csv', index=False, header=False)
以上代码执行完毕后,在该代码脚本所在的文件夹下,就会生成两个新文件label.csv以及data.csv。在执行代码前,注意修改train.csv在本地的路径。
3.3 数据可视化
将数据分离后,人脸像素数据全部存储在data.csv文件中,其中每行数据就是一张人脸。按行读取数据,利用opencv将每行的2304个数据恢复为一张48X48的人脸图片,并保存为jpg格式。在保存这些图片时,将第一行数据恢复出的人脸命名为0.jpg,第二行的人脸命名为1.jpg…,以方便与label[0]、label[1]…一一对应。
import cv2
import numpy as np
# 指定存放图片的路径
path = './/face'
# 读取像素数据
data = np.loadtxt('data.csv')
# 按行取数据
for i in range(data.shape[0]):
face_array = data[i, :].reshape((48, 48)) # reshape
cv2.imwrite(path + '//' + '{}.jpg'.format(i), face_array) # 写图片
以上代码虽短,但涉及到大量数据的读取和大批图片的写入,因此占用的内存资源较多,且执行时间较长(视机器性能而定,一般要几分钟到十几分钟不等)。代码执行完毕,我们来到指定的图片存储路径,就能发现里面全部是写好的人脸图片。
粗略浏览一下这些人脸图片,就能发现这些图片数据来源较广,且并不纯净。就前60张图片而言,其中就包含了正面人脸,如1.jpg;侧面人脸,如18.jpg;倾斜人脸,如16.jpg;正面人头,如7.jpg;正面人上半身,如55.jpg;动漫人脸,如38.jpg;以及毫不相关的噪声,如59.jpg。放大图片后仔细观察,还会发现不少图片上还有水印。种种因素均给识别提出了严峻的挑战。

3.4 在pytorch下创建数据集
现在我们有了图片,但怎么才能把图片读取出来送给模型呢?
最简单粗暴的方法就是直接用opencv将所有图片读取出来,以numpy中array的数据格式直接送给模型。如果这样做的话,会一次性把所有图片全部读入内存,占用大量的内存空间,且只能使用单线程,效率不高,也不方便后续操作。
其实在pytorch中,有一个类(torch.utils.data.Dataset)是专门用来加载数据的,我们可以通过继承这个类来定制自己的数据集和加载方法。以下为基本流程。
3.4.1 创建data-label对照表
首先,我们需要划分一下训练集和验证集。在本次作业中,共有28709张图片,取前24000张图片作为训练集,其他图片作为验证集。新建文件夹train和val,将0.jpg到23999.jpg放进文件夹train,将其他图片放进文件夹val。
在继承torch.utils.data.Dataset类定制自己的数据集时,由于在数据加载过程中需要同时加载出一个样本的数据及其对应的label,因此最好能建立一个data-label对照表,其中记录着data和label的对应关系(“data-lable对照表”并非官方名词,这个技术流程是笔者参考了他人的博客后自己摸索的,这个名字也是笔者给命的名)。
有童鞋看到这里就会提出疑问了:在人脸可视化过程中,每张图片的命名不都和label的存放顺序是一一对应关系吗,为什么还要多此一举,再重新建立data-label对照表呢?笔者在刚开始的时候也是这么想的,按顺序(0.jpg, 1.jpg, 2.jpg…)加载图片和label(label[0], label[1], label[2]…),岂不是方便、快捷又高效?结果在实际操作的过程中才发现,程序加载文件的机制是按照文件名首字母(或数字)来的,即加载次序是0,1,10,100…,而不是预想中的0,1,2,3…,因此加载出来的图片不能够和label[0],label[1],lable[2],label[3]…一一对应,所以建立data-label对照表还是相当有必要的。
建立data-label对照表的基本思路就是:指定文件夹(train或val),遍历该文件夹下的所有文件,如果该文件是.jpg格式的图片,就将其图片名写入一个列表,同时通过图片名索引出其label,将其label写入另一个列表。最后利用pandas库将这两个列表写入同一个csv文件。
执行这段代码前,注意修改相关文件路径。代码执行完毕后,会在train和val文件夹下各生成一个名为dataset.csv的data-label对照表。
import os
import pandas as pd
def data_label(path):
# 读取label文件
df_label = pd.read_csv('label.csv', header = None)
# 查看该文件夹下所有文件
files_dir = os.listdir(path)
# 用于存放图片名
path_list = []
# 用于存放图片对应的label
label_list = []
# 遍历该文件夹下的所有文件
for file_dir in files_dir:
# 如果某文件是图片,则将其文件名以及对应的label取出,分别放入path_list和label_list这两个列表中
if os.path.splitext(file_dir)[1] == ".jpg":
path_list.append(file_dir)
index = int(os.path.splitext(file_dir)[0])
label_list.append(df_label.iat[index, 0])
# 将两个列表写进dataset.csv文件
path_s = pd.Series(path_list)
label_s = pd.Series(label_list)
df = pd.DataFrame()
df['path'] = path_s
df['label'] = label_s
df.to_csv(path+'\\dataset.csv', index=False, header=False)
def main():
# 指定文件夹路径
train_path = 'F:\\0gold\\ML\\LHY_class\\FaceData\\train'
val_path = 'F:\\0gold\\ML\\LHY_class\\FaceData\\val'
data_label(train_path)
data_label(val_path)
if __name__ == "__main__":
main()
OK,代码执行完毕,让我们来看一看data-label对照表里面具体是什么样子吧!

3.4.2 重写Dataset类
首先介绍一下Pytorch中Dataset类:Dataset类是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。其中父类中的两个私有成员函数getitem()和len()必须被重载,否则将会触发错误提示。其中getitem()可以通过索引获取数据,len()可以获取数据集的大小。在Pytorch源码中,Dataset类的声明如下:
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
我们通过继承Dataset类来创建我们自己的数据加载类,命名为FaceDataset。
import torch
from torch.utils import data
import numpy as np
import pandas as pd
import cv2
class FaceDataset(data.Dataset):
首先要做的是类的初始化。之前的data-label对照表已经创建完毕,在加载数据时需用到其中的信息。因此在初始化过程中,我们需要完成对data-label对照表中数据的读取工作。
通过pandas库读取数据,随后将读取到的数据放入list或numpy中,方便后期索引。
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
# root为train或val文件夹的地址
self.root = root
# 读取data-label对照表中的内容
df_path = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[0]) # 读取第一列文件名
df_label = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[1]) # 读取第二列label
# 将其中内容放入numpy,方便后期索引
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
接着就要重写getitem()函数了,该函数的功能是加载数据。在前面的初始化部分,我们已经获取了所有图片的地址,在这个函数中,我们就要通过地址来读取数据。
由于是读取图片数据,因此仍然借助opencv库。需要注意的是,之前可视化数据部分将像素值恢复为人脸图片并保存,得到的是3通道的灰色图(每个通道都完全一样),而在这里我们只需要用到单通道,因此在图片读取过程中,即使原图本来就是灰色的,但我们还是要加入参数从cv2.COLOR_BGR2GARY,保证读出来的数据是单通道的。读取出来之后,可以考虑进行一些基本的图像处理操作,如通过高斯模糊降噪、通过直方图均衡化来增强图像等(经试验证明,在本次作业中,直方图均衡化并没有什么卵用,而高斯降噪甚至会降低正确率,可能是因为图片分辨率本来就较低,模糊后基本上什么都看不清了吧)。读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d() API所接受的数据格式是(batch_size, channel, width, higth),本次图片通道为1,因此我们要将48X48 reshape为1X48X48。
# 读取某幅图片,item为索引号
def __getitem__(self, item):
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 高斯模糊
# face_Gus = cv2.GaussianBlur(face_gray, (3,3), 0)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
# 像素值标准化
face_normalized = face_hist.reshape(1, 48, 48) / 255.0 # 为与pytorch中卷积神经网络API的设计相适配,需reshape原图
# 用于训练的数据需为tensor类型
face_tensor = torch.from_numpy(face_normalized) # 将python中的numpy数据类型转化为pytorch中的tensor数据类型
face_tensor = face_tensor.type('torch.FloatTensor') # 指定为'torch.FloatTensor'型,否则送进模型后会因数据类型不匹配而报错
label = self.label[item]
return face_tensor, label
最后就是重写len()函数获取数据集大小了。self.path中存储着所有的图片名,获取self.path第一维的大小,即为数据集的大小。
1 # 获取数据集样本个数
2 def __len__(self):
3 return self.path.shape[0]
class FaceDataset(data.Dataset):
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
self.root = root
df_path = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
# 读取某幅图片,item为索引号
def __getitem__(self, item):
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 高斯模糊
# face_Gus = cv2.GaussianBlur(face_gray, (3,3), 0)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
# 像素值标准化
face_normalized = face_hist.reshape(1, 48, 48) / 255.0 # 为与pytorch中卷积神经网络API的设计相适配,需reshape原图
# 用于训练的数据需为tensor类型
face_tensor = torch.from_numpy(face_normalized) # 将python中的numpy数据类型转化为pytorch中的tensor数据类型
face_tensor = face_tensor.type('torch.FloatTensor') # 指定为'torch.FloatTensor'型,否则送进模型后会因数据类型不匹配而报错
label = self.label[item]
return face_tensor, label
# 获取数据集样本个数
def __len__(self):
return self.path.shape[0]
3.4.3 数据集的使用
到此为止,我们已经成功地写好了自己的数据集加载类。那么这个类该如何使用呢?下面笔者将以训练集(train文件夹下的数据)加载为例,讲一下整个数据集加载类在模型训练过程中的使用方法。
首先,我们需要将这个类实例化。
1 # 数据集实例化(创建数据集)
2 train_dataset = FaceDataset(root='E:\\WSD\\HW3\\FaceData\\train')
train_dataset即为我们实例化的训练集,要想加载其中的数据,还需要DataLoader类的辅助。DataLoader类总是配合Dataset类一起使用,DataLoader类可以帮助我们分批次读取数据,也可以通过这个类选择读取数据的方式(顺序 or 随机乱序),还可以选择并行加载数据等,这个类并不要我们重写。
1 # 载入数据并分割batch
2 train_loader = data.DataLoader(train_dataset, batch_size)
最后,我们就能直接从train_loader中直接加载出数据和label了,而且每次都会加载出一个批次(batch)的数据和label。
1 for images, labels in train_loader:
2 '''
3 通过images和labels训练模型
4 '''
4 网络模型搭建
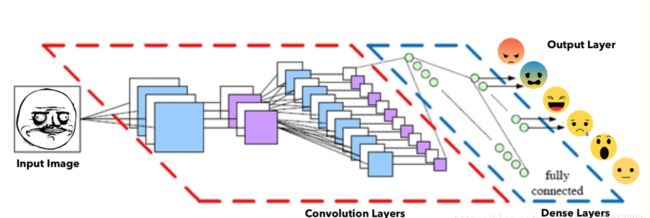
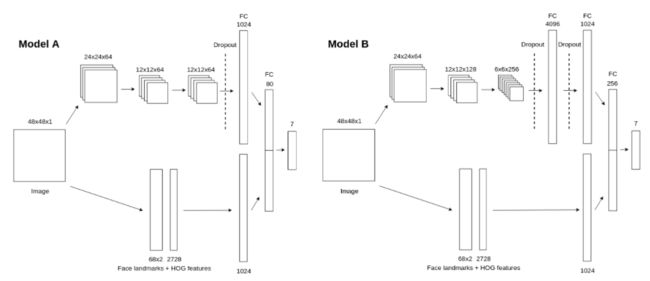
通过Pytorch搭建基于卷积神经网络的分类器。刚开始是自己设计的网络模型,在训练时发现准确度一直上不去,折腾一周后走投无路,后来在github上找到了一个做表情识别的开源项目,用的是这个项目的模型结构,但还是没能达到项目中的精度(acc在74%)。下图为该开源项目中公布的两个模型结构,笔者用的是Model B ,且只采用了其中的卷积-全连接部分,如果大家希望进一步提高模型的表现能力,可以考虑向模型中添加Face landmarks + HOG features 部分。
可以看出,在Model B 的卷积部分,输入图片shape为48X48X1,经过一个3X3X64卷积核的卷积操作,再进行一次2X2的池化,得到一个24X24X64的feature map 1(以上卷积和池化操作的步长均为1,每次卷积前的padding为1,下同)。将feature map 1经过一个3X3X128卷积核的卷积操作,再进行一次2X2的池化,得到一个12X12X128的feature map 2。将feature map 2经过一个3X3X256卷积核的卷积操作,再进行一次2X2的池化,得到一个6X6X256的feature map 3。卷积完毕,数据即将进入全连接层。进入全连接层之前,要进行数据扁平化,将feature map 3拉一个成长度为6X6X256=9216的一维tensor。随后数据经过dropout后被送进一层含有4096个神经元的隐层,再次经过dropout后被送进一层含有1024个神经元的隐层,之后经过一层含256个神经元的隐层,最终经过含有7个神经元的输出层。一般再输出层后都会加上softmax层,取概率最高的类别为分类结果。
我们可以通过继承nn.Module来定义自己的模型类。以下代码实现了上述的模型结构。需要注意的是,在代码中,数据经过最后含7个神经元的线性层后就直接输出了,并没有经过softmax层。这是为什么呢?其实这和Pytorch在这一块的设计机制有关。因为在实际应用中,softmax层常常和交叉熵这种损失函数联合使用,因此Pytorch在设计时,就将softmax运算集成到了交叉熵损失函数CrossEntropyLoss()内部,如果使用交叉熵作为损失函数,就默认在计算损失函数前自动进行softmax操作,不需要我们额外加softmax层。Tensorflow也有类似的机制。
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# 输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding
# input:(bitch_size, 1, 48, 48), output:(bitch_size, 64, 48, 48), (48-3+2*1)/1+1 = 48
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
# output(bitch_size, 64, 24, 24)
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
4.1 训练模型
有了模型,就可以通过数据的前向传播和误差的反向传播来训练模型了。在此之前,还需要指定优化器(即学习率更新的方式)、损失函数以及训练轮数、学习率等超参数。
在本次作业中,我们采用的优化器是SGD,即随机梯度下降,其中参数weight_decay为正则项系数;损失函数采用的是交叉熵;可以考虑使用学习率衰减。
def train(train_dataset, batch_size, epochs, learning_rate, wt_decay):
# 载入数据并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
# 构建模型
model = FaceCNN()
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
# 逐轮训练
for epoch in range(epochs):
# 记录损失值
loss_rate = 0
# scheduler.step() # 学习率衰减
model.train() # 模型训练
for images, labels in train_loader:
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model.forward(images)
# 误差计算
loss_rate = loss_function(output, labels)
# 误差的反向传播
loss_rate.backward()
# 更新参数
optimizer.step()
4.2 模型的保存与加载
我们训练的这个模型相对较小,因此可以直接保存整个模型(包括结构和参数)。
# 模型保存
torch.save(model, 'model_net1.pkl')
# 模型加载
model_parm = 'model_net1.pkl'
model = torch.load(net_parm)
5 相关源码
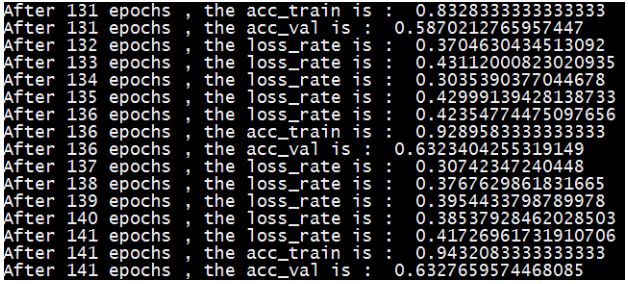
代码在CPU上跑起来较慢,视超参数和机器性能不同,一般跑完需耗时几小时到几十小时不等。代码执行时,每轮输出一次损失值,每5轮输出一次在训练集和验证集上的正确率。有条件的可以在GPU上尝试。
import torch
import torch.utils.data as data
import torch.nn as nn
import torch.optim as optim
import numpy as np
import pandas as pd
import cv2
# 参数初始化
def gaussian_weights_init(m):
classname = m.__class__.__name__
# 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.04)
# 人脸旋转,尝试过但效果并不好,本次并未用到
def imgProcess(img):
# 通道分离
(b, g, r) = cv2.split(img)
# 直方图均衡化
bH = cv2.equalizeHist(b)
gH = cv2.equalizeHist(g)
rH = cv2.equalizeHist(r)
# 顺时针旋转15度矩阵
M0 = cv2.getRotationMatrix2D((24,24),15,1)
# 逆时针旋转15度矩阵
M1 = cv2.getRotationMatrix2D((24,24),15,1)
# 旋转
gH = cv2.warpAffine(gH, M0, (48, 48))
rH = cv2.warpAffine(rH, M1, (48, 48))
# 通道合并
img_processed = cv2.merge((bH, gH, rH))
return img_processed
# 验证模型在验证集上的正确率
def validate(model, dataset, batch_size):
val_loader = data.DataLoader(dataset, batch_size)
result, num = 0.0, 0
for images, labels in val_loader:
pred = model.forward(images)
pred = np.argmax(pred.data.numpy(), axis=1)
labels = labels.data.numpy()
result += np.sum((pred == labels))
num += len(images)
acc = result / num
return acc
class FaceDataset(data.Dataset):
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
self.root = root
df_path = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
# 读取某幅图片,item为索引号
def __getitem__(self, item):
# 图像数据用于训练,需为tensor类型,label用numpy或list均可
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 高斯模糊
# face_Gus = cv2.GaussianBlur(face_gray, (3,3), 0)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
# 像素值标准化
face_normalized = face_hist.reshape(1, 48, 48) / 255.0
face_tensor = torch.from_numpy(face_normalized)
face_tensor = face_tensor.type('torch.FloatTensor')
label = self.label[item]
return face_tensor, label
# 获取数据集样本个数
def __len__(self):
return self.path.shape[0]
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# 第一次卷积、池化
self.conv1 = nn.Sequential(
# 输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding
# input:(bitch_size, 1, 48, 48), output:(bitch_size, 64, 48, 48), (48-3+2*1)/1+1 = 48
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层
nn.BatchNorm2d(num_features=64), # 归一化
nn.RReLU(inplace=True), # 激活函数
# output(bitch_size, 64, 24, 24)
nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化
)
# 第二次卷积、池化
self.conv2 = nn.Sequential(
# input:(bitch_size, 64, 24, 24), output:(bitch_size, 128, 24, 24), (24-3+2*1)/1+1 = 24
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
# output:(bitch_size, 128, 12 ,12)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 第三次卷积、池化
self.conv3 = nn.Sequential(
# input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 12, 12), (12-3+2*1)/1+1 = 12
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
# output:(bitch_size, 256, 6 ,6)
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=1024),
nn.RReLU(inplace=True),
nn.Linear(in_features=1024, out_features=256),
nn.RReLU(inplace=True),
nn.Linear(in_features=256, out_features=7),
)
# 前向传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
# 数据扁平化
x = x.view(x.shape[0], -1)
y = self.fc(x)
return y
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay):
# 载入数据并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
# 构建模型
model = FaceCNN()
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
# 逐轮训练
for epoch in range(epochs):
# 记录损失值
loss_rate = 0
# scheduler.step() # 学习率衰减
model.train() # 模型训练
for images, labels in train_loader:
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model.forward(images)
# 误差计算
loss_rate = loss_function(output, labels)
# 误差的反向传播
loss_rate.backward()
# 更新参数
optimizer.step()
# 打印每轮的损失
print('After {} epochs , the loss_rate is : '.format(epoch+1), loss_rate.item())
if epoch % 5 == 0:
model.eval() # 模型评估
acc_train = validate(model, train_dataset, batch_size)
acc_val = validate(model, val_dataset, batch_size)
print('After {} epochs , the acc_train is : '.format(epoch+1), acc_train)
print('After {} epochs , the acc_val is : '.format(epoch+1), acc_val)
return model
def main():
# 数据集实例化(创建数据集)
train_dataset = FaceDataset(root='E:\\WSD\\HW3\\FaceData\\train')
val_dataset = FaceDataset(root='E:\\WSD\\HW3\\FaceData\\val')
# 超参数可自行指定
model = train(train_dataset, val_dataset, batch_size=128, epochs=100, learning_rate=0.1, wt_decay=0)
# 保存模型
torch.save(model, 'model_net1.pkl')
if __name__ == '__main__':
main()