注意力机制在通道和空间中的融合应用(CBAM: Convolutional Block Attention Module)
摘要
我们提出了一个对前馈神经网络十分有效的简单注意力模型。我们的注意力模型会关注feature map的通道和空间,之后模型输出的attention maps会与输入的特征图相乘。这个模型既轻量又通用,可以被加入到任何CNN中,并且可以一起与网络进行端到端的训练。
简介
最近的研究表明,深度(depth),宽度(width),基数(cardinality),这三个因素对CNN网络的表现最相关。从LeNet到Residual-style Networks,网络变得越来越深。VGG表明堆叠相同形状的块可以得到合理的结果。ResNet表明利用跳跃链接可以构建更深的网络。GoogLeNet表明宽度可以影响模型的性能。Zagoruyko 和 Komodakis提出了在ResNet中增加宽度。Xception和ResNetXt表明基数不仅可以减少参数,并且比单纯增加网络的宽度和深度对网络的表现力影响更大。
我们提出的是一种注意力机制,目的在于通过使用注意力机制来增加表现能力:专注于重要的特征,并抑制不必要的特征。我们把它命名为 “Convolutional Block Attention Module”(CBAM) 因为卷积运算是将跨通道信息和空间信息混合在一起来提取信息特征的。我们 依次加入通道注意力机制和空间注意力机制来强调通道和空间维度的特征。通道注意力主要是用来知道是'什么',空间注意力主要是用来知道在'哪里'。
主要贡献
1. 我们提出了一种简单而有效的注意模块(CBAM),可广泛应用于提高cnn的表征能力
2. 我们通过广泛的消融研究来验证我们的注意力模块的有效性。
3. 通过插入我们的轻量级模块,我们验证了各种网络的性能在多个基准测试(ImageNet-1K、MS COCO和VOC 2007)上得到了极大的改善。
相关工作
“Network engineering” 是视觉研究中最重要的一部分,自从实现了大规模的CNN后,大量的架构被提出。一种直观而简单的扩展方法是增加神经网络的深度。Szegedy等人介绍了使用多分支架构的深度Inception网络,其中每个分支都是仔细定制的,而由于梯度传播的困难,深度的原始增加达到饱和。ResNet提出的跳跃链接使得网络可以变得很深。基于这一点,WideResNet,Inception-ResNet,ResNeXt等网络开始发展。WideResNet提出了一种具有较多卷积滤波器和较低深度的残差网络。PyramidNet将WideResNet的网络宽度进一步加大。ResNeXt使用分组卷积,并表明增加基数可以获得更好的分类精度。最近提出的DenseNet,迭代地连接输入特征和输出特征,使每个卷积块从所有前面的块接收原始信息。他们的研究都是关注的宽度,深度和基数,但我们的研究关注的是注意力。
注意力机制
注意力在人类感知中起着重要的作用,人类视觉系统的一个重要特性是,重点关注整个场景中的某些部分。
Wang et al.[27]提出了Residual Attention Network,该网络使用了编码器解码器风格的注意模块。通过细化特征图,该网络不仅性能良好,而且对噪声输入具有鲁棒性。我们把注意力机制依次运用在通道和空间上。这样就可以简化计算和参数,使得模型可以即插即用在任何网络上。
在SE(Squeeze-and-Excitation)这个方法中,他们使用了全局平均池化来计算通道注意力。但是我们发现这些都是次优特征,因此为我们使用的是最大池化。他们还错过了空间注意力,这在决定“在哪里”聚焦方面起着重要作用
Convolutional Block Attention Module

一个![]() 的特征图作为输入,CBAM会依次输出一个
的特征图作为输入,CBAM会依次输出一个![]() 的通道特征图
的通道特征图 和一个
和一个![]() 的空间特征图
的空间特征图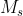 。在做乘法时,通道的注意力会沿着空间维度传播,空间注意力也会沿着通道维度传播。通道注意力模块和空间注意力模块,这两个模块可以并行或者串行放置,但是串行的结果比并行好,并且顺序为先通道后空间最佳。
。在做乘法时,通道的注意力会沿着空间维度传播,空间注意力也会沿着通道维度传播。通道注意力模块和空间注意力模块,这两个模块可以并行或者串行放置,但是串行的结果比并行好,并且顺序为先通道后空间最佳。
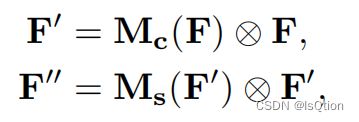
其中, 表示对应位置元素相乘(element-wise multiplication)
表示对应位置元素相乘(element-wise multiplication)
通道注意力
由于feature map的每个通道都被认为是一个特征检测器,所以通道的注意力集中在给定一个输入图像是什么。为了有效地计算通道注意力,我们压缩了输入特征图的空间维数。为了聚合空间信息,对于平均池化(average-pooling),Zhou建议使用它来学习目标对象的范围,Hu等人在他们的注意模块中采用了它来计算空间统计。我们认为,最大池化(max-pooling)收集了另一个关于不同对象特征的重要线索,以推断更细微的通道注意, 所以我们两者都用了。我们的经验证实,利用这两个特性比单独使用它们大大提高了网络的表示能力。
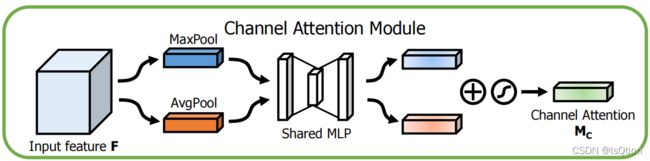
首先利用平均池化和最大池化来聚合特征图的空间信息,分别得到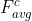 和
和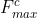 ,然后,这将和转发到一个共享的只有一个隐藏层的MLP网络,隐藏层的神经元个数是
,然后,这将和转发到一个共享的只有一个隐藏层的MLP网络,隐藏层的神经元个数是![]() ,其中r (reduction ratio)是超参数。通多最大池化和平均池化分别得到的两个channel attention map的维度都是
,其中r (reduction ratio)是超参数。通多最大池化和平均池化分别得到的两个channel attention map的维度都是![]() ,将经过sigmoid之后,两者相加就是Channel Attention 的输出
,将经过sigmoid之后,两者相加就是Channel Attention 的输出
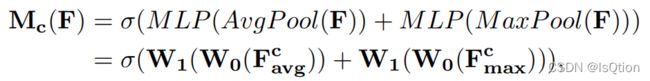
其中σ表示sigmoid
代码
#通道注意力中的共享MLP层
class MLP(nn.Module):
def __init__(self,in_channel,reduction_radio):
super(MLP, self).__init__()
self.in_channel = in_channel
self.out_channel = int(in_channel/reduction_radio)
self.layer = nn.Sequential(
nn.Linear(self.in_channel,self.out_channel),
nn.Linear(self.out_channel,self.in_channel)
)
def forward(self,input):
res = self.layer(input)
return res
#通道注意力机制
class CA_model(nn.Module):
#feature_map的大小,通道数,缩减率
def __init__(self,map_size,channel,reduction_radio):
super(CA_model, self).__init__()
self.maxpooling = nn.MaxPool2d(map_size,stride=1)
self.avgpooling = nn.AvgPool2d(map_size,stride=1)
self.MLP = MLP(channel,reduction_radio) #共享的MLP网络
self.sigmoid = nn.Sigmoid()
def forward(self,input):
#对每个通道进行最大池化和平均池化
feature_max = self.maxpooling(input).view(input.shape[0],1,-1)
feature_avg = self.avgpooling(input).view(input.shape[0],1,-1)
#将获得的两个attention map送入共享MLP中
feature_max = self.MLP(feature_max)
feature_avg = self.MLP(feature_avg)
feature_avg = self.sigmoid(feature_avg)
#最后的输出就是两个attention map的加和
return feature_avg+feature_max空间注意力
我们利用特征间的空间关系生成空间注意图,不同于通道注意力,空间注意力更重视在哪里。沿着通道轴进行平均池化和最大池化,把通过这两个池化操作得到的两个HxW的特征图拼接起来。将拼接好的特征图进行卷积,最后执行sigmoid激活得到Spatial Attention 。
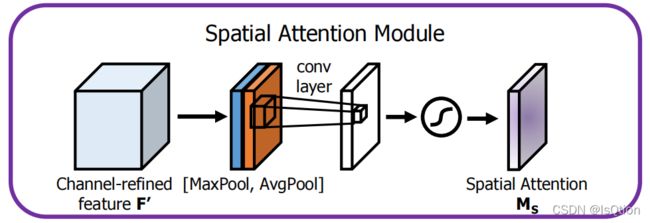
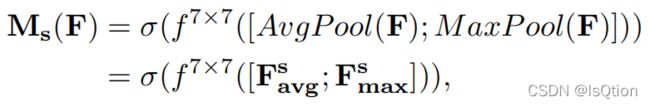
其中,![]() 表示卷积核大小为7的卷积操作,σ表示sigmoid
表示卷积核大小为7的卷积操作,σ表示sigmoid
沿着通道轴的池化
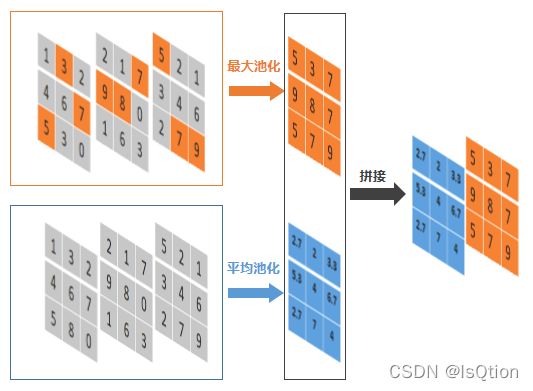
沿着通道轴的最大池化,就是看每个通道的对应位置,哪个数值最大就保留最大的数值。
沿着通道轴的平均池化,就是计算每个通道对应位置的平均值。
代码
# 空间注意力机制
class SA_model(nn.Module):
def __init__(self):
super(SA_model, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, padding=3, stride=1),
nn.Sigmoid()
)
def forward(self,input):
#沿着通道轴进行最大池化和平均池化
feature_max = self.maxpooling(input)
feature_avg = self.avgpooling(input)
#得到的通道间的最大池化attention map 与 平均池化的attention_map拼接在一起
feature_map = torch.cat((feature_avg,feature_max),1).view(input.shape[0],2,input.shape[2],-1)
#将拼接在一起的attention map放入一个卷积和激活
res = self.layer(feature_map)
return res
#通道间最大池化
def maxpooling(self,input):
res = torch.max(input,axis=1)[0]
return res
#通道间平均池化
def avgpooling(self,input):
res = torch.mean(input,dim=1)
return res整体代码
import torch.nn as nn
import torch
#通道注意力中的共享MLP层
class MLP(nn.Module):
def __init__(self,in_channel,reduction_radio):
super(MLP, self).__init__()
self.in_channel = in_channel
self.out_channel = int(in_channel/reduction_radio)
self.layer = nn.Sequential(
nn.Linear(self.in_channel,self.out_channel),
nn.Linear(self.out_channel,self.in_channel)
)
def forward(self,input):
res = self.layer(input)
return res
#通道注意力机制
class CA_model(nn.Module):
#feature_map的大小,通道数,缩减率
def __init__(self,map_size,channel,reduction_radio):
super(CA_model, self).__init__()
self.maxpooling = nn.MaxPool2d(map_size,stride=1)
self.avgpooling = nn.AvgPool2d(map_size,stride=1)
self.MLP = MLP(channel,reduction_radio) #共享的MLP网络
self.sigmoid = nn.Sigmoid()
def forward(self,input):
#对每个通道进行最大池化和平均池化
feature_max = self.maxpooling(input).view(input.shape[0],1,-1)
feature_avg = self.avgpooling(input).view(input.shape[0],1,-1)
#将获得的两个attention map送入共享MLP中
feature_max = self.MLP(feature_max)
feature_avg = self.MLP(feature_avg)
feature_avg = self.sigmoid(feature_avg)
#最后的输出就是两个attention map的加和
return feature_avg+feature_max
# 空间注意力机制
class SA_model(nn.Module):
def __init__(self):
super(SA_model, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, padding=3, stride=1),
nn.Sigmoid()
)
def forward(self,input):
#沿着通道轴进行最大池化和平均池化
feature_max = self.maxpooling(input)
feature_avg = self.avgpooling(input)
#得到的通道间的最大池化attention map 与 平均池化的attention_map拼接在一起
feature_map = torch.cat((feature_avg,feature_max),1).view(input.shape[0],2,input.shape[2],-1)
#将拼接在一起的attention map放入一个卷积和激活
res = self.layer(feature_map)
return res
#通道间最大池化
def maxpooling(self,input):
res = torch.max(input,axis=1)[0]
return res
#通道间平均池化
def avgpooling(self,input):
res = torch.mean(input,dim=1)
return res
class conv_block_attention_model(nn.Module):
def __init__(self,map_size,channel,reduction_radio):
super(conv_block_attention_model, self).__init__()
self.CA_model = CA_model(map_size,channel,reduction_radio)
self.SA_model = SA_model()
def forward(self,input):
#先取得通道的attention map
channel_attention = self.CA_model(input)
#将通道注意力与输入相乘得到新的feature map
for i in range(input.shape[0]):
for j in range(channel_attention.shape[2]):
input[i,j] = input[i,j]*channel_attention[i,0,j]
# 用新得到的feature map获取空间的attention map
spatial_attention = self.SA_model(input)
# 将得到的attention map与加入了通道注意力的feature map按位相乘
for i in range(input.shape[0]):
for j in range(input.shape[1]):
input[i,j] = input[i,j]*spatial_attention[i]
return input