Python:对西瓜书csv数据进行数据分析,训练模型并测试
这次我们来系统的了解一下决策树DecisionTreeClassifier的实现和预测
整体需求包:
csv、DictVectorizer、LabelBinarizer、DecisionTreeClassifier、numpy、graphviz、matplotlib、predict
导入需求包:(graphviz后面会用到)
import csv
import matplotlib.pyplot as plt
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
from sklearn import tree
import numpy as np
需求包介绍:
1.Python读取csv文件(详解版,看了无师自通)
csv文件的本质是一种以文本存储的表格数据(使用WPS、Excel即可读取csv);
通常第一行是表头说明每列含义,接下来每行代表一行数据。
2.python中DictVectorizer的使用
对特征值进行二进制编码,参考《数字电子技术》中的小白鼠试毒药问题
3.python编程之sklearn.preprocessing.LabelBinarizer()的用法解析
与DictVectorizer函数很像,都是one-hot编码的转换。只是设计目的不一样,LabelBinarizer用来解决标签的转化
4.【Python机器学习】——决策树DecisionTreeClassifier详解
DecisionTreeClassifier属于分类树,这次我们用利用信息熵计算的ID3算法实现
5.python之numpy的基本使用
本文中只在末尾用到了reshape函数
6.graphviz python_决策树可视化python
可以说graphviz远没有matplotlib.pyplot好用,又得下载graphviz还得输指令的
7.【Python】 【绘图】plt.figure()的使用
这里主要用的是pyplot中的tree函数,不过没找到相关博客。后面有时间我再写一篇相关介绍,先放上figure函数的用法(创建背景图)
8.python中predict函数_sklearn中predict()与predict_proba()用法区别
对新建数据进行预测
读取数据:
import csv
with open('wm20.csv','rt')as f: #运用open with函数自行关闭wm20.csv节省资源
file = csv.reader(f) #将文件内存位置赋值给file变量
headers = next(file) #next(file)为读取csv第一行,将其赋值给headers表头变量
print(headers)
输出:[‘编号’, ‘色泽’, ‘根蒂’, ‘敲声’, ‘纹理’, ‘脐部’, ‘触感’, ‘好瓜’]
我已经提前把西瓜数据导入为csv格式:wm20.csv 免费下载
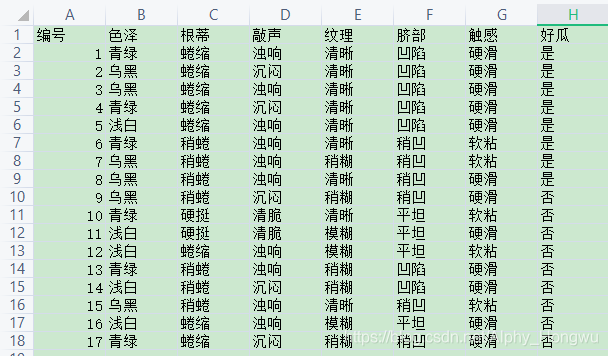
分离标签和特征:
要将数据变为决策树可用的数据,我们需要把整体数据分离为标签和特征两种
data = []
target = []
for row in file:
target.append(row[len(header)-1])
dataDict = {}
for i in range(1,len(row)-1): #list引导必须是int或者slices,所以不能直接把row当引导
dataDict[header[i]]=row[i] #把每列的值赋值给改列表头,放到字典中
data.append(dataDict)
print(data)
print(target)
输出:
[{‘色泽’: ‘青绿’, ‘根蒂’: ‘蜷缩’, ‘敲声’: ‘浊响’, ‘纹理’: ‘清晰’, ‘脐部’: ‘凹陷’, ‘触感’: ‘硬滑’}, {‘色泽’: ‘乌黑’, ‘根蒂’: ‘蜷缩’, ‘敲声’: ‘沉闷’, ‘纹理’: ‘清晰’, ‘脐部’: ‘凹陷’, ‘触感’: ‘硬滑’}…{‘色泽’: ‘青绿’, ‘根蒂’: ‘蜷缩’, ‘敲声’: ‘沉闷’, ‘纹理’: ‘稍糊’, ‘脐部’: ‘稍凹’, ‘触感’: ‘硬滑’}]
[‘是’, ‘是’, ‘是’, ‘是’, ‘是’, ‘是’, ‘是’, ‘是’, ‘否’, ‘否’, ‘否’, ‘否’, ‘否’, ‘否’, ‘否’, ‘否’, ‘否’]
把特征值转换为0、1数组
这里输出结果可能有人看不懂,其实仔细观察会发现。色泽3种、根蒂3种、敲声3种、纹理3种、脐部3种、触感2种,加起来就是17种。而输出的数组也刚好有17列,结合上文中对DictVectorizer的解释,就不难理解:
拿色泽和触感为例:
将色泽编码为:乌黑[1,0,0]、青绿[0,1,0]、浅白[0,0,1]
将触感编码为:硬滑[1,0]、软粘[0,1]
那么
{‘色泽’:’乌黑’,’触感‘:’硬滑‘}的西瓜转化为二进制编码就变成了[1,0,0,1,0]
{’色泽‘:’浅白‘,’触感’:‘软粘’}的西瓜转化为二进制编码就变成了[0,0,1,0,1]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
dummyX = vec.fit_transform(feature).toarray() #利用DictVectorizer方法将特征编码为二进制数组
print("dummyX:",str(dummyX))
print(vec.get_feature_names()) #统计表中出现过的特征词
输出:
dummyX: [[0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 1. 0. 0. 1. 0.]
…省略n个西瓜…
[1. 0. 0. 0. 0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]]
[‘敲声=沉闷’, ‘敲声=浊响’,…, ‘触感=硬滑’, ‘触感=软粘’]
把标签转换为0、1数组
标签部分只有’是‘、’否‘,所以我们可以直接利用LabelBinarizer进行编码
from sklearn import preprocessing
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(label) ###利用LabelBinarizer将target数据转化为0、1
print("dummyY:"+str(dummyY))
输出:
dummyY:[[1]
[1]
…省略n个西瓜
[0]
[0]]
使用ID3建立决策树
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='entropy')
decision = clf.fit(dummyX,dummyY)
我们已经将所需要的数据、标签数据转化为了所需要的格式,现在直接引用DecisionTreeClassifier函数即可得到决策树。
创建出文件并实现可视化
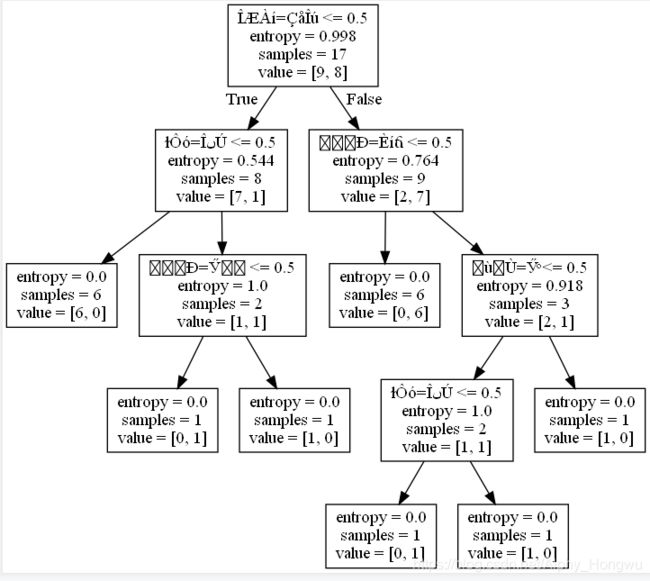
方法一:Graphviz
利用open函数将结果输出为.dot文件,再通过graphviz转化为.png
with open('wm20.dot','w')as output: #将结果输出为.dot文件,并运用指令实现可视化
output = tree.export_graphviz(decision,feature_names=vec.get_feature_names(),out_file=output)
下载了Graphviz后,在输出文件的文件夹下shift+右键会出现“在此处打开Powershell窗口”。之后在窗口内输入指令:dot -Tpng wm20.dot -o wm20.png即可获得.png的结果图如下:
方法二:matplotlib.pyplot
直接引用pyplot包,能够通过指令直接输出决策树图
import matplotlib.pyplot as plt
plt.figure(1)
tree.plot_tree(decision)
plt.show()
输出结果如下:

测试集预测
我们按照上面的DictVectorizer的编码方法自己编俩新的西瓜数据,我们选用{‘浅白’,‘蜷缩’,‘浊响’,‘清晰’,‘稍凹’,'硬滑’}和{‘浅白’,‘硬挺’,‘清脆’,‘模糊’,‘平坦’,'硬滑’}的数据进行预测。
newwnX = [[0,0,1,0,0,1,0,1,0,1,0,0,0,1,0,1,0], #{'浅白','蜷缩','浊响','清晰','稍凹','硬滑’}的西瓜数据
[0,0,1,1,0,0,0,1,0,0,1,0,0,1,0,1,0]] #{'浅白','硬挺','清脆','模糊','平坦','硬滑’}的西瓜数据
""""
#新版sklearn所有数组默认为二维,即使只有一行或一列,也必须reshape为(1,-1)。
这里我们输入了两个西瓜数据,本身就是二维所以不需要转变。
"""
# newwnX = np.array(newwnX).reshape(2,17)
pY = clf.predict(newwnX)
print("pY:"+str(pY))
输出:pY:[1 1]
可以看出,即使我们故意选了一个常识中很生的西瓜,它也预测为好瓜。要么这人工智能(zhang)坑我们,要么就是这个模型很烂,要么就是代码有问题
整合代码如下:
import csv
import matplotlib.pyplot as plt
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
from sklearn import tree
import numpy as np
with open('wm20.csv','r')as f:
file = csv.reader(f)
header = next(file)
data = []
target = []
for row in file:
target.append(row[len(header)-1])
dataDict = {}
for i in range(1,len(row)-1): #list引导必须是int或者slices,所以不能直接把row当引导
dataDict[header[i]]=row[i] #把每列的值赋值给改列表头,放到字典中
data.append(dataDict)
vec = DictVectorizer()
dummyX = vec.fit_transform(data).toarray() #利用DictVectorizer方法将特征编码为二进制数组
lb = preprocessing.LabelBinarizer() #利用LabelBinarizer将target数据转化为0、1
dummyY = lb.fit_transform(target)
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX,dummyY)
plt.figure(1)
tree.plot_tree(clf)
plt.show()
# with open('wm20.dot','w')as output: #将结果输出为.dot文件,并运用指令实现可视化
# output = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=output)
newwnX = [[0,0,1,0,0,1,0,1,0,1,0,0,0,1,0,1,0], #{'浅白','蜷缩','浊响','清晰','稍凹','硬滑’}的西瓜数据
[0,0,1,1,0,0,0,1,0,0,1,0,0,1,0,1,0]] #{'浅白','硬挺','清脆','模糊','平坦','硬滑’}的西瓜数据
""""
#新版sklearn所有数组默认为二维,即使只有一行或一列,也必须reshape为(1,-1)。
这里我们输入了两个西瓜数据,本身就是二维所以不需要转变。
"""
# newwnX = np.array(newwnX).reshape(2,17)
pY = clf.predict(newwnX)
print("pY:"+str(pY))