Reliable Cloud Infrastructure: Design and Process学习笔记
最后更新2022/03/16
忘记更新对应的学习笔记,补上。这一科有9节,加上0章简介
简介
google cloud的好多功能有点相似,这科内容是介绍应该选什么产品,怎么选择,怎么规划,怎么设计等等。首先,你要有个软件产品的设计思想,包括对需求和用户的定义,这个没人能帮你,要你自己解决,google cloud只是个辅助的实现工具,要拿这个工具干什么,你自己决定。
有了这个核心设计思想之后,就要对实现过程进行解构,例如将大目标——10个亿,变成10个1个亿的小目标。。。在现代设计中,基于云架构的系统,最佳的实现方案是采用微服务的模式,换句话说,10个一个亿的小目标并非10个单一一亿目标重复10次,如果这样,和1个10亿目标没什么区别,他们之间的关联太密切了。这10个一个亿的目标是完全独立的10个不同目标,只是恰好他们各是1亿而已,实际上,可能是3亿,5千万,1亿2等等10个各不相同的目标,只是他们之和恰好10亿而已,任何两个小目标之间,最好没有任何联系。当然,作为复杂的软件体系,子目标之间不可避免要互相关联,以上说明的目的只是在于尽力求简,简化到每个目标只依赖于最简单的某个google云服务既可实现。(其实,跟没说一样。。。到底要怎么办,还得以后具体分析)
然后,还要有存储,去恰当地保存以上目标在实现过程中的数据,当然也要包括承载实现目标的一切,代码,参数等等。
请从下面选择出你需要的产品,每个一个图标,有没有搞错?!美式幽默而已。
 当然,还要有安全,还要有监控等等。下面就具体介绍设计的详细过程:
当然,还要有安全,还要有监控等等。下面就具体介绍设计的详细过程:
- 定义服务
- 微服务设计和架构
- DevOps自动化
- 选择存储方案
- 选择云及混合网络架构
- 在google cloud部署应用
- 设计可靠的系统
- 安全
- 维护和监控
在实操之前,咱们要现有个假设的需求,这个例子里是一个叫做ClickTravel的旅游代理公司,想要建立一个全球规模的电子商务网站为客户服务。主要功能包括:
- 为游客提供查找和下定单服务,包括飞机、酒店、火车、租车
- 根据用户单独需求定价(显然大数据杀熟!!!)
- 强大的信息交流功能,包括评价、发帖、分析等
- 供应商(飞机、火车、酒店)能提供(实时)库存
该系统的用户包括:
- 旁观路人甲游客
- 已下单用户
- 供应商
- 经理
定义服务
定义服务首先要了解需求,也就是我们要干什么。
需求
现要搞清requirements,需求概括起来是5个W,11项:
- who
- 用户是谁?
- 开发者是谁?
- 运营者是谁?
- what
- 我们搞的这个玩意儿是干什么的?
- 最主要功能有哪些?
- why
- 为什么需要这个系统?
- when
- 什么时候用户要交货?
- 什么时候开发者要完工?(为啥和交货不是一个时间呢?测试?改进?)
- hoW
- 这玩意工作的如何?
- 有多少用户使用?
- 有多少数据?
user和role
需求可以用user story进行描述。那么什么是用户?在定义用户,user的时候,有一个关键词:角色
- 角色role不是单独的人或者头衔,一个人可能扮演多个角色,一个角色也可能由多人扮演,每个人具有相同的特质
- 角色需要是一种标签,能够描述特定的用户行为:用户要做什么?仅仅“使用”并非一个贴切的定义,每个人都会“使用”“操作”我们要设计的系统
- 角色举例:购物者、账户拥有者、客户(精确点说:逛街的)、管理员、经理
确切来说,用户并非一个物理人,它应该是持有特定行为的系统使用者的分类,这个分类则是为了分析系统而设定,特定行为也不见得是人类动作、操作,例如一个微服务客户端访问另一个微服务提供者,这个微服务客户端的访问行为也具有角色的特点,会根据具体设计而进行归类设计。
user story
在设计时,要对role进行多次发散、合并(除重、归类)的过程,尽力做包含所有动作要求且不交叠重复。同时,使用用户故事(user story)的方式来表达这个需求功能特征:
- 角色,也就是user
- 动作,完整操作过程
- 价值,为什么要这个功能,能实现什么价值
下面是一句话的user story:
账户查询
作为一个账户拥有者(角色),我需要随时可以检查账户余额(动作)以避免我的账户透支(价值)。
可以以这个为模板:
As [ type of user] I want to [ do something ] so that I can [ get some benefit ]
或者:
Given [ some context ] When I [ do something ] Then [ this should happen ]
User story是进行(程序)系统设计的关键,可以用INVEST模型去确定user story:
- Independent: 用户故事(个人觉得用用户动作、用户事件、用户操作更好)需要是独立事件,以避免在规划和调度调整时与其它事件冲突;
- Negotitable:可调整的,可变通的,这是需要完成的动作或事件,但又不是100%严格规定了什么时候做,怎么做,被写到合同中,按精确步骤执行的事情。并且,这是一个用户和开发者之间的妥协和交互,用户说我要!开发者说这样行不?用户说那里要加点。开发者说太难,我在这里给你加点。。。
- Valiable:有价值的,最终必须对用户有用,即使是领导每天不一定看的报表,对领导这种特殊用户,也是有用的,虽然他并不看;
- Estimatable: 可评估的,换句话说,是可实现的,有方法的,如果属于未经证明的猜想,显然不在此列。例如,对程序员说:我需要年底销售额预测!这不是程序完成的,这先要由商业咨询拿到预测公式,有公式,有基础数据来源,这就是可评估的,没有这些,就是找错了人。
- Small:这个特性我喜欢,用户故事必须很小,可以很“容易”快速实现,如果太庞大,太复杂,说明拆分不够细;
- Testable:可测试,不能测试,实现了啥功能,结果对不对,谁都不知道啊!
SLO,SLA,SLI
这是对需求进行评估的一组参数或规则。
上一节说过对user story(及完成结果)要能测试和评估,例如在给定的限定条件下(时间、资金、人员),能达到什么样的结果?
KPI就是对这些结果进行评估的具体指标的统称,其实,KPI就是把远大理想翻译成人话并且有实际数据可以进行比较:
Goal: 增加网店的转化率
KPI:网络销售额与网络流量的比率
既然KPI是人话,那就是可以达到的,它需要具有SMART特征:
- Specific:写得清清楚楚,明明白白,直截了当。不能是:请参考本文第二段第三行之类;
- Measurable:又强调一遍,要可落实的具体数据,不说精确到小数点后六位,至少也要是ABCD,与家长对话中:考得怎样啊?还行,这种是无法蒙混过关的;
- Achievable:不能自不量力,对吧?设定不切实际的目标等于没有目标;
- Relevant:有关联的,不是胡说八道的。我们要超英赶美,这就是Goal,亩产要达到1万斤,这就是KPI之一,而且亩产1万斤,全国粮食产量肯定赶美了,这就是有相关性。如果设定KPI为只生一个好,不能说没有relevant,如果中国人口比美国还少,是不是人均GDP就比美国还多?能赶美了?但这个相关性有点牵强。
-Time-bound:有时间范围。大部分KPI都是在一定是小范围内有效,而且会随着时间范围急剧变化,没有时效范围限定,KPI往往失去意义。
下面是这几个名词之间的关系:
SLI,service level indicator是与server密切相关的KPI
SLO,service level object是基于SLI所要达到的目标,指标
SLA,service level agreement把SLO固化到纸面协议的合同文本,如果供应商没达到,会有罚金付给用户作为补偿;
由于SLI是KPI中的一种,所以必须是measurable且具有time-bound,而目标结果SLO则需要achievable且relevent
SLO设定的标准:
- SLO不是越高越好,与之相反,SLO是在你客户能容忍的情况下,越低越好。老板给员工发工资,就深谙此道。
- SLO越高,计算资源和操作成本越高
- 应用不要提供太高的SLO,用户基本满足于你日常提供的服务指标,只要你别做得更差
注:前互联网时代或许如此,如今。。。特别是越来越多mission critical的应用被移植到互联网,而且自媒体的信息裂变链式反应能力越来越强大,今后互联网应用估计也会按照任务对重要性进行分类吧?
举例:
SLI: HTTP成功响应延时在200ms之内
SLO:99%的HTTP响应延时<=200ms
SLA: 如果HTTP响应延时大于300ms的百分比超过1%,则用户会收到补偿金
微服务设计和架构
这节介绍如何将单体应用拆分为微服务应用,确定微服务的边界,设计有状态及无状态的服务以优化性能和可靠性,按照12指标进行应用部署,建立松耦合的REST架构,设计一致的、标准的RESTful API服务。
先看什么是微服务
微服务
微服务是一种架构模型,是将一个整体的大单体程序拆分为若干很小的、相互独立的服务模块程序。Google提供了若干引擎去支持运行各种微服务模块程序,包括:App Engine,GKE,Cloud Run,Cloud Function,各自有各自不同的颗粒度和承载特点。
微服务和单体应用各有优缺点,具体不写了。
设计微服务的关键点在界定微服务的边界,也就是做拆分时从什么地方下刀,切分功能的同时,还要考虑如何在操作系统层、数据层已经UI表现层进行纵向整合,同时,如果同一微服务模块为多个体系服务,还要研究如何进行服务隔离。
有状态和无状态
现要区分出有状态和无状态的区别,只要不需要随时间、访问实时变化的数据的服务都属于无状态服务。同时,有状态的服务也往往可以拆分为无状态处理和状态数据保存(处理)两部分,而前者是无状态的。
有状态应用难以扩展(并行),难以升级(需要一致数据导致必须绝对意义的升级中断时间),需要备份(逻辑上数据只有也只能有一份,即使物理层镜像不能保证数据可靠)。
基于以上特点,将业务尽可能由无状态处理完成是设计要点,但由于性能、可靠性、复杂性等等因素,有时又不可避免需要设计有状态服务。下面一些设计要点可以帮助减少有状态服务:
尽力避免在server的内存中保留需要共享的状态信息。因为如果状态信息是需要共享的,而server的内存又显然是非共享的,这就要求同一session访问请求必须始终发送到同一server(只有这个server实例才拥有状态数据),防火墙或者负载均衡设备必须保存session标识(配置为sticky session模式既session affinity),并根据此session标识进行转发,额外负担极大。
解决方案是配置共享的后端存储保存状态信息,可以是firestore或者cloud sql,而如果需要性能,则可以增加memorystore,这些都是google cloud提供的标准服务。
最佳实践是这样的5层结构:
- 对外由cloud dns或/及http load balancer提供复杂均衡
- 无状态的前端业务服务
- network load balancer提供内部负载均衡
- 无状态的后端业务服务
- 有状态的后端数据存储服务
最佳实践 SaaS 应用的12指标特点
详见:https://12factor.net
- 最大化可迁移性
- 部署在云端
- 支持连续部署
- 方便扩展
以上是12指标?才4个。。。错了,这是12指标应用的特点,下面才是具体的指标:
- 统一(一个)代码体系,或者叫基础。英文是codebase,很难翻译,对应中文是统一软件基准吧,其含义是一个软件应用的代码不要东拼西凑,虽然每段程序可以copy paste过来,但要统一集中管理,包括版本、组合等等,都是唯一的,统一的。具体来说,需要采用git等工具进行软件代码管理。
- 需要有依赖关系管理。git是管源代码的,但一个大型软件不可避免需要用到一些成熟的、已有的工具包,也就是别人的软件,这些软件不能或者很难或者没必要加入到git中,那么就需要从另一边进行统一管理,也就是运行包管理。因此需要maven,pip,NPM之类进行管理,而依赖关系定义文件则被保存在源代码资源中,由git等完成管理。
- 配置清晰明确地定义在环境变量中,不要弄特别复杂的、加密的、隐藏的配置参数,甚至通过特别的连接访问去抽取。
- 后台支持服务化,把所有的数据库、缓存、队列都变成后台服务,通过URL获取(控制),可以很方便地更换支持实现方案。
- 清晰分开生成、发布、运行三个过程(阶段)。build由源代码生成运行包,发布将运行包和配置文件在运行环境中组合提供,运行则最终执行。
- 进程化。将应用编程若干需要被执行的进程执行,而且这些程序都是无状态的,如果必须状态支持,则从独立的数据库服务中读取(写入)状态。
- 绑定网络端口提供服务。应用自身可以独立支持外部访问被绑定的端口,而无需嵌套在其它服务之内,例如apache提供web访问壳。其中的通信协议可以是自己定义的,不一定需要采用标准的html等等,但是由于有很多成熟的解析包可用,使用html可能更容易。
- 可并行。由于应用由进程绑定端口实现,且无状态冲突,因此可以方便地扩展运行多个,实现并行。
- 可丢弃。任何一个应用实例(进程)都可以快速地、随时地启动和停止,换句话说,应用实例处理过程应当允许意外错误发生,发生之后最简单的解决办法应当被设计为重新启动,重新开始,并且重启后应当能解决问题。
- 开发和生产等价。尽力让开发环境和生产环境相同,通过docker等工具可以更好地实现这个要求。
- 日志,将log作为流式生成的事件,集中统一输出到标准输出
- 管理工作日常任务化,它应当成为应用自动处理逻辑中的一部分,而不是一次性的,一劳永益的或者手工完成的动作。
REST,microservice应该是松耦合的
client别知道太多,干好自己的一点点事就行。通信采用https协议,基于plain text(大白话文字)的。client请求有get,post,put,delete很简单,请求数据采用JSON或XML。可以不中断服务动态添加功能。如果做不到以上这些,实现松耦合,你最终得到的还是一个不伦不类的单体应用。
REST含义是REpresentational State Transfer(表达状态传递),其协议,其实可以随意制定,这只是一种设计思想,但多半采用HTTP,也有采用gRPC等等。支持REST的endpoint被称为RESTful,通信模式是客户机、服务器模式,采用请求、应答的处理方案。当然,也有其它的实现方案,特别是对于某些特殊场景,例如如果需要流数据传送的场景,更可能采用gRPC。
web下通过HTTP(S)实现RESTful
与Web场景结合,URI用来标识资源,返回数据中用被确定保存下来的数据(不会被改变,不是临时的,但实际上也可能是临时,只是这个临时相对于对话session来说是永恒的,足够久了,例如几天)标识对应的资源的相关信息(状态数据)。REST应用提供了一致的、统一的接口,资源信息也可以被缓存。
这里有若干抽象的概念,例如资源其实就是一堆信息,我们需要啥信息,都可以抽象为资源;而REpresentation则是资源信息的表述,复述。例如我想知道你的名字,想知道就可以作为一个请求发送过去,对应的资源就是你的名字,返回的内容呢,可以是包含你名字的表达的资源包。(不似人话。。。你明白就好)
这个HTTP通信协议的基础结构信息,client to server:
verb,可能是get, post, put, delete
uri, 目标资源地址
http version
request head,元数据,包括采用什么协议,JSON,XML?等
request body, 详细的资源状态信息(可能有)
verb中get是取数据(已知元数据),post是生成(元数据)及放数据,put是放(已知元数据)及修改数据,delete是删除数据
server-client返回格式:
http version
response code,2xx OK,4xx client error(你瞎搞,啥请求啊,回答不了),5xx server error(我出问题了,你的请求没问题,但我没法回答)
response header
response body
在设计时,URI标识资源,不要把动作放到里面,例如/path,这个uri不错,/getPath就不好,应该是通过get请求/path,虽然用/getPath也可以实现和get请求/path同样结果,但编程处理容易造成混乱。
下面是一个设计的表达图,方便理解:
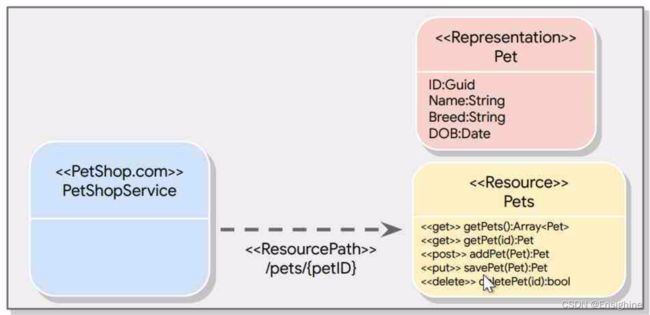
API设计
最后,我们来看API,作为REST API服务,service function一般会定义成:service.collection.verb这种格式(中间不一定是.,只是表达分割),参数通过URL或者http body传递。这种通用的格式其实是统一命名规则,编写开发者很容易创造出来,使用者很容易记忆或猜测学习。
查看所有的instance就可以用如下URI的get request:
https://compute.googleapis.com/compute/v1/projects/{project}/zone/{zone}/instances
除了HTTP,JSON这一类,还有OpenAPI等API协议标准,google是完全支持OpenAPI的。
当然,google也创造了自己的API,gRPC,gRPC可以由HTTP/2提供负载均衡,这很重要,这意味着能通过普通的http协议直接从外网通过gRPC协议获取gcloud中部署的应用的数据(经由Envoy Proxy)。与JSON,OpenAPI不同,它是binary传送的(高性能),它还支持流。
tools for API
google提供了两个工具帮助API设计和使用,都支持用户认证,监控,加密安全,OpenAPI和gRPC等
- Cloud EndPoint,区别是这个只能在Google cloud部署,也就是如果是服务端,在google cloud上的backend,那么优先采用这个东东
- Apigee,这个可以在任何地方部署,当然包括Google cloud。如果有各种杂七杂八的东西,特别是要在gcloud外部署,那就只能用这个了
DevOps自动化
这一节要研究使用CI/DI工具进行流水线自动化的过程,其中包括研究怎么用cloud repository管理源程序,自动构建、云构建、出发构建,使用容器注册管理生成image,使用Terrraform等。
CI是continuity integration,持续集成,要完成如下几个工作:
开发者将代码(开发完成后的代码)登录注册,运行单元测试,创建部属用的资源包image,最后是将生成的资源包保存在容器注册体系中,等待最终部署。
google提供了完整的,全覆盖的,整合的CI工具,由cloud source repositories对源代码资源进行管理,cloud build则根据设定好的步骤完成最终执行包(部署用的image)生成。
build过程还可以通过build trigger进行触发,后台自动完成,例如查看git repository是否有变更(新代码提交)。这个过程由设置cloud build trigger实现。Trigger可以设置为仅对变化影响到的代码或更复杂的判断条件。
容器注册(container registry),最后生成的部署资源包(docker image,deployment package)经由集中的容器管理统一管理,承载image的同时,还可以进行安全(或者叫做弱点)扫描,控制访问授权等等。
下面就不详细介绍细节了,只对一些地方强调一下。
cloud source repositories由IAM统一控制授权,可以经由pub/sub发送事件信息,能够与cloud debugger,logger集成在一起,可以将代码直接部署到app engine,还能与外部github,bitbucket代码管理工具直连,同步。
cloud build则一条命令就可以完成build工作,可以用docker的命令,也可以用gcloud(和docker命令很类似),最后也是一条命令就能提交image到容器注册,例如:
gcloud build submit --tag gcr.io/project-id/image-name .
其中,tag必须与build时设置相同(我觉得这其实就是保存的位置或索引),image名字必须gcr.io开头(更印证了这是个索引,gcr.io就是保存所在微服务定义)。最后,.所在位置(当前目录)必须有Dockerfile做控制完成container image生成,技术上来说google就是用docker实现的。
build可以通过设置trigger触发,每当submit发生,trigger验证触发条件是否满足以执行build。trigger能够基于branch,特定tag(包括对tag进行正则表达验证)触发。而build的控制文件则可以时Dockerfile或者cloudbuild.yaml(如果使用google工具)
container registry其实就是google自己的docker repository,可以直接使用docker push, pull命令操作。
不确定是否是省缺(应该是),google在build和container registry增加了自动签名(发放证明)的过程,注册时会将证明同时附加到image,而部署前需要进行验证。
CI的顶层就是这些,下面要看CI的底层,infrastructure,这个实现技术叫做IaS,Infrastructure as Code
一句关键的总结,这是核心设计基础的转变:
在云上,所有基础设施必须是可抛弃的
具体来说,没时间精力去安装、打补丁、升级、修机器,一切都要自动实现,缺机器,自动生成一个,坏掉了(需要升级),再自动生成一个,有问题的直接干掉(抛弃掉,好残忍!)。
google支持的相关技术、工具:
Terraform
Chef
Puppet
Ansible
Packer
Terraform是IaS工具,特点如下:
- 可重复的部署过程
- 定义性(描述性?)语言(HashiCorp Configuration Language,HCL),就是这个小破公司自己定义的,由模块(blocks),参数(arguments)和表达(expressions)组合而成。之所以用描述方式,是希望定义只有结果目标,具体实现过程是厂商做的,无需用户操心,厂商应当去选择、确定如何实现一致的,可重复的最终结果,以及中间的具体步骤顺序(这个思想很不错)。
- 以应用为中心(infrastructure就是个配菜。。?!)
- 并行部署
- 以模板驱动
Terraform HCL语言大概规则是:
block-type “block-label” “block-label” {
# block body (注释)
identifier = expression # 每个具体参数
}
例如:
resource “google_compute_network” “default” {
name = “${var.network_name}”
auto_create_subnetworks = false
}
一看就大概明白了七七八八:
定义了一个资源,是缺省的google 计算引擎的网络,命名方案是来自network_name变量,不自动创建subnet
选择存储
先总结一下:
- 将二进制image数据(一般杂七杂八大部分数据)保存到cloud storage
- 将关系型数据保存到cloud sql或者spanner(后者是前者容量大,地域广的扩展)
- 将NoSQL数据(非强关连,但还有格式)数据保存在Firestore和Bigtable(后者同样是大)
- 缓存数据保存在cachestore
- 最终整合用于统计分析的数据保存在BigQuery
在每一归类下,还有其它维度区分,例如SLA(可用性):
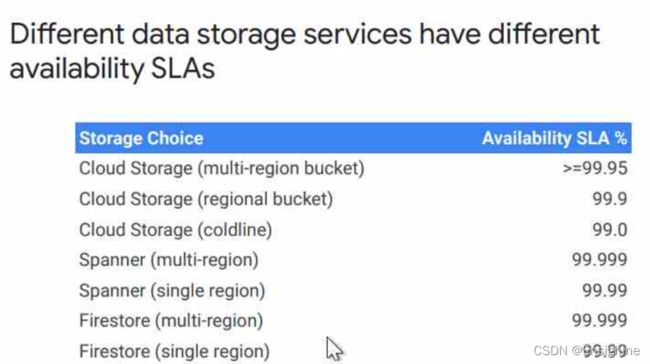 持久性维度(注意,大部分都需要配合手工、额外的备份、快照、导出工作或者设置参数):
持久性维度(注意,大部分都需要配合手工、额外的备份、快照、导出工作或者设置参数):
 可扩展性维度(扩展方案):
可扩展性维度(扩展方案):
水平扩展(一堆小节点,但要手动增加):bigtable, spanner
垂直扩展(用很大,更大的机器,手动添加):cloud sql, memorystore
自动扩展:cloud store, bigquery, firestore
 一致性保障维度:
一致性保障维度:
 很意外,大部分情况下一致性还是不错的,只要记住bigtable和memory store不保证强一致性就行了(但即使是这两者,也是保证最终一致性的),特别是如果bigquery如果没有replication,则同样有强一致性。
很意外,大部分情况下一致性还是不错的,只要记住bigtable和memory store不保证强一致性就行了(但即使是这两者,也是保证最终一致性的),特别是如果bigquery如果没有replication,则同样有强一致性。
成本维度:
- bigtable和spanner很贵,特别是对于很少数据量的时候,相对数据量越大,越便宜
- firestore相对便宜一点,但要收读写费
- cloud store更便宜,但性能有点差(特别是对随机读写),不适合保存数据库
- bigquery相对更便宜(不知道和cloud store比较如何?),但不适合快速访问记录,而且按照查询付费
这一页是考试重点,一定要记住:
 还有一些没有提到的storage:
还有一些没有提到的storage:
filestore,对于需要mount到vm的,这就是某种fs
block storage,直接供vm使用,有disk和ssd两种
有了存储,如何传(原始)数据过去?
cloud网络直传,都在internet,直接传到cloud storage,最好装个transfer agent,这个是在Docker container里面的,只要这个container能看到(mount)上的数据,都可以传到google cloud storage,最多数十亿文件,数百TB数据(要考虑上传网络带宽),在console可以看到状态,有传输log,加密传。
transfer appliance单独硬件,装载最多1PB,运到机房,安装,加密、保存数据到该设备,运回google,解密释放。加解密好像是自动完成,key在你自己手中控制。
从google application,例如yourtube,google ads,以及amazon redshift/S3 直接(定期)下载数据到bigquery。这个可以配置为schedule job
cloud and hybrid network
下面研究网络。google当前的网络由21个regions,64 zones构成,一个zone当成一个数据中心吧,一个region呢,算地区?PoP呢?point of presence感觉是某种存在,大概可以说是internet接入点?
google的VPC是全球化的,virtual private cloud,可以理解为给你切分出一块虚拟的,被隔离的网络体系供使用,在同一VPC内部,网络在底层是完全互通的,我理解就是一个单一二层network,甚至可以弄个数据包全球广播。
可以任意配置(subnet)网络和IP子网,但也有些限制,例如不能有地址冲突的两个IP子网,每个IP子网可以自由动态扩展(只要范围不冲突),不会有中断时间,但缩减不是自由的。另外,每个subnet可以有多个ip网段。
关于vm和network(二层网络)和subnet(IP子网)有这样要求:
每个VM至少有连一个subnet,每个VM最多8个interface,每个interface只能连一个network,由于interface是虚拟的,连多个interfaces没啥用,而且容易引起网络数据传输混乱。除此之外,最多interface支持还和vCPU数量有关,vCPU越多,可以支持的interface越多。
每个project可以有一个或多个network(仅被称为VPC?)多个project可以共用同一VPC。
google的全球负载均衡技术由http balancer实现,基于DNS实现,支持任何http, tcp/ssl代理,会根据访问请求所在位置自动发送到最近服务点(解析合适的服务IP)。主要为internet访问提供服务。
google还有区域负载均衡,支持http, tcp, udp,无论是公网IP还是私有IP都可以,(后端设备使用)任何端口都行(可以将负载发送到后端设备的不同端口)。但是后端设备只能在同一区域内,不能跨区域。
如果负载均衡对internet服务,建议开启ssl,google帮你管理ssl认证。
负载均衡配置选项:
 如果是HTTP(s),则甚至可以根据请求内容(layer 7)进行负载均衡任务分配。
如果是HTTP(s),则甚至可以根据请求内容(layer 7)进行负载均衡任务分配。
如果是TCP,则只能到传输层既TCP链路(layer 7, 源、目IP和端口)进行均衡。
如果是UDP,则只能对在同一region(一个subnet)的设备进行均衡(没有session,无法记录时序,跨region就乱套了)。
同时google还有CDN,能cache vm web的静态数据,GKE和cloud storage bucket里的(静态)数据。
网络互联,这也是个重点课题。
- 如果都在google cloud,直接vpc peering,只要网段不冲突就OK。
- 如果在google cloud之外,那可以用cloud ,要求可靠性则用cloud + HA,都需要自己配置网络路由。有传统VPN,只支持静态路由,或者cloud router支持动态路由协议(VPN+HA要求)。VPN+HA连接有很多种方式,暂不一一分析,以后看看实验中是否有要求。
- cloud interconnect专线直连,最低50Mbps,最高可达10-200Gbps,支持直接访问VPC各subnet,当然需要自己配置静态或者动态路由
- 通过其它ISP,google cloud与一些大通讯服务商有直通线路,通过这个服务商中专一下,等同延长了直连的专线。
在google cloud部署应用
现要确定到底用哪种引擎。
- 如果必须限定OS、机型,那就只能用compute engine了(如果OS特殊,连Google cloud都用不了。。。)
- 如果必须要容器(例如特定的平台、有一定性能要求),想自己管理,那就是GKE;不想自己管,那就是cloud run,另外GKE可以使用有状态应用,只要配置好container对应好state保存空间即可,但cloud run不行
- 应用是事件驱动的,则采用cloud function
- 如果只是普通基于java或者web的应用,则用app engine
首先,把应用限定为非数据库类、非存储类应用,这些都有专门的产品支持。普通应用如果又必须要计算引擎,最好的方案是基于模板创建instance group,这个模板应是能运行该应用的最小资源需求的vm,在启动脚本中绑定从repository安装程序。instance group manager负责生成、启动vm,根据用户负载(例如每分钟平均访问请求数)设置自动扩展,增加健康检查,在多个zone部署以实现高可用。
如果在多个region有部署,则用global loadbalancer,否则只需要region loadbalancer(好像不存在独立设置,会根据配置自动选择),增加CDN,对外服务采用SSL,对内服务(loadbalancer后端访问地址)一定使用内部地址,这样确保数据流不会误走internet
关于app engine:
- 每个project只能有1个app engine,但可以host多个services
- 每个service可以有多个version
- 能够根据设置对访问进行版本间分流
关于cloud function:
- 事件驱动,可以被web request,存储数据变化(upload),pub/sub信息驱动
- 完全自动管理,自扩展,省钱(只按执行时间计费,以100ms为单位)
设计可靠的系统
这个可靠性是个统称,具体来说至少包括可用、持久、扩展三个放面,三方面都达到很高的水平。这要求系统必须有容错能力,没有单点故障点,没有相关故障点,没有级联故障点。
对我个人,研究了很久高可用,前面几个概念都有深入理解,后面的的单点故障问题也探讨了很久,相关故障点和级联故障点稍微新奇一点,但也很容易理解,而且类似场景在云,这种单一、海量部署的情况下特别常见。
具体来说,按字面意思correlated failure相关故障可以更准确地翻译为相似故障,也就是类型、架构、模式相近的情况下发生的一种故障,这种故障在某个具体实例爆发具有偶然性,但对于这一类实例却具有内在的必然,有点类似系统性的设计错误,但并不仅仅是错误那么简单,即使是没有错误,但居于现场情况,却一定或者早晚会发生。例如不严查用火安全,管理易燃物,早晚由于疏忽大意等意外偶然事件,导致严重火灾发生,火灾就是correlated failure,而增加用火安全教育、严格易燃物管理、有防火行为规范、使用阻燃物制造等等就属于解决correlated failure的方案。
与correlated failure类似的cascading failure则是另一种情况,可以表达为为了避免或者修复前一个问题,而造成更多、更严重的问题,以至于最终系统崩溃。这样的例子也很常见,特别是在设计避免单点失效系统时,最简单粗暴的方案就是设计冗余,但并非简单的冗余就可以解决问题,如果没能很好地处理故障后通过冗余进行故障规避,如何能自动修复错误,甚至在故障之前如何探测错误,很可能冗余设计会造成业务阻塞,问题越积越多最后还是系统崩溃。连环撞车,剧场火灾逃生口塞死等等,都是没有对单一故障冗余之后的问题进行很好地处理,只简单粗暴地以猛然刹车停车、以多开逃生门来解决。
从某种意义上说,这是一个多样性避免灾难、缓慢延长处理时间(或吞吐量)降低单位时间影响度的时间、空间联合解决方案去应对时间、空间的多样性故障。
还有一种过载(错误)问题,也是需要云架构需要解决的常见问题。解决方案通常是采用过载断路器(circuit breaker)以及指数型回退方案等常用的设计模型。断路器(保险丝)都好理解,就是过载就咔嚓,不对过载部分业务对象提供服务了,那指数回退是什么?这是一种相对柔和一点的断路方案。具体来说,如果发现某部分业务、区域访问量过大,那么就人为(当然是设计成自动实现,而不是真的需要人实时现场操作)强制减少部分访问请求,如果依然过载,那么再将限制增加一倍(或者某个倍数,总之,每次增加幅度是指数级增长的),这样重复,直到系统能够承载这些业务,再逐步恢复,也是指数级逐步恢复,降低时是越降幅度越大,恢复时是越恢复,增加幅度越大。
存储也要有对应的韧性设计,而且要增加被动检测。韧性同样是高可用的概念之一,就是既刚又柔。在强大外力破坏面前,先刚,能撑就撑,而如果撑不住,并不是直接垮掉或者撂挑子不干了,而是做适当规避,勉力支撑最后自己能支撑的部分,这叫柔。
最后的lazy detetion没有合适的翻译,叫做延期清理数据垃圾?先这么写吧。
设计时要考虑到正常工作情况、降级工作情况以及故障工作情况。传统设计一般只考虑正常工作,对其他两点是很少提及的,及时研究,也是研究如何实现对上层透明,既在本设计层,能硬抗故障。随着业务系统越来越复杂,系统内故障越来越无法避免,系统设计无法完全忽视错误、故障的存在,不能把所有事情都由底层系统透明底硬抗,要主动考虑当有故障的时候如何处理,如何降级以避免更长期、更大规模、更严重问题。
分析容灾场景和容灾方案,实施、测试或模拟灾难恢复。
我们这一代人,前几天还在感慨岁月静好,没想到这两三年间,一切活了这么久都没见过的事情都亲眼所见,亲耳所闻,亲身所感,必须亲历而为了,明天就是发生WWIII,需要去住石洞、磨石斧我都毫不惊诧。以上说了很多个人感慨,主要是相关内容撞枪口了。
- availability 可靠性,需要做到具有故障容忍能力,有备份系统,有健康检查(方案),使用清晰的数据实时标识成功、失败数据
- durability持久度,通常指数据,特指如果由于硬件或者系统(包括逻辑)故障有多大的几率造成数据丢失。需要使数据复制到多个zone(zone为GCP的单点失效单元,在同一zone内有单点失效可能,跨zone则保证没有单点故障点),做定期备份(注意,冗余复制并不能解决逻辑层面故障,无论复制多少份,逻辑数据依然是1份,备份则是有时间点概念的,不同备份在逻辑上是分属不同时间点的多份)。最后备份还需要做定期恢复测试。
- 扩展性,要保证系统能跟随数据和用户增长持续工作。因此,需要监视使用量,需要系统能够根据负载变化自动增加或者减少承载用的计算机设备。
避免单点失效的方案
定义基础单元,以单元为评估基础,每个单元是一个单点失效单元。
单元要实现冗余的冗余,N+2,常见的冗余是N+1,不够,再加一个要做到N+2,这是要保证在测试、升级的时候,依然有冗余保证。
每个单元都能负担额外增加的负载,要有安全系数。
但既不要将单元扩得非常大,例如一个单元涵盖了全系统,把所有一切都作为单元内部组件,黑箱处理,也不要对单元设置非常大的安全系数。
尽力将单元设计成可以用无状态的克隆产品直接替换(也就是要把数据/状态数据存储与单元处理部分分开)。
了解相关故障
如果单一机器故障,则由此机器提供支持服务的所有系统都会故障(受影响);
如果机柜中为此机柜服务的交换机(top-of-rack)故障,则全机柜的服务器都无法访问。
如果一个zone甚至一个region出问题,则该zone或region内的所有设备都死翘翘。
软件如果有问题,运行同样软件的所有服务器都面临同样的问题。
如果存在全局配置,那么要是多个系统依赖这个配置体系,则他们可能统统完蛋,无一例外。
一组可能同步发生问题的相关组件被称为failure domain。
想要避免相关故障有什么方法?
- 按照failure domain将业务切分为多个服务
- 将它们部署到多个zone或/及region,具体跨多少,根据投资成本和服务范围,有钱任性就全球部署,至于WWIII之后还有没有internet就不在考虑范围之内了,毕竟用户都没了。
- 将服务组件切分,分散部署到多个处理器。
- 设计独立的,松耦合的,但相互协同的服务。
最后一句话,简直就是放X。。。。
了解级联故障
一句话解释,如果一个系统出问题,导致其它系统过载,然后依次崩溃。这种情况通常出现在负载均衡体系中,如果该体系中任何一个单点都不足以承载某个单点故障之后分散过来的额外业务,那么该体系的设计就存在级联故障。
解决方案不一定必须让一个单点能完全全部业务,有时,缩小单点所能承载的业务量,但增加全部分担节点的数量也是解决方案。因为每个分担节点就是一个单点故障点,当出现故障时,其上业务负载需要其它节点去承担,而如果节点数量多,那么每个节点承载的业务量负载就相对较小,再分散到相对较多的其它节点,每个完好节点所增加的额外负载也就变少了。
“查询到死”过载
这是个比喻,不见得一定是查询操作,但往往都是读操作,其最终现象是耗尽系统资源。由于系统由多个节点提供服务,当出现一例这样的访问,一个节点将被负载耗死,而由于访问请求没能得到回应,该请求(或此类请求)又会被转送到正常节点处理,然后再耗死这个节点,如此逐渐波及到所有节点,直到系统崩溃或者塞死。这是一个典型的多个逃生门依次被人流塞死的现相。究其根本,是业务处理逻辑有问题,过度消耗资源,但大部分时候,所谓过度并不那么显而易见,需要综合分析请求延时、资源使用率(CPU、内存、IO等等),错误率等实时数据来辅助判定,而其也无法在系统层面得以根治,需要转回开发程序员解决。
正反馈循环过载
更典型来说,当你希望系统更加可靠,对失败的访问请求进行了重试,而重试操作恰恰导致系统不稳定,更容易过载。
解决方案是当试图对失败请求进行重试的时候要考虑到正反馈过载的可能,采用若干办法去避免无限重试(设定最大重试次数)或者重试被堆积(达到一定失败数量则进行清里工作或者封闭相应的请求)。更精细的方案是使用指数式的回退重试,例如逐渐(按指数倍数)增加两次失败重试之间的等待时间,设定最大重试次数或者超时时间。
设置断路器保护
在一开始就考虑到降级状态,当服务偶发中断,造成大量访问请求失败,这些失败请求都会重试,因此会阻塞后端服务。如果在设计之初就想到此问题,可以在前端设置代理体系,并在代理设备设置健康检查判定后端服务状态,如果后端服务节点有问题,则代理设备根本不向后端转发请求。
在GKE,有Istio可以完成此工作。
lazy deletion延期清理
数据没用了,别着急清理,因为误删除数据是常有的事情,以下延期清理方案被认为是有效的:

容灾设计
先看标准的高可用设计要点:
- 设置多个server
- 由instance group控制server实例,通常在设置instance group的时候选择multiple zones,并且设置health check,enable auto-healing。health-check同时也可以用于负载均衡设备作为分配负载的依据。
- 如果是GKE,也可以设置regional cluster
- 在另一个zone设置数据库/存储的备份,或者采用跨zone的分布式数据库/存储,例如spanner或者firestore
- 存储(cloud storage)的高可用可以分为单region,双region和多region。其中双region和多region成本一样,可靠性比单region多了0.05%(差不多第4个9),当然延时稍大一点,具体多少没说。
- 如果是cloud sql,则需要在另一个zone设置replica,成本翻倍啦
- firestore或spanner本身就可设置跨region,多region比单region能多一个9,可用性由99.99%提高到99.999%
可用性指标对应的全年(计划内、计划外)业务中断时间
9% 33天,基本不可接受,个人容忍下限
99% 79小时,勉强可接受,个人或者企业正常业务容忍下线
99.9% 8小时,一般可接受,非关键业务正常容忍度,特别是对计划内事件的容忍度
99.99% 47分钟,一般可接受,对关键业务计划内或者非关键业务偶然事故
99.999% <5分钟,极度重要、关键业务要求,超越此要求的情况很少
99.9999% 28秒,更高的可用性对普通商业业务意义不大,但不排除特别场景,例如股票交易、导弹卫星核反应堆控制等
- 容灾,冷备份方案:创建快照、机器的镜像,数据备份,保存到其它region的存储;如果主region故障,在其它region重起备份;路由访问到新region;文档化操作步骤并定期演练;
- 容灾,热备份方案:跨多region创建instance group;使用全球负载均衡;将非结构化数据保存在多region的存储bucket;使用spanner或firestore跨region部署保存结构化数据
针对容灾,还要进行灾难场景头脑风暴,对不同业务服务定义RTO,RPO以及恢复优先级。灾难不仅仅有自然灾难,而是所有一切包含人工误操作在内的造成数据丢失或不可用,造成服务中断的场景。
下一步根据设定场景和RPO,RTO指标设计不同的组件资源实现方案,制定备份、恢复方案。这个(容灾准备)方案需要与日常操作结合,称为日常操作中的一部分。
规划:
- 有哪些可能的灾难
- 如何确定不同的灾难场景,选择合适的应对方案
- 文档化应对方案
定期实施
- 可以在生产环境或者测试环境练习
- 注意实施风险(个人强调,在生产环境都小心,但在测试环境同样要小心,因为在演练方案中,很多时候与实际生产环境根本无法完全隔离,很容易纠缠不清,甚至对生产数据误操作)
- 这也是最后这条要平衡风险:对系统缺陷点没有正确认识的风险。不实施,不练习,你根本不知道有问题。练习了,如果反而造成问题怎么办?其实这纯粹是无知者无畏,没看到,不等于不存在,有准备地应对,总比突发意外更好把控最终走向,失败风险也更小
安全
google cloud安全是用户和google共同的责任
先说清楚,你我都有责任,不是google一家负责的。google提供工具,并监视着你运行的服务,google cloud也有提升平台安全的控制手段和各种功能特性。
如果进行了适当的设置,google提供了工具去构建一个安全的环境,同时也支持集成第三方的安全工具,最后还有工具去监视和审计逆的网络及各种资源安全。包括以下各个放面:

最少授权原则
这是安全的一项通用准则,用户只能获得完成他的工作的必须授权,不额外提供额外的授权。这同样适用于计算机实例,运行程序。通过IAM可以实施这个原则,通过登录识别用户,通过服务账号确定计算机或者代码,通过将角色赋予用户或者服务账号进行授权,控制他们可以做什么(其它都不可以做)。
职责分开
这个控制的含义是把一些关键操作赋予不同的操作者,这可以避免目标方向冲突,能检测到控制错误,包括安全缺口或者信息窃贼:
- 更改或删除数据与检测这个动作的责任人分开
- 获取敏感数据需要多次/人授权
- 敏感系统的设计、实施、报告分别由不同人完成
例如,写代码的人不部署代码,部署代码的人不修改代码。如何实现呢?
- 使用不同项目区分责任
- 不同人在不同项目被授予不同权限
- 使用foler去帮助进行组织、项目管理
定期审计log以发现攻击
log包括:
- admin logs
- data access logs
- VPC flow logs
- Firewall logs
- System logs
Google Cloud也付合很多第三方或者政府的安全标准,包括:
- ISO/IEC27001
- HIPPA
- FedRAMP
- SOC 1
别担心google cloud是否通过安全认证,只要你的程序OK,google cloud就OK,好好研究如何用google cloud的各种安全功能实现程序通过安全认证对外提供服务吧!(牛皮爆了。。。)
google cloud有security command center一个页面提供对组织和项目的安全统一管理,这是一个安全的dashboard
人的安全
先要把人user授权给项目project,把user置为项目的成员member,并赋予不同角色。一个人user可以被赋予多个roles。
每个member就是不同的user,通过登录login识别。member可以被加入到组以便于管理。role是一组授权,也是为了便于管理。通过console可以方便地查看不同role具有的授权具体是什么。使用group对人进行分组,使用folder,project对resource进行分组,使用role对授权进行分组。注意最小授权原则,尽力避免分配owerner或者editor授权,对大部分用户,这两者授权都是超限的。
Identity-Aware Proxy(IAP)使得google cloud能很容易地控制对vm或者application(GKE,application engine)授权,即使他们隐藏在负载均衡设备之后。配置后,用户必须登录才能进行下一步操作。Admin控制谁可以访问app。而且用户无需VPN就可以对基于web的application进行相应允许的操作。
授权过程以(internet)联合服务的形式提供(CIAM customer identity access management),与其它很多网络应用整合在一起,何以进行相互授权。例如你可以用facebook账号登录,然后就拥有了与该账号在google cloud捆绑的授权。不仅仅网络账号,包括手机、email/密码等很多种方式都可以完成登录。
与真实用户类似,还可以创建服务账号用于vm,gke,通过对服务账号授权,可以让vm运行进程仅仅具有服务账号所授之权利。
service account无法直接登录,只能用将ServiceAccountUser role赋予某个普通用户的方式让该用户获得此service account的权利。service account代表用户授权的同时也与对应的资源绑定,也就是此service account只能操作对应的资源,完成授权的任务。
创建service account的同时可以(选项)创建并下载key,拥有此key就等同于拥有此service account(owner ),key是json格式。这个key很强,所以要注意安全,key有两种管理模式,google管理或者用户自己管理。如果是google管理,google会定期更新此key,最长周期是2周,这样避免某个用户如果之应当临时拥有授权(拿到此key),而以后一直拥有授权无法被删除。用户管理的key没有自动过期,但一个service account也可以最多创建10对key以便人工进行轮换控制,而且google有cloud KMS系统帮助管理人工key。
key对于CLI操作很有用,这样可以凭借key不登录console就拥有所赋予的权利,使用命令操作完成任务。
网络安全
不要配置(移除)外部IP以提高vm的安全性(通过防火墙对外暴露service ip)。可以通过google console提供的shell或者vm的ssh连接去登录vm,或者通过堡垒机(一台单独的,特别加强安全的,拥有外部IP的)作为跳板访问内部私有设备。google cloud console也算作堡垒机的一种吧,一些堡垒机(设备)还可以支持NAT功能,允许通过外界直接访问内部地址,或者允许内部设备访问外部。
所有的internet访问应该在负载均衡设备、防火墙(proxy或WAF web application firewall是一种reverse proxy),API gateway,IAP (In Application Programming应用内部与服务端通信的程序规则、协议),其含义是由internet发起的访问请求无法一次、直接地穿透保护层,直达内部,需要通过先建立与以上这些堡垒设备连接之后,二次发起内部请求才能送达内部,而二次请求所能采用的通信协议具有更多的限制,这样使攻击困难度增加了不止一个数量级,保护方案也更多,同时有更多的监视、过滤、跟踪、记录手段,且不会造成过度的资源占用,因为只有与堡垒机建立连接之后(无论是正常访问还是攻击访问)再次发起的二次请求才值得去关注,已经大大缩减了需要关注的数据量。
由于最小授权原则,google的所有资源都是只有被授权才能获得访问权,即使内部资源、设备、服务账号都是如此。以下命令将允许内部网段A访问存储:
gcloud compute networks subnets update subnet-a --enable-private-ip-google-access
对于VM,所有的由外到内的访问请求都是禁止的,除非设置防火墙规则允许它(相反,由内到外的访问缺省是允许的)。
google对API的控制通过cloud endpoints完成,每个call都通过JSON web token或者google API keys授权。授权控制与IAM被整合在一起。
帮助记忆(待确定):一切在google cloud内部的API相关管理,通过cloud endpoints完成,而如果需要部署到外google cloud外部,则需要通过APigee,换句话说,APigee可以被单独下载到任何机器,与任何语言整合。
google endpoints都使用https,但用户应用自己的endpoints根据需要去配置协议,建议HTTPS或者TLS,应用程序级别的安全由用户自己负责,google管不了,只提供工具。
抵御DDoS攻击,google提供了全球负载均衡检测并丢弃(将攻击地址列入黑名单?直接丢弃来自攻击地址的访问请求包)攻击访问;通过CDN保护后方资源(这样就变成攻击者与google比拼财力,看我的cache大,还是你的访问多!)。
google提供了cloud armor来创建网络安全策略:
- 对google资源设定IP地址(及范围)黑白名单
- 对已知的攻击设置黑名单(攻击端口、攻击协议等等)
安全策略支持最高到第7层应用层协议,例如SQL注入攻击等;
本节最后一部分谈加密。google用了一个很有意思的词:at rest。意思就是数据google省缺是加密的,但是并非实时,也就是数据保存后,如果系统不忙,一定、早晚会被加密,但如果保存的时候很忙,那么就只能先写下来,保证数据持久性,然后找空余时间加密。读取呢,实时解密的(或者不需要,因为还没真正加密,但这事就不用你操心了),这样做几乎观察不到有性能下降,
加密采用AES-256方案,key由google KMS管理并且定期轮换。如果由于法规遵从原因,你可以自己管理key(CMEK customer managed encryption keys),自己创建key、设定轮换时间。CMEK基于google KMS实现,可以由KMS创建Key(或者上载key),由KMS完成轮换操作等,在每个API call授权时由KMS完成认证。Key只存在于内存中(不知道是否是全部key,包括公钥)。
避免数据丢失API可以帮助你发现、校验敏感数据,包括email,信用卡号、税号等等,也可以自己定义敏感数据类型(我觉得就是个正则表达,只是可以定期扫描各种类型的存储数据而已),能够对数据进行删除、掩码、令牌化(转换替代),或者只是发现识别所在位置
维护和监视
好长的课程,终于到了最后一节,加油!
三个概念:rolling update(滚动升级),blue/green deployment(红绿部署),canary(金丝雀)发布
微服务架构的一个要点,也是特点是要做到服务升级时不能断开客户,不能中断业务。所以:
- 最好能100%做到向前兼容
- 在URL中加入版本号,如果需要发起中断业务的变更(包括无法兼容以前版本),那就把改编版本号
- 单纯部署新版本应用则无需中断业务
- 在新版本上线之前要经果有效的测试过程
具体如何能做到升级时不中断业务呢?一般我们会把服务实例置于复杂均衡器之后,那么就可以每次更新一个后台实例,采用滚动升级的方案可以让两个版本的服务实例同时工作。滚动升级是instance group的特性,只要修改instance模板即可升级新版本。滚动升级也是GKE的缺省设置,只需要修改Docker image既完成升级。App Engine更是全自动完成此滚动升级过程。
如果不想采用滚动升级,同时运行两个版本,那可以采用蓝绿部署的方案。这是两套完整、相互独立的部署。蓝色为当前版本,绿色为新版本。新版本经果严格测试通过后,可以一步将访问由蓝切绿。如果绿版(新)运行中出现问题,可以再马上切回蓝版。DNS能完成vm、负载均衡设备切换,GKE configure service可完成service(label)切换,App Engine则可以通过spliting traffic完成。
在滚动升级之前,还可以增加canary release去降低升级风险。具体来说部署一个单一实例,并发送一小部分访问请求,监视运行中的错误。对于VM,可以创建一个新的instance group,并在loadbalancer上将其设置为“额外的additional”后端设备。在GKE可以采用同样label创建新pod,负载自动会发送过去一部分。App Engine依然可以用splitting traffic实现。个人觉得,这个和滚动升级没啥区别,只是把滚动升级这种连续自动完全升级过程阶段化,只升级其中一个实例,然后看看有没有问题,持续运行一段时间,而不同于滚动升级依次自动连续不断升级过去,中间多加了观望、后悔、思考的时间。滚动升级重在不间断地升级,金丝雀发布重在在小范围实验中尽早发现问题。
接下来,或者不得不,还是谈一下钱。所有的google cloud都是要钱的,创建项目一时爽,月底付费火葬场。容量规划是个连续的,步骤清晰的循环:
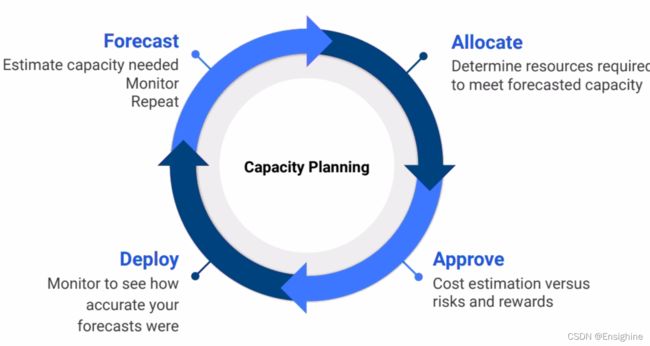 优化计算资源成本:
优化计算资源成本:
- 先建个比较小的vm,测试是否工作
- 如果可能,用更多但是更小资源的vm实现,通过设置autoscaling来满足负载要求
- 考虑到连续(确保)使用折扣
- 至少一部分资源采用抢占模式,这样可以获得最高二折(80% off)的折扣,主要要增加auto healing设置以变能够自动重新创建vm,恢复运行
- google cloud rightsizing recommendation能在vm使用率不足时想你报警
优化磁盘成本:
- 不要过度准备磁盘空间,刚好够用就行
- 注意性能要求,主要是IO访问类型,小块读、写或者大块读、写
- 合理配置实例优化数据访问
- 根据IO请求,选择磁盘或者SSD
优化网络成本:
- 更贴近数据创建vm,通信成本是在同zone网络通信免费),在同region的google服务访问一般免费(memorystore for redis除外),但其它所有出到internet或者跨zone的数据通信(非google service)都要收费
GKE的用量表usage metering可以帮助避免过度预建过大的GKE cluster,实现metering需要从meterics server把PodMeterics数据下载到bigquery的两个表里。与billing export对比,就可以知道是否过度预留了容量。数据可以在Data studio dashboard查看
注意不同存储的价格差距,在决定之前多比较以下,够用即可。例如:1GB firestore免费,而1GB bigtable要1400刀/月
还可以考虑google的其它服务,这些都不需要自备存储。(当然,有其它的收费方案),例如CDN, caching, messaging, queueing
google cloud pricing calculator可以预估成本。
最后billing report能看到最后实际发生的所有费用的细节。(vm sizing recommendation就在这里面)如果想进一步详细分析,可以export到bigquery
google data studio可以将数据变为可视图表。
可以设置预算警报cloud function,通过pub/sub发送给相应的责任人,以便他们及时了解预算使用情况。
关于监控有以下工具,各有专长。具体使用特点以后再补充:
- monitoring,查看各种实时(其实滞后那么几分钟)的metric指标,入选者作为SLI指标去评价SLA达成度,也可以了解到趋势、瓶颈、可以从哪节省成本等等。通过uptime check去监视可用度及延时。SRE的4大黄金信息是延时、流量、错误和饱和度(或者说是使用率吧)。当服务出问题是发送报警以及时处理,这样才能实现SLO(SLO就是60分标准,SLI是各科,具体metric是考试,SLA是与家长定的保证书)
- logging,全部信息
- trace,运行中数据获取
- debugger,程序有错误问题,要debugger
- error reporting,各种错误报告,通常都是访问请求错误
- profiler,看看各段(内部)程序执行时间