【Python】机器学习笔记10-高斯混合模型(Gaussian Mixture Model)
本文的参考资料:《Python数据科学手册》;
本文的源代上传到了Gitee上;
本文用到的包:
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from sklearn.datasets import make_blobs, make_moons, load_digits
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from sklearn.decomposition import PCA
sns.set()
plt.rc('font', family='SimHei')
plt.rc('axes', unicode_minus=False)
高斯混合模型GMM
理解K-means算法的缺陷
理解K-means模型的一种方法是:它在以每一个簇的中心为圆心画了一个圆,圆的半径是这一簇中的与簇中心距离最远的点到簇中心的距离,基于上述判断,对K-means聚类的可视化如下所示:
n_clusters = 4
x_train, y_true = make_blobs(
n_samples=200, centers=n_clusters,
cluster_std=1.5, random_state=233,
)
fig, axs = plt.subplots(1, 2, figsize=(16, 8)) # type: plt.Figure, np.ndarray
ax_data = axs[0] # type: plt.Axes
ax_pred = axs[1] # type: plt.Axes
model = KMeans(n_clusters=n_clusters)
y_pred = model.fit_predict(x_train)
cm = plt.cm.get_cmap('rainbow', lut=n_clusters)
fig.suptitle('K-means应用于圆形聚类数据(正常工作)')
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.6, cmap=cm)
ax_data.axis('equal')
ax_data.set_title('训练数据')
ax_pred.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_pred, edgecolors='k', alpha=0.6, cmap=cm)
for i in range(n_clusters):
center = model.cluster_centers_[i, :]
dot = x_train[y_pred == i]
r = 0
for j in range(dot.shape[0]):
dx = center[0] - dot[j, 0]
dy = center[1] - dot[j, 1]
r = max(r, np.sqrt(dx ** 2 + dy ** 2))
ax_pred.add_patch(plt.Circle(xy=center, radius=r, alpha=0.3, lw=3, fc='gray'))
ax_pred.axis('equal')
ax_pred.set_title('K-means聚类结果')
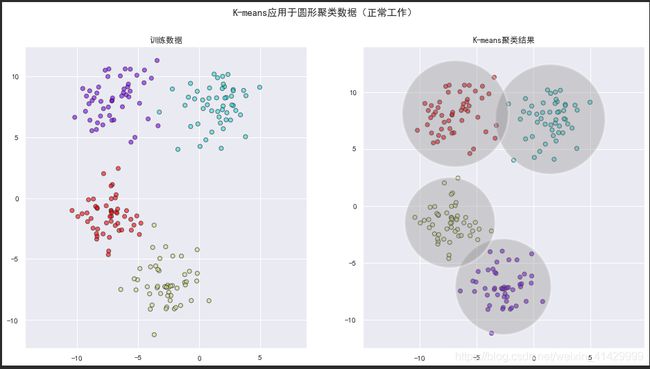
在这样的工作方式之下,每一个数据点到簇中心的距离会被作为训练集分配簇的硬切断(只能定性的判断每一个数据点属于哪一个簇,不能计算概率);同时,这也意味着K-means要求数据是接近圆形的分布,所以,如果我们对数据进行一些线性变换,K-means就会失效,如图下面的示例所示:
n_clusters = 4
x_train, y_true = make_blobs(
n_samples=200, centers=n_clusters,
cluster_std=1.5, random_state=233,
)
rng = np.random.RandomState(seed=13)
x_train = np.dot(x_train, rng.randn(2, 2))
model = KMeans(n_clusters=n_clusters)
y_pred = model.fit_predict(x_train)
fig, axs = plt.subplots(1, 2, figsize=(16, 8)) # type: plt.Figure, np.ndarray
ax_data = axs[0] # type: plt.Axes
ax_pred = axs[1] # type: plt.Axes
cm = plt.cm.get_cmap('rainbow', lut=n_clusters)
fig.suptitle('K-means应用于非圆形聚类数据(失效)')
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.6, cmap=cm)
ax_data.axis('equal')
ax_data.set_title('训练数据')
ax_pred.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_pred, edgecolors='k', alpha=0.6, cmap=cm)
for i in range(n_clusters):
center = model.cluster_centers_[i, :]
dot = x_train[y_pred == i]
r = 0
for j in range(dot.shape[0]):
dx = center[0] - dot[j, 0]
dy = center[1] - dot[j, 1]
r = max(r, np.sqrt(dx ** 2 + dy ** 2))
ax_pred.add_patch(plt.Circle(xy=center, radius=r, alpha=0.3, lw=3, fc='gray'))
ax_pred.axis('equal')
ax_pred.set_title('K-means聚类结果')
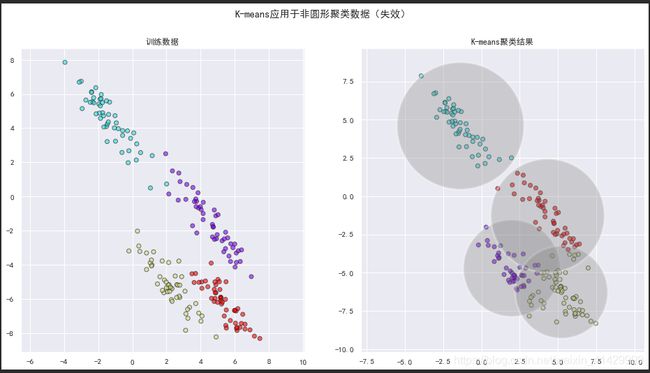
一般化的E-M:高斯混合模型(Gaussian Mixture Model)
从K-means存在的缺点出发,可以提出如下的改进意见:例如可以比较数据点与所有的簇中心的距离从而衡量这个点分配到每一个簇的概率,或者将簇的边界由正圆变为椭圆来来得到不同形状的簇,这两个改进意见构成了GMM的两个基本部分。
期望最大化应用于GMM的步骤:
- 确定初始簇的位置和形状
- 重复一下步骤直至结果收敛:
- 为每一个点找到对应属于每个簇的概率作为权重
- 更新每个簇的位置,将其标准化,并给予所有数据点的权重来确定簇的形状
在sklearn中,高斯混合模型由GaussianMixture类实现,这个类的covariance_type参数控制了每一个簇的形状自由度;
covariance_type=diag时,簇在每个维度的尺寸可以单独设置,但是椭圆的边界与主轴坐标平行;
covariance_type=spherical时,簇在每个维度上的尺寸相等,效果类似于K-means;
covariance_type=full时,允许每一个簇在任意方向上改变尺寸;
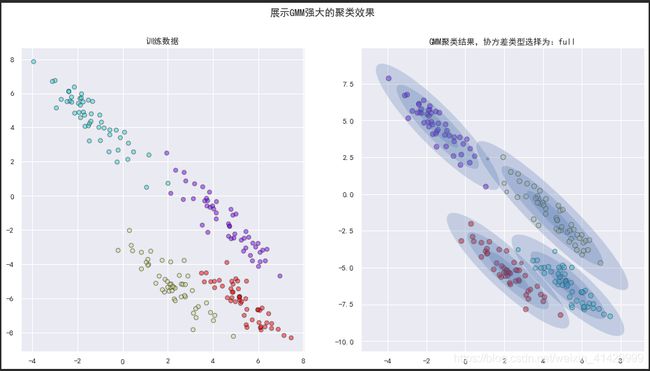
在之前的数据上使用高斯混合模型,效果如下:
n_clusters = 4
x_train, y_true = make_blobs(
n_samples=200, centers=n_clusters,
cluster_std=1.5, random_state=233,
)
rng = np.random.RandomState(seed=13)
x_train = np.dot(x_train, rng.randn(2, 2))
model = GaussianMixture(n_components=n_clusters, covariance_type='full')
model.fit(x_train)
y_pred = model.predict(x_train)
y_prob = model.predict_proba(x_train)
fig, axs = plt.subplots(1, 2, figsize=(16, 8)) # type: plt.Figure, list
ax_data = axs[0] # type: plt.Axes
ax_pred = axs[1] # type: plt.Axes
cm = plt.cm.get_cmap('rainbow', lut=4)
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.5, cmap=cm)
ax_data.set_title('训练数据')
ax_pred.scatter(
x=x_train[:, 0], y=x_train[:, 1], c=y_pred, s=50 * y_prob.max(axis=1) ** 4,
edgecolors='k', alpha=0.5, cmap=cm,
)
for pos, cov, w in zip(model.means_, model.covariances_, model.weights_): # 椭圆的画法就照抄书本了
u, s, vt = np.linalg.svd(cov)
angle = np.degrees(np.arctan2(u[1, 0], u[0, 0]))
width, height = 2 * np.sqrt(s)
for nsig in range(1, 4):
ax_pred.add_patch(Ellipse(
pos, nsig * width, nsig * height, angle,
alpha=w,
))
ax_pred.set_title(f'GMM聚类结果,协方差类型选择为:{model.covariance_type}')
fig.suptitle('展示GMM强大的聚类效果')
(这里以概率大小作为了每一个点的尺寸)
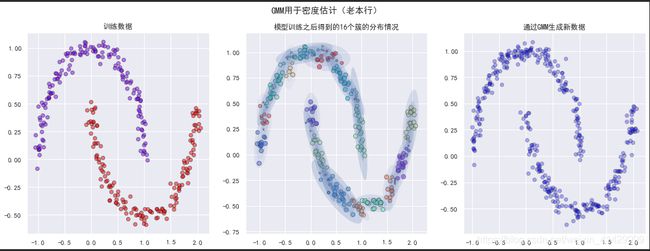
将GMM用于密度估计
虽然我们这里将GMM当作聚类算法进行介绍,但是GMM在本质上是一个密度估计算法,用于描述数据分布的生成概率模型;
例如,下面我们使用一个16簇的GMM模型拟合数据,然后通过拟合得到的16个成分的分布情况并生成新的数据;
n_clusters=16
fig, axs = plt.subplots(1, 3, figsize=(18, 6)) # type: plt.Figure, list
ax_data, ax_model, ax_resample = (i for i in axs) # type: plt.Axes, plt.Axes, plt.Axes
cm = plt.cm.get_cmap('rainbow', lut=n_clusters)
x_train, y_true = make_moons(n_samples=300, random_state=233, noise=0.05)
model = GaussianMixture(n_components=n_clusters, covariance_type='full')
model.fit(x_train)
y_pred = model.predict(x_train)
y_prob = model.predict_proba(x_train)
x_resample = model.sample(n_samples=400)[0]
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.5, cmap=cm)
ax_data.set_title('训练数据')
ax_model.scatter(
x=x_train[:, 0], y=x_train[:, 1], c=y_pred, s=50 * y_prob.max(axis=1) ** 4,
edgecolors='k', alpha=0.5, cmap=cm,
)
for pos, cov, w in zip(model.means_, model.covariances_, model.weights_): # 椭圆的画法就照抄书本了
u, s, vt = np.linalg.svd(cov)
angle = np.degrees(np.arctan2(u[1, 0], u[0, 0]))
width, height = 2 * np.sqrt(s)
for nsig in range(1, 4):
ax_model.add_patch(Ellipse(
pos, nsig * width, nsig * height, angle,
alpha=2.33 * w,
))
ax_model.set_title(f'模型训练之后得到的{model.n_components}个簇的分布情况')
ax_resample.scatter(x=x_resample[:, 0], y=x_resample[:, 1], c='blue', edgecolors='k', alpha=0.3, cmap=cm)
ax_resample.set_title('通过GMM生成新数据')
fig.suptitle('GMM用于密度估计(老本行)')
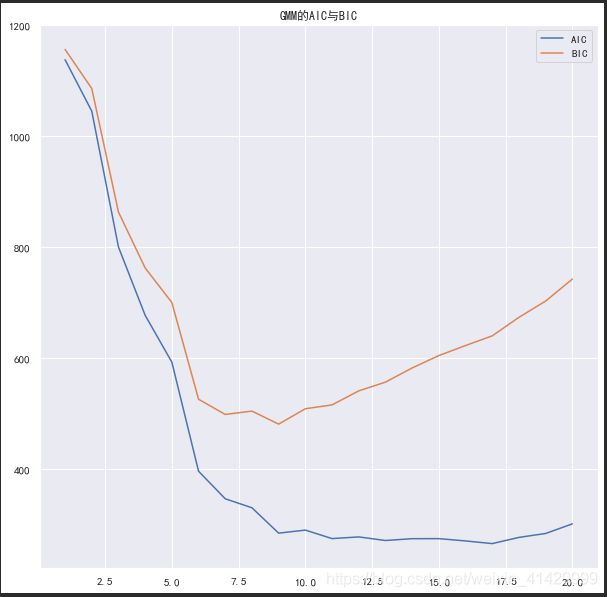
既然要使用GMM来进行密度估计,就会牵扯到到底要使用多少个簇的问题,sklearn中的GMM模型内置了两种度量准则:**赤池信息量准则(AIC)和贝叶斯信息准则(BIC)**来帮助我们确定GMM模型的最佳成分数;
一般来讲,对应AIC或者BIC最小的成分数是最佳的;
AIC和BIC两个指标可以由GaussianMixture类的aic函数和bic函数计算;
models = [GaussianMixture(n_components=i, random_state=233, covariance_type='full').fit(x_train) for i in range(1, 20 + 1)]
aic = [m.aic(x_train) for m in models]
bic = [m.bic(x_train) for m in models]
plt.figure(figsize=(10, 10))
plt.plot(range(1, 20 + 1), aic, label='AIC')
plt.plot(range(1, 20 + 1), bic, label='BIC')
plt.legend(loc='upper right')
plt.title('GMM的AIC与BIC')
案例:使用GMM生成新的手写数字
由于我们使用的手写数字由64维,而GMM在高维数据中可能不太会收敛,我们首先使用PCA进行降维,保留99%的方差;
将数据降维之后,我们使用GMM内置的AIC和BIC函数计算不同成分数下模型的这两个指标,确定最后使用的成分数,这里选择100个成分;
最后使用训练好的GMM模型生成数据,然后使用之前的PCA模型将数据重新转换至64维,并显示,查看效果;
降维并确定成分数:
digits = load_digits()
pca = PCA(n_components=0.99, whiten=True)
digits_data_reduced = pca.fit_transform(digits.data)
print(f'原始数据维度:{digits.data.shape[-1]}')
print(f'使用PCA降维并保留{pca.n_components * 100}%方差后的维度:{digits_data_reduced.shape[-1]}')
n_components = list(range(50, 200 + 1, 5))
models = [GaussianMixture(n_components=i, covariance_type='full').fit(digits_data_reduced) for i in n_components]
aic = [m.aic(digits_data_reduced) for m in models]
bic = [m.bic(digits_data_reduced) for m in models]
plt.figure(figsize=(10, 10))
plt.plot(n_components, aic, label='AIC')
plt.plot(n_components, bic, label='BIC')
plt.legend(loc='upper right')
plt.title('确定对手写数字使用GMM的最佳成分数')

训练模型并生成新的手写数字:
model = GaussianMixture(n_components=100, covariance_type='full')
model.fit(digits_data_reduced)
digits_new = model.sample(200)[0]
digits_new = pca.inverse_transform(digits_new)
digits_new = digits_new.reshape(digits_new.shape[0], 8, 8)
fig, axs = plt.subplots(10, 10, figsize=(12, 12)) # type: plt.Figure, np.ndarray
fig.subplots_adjust(hspace=0.1, wspace=0.1)
fig.suptitle('手写数字-训练数据')
for i, ax in enumerate(axs.flatten()): # type: int, plt.Axes
ax.imshow(digits.data[i].reshape(8, 8), cmap='binary', origin='lower')
ax.set_xticks([])
ax.set_yticks([])
ax.text(x=0, y=0, s=str(digits.target_names[digits.target[i]]), color='green')
fig, axs = plt.subplots(10, 10, figsize=(12, 12)) # type: plt.Figure, np.ndarray
fig.subplots_adjust(hspace=0.1, wspace=0.1)
fig.suptitle('手写数字-使用GMM学习后生成')
for i, ax in enumerate(axs.flatten()): # type: int, plt.Axes
ax.imshow(digits_new[i], cmap='binary', origin='lower')
ax.set_xticks([])
ax.set_yticks([])


我最后做出来的结果并没有书本上的结果那么理想,原因暂时未知;
完整代码(Jupyter Notebook)
#%% md
# 高斯混合模型GMM
## 理解K-means算法的缺陷
理解K-means模型的一种方法是:它在以每一个簇的中心为圆心画了一个圆,圆的半径是这一簇中的与簇中心距离最远的点到簇中心的距离,基于上述判断,
对K-means聚类的可视化如下所示:
在这样的工作方式之下,每一个数据点到簇中心的距离会被作为训练集分配簇的**硬切断**(只能定性的判断每一个数据点属于哪一个簇,不能计算概率),
同时,这也意味着K-means要求数据是接近圆形的分布,所以,如果我们对数据进行一些线性变换,K-means就会失效,如图所示:
#%%
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from sklearn.datasets import make_blobs, make_moons, load_digits
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
from sklearn.decomposition import PCA
sns.set()
plt.rc('font', family='SimHei')
plt.rc('axes', unicode_minus=False)
#%%
n_clusters = 4
x_train, y_true = make_blobs(
n_samples=200, centers=n_clusters,
cluster_std=1.5, random_state=233,
)
fig, axs = plt.subplots(1, 2, figsize=(16, 8)) # type: plt.Figure, np.ndarray
ax_data = axs[0] # type: plt.Axes
ax_pred = axs[1] # type: plt.Axes
model = KMeans(n_clusters=n_clusters)
y_pred = model.fit_predict(x_train)
cm = plt.cm.get_cmap('rainbow', lut=n_clusters)
fig.suptitle('K-means应用于圆形聚类数据(正常工作)')
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.6, cmap=cm)
ax_data.axis('equal')
ax_data.set_title('训练数据')
ax_pred.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_pred, edgecolors='k', alpha=0.6, cmap=cm)
for i in range(n_clusters):
center = model.cluster_centers_[i, :]
dot = x_train[y_pred == i]
r = 0
for j in range(dot.shape[0]):
dx = center[0] - dot[j, 0]
dy = center[1] - dot[j, 1]
r = max(r, np.sqrt(dx ** 2 + dy ** 2))
ax_pred.add_patch(plt.Circle(xy=center, radius=r, alpha=0.3, lw=3, fc='gray'))
ax_pred.axis('equal')
ax_pred.set_title('K-means聚类结果')
#%%
n_clusters = 4
x_train, y_true = make_blobs(
n_samples=200, centers=n_clusters,
cluster_std=1.5, random_state=233,
)
rng = np.random.RandomState(seed=13)
x_train = np.dot(x_train, rng.randn(2, 2))
model = KMeans(n_clusters=n_clusters)
y_pred = model.fit_predict(x_train)
fig, axs = plt.subplots(1, 2, figsize=(16, 8)) # type: plt.Figure, np.ndarray
ax_data = axs[0] # type: plt.Axes
ax_pred = axs[1] # type: plt.Axes
cm = plt.cm.get_cmap('rainbow', lut=n_clusters)
fig.suptitle('K-means应用于非圆形聚类数据(失效)')
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.6, cmap=cm)
ax_data.axis('equal')
ax_data.set_title('训练数据')
ax_pred.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_pred, edgecolors='k', alpha=0.6, cmap=cm)
for i in range(n_clusters):
center = model.cluster_centers_[i, :]
dot = x_train[y_pred == i]
r = 0
for j in range(dot.shape[0]):
dx = center[0] - dot[j, 0]
dy = center[1] - dot[j, 1]
r = max(r, np.sqrt(dx ** 2 + dy ** 2))
ax_pred.add_patch(plt.Circle(xy=center, radius=r, alpha=0.3, lw=3, fc='gray'))
ax_pred.axis('equal')
ax_pred.set_title('K-means聚类结果')
#%% md
## 一般化的E-M:高斯混合模型(Gaussian Mixture Model)
从K-means存在的缺点出发,可以提出如下的改进意见:例如可以比较数据点与所有的簇中心的距离从而衡量这个点分配到每一个簇的概率,或者将簇的边界由正圆
变为椭圆来来得到不同形状的簇,这两个改进意见构成了GMM的两个基本部分。
期望最大化应用于GMM的步骤:
- 确定初始簇的位置和形状
- 重复一下步骤直至结果收敛:
- 为每一个点找到对应属于每个簇的概率作为权重
- 更新每个簇的位置,将其标准化,并给予所有数据点的权重来确定簇的形状
在sklearn中,高斯混合模型由GaussianMixture类实现,这个类的covariance_type参数控制了每一个簇的形状自由度;<br>
covariance_type=diag时,簇在每个维度的尺寸可以单独设置,但是椭圆的边界与主轴坐标平行;<br>
covariance_type=spherical时,簇在每个维度上的尺寸相等,效果类似于K-means;<br>
covariance_type=full时,允许每一个簇在任意方向上改变尺寸;
#%%
n_clusters = 4
x_train, y_true = make_blobs(
n_samples=200, centers=n_clusters,
cluster_std=1.5, random_state=233,
)
rng = np.random.RandomState(seed=13)
x_train = np.dot(x_train, rng.randn(2, 2))
model = GaussianMixture(n_components=n_clusters, covariance_type='full')
model.fit(x_train)
y_pred = model.predict(x_train)
y_prob = model.predict_proba(x_train)
fig, axs = plt.subplots(1, 2, figsize=(16, 8)) # type: plt.Figure, list
ax_data = axs[0] # type: plt.Axes
ax_pred = axs[1] # type: plt.Axes
cm = plt.cm.get_cmap('rainbow', lut=4)
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.5, cmap=cm)
ax_data.set_title('训练数据')
ax_pred.scatter(
x=x_train[:, 0], y=x_train[:, 1], c=y_pred, s=50 * y_prob.max(axis=1) ** 4,
edgecolors='k', alpha=0.5, cmap=cm,
)
for pos, cov, w in zip(model.means_, model.covariances_, model.weights_): # 椭圆的画法就照抄书本了
u, s, vt = np.linalg.svd(cov)
angle = np.degrees(np.arctan2(u[1, 0], u[0, 0]))
width, height = 2 * np.sqrt(s)
for nsig in range(1, 4):
ax_pred.add_patch(Ellipse(
pos, nsig * width, nsig * height, angle,
alpha=w,
))
ax_pred.set_title(f'GMM聚类结果,协方差类型选择为:{model.covariance_type}')
fig.suptitle('展示GMM强大的聚类效果')
#%% md
## 将GMM用于密度估计
虽然我们这里将GMM当作聚类算法进行介绍,但是GMM在本质上是一个**密度估计算法**,用于描述**数据分布的生成概率模型**;<br>
例如,下面我们使用一个16簇的GMM模型拟合数据,然后通过拟合得到的16个成分的分布情况生成新的数据;<br>
既然要使用GMM来进行密度估计,就会牵扯到到底要使用多少个簇的问题,sklearn中的GMM模型内置了两种度量准则:**赤池信息量准则(AIC)**和
**贝叶斯信息准则(BIC)**来帮助我们确定GMM模型的最佳成分数;<br>
一般来讲,对应AIC或者BIC最小的成分数是最佳的;
#%%
n_clusters=16
fig, axs = plt.subplots(1, 3, figsize=(18, 6)) # type: plt.Figure, list
ax_data, ax_model, ax_resample = (i for i in axs) # type: plt.Axes, plt.Axes, plt.Axes
cm = plt.cm.get_cmap('rainbow', lut=n_clusters)
x_train, y_true = make_moons(n_samples=300, random_state=233, noise=0.05)
model = GaussianMixture(n_components=n_clusters, covariance_type='full')
model.fit(x_train)
y_pred = model.predict(x_train)
y_prob = model.predict_proba(x_train)
x_resample = model.sample(n_samples=400)[0]
ax_data.scatter(x=x_train[:, 0], y=x_train[:, 1], c=y_true, edgecolors='k', alpha=0.5, cmap=cm)
ax_data.set_title('训练数据')
ax_model.scatter(
x=x_train[:, 0], y=x_train[:, 1], c=y_pred, s=50 * y_prob.max(axis=1) ** 4,
edgecolors='k', alpha=0.5, cmap=cm,
)
for pos, cov, w in zip(model.means_, model.covariances_, model.weights_): # 椭圆的画法就照抄书本了
u, s, vt = np.linalg.svd(cov)
angle = np.degrees(np.arctan2(u[1, 0], u[0, 0]))
width, height = 2 * np.sqrt(s)
for nsig in range(1, 4):
ax_model.add_patch(Ellipse(
pos, nsig * width, nsig * height, angle,
alpha=2.33 * w,
))
ax_model.set_title(f'模型训练之后得到的{model.n_components}个簇的分布情况')
ax_resample.scatter(x=x_resample[:, 0], y=x_resample[:, 1], c='blue', edgecolors='k', alpha=0.3, cmap=cm)
ax_resample.set_title('通过GMM生成新数据')
fig.suptitle('GMM用于密度估计(老本行)')
models = [GaussianMixture(n_components=i, random_state=233, covariance_type='full').fit(x_train) for i in range(1, 20 + 1)]
aic = [m.aic(x_train) for m in models]
bic = [m.bic(x_train) for m in models]
plt.figure(figsize=(10, 10))
plt.plot(range(1, 20 + 1), aic, label='AIC')
plt.plot(range(1, 20 + 1), bic, label='BIC')
plt.legend(loc='upper right')
plt.title('GMM的AIC与BIC')
#%% md
## 案例:使用GMM生成新的手写数字
由于我们使用的手写数字由64维,而GMM在高维数据中可能不太会收敛,我们首先使用PCA进行降维,保留99%的方差;
将数据降维之后,我们使用GMM内置的AIC和BIC函数计算不同成分数下模型的两个标准,确定最后使用的成分数,这里选择100个成分;
最后使用训练好的GMM模型生成数据,然后使用之前的PCA模型将数据重新转换至64维,并显示,查看效果;
#%%
digits = load_digits()
pca = PCA(n_components=0.99, whiten=True)
digits_data_reduced = pca.fit_transform(digits.data)
print(f'原始数据维度:{digits.data.shape[-1]}')
print(f'使用PCA降维并保留{pca.n_components * 100}%方差后的维度:{digits_data_reduced.shape[-1]}')
n_components = list(range(50, 200 + 1, 5))
models = [GaussianMixture(n_components=i, covariance_type='full').fit(digits_data_reduced) for i in n_components]
aic = [m.aic(digits_data_reduced) for m in models]
bic = [m.bic(digits_data_reduced) for m in models]
plt.figure(figsize=(10, 10))
plt.plot(n_components, aic, label='AIC')
plt.plot(n_components, bic, label='BIC')
plt.legend(loc='upper right')
plt.title('确定对手写数字使用GMM的最佳成分数')
#%%
model = GaussianMixture(n_components=100, covariance_type='full')
model.fit(digits_data_reduced)
digits_new = model.sample(200)[0]
digits_new = pca.inverse_transform(digits_new)
digits_new = digits_new.reshape(digits_new.shape[0], 8, 8)
fig, axs = plt.subplots(10, 10, figsize=(12, 12)) # type: plt.Figure, np.ndarray
fig.subplots_adjust(hspace=0.1, wspace=0.1)
fig.suptitle('手写数字-训练数据')
for i, ax in enumerate(axs.flatten()): # type: int, plt.Axes
ax.imshow(digits.data[i].reshape(8, 8), cmap='binary', origin='lower')
ax.set_xticks([])
ax.set_yticks([])
ax.text(x=0, y=0, s=str(digits.target_names[digits.target[i]]), color='green')
fig, axs = plt.subplots(10, 10, figsize=(12, 12)) # type: plt.Figure, np.ndarray
fig.subplots_adjust(hspace=0.1, wspace=0.1)
fig.suptitle('手写数字-使用GMM学习后生成')
for i, ax in enumerate(axs.flatten()): # type: int, plt.Axes
ax.imshow(digits_new[i], cmap='binary', origin='lower')
ax.set_xticks([])
ax.set_yticks([])